This section presents the theory of the models used to develop this work. First, important concepts of competitive neural networks are explained. Second, a summary of the theory of fuzzy sets is presented, ending with the discussion subsection.
2.1. Competitive Neural Network
Competitive Neural Networks deviate from traditional feedforward neural networks by introducing a competitive layer. This layer is often referred to as the competitive or Kohonen layer which facilitates competition among neurons. Neurons compete to become the most responsive to specific input patterns, fostering a dynamic environment where only the most relevant neurons survive and adapt [
18].
Competitive Neural Networks work in unsupervised learning scenarios, where the network must identify patterns and structure within the data without explicit labels. The competitive layer fosters neuron specialization, with each neuron becoming an expert in recognizing a specific pattern or feature. Through continuous competition and adaptation, the network refines its internal representation, making it highly adept at capturing intricate relationships within the input data.
In [
19] the authors describe three fundamental components of competitive learning rules:
Activation of Neuron Set: Neurons (process units) exhibit activation or inactivity in response to specific input patterns. Distinct synaptic weight values are assigned to each neuron, contributing to individualized responsiveness.
Limitation on Neuron Strength: A constraint is applied to the “strength” of each neuron, regulating its responsiveness within the network.
Competitive Mechanism: Neurons compete to respond to subsets of input patterns. The outcome is designed such that only one neuron from the group is activated, promoting specialization.
Moreover, within a CNN, a binary process unit serves as a simple computational entity capable of assuming only two states: active (on) or inactive (off). For each binary process unit i, there exists an associated synaptic weights vector () to weigh the incoming values from the input vectors.
The synaptic potential is defined as follows: if
signals, represented by the vector
), reach the processing unit
i, and the synaptic weights vector of each unit is
, then the synaptic potential is computed using Equations (1) and (2).
where:
Defined by
N input sensors,
M process units, and interconnecting links between each sensor and process unit, a CNN is characterized by the association of specific values, denoted as
, with each connection linking sensor
to process unit
.
Figure 1 provides a visual representation of a Competitive Neural Network (CNN).
With each input collected by the sensors, the activation of only one process unit occurs, specifically the unit with the highest synaptic potential, which is acknowledged as the winning unit.
Consequently, when denoting the state of process unit
with the variable
, it adopts a value of 1 during activation and 0 otherwise. The computational dynamics of the network are obtained by Equation (3).
The synaptic weights are established through an unsupervised learning process. The objective is to activate the process unit whose synaptic weight vector is most similar to the input vector. The degree of similarity between the input vector
and the synaptic weights vector of process unit
,
), is determined by the Euclidean distance between these vectors. This distance is given by Equation (4).
Hence, if
represents the winning process unit, after introduction of the input pattern, the validation that the winning unit possesses the synaptic weight vector most similar to the input vector is expressed through Equation (5).
The aim of the unsupervised learning in the CNN is to autonomously identify groups or classes. To achieve this, the criterion of the minimum squares is calculated using Equation (6).
In (6),
denotes the error in iteration
k, derived from the distance between the input pattern
belonging to class M and the synaptic weight vector
. This is identified as the learning rule, which is denoted in Equation (7).
In this scenario, the new synaptic weights vector
is a linear combination of the vectors
and
, with
representing the learning rate, as expressed in Equation (8), where
is the current iteration and T is the total number of the iterations; therefore, the initial value of
could be (0, 1). The learning rate will be decrementing; if
reaches 0, the CNN will stop learning.
In the state of the art method, we can find a large number of research works, exploiting the advantages of Competitive Neural Networks or Competitive Learning and applying them in different areas. In [
9], the author provides a comprehensive overview of competitive learning-based clustering methods. In [
11], a framework for different clustering methods like Fuzzy C-Means and K-Means clustering, entropy constrained vector quantization, or topological feature maps and CNN is proposed. In [
20], the authors explore the exponential synchronization problem for a class of the CNN.
In other applications, the CompNet model based on Competitive Neural Networks and Learnable Gabor Kernels is presented in [
21], the model is implemented for Palmprint Recognition; according to the results, the proposal achieved the lowest error rate compared to the most commonly state of the art methods. In [
22], a Competitive Neural Network is used to estimate a rice-plant area; the authors demonstrate that these kinds of models are useful for the classification of the satellite data. In hybrid methods, in [
23], the CNN is optimized and is applied to solve a complex problem in the field of chemical engineering; the authors proposed a novel neural network optimizer that leverages the advantages of both an improved evolutionary competitive algorithm and gradient-based backpropagation. In [
24], the Fireworks Algorithm (FWA) was implemented to optimize the neurons of the CNN and improve the results of the traditional model. In order to improve the CNN, a novel classification algorithm that is based on the integration between competitive learning and the computational power of quantum computing is presented in [
25]. These and other researches [
26] demonstrate the potential of this area to solve a variety of problems.
2.2. Fuzzy Sets
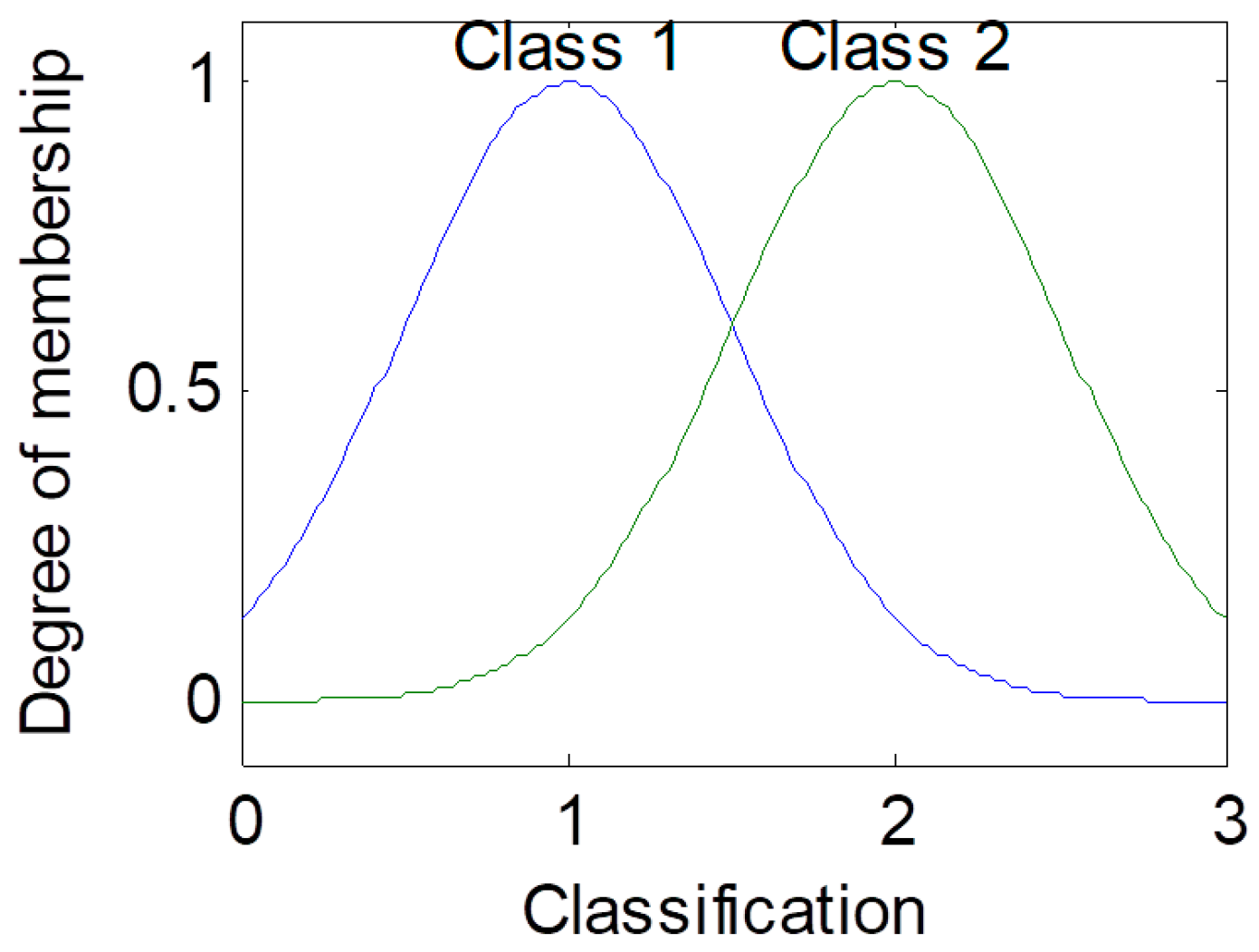
A fuzzy set is characterized by a membership function that assigns a degree of membership to each element of the universal set. The membership function represents the uncertainty or vagueness associated with the degree to which an element belongs to a particular set [
16,
17].
The most popular Type-1 FISs are Mamdani [
27] and Takagi–Sugeno–Kang [
28]. The Mamdani FIS [
27] is a model based on fuzzy logic principles that facilitates the representation and processing of uncertain or imprecise information. It has been successfully applied in several domains, due to its ability to model complex systems and handle linguistic variables in a way that humans can interpret. In this system, antecedents and consequents are represented by fuzzy membership functions.
The Takagi–Sugeno–Kang FIS, better known as Sugeno FIS, is a type of fuzzy logic system that uses linguistic rules and fuzzy logic principles to model and infer relationships between input and output variables. Introduced by Takagi and Sugeno [
28], the Sugeno FIS represents rules in an IF-THEN format, where the antecedents are formed using fuzzy sets and the consequents are linear functions. This model is widely applied in areas such as control systems, decision making, and pattern recognition due to its transparency and ease of interpretation.
Researchers around the world have incorporated the fuzzy sets theory to solve classification challenges, more specifically, to classify features with a high degree of similarity or uncertainty for different datasets. In [
6], the authors proposed a fuzzy clustering method using Interval Type-2 FIS combined with Possibilistic C-Means (PCM) and Fuzzy C-Means (FCM) clustering algorithms. In [
29], optimization with swarm algorithms is applied to enhance an Interval Type-2 Fuzzy FIS for data classification. The proposal was tested on datasets from the UCI machine learning library and satellite image data. The results demonstrate that utilizing optimization algorithms can significantly improve accuracy in solving data classification problems. In [
30], the authors introduce an unsupervised outlier detection algorithm which implements K-NN and fuzzy logic. Recognizing the limitations of unsupervised approaches in handling complex datasets, the authors provide a solution to this problem by proposing the utilization of K-NN rule and fuzzy logic for effective outlier detection. In [
31], a hybrid method based on fuzzy logic and Genetic Algorithm applied to the text classification Twitter is proposed. In [
32], the approach combines Fuzzy C-Means clustering and a fuzzy inference system for an audiovisual quality of experience. Experimental analyses indicate that the proposed framework outperforms methods without optimization and existing models, specifically MLP-based techniques.
2.3. Discussion
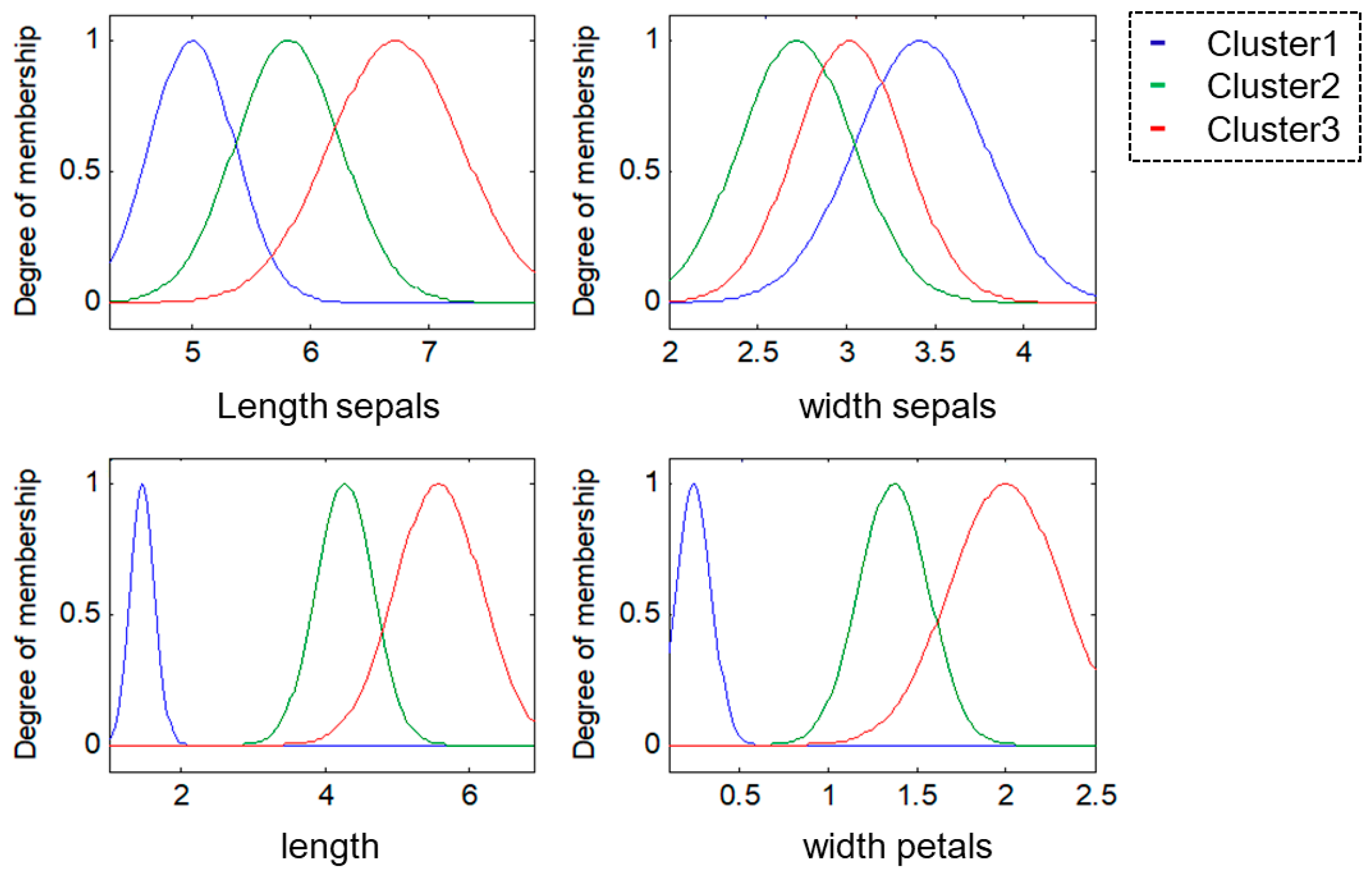
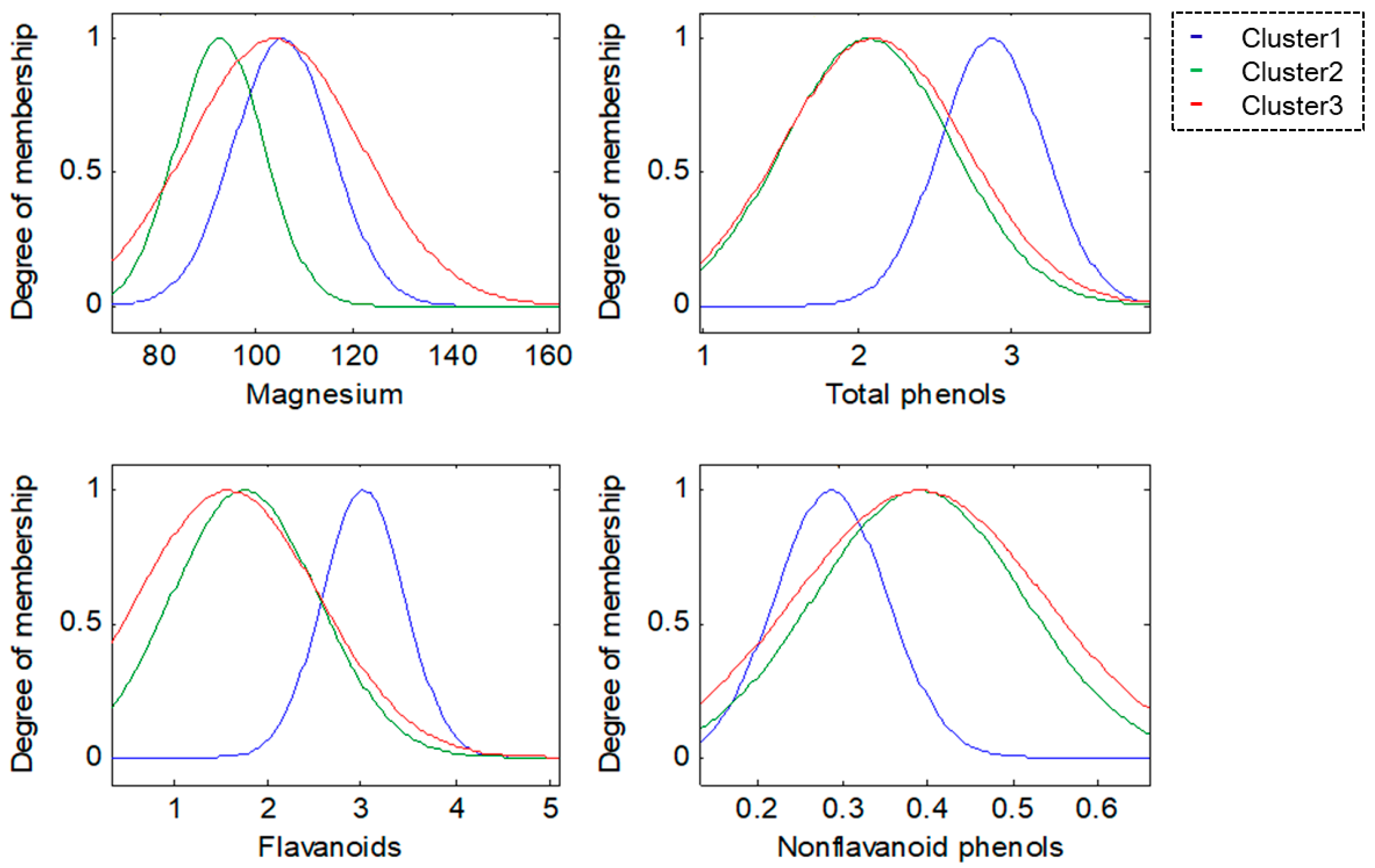
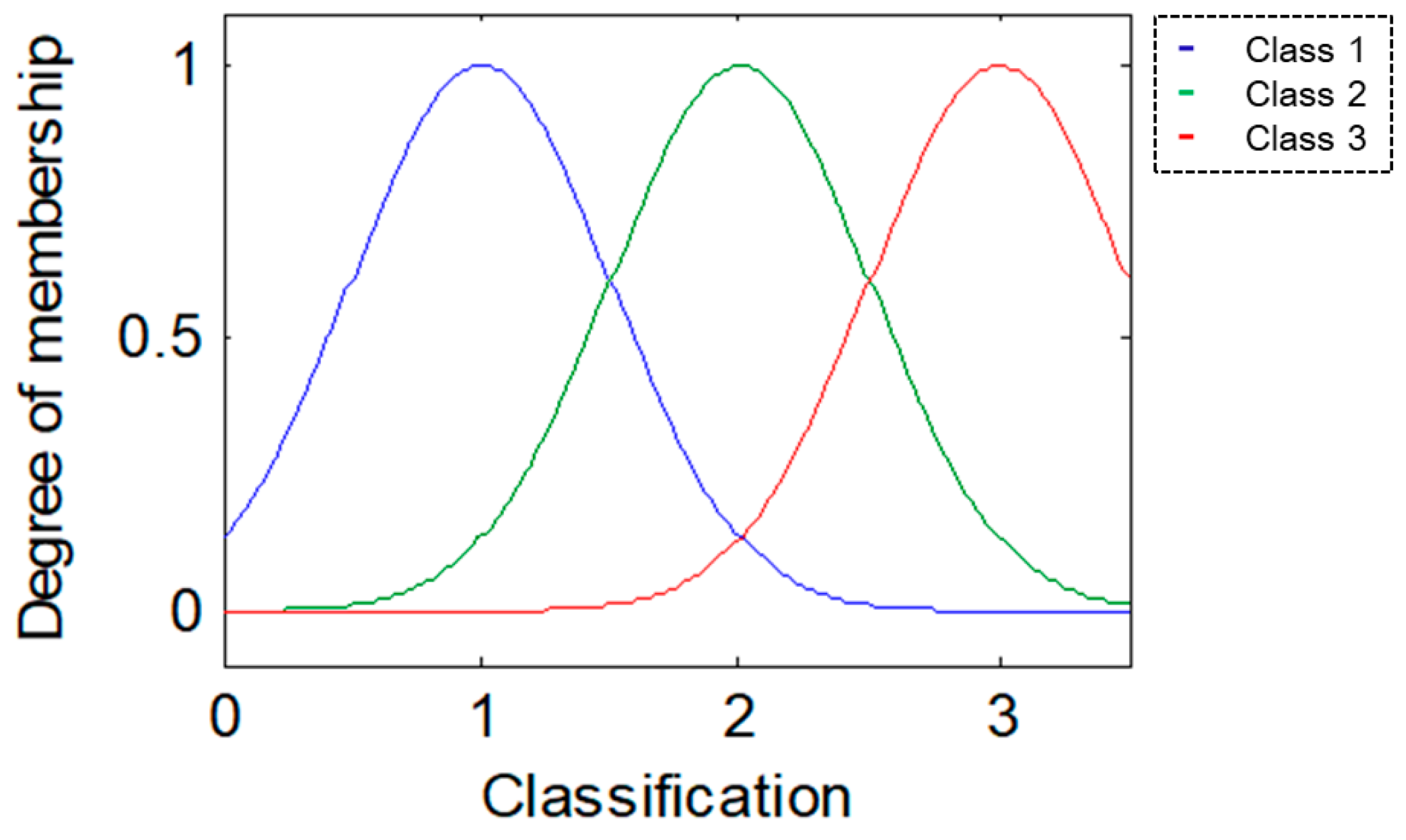
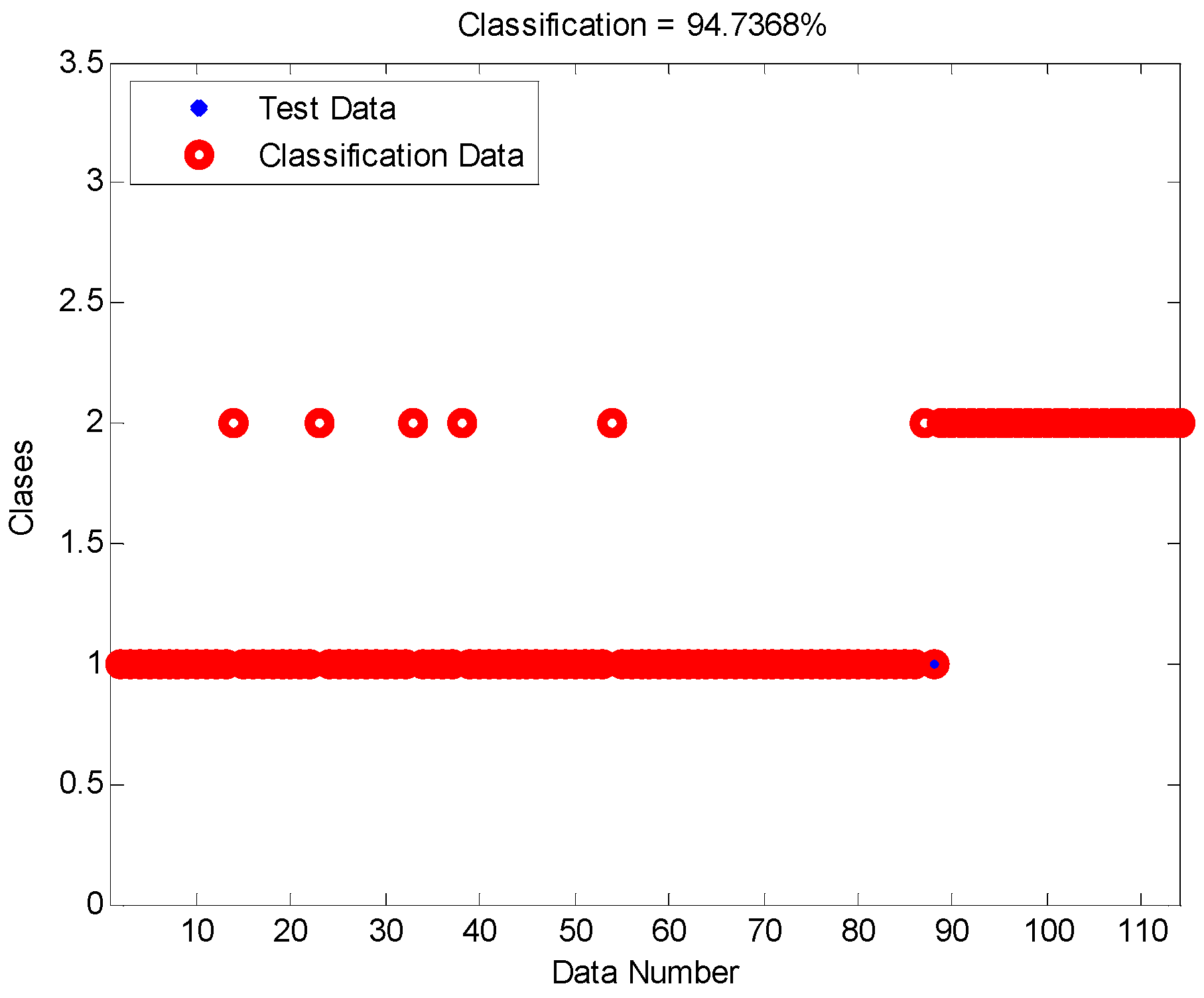
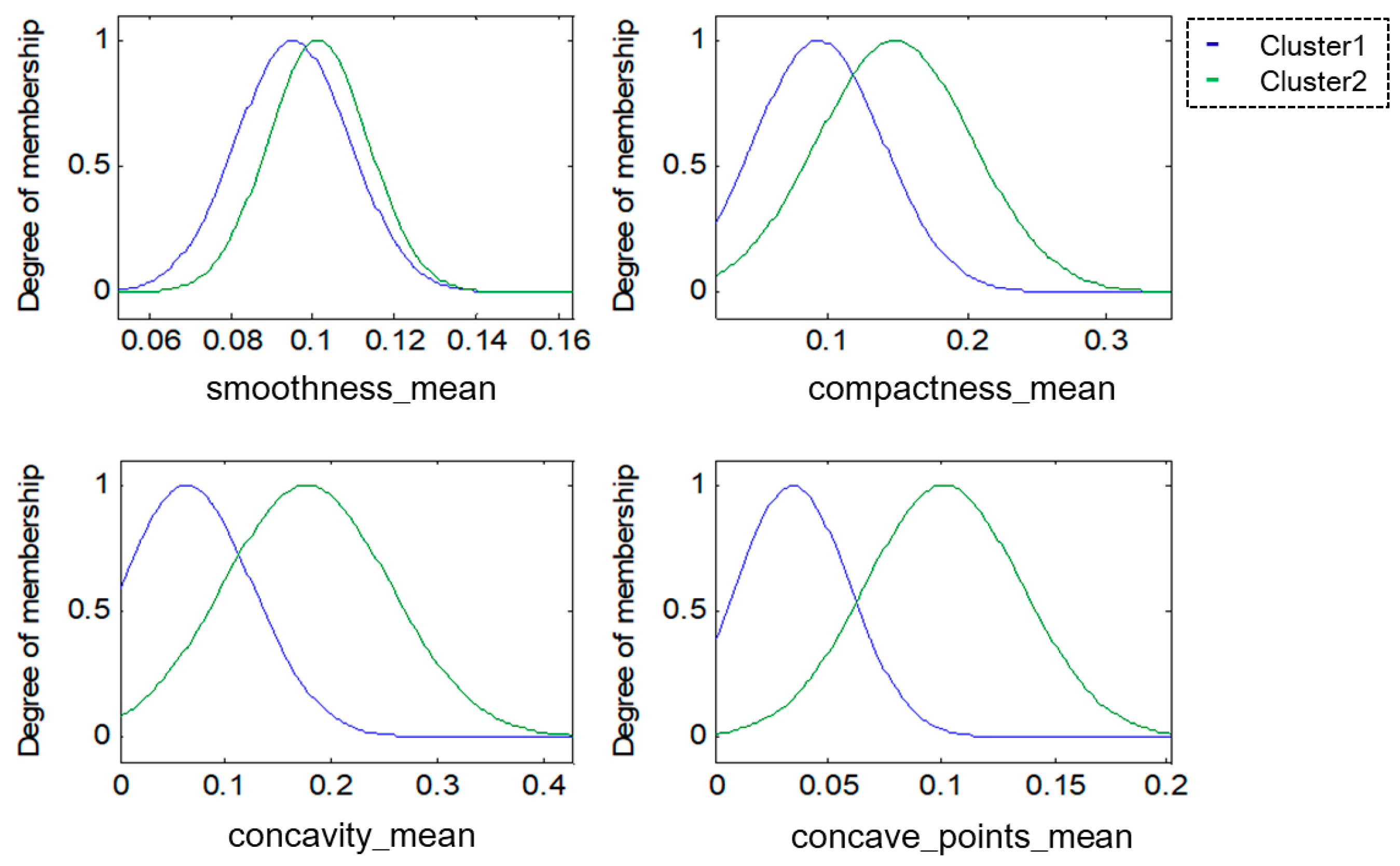
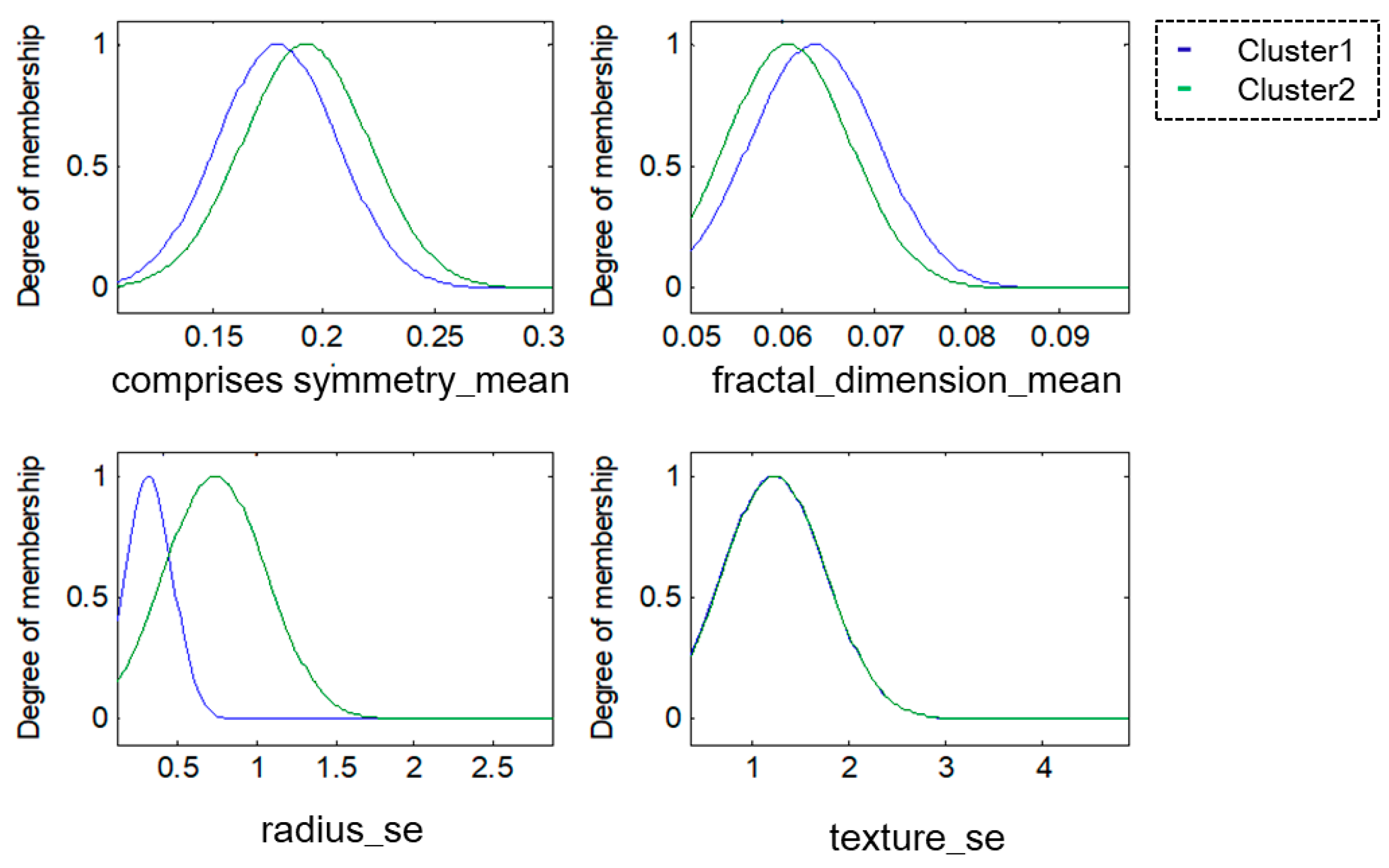
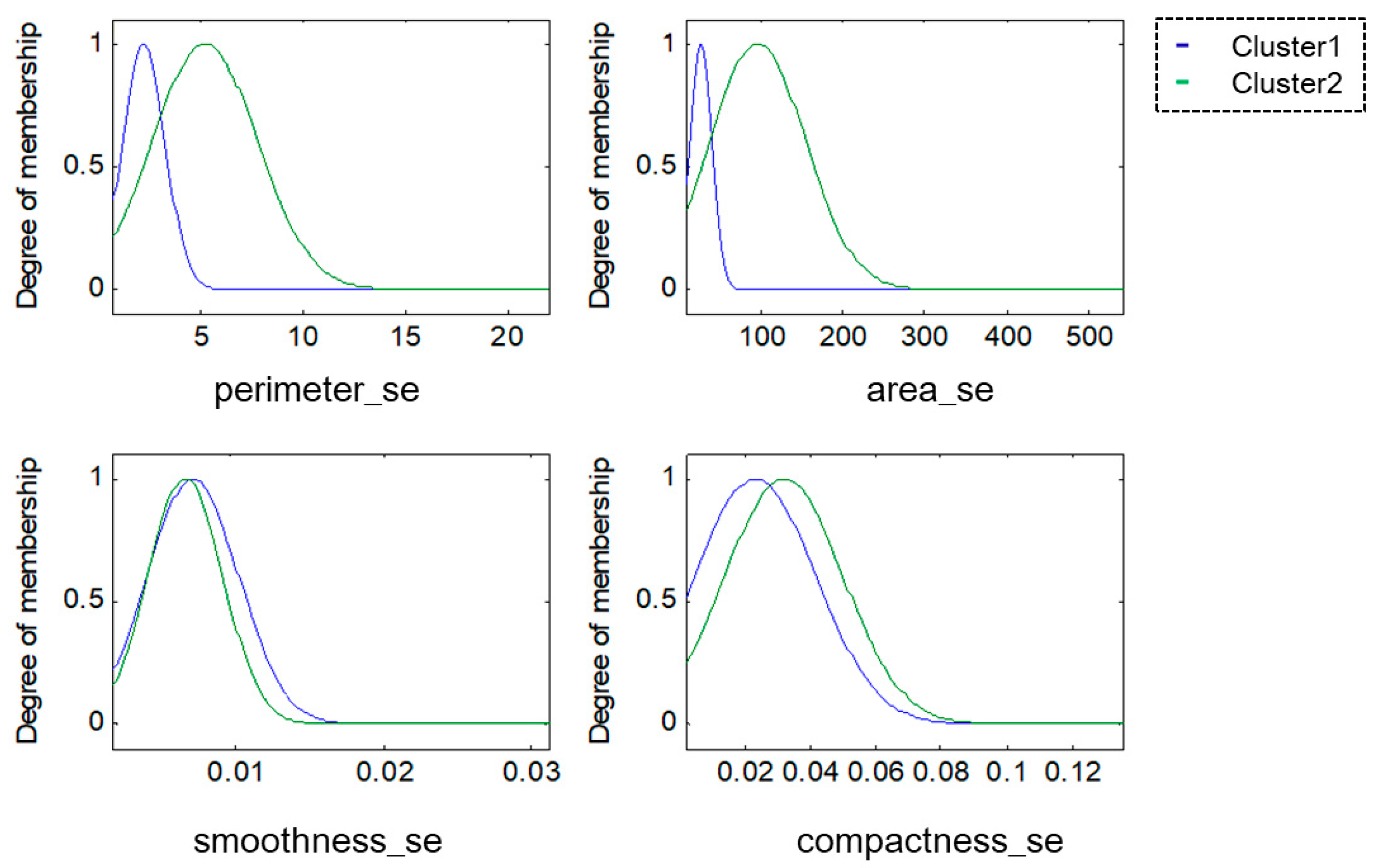
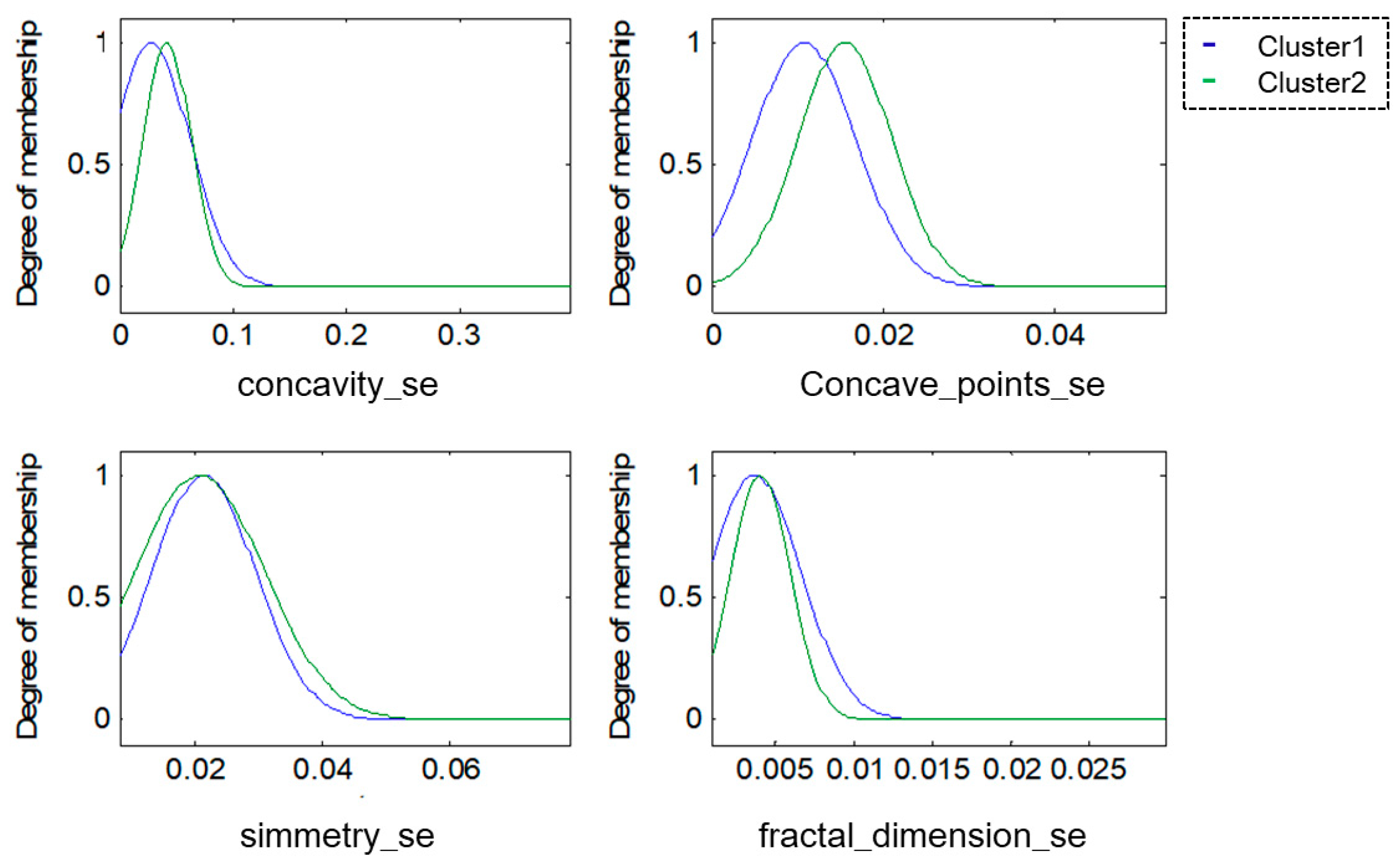
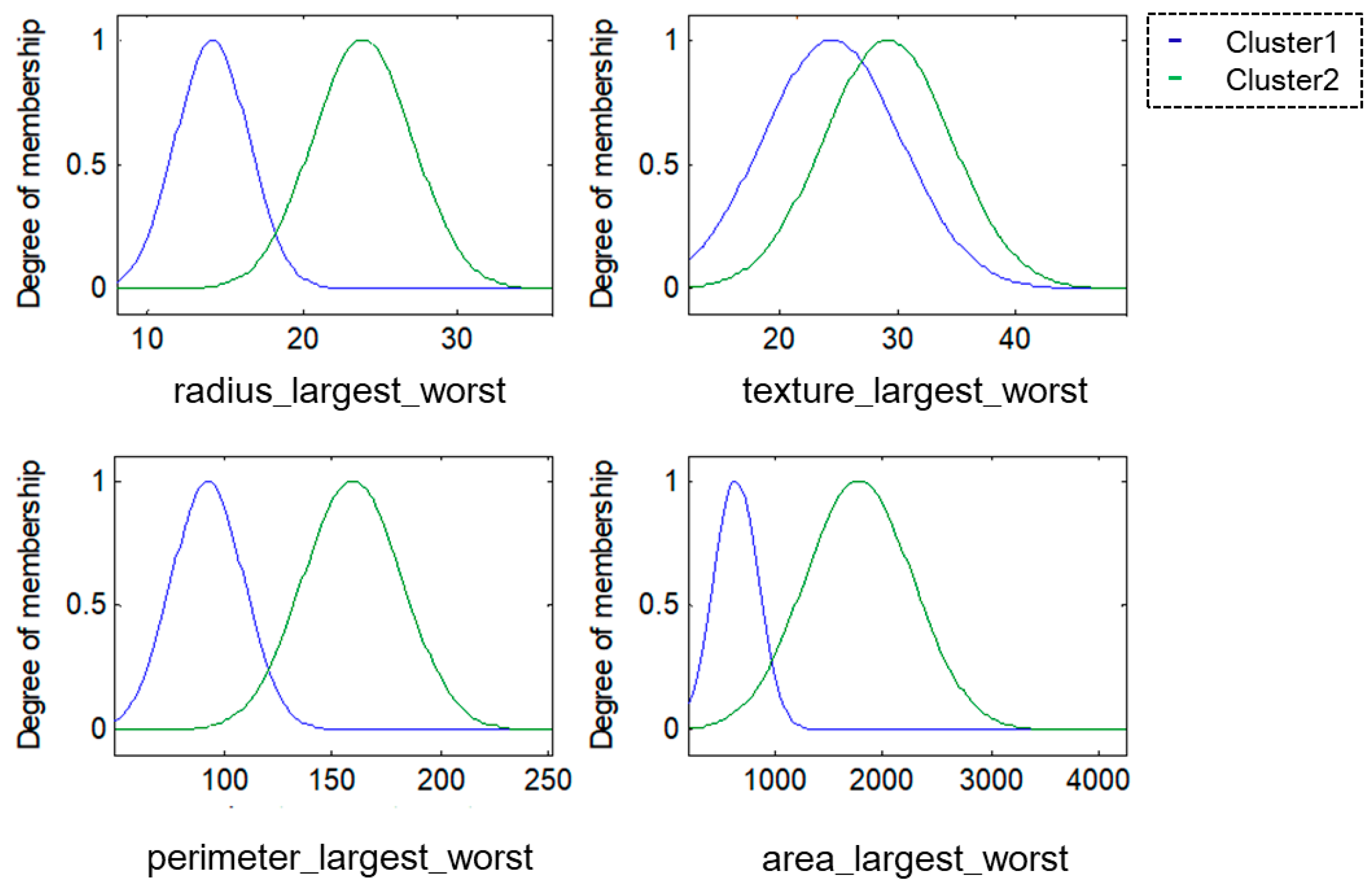
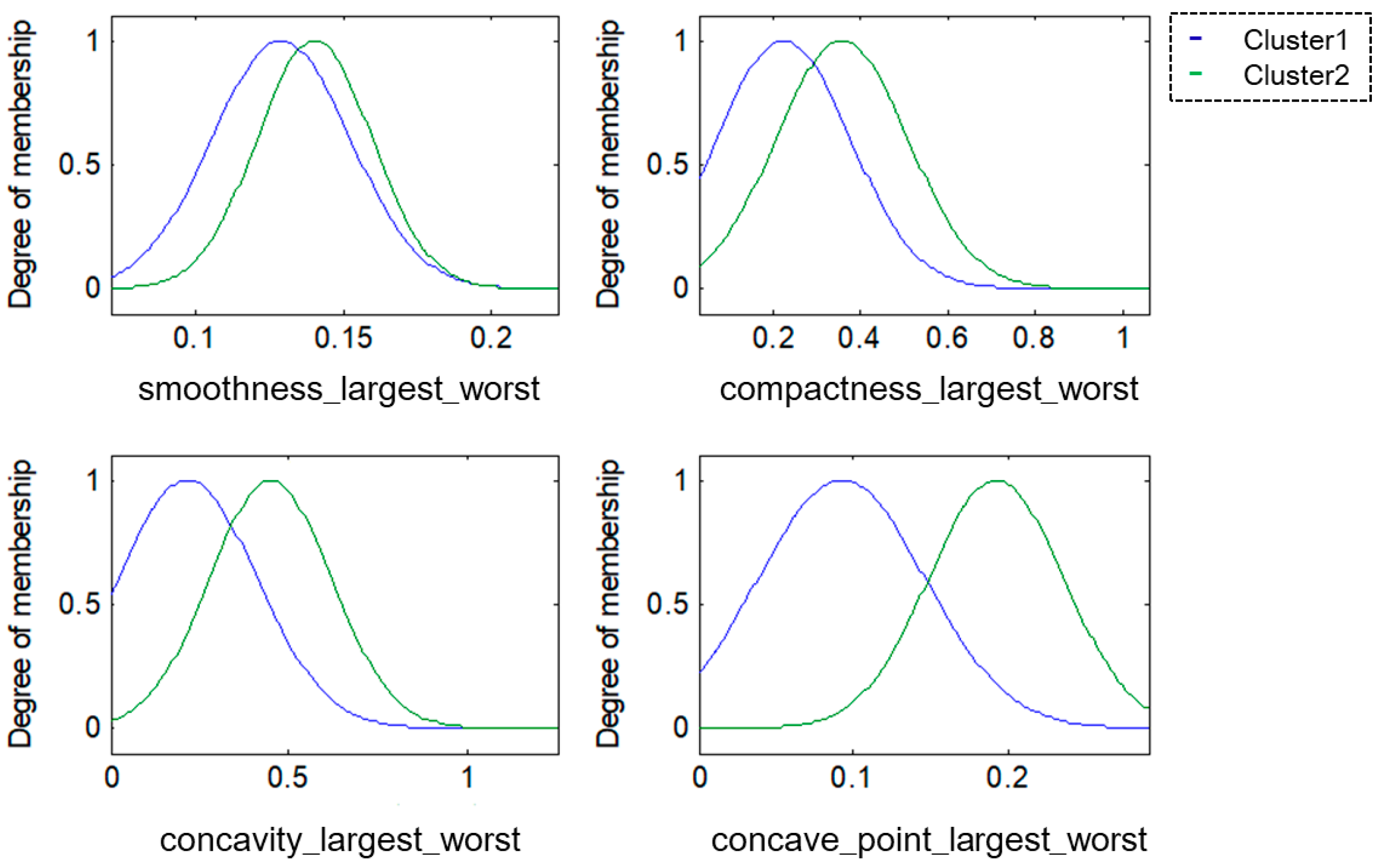
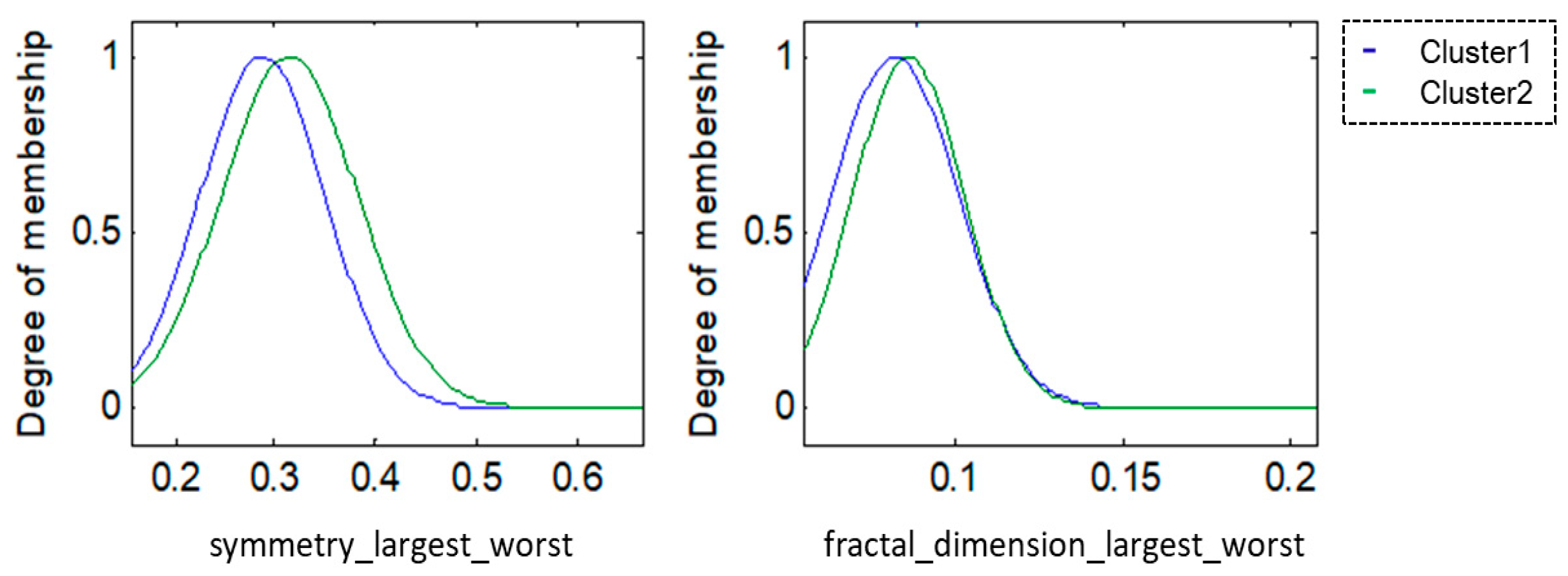
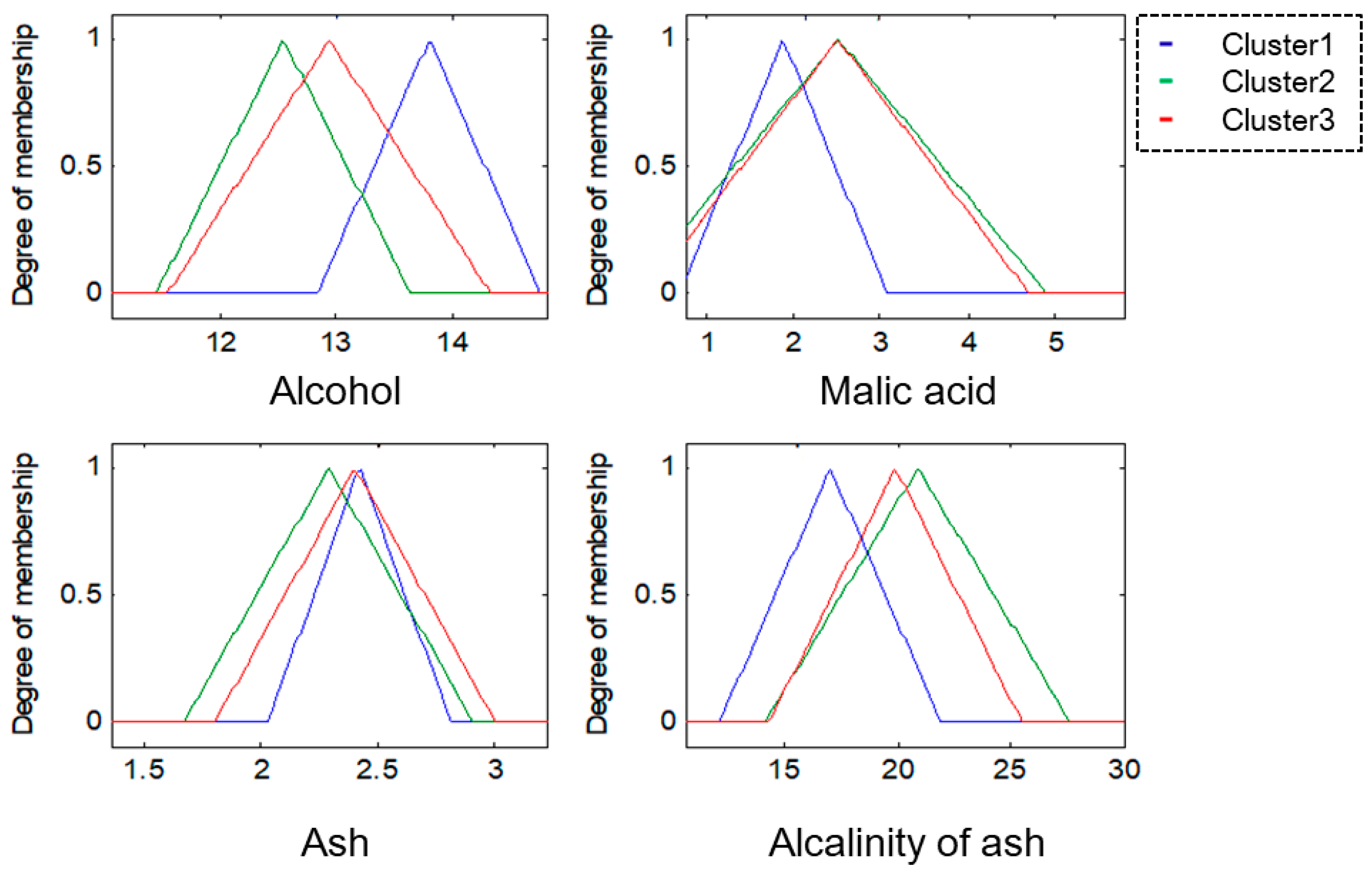
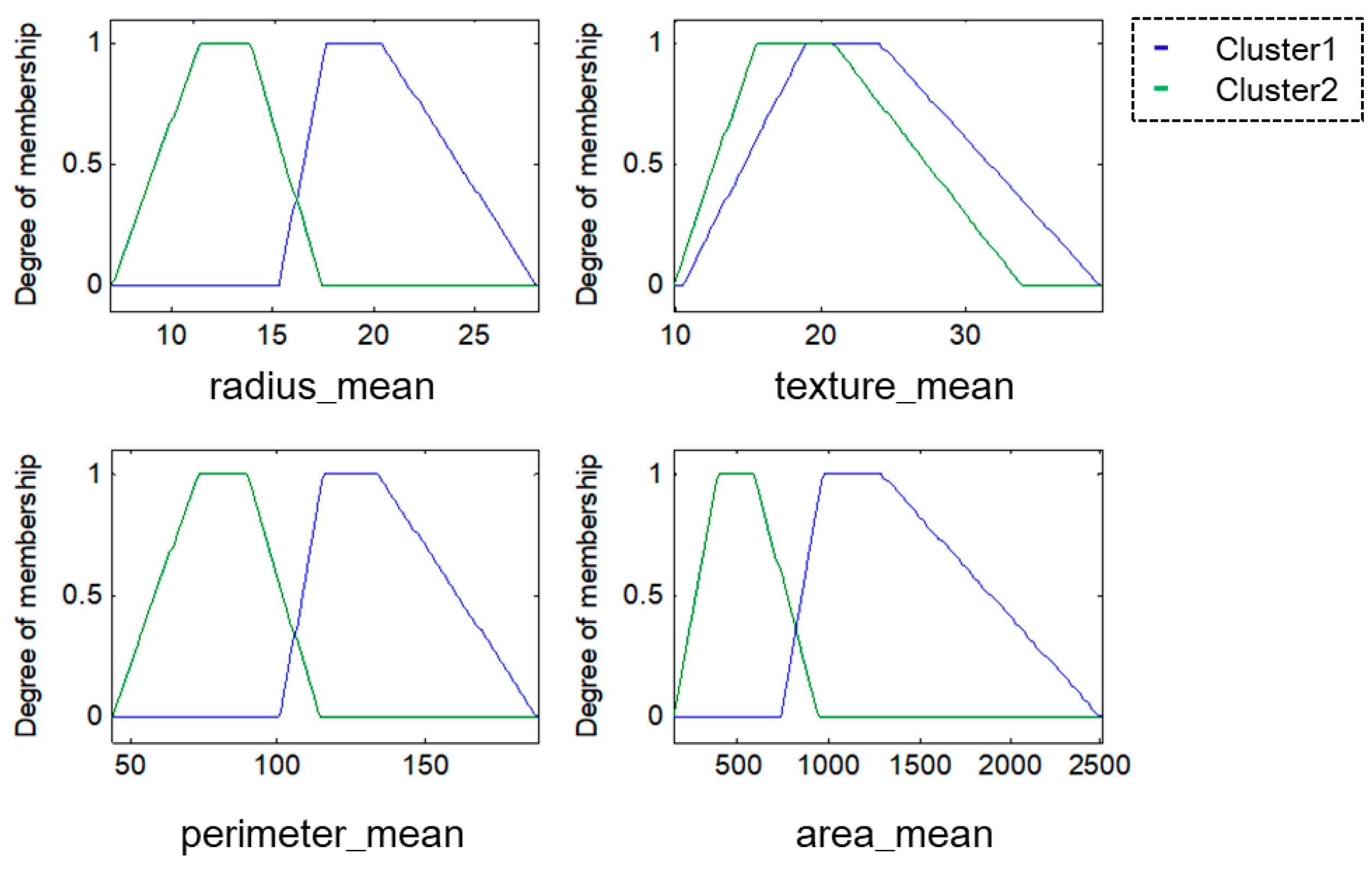
For this research, the methodologies of Competitive Neural Networks and Fuzzy Inference Systems were selected due to the great results they have produced in research carried out by scientists around the world, specifically, in research focused on data clustering and classification problems. On the one hand, unsupervised approaches have limitations under complex datasets; therefore, to solve this problem, we propose the use of fuzzy logic to generate a robust model. Furthermore, one of the limitations of fuzzy logic is how to obtain the parameters (type of inference system, type of input and output MF, the parameters of the MF, how the MFs are granulated, and generate the fuzzy rules). In this sense, the CNN helps to obtain the MF parameters from the data, how these are granulated, and generate fuzzy rules based on the input data.
To model the FIS, we selected the Mamdani and Sugeno systems; these have yielded good results in classification problems as we have previously mentioned. The choice of Triangular, Gaussian, and Trapezoidal MFs is based on the experts in the area according to previous works [
24,
33], where the FIS is modeled with the aforementioned MFs and after several tests, we can obtain the best accuracy results. Finally, it is important to mention that these three types of membership functions are designed with mathematical and metric functions according to their form. The detailed explanation and the obtained results will be presented in
Section 3.





































{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}