4.1. Model Parameter Setting
Determining the optimal number of nodes in the hidden layer entails finding the right balance between fitting capacity, computational efficiency, and feature representation. As specified in Equation (19):
In Equation (19), is the implicit layer’s node count; is the input layer’s node count; is the output layer’s node count; and is an integer from 1 to 10.
The evaluation criteria for BP neural networks are
,
, and
, which are used to compare the performance of the BP model with that of the ACO-BP model, as specified in Equations (20)–(22):
In Equations (20)–(22), denotes the total number of samples; denotes the i sample j’s true value; and signifies the predicted value of the model for the same sample i. The smaller the value of , , and , the more reasonable the corresponding hidden layer’s node count.
Based on Equation (9), the range of the hidden layer’s node count in the BP neural network is set between 3 and 12. Using MATLAB to increase or decrease the number of hidden layer nodes, it is determined that the hidden layer’s node count is 8, and the corresponding mean square error is the smallest, as shown in
Table 5. Therefore, the optimal hidden layer’s node count for the BP neural network is 8. The remaining parameters are determined according to the actual learning rate and stability, and the learning rate is set to 0.01, the number of training times is 1000, and the minimum error of the training target is 10
−7.
The parameter setting of the ant colony optimization (ACO) algorithm is mainly considered to determine the accuracy of the algorithm and the computing rate. After repeated validation experiments, the pheromone volatility coefficient is , the number of ants is 10, the momentum factor is 0.1, the learning rate is 0.01, the number of iterations is 1000, the transfer probability constant is 0.2, the total amount of pheromone release is 1, the weighting threshold takes the range of [–3, 3], and the maximum number of evolutionary generations is 50.
The fitness function used for evaluating the performance of the training and test sets as a whole is the
, which is represented by the following equation:
In Equation (23), is the training set sample and is the test set sample.
The evolutionary convergence curve of the ant colony algorithm is shown in
Figure 7. It can be observed that the convergence curve has a steep slope, indicating that the ant colony algorithm tends to stabilize at generation 29. This suggests a fast convergence rate and minimal fluctuations. The algorithm gradually stabilizes near a good solution within a smaller number of iterations, illustrating its fast convergence speed. The final convergence point of the convergence curve is (29, 0.083), which corresponds to 29 evolutionary generations. The lower
value indicates a better solution, suggesting that the algorithm has found a higher-quality optimal solution [
38]. This validates the reasonableness of the selected parameters, which can be used as initial values for the algorithm’s parameters.
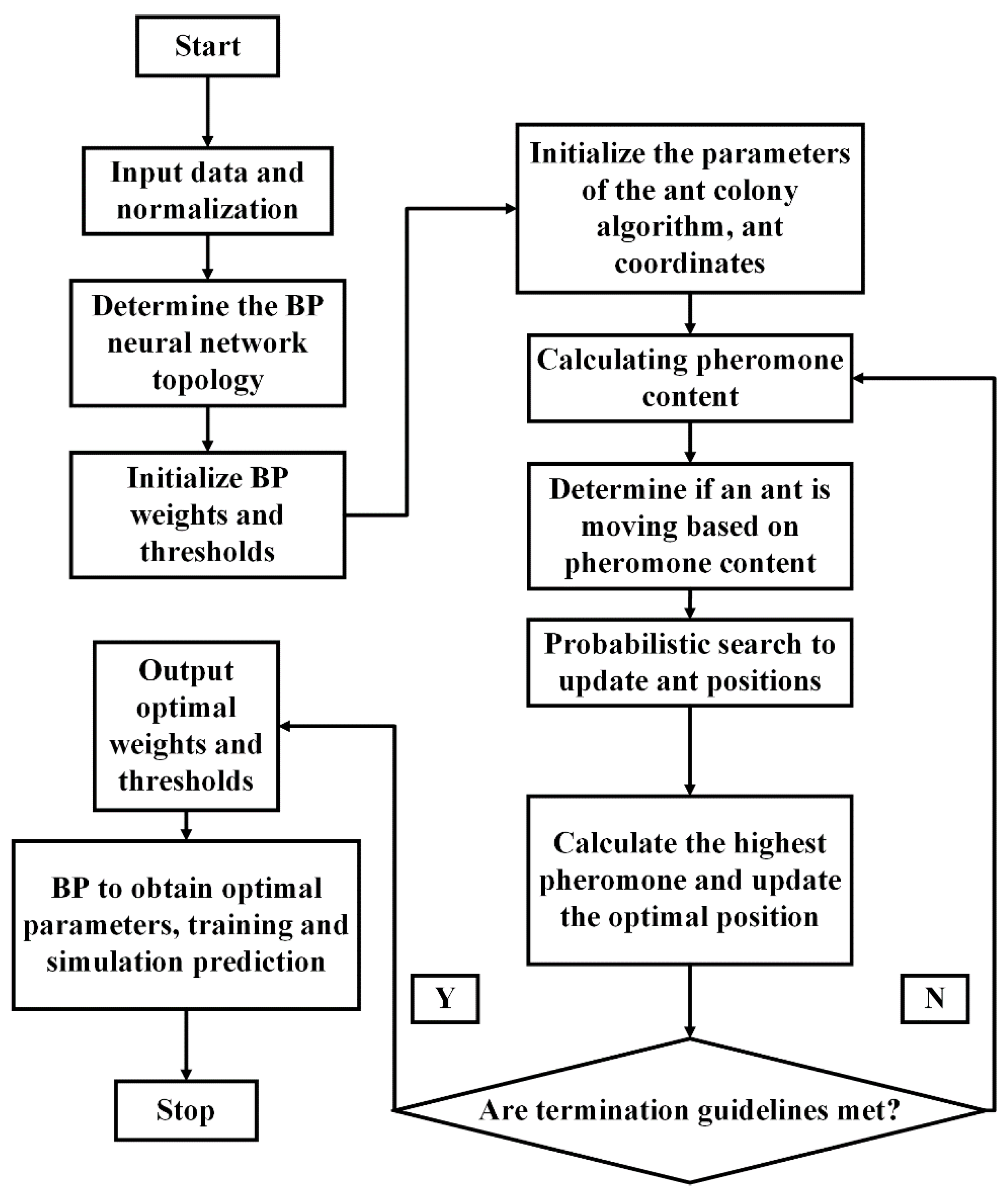
4.2. ACO-BP-Based Driving Style Model Identification and Result Analysis
The US-101 freeway vehicle data in the NGSIM dataset was selected and screened to identify 301 free-lane-changing vehicles that met the requirements.
Table 6 presents the specific sample data.
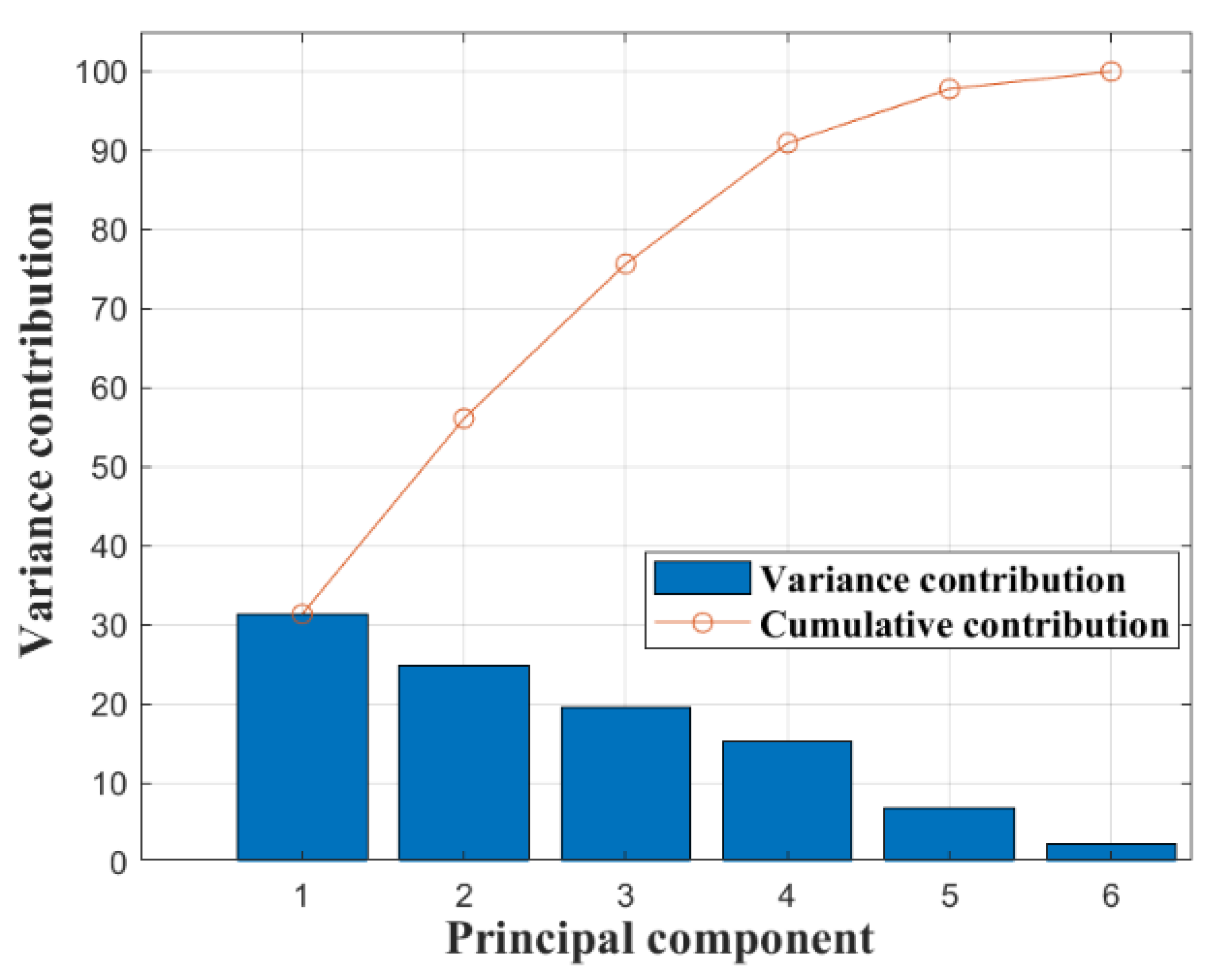
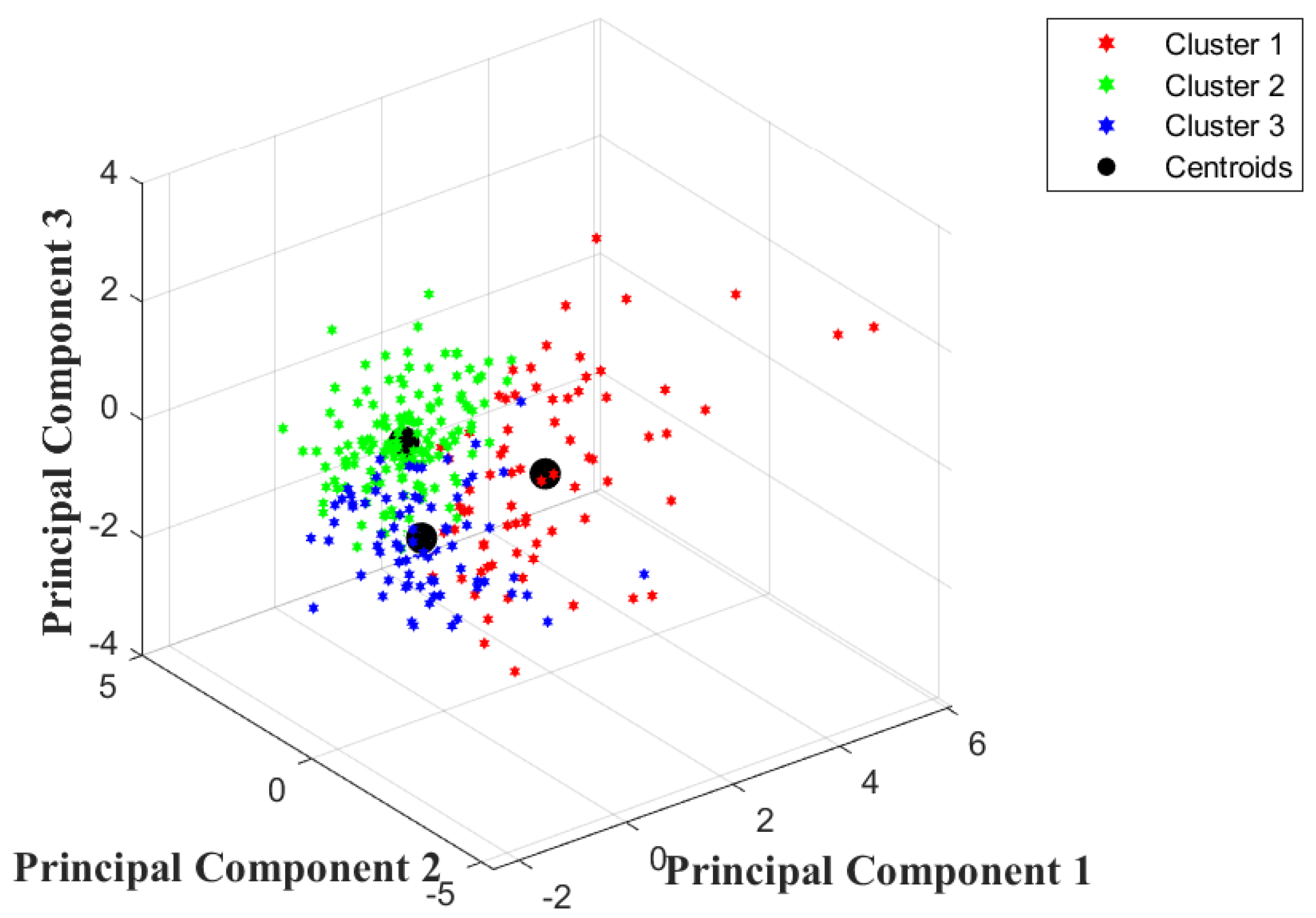
After the sample data were analyzed by PCA downscaling and K-means clustering analysis, the inputs of the driving style model were the top 4 principal component scores with a cumulative variance contribution rate greater than 85%, and the clustering result dataset of the K-means clustering analysis was the output of the model. In order to ensure that the neural network can fully learn the features and patterns of the data, 70% of the data is classified as the training data of the neural network, and the remaining 30% is classified as the test data of the neural network. To ensure the validity of the test data and enhance the accuracy of the model’s recognition, the selection of data samples was determined based on the outcomes of the K-means clustering analysis. Specifically, the sample set is composed of 25% radical data, 49% ordinary data, and 26% conservative data.
MATLAB is used to simulate and analyze the ACO-BP driving style recognition model, and the errors and accuracies of the simulated model are shown in
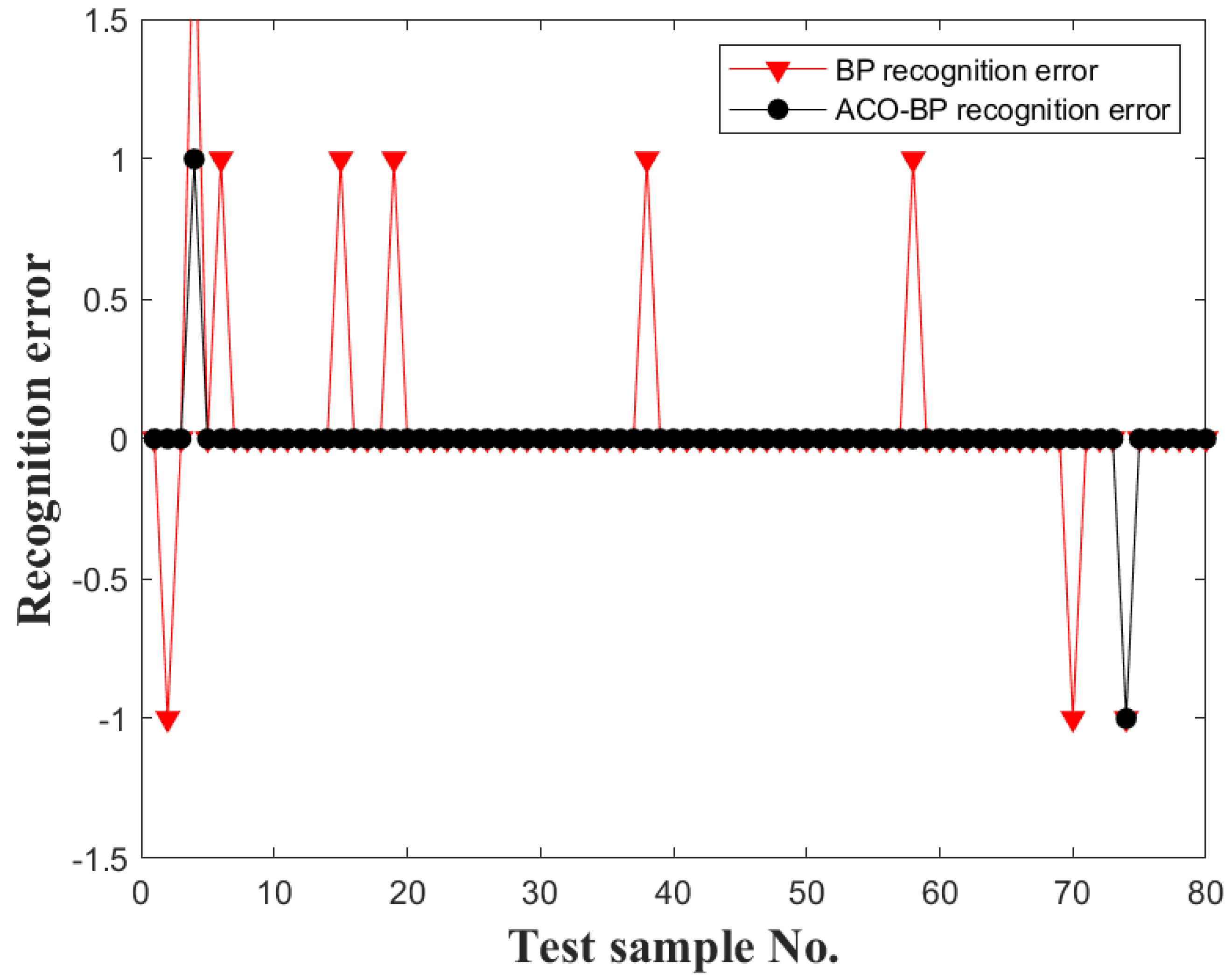
Table 7. The ACO-BP model achieves a recognition accuracy of 96.7%, showing a significant improvement of 6.7% compared to the BP model’s recognition accuracy of 90%. The errors of the ACO-BP model are smaller than those of the BP model, and the accuracy of recognition surpasses that of the BP model. The simulation results comparing the recognition errors of the BP model and the ACO-BP model are shown in
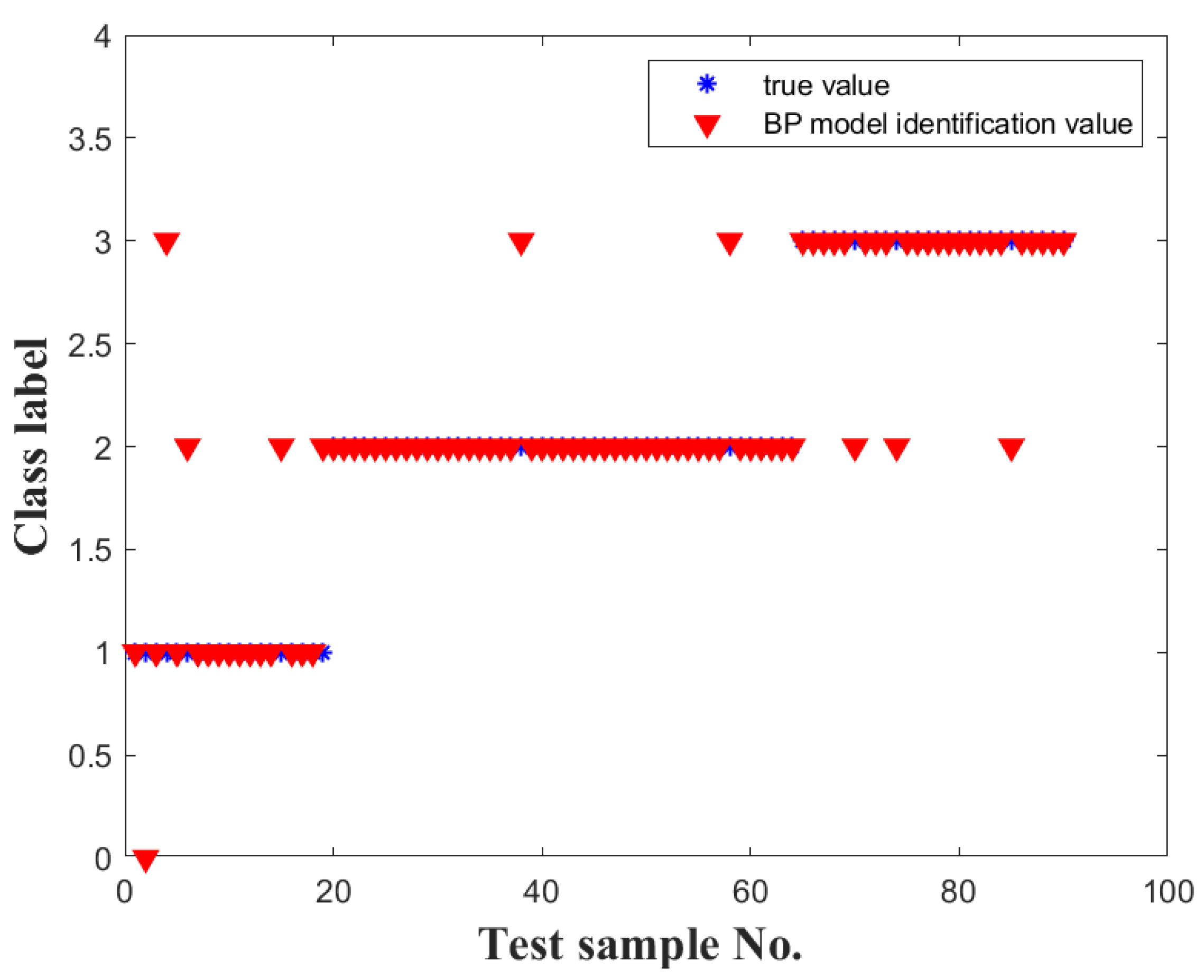
Figure 8. It is evident that the optimized model has fewer error points, resulting in smoother graphs. The error values of all points tend to be closer to 0.
The ACO-BP driving style recognition model has a clear advantage in terms of the overall error of the two models, with higher recognition accuracy. However, according to the relevant research, due to the more uncertain and dangerous driving behavior of aggressive-style drivers, they have significantly higher accident rates than the other two driving styles. Therefore, at the same time, the ACO-BP model is required to recognize the effect of each driving style and cannot have a large error in order to prevent the overfitting problem.
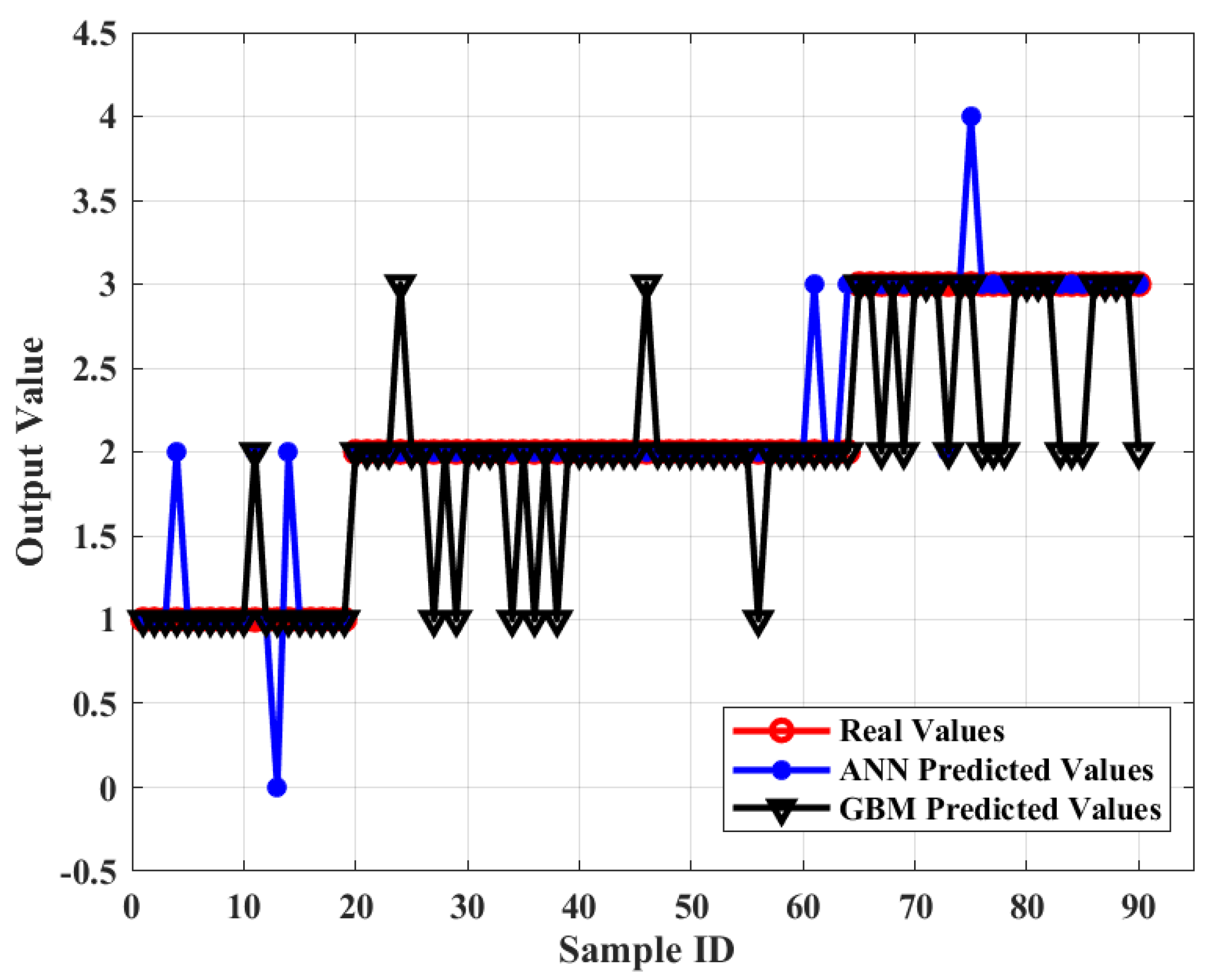
To further investigate the model’s effectiveness in recognizing driving styles in a more detailed manner, individual simulations are conducted to examine the impacts of identifying the three driving styles. The simulation results are shown in
Figure 9 and
Figure 10, which clearly show that the ACO-BP model has only 1, 0, and 2 samples producing recognition errors for each of the three driving styles of aggressive, ordinary, and conservative, respectively, while the BP model has 4, 2, and 3 samples producing recognition errors for each of the three driving styles, respectively. This indicates that, more than just the overall error, the ACO-BP model has better recognition accuracy than the BP model. When targeting different types of driving styles, the ACO-BP model is able to perform good recognition, and the recognition accuracy does not vary greatly due to the change in driving styles.
The specific recognition accuracy results for the 3 driving styles are shown in
Table 8, which shows that for different driving styles, the recognition accuracy of the ACO-BP model is higher than that of the BP model. For the three driving styles of aggressive, normal, and conservative, the recognition accuracies are much improved, respectively: 13.7%, 4.4%, and 4.3%. It further proves the recognition accuracy and recognition value reliability of the ACO-BP model, and the recognition effect has obvious advantages for such an accident-prone driving population as the aggressive type.
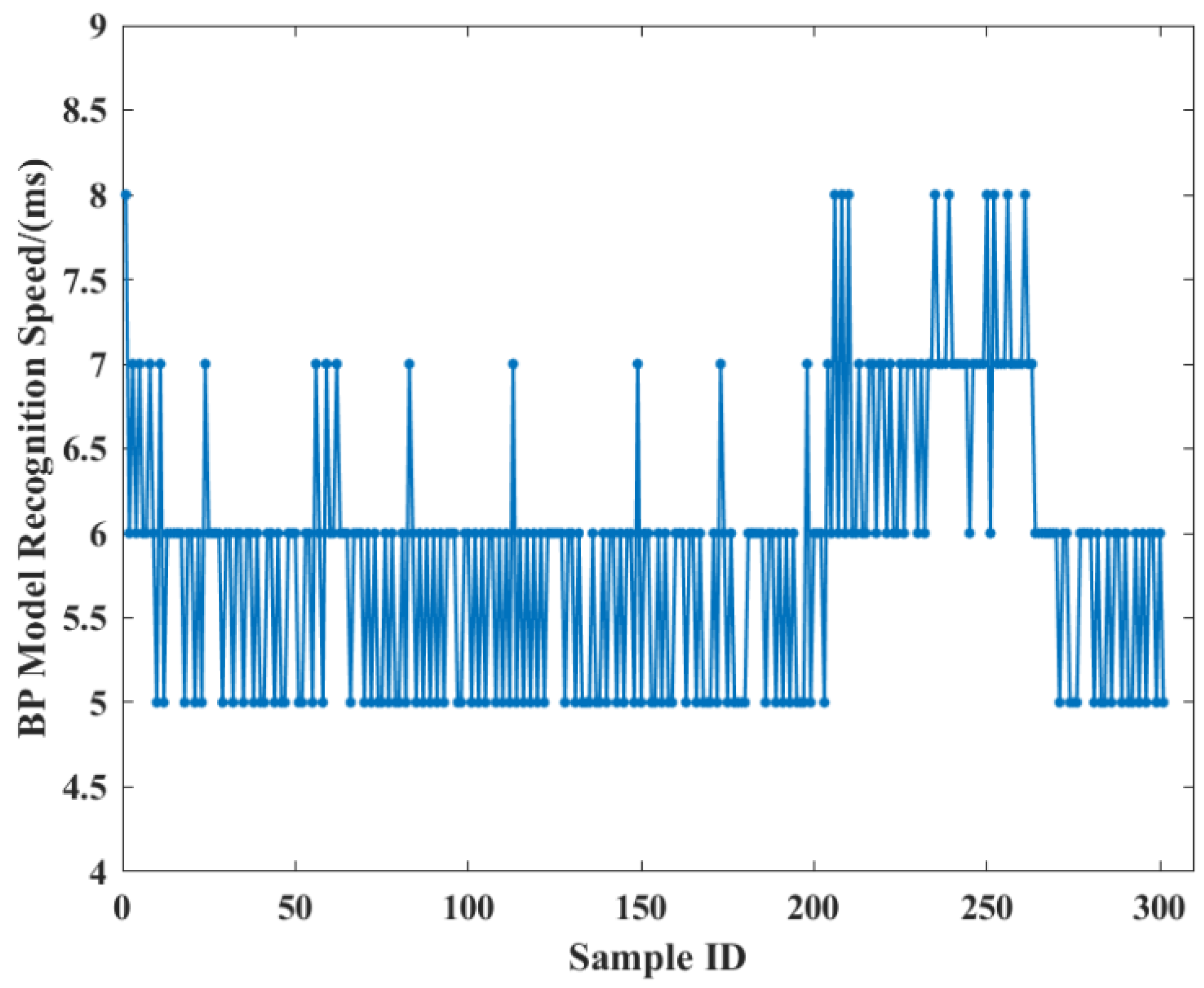
The driving style recognition speeds of the BP driving style recognition model and the ACO-BP driving style recognition model are shown in
Figure 11 and
Figure 12, respectively. The slowest recognition speed for the BP driving style recognition model is 8 ms, and the fastest recognition speed is 5 ms. For the ACO-BP driving style recognition model, the slowest recognition speed is 7 ms, and the fastest recognition speed is 5 ms, with a relatively uniform distribution within the range. The results indicate that, although ACO-BP is a hybrid model, it has not been significantly affected, as the recognition speed remains fast. Compared to the BP model, the recognition speed of the ACO-BP model is more even, and the speed range is more compact. Therefore, the ACO-BP driving style recognition model demonstrates better real-time performance compared to the BP driving style recognition model, enabling better adaptation to the actual road conditions of autonomous vehicles. It allows for timely recognition of driving styles, the avoidance of hazardous driving behaviors, and the improvement of driving safety.

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}