
Training-Free Acoustic-Based Hand Gesture Tracking on Smart Speakers


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
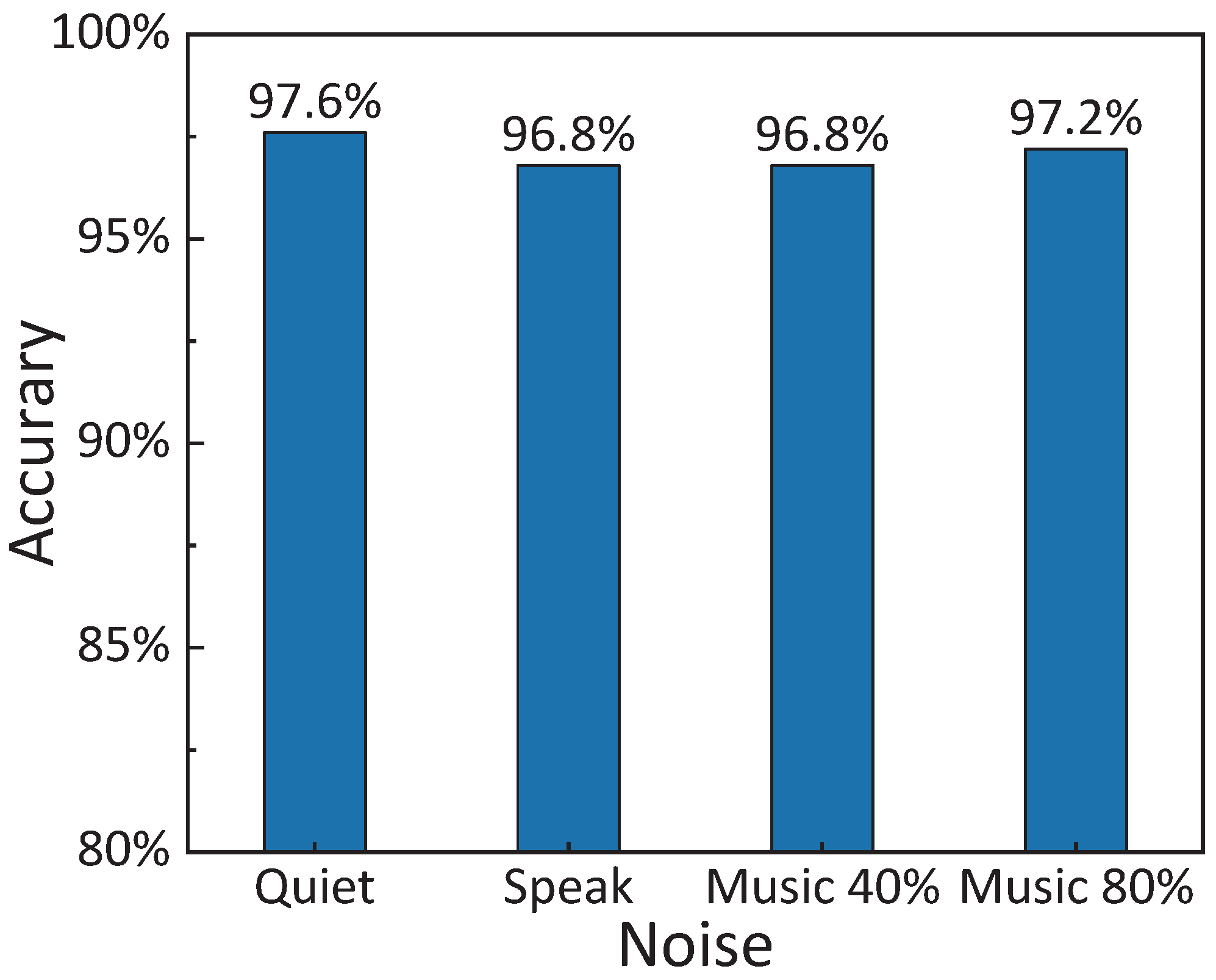{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
- TaGesture employs an inaudible acoustic signal to realize device-free and training-free hand gesture recognition, with a commercial speaker and microphone array. We believe TaGesture can be widely deployed on smart devices in the real world.
- We propose a novel acoustic hand-tracking-smoothing algorithm with IMM Kalman Filter, which can eliminate localization angle ambiguity of hand tracking. Furthermore, we propose a classification algorithm to realize acoustic-based hand gesture recognition without training.
- We conduct comprehensive experiments to evaluate the performance of TaGesture. Results show that the total accuracy of acoustic-based hand gesture recognition is 97.5%, and the furthest sensing distance is 3 m.
2. Preliminaries
3. Materials and Methods
3.1. Interference Cancellation
3.2. Signal Enhancement
3.3. Position Estimation
3.4. Hand Tracking
3.4.1. Tracking Model
3.4.2. Input Interaction
3.4.3. Kalman Filter
3.4.4. Model Probability Update
3.4.5. Combination
3.5. Hand Gesture Recognition
- (a)
- We extract the first, middle, and last points from the trajectory. Then, we take the middle point as the vertex of the angle , which can be calculated by the cosine law. If < 90°, the trajectory is draw a circle.
- (b)
- If > 90°, we define the moving displacement along the x and y axis as and , respectively. If , the trajectory is swipe left or swipe right. If , the trajectory is push forward or pull back.
- (c)
- To further distinguish between swipe left and swipe right, if , the trajectory is swipe left. If , the trajectory is swipe right. To further distinguish between push forward or pull back, if , the trajectory is pull back. If , the trajectory is push forward.
4. Results
4.1. Implementation
4.2. Overall Performance
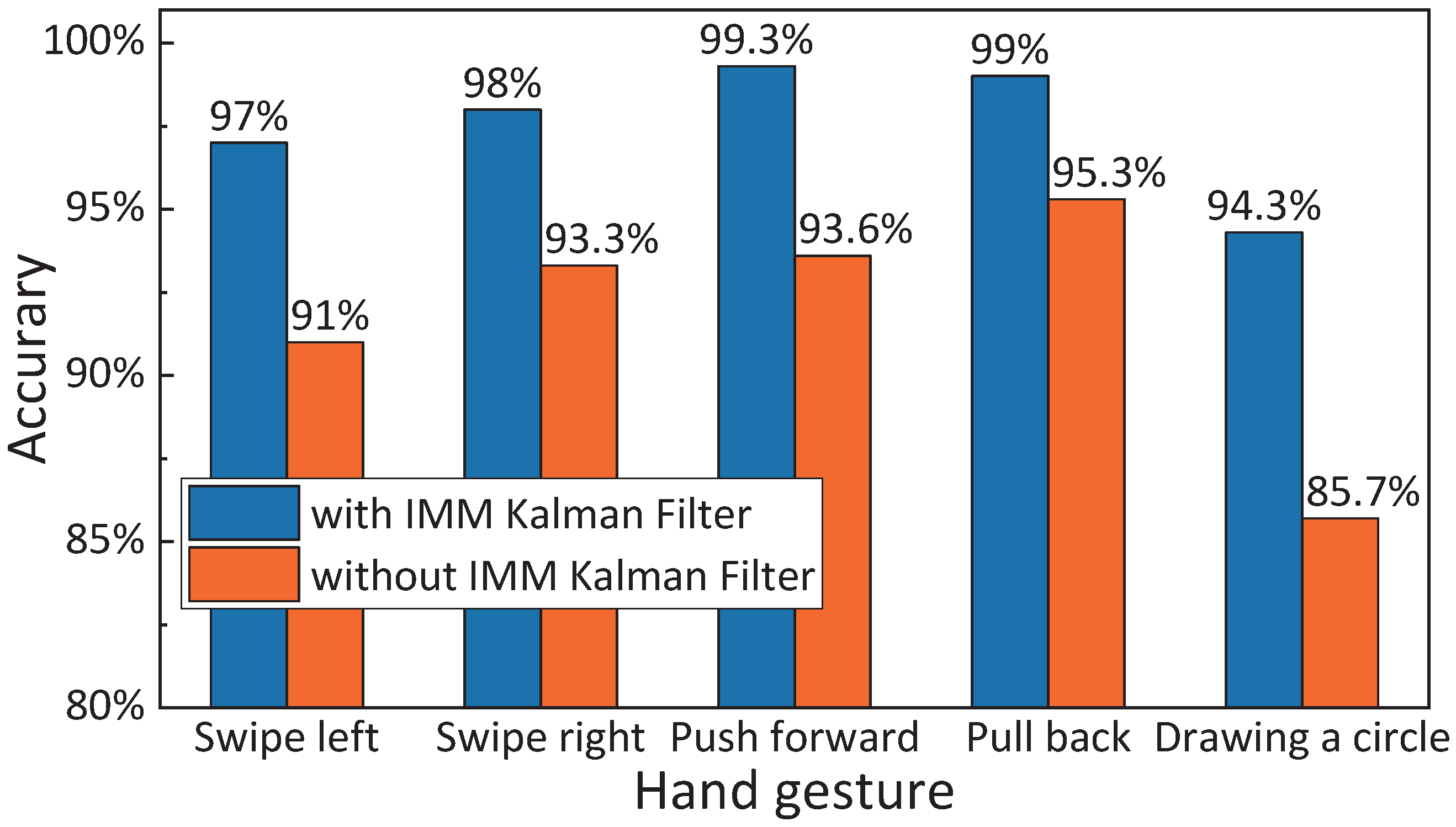
4.3. Evaluation of IMM Kalman Filter
4.4. Impact of Different Distances
4.5. Impact of Ambient Noise
4.6. Impact of User Diversity
4.7. Impact of Different Environments
5. Related Work
5.1. Gesture Recognition Based on Wireless Signal
5.2. Wireless Sensing Based on Acoustic Signal
6. Discussion
6.1. Traditional Tracking Method
6.2. Limitation and Future Work
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Wang, C.; Liu, J.; Chen, Y.; Liu, H.; Xie, L.; Wang, W.; He, B.; Lu, S. Multi-touch in the air: Device-free finger tracking and gesture recognition via cots rfid. In Proceedings of the IEEE INFOCOM 2018—IEEE Conference on Computer Communications, Honolulu, HI, USA, 15–19 April 2018; pp. 1691–1699. [Google Scholar]
- Pan, T.Y.; Tsai, W.L.; Chang, C.Y.; Yeh, C.W.; Hu, M.C. A hierarchical hand gesture recognition framework for sports referee training-based EMG and accelerometer sensors. IEEE Trans. Cybern. 2020, 52, 3172–3183. [Google Scholar] [CrossRef] [PubMed]
- Han, H.; Yoon, S.W. Gyroscope-based continuous human hand gesture recognition for multi-modal wearable input device for human machine interaction. Sensors 2019, 19, 2562. [Google Scholar] [CrossRef] [PubMed]
- Koch, P.; Dreier, M.; Böhme, M.; Maass, M.; Phan, H.; Mertins, A. Inhomogeneously stacked rnn for recognizing hand gestures from magnetometer data. In Proceedings of the 2019 27th European Signal Processing Conference (EUSIPCO), A Coruña, Spain, 2–6 September 2019; pp. 1–5. [Google Scholar]
- León, D.G.; Gröli, J.; Yeduri, S.R.; Rossier, D.; Mosqueron, R.; Pandey, O.J.; Cenkeramaddi, L.R. Video hand gestures recognition using depth camera and lightweight cnn. IEEE Sens. J. 2022, 22, 14610–14619. [Google Scholar] [CrossRef]
- Li, C.; Liu, M.; Cao, Z. WiHF: Enable user identified gesture recognition with WiFi. In Proceedings of the IEEE INFOCOM 2020—IEEE Conference on Computer Communications, Toronto, ON, Canada, 6–9 July 2020; pp. 586–595. [Google Scholar]
- Xie, B.; Xiong, J. Combating interference for long range LoRa sensing. In Proceedings of the 18th Conference on Embedded Networked Sensor Systems, Virtual, 16–19 November 2020; pp. 69–81. [Google Scholar]
- Venkatnarayan, R.H.; Shahzad, M. Gesture recognition using ambient light. Proc. ACM Interact. Mob. Wearable Ubiquitous Technol. 2018, 2, 1–28. [Google Scholar] [CrossRef]
- Ahmed, S.; Kim, W.; Park, J.; Cho, S.H. Radar-Based Air-Writing Gesture Recognition Using a Novel Multistream CNN Approach. IEEE Internet Things J. 2022, 9, 23869–23880. [Google Scholar] [CrossRef]
- Ling, K.; Dai, H.; Liu, Y.; Liu, A.X.; Wang, W.; Gu, Q. Ultragesture: Fine-grained gesture sensing and recognition. IEEE Trans. Mob. Comput. 2020, 21, 2620–2636. [Google Scholar] [CrossRef]
- Li, D.; Liu, J.; Lee, S.I.; Xiong, J. FM-track: Pushing the limits of contactless multi-target tracking using acoustic signals. In Proceedings of the 18th Conference on Embedded Networked Sensor Systems, Virtual, 16–19 November 2020; pp. 150–163. [Google Scholar]
- Møller, H.; Pedersen, C.S. Hearing at low and infrasonic frequencies. Noise Health 2004, 6, 37–57. [Google Scholar] [PubMed]
- Cai, C.; Zheng, R.; Luo, J. Ubiquitous acoustic sensing on commodity iot devices: A survey. IEEE Commun. Surv. Tutor. 2022, 24, 432–454. [Google Scholar] [CrossRef]
- Li, D.; Liu, J.; Lee, S.I.; Xiong, J. Room-Scale Hand Gesture Recognition Using Smart Speakers. In Proceedings of the 20th ACM Conference on Embedded Networked Sensor Systems, Boston, MA, USA, 6–9 November 2023; pp. 462–475. [Google Scholar]
- Gao, R.; Li, W.; Xie, Y.; Yi, E.; Wang, L.; Wu, D.; Zhang, D. Towards robust gesture recognition by characterizing the sensing quality of WiFi signals. Proc. ACM Interact. Mob. Wearable Ubiquitous Technol. 2022, 6, 1–26. [Google Scholar] [CrossRef]
- Li, B.; Yang, J.; Yang, Y.; Li, C.; Zhang, Y. Sign language/gesture recognition based on cumulative distribution density features using UWB radar. IEEE Trans. Instrum. Meas. 2021, 70, 1–13. [Google Scholar] [CrossRef]
- Webber, J.; Mehbodniya, A. Recognition of Hand Gestures using Visible Light and a Probabilistic-based Neural Network. In Proceedings of the 2022 4th IEEE Middle East and North Africa COMMunications Conference (MENACOMM), Amman, Jordan, 6–8 December 2022; pp. 54–58. [Google Scholar]
- Yin, Y.; Yu, X.; Gao, S.; Yang, X.; Chen, P.; Niu, Q. MineSOS: Long-Range LoRa-Based Distress Gesture Sensing for Coal Mine Rescue. In Proceedings of the International Conference on Wireless Algorithms, Systems, and Applications, Dalian, China, 24–26 November 2022; pp. 105–116. [Google Scholar]
- Merenda, M.; Cimino, G.; Carotenuto, R.; Della Corte, F.G.; Iero, D. Edge machine learning techniques applied to rfid for device-free hand gesture recognition. IEEE J. Radio Freq. Identif. 2022, 6, 564–572. [Google Scholar] [CrossRef]
- Lian, J.; Lou, J.; Chen, L.; Yuan, X. Echospot: Spotting your locations via acoustic sensing. Proc. ACM Interact. Mob. Wearable Ubiquitous Technol. 2021, 5, 113. [Google Scholar] [CrossRef]
- Wang, Y.; Shen, J.; Zheng, Y. Push the limit of acoustic gesture recognition. IEEE Trans. Mob. Comput. 2020, 21, 1798–1811. [Google Scholar] [CrossRef]
- Wang, P.; Jiang, R.; Guo, Z.; Liu, C. Afitness: Fitness Monitoring on Smart Devices via Acoustic Motion Images. ACM Trans. Sens. Netw. 2023. [Google Scholar] [CrossRef]
- Lian, J.; Du, C.; Lou, J.; Chen, L.; Yuan, X. EchoSensor: Fine-Grained Ultrasonic Sensing for Smart Home Intrusion Detection. ACM Trans. Sens. Netw. 2023, 20, 1–24. [Google Scholar] [CrossRef]
- Lian, J.; Yuan, X.; Li, M.; Tzeng, N.F. Fall detection via inaudible acoustic sensing. Proc. ACM Interact. Mob. Wearable Ubiquitous Technol. 2021, 5, 114. [Google Scholar] [CrossRef]
- Fu, Y.; Wang, S.; Zhong, L.; Chen, L.; Ren, J.; Zhang, Y. SVoice: Enabling Voice Communication in Silence via Acoustic Sensing on Commodity Devices. In Proceedings of the 20th ACM Conference on Embedded Networked Sensor Systems, Boston, MA, USA, 6–9 November 2022; pp. 622–636. [Google Scholar]
- Wu, Y.; Li, F.; Xie, Y.; Wang, Y.; Yang, Z. SymListener: Detecting Respiratory Symptoms via Acoustic Sensing in Driving Environments. ACM Trans. Sens. Netw. 2023, 19, 1–21. [Google Scholar] [CrossRef]












Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xu, X.; Zhang, X.; Bao, Z.; Yu, X.; Yin, Y.; Yang, X.; Niu, Q. Training-Free Acoustic-Based Hand Gesture Tracking on Smart Speakers. Appl. Sci. 2023, 13, 11954. https://doi.org/10.3390/app132111954
Xu X, Zhang X, Bao Z, Yu X, Yin Y, Yang X, Niu Q. Training-Free Acoustic-Based Hand Gesture Tracking on Smart Speakers. Applied Sciences. 2023; 13(21):11954. https://doi.org/10.3390/app132111954
Chicago/Turabian StyleXu, Xiao, Xuehan Zhang, Zhongxu Bao, Xiaojie Yu, Yuqing Yin, Xu Yang, and Qiang Niu. 2023. "Training-Free Acoustic-Based Hand Gesture Tracking on Smart Speakers" Applied Sciences 13, no. 21: 11954. https://doi.org/10.3390/app132111954