
Datacentric Similarity Matching of Emergent Stigmergic Clustering to Fractional Factorial Vectoring: A Case for Leaner-and-Greener Wastewater Recycling

Abstract
:1. Introduction
2. Materials and Methods
2.1. Orthogonal Screening for Comparing Non-Linear Effects between Two Filtration Processes
2.2. The Naïve OA Sampler/Databionic-Swarm Classifier Profiler
2.3. The UF-/NF-Membrane Process Treatment Dataset Description
2.4. The Methodological Outline
- (1)
- Determine the relevant UF-/NF-membrane process characteristics that represent the water recovery performance—adaptable to the specific application.
- (2)
- Select a group of UF-/NF-membrane process controlling factors.
- (3)
- Determine the minimum group of factor settings, which span the operational requirements, avoiding information loss due to ignored curvature effects.
- (4)
- Program fast-track trials by deploying a suitable one-shot OA sampler that potentially detects non-linear tendencies.
- (5)
- Conduct the prescribed Taguchi-type OA recipes (step 4) and construct the multi-characteristic mini-dataset.
- (6)
- (7)
- Inspect the characteristic data vectors for correlations and reduce accordingly the number of responses by eliminating correlated characteristics.
- (8)
- Pre-screen the number of candidate clusters by evaluating available distance measures, employing visual and numerical tools: (1) the Shepard plot and (2) the Kruskal stress estimations.
- (9)
- Obtain the cluster dendrogram and the Databionic-swarm-solver-labelled clusters for the reduced-response OA dataset.
- (10)
- Evaluate the cluster similarity (partitioning effectiveness) between the bionic cluster-identification memberships and the pre-labelled OA factorial setting vectors by applying the Davies–Bouldin Index.
- (11)
- Determine the hierarchy of the potent controlling effects between the processes.
2.5. The Computational Aids
3. Results
3.1. Visual Data Screening of The Multi-Characteristic Permeate Quality and Water Recovery Efficiency
3.1.1. The Ultrafiltration Process
3.1.2. The Nanofiltration Process
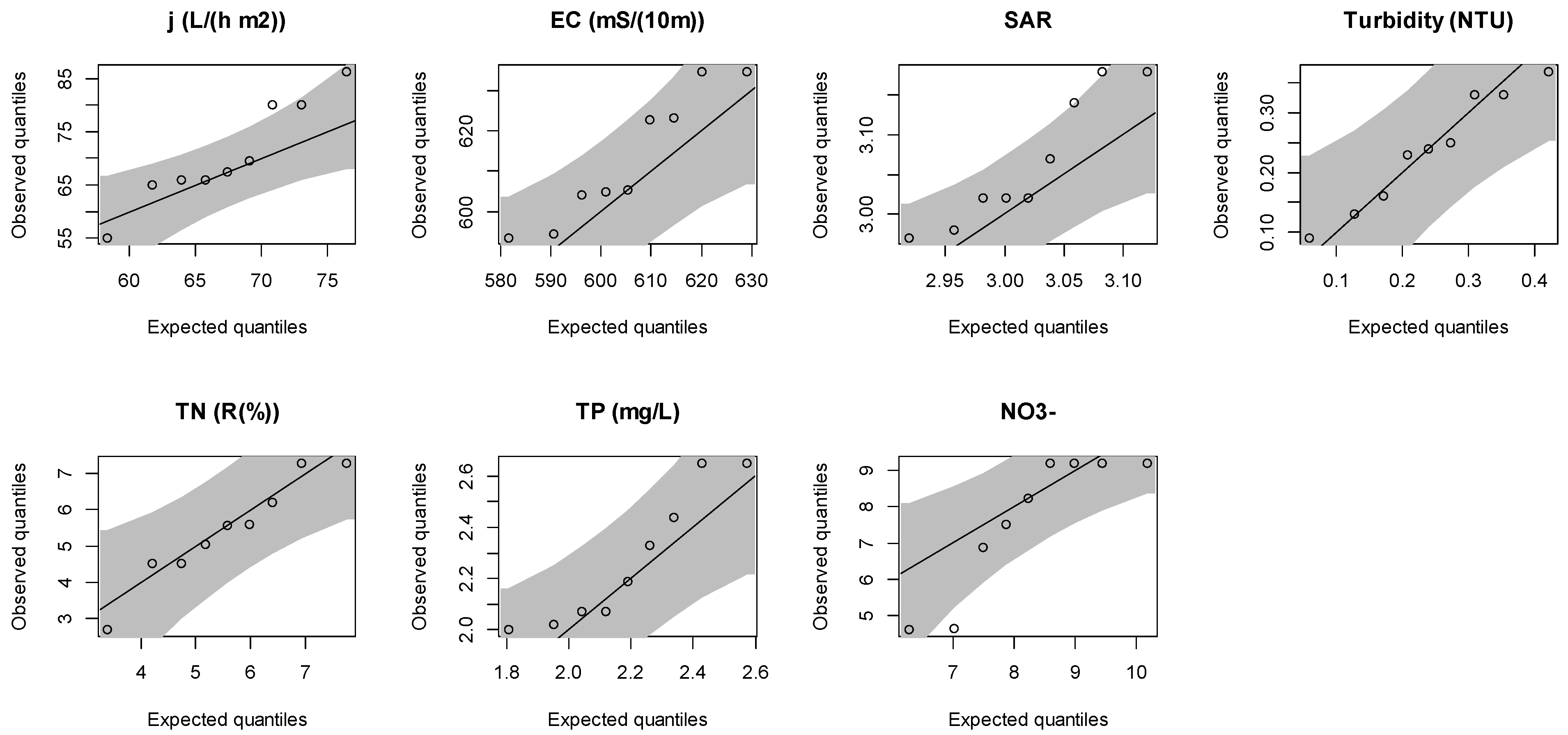
3.2. Nonparametric Characteristic Correlation Estimation and Characteristic Selection on Efficiency
3.2.1. The Ultrafiltration Process
3.2.2. The Nanofiltration Process
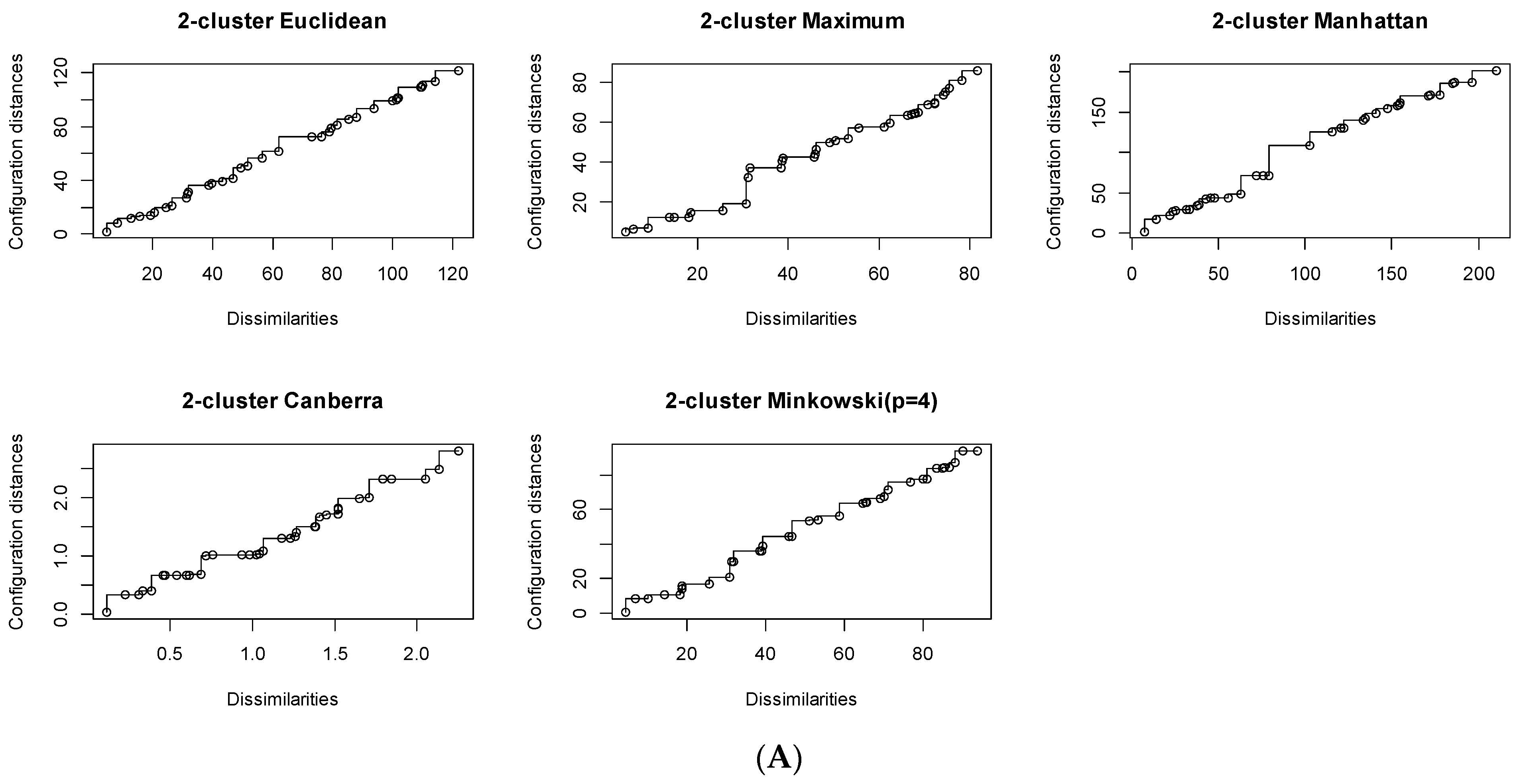
3.3. Graphical Pre-Screening of the Candidate Distance Measures
3.3.1. The Ultrafiltration Process Multi-Characteristic Distance Measure Selection
3.3.2. The Nanofiltration Process Characteristics Multi-Characteristic Distance Measure Selection
3.4. Ultrametric Self-Organizing Clustering and Validating Metric Comparison to Fractional Factorial Setting Vectors
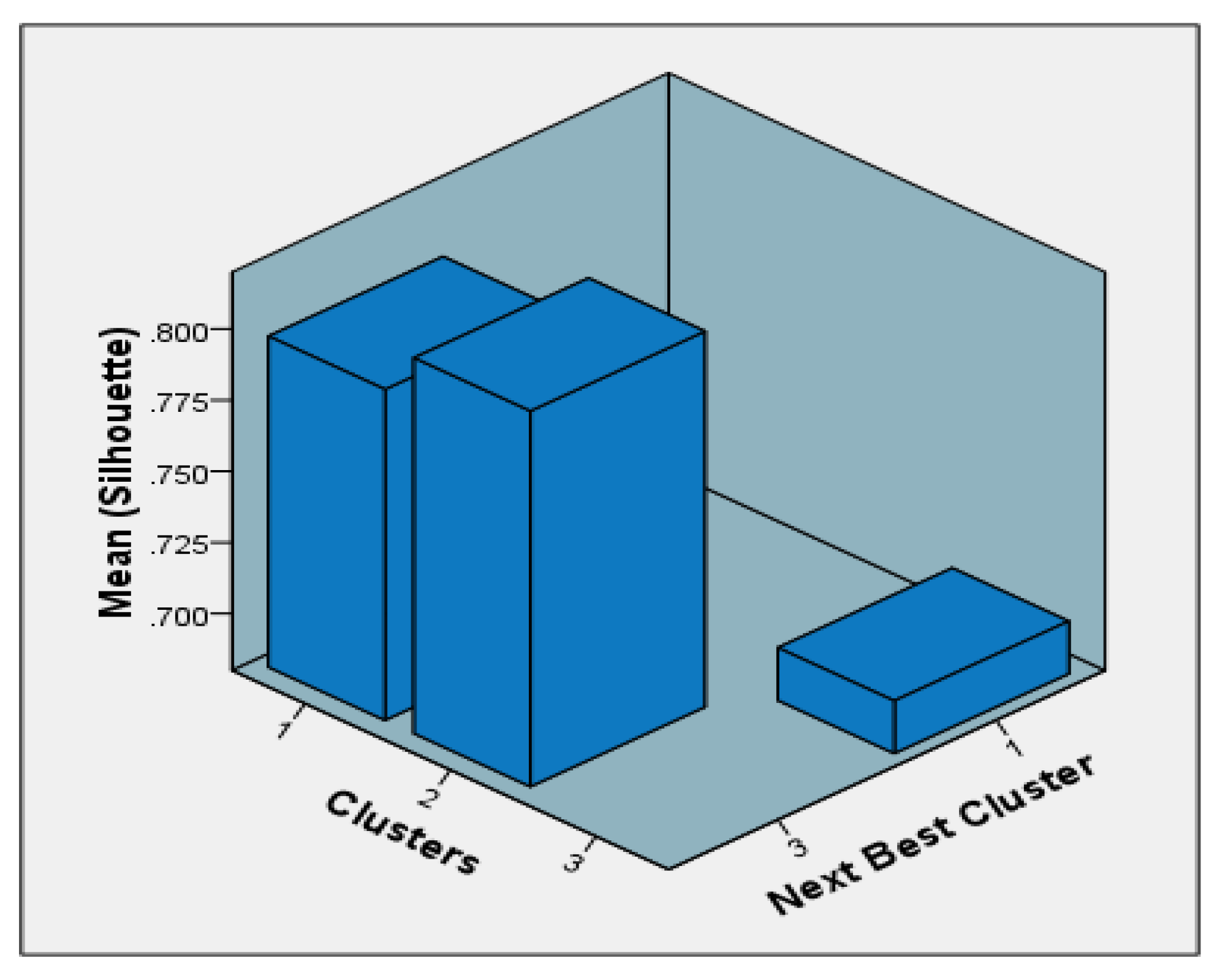
3.4.1. The Ultrafiltration Process Parameter-Free-Projection Self-Organized Clustering
3.4.2. The Nanofiltration Process Parameter-Free Projection Self-Organized Clustering
- (1)
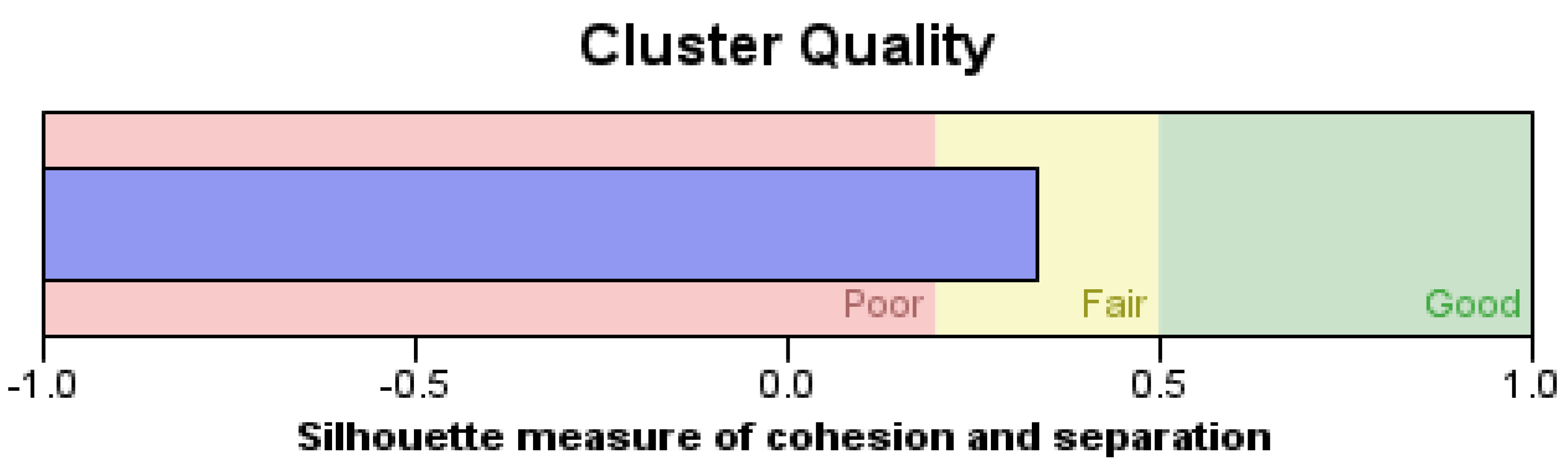
- The self-validation of the tri-characteristic clustering was in agreement regardless of the cluster size; the Davies–Bouldin index was confined to values between 0.34 and 0.41 for all four estimations.
- (2)
- The Davies–Bouldin index estimations, within a preset cluster size, was in agreement regardless of the selection of the two centrotypes. This might imply a more reliable “internal standard” with respect to the ultrafiltration process outcomes.
- (3)
- It was factor A that mimicked the behavior of the self-validator estimations, thus delivering the maximum information by ensuring that the similarity between the factor-A vectoring and the inherent internal clustering pattern were almost indistinguishable; the membership identification entries from the Databionic classifier and the fractional factorial setting vector for factor A matched. Particularly, for the case in which the cluster size was set at k = 3, the centroid- and medoid-based Davies–Bouldin index estimates were also identical; their computed values were 0.41 and 0.40, respectively. From this behavior, it was inferred that factor A should be assigned a simpler linear model.
- (4)
- The remaining three factors may be deemed weak since their Davies–Bouldin index magnitudes were substantially larger.
4. Discussion
4.1. Datacentric Evaluation by Re-Profiling Comparisons for the Ultrafiltration Process Characteristics
4.2. Datacentric Evaluation by Re-Profiling Comparisons for the Nanofiltration Process Characteristics
5. Conclusions
Funding
Data Availability Statement
Conflicts of Interest
References
- United Nations. Sustainable Development Goals, Goal 6: Clean Water and Sanitation. Available online: https://www.undp.org/sustainable-development-goals/clean-water-and-sanitation (accessed on 21 September 2023).
- Mekonnen, M.M.; Hoekstra, A.Y. Four billion people facing severe water scarcity. Sci. Adv. 2016, 2, e1500323. [Google Scholar] [CrossRef] [PubMed]
- Kummu, M.; Guillaume, J.H.A.; de Moel, H.; Eisner, S.; Florke, M.; Porkka, M.; Siebert, S.; Veldkamp, T.I.E.; Ward, P.J. The world’s road to water scarcity: Shortage and stress in the 20th century and pathways towards sustainability. Sci. Rep. 2016, 6, 38495. [Google Scholar] [CrossRef] [PubMed]
- Liu, J.; Yang, H.; Gosling, S.N.; Kummu, M.; Florke, M.; Pfister, S.; Hanasaki, N.; Wada, Y.; Zhang, X.; Zheng, C.; et al. Water scarcity assessments in the past, present, and future. Earths Future 2017, 5, 545–559. [Google Scholar] [CrossRef] [PubMed]
- ISO 14046; Environmental Management-Water Footprint-Principles, Requirements and Guidelines. International Organization for Standardization: Geneva, Switzerland, 2014.
- Hoekstra, A.Y.; Mekonnen, M.M. The water footprint of humanity. Proc. Natl. Acad. Sci. USA 2012, 109, 3232–3237. [Google Scholar] [CrossRef] [PubMed]
- Vanham, D.; Hoekstra, A.Y.; Wada, Y.; Bouraoui, F.; de Roo, A.; Mekonnen, M.M.; van de Bund, W.J.; Batelan, O.; Pavelic, P.; Bastiaanssen, W.G.M.; et al. Physical water scarcity metrics for monitoring progress towards SDG target 6.4: An evaluation of indicator 6.4.2 “Level of water stress”. Sci. Total Environ. 2018, 613–614, 218–232. [Google Scholar] [CrossRef] [PubMed]
- Zeng, Z.; Liu, J.; Savenije, H.H.G. A simple approach to assess water scarcity integrating water quantity and quality. Econ. Indic. 2013, 34, 441–449. [Google Scholar] [CrossRef]
- Liu, J.; Liu, Q.; Yang, H. Assessing water scarcity by simultaneously considering environmental flow requirements, water quantity, and water quality. Ecol. Indic. 2016, 60, 434–441. [Google Scholar] [CrossRef]
- Quinteiro, P.; Ridoutt, B.G.; Arroja, L.; Dias, A.C. Identification of methodological challenges remaining in the assessment of a water scarcity footprint: A review. Int. J. Life Cycle Assess. 2018, 23, 164–180. [Google Scholar] [CrossRef]
- Schuns, J.F.; Hoekstra, A.Y.; Booij, M.J. Review and classification of indicators of green water availability and scarcity. Hydrol. Earth Syst. Sci. 2015, 12, 5519–5564. [Google Scholar] [CrossRef]
- Kahil, T.; Albiac, J.; Fischer, G.; Strokal, M.; Tramberend, S.; Greve, P.; Tang, T.; Burek, P.; Burtscher, R.; Wada, Y. A nexus modeling framework for assessing water scarcity solutions. Curr. Opin. Environ. Sustain. 2019, 40, 72–80. [Google Scholar] [CrossRef]
- Ledari, M.B.; Saboohi, Y.; Azamian, S. Water-food-energy-ecosystem nexus model development: Resource scarcity and regional development. Energy Nexus 2023, 10, 100207. [Google Scholar] [CrossRef]
- Shemer, H.; Wald, S.; Semiat, R. Challenges and Solutions for Global Water Scarcity. Membranes 2023, 13, 612. [Google Scholar] [CrossRef] [PubMed]
- Wu, C.; Liu, W.; Deng, H. Urbanization and the Emerging Water Crisis: Identifying Water Scarcity and Environmental Risk with Multiple Applications in Urban Agglomerations in Western China. Sustainability 2023, 15, 12977. [Google Scholar] [CrossRef]
- Pierrat, E.; Laurent, A.; Dorber, M.; Rygaard, M.; Verones, F.; Hauschild, M. Advancing water footprint assessments: Combining the impacts of water pollution and scarcity. Sci. Total Environ. 2023, 870, 161910. [Google Scholar] [CrossRef] [PubMed]
- Li, H.; Chen, Q.; Liu, G.; Lombardi, G.V.; Su, M.; Yang, Z. Uncovering the risk spillover of agricultural water scarcity by simultaneously considering water quality and quantity. J. Environ. Manag. 2023, 343, 118209. [Google Scholar] [CrossRef] [PubMed]
- Mekonnen, M.M.; Hoekstra, A.Y. The green, blue and grey water footprint of crops and derived crop products. Hydrol. Earth Syst. Sci. 2011, 15, 1577–1600. [Google Scholar] [CrossRef]
- Mancosu, N.; Snyder, R.L.; Kyriakakis, G.; Spano, D. Water scarcity and future challenges for food production. Water 2015, 7, 975–992. [Google Scholar] [CrossRef]
- Winter, J.M.; Lopez, J.R.; Ruane, A.C.; Young, C.A.; Scanlon, B.R.; Rosenzweig, C. Representing water scarcity in future agricultural assessments. Anthropocene 2017, 18, 15–26. [Google Scholar] [CrossRef]
- Ingrao, C.; Strippoli, R.; Lagioia, G.; Huisingh, D. Water scarcity in agriculture: An overview of causes, impacts and approaches for reducing the risks. Heliyon 2023, 9, e18507. [Google Scholar] [CrossRef] [PubMed]
- Morante-Carballo, F.; Montalván-Burbano, N.; Quiñonez-Barzola, X.; Jaya-Montalvo, M.; Carrión-Mero, P. What do We Know about Water Scarcity in Semi-Arid Zones? A Global Analysis and Research Trends. Water 2022, 14, 2685. [Google Scholar] [CrossRef]
- Ungureanu, N.; Vladut, V.; Voicu, G. Water scarcity and wastewater reuse in crop irrigation. Sustainability 2020, 12, 9055. [Google Scholar] [CrossRef]
- Jaramillo, M.F.; Restrepo, I. Wastewater reuse in agriculture: A review about its limitations and benefits. Sustainability 2017, 9, 1734. [Google Scholar] [CrossRef]
- Lopez-Serrano, M.J.; Velasco-Munoz, J.F.; Arnar-Sanchez, J.A.; Roman-Sanchez, I.M. Sustainable use of wastewater in agriculture: A bibliometric analysis of worldwide research. Sustainability 2020, 12, 8948. [Google Scholar] [CrossRef]
- Elgallal, M.; Fletcher, L.; Evans, B. Assessment of potential risks associated with chemicals in wastewater used for irrigation in arid and semiarid zones: A review. Agr. Water Manag. 2016, 177, 419–431. [Google Scholar] [CrossRef]
- Saliu, T.D.; Oladoja, N.A. Nutrient recovery from wastewater and reuse in agriculture: A review. Environ. Chem. Lett. 2021, 19, 2299–2316. [Google Scholar] [CrossRef]
- Gude, V.G. Desalination and water reuse to address global water scarcity. Rev. Environ. Sci. Biotechnol. 2017, 16, 591–609. [Google Scholar] [CrossRef]
- Jimenez, S.; Mico, M.M.; Arnaldos, M.; Medina, F.; Contreras, S. State of the art of produced water treatment. Chemosphere 2018, 192, 186–208. [Google Scholar] [CrossRef]
- Younas, F.; Mustafa, A.; Rahman Farooqi, Z.U.; Wang, X.; Younas, S.; Mohy-Ud-Din, W.; Hameed, M.A.; Abrar, M.M.; Maitlo, A.A.; Noreen, S.; et al. Current and emerging adsorbent technologies for wastewater treatment: Trends, limitations, and environmental implications. Water 2021, 13, 215. [Google Scholar] [CrossRef]
- Davis, M. Water and Wastewater Engineering: Design Principles and Practice; McGraw Hill: New York, NY, USA, 2019. [Google Scholar]
- Edzwald, J. Water Quality and Treatment: A Handbook on Drinking Water; McGraw Hill: New York, NY, USA, 2010. [Google Scholar]
- Mohammad, A.W.; Teow, Y.H.; Ang, W.L.; Chung, Y.T.; Oatley-Radcliffe, D.L.; Hilal, N. Nanofiltration membranes review: Recent advances and future prospects. Desalination 2015, 356, 226–254. [Google Scholar] [CrossRef]
- Jia, T.-Z.; Rong, M.-Y.; Chen, C.-T.; Yong, W.F.; Lau, S.K.; Zhou, R.F.; Chen, M.; Sun, S.P. Recent advances in nanofiltration-based hybrid processes. Desalination 2023, 565, 116852. [Google Scholar] [CrossRef]
- Rabiee, N.; Sharma, R.; Foorginezhad, S.; Jouyandeh, M.; Asadnia, M.; Rabiee, M.; Akhavan, O.; Lima, E.C.; Formela, K.; Ashrafizadeh, M.; et al. Green and Sustainable Membranes: A review. Environ. Res. 2023, 231, 116133. [Google Scholar] [CrossRef]
- Elsaid, K.; Olabi, A.G.; Abdel-Wahab, A.; Elkamel, A.; Alami, A.H.; Inayat, A.; Chae, K.-J.; Abdelkareem, M.A. Membrane processes for environmental remediation of nanomaterials: Potentials and challenges. Sci. Total Environ. 2023, 879, 162569. [Google Scholar] [CrossRef] [PubMed]
- Fu, F.; Wang, Q. Removal of heavy metal ions from wastewaters: A review. J. Environ. Manag. 2011, 92, 407–418. [Google Scholar] [CrossRef] [PubMed]
- Parashar, N.; Hait, S. Recent advances on microplastics pollution and removal from wastewater systems: A critical review. J. Environ. Manag. 2023, 340, 118014. [Google Scholar] [CrossRef] [PubMed]
- Kima, S.; Chua, K.H.; Al-Hamadania, Y.A.J.; Park, C.M.; Jang, M.; Kim, D.-H.; Yue, M.; Heof, J.; Yoon, Y. Removal of contaminants of emerging concern by membranes in water and wastewater: A review. Chem. Eng. J. 2018, 335, 896–914. [Google Scholar] [CrossRef]
- Alzahrania, S.; Mohammad, A.W. Challenges and trends in membrane technology implementation for produced water treatment: A review. J. Water Process Eng. 2014, 4, 107–133. [Google Scholar] [CrossRef]
- Al Aania, S.; Mustafa, T.N.; Hilal, N. Ultrafiltration membranes for wastewater and water process engineering: A comprehensive statistical review over the past decade. J. Water Process Eng. 2020, 35, 101241. [Google Scholar] [CrossRef]
- Ji, K.; Liu, C.; He, H.; Mao, X.; Wei, L.; Wang, H.; Zhang, M.; Shen, Y.; Sun, R.; Zhou, F. Research Progress of Water Treatment Technology Based on Nanofiber Membranes. Polymers 2023, 15, 741. [Google Scholar] [CrossRef] [PubMed]
- Zhao, Y.; Tong, T.; Wang, X.; Lin, S.; Reid, E.M.; Chen, Y. Differentiating Solutes with Precise Nanofiltration for Next Generation Environmental Separations: A Review. Environ. Sci. Technol. 2021, 55, 1359–1376. [Google Scholar] [CrossRef] [PubMed]
- Qiu, Y.; Depuydt, S.; Ren, L.-F.; Zhong, C.; Wu, C.; Shao, J.; Xia, L.; Zhao, Y.; Van der Bruggen, B. Progress of Ultrafiltration-Based Technology in Ion Removal and Recovery: Enhanced Membranes and Integrated Processes. ACS EST Water 2023, 3, 1702–1719. [Google Scholar] [CrossRef]
- Zhao, M.; Xu, Y.; Zhang, C.; Rong, H.; Zeng, G. New trends in removing heavy metals from wastewater. Appl. Microbiol. Biotechnol. 2016, 100, 6509–6518. [Google Scholar] [CrossRef]
- Kaswan, M.S.; Rathi, R.; Cross, J.; Garza-Reyes, J.A.; Antony, J.; Yadav, V. Integrating Green Lean Six Sigma and industry 4.0: A conceptual framework. J. Manuf. Technol. Manag. 2023, 34, 87–121. [Google Scholar] [CrossRef]
- Rajarajeswari, C.; Anbalagan, C. Integration of the green and lean principles for more sustainable development: A case study. Mater. Today Proc. 2023; in press. [Google Scholar] [CrossRef]
- Yadav, Y.; Kaswan, M.S.; Gahlot, P.; Duhan, R.K.; Garza-Reyes, J.A.; Rathi, R.; Chaudhary, R.; Yadav, G. Green Lean Six Sigma for sustainability improvement: A systematic review and future research agenda. Int. J. Lean Six Sigma 2023, 14, 759–790. [Google Scholar] [CrossRef]
- Yadav, S.; Samadhiya, A.; Kumar, A.; Majumdar, A.; Garza-Reyes, J.A.; Luthra, S. Achieving the sustainable development goals through net zero emissions: Innovation-driven strategies for transitioning from incremental to radical lean, green and digital technologies. Resour. Conserv. Recycl. 2023, 197, 107094. [Google Scholar] [CrossRef]
- Fiorello, M.; Gladysz, B.; Corti, D.; Wybraniak-Kujawa, M.; Ejsmont, K.; Sorlini, M. Towards a smart lean green production paradigm to improve operational performance. J. Clean. Prod. 2023, 413, 137418. [Google Scholar] [CrossRef]
- Elemure, I.; Dhakal, H.N.; Leseure, M.; Radulovic, J. Integration of Lean Green and Sustainability in Manufacturing: A Review on Current State and Future Perspectives. Sustainability 2023, 15, 10261. [Google Scholar] [CrossRef]
- Vinuesa, R.; Azizpour, H.; Leite, I.; Balaam, M.; Dignum, V.; Domisch, S.; Fellander, A.; Langhans, S.D.; Tegmark, M.; Nerini, F.F. The role of artificial intelligence in achieving the Sustainable Development Goals. Nature Commun. 2020, 11, 233. [Google Scholar] [CrossRef] [PubMed]
- Farrukh, A.; Mathrani, S.; Sajjad, A. Green-lean-six sigma practices and supporting factors for transitioning towards circular economy: A natural resource and intellectual capital-based view. Resour. Policy 2023, 84, 103789. [Google Scholar] [CrossRef]
- Kaswan, M.S.; Rathi, R.; Garza-Reyes, J.A.; Antony, J. Green Lean Six Sigma sustainability—Oriented project selection and implementation framework for manufacturing industry. Int. J. Lean Six Sigma 2023, 14, 33–71. [Google Scholar] [CrossRef]
- Fercoq, A.; Lamouri, S.; Carbone, V. Lean/Green integration focused on waste reduction techniques. J. Clean. Prod. 2016, 137, 567–578. [Google Scholar] [CrossRef]
- Dieste, M.; Panizzolo, R.; Garza-Reyes, J.A.; Anosike, A. The relationship between lean and environmental performance: Practices and measures. J. Clean. Prod. 2019, 224, 120–131. [Google Scholar] [CrossRef]
- George, M.; Blackwell, D.; Rajan, D. Lean Six Sigma in the Age of Artificial Intelligence: Harnessing the Power of the Fourth Industrial Revolution; McGraw-Hill: New York, NY, USA, 2019. [Google Scholar]
- George, M.; Works, J.; Watson-Hemphill, K. Fast Innovation: Achieving Superior Differentiation, Speed to Market, and Increased Profitability; McGraw-Hill: New York, NY, USA, 2005. [Google Scholar]
- Bolisetty, S.; Peydayesh, M.; Mezzenga, R. Sustainable technologies for water purification from heavy metals: Review and analysis. Chem. Soc. Rev. 2019, 48, 463–487. [Google Scholar] [CrossRef] [PubMed]
- Wang, K.; Wang, X.; Januszewski, B.; Liu, Y.; Li, D.; Fu, R.; Elimelech, M.; Huang, X. Tailored design of nanofiltration membranes for water treatment based on synthesis–property–performance relationships. Chem. Soc. Rev. 2022, 51, 672–719. [Google Scholar] [CrossRef] [PubMed]
- Burn, D.H.; McBean, E.A. Optimization modelling of water quality in an uncertain environment. Water Resour. Res. 1985, 21, 934–940. [Google Scholar] [CrossRef]
- Yasar, A.; Dogan, E.C.; Ayberk, H.S.; Aydiner, C. Water Recovery from Urban Wastewater for Irrigation using Ultrafiltration and Nanofiltration: Optimization and Performance. Clean Soil Air Water 2022, 50, 2200280. [Google Scholar] [CrossRef]
- Malviya, A.; Jaspal, D. Artificial intelligence as an upcoming technology in wastewater treatment: A comprehensive review. Environ. Technol. Rev. 2021, 10, 177–187. [Google Scholar] [CrossRef]
- Pilar Callao, M. Multivariate experimental design in environmental analysis. Trends Anal. Chem. 2014, 62, 86–92. [Google Scholar] [CrossRef]
- Fisher, R.A. Statistical Methods, Experimental Design, and Scientific Inference; Oxford University Press: Oxford, UK, 1990. [Google Scholar]
- Box, G.E.P.; Hunter, W.G.; Hunter, J.S. Statistics for Experimenters—Design, Innovation, and Discovery; Wiley: New York, NY, USA, 2005. [Google Scholar]
- Taguchi, G.; Chowdhury, S.; Wu, Y. Quality Engineering Handbook; Wiley: Hoboken, NJ, USA, 2004. [Google Scholar]
- Taguchi, G.; Chowdhury, S.; Taguchi, S. Robust Engineering: Learn How to Boost Quality while Reducing Costs and Time to Market; McGraw-Hill: New York, NY, USA, 2000. [Google Scholar]
- Perrett, J.J.; Higgins, J.J. A Method for Analyzing Unreplicated Agricultural Experiments. Crop Sci. 2006, 46, 2482–2485. [Google Scholar] [CrossRef]
- Stewart-Oaten, A.; Bence, J.R.; Osenberg, C.W. Assessing effects of unreplicated perturbations: No simple solutions. Ecology 1992, 73, 1396. [Google Scholar] [CrossRef]
- Pagliari, P.H.; Ranaivoson, A.Z.; Strock, J.S. Options for statistical analysis of unreplicated paired design drainage experiments. Agr. Water Manag. 2021, 244, 106604. [Google Scholar] [CrossRef]
- Hamada, M.; Balakrishnan, N. Analyzing unreplicated factorial experiments: A review with some new proposals. Stat. Sin. 1998, 8, 1–28. [Google Scholar]
- Derringer, G.; Suich, R. Simultaneous optimization of several response variables. J. Qual. Technol. 1980, 12, 214–219. [Google Scholar] [CrossRef]
- Carlson, R.; Nordahl, A.; Barth, T.; Myklebust, R. An approach to evaluating screening experiments when several responses are measured. Chemom. Intell. Lab. Syst. 1991, 12, 237–255. [Google Scholar] [CrossRef]
- Nicolis, G.; Prigogine, I. Self-Organization in Nonequilibrium Systems: From Dissipative Structures to Order through Fluctuations; Wiley: Hoboken, NJ, USA, 1977. [Google Scholar]
- Prigogine, I. The End of Certainty; Free Press: New York, NY, USA, 1997. [Google Scholar]
- Breiman, L. Statistical modeling: The two cultures. Stat. Sci. 2001, 16, 199–231. [Google Scholar] [CrossRef]
- Besseris, G.J. Concurrent multiresponse multifactorial screening of an electrodialysis process of polluted wastewater using robust non-linear Taguchi profiling. Chemom. Intell. Lab. Syst. 2020, 200, 103997. [Google Scholar] [CrossRef]
- Besseris, G. Micro-Clustering and Rank-Learning Profiling of a Small Water-Quality Multi-Index Dataset to Improve a Recycling Process. Water 2021, 13, 2469. [Google Scholar] [CrossRef]
- Besseris, G. Wastewater Quality Screening Using Affinity Propagation Clustering and Entropic Methods for Small Saturated Nonlinear Orthogonal Datasets. Water 2022, 14, 1238. [Google Scholar] [CrossRef]
- Thrun, M.C.; Ultsch, A. Swarm intelligence for self-organized clustering. Artif. Intell. 2021, 290, 103237. [Google Scholar] [CrossRef]
- Thrun, M.C. Projection-Based Clustering through Self-Organization and Swarm Intelligence; Springer: Berlin/Heidelberg, Germany, 2018; ISBN 978-3658205393. [Google Scholar]
- Shepard, R.N. The analysis of proximities: Multidimensional scaling with an unknown distance function-Part II. Psychometrika 1962, 27, 219–246. [Google Scholar] [CrossRef]
- Kruskal, J.B. Multidimensional scaling by optimizing goodness of fit to a nonmetric hypothesis. Psychometrika 1964, 29, 1–27. [Google Scholar] [CrossRef]
- Davies, D.L.; Bouldin, D.W. A cluster separation measure. IEEE Trans. Pattern Anal. Mach. Intell. 1979, 1, 224–227. [Google Scholar] [CrossRef]
- Nash, J. Non-cooperative games. Ann. Math. 1951, 54, 286–295. [Google Scholar] [CrossRef]
- McGill, R.; Tukey, J.W.; Larsen, W.A. Variations of box plots. Am. Stat. 1978, 32, 12–16. [Google Scholar]
- Wilk, M.B.; Gnanadesikan, R. Probability plotting methods for the analysis of data. Biometrika 1968, 55, 1–17. [Google Scholar] [CrossRef] [PubMed]
- Kampstra, P. Beanplot: A boxplot alternative for visual comparison of distributions. J. Stat. Soft. 2008, 28, 1–9. [Google Scholar] [CrossRef]
- R Core Team. R (Version 4.3.1): A Language and Environment for Statistical Computing; R Foundation for Statistical Computing: Vienna, Austria, 2023; Available online: https://www.R-project.org/ (accessed on 16 June 2023).
- Spearman, C. The proof and measurement of association between two things. Am. J. Psych. 1904, 15, 72–101. [Google Scholar] [CrossRef]
- Zwillinger, D.; Kokoska, S. Standard Probability and Statistical Tables and Formula; Chapman & Hall: Boca Raton, FL, USA, 2000. [Google Scholar]
- Shapiro, S.S.; Wilk, M.B. An analysis of variance test for normality (complete samples). Biometrika 1965, 52, 591–611. [Google Scholar] [CrossRef]
- Kolmogorov, A. Sulla determinazione empirica di una legge di distibuzione. Giorn. Ist. Ital. Attuari 1933, 4, 83–91. [Google Scholar]
- Smirnov, N. Table for estimating the goodness of fit of empirical distributions. Ann. Math. Stat. 1948, 19, 279–281. [Google Scholar] [CrossRef]
- Lilliefors, H.W. On the Kolmogorov-Smirnov test for normality with mean and variance unknown. J. Am. Stat. Assoc. 1967, 62, 399–402. [Google Scholar] [CrossRef]



















{kind=link}
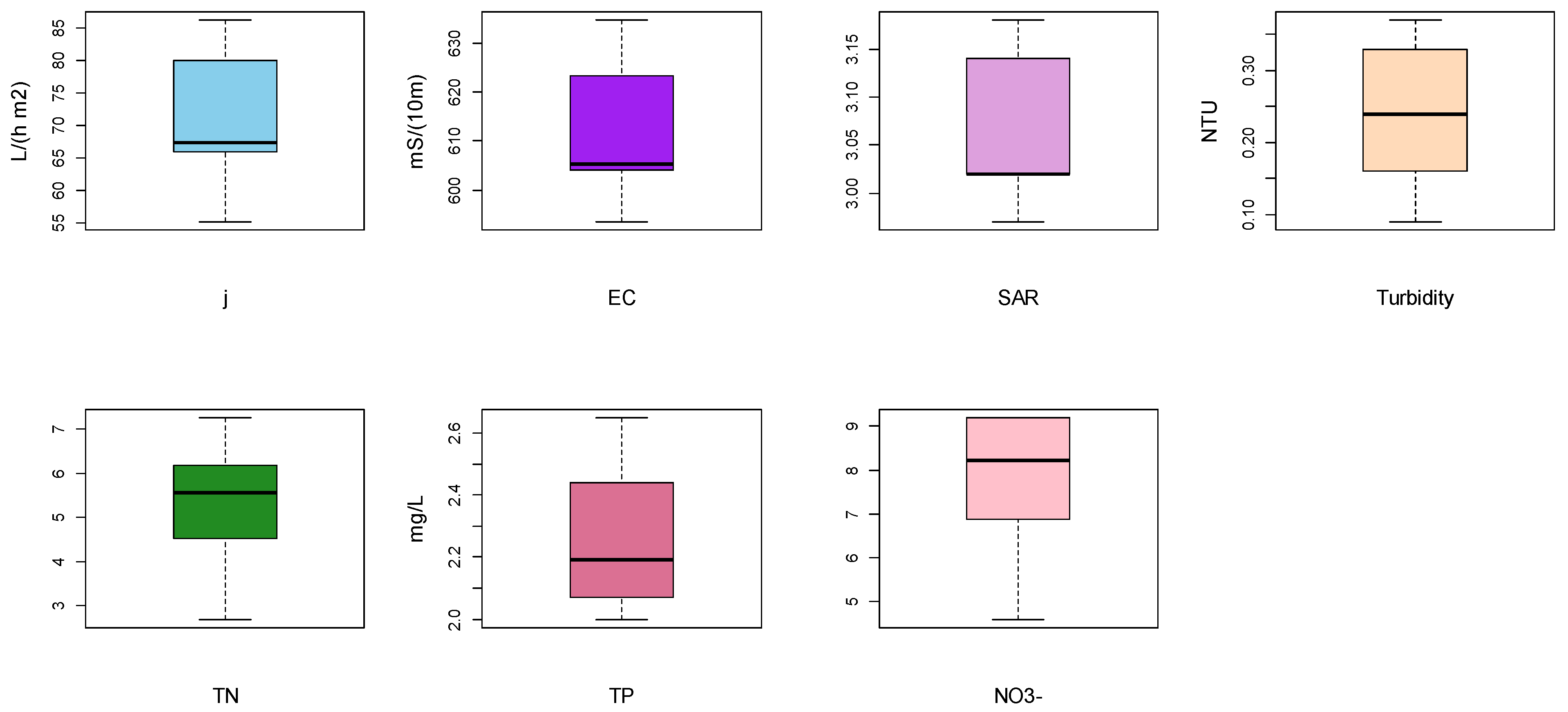{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Spearman′s Rho | Significance (Two-Tailed) | 95% Confidence Intervals (Two-Tailed) a,b | ||
|---|---|---|---|---|
| Lower | Upper | |||
| j—EC | −0.017 | 0.966 | −0.686 | 0.668 |
| j—SAR | −0.621 | 0.074 | −0.914 | 0.096 |
| j—Turb | −0.134 | 0.731 | −0.744 | 0.597 |
| j—TN | 0.343 | 0.366 | −0.435 | 0.828 |
| j—TP | 0.294 | 0.442 | −0.478 | 0.810 |
| j—NO3 | −0.322 | 0.398 | −0.820 | 0.454 |
| EC—SAR | −0.179 | 0.645 | −0.763 | 0.567 |
| EC—Turb | 0.201 | 0.604 | −0.551 | 0.773 |
| EC—TN | −0.561 | 0.116 | −0.897 | 0.188 |
| EC—TP | 0.689 | 0.040 | 0.022 | 0.932 |
| EC—NO3 | 0.252 | 0.512 | −0.512 | 0.794 |
| SAR—Turb | −0.180 | 0.644 | −0.764 | 0.566 |
| SAR—TN | −0.419 | 0.262 | −0.854 | 0.361 |
| SAR—TP | −0.262 | 0.496 | −0.798 | 0.505 |
| SAR—NO3 | −0.022 | 0.955 | −0.689 | 0.665 |
| Turb—TN | −0.055 | 0.889 | −0.706 | 0.646 |
| Turb—TP | 0.308 | 0.420 | −0.466 | 0.815 |
| Turb—NO3 | −0.127 | 0.745 | −0.740 | 0.602 |
| TN—TP | −0.371 | 0.325 | −0.838 | 0.409 |
| TN—NO3 | −0.131 | 0.737 | −0.742 | 0.599 |
| TP—NO3 | 0.202 | 0.602 | −0.551 | 0.773 |
| Characteristics (Ultrafiltration Process) | QCD | Efficiency | Relative Efficiency | Cumulative Relative Efficiency |
|---|---|---|---|---|
| Turbidity | 0.35 | 0.123 | 0.664 | 0.664 |
| TN | 0.16 | 0.0256 | 0.139 | 0.803 |
| NO3 | 0.14 | 0.0196 | 0.106 | 0.909 |
| J | 0.097 | 0.00941 | 0.051 | 0.960 |
| TP | 0.082 | 0.00672 | 0.036 | 0.997 |
| SAR | 0.019 | 0.000361 | 0.002 | 0.999 |
| EC | 0.016 | 0.000256 | 0.001 | 1 |
| Total | 0.18445 | 1 |
| Spearman′s Rho | Significance (Two-Tailed) | 95% Confidence Intervals (Two-Tailed) a,b | ||
|---|---|---|---|---|
| Lower | Upper | |||
| j—EC | −0.703 | 0.035 | −0.935 | −0.049 |
| j—Turb | −0.151 | 0.699 | −0.751 | 0.586 |
| j—TN | −0.377 | 0.318 | −0.840 | 0.403 |
| j—TP | −0.469 | 0.203 | −0.870 | 0.305 |
| j—NO3 | 0.468 | 0.204 | −0.306 | 0.870 |
| EC—Turb | 0.500 | 0.170 | −0.268 | 0.879 |
| EC—TN | 0.667 | 0.050 | −0.019 | 0.926 |
| EC—TP | 0.667 | 0.050 | −0.019 | 0.926 |
| EC—NO3 | −0.881 | 0.002 | −0.976 | −0.507 |
| Turb—TN | 0.217 | 0.576 | −0.540 | 0.779 |
| Turb—TP | 0.333 | 0.381 | −0.444 | 0.824 |
| Turb—NO3 | −0.390 | 0.300 | −0.844 | 0.390 |
| TN—TP | 0.133 | 0.732 | −0.598 | 0.743 |
| TN—NO3 | −0.746 | 0.021 | −0.945 | −0.139 |
| TP—NO3 | −0.339 | 0.372 | −0.826 | 0.439 |
| Characteristics (Nanofiltration Process) | QCD | Efficiency | Relative Efficiency | Cumulative Relative Efficiency |
|---|---|---|---|---|
| NO3 | 0.614 | 0.377 | 0.389 | 0.389 |
| EC | 0.613 | 0.376 | 0.387 | 0.776 |
| TN | 0.36 | 0.130 | 0.134 | 0.910 |
| J | 0.24 | 0.0576 | 0.0594 | 0.969 |
| TP | 0.17 | 0.0289 | 0.0298 | 0.999 |
| Turbidity | 0.032 | 0.00102 | 0.00106 | 1 |
| Total | 0.970 | 1 |
| Distance Measure | Cluster Number | Kruskal Stress Value |
|---|---|---|
| Euclidean | 2 | 6.89 × 10−14 |
| Euclidean | 3 | 4.66 × 10−14 |
| Maximum | 2 | 3.13 |
| Maximum | 3 | 8.51 × 10−3 |
| Manhattan | 2 | 2.63 |
| Manhattan | 3 | 5.12 × 10−3 |
| Canberra | 2 | 9.36 |
| Canberra | 3 | 2.14 |
| Minkowski (p = 4) | 2 | 4.19 × 10−3 |
| Minkowski (p = 4) | 3 | 2.22 × 10−3 |
| Distance Measure | Cluster Number | Kruskal Stress Value |
|---|---|---|
| Euclidean | 2 | 5.42 × 10−14 |
| Euclidean | 3 | 6.01 × 10−14 |
| Maximum | 2 | 2.32 × 10−3 |
| Maximum | 3 | 5.15 × 10−3 |
| Manhattan | 2 | 9.03 ×10−3 |
| Manhattan | 3 | 5.58 × 10−14 |
| Canberra | 2 | 5.98 × 10−3 |
| Canberra | 3 | 6.58 × 10−14 |
| Minkowski (p = 4) | 2 | 7.91 × 10−3 |
| Minkowski (p = 4) | 3 | 5.78 × 10−14 |
| Davies–Bouldin Index Estimation For Fractional Factorial Vectors | |||||
|---|---|---|---|---|---|
| Centrotypes | Self-validation | A | B | C | D |
| Centroids | 0.74 (0.80) * | 1.89 | 6.79 | 1.88 | 4.7 |
| Medoids | 0.76 (1.07) * | 1.27 | 2.08 | 3.55 | 4.44 |
| Davies–Bouldin Index Estimation for Fractional Factorial Vectors | ||||||
| Cluster Size | Centrotypes | Self-validation | A | B | C | D |
| k = 2 | Centroids | 0.39 | 0.41 | 12.1 | 19.97 | 22.87 |
| Medoids | 0.34 | 0.4 | 5.63 | 5.61 | 5.6 | |
| k = 3 | Centrotypes | Self-validation | A | B | C | D |
| Centroids | 0.41 | 0.41 | 12.1 | 19.97 | 22.87 | |
| Medoids | 0.4 | 0.4 | 5.63 | 5.61 | 5.6 | |
| Kolmogorov–Smirnov a | Shapiro–Wilk | |||||
|---|---|---|---|---|---|---|
| Statistic | Df | p-Value | Statistic | df | p-Value | |
| J | 0.208 | 9 | 0.200 * | 0.927 | 9 | 0.452 |
| EC | 0.241 | 9 | 0.141 | 0.886 | 9 | 0.180 |
| SAR | 0.261 | 9 | 0.079 | 0.865 | 9 | 0.110 |
| Turb | 0.167 | 9 | 0.200 * | 0.948 | 9 | 0.672 |
| TN | 0.156 | 9 | 0.200 * | 0.945 | 9 | 0.633 |
| TP | 0.222 | 9 | 0.200 * | 0.864 | 9 | 0.106 |
| NO3− | 0.240 | 9 | 0.142 | 0.800 | 9 | 0.020 |
| PROCESS | |||||
|---|---|---|---|---|---|
| Ultrafiltration | Nanofiltration | ||||
| Characteristic Estimator | Statistic | Std. Error | Statistic | Std. Error | |
| J | |||||
| Skewness | 0.249 | 0.717 | 1.879 | 0.717 | |
| Kurtosis | −0.418 | 1.400 | 3.847 | 1.400 | |
| EC | |||||
| Skewness | 0.251 | 0.717 | −0.171 | 0.717 | |
| Kurtosis | −1.623 | 1.400 | −1.705 | 1.400 | |
| SAR | |||||
| Skewness | 0.518 | 0.717 | |||
| Kurtosis | −1.496 | 1.400 | |||
| TURBIDITY | |||||
| Skewness | −0.148 | 0.717 | −2.746 | 0.717 | |
| Kurtosis | −1.163 | 1.400 | 7.885 | 1.400 | |
| TN | |||||
| Skewness | −0.430 | 0.717 | 0.990 | 0.717 | |
| Kurtosis | 0.345 | 1.400 | −0.204 | 1.400 | |
| TP | |||||
| Skewness | 0.589 | 0.717 | −1.023 | 0.717 | |
| Kurtosis | −1.357 | 1.400 | −0.848 | 1.400 | |
| NO3 | |||||
| Skewness | −0.913 | 0.717 | −0.761 | 0.717 | |
| Kurtosis | −0.711 | 1.400 | −1.720 | 1.400 | |
| Characteristic | Cluster # | ||
|---|---|---|---|
| 1 | 2 | 3 | |
| J | 62.4 | 68.9 | 83.2 |
| EC | 634.7 | 600.4 | 623.0 |
| SAR | 3.08 | 3.09 | 3.00 |
| Turbidity | 0.31 | 0.22 | 0.21 |
| TN | 3.60 | 5.83 | 6.15 |
| TP | 2.65 | 2.07 | 2.38 |
| NO3 | 8.36 | 6.90 | 8.72 |
| Characteristic | Cluster | Error | F-Ratio | p-Value | ||
| Mean Square | Df | Mean Square | Df | |||
| J | 232.789 | 2 | 47.418 | 6 | 4.909 | 0.055 |
| EC | 963.093 | 2 | 23.303 | 6 | 41.329 | <0.001 |
| SAR | 0.006 | 2 | 0.007 | 6 | 0.890 | 0.459 |
| Turbidity | 0.006 | 2 | 0.010 | 6 | 0.587 | 0.585 |
| TN | 4.250 | 2 | 1.371 | 6 | 3.099 | 0.119 |
| TP | 0.258 | 2 | 0.005 | 6 | 55.501 | <0.001 |
| NO3 | 3.021 | 2 | 3.805 | 6 | .794 | 0.494 |
| Characteristic | Kolmogorov–Smirnov a | Shapiro–Wilk | ||||
|---|---|---|---|---|---|---|
| Statistic | Df | p-Value | Statistic | Df | p-Value | |
| J | 0.283 | 9 | 0.036 | 0.735 | 9 | 0.004 |
| EC | 0.198 | 9 | 0.200* | 0.888 | 9 | 0.192 |
| Turbidity | 0.376 | 9 | <0.001 | 0.597 | 9 | <0.001 |
| TN | 0.247 | 9 | 0.121 | 0.872 | 9 | 0.131 |
| TP | 0.345 | 9 | 0.003 | 0.761 | 9 | 0.007 |
| NO3− | 0.291 | 9 | 0.027 | 0.731 | 9 | 0.003 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Besseris, G. Datacentric Similarity Matching of Emergent Stigmergic Clustering to Fractional Factorial Vectoring: A Case for Leaner-and-Greener Wastewater Recycling. Appl. Sci. 2023, 13, 11926. https://doi.org/10.3390/app132111926
Besseris G. Datacentric Similarity Matching of Emergent Stigmergic Clustering to Fractional Factorial Vectoring: A Case for Leaner-and-Greener Wastewater Recycling. Applied Sciences. 2023; 13(21):11926. https://doi.org/10.3390/app132111926
Chicago/Turabian StyleBesseris, George. 2023. "Datacentric Similarity Matching of Emergent Stigmergic Clustering to Fractional Factorial Vectoring: A Case for Leaner-and-Greener Wastewater Recycling" Applied Sciences 13, no. 21: 11926. https://doi.org/10.3390/app132111926