
DP-YOLO: Effective Improvement Based on YOLO Detector

Abstract
:1. Introduction
- Modifying the expansion policy of positive samples in label assignment. Combined with the previous work, the quality of positive samples can be improved by considering the effective receptive field characteristics, which can be used to update the parameters in the deep network to obtain a better detector.
- Introducing deformable convolution into the backbone network of YOLOv5s in a more cost-effective way. By leveraging the distinct properties of various deformable convolution operators to design and balance them, a substantial enhancement in detection accuracy is attained on the generalized dataset. Remarkably, this improvement is achieved with only a minor increase in the number of parameters and computational effort required.
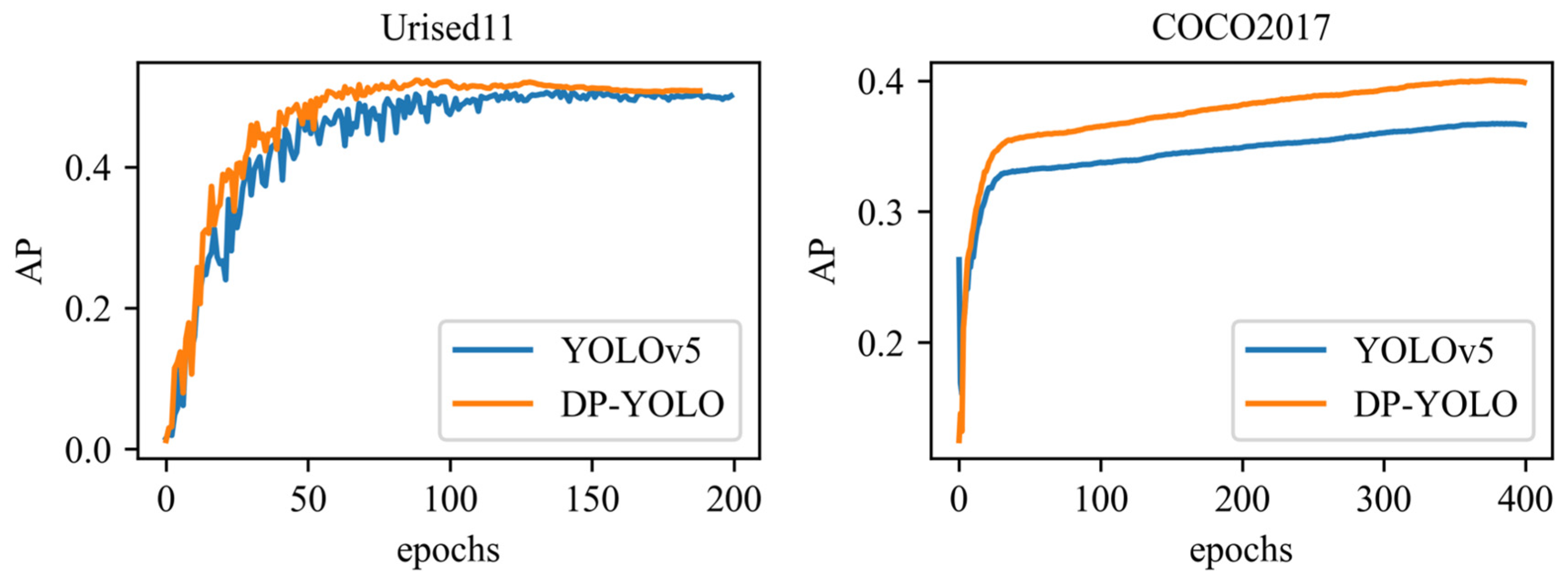
- The improved detector DP-YOLO under the action of both methods was validated and analyzed on a urine sediment dataset for a specific assay domain, in addition to being validated on the generic dataset COCO2017.
2. Related Work
2.1. Label Assignment
2.2. Deformable Convolution
3. Approaches
3.1. Petal-like Sample Amplification (PSA)
3.2. Deformable YOLO v5 Backbone (DYB)
3.3. Urine Sediment Dataset
3.3.1. Urine Sediment Detection
3.3.2. Datasets in the Field of Urine Sediment Detection
3.3.3. Urised11
4. Experiment
4.1. Experimental Environment and Details
4.2. Evaluation Metrics
4.3. Experimental Results and Analysis
4.4. Impact of PSA on Label Assignment
4.5. Comparison Experiments about DYB
4.6. Comparison with SOTA Method on Urised11 Dataset
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| 65.4 |
References
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar] [CrossRef]
- Girshick, R. Fast r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. Adv. Neural Inf. Process. Syst. 2015, 28, 1497. [Google Scholar] [CrossRef] [PubMed]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar] [CrossRef]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.-Y.; Berg, A.C. Ssd: Single shot multibox detector. In Proceedings of the Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Proceedings, Part I 14. pp. 21–37. [Google Scholar] [CrossRef]
- Lin, T.-Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30, 3762. [Google Scholar] [CrossRef]
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End-to-end object detection with transformers. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; pp. 213–229. [Google Scholar] [CrossRef]
- Pang, J.; Chen, K.; Shi, J.; Feng, H.; Ouyang, W.; Lin, D. Libra r-cnn: Towards balanced learning for object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–19 June 2019; pp. 821–830. [Google Scholar] [CrossRef]
- Tian, Z.; Shen, C.; Chen, H.; He, T. Fcos: Fully convolutional one-stage object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 9627–9636. [Google Scholar]
- Duan, K.; Bai, S.; Xie, L.; Qi, H.; Huang, Q.; Tian, Q. Centernet: Keypoint triplets for object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 6569–6578. [Google Scholar] [CrossRef]
- Zhang, X.; Wan, F.; Liu, C.; Ji, R.; Ye, Q. Freeanchor: Learning to match anchors for visual object detection. Adv. Neural Inf. Process. Syst. 2019, 32, 2466. [Google Scholar] [CrossRef]
- Zhang, S.; Chi, C.; Yao, Y.; Lei, Z.; Li, S.Z. Bridging the gap between anchor-based and anchor-free detection via adaptive training sample selection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 9759–9768. [Google Scholar] [CrossRef]
- Ge, Z.; Liu, S.; Li, Z.; Yoshie, O.; Sun, J. Ota: Optimal transport assignment for object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 303–312. [Google Scholar] [CrossRef]
- Zhu, B.; Wang, J.; Jiang, Z.; Zong, F.; Liu, S.; Li, Z.; Sun, J. Autoassign: Differentiable label assignment for dense object detection. arXiv 2020, arXiv:2007.03496. [Google Scholar] [CrossRef]
- Feng, C.; Zhong, Y.; Gao, Y.; Scott, M.R.; Huang, W. Tood: Task-aligned one-stage object detection. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, BC, Canada, 11–17 October 2021; pp. 3490–3499. [Google Scholar] [CrossRef]
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Venice, Italy, 22–29 October 2017; pp. 7263–7271. [Google Scholar] [CrossRef]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar] [CrossRef]
- Bochkovskiy, A.; Wang, C.-Y.; Liao, H.-Y.M. Yolov4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar] [CrossRef]
- Ge, Z.; Liu, S.; Wang, F.; Li, Z.; Sun, J. Yolox: Exceeding yolo series in 2021. arXiv 2021, arXiv:2107.08430. [Google Scholar] [CrossRef]
- Wang, C.-Y.; Bochkovskiy, A.; Liao, H.-Y.M. YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. arXiv 2022, arXiv:2207.02696. [Google Scholar] [CrossRef]
- Li, C.; Li, L.; Jiang, H.; Weng, K.; Geng, Y.; Li, L.; Ke, Z.; Li, Q.; Cheng, M.; Nie, W. YOLOv6: A single-stage object detection framework for industrial applications. arXiv 2022, arXiv:2209.02976. [Google Scholar] [CrossRef]
- Dai, J.; Qi, H.; Xiong, Y.; Li, Y.; Zhang, G.; Hu, H.; Wei, Y. Deformable convolutional networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 764–773. [Google Scholar] [CrossRef]
- Zhu, X.; Hu, H.; Lin, S.; Dai, J. Deformable convnets v2: More deformable, better results. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–19 June 2019; pp. 9308–9316. [Google Scholar] [CrossRef]
- Wang, W.; Dai, J.; Chen, Z.; Huang, Z.; Li, Z.; Zhu, X.; Hu, X.; Lu, T.; Lu, L.; Li, H. Internimage: Exploring large-scale vision foundation models with deformable convolutions. arXiv 2022, arXiv:2211.05778. [Google Scholar] [CrossRef]
- Huang, L.; Yang, Y.; Deng, Y.; Yu, Y. Densebox: Unifying landmark localization with end to end object detection. arXiv 2015, arXiv:1509.04874. [Google Scholar] [CrossRef]
- Luo, W.; Li, Y.; Urtasun, R.; Zemel, R. Understanding the effective receptive field in deep convolutional neural networks. Adv. Neural Inf. Process. Syst. 2016, 29, 4128. [Google Scholar] [CrossRef]
- Wang, Q.; Qian, Y.; Hu, Y.; Wang, C.; Ye, X.; Wang, H. M2YOLOF: Based on effective receptive fields and multiple-in-single-out encoder for object detection. Expert Syst. Appl. 2023, 213, 118928. [Google Scholar] [CrossRef]
- Liang, Y.; Tang, Z.; Yan, M.; Liu, J. Object detection based on deep learning for urine sediment examination. Biocybern. Biomed. Eng. 2018, 38, 661–670. [Google Scholar] [CrossRef]
- Avci, D.; Sert, E.; Dogantekin, E.; Yildirim, O.; Tadeusiewicz, R.; Plawiak, P. A new super resolution Faster R-CNN model based detection and classification of urine sediments. Biocybern. Biomed. Eng. 2023, 43, 58–68. [Google Scholar] [CrossRef]
- Goswami, D.; Aggrawal, H.O.; Gupta, R.; Agarwal, V. Urine microscopic image dataset. arXiv 2021, arXiv:2111.10374. [Google Scholar] [CrossRef]
- Tuncer, T.; Erkuş, M.; Çınar, A.; Ayyıldız, H.; Tuncer, S.A. Urine Dataset having eigth particles classes. arXiv 2023, arXiv:2302.09312. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Adv. Neural Inf. Process. Syst. 2012, 25, 84–90. [Google Scholar] [CrossRef]
- Zhang, R.; Isola, P.; Efros, A.A.; Shechtman, E.; Wang, O. The unreasonable effectiveness of deep features as a perceptual metric. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 586–595. [Google Scholar] [CrossRef]
- Lin, T.-Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft coco: Common objects in context. In Proceedings of the Computer Vision–ECCV 2014: 13th European Conference, Zurich, Switzerland, 6–12 September 2014; Proceedings, Part V 13. pp. 740–755. [Google Scholar] [CrossRef]
- Chen, K.; Wang, J.; Pang, J.; Cao, Y.; Xiong, Y.; Li, X.; Sun, S.; Feng, W.; Liu, Z.; Xu, J. MMDetection: Open mmlab detection toolbox and benchmark. arXiv 2019, arXiv:1906.07155. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar] [CrossRef]







| Stage 1 | Stage 2 | Stage 3 | Stage 4 | |||||
|---|---|---|---|---|---|---|---|---|
| C3 | 18.8 K | 31.5 | 115.7 K | 47.8 | 625.2 K | 64.3 | 1.4 M | 21.6 |
| D2C3 | 50.1 K | 67.3 | 240.5 K | 68.6 | 999.1 K | 57.2 | 1.2 M | 30.4 |
| D3C3 | 16.7 K | 16.7 | 96.6 K | 39.9 | 503.2 K | 51.7 | 1.0 M | 26.1 |
| Classes | Sample | Train Labels | Val Labels | Classes | Sample | Train Labels | Val Labels |
|---|---|---|---|---|---|---|---|
| eryth |  | 22,731 | 6065 | cast |  | 2673 | 646 |
| leuko |  | 6171 | 1525 | pcast |  | 717 | 205 |
| leukoc |  | 573 | 153 | epith |  | 7035 | 1562 |
| mycete |  | 939 | 227 | epithn |  | 336 | 117 |
| cryst |  | 2605 | 664 | sperm |  | 108 | 25 |
| yeast |  | 2560 | 559 |
| Class | LPIPS | Samples |
|---|---|---|
| epith | 0.505 |  |
| pcast | 0.497 |  |
| sperm | 0.496 |  |
| cast | 0.474 |  |
| mycete | 0.415 |  |
| epithn | 0.407 |  |
| yeast | 0.396 |  |
| Method | FPS | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| YOLOv5s | |||||||||
| +PSA | |||||||||
| +DYB | |||||||||
| +ALL |
| Expansion Strategy | Number of Positive Samples | Total Number of Positive Samples | ||
|---|---|---|---|---|
| Detection Layer 1 | Detection Layer 2 | Detection Layer 3 | ||
| Inital | 3,273,436 | 4,264,833 | 3,136,284 | 10,674,553 |
| PSA Additional rate | 3,437,983 +5.03% | 4,474,331 +4.91% | 3,291,197 +4.94% | 11,203,511 +4.96% |
| I + J | ||||||||
|---|---|---|---|---|---|---|---|---|
| - | ||||||||
| 0 + 4 | ||||||||
| 1 + 3 | ||||||||
| 2 + 2 | ||||||||
| 3 + 1 (*) | ||||||||
| 4 + 0 |
| Size | |||||||||
|---|---|---|---|---|---|---|---|---|---|
| [608, 608] | |||||||||
| [1333, 800] | 48.6 | ||||||||
| [1333, 800] | |||||||||
| [1024, 1024] | |||||||||
| [640, 640] | |||||||||
| [512, 512] | |||||||||
| [640, 640] | |||||||||
| [640, 640] |
| Pcast | Epithn | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| FCOS | |||||||||||
| 75.8 | |||||||||||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, C.; Wang, Q.; Qian, Y.; Hu, Y.; Xue, Y.; Wang, H. DP-YOLO: Effective Improvement Based on YOLO Detector. Appl. Sci. 2023, 13, 11676. https://doi.org/10.3390/app132111676
Wang C, Wang Q, Qian Y, Hu Y, Xue Y, Wang H. DP-YOLO: Effective Improvement Based on YOLO Detector. Applied Sciences. 2023; 13(21):11676. https://doi.org/10.3390/app132111676
Chicago/Turabian StyleWang, Chao, Qijin Wang, Yu Qian, Yating Hu, Ying Xue, and Hongqiang Wang. 2023. "DP-YOLO: Effective Improvement Based on YOLO Detector" Applied Sciences 13, no. 21: 11676. https://doi.org/10.3390/app132111676