
A Deep Transfer Learning-Based Network for Diagnosing Minor Faults in the Production of Wireless Chargers

Abstract
:1. Introduction
2. Basic Theory
2.1. CNN and LSTM
2.2. MMD-Based TL
3. The Proposed Methodology
3.1. DNN Construction-Based Deep Learning
3.1.1. Raw Data Pre-Processing
3.1.2. Design DNN Construction
3.2. Transfer from to
3.2.1. Transfer of Network Parameters
3.2.2. Domain Adaptation
3.2.3. Weighted Voting for Kernel MMD Selection
3.3. Transfer of Softmax Layer Parameters
3.4. Model Evaluation
4. Experiment Verification
4.1. Experimental Platform Construction and Data Description
4.2. Experimental Results
4.2.1. Comparison without Transfer with Individual Models
4.2.2. Comparison with Other Models with Transfer
4.3. Experiment Analysis
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Nomenclature
| DL | deep learning |
| SAE | stacked auto-encoder |
| DTLCL | a transfer-based deep neural network |
| MTL | model-based transfer learning |
| DNN | deep neural network |
| DTN | deep transfer network |
| MMD | maximum mean discrepancy |
| SAE | stacked auto-encoder |
| CNN | convolutional neural network |
| DBN | deep belief network |
| RNN | recurrent neural network |
| LSTM | long short-term memory |
| ML | machine learning |
| SVM | support vector machine |
| LR | logistic regression |
| k-NN | k-nearest neighbour |
| DDA | deep domain adaptation |
| WV | weighted voting |
| TL | transfer learning |
| ITL | instance-based transfer learning |
| FTL | feature-based transfer learning |
| MTL | model-based transfer learning |
| RTL | relation-based transfer learning |
| DNN | deep neural network |
| DDA | deep domain adaptation |
| source domain | |
| target domain | |
| source domain dataset | |
| the total number of samples | |
| y | actual label |
| the ith sample | |
| p | the dimensionality of the sample |
| target domain dataset without label | |
| the total number of the sample | |
| the jth sample | |
| the kernel | |
| DNNs | the model of significant faults |
| DNNt | the model of minor faults |
| the training dataset with many significant fault samples | |
| the training dataset with only a few minor fault samples | |
| min–max mormalization | |
| x | the pre-conversion value |
| the converted value | |
| the maximum value of the original data | |
| the minimum value of the original data | |
| SMOTE | synthetic minority oversampling technique |
| the number of neurons in the jth hidden layer of the | |
| the training dataset from significant fault. | |
| the initial set of parameters for the network | |
| the set of parameters of the weight matrix and bias of the input layer | |
| . | layer-by-layer training updates parameters |
| abstract features | |
| the comprehensive evaluation index for single CNN model training | |
| the comprehensive evaluation index for single LSTM model training | |
| TP | true positive |
| FP | false positive |
| FN | false negative |
| parameter of softmax from | |
| parameter of softmax from | |
| random initialization | |
| P | precision |
| R | recall |
| F | comprehensive index |
| CWRU | Case Western Reserve University |
| N | normal fault |
| OF | outer circle fault |
| GPF | gear pitting fault |
| IF | inner circle fault |
| GBTF | gear broken tooth fault |
| RF | rolling element fault |
References
- Wang, G.; Zhao, G.; Xie, J.; Liu, K. Ensemble Learning Based Correlation Coefficient Method for Robust Diagnosis of Voltage Sensor and Short-Circuit Faults in Series Battery Packs. IEEE Trans. Power Electron. 2023, 38, 9143–9156. [Google Scholar] [CrossRef]
- Shahapure, S.B.; Kulkarni, V.A.; Shinde, S.M. A Technology Review of Energy Storage Systems, Battery Charging Methods and Market Analysis of EV Based on Electric Drives. Int. J. Electr. Electron. Res. 2022, 10, 23–35. [Google Scholar] [CrossRef]
- Dong, Y.; Lu, W.; Chen, H. Optimization Study for Lateral Offset Tolerance of Electric Vehicles Dynamic Wireless Charging. IEEJ Trans. Electr. Electron. Eng. 2020, 15, 1219–1229. [Google Scholar] [CrossRef]
- Feng, H.; Tavakoli, R.; Onar, O.C.; Pantic, Z. Advances in High-Power Wireless Charging Systems: Overview and Design Considerations. IEEE Trans. Transp. Electrif. 2020, 6, 886–919. [Google Scholar] [CrossRef]
- Jia, F.; Lei, Y.; Lin, J.; Zhou, X.; Lu, N. Deep neural networks: A promising tool for fault characteristic mining and intelligent diagnosis of rotating machinery with massive data. Mech. Syst. Signal Process. 2016, 72–73, 303–315. [Google Scholar] [CrossRef]
- Shao, H.; Jiang, H.; Wang, F.; Zhao, H. An enhancement deep feature fusion method for rotating machinery fault diagnosis. Knowl.-Based Syst. 2017, 119, 200–220. [Google Scholar] [CrossRef]
- Chen, Z.; Deng, S.; Chen, X.; Li, C.; Sanchez, R.-V.; Qin, H. Deep neural networks-based rolling bearing fault diagnosis. Microelectron. Reliab. 2017, 75, 327–333. [Google Scholar] [CrossRef]
- Li, C.; Sánchez, R.-V.; Zurita, G.; Cerrada, M.; Cabrera, D. Fault Diagnosis for Rotating Machinery Using Vibration Measurement Deep Statistical Feature Learning. Sensors 2016, 16, 895. [Google Scholar] [CrossRef]
- Shao, H.; Jiang, H.; Zhang, X.; Niu, M. Rolling bearing fault diagnosis using an optimization deep belief network. Meas. Sci. Technol. 2015, 26, 115002. [Google Scholar] [CrossRef]
- Janssens, O.; Slavkovikj, V.; Vervisch, B.; Stockman, K.; Loccufier, M.; Verstockt, S.; Van de Walle, R.; Van Hoecke, S. Convolutional Neural Network Based Fault Detection for Rotating Machinery. J. Sound Vib. 2016, 377, 331–345. [Google Scholar] [CrossRef]
- Guo, X.; Chen, L.; Shen, C. Hierarchical adaptive deep convolution neural network and its application to bearing fault diagnosis. Measurement 2016, 93, 490–502. [Google Scholar] [CrossRef]
- Hu, Y.; Wang, Y.; Wang, H. A decoding method based on RNN for OvTDM. China Commun. 2020, 17, 1–10. [Google Scholar] [CrossRef]
- Zhuang, F.; Qi, Z.; Duan, K.; Xi, D.; Zhu, Y.; Zhu, H.; Xiong, H.; He, Q. A Comprehensive Survey on Transfer Learning. Proc. IEEE 2021, 109, 43–76. [Google Scholar] [CrossRef]
- Bi, J.; Lee, J.-C.; Liu, H. Performance Comparison of Long Short-Term Memory and a Temporal Convolutional Network for State of Health Estimation of a Lithium-Ion Battery Using Its Charging Characteristics. Energies 2022, 15, 2448. [Google Scholar] [CrossRef]
- Kathigi, A.; Krishnappa, H.K. Handwritten Character Recognition Using Unsupervised Feature Selection and Multi Support Vector Machine Classifier. Int. J. Intell. Eng. Syst. 2021, 14, 290–300. [Google Scholar] [CrossRef]
- Lee, J.M. Fast k-Nearest Neighbor Searching in Static Objects. Wirel. Pers. Commun. 2017, 93, 147–160. [Google Scholar] [CrossRef]
- Liu, K.; Peng, Q.; Teodorescu, R.; Foley, A.M. Knowledge-Guided Data-Driven Model with Transfer Concept for Battery Calendar Ageing Trajectory Prediction. IEEE/CAA J. Autom. Sin. 2023, 10, 272–274. [Google Scholar] [CrossRef]
- Liu, K.; Peng, Q.; Che, Y.; Zheng, Y.; Li, K.; Teodorescu, R.; Widanage, D.; Barai, A. Transfer learning for battery smarter state estimation and ageing prognostics: Recent progress, challenges, and prospects. Adv. Appl. Energy 2023, 9, 100117. [Google Scholar] [CrossRef]
- Choudhry, A.; Khatri, I.; Jain, M.; Vishwakarma, D.K. An Emotion-Aware Multitask Approach to Fake News and Rumour Detection using Transfer Learning. IEEE Trans. Comput. Soc. Syst. 2022; early access. [Google Scholar]
- Peng, Q.; Liu, W.; Zhang, Y.; Zeng, S.; Graham, B. Generation planning for power companies with hybrid production technologies under multiple renewable energy policies. Renew. Sustain. Energy Rev. 2023, 176, 113209. [Google Scholar] [CrossRef]
- Zhu, Y.; Zhuang, F.; Wang, J.; Chen, J.; Shi, Z.; Wu, W.; He, Q. Multi-representation adaptation network for cross-domain image classification. Neural Netw. 2019, 119, 214–221. [Google Scholar] [CrossRef]
- Lin, W.; Mak, M.-W.; Li, L.; Chien, J.-T. Reducing Domain Mismatch by Maximum Mean Discrepancy Based Autoencoders. In Proceedings of the Speaker and Language Recognition Workshop (Odyssey 2018), Les Sables d’Olonne, France, 26–29 June 2018. [Google Scholar] [CrossRef]
- Sapkota, U.; Solorio, T.; Montes, M.; Bethard, S. Domain Adaptation for Authorship Attribution: Improved Structural Correspondence Learning. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Berlin, Germany, 7–12 August 2016. [Google Scholar] [CrossRef]
- Sanodiya, R.K.; Mishra, S.; Arun, P.V. Manifold embedded joint geometrical and statistical alignment for visual domain adaptation. Knowl.-Based Syst. 2022, 257, 109886. [Google Scholar] [CrossRef]
- Li, Y.; Zheng, H.; Zhu, H.; Ai, H.; Dong, X. Cross-People Mobile-Phone Based Airwriting Character Recognition. In Proceedings of the 25th International Conference on Pattern Recognition (ICPR), Milan, Italy, 10–15 January 2021. [Google Scholar] [CrossRef]
- Davis, J.; Domingos, P. Deep Transfer: A Markov Logic Approach. AI Mag. 2011, 32, 51–53. [Google Scholar] [CrossRef]
- Ganin, Y.; Ustinova, E.; Ajakan, H.; Germain, P.; Larochelle, H.; Laviolette, F.; Marchand, M.; Lempitsky, V. Domain-Adversarial Training of Neural Networks. In Domain Adaptation in Computer Vision Applications; Advances in Computer Vision and Pattern Recognition; Springer: Cham, Switzerland, 2017; pp. 189–209. [Google Scholar] [CrossRef]
- Bousmalis, K.; Trigeorgis, G.; Silberman, N.; Krishnan, D.; Erhan, D. Domain Separation Networks. arXiv 2016, arXiv:1608.06019. [Google Scholar]
- Chen, D.; Yang, S.; Zhou, F. Transfer Learning Based Fault Diagnosis with Missing Data Due to Multi-Rate Sampling. Sensors 2019, 19, 1826. [Google Scholar] [CrossRef] [PubMed]
- Han, T.; Liu, C.; Yang, W.; Jiang, D. Learning transferable features in deep convolutional neural networks for diagnosing unseen machine conditions. ISA Trans. 2019, 93, 341–353. [Google Scholar] [CrossRef]
- Shukla, V.; Choudhary, S. Deep Learning in Neural Networks: An Overview. In Deep Learning in Visual Computing and Signal Processing; Apple Academic Press: Palm Bay, FL, USA, 2022; pp. 29–53. [Google Scholar] [CrossRef]
- Long, M.; Wang, J.; Cao, Y.; Sun, J.; Yu, P.S. Deep Learning of Transferable Representation for Scalable Domain Adaptation. IEEE Trans. Knowl. Data Eng. 2016, 28, 2027–2040. [Google Scholar] [CrossRef]
- Jwa, H.; Oh, D.; Park, K.; Kang, J.; Lim, H. exBAKE: Automatic Fake News Detection Model Based on Bidirectional Encoder Representations from Transformers (BERT). Appl. Sci. 2019, 9, 4062. [Google Scholar] [CrossRef]
- Sahoo, S.R.; Gupta, B.B. Multiple features based approach for automatic fake news detection on social networks using deep learning. Appl. Soft Comput. 2021, 100, 106983. [Google Scholar] [CrossRef]
- Azamfar, M.; Li, X.; Lee, J. Intelligent ball screw fault diagnosis using a deep domain adaptation methodology. Mech. Mach. Theory 2020, 151, 103932. [Google Scholar] [CrossRef]
- Guo, L.; Lei, Y.; Xing, S.; Yan, T.; Li, N. Deep Convolutional Transfer Learning Network: A New Method for Intelligent Fault Diagnosis of Machines with Unlabeled Data. IEEE Trans. Ind. Electron. 2019, 66, 7316–7325. [Google Scholar] [CrossRef]
- Xie, Y.; Zhao, J.; Qiang, B.; Mi, L.; Tang, C.; Li, L. Attention Mechanism-Based CNN-LSTM Model for Wind Turbine Fault Prediction Using SSN Ontology Annotation. Wirel. Commun. Mob. Comput. 2021, 2021, 6627588. [Google Scholar] [CrossRef]
- He, Z.; Shao, H.; Zhang, X.; Cheng, J.; Yang, Y. Improved Deep Transfer Auto-Encoder for Fault Diagnosis of Gearbox Under Variable Working Conditions with Small Training Samples. IEEE Access 2019, 7, 115368–115377. [Google Scholar] [CrossRef]
- Hemalatha, P.; Amalanathan, G.M. FG-SMOTE: Fuzzy-based Gaussian synthetic minority oversampling with deep belief networks classifier for skewed class distribution. Int. J. Intell. Comput. Cybern. 2021, 14, 270–287. [Google Scholar] [CrossRef]
- Li, J.; Zhu, Q.; Wu, Q.; Fan, Z. A novel oversampling technique for class-imbalanced learning based on SMOTE and natural neighbors. Inf. Sci. 2021, 565, 438–455. [Google Scholar] [CrossRef]
- Chakraborty, D.; Narayanan, V.; Ghosh, A. Integration of deep feature extraction and ensemble learning for outlier detection. Pattern Recognit. 2019, 89, 161–171. [Google Scholar] [CrossRef]
- Ma, S.; Chu, F. Ensemble deep learning-based fault diagnosis of rotor bearing systems. Comput. Ind. 2019, 105, 143–152. [Google Scholar] [CrossRef]
- Wang, Z.-Y.; Lu, C.; Zhou, B. Fault diagnosis for rotary machinery with selective ensemble neural networks. Mech. Syst. Signal Process. 2018, 113, 112–130. [Google Scholar] [CrossRef]
- Shao, H.; Jiang, H.; Lin, Y.; Li, X. A novel method for intelligent fault diagnosis of rolling bearings using ensemble deep auto-encoders. Mech. Syst. Signal Process. 2018, 102, 278–297. [Google Scholar] [CrossRef]
- Case Western Reserve University, Bearing Data Center. Available online: https://engineering.case.edu/bearingdatacenter/download-data-file (accessed on 23 September 2020).
- Machine Heart Technology Co., Ltd. Available online: https://sota.jiqizhixin.com/implements/facebookresearch-mmbt_mmbt (accessed on 1 June 2021).
- Machine Heart Technology Co., Ltd. Available online: https://sota.jiqizhixin.com/implements/huggingface-distilbert_transformers (accessed on 6 August 2023).














{kind=link}
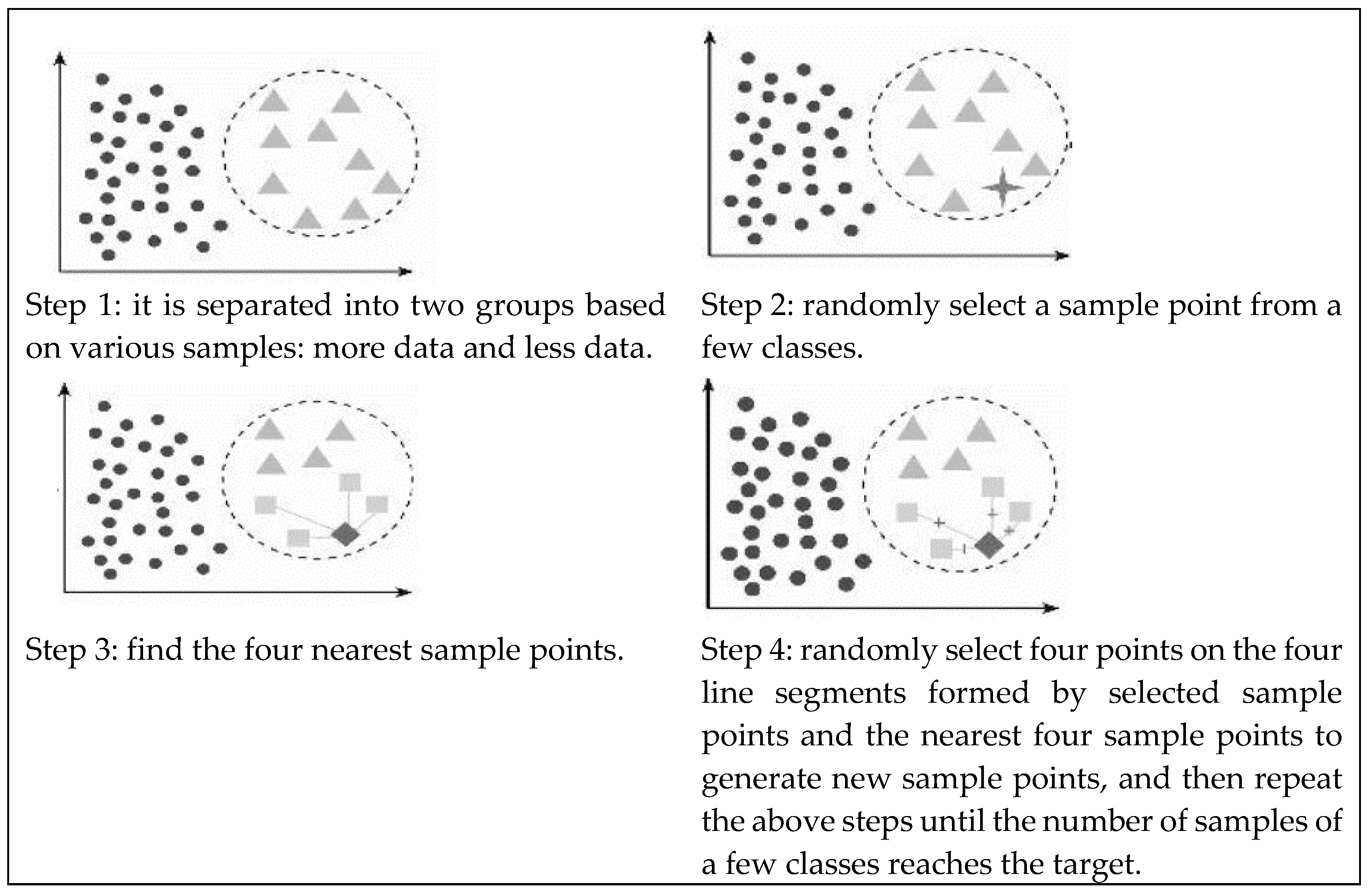{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
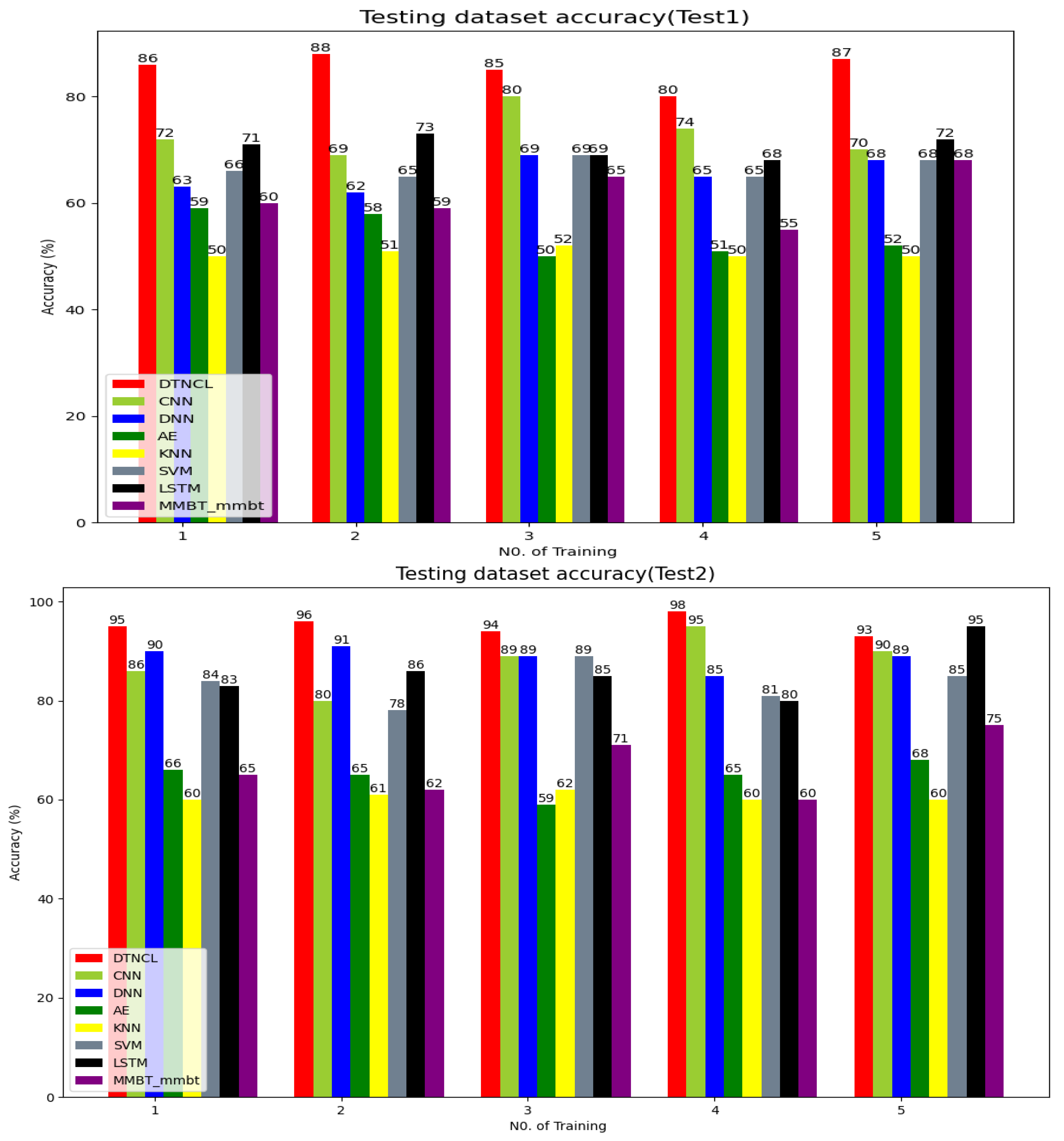{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Layers | Parameters | Activation | Output Size |
|---|---|---|---|
| Input | / | / | (None, 2048, 1) |
| conv1D | Filters:16, kernel_size: 64, strides: 16 | relu | (None, 128, 16) |
| BatchNormalization | / | / | (None, 128, 16) |
| MaxPooling1D | pool_size: 2 | relu | (None, 64, 16) |
| conv1D | Filter: 16, kernel_size: 64, strides: 16 | relu | (None, 64, 32) |
| BatchNormalization | / | / | (None, 64, 32) |
| MaxPooling1D | pool_size: 2 | relu | (None, 32, 32) |
| conv1D | Filters: 16, kernel_size: 64,strides: 16 | relu | (None, 32, 32) |
| BatchNormalization | / | / | (None, 32, 32) |
| MaxPooling1D | pool_size: 2 | relu | (None, 16, 32) |
| LSTM | recurrent_activation: hard_sigmoid | tanh | (None, 16, 32) |
| Flatten | / | / | (None, 512) |
| Dropout | 0.3 | (None, 512) | |
| Dense1 | / | relu | (None, 256) |
| Dense2 | / | relu | (None, 128) |
| Dense3 | / | relu | (None, 32) |
| Classifier | kernel_regularizer: l1(1 × 10−4) | softmax | (None, 4) |
| Dataset | Load/hp | Speed of Rotation/RPM | Fault Conditions | Samples Size |
|---|---|---|---|---|
| A | 0/1/2/3 | 1797/1772 1750/1730 | N/RF//IF/OF | 1200 × 4 |
| B | 0/1/2 | 500/1000/1425 | N/RF/IF/OF GPF/GBTF | 200 × 6 |
| Model | Hyper-Parameters | Iterations |
|---|---|---|
| CNN | structure: (2048, 1) (128, 32) (64, 32) (2048) (100) (6) | 1000 |
| LSTM | structure: (2048, 1) (2048, 32) (65,536) (32) (32) (6) | 1000 |
| AE | encoder: 2048-128-32-6; decoder 6-32-128-2048 | 1000 |
| KNN | n_neighbors: 5; p = 1; weight: uniform; leaf_size: 30 | / |
| SVM | Cache size: 200, degree: 3 C:1.1 | / |
| DTLCL | structure: (2048, 1) (128, 16) (64, 16) (64, 32) (32, 32) (32, 32) (16, 32) (16, 32) (512) (512) (32) (32) (6) | 1000 |
| DTLCL_A | structure: (2048, 1) (128, 16) (64, 16) (64, 32) (32, 32) (32, 32) (16, 32) (512) (512) (32) (32) (6) | 1000 |
| DTLCL_B | structure: (2048, 1)-(16, 32)-512-512-32-32-6 | 1000 |
| Working Condition | Significant Fault | Minor Fault |
|---|---|---|
| Load (hp) | 1 | 2 |
| Speed (rpm) | 1750 | 1000 |
| Fault size (inch) | 0.021 | 0.0036 |
| Status type | 4 (NRF, IF, OF) | 6 (N, RF, IF, OF, GPF, GBTF) |
| Test | Model | Accuracy of Training/Loss | Accuracy of Validation/Loss | Accuracy of Testing/Loss | Time of Training |
|---|---|---|---|---|---|
| Test1 | DTLCL | (0.884 ± 0.52)/0.42 | (0.876 ± 0.43)/0.43 | (0.885 ± 0.55)/0.43 | 18 s |
| CNN | (0.786 ± 0.63)/0.64 | (0.731 ± 0.72)/1.66 | (0.723 ± 0.64)/1.78 | 22 s | |
| LSTM | (0767 ± 0.51)/1.52 | (0.728 ± 0.62)/1.54 | (0.707 ± 0.62)/1.53 | 26 s | |
| DNN | (0.602 ± 3.52)/1.57 | (0.634 ± 3.52)/1.64 | (0.645 ± 3.54)/1.47 | 35 s | |
| AE | (0.540 ± 3.52)/0.75 | (0.562 ± 3.87)/1.44 | (0.524 ± 3.72)/1.23 | 24 s | |
| KNN | (0.552 ± 1.22) | (0.541 ± 1.29) | (0.506 ± 1.32) | 107 s | |
| SVM | (0.679 ± 3.82) | (0.651 ± 3.38) | (0.661 ± 3.38) | 19 s | |
| DTLCL _A | (0.802 ± 0.41)/0.61 | (0.798 ± 0.51)/0.58 | (0.805 ± 0.45)/0.54 | 17 s | |
| DTLCL _B | (0.791 ± 0.58)/0.52 | (0.787 ± 0.64)/0.53 | (0.784 ± 0.55)/0.57 | 16 s | |
| MMBT_mmbt | (0.754 ± 0.51)/1.43 | (0.713 ± 0.63)/1.48 | (0.718 ± 0.60)/1.52 | 25 s | |
| Test2 | DTLCL | (0.953 ± 0.32)/0.38 | (0.946 ± 0.33)/0.36 | (0.945 ± 0.34)/0.37 | 19 s |
| CNN | (0.886 ± 0.43)/0.58 | (0.872 ± 0.41)/1.32 | (0.877 ± 0.43)/1.22 | 23 s | |
| LSTM | (0854 ± 0.51)/0.62 | (0.824 ± 0.52)/1.48 | (0.835 ± 0.54)/1.37 | 30 s | |
| DNN | (0.872 ± 2.50)/1.23 | (0.874 ± 2.54)/1.35 | (0.885 ± 2.51)/1.33 | 39 s | |
| AE | (0.630 ± 3.42)/0.52 | (0.664 ± 3.37)/1.12 | (0.654 ± 3.22)/1.01 | 27 s | |
| KNN | (0.652 ± 1.01) | (0.641 ± 1.12) | (0.616 ± 1.28) | 118 s | |
| SVM | (0.859 ± 3.82) | (0.840 ± 3.38) | (0.841 ± 3.38) | 22 s | |
| DTLCL _A | (0.892 ± 0.41)/0.52 | (0.898 ± 0.51)/0.53 | (0.895 ± 0.45)/0.51 | 18 s | |
| DTLCL _B | (0.863 ± 0.58)/0.54 | (0.868 ± 0.64)/0.56 | (0.887 ± 0.55)/0.53 | 17 s | |
| MMBT_mmbt | (0.845 ± 0.54)/0.57 | (0.831 ± 0.52)/1.38 | (0.851 ± 0.53)/1.36 | 25 s |
| Test | Model | Accuracy of Training | Accuracy of Validation | Accuracy of Testing | Time of Training |
|---|---|---|---|---|---|
| Test 3 | DTLCL | 0.884 | 0.876 | 0.885 | 18 s |
| D-CORAL | 0.834 | 0.823 | 0.837 | 21 s | |
| DANN | 0.821 | 0.818 | 0.824 | 22 s | |
| TCNN | 0.882 | 0.841 | 0.843 | 19 s | |
| TAE | 0.580 | 0.562 | 0.524 | 22 s | |
| InceptionV3 | 0.612 | 0.651 | 0.557 | 27 s | |
| Xception | 0.729 | 0.749 | 0.732 | 17 s | |
| DistilBERT_transformers | 0.581 | 0.579 | 0.543 | 23 s | |
| Test 4 | DTLCL | 0.953 | 0.946 | 0.945 | 19 s |
| D-CORAL | 0.926 | 0.915 | 0.933 | 22 s | |
| DANN | 0.911 | 0.918 | 0.909 | 23 s | |
| TCNN | 0.956 | 0.923 | 0.934 | 20 s | |
| TAE | 0.734 | 0.781 | 0.752 | 24 s | |
| InceptionV3 | 0.754 | 0.702 | 0.715 | 28 s | |
| Xception | 0.871 | 0.865 | 0.864 | 17 s | |
| DistilBERT_transformers | 0.712 | 0.705 | 0.701 | 20 s |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, Y.; Li, W.; Zhu, H. A Deep Transfer Learning-Based Network for Diagnosing Minor Faults in the Production of Wireless Chargers. Appl. Sci. 2023, 13, 11514. https://doi.org/10.3390/app132011514
Wang Y, Li W, Zhu H. A Deep Transfer Learning-Based Network for Diagnosing Minor Faults in the Production of Wireless Chargers. Applied Sciences. 2023; 13(20):11514. https://doi.org/10.3390/app132011514
Chicago/Turabian StyleWang, Yuping, Weidong Li, and Honghui Zhu. 2023. "A Deep Transfer Learning-Based Network for Diagnosing Minor Faults in the Production of Wireless Chargers" Applied Sciences 13, no. 20: 11514. https://doi.org/10.3390/app132011514