
Target Localization and Grasping of Parallel Robots with Multi-Vision Based on Improved RANSAC Algorithm

Abstract
:1. Introduction
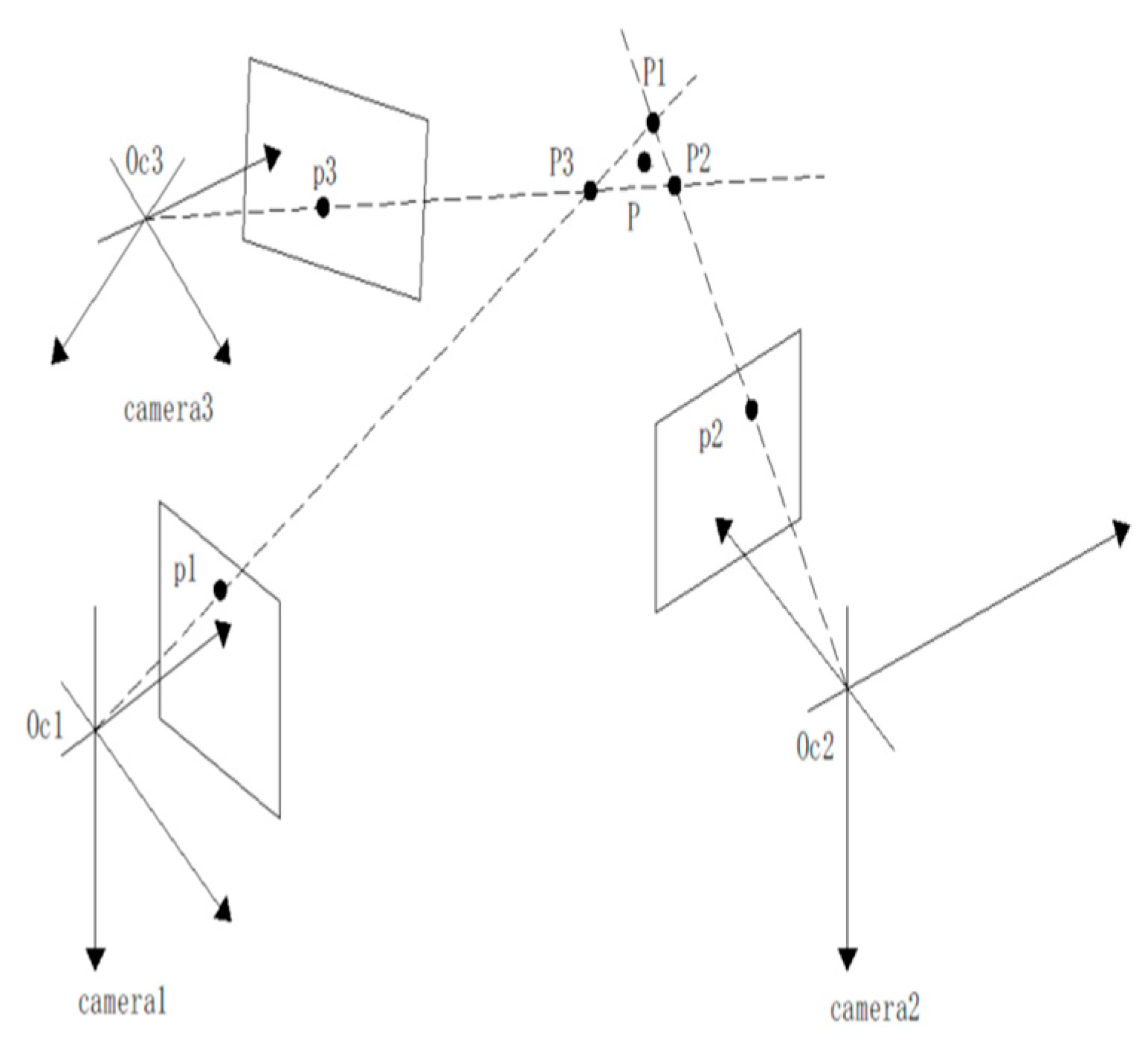
2. Trinocular Vision Model
2.1. Two-Dimensional Vision
2.2. Three-Dimensional Vision
3. Target Image Optimization Processing
3.1. Image Gray Scaling
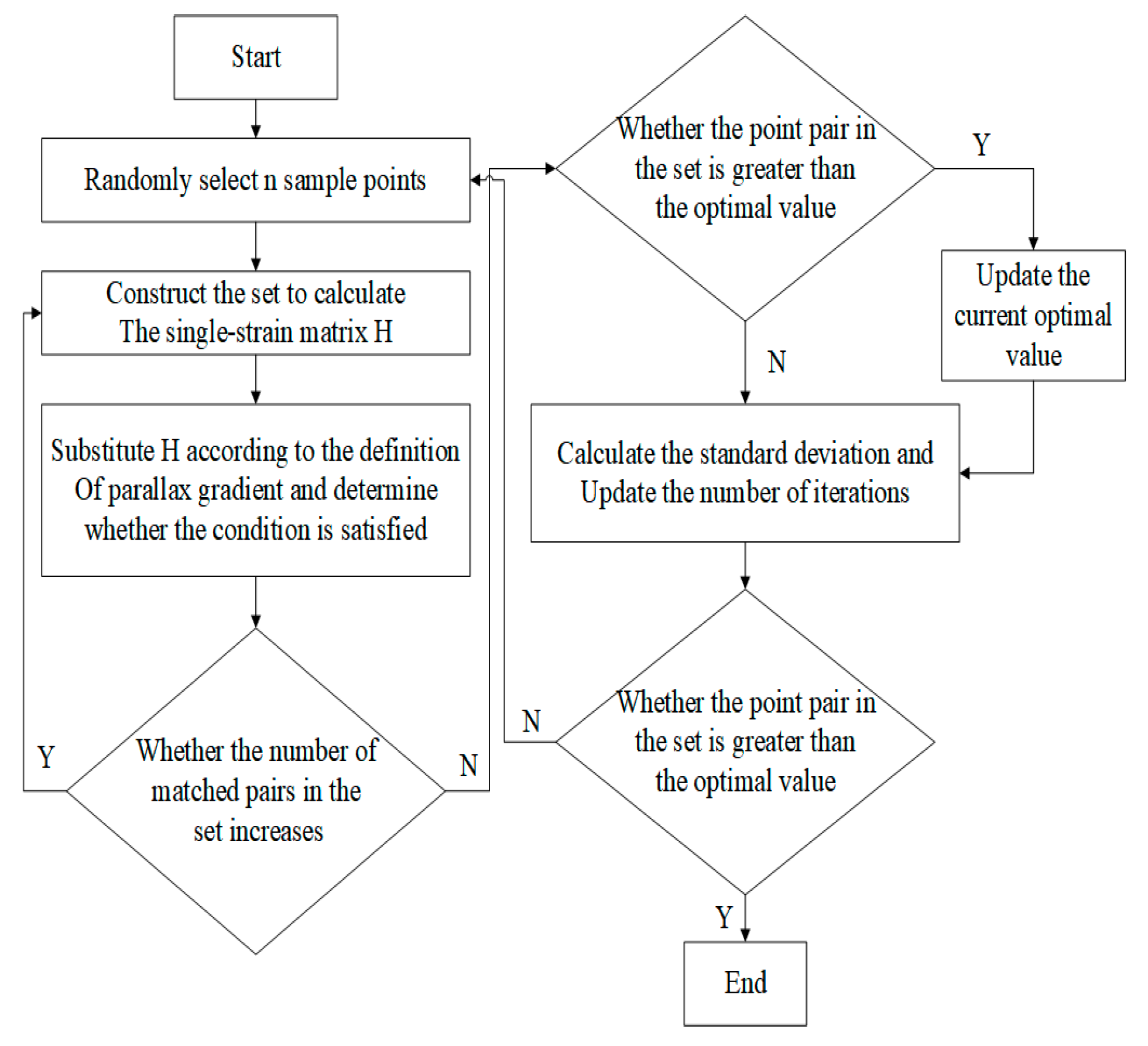
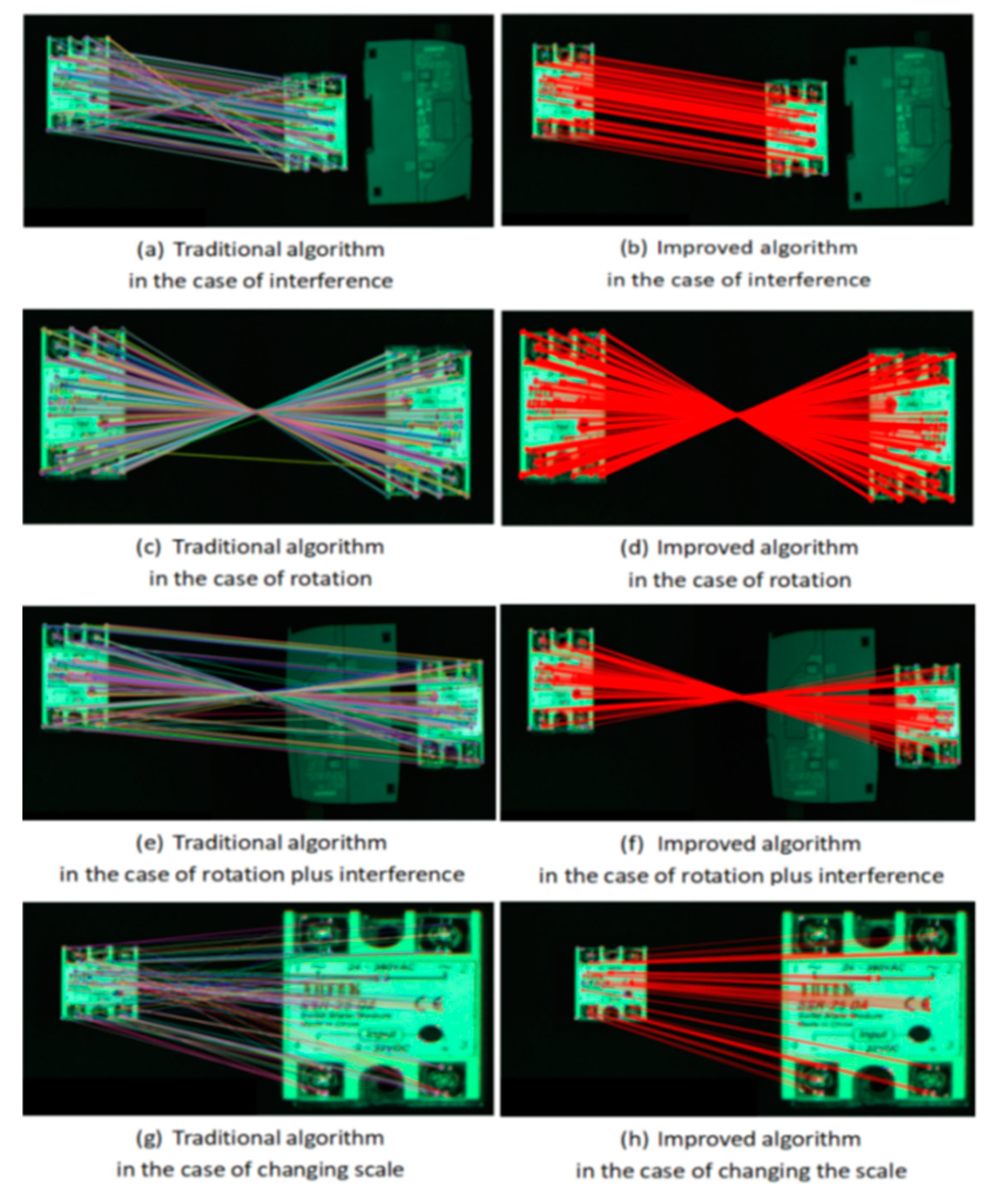
3.2. Improved RANSAC Algorithm
- (1)
- Traditional algorithm
- (2)
- Improved mis-matching algorithm
3.3. Three-Dimensional Reconstruction
4. Parallel Robot Gripping
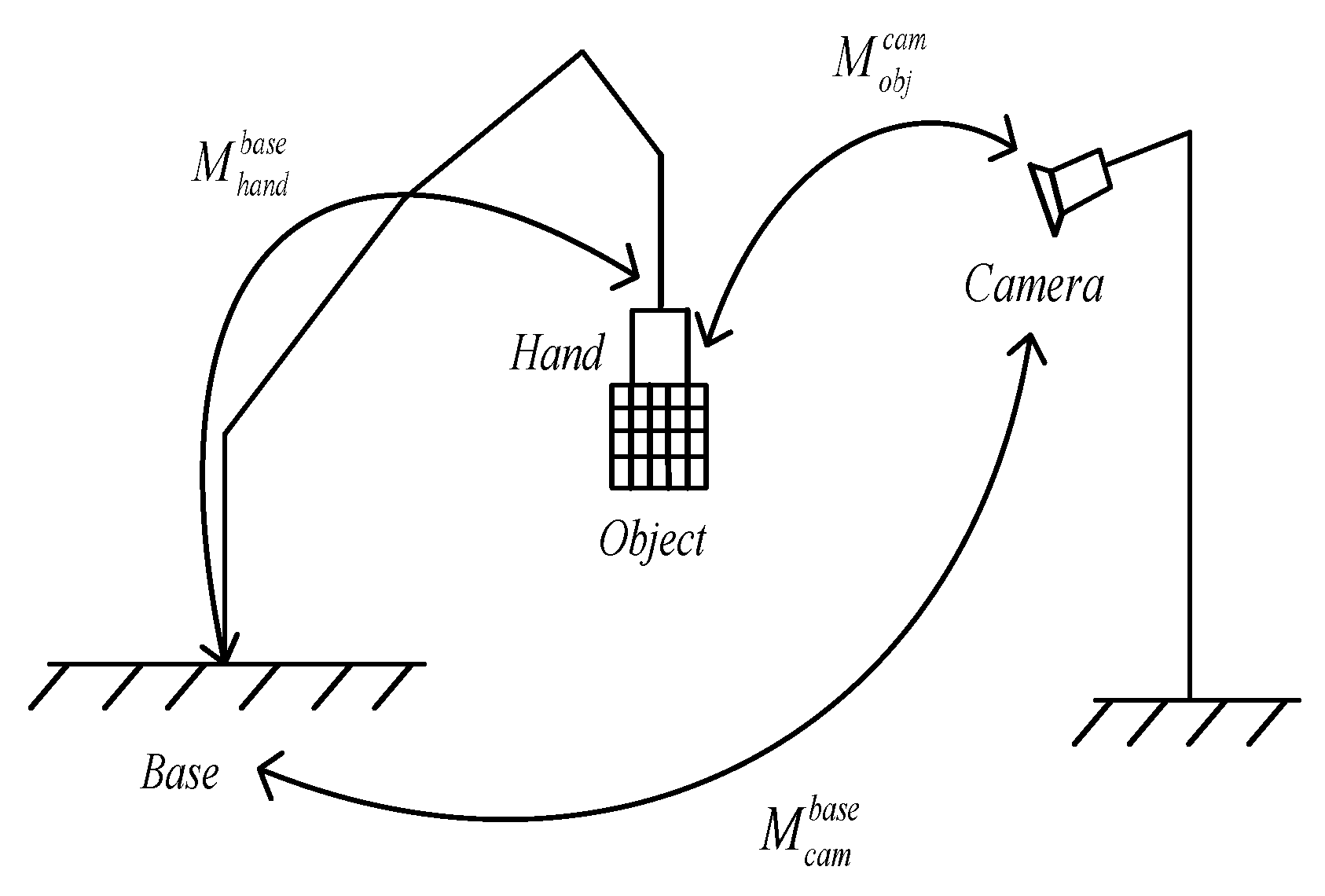
4.1. Hand–Eye Calibration
4.2. Positioning and Grasping Experiments
5. Discussion
6. Summary
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Chen, W.; Luo, X.; Liang, Z.; Li, C.; Wu, M.; Gao, Y.; Jia, X. A Unified Framework for Depth Prediction from a Single Image and Binocular Stereo Matching. Remote Sens. 2020, 12, 588. [Google Scholar] [CrossRef]
- Okutomi, M.; Kanade, T. A multiple-baseline stereo. IEEE Trans. Pattern Anal. Mach. Intell. 1993, 15, 353–363. [Google Scholar] [CrossRef]
- Yang, J.; Hua, Y. A SURF optimization algorithm applied to binocular ranging. Softw. Guide 2021, 20, 195–199. [Google Scholar]
- Lowe, D.G.; Lowe, D.G. Distinctive Image Features from Scale-Invariant Key-points. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Bay, H.; Tuytelaars, T.; Van Gool, L. SURF: Speeded up robust features. Comput. Vis. Image Underst. 2006, 110, 404–417. [Google Scholar]
- Kumar, G.K.; Shaik, M.F.; Kulkarni, V.; Busi, R. Power and Delay Efficient Haar Wavelet Transform for Image Processing Application. J. Circuits Syst. Comput. 2022, 31, 2220001. [Google Scholar] [CrossRef]
- Lin, P.D. Simple and practical approach for computing the ray Hessian matrix in geometrical optics. J. Opt. Soc. Am. 2018, 35, 210–220. [Google Scholar] [CrossRef] [PubMed]
- Huang, Y.; Yan, Z.; Jiang, X.; Jing, T.; Chen, S.; Lin, M.; Zhang, J.; Yan, X. Performance Enhanced Elemental Array Generation for Integral Image Display Using Pixel Fusion. Front. Phys. 2021, 9, 639117. [Google Scholar] [CrossRef]
- Cui, J.; Sun, C.; Li, Y.; Fu, L.; Wang, P. Improved algorithm for fast image matching based on SURF. J. Instrum. 2022, 43, 47–53. [Google Scholar]
- Yang, G.-X.; Wang, Y.-K.; Xie, Z.-M. Scene judgment enhanced SURF image matching algorithm. Surv. Mapp. Bull. 2022, S2, 233–236+259. [Google Scholar] [CrossRef]
- Sangappa, H.K.; Ramakrishnan, K.R. A probabilistic analysis of a common RANSAC heuristic. Mach. Vis. Appl. 2019, 30, 71–89. [Google Scholar] [CrossRef]
- Fischler, M.A.; Bolles, R.C. Random sample consensus: A paradigm for model fitting with applications to image analysis and automated cartography. Commun. ACM 1981, 24, 381–395. [Google Scholar] [CrossRef]
- Huang, H.-B.; Nie, X.-F.; Li, X.-L.; Zhang, Y.; Xiong, W.-Y. Research on bi-directional feature matching algorithm based on normalized Euclidean distance. Comput. Telecommun. 2018, 1, 35–40. [Google Scholar]
- Zhao, C.; Zhang, X.; Yang, Y. 3D reconstruction based on SGBM semi-global stereo matching algorithm. Laser J. 2021, 42, 139–143. [Google Scholar]
- Zhao, Z.; Weng, Y. A flexible method combining camera calibration and hand-eye calibration. Robotica 2013, 31, 747–756. [Google Scholar] [CrossRef]
- Sonka, M.; Hlavac, V.; Boyle, R. Image processing, analysis, and machine vision. J. Electron. Imaging 2014, XIX. [Google Scholar]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. ImageNet Large Scale Visual Recognition Challenge. Int. J. Comput. Vis. 2015, 115, 211–252. [Google Scholar] [CrossRef]
- Deng, G.; Wu, S.; Zhou, S.; Chen, B.; Liao, Y. A Robust Discontinuous Phase Unwrapping Based on Least-Squares Orientation Estimator. Electronics 2021, 10, 2871. [Google Scholar] [CrossRef]
- Lu, X. Research on Workpiece Positioning Technology Based on Binocular Stereo Vision; Zhejiang University: Hangzhou, China, 2019. [Google Scholar]
- Kang, J.; Chen, L.; Deng, F.; Heipke, C. Context pyramidal network for stereo matching regularized by disparity gradients. ISPRS J. Photogramm. Remote Sens. 2019, 157, 201–215. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Scenes | Algorithm | Total Number of Matched Pairs | Correctly Matching Logarithms | Correct Match Rate/% | Matching Time/s |
|---|---|---|---|---|---|
| Interference | SURF | 123 | 74 | 60.38 | 1.913 |
| Improvements | 96 | 93 | 97.32 | 1.482 | |
| Rotation | SURF | 138 | 109 | 78.75 | 1.620 |
| Improvements | 99 | 92 | 93.78 | 1.113 | |
| Rotation plus interference | SURF | 103 | 70 | 67.89 | 1.749 |
| Improvements | 92 | 89 | 96.98 | 0.948 | |
| Scale change | SURF | 113 | 87 | 77.32 | 1.561 |
| Improvements | 98 | 96 | 97.90 | 1.215 |
| Number of Experimental Groups (Groups) | SURF Algorithm Grabs Objects (pcs) | SURF Algorithm Crawl Accuracy (%) | Improvements to RANSAC Number of Catches (pcs) | Improvements to RANSAC Crawl Accuracy (%) |
|---|---|---|---|---|
| 1 | 20 | 71.43 | 25 | 89.29 |
| 2 | 21 | 75.00 | 27 | 96.43 |
| 3 | 18 | 64.28 | 27 | 96.43 |
| 4 | 22 | 78.57 | 26 | 92.86 |
| 5 | 20 | 71.43 | 26 | 92.86 |
| 6 | 19 | 67.85 | 25 | 89.29 |
| 7 | 22 | 78.57 | 26 | 92.86 |
| 8 | 23 | 82.14 | 27 | 96.43 |
| 9 | 20 | 71.43 | 27 | 96.43 |
| 10 | 22 | 78.57 | 25 | 89.29 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gao, R.; Li, Y.; Liu, Z.; Zhang, S. Target Localization and Grasping of Parallel Robots with Multi-Vision Based on Improved RANSAC Algorithm. Appl. Sci. 2023, 13, 11302. https://doi.org/10.3390/app132011302
Gao R, Li Y, Liu Z, Zhang S. Target Localization and Grasping of Parallel Robots with Multi-Vision Based on Improved RANSAC Algorithm. Applied Sciences. 2023; 13(20):11302. https://doi.org/10.3390/app132011302
Chicago/Turabian StyleGao, Ruizhen, Yang Li, Zhiqiang Liu, and Shuai Zhang. 2023. "Target Localization and Grasping of Parallel Robots with Multi-Vision Based on Improved RANSAC Algorithm" Applied Sciences 13, no. 20: 11302. https://doi.org/10.3390/app132011302