
Acceleration of Nuclear Reactor Simulation and Uncertainty Quantification Using Low-Precision Arithmetic

Abstract
:1. Introduction
2. Multiprecision Hardware
2.1. SIMD
2.2. Half-Precision
2.3. FPGA
2.4. Novel Data Types
2.5. Multiprecision Emulators
2.6. Multiprecision Analysis Tools
3. Numerical Results
- Code profiling;
- Uncertainty propagation;
- Multiprecision analysis;
- Multiprecision emulation;
- Speed-up evaluation.
3.1. Code Profiling
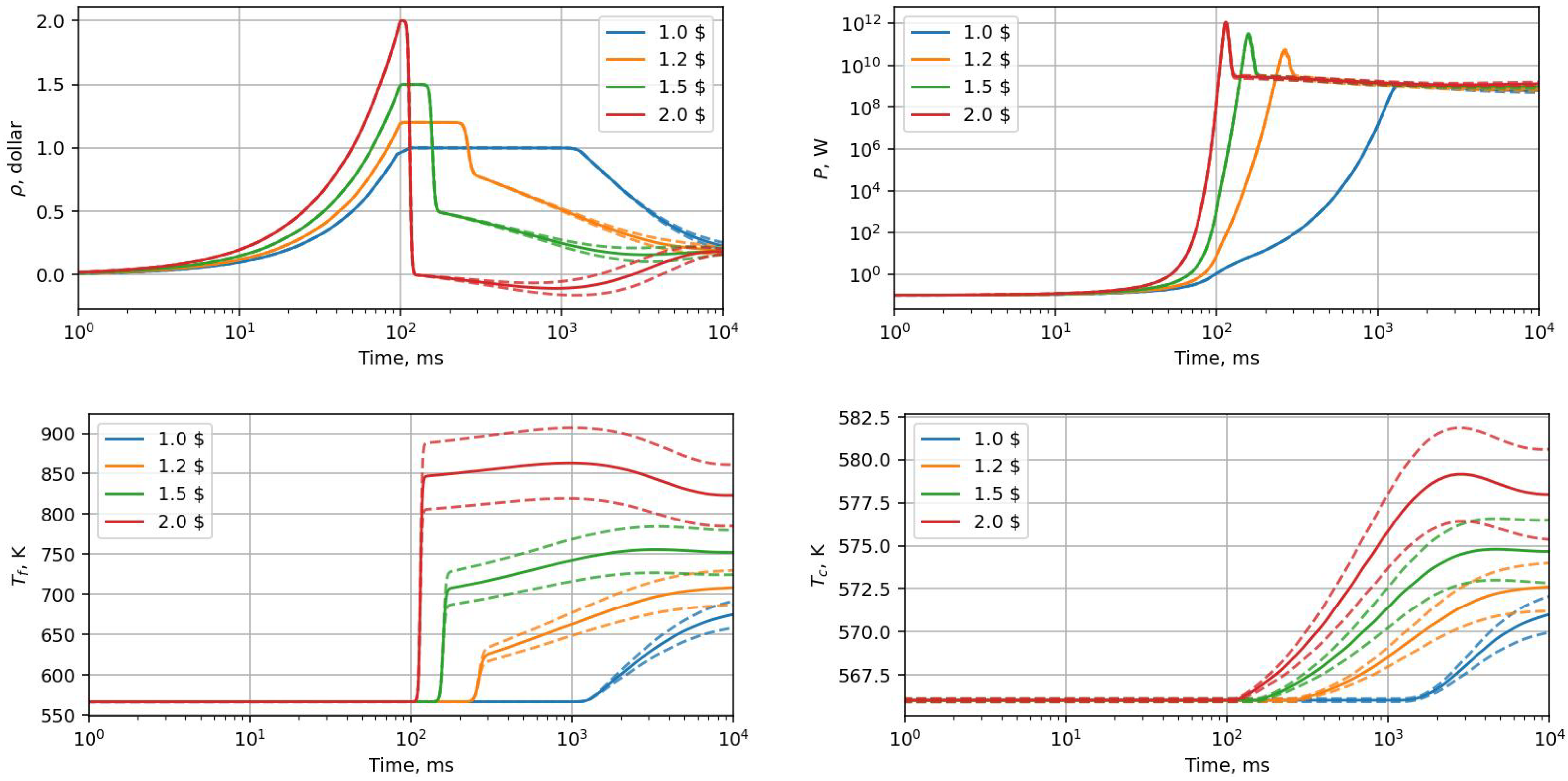
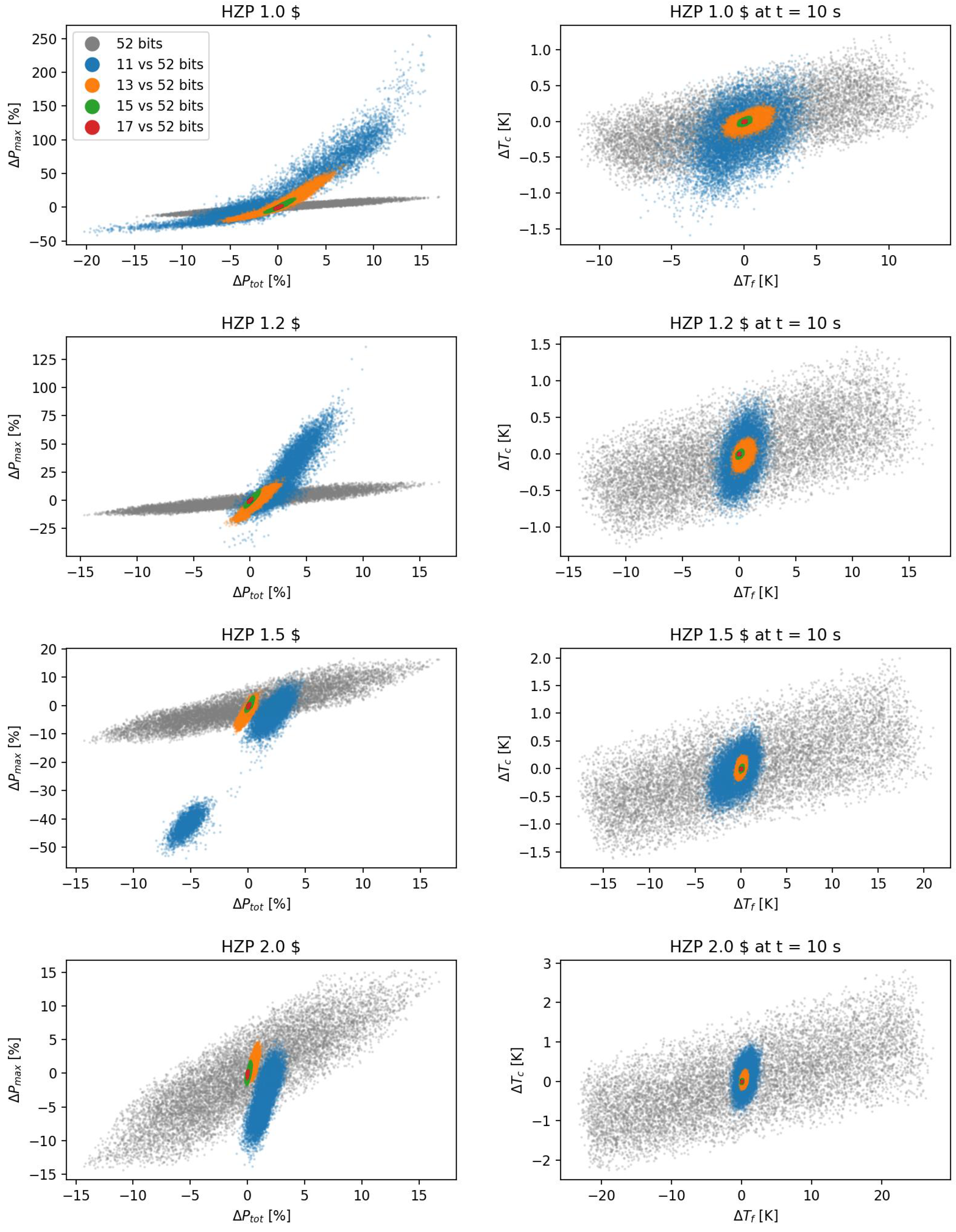
3.2. Uncertainty Propagation
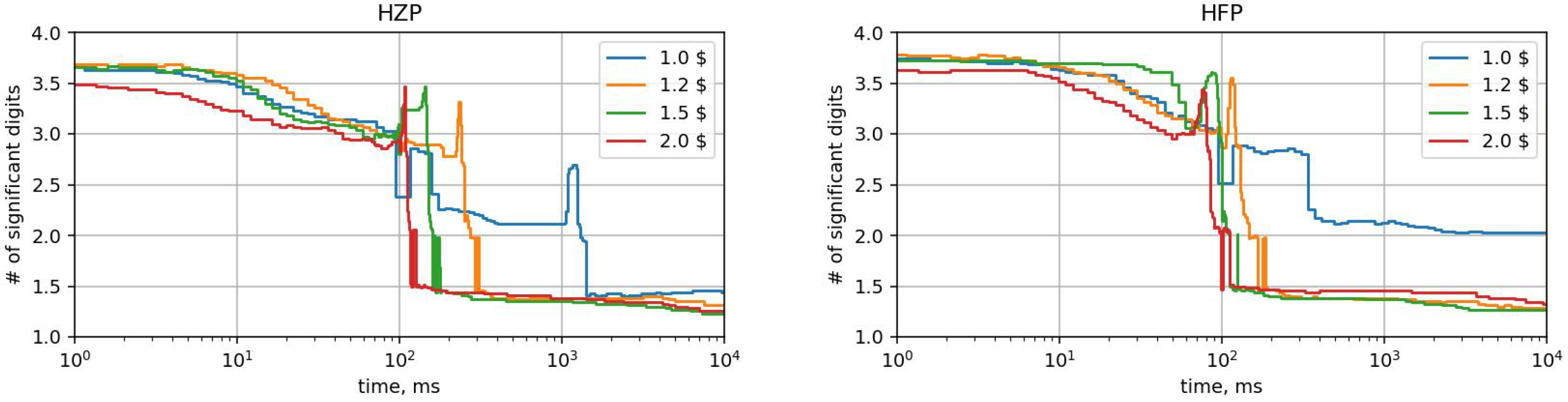
3.3. Multiprecision Analysis
3.4. Multiprecision Emulation
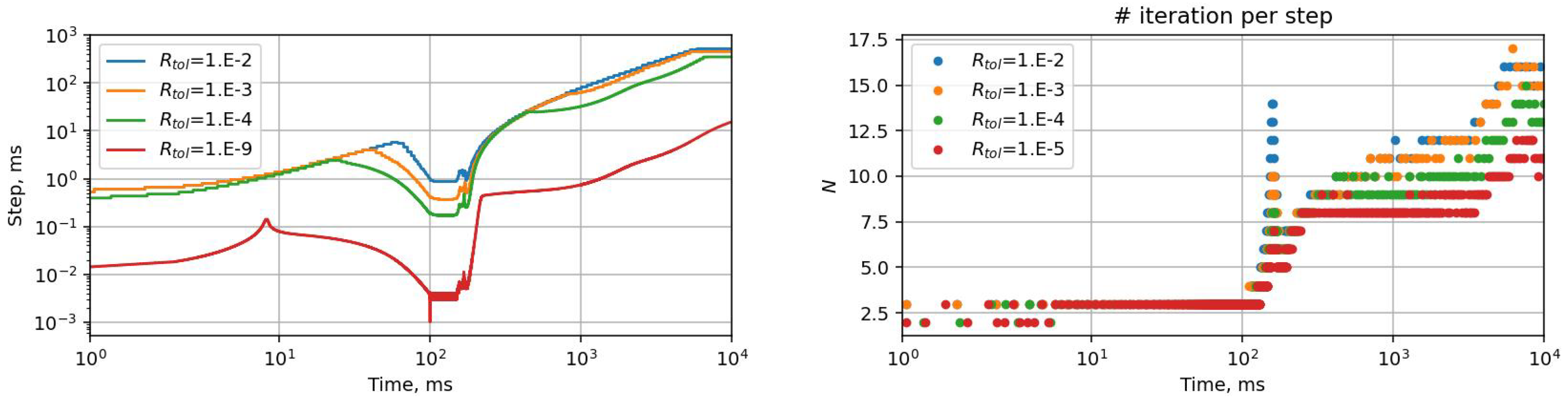
3.5. Speed-Up Evaluation
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Sample Availability
Abbreviations
| FPGA | Field-programmable gate array |
| PWR | Pressurized water reactor |
| RIA | Reactivity initiated accident |
| UQ | Uncertainty quantification |
Appendix A. IEEE-754 Standard

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| BF16 | FP16 | FP32 | FP64 | |
|---|---|---|---|---|
| Width | 16 | 16 | 32 | 64 |
| Significand | 8 | 10 | 23 | 52 |
| Exponent | 7 | 5 | 8 | 11 |
| Max | 3.38 | 6.55 | 3.40 | 1.79 |
| Min | 1.17 | 6.10 | 1.17 | 2.22 |
| eps | 3.06 | 9.76 | 1.19 | 2.22 |
Appendix B. Mathematical Model
| Par | Units | Value | Description | |
|---|---|---|---|---|
| W | 0.1 | Initial power | ||
| s | 10 | Mean generation time | ||
| t | 95 | Fuel mass | ||
| t | 15 | Coolant mass | ||
| J/kg K | 260 | 6 | Fuel heat capacity | |
| J/kg K | 5400 | 6 | Coolant heat capacity | |
| pcm/K | −5 | 9 | Doppler coefficient | |
| pcm/K | 1 | 9 | Coolant total temp/dens coefficient | |
| MW/K | 5.4 | 9 | Heat transfer × surface | |
| K | 566 | Inlet temperature | ||
| v | m/s | 5 | Coolant velocity |
| N | , | , pcm |
|---|---|---|
| 1 | 0.0127 | 26.6 |
| 2 | 0.0317 | 149.1 |
| 3 | 0.1150 | 131.6 |
| 4 | 0.3110 | 284.9 |
| 5 | 1.4000 | 89.6 |
| 6 | 3.8700 | 18.2 |

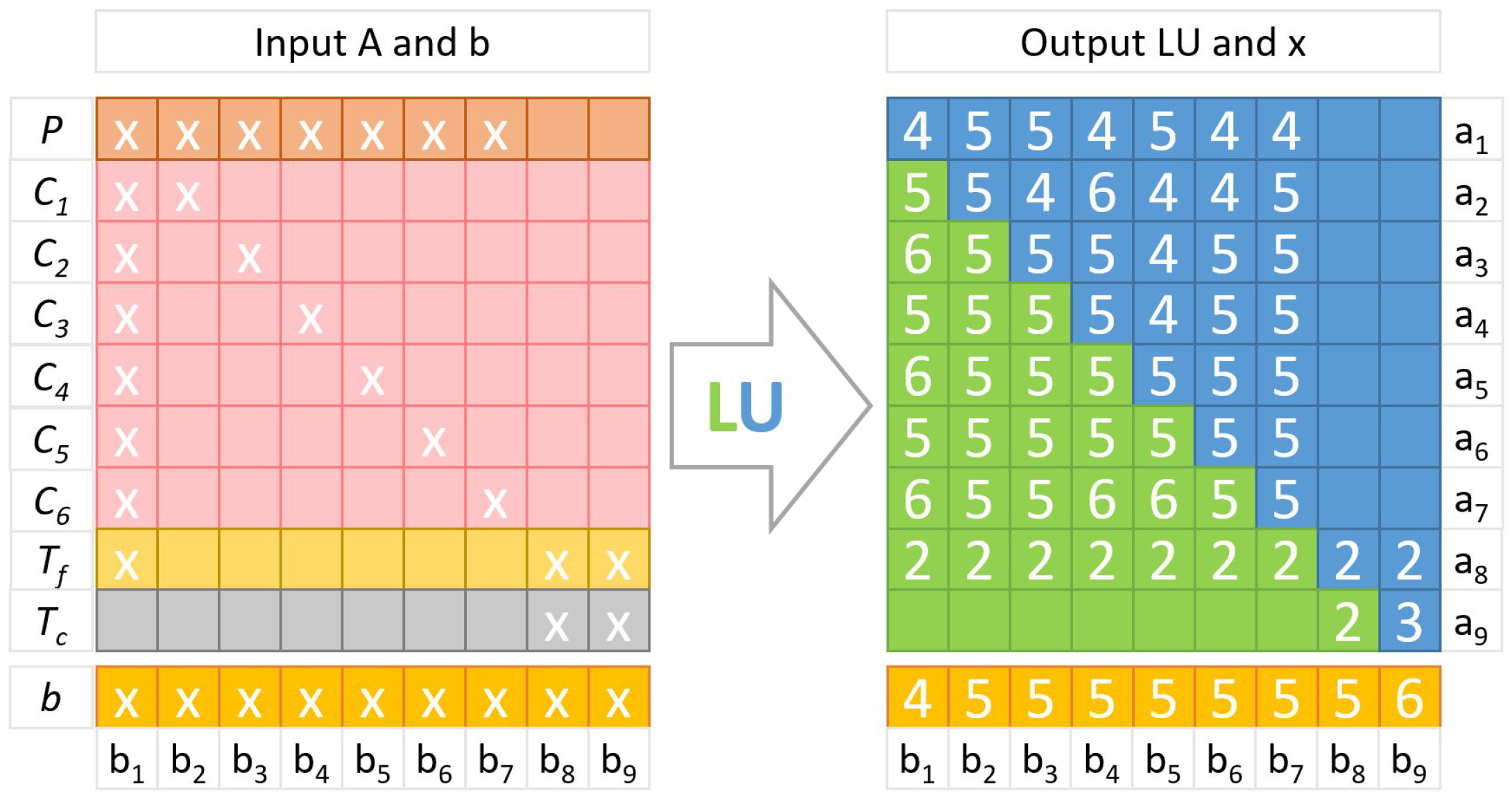
Appendix C. Numerical Scheme
References
- Turner, J.A.; Clarno, K.; Sieger, M.; Bartlett, R.; Collins, B.; Pawlowski, R.; Schmidt, R.; Summers, R. The Virtual Environment for Reactor Applications (VERA). Design and architecture. J. Comput. Phys. 2016, 326, 544–568. [Google Scholar] [CrossRef] [Green Version]
- Avramova, M.; Abaraca, A.; Hou, J.; Ivanov, K. Innovations in Multi-Physics Methods Development, Validation, and Uncertainty Quantification. J. Nucl. Eng. 2021, 2, 44–56. [Google Scholar] [CrossRef]
- Wang, Y.; Schunert, S.; Ortensi, J.; Laboure, V.; DeHart, M.; Prince, Z. Rattlesnake: A MOOSE-Based Multiphysics Multischeme Radiation Transport Application. Nucl. Technol. 2021, 207, 1047–1072. [Google Scholar] [CrossRef]
- State-of-the-Art Report on Multi-Scale Modelling of Nuclear Fuels; OECD: Paris, France, 2015.
- Cooper, M.W.D. Atomic Scale Simulation of Irradiated Nuclear Fuel. Ph.D. Thesis, Imperial College, London, UK, 2015. [Google Scholar]
- Hennessy, J.L.; Patterson, D.A. Computer Architecture: A Quantitative Approach, 6th ed.; Elsevier: Amsterdam, The Netherlands, 2018. [Google Scholar]
- Cohen, E.; Dolev, S.; Rosenblit, M. All-optical design for inherently energy-conserving reversible gates and circuits. Nat. Commun. 2016, 7, 11424. [Google Scholar] [CrossRef] [PubMed]
- Lewin, D.I. DNA Computing. Nat. Commun. 2002, 4, 5–8. [Google Scholar] [CrossRef]
- Wang, T. Novel Computing Paradigms Using Oscillators. Ph.D. Thesis, University of California, Berkeley, CA, USA, 2019. [Google Scholar]
- Mittal, S. A Survey of Techniques for Approximate Computing. ACM Comput. Surv. 2015, 48, 1–33. [Google Scholar] [CrossRef] [Green Version]
- Weber, L.; Honecker, A.; Normand, B.; Corboz, P.; Mila, F.; Wessel, S. Quantum Monte Carlo simulations in the trimer basis: First-order transitions and thermal critical points in frustrated trilayer magnets. SciPost Phys. 2022, 12, 29. [Google Scholar] [CrossRef]
- Xiao, F.; Liang, F.; Wu, B.; Liang, J.; Cheng, S.; Zhang, G. Posit Arithmetic Hardware Implementations with The Minimum Cost Divider and Square Root. Electronics 2020, 9, 1622. [Google Scholar] [CrossRef]
- Haq Rashed, M.R.; Jha, S.K.; Ewetz, R. Hybrid Analog-Digital In-Memory Computing. In Proceedings of the 2021 IEEE/ACM International Conference On Computer Aided Design (ICCAD), Munich, Germany, 1–4 November 2021; pp. 1–9. [Google Scholar] [CrossRef]
- Jeffress, S.; Duben, P.; Palmer, T. Bitwise Efficiency in Chaotic Models. Proc. R. Soc. A 2017, 473, 20170144. [Google Scholar] [CrossRef]
- Russel, F.P.; Duben, P.D.; Niu, X.; Luk, W.; Palmer, T.N. Exploiting the Chaotic Behaviour of Atmospheric Models with Reconfigurable Architectures. Comput. Phys. Commun. 2017, 221, 160–173. [Google Scholar] [CrossRef]
- Agrawal, A.; Mueller, S.M.; Fleischer, B.M.; Sun, X.; Wang, N.; Choi, J.; Gopalakrishnan, K. DLFloat: A 16-b Floating Point Format Designed for Deep Learning Training and Inference. In Proceedings of the 2019 IEEE 26th Symposium on Computer Arithmetic (ARITH), Kyoto, Japan, 10–12 June 2019; pp. 92–95. [Google Scholar] [CrossRef]
- Harvey, D.; van Der Hoven, J. Integer Multiplication in time O (n log n). Ann. Math. 2021, 193, 563–617. [Google Scholar] [CrossRef]
- Karatsuba, A.A. The Complexity of Computations. Proc. Steklov Inst. Math. 1995, 211, 169–183. [Google Scholar]
- Hartstein, A.; Srinivasan, V.; Puzak, T.R.; Emma, P.G. Cache miss behavior: Is it . In Proceedings of the 3rd Conference on Computing Frontiers, Ischia, Italy, 3–5 May 2006; pp. 313–330. [Google Scholar]
- Liang, L.; Zhang, Q.; Song, P.; Zhang, Z.; Zhao, Q.; Wu, H.; Cao, L. Overlapping Communication and Computation of GPU/CPU Heterogeneous Parallel Spatial Domain Decomposition MOC Method. Ann. Nucl. Energy 2020, 135, 106998. [Google Scholar] [CrossRef]
- Best Estimate Safety Analysis for Nuclear Power Plants: Uncertainty Evaluation; Technical Report 52; IAEA: Vienna, Austria, 2008.
- Abdel-Khalik, H.S.; Bang, Y.; Kennedy, C.; Hite, J. Reduced Order Modeling for Nonlinear Multi-Component Models. Int. J. Uncertain. Quantif. 2012, 2, 341–361. [Google Scholar] [CrossRef] [Green Version]
- Bang, Y.; Abdel-Khalik, H.S.; Hite, J.M. Hybrid Reduced Order Modeling Applied to Nonlinear Models. Int. J. Numer. Methods Eng. 2012, 91, 929–949. [Google Scholar] [CrossRef]
- Cherezov, A.; Sanchez, R.; Joo, H.G. A Reduced-Basis Element Method for Pin-by-Pin Reactor Core Calculations in Diffusion and SP3 Approximations. Ann. Nucl. Energy 2018, 116, 195–209. [Google Scholar] [CrossRef]
- Phillips, T.R.F.; Heaney, C.E.; Smith, P.N.; Pain, C.C. An autoencoder-based reduced-order model for eigenvalue problems with application to neutron diffusion. Int. J. Numer. Methods Eng. 2021, 122, 3780–3811. [Google Scholar] [CrossRef]
- Bokov, P.M.; Botes, D.; Groenewald, S.A. Dual Number Automatic Differentiation as Applied to two-group cross-section uncertainty propagation. Nucl. Technol. Radiat. Prot. 2021, 36, 107–115. [Google Scholar] [CrossRef]
- Henry, G.; Tang, P.T.P.; Heinecke, A. Leveraging the bloat16 Artificial Intelligence Datatype for Higher-Precision Computations. arXiv 2019, arXiv:1904.06376. [Google Scholar]
- Ho, N.M.; Wong, W.F. Exploiting half precision arithmetic in Nvidia GPUs. In Proceedings of the 2017 IEEE High Performance Extreme Computing Conference (HPEC), Waltham, MA, USA, 12–14 September 2017; pp. 1–7. [Google Scholar] [CrossRef]
- Algredo-Badillo, I.; Conde-Mones, J.J.; Hernandez-Gracidas, C.A.; Morin-Castillo, M.M.; Oliveros-Oliveros, J.J.; Feregrino-Uribe, C. An FPGA-based analysis of trade-offs in the Presence of Ill-conditioning and Different Precision Levels in Computations. PLoS ONE 2020, 15, 106998. [Google Scholar] [CrossRef]
- Gustafson, J.L. The End of Error: Unum Computing; Chapman and Hall/CRC: Boca Raton, FL, USA, 2015. [Google Scholar]
- Defour, D. FP-ANR: A Representation Format to Handle Floating-Point Cancellation at Run-Time. HAL Archive. 2017. Available online: https://hal.inria.fr/lirmm-01549601/ (accessed on 19 December 2022).
- Podobas, A.; Matsuoka, S. Hardware Implementation of POSITs and Their Application in FPGAs. In Proceedings of the IEEE International Parallel and Distributed Processing Symposium Workshops, Vancouver, BC, Canada, 21–25 May 2018. [Google Scholar]
- Demeure, N. Gestion du Compromis Entre la Performance et la Précision de Code de Calcul. Ph.D. Thesis, Université Paris-Saclay, Paris, France, 2021. [Google Scholar]
- Dawson, A.; Duben, P.D. RPE v5: An Emulator for Reduced Floating-Point Precision in Large Numerical Simulations. Geosci. Model Dev. 2017, 10, 2221–2230. [Google Scholar] [CrossRef] [Green Version]
- Eberhart, P.; Brajard, J.; Fortin, P.; Jezequel, F. High Performance Numerical Validation using Stochastic Arithmetic. Reliab. Comput. 2015, 21, 35–52. [Google Scholar]
- Golub, G.H.; Loan, C.F.V. Matrix Computations, 3rd ed.; Johns Hopkins University Press: Baltimore, MD, USA, 1996. [Google Scholar]
- Graham, S.L.; Kessler, P.B.; McKusick, M.K. An execution profiler for modular programs. Softw. Pract. Exper. 1983, 13, 671–685. [Google Scholar] [CrossRef]
- pyDOE: The Experimental Design Package for Python. Available online: https://pythonhosted.org/pyDOE (accessed on 19 December 2022).
- Chatelain, Y.; Petit, E.; de O. Castro, P.; Lartigue, G.; Defour, D. Automatic Exploration of Reduced Floating-Point Representation in Iterative Methods. In Proceedings of the 25th International Conference Euro-Par 2019 Parallel Processing, Gottingen, Germany, 26–30 August 2019; pp. 481–494. [Google Scholar]




| Arithmetic Complexity | |||
|---|---|---|---|
| # | Code Listing | % | FLOP |
| 01: | do j = 1, n | ||
| 02: | do i = 1, j | ||
| 03: | do k = 1, i − 1 | ||
| 04: | A (i, j) = A (i, j) − A (i, k) ∗ A (k, j) | 38 | |
| 05: | do i = j + 1, n | ||
| 06: | S = A (i, j) | ||
| 07: | do k = 1, j − 1 | ||
| 08: | S = S − A (i, k) ∗ A (k, j) | 26 | |
| 09: | A (i, j) = S / (A (j, j) − 1/h) | 10 | |
| 10: | do i = 1, n | ||
| 11: | do k = 1, i − 1 | ||
| 12: | b(i) = b(i) − A (i, k) ∗ b(k) | 10 | |
| 13: | do i = n, 1, −1 | ||
| 14: | S = −b (i) / h | 3 | n |
| 15: | do k = i + 1, n | ||
| 16: | S = S − A (i, k) ∗ b (k) | 10 | |
| 17: | b (i) = S / (A (i,i) − 1/h) | 3 | n |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cherezov, A.; Vasiliev, A.; Ferroukhi, H. Acceleration of Nuclear Reactor Simulation and Uncertainty Quantification Using Low-Precision Arithmetic. Appl. Sci. 2023, 13, 896. https://doi.org/10.3390/app13020896
Cherezov A, Vasiliev A, Ferroukhi H. Acceleration of Nuclear Reactor Simulation and Uncertainty Quantification Using Low-Precision Arithmetic. Applied Sciences. 2023; 13(2):896. https://doi.org/10.3390/app13020896
Chicago/Turabian StyleCherezov, Alexey, Alexander Vasiliev, and Hakim Ferroukhi. 2023. "Acceleration of Nuclear Reactor Simulation and Uncertainty Quantification Using Low-Precision Arithmetic" Applied Sciences 13, no. 2: 896. https://doi.org/10.3390/app13020896