1. Introduction
With the intelligent development of mechanical equipment, high speed and heavy load have become the main characteristics of the modern mechanical system. Rolling bearings play a vital role in the operation of rotating machinery. They are widely used and easy to be damaged, thus it is necessary to monitor and diagnose their condition [
1,
2].
In the past few decades, studies on the evaluation of mechanical health status based on vibration signals have appeared frequently in the literature [
3]. Generally, signal processing methods [
4,
5,
6,
7]—such as available time and frequency domain analysis, wavelet analysis, local wave analysis, and load identification in order to extract the signal characteristics and accomplish the goals of analysis and diagnosis, although the mechanical system is complex with interrelated subsystems—lead to the determination that the fault signal representation is not a one to one correspondence as it consists of various components, making traditional signal processing methods difficult for extracting effective features. However, data-driven deep learning methods can adaptively extract signal features and provide accurate diagnosis results. Therefore, deep learning-based methods of fault diagnosis have been applied more and more [
8,
9,
10,
11,
12,
13,
14].
Despite the fact that deep learning has led to numerous research successes in the field of fault diagnosis, it is difficult to explain or visualize the process of result realization and output due to the layered architecture formed by stacking nonlinear processing units. Moreover, the model has weak explanatory power; thus, it is called the “black box” method [
15]. The deep model’s potential for use in industrial field equipment fault diagnosis is severely limited as a result. Therefore, some researchers try to add attention mechanisms to the network in order to explore the interrelationship of data in the black box and hidden features that are currently difficult to find.
At present, the attention mechanism has been widely applied in the fields of text translation [
16], speech recognition [
17], document classification [
18], etc. In the field of fault diagnosis, Li et al. [
19] searched for important feature segments of signals by combining neural networks and attention mechanisms. Yang et al. [
20] improved the interpretability of networks by combining the convolutional neural network model of the recursive gated unit and attention mechanism, and its visualization effect was verified on bearing datasets. According to the classification of literature [
21], the above attention mechanisms are classified as soft attention. This kind of algorithm uses the weighted average of all the hidden states of the input sequence to construct the content vector. The application of the soft weighting method makes it easy for neural networks to learn effectively by back propagation, but it also leads to the cost of a second calculation. Xu et al. [
21] proposed the hard attention model, in which the content vector is calculated by sampling the hidden state according to the probability of the input sequence, which significantly reduces the cost of calculation. However, its framework is not differentiable, and it cannot use the back propagation method for the iterative calculation. To achieve gradient back propagation, the Monte Carlo Sampling method is used to estimate the gradient of modules. Vaswani et al. [
22] creatively proposed that the Transformer’s attention structure replaces RNN, which can be processed in parallel to achieve higher computational efficiency and solve the problem of long sequence gradient disappearance. However, it requires computing the relationship between pairs of sequences, which consumes more computing resources.
Luong et al. [
23] further developed the attention mechanism and divided it into the local attention mechanism and global attention mechanism. Similar to the soft attention mechanism, the global attention mechanism takes notice of all sequences in data, which makes the network have a large computation cost and leads to the degradation of network performance [
24]. The local attention mechanism is a trade-off between the soft and hard attention mechanisms. The network focuses on the area near the target sequence and reduces the computation expense. However, the local attention mechanism ignores the connection between non-adjacent sequences, thus its application has certain limitations [
24]. Xue et al. [
24] proposed a gated attention mechanism to address the above problems, which includes the trunk network and the secondary network. The trunk network realizes global attention, and the secondary network adopts a gated mechanism to select the sequence to be paid attention to in order to assist the attention sequence of the trunk network. However, in the literature [
24], the input of the secondary network is consistent with that of the trunk network, which also leads to a larger parameter scale and additional computing costs. Zhao et al. [
25] added a tiny filtering module in the deep network to generate soft thresholds through the attention mechanism to filter out unimportant information about features and significantly boost the performance against noise. The inputs of this module are channel characteristics after global maximum pooling; hence, the increase of parameters and computation cost is minimal. However, the filtering of the network is aimed at the internal characteristics of the channel, and all the sequences are still involved in the calculation, which cannot significantly reduce the network’s cost. At the same time, the operation of soft threshold filtering in the literature [
25] is closer to the hard threshold method, which cannot be calculated by the back propagation method and needs to be optimized by a reinforcement learning strategy. To solve this problem, the gated attention network [
24] uses the method of Gumbel-Softmax to simulate Bernoulli binomial distribution to achieve the calculation purpose of back propagation. Fu et al. [
26] provided a mask function in line with the principle of back propagation in the target detection task, which can approximately simulate Bernoulli binomial distribution.
In this article, a new method, Adaptive Sparse Attention Network (ASAN), was proposed by borrowing the idea of soft threshold filtering in [
25] and combining the advantages of global and local attention mechanisms. A network using the convolution of the neural network feature extraction ability and a two-way LSTM network has the advantages of dealing with long time-series data. Based on this added adaptive sparse attention module, the module generated a soft threshold adaptively by learning and using the threshold value filtering on the attention coefficient, removing unimportant sequence features and achieving the goal of sparse attention. The test and visual analysis are carried out on the CWRU bearing dataset and compared with the existing research. The outcomes indicate that the proposed ASAN method has better interpretability and higher training efficiency on the premise of keeping the model’s performance intact. It is important to note that although the CWRU bearing dataset is not difficult to classify and most models can achieve good results on this dataset, it is difficult to reflect the difference in model performance through it. However, it is still of great value to obtain the fault information distribution in data by exploring and verifying the feature extraction process of the model, especially in the current state of insufficient exploration of the explicability of the deep learning model.
The following are this paper’s contributions:
A new adaptive sparse attention network, ASAN, is proposed, which uses a soft threshold to filter attention weight sequences and ignores redundant sequences through sparse operation, thus paying more attention to corresponding features.
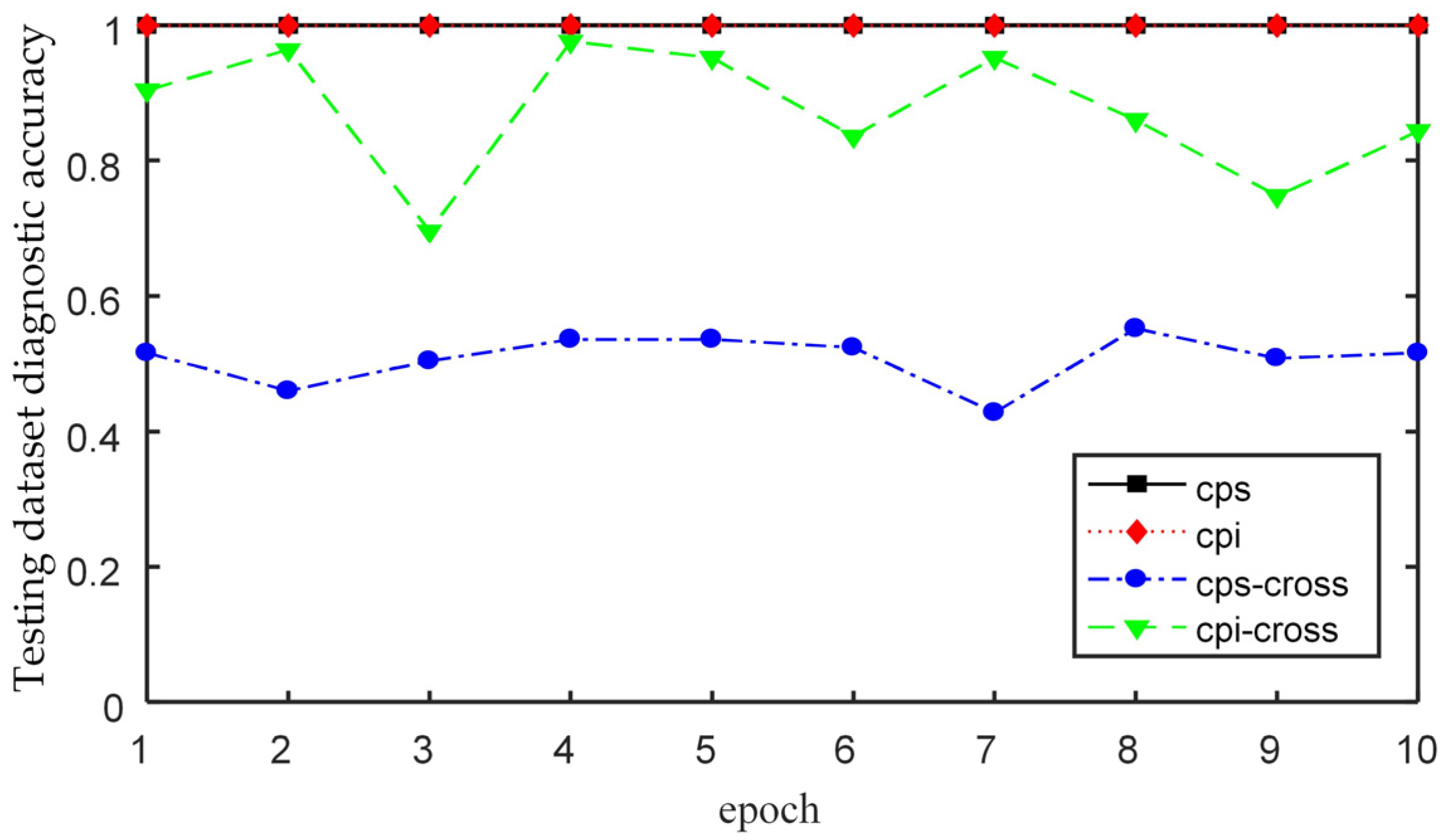
Considering the influence of the independent and shared settings of the convolution parameters of each sequence on network performance, the comparison results of the cross-condition diagnosis performance show that the diagnosis method with the independent settings of the convolution parameters of each sequence has better generalization.
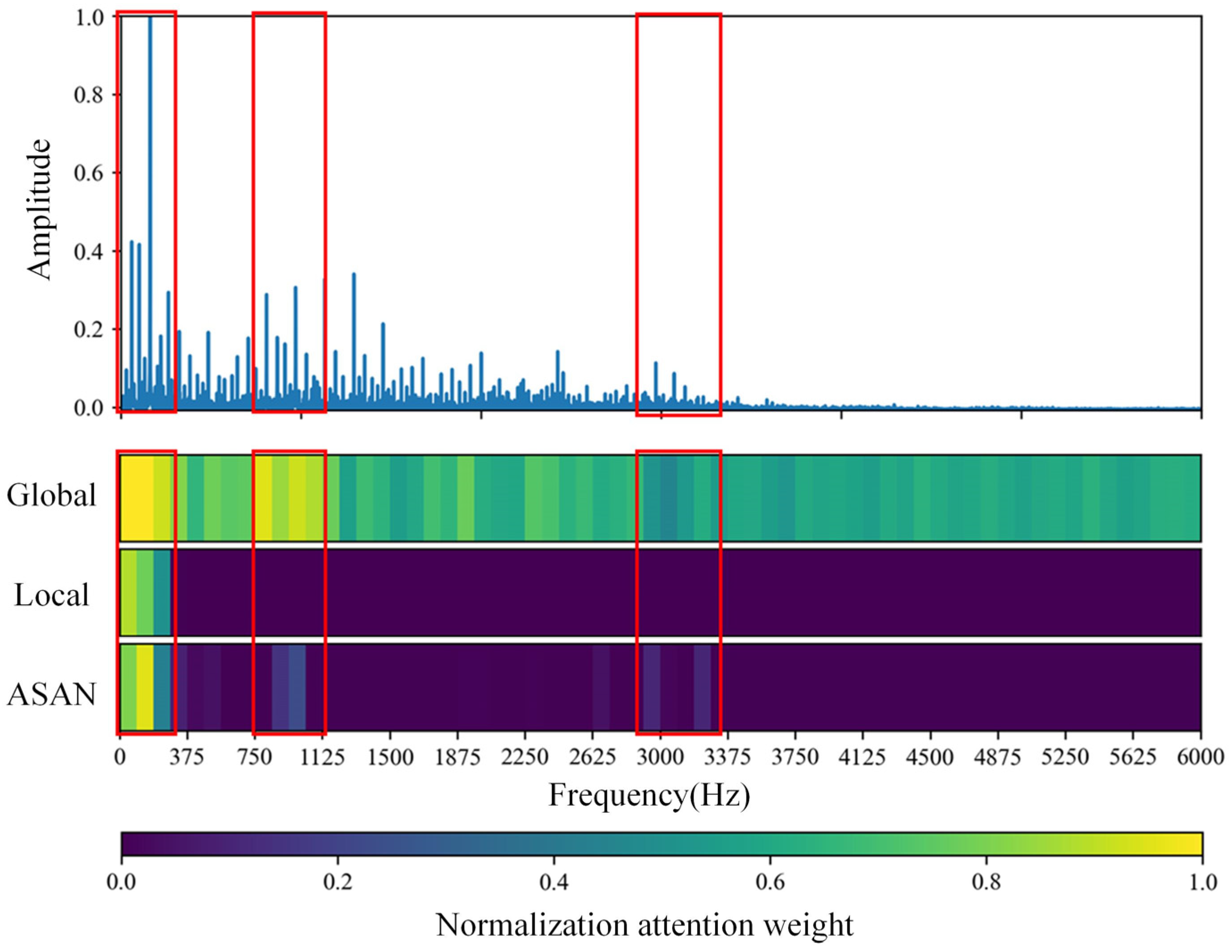
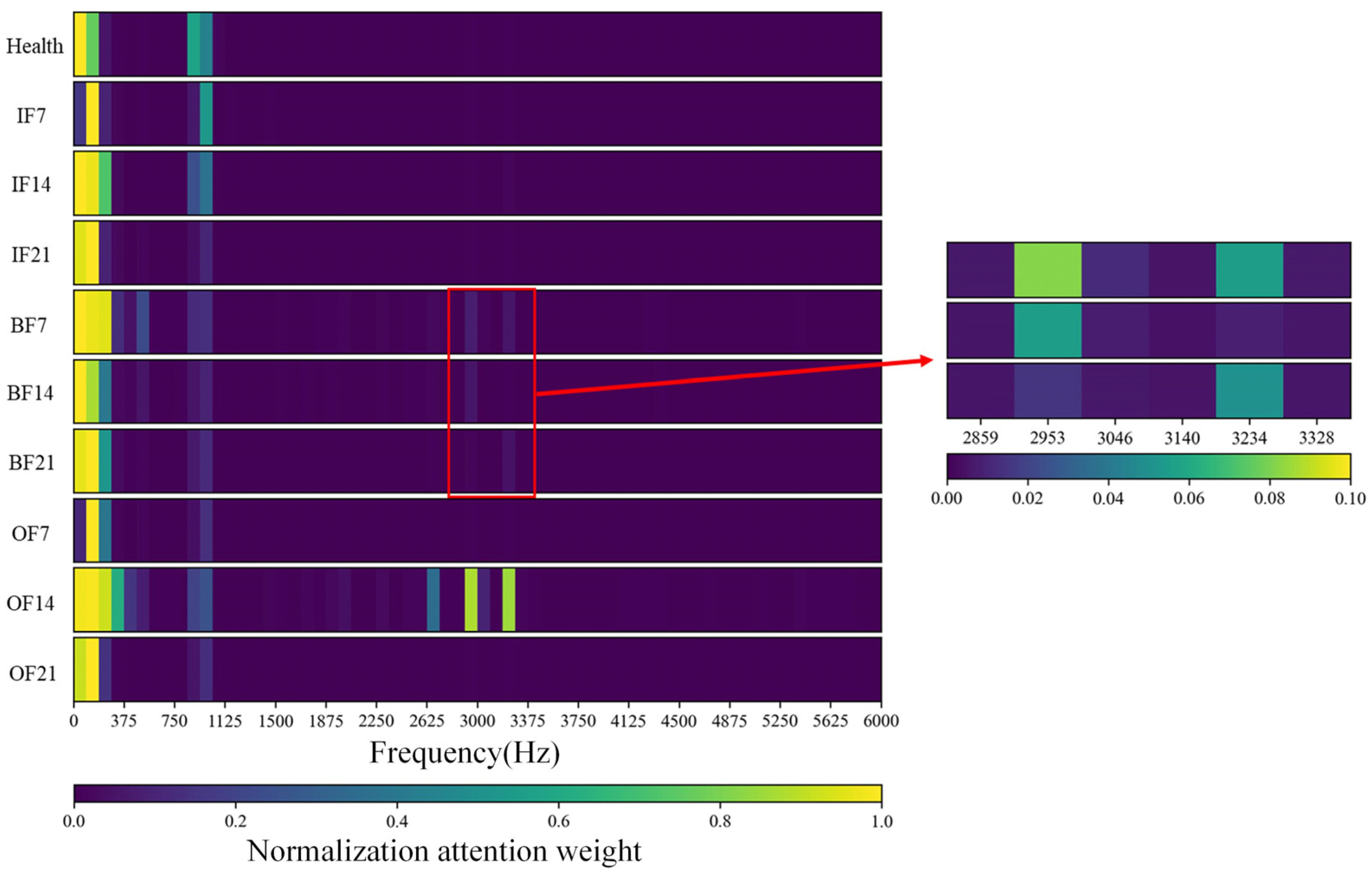
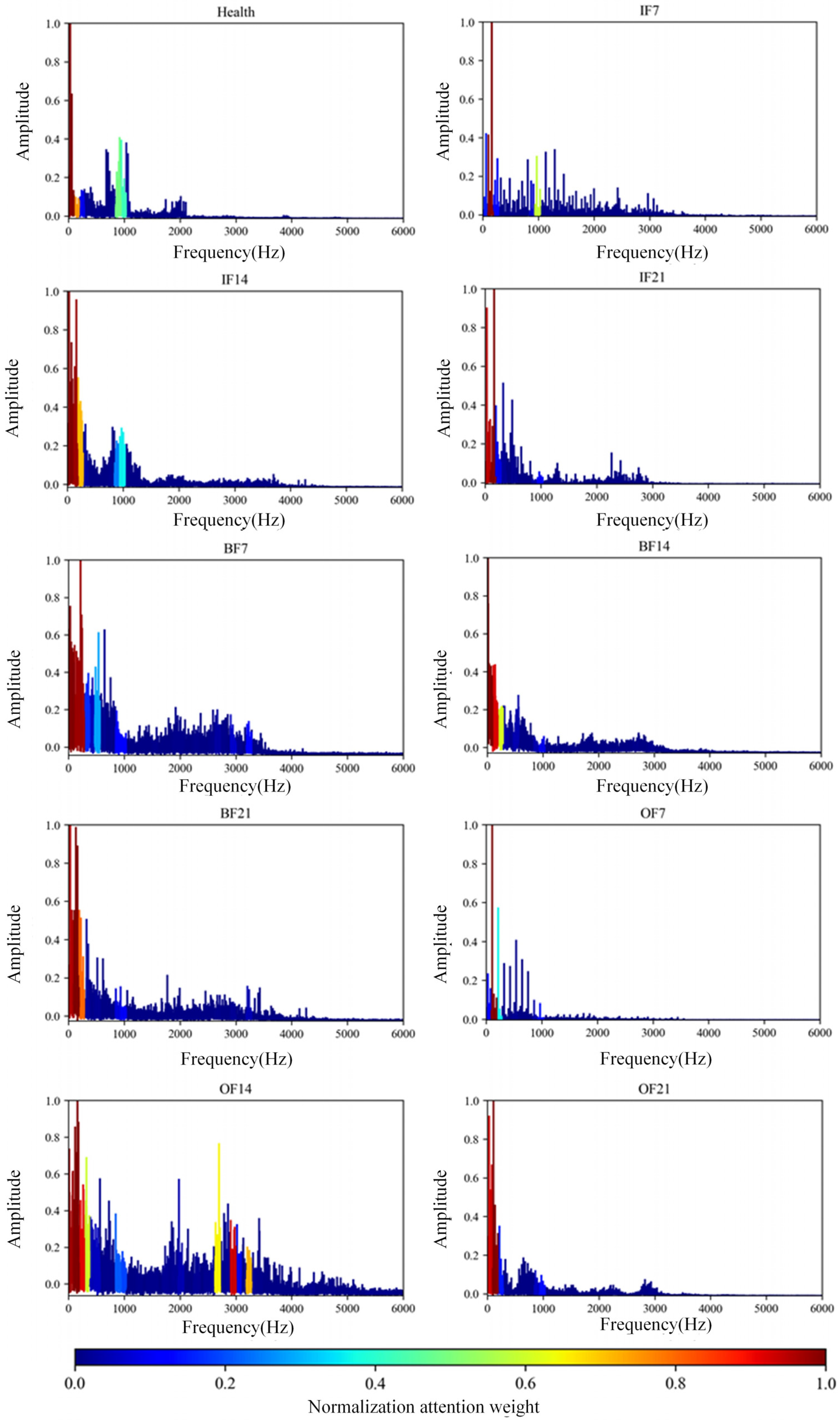
The effectiveness of the proposed algorithm is verified on the CWRU bearing dataset. The attention mechanism mainly captures 1I, 1I side frequency, 6I of IF, 1-3x, 1B, 2B of BF, and 1O, 2O, 3O of OF, which is consistent with the rule of fault diagnosis knowledge (IF is the inner ring fault, BF is the ball fault, OF is the outer ring fault, 1X is the power frequency of the bearing, 1I is one time of the characteristic frequency of the bearing with inner ring fault, and 1B and 1O are the same). The proposed method can locate the fault feature region and has better interpretability and visualization effect.
The remainder of the paper is organized in the following way.
Section 2 briefly introduces the theory of convolutional neural networks, BiLSTM networks, and attention mechanisms.
Section 3 describes the specific structure of the proposed model and the fault diagnosis process.
Section 4 discusses the obtained results through comparative validation.
Section 5 concludes the paper.
2. Introduction of Relevant Basic Models
This section presents the theoretical principles of the basic network layers used in the proposed model. The proposed model first extracts the primary features of the signal sequence by the convolutional layer. Next, it extracts the long sequence signal features by the BiLSTM layer to capture the dependency between the before and after time features. Then, it focuses on the important features via the sparse attention mechanism. Finally, it completes the fault diagnosis via a softmax layer. Therefore, the basic network layers of the proposed method include the convolutional layer, the BiLSTM layer, and the attention mechanism layers. They are described as follows.
2.1. Convolutional Neural Network
The Convolutional Neural Network (CNN) is one of the typical neural network structures at present. CNN has good data feature extraction capability without excessive data preprocessing. Moreover, CNN is widely used in natural speech processing and image recognition due to its characteristics of local receptive field, spatial subsampling, and weight sharing [
26,
27,
28,
29,
30]. In this study, for vibration signals or frequency domain signal sequences, 1DCNN is used for feature extraction, which is briefly introduced below.
Suppose the input data sequence is
, where
N is the length of the sequence, the length of the convolution kernel is
, and the sliding step is
s, then the sequence intercepted when the convolution kernel slides
i step on the input sequence is
. Finally, the convolution operation can be defined as:
where the output
is the feature learned by the convolution kernel during the sliding
i step,
is the convolution operation,
is the sliding number,
f is the nonlinear activation function,
is the
j convolution kernel,
is the offset. Then, the characteristic graph of the
j convolution kernel
is obtained.
Typically, a pooling layer is added between adjacent convolutional layers to extract important local information and reduce the dimension of the output matrix. Common pooling layer operations include maximum pooling, average pooling, and L2 pooling. Finally, the convolutional neural network flattens the learned features to the full connection layer, which is used to integrate the abstract features extracted from the previous layers and realize the direct link between the output data and the CNN.
The operation of multiple convolutional kernels enhances the ability of network data extraction, while multiple convolutional layers and pooling layers improve the learning ability of the CNN. The reasonable setting of CNN network parameters enables the CNN to better learn fault diagnosis knowledge.
2.2. BiLSTM Network
Bearing vibration acceleration time series contains rich state information. Recursive analysis of the time series can help extract the periodic response characteristics [
31,
32]. The recursive neural network (RNN) includes feedback connections between its hidden layer and the layer before it [
33], and it has the ability to process sequential information. RNN can be trained using back propagation with target output and sequence input data.
For the input sequence
, RNN hidden state vector calculation sequence
, the output sequence
, through the iterative equation below, from
t = 1 to
N.
The w is the weight matrix and the b is the offset term. Where represents the weight matrix for transformation between the hidden layer and the input layer, and is the offset vector of the hidden layer. The f is the nonlinear activation function of the hidden layer.
In general,
can be a sigmoid function in RNN. However, RNN’s performance suffers significantly as a result of the gradient disappearance issue during back propagation, which indicates that RNN may not be able to effectively capture long sequence data features. Therefore, a long- and short-term memory architecture (LSTM) was proposed to model the dependency between long sequences and prevent the problem of gradient disappearance in back propagation [
19].
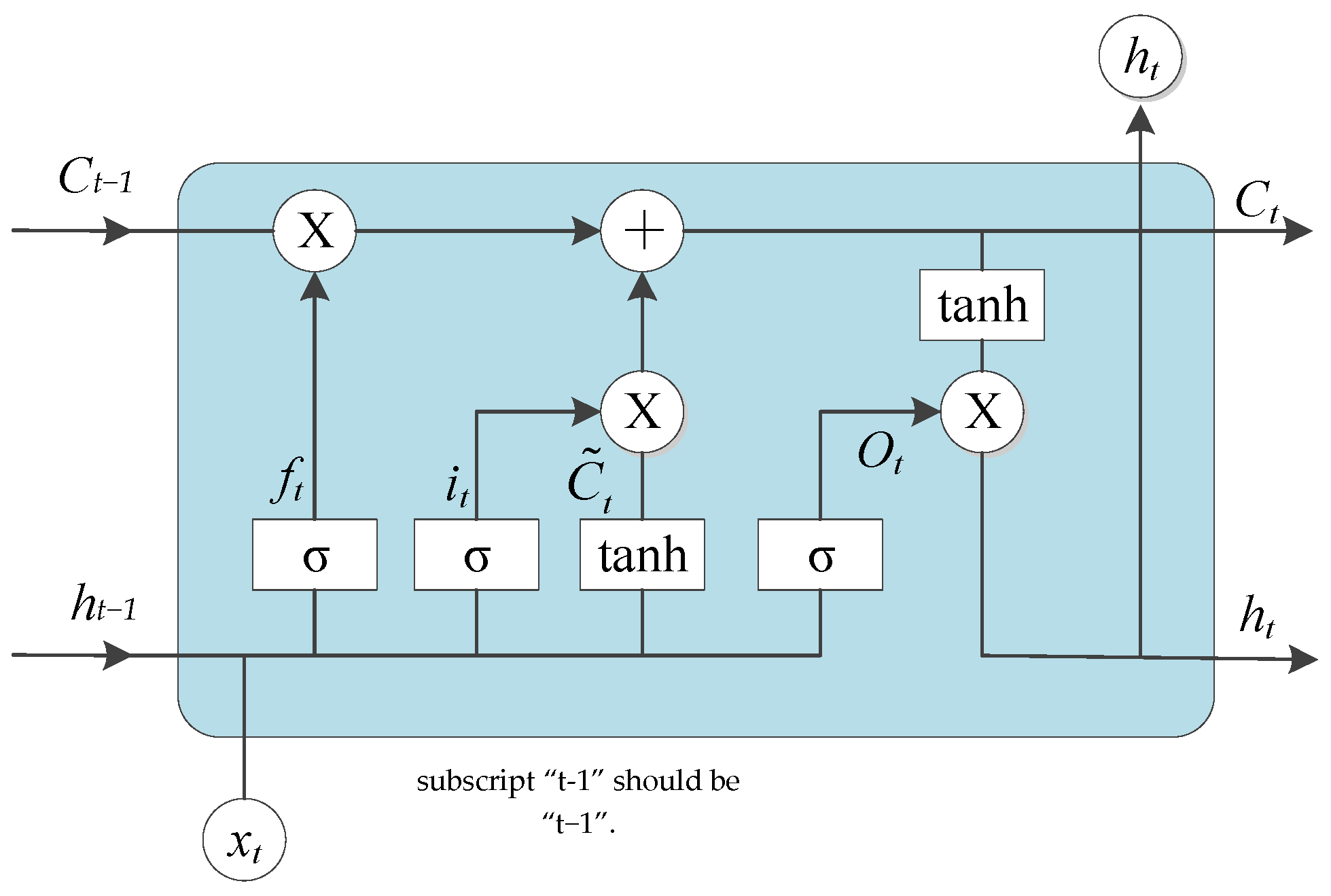
Figure 1 shows the LSTM operation process. The core idea of LSTM lies in its memory unit, which is an accumulator of state information. The LSTM has the ability to add or remove information from the cellular state, and this fine-tuning is achieved through the structure of the “gate”. Among them, the input gate
controls how much of the current network input
is saved to the unit state
, the forgetting gate
controls how much of the last moment’s unit state
is reserved to the current moment
, and the output gate
controls how much of the unit state
is sent to the current output value
of LSTM. The mainstream LSTM algorithm in [
34] is adopted in this study, as shown in the following function:
where
is the sigmoid activation function. Accordingly, the w matrix subscript in the formula is easy to understand. For example,
represents the matrix of transformation between the input gate and the hidden layer,
represents the matrix of transformation between the input state and the output gate, etc. With LSTM, the back propagation gradient can be captured in memory cells to prevent rapid loss.
LSTM assumes that the current time step is determined by the sequence of previous earlier time steps; thus, it passes information forward and backward through hidden states. Sometimes, the current time step may also be determined by subsequent time steps. If LSTM can keep an eye out for both front and back information, the network will better mine the characteristic information of vibration signals.
Bidirectional RNN realizes bidirectional information transmission by setting two parts: forward hidden information
and backward hidden information
. The iterative updating process of the output layer is as follows:
Bidirectional LSTM can be realized by incorporating LSTM into the bidirectional RNN framework.
2.3. Attentional Mechanism
It has been widely pointed out in the literature that different segments in the spectrum contribute differently to fault characteristics. This inspired the use of attentional mechanisms. In this study, the segmented spectral sequence signals are used as input, and an attention mechanism is employed to generate an attention coefficient for each segment sequence, which enhances or weakens the characteristics of a segment signal by weighting the product. The attention weights are also visualized to locate the frequency domain interval segment where the fault information is located, which is consistent with the mechanism of increasing the amplitude of the rotational frequency and its multiples in bearing fault diagnosis.
The computational process of the attentional mechanism can be described as follows:
Among them, represents the degree of correlation between the ith input sequence and the ith query sequence, that is, the ith attention coefficient. represents the attention scoring function, which is used to calculate the correlation between the input sequence and the query sequence. represents the input vector, and q represents the query vector.
Here, the query vector, key vector, and value vector are all hidden states of the input vector x. The query vector and key vector generate attention weight coefficients by the scoring function and then assign the coefficients to the corresponding value vector segments to enhance the signal representation by weighted fusion.
Different scoring functions can produce different attention mechanisms. The scoring function used in this paper is obtained from the following formula:
where
W and
b are the trainable weight matrices and bias terms respectively.
Finally, the enhanced representation of the input data
is obtained by the following formula:
Then, the enhanced signal
is used as the input for further diagnosis. The softmax classifier was used to complete the final bearing status classification.
where
and
are the weight matrix and offset term, respectively. The network output is interpreted as the probability of various classes [
35], and the final fault classification diagnosis is carried out.
3. The Proposed Adaptive Sparse Attention Network (ASAN)
3.1. Adaptive Sparse Attention Network
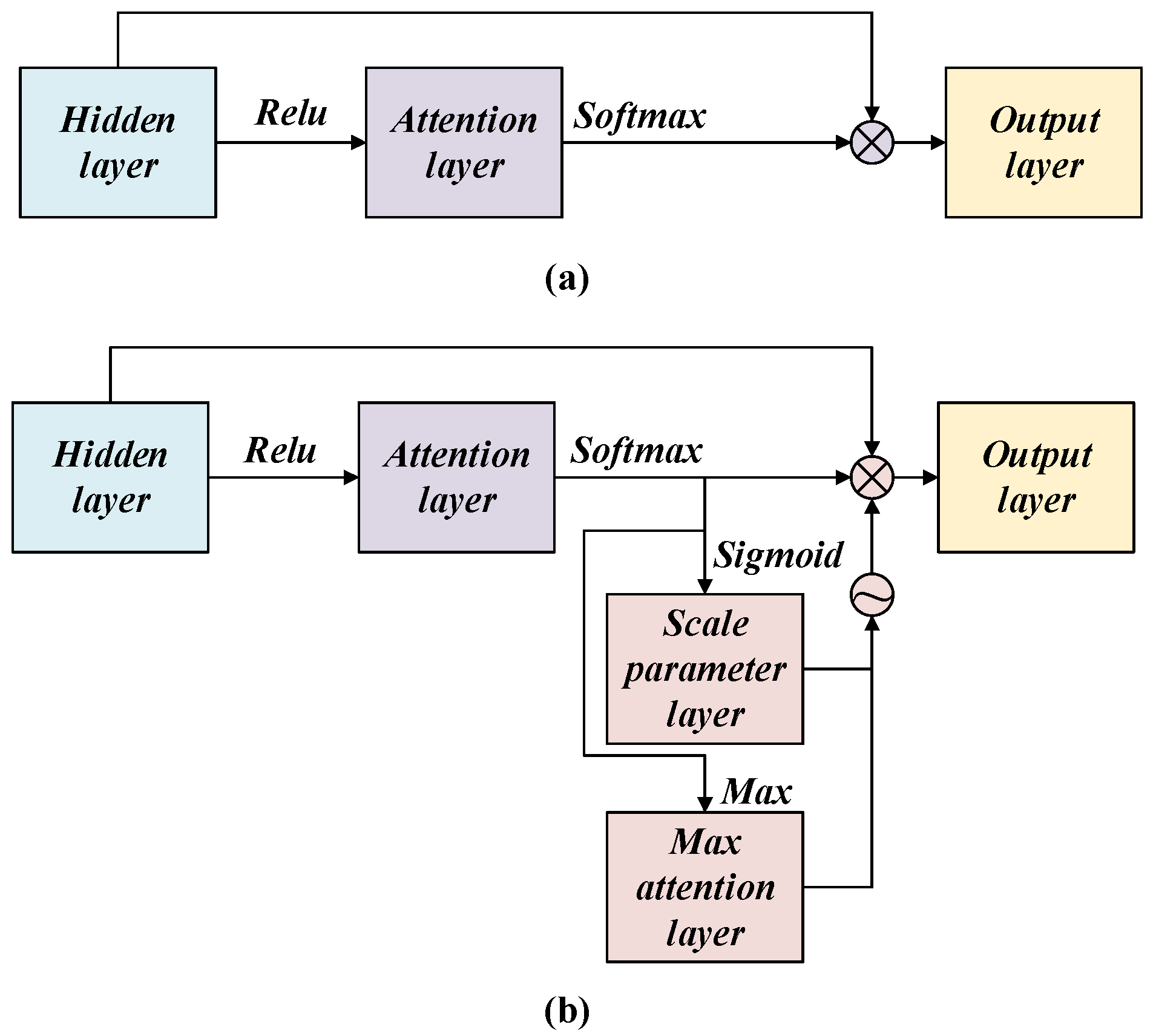
The attention mechanism imposes a set of attention coefficients on the whole sequence. Among them, the attention coefficients imposed by the more important sequence segments are large, and the attention coefficients imposed by the unimportant sequence segments are small, thus enhancing the classification ability of the network. However, in the application of fault diagnosis, the attention coefficients are scattered to more sequence segments with less classification contribution. As a result, the attention model imposes more computing costs and focuses on more redundant information. To get around this issue, we propose an adaptive thinning attention method. Through a layer of nonlinear transformation layers, the adaptive learning attention threshold is used to filter out smaller attention coefficients to achieve the purpose of attention thinning. The process is as follows.
The typical attention structure is shown in
Figure 2a, and the proposed adaptive sparse attention structure is shown in
Figure 2b. This module adds a Scale parameter layer and a Max attention layer after the attention layer. The Scale parameter layer takes the output
z of the attention layer as the input and finally generates a scale parameter
. The calculation process is shown as follows:
where
and
are the trainable weight matrix and bias terms, respectively.
The Max attention layer takes the output
z of the attention layer and the output
of the Scale parameter layer as input, and an attention threshold is finally generated
. The calculation process is shown as follows:
Then the natural exponential function is used to construct the filter function. The calculation process is as follows:
Here, when , the output result of tends to be 0. When , equals 0.5. When , tends to be 1.
Last, the output of the threshold filter and the output of the attention layer are reconstructed with the softmax function to obtain the attention coefficient
. The procedure for calculating is as follows:
where
represents the number of sequences.
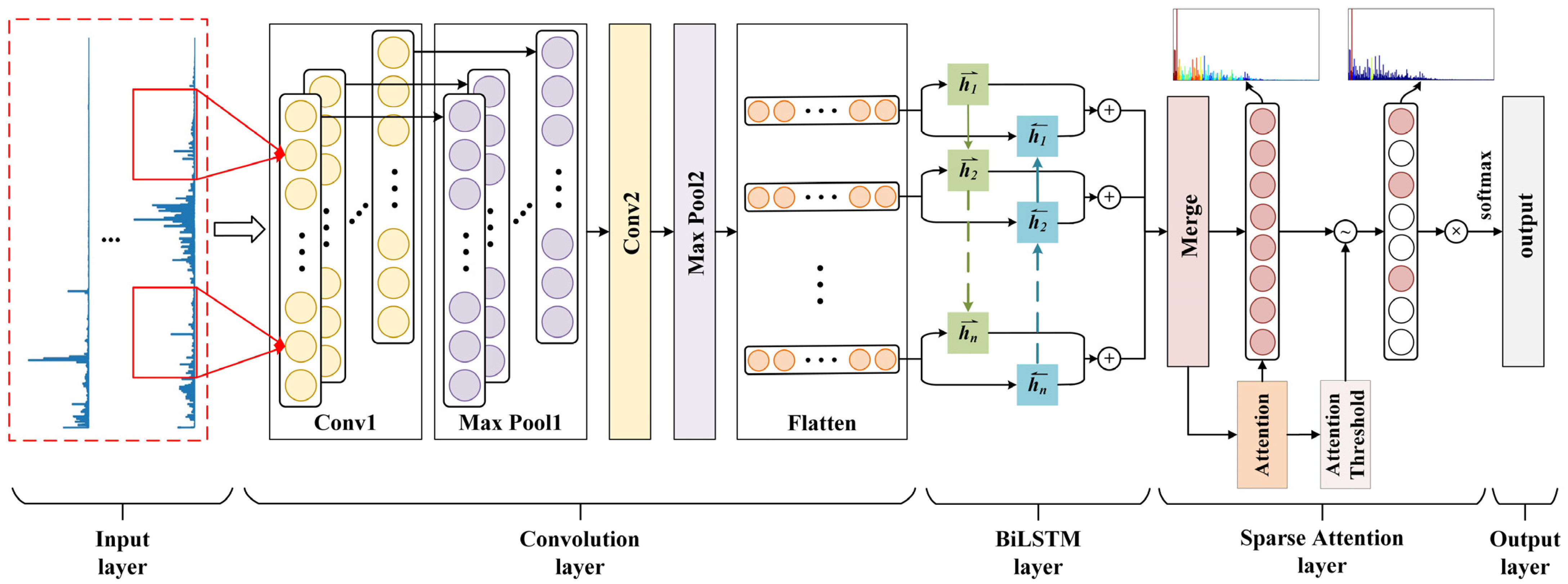
3.2. The Network Structure
The structure of the proposed deep network for fault diagnosis is depicted in
Figure 3. To further illustrate, the bearing vibration envelope spectrum signal is used as the model input.
First, the input data sample is divided into subsamples, i.e., sequences, and each subsample contains data points (all adjusted to integers for the convenience of subsequent calculation). Next, the convolution layers Conv1 and Conv2 are used to extract features for each signal segment, and then the max-pooling operation is carried out. The two convolution layers use the same structure, but the parameters are slightly different. Multiple local convolutional kernels with a window length of are used for each layer respectively, and the zeroing operation is carried out to keep the dimension of the feature extraction layer unchanged. Each sequence signal’s spatial characteristics can be deduced in this manner.
Then, a full-connection layer was added to each segment of the signal for feature extraction, and softmax was used to assign attention weight to each segment of the signal. Subsequently, the attention weight is filtered by an adaptive threshold, and a sparse attention weight is obtained. Finally, the enhanced representation vector of the signal is created by multiplying the sparse attention weight by each segment signal.
After the signal is enhanced by sparse attention, all the sequence features are integrated into a bidirectional LSTM layer. The bidirectional LSTM can connect forward and backward hidden states to capture sequential information in the input data.
Dropout technology is a useful regularization technique that can prevent training data from being over-fitted. The authors of [
36] recommended using dropout technology with a ratio of 0.4 at multiple levels of the network. In addition, the rectified linear unit (ReLU) activation function is generally used in the network. Because they do not have the problem of gradient disappearance or gradient diffusion during training, they can generally achieve better performance, especially in deep architectures [
37]. Among them, the leaky ReLU first proposed is a variant of ReLU, which can be used as the attention module’s activation function to determine the difference in how attention weight is distributed. In this study, the cross-entropy function was used as the loss function [
38]. The parameters of the proposed network are shown in
Table 1.
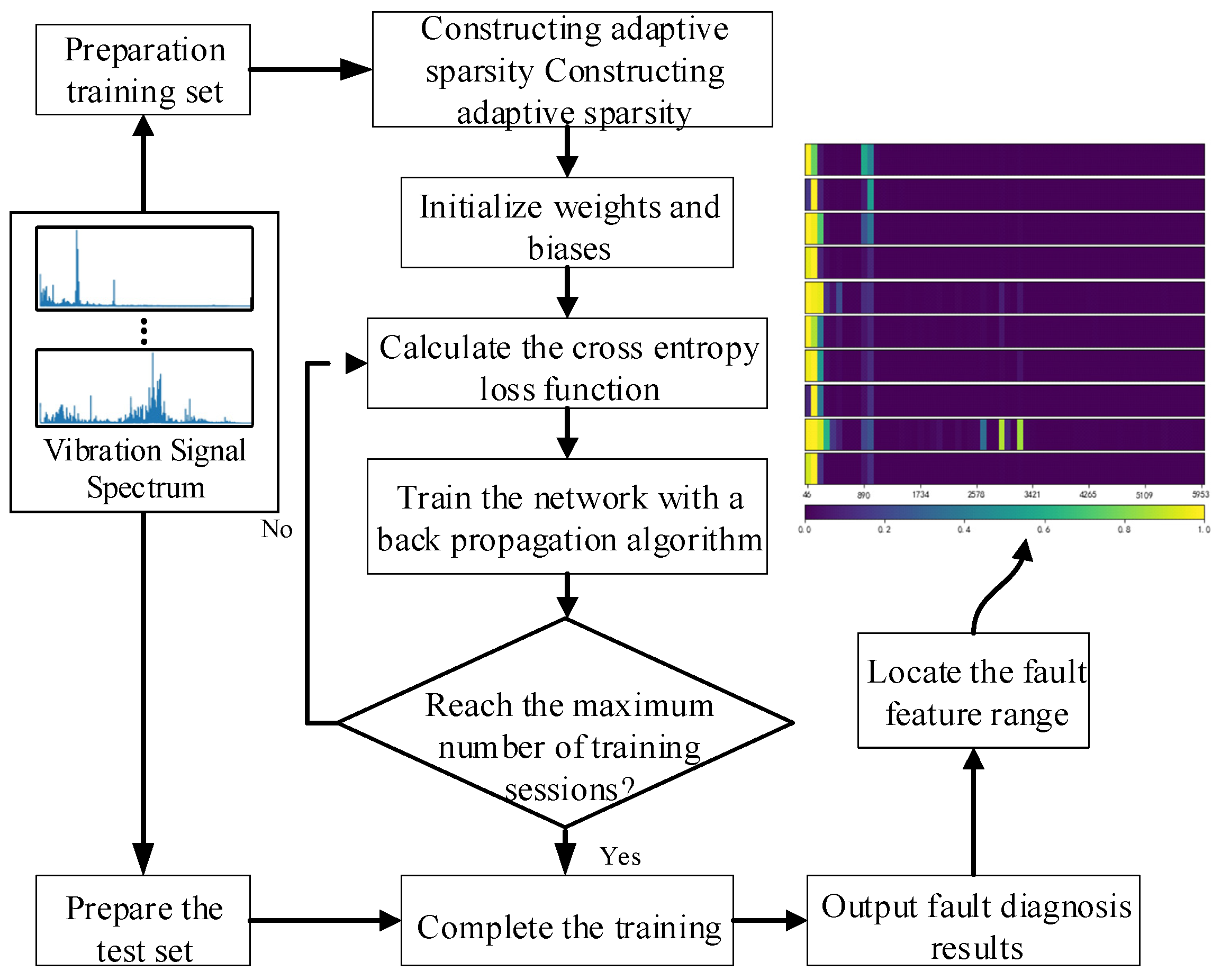
3.3. The Diagnosis Process
Figure 4 depicts the proposed fault diagnosis method’s flowchart. First, the original mechanical vibration signals are collected by sensors. Then, the vibration data are preprocessed to conform to the input format of the model, and training samples and test samples are made accordingly. The network obtains fault diagnosis results through training and learning, and the knowledge learned in the diagnosis process is well explained through corresponding visualization methods.
Next, the network configuration is selected from the architecture presented in
Section 3.2, based on the information in the dataset and the particular issue with fault diagnosis. The detailed network structure includes the number of layers, the number and size of convolutional kernels at the convolutional layer, the number of neurons, etc., which are mainly determined by model verification in experimental research, with vibration data as the input of the model. Network biases and weights are initialized with the Xavier standard initializer.
The BP (Back-Propagation) algorithm was used to update all parameters in the network, and the target was minimized in small batches using the Adam optimization technique. The learning rate is 0.001, and after 300 training, the proposed network loss function converges on the whole.
Table 1 displays the corresponding parameters.
Finally, the test fault diagnosis results are obtained by incorporating the test samples into the proposed model following the completion of the training phase. At the same time, the fault feature region that is most relevant to the result can be located through the model, which lays a foundation for the subsequent difficult fault research and diagnosis.
5. Conclusions
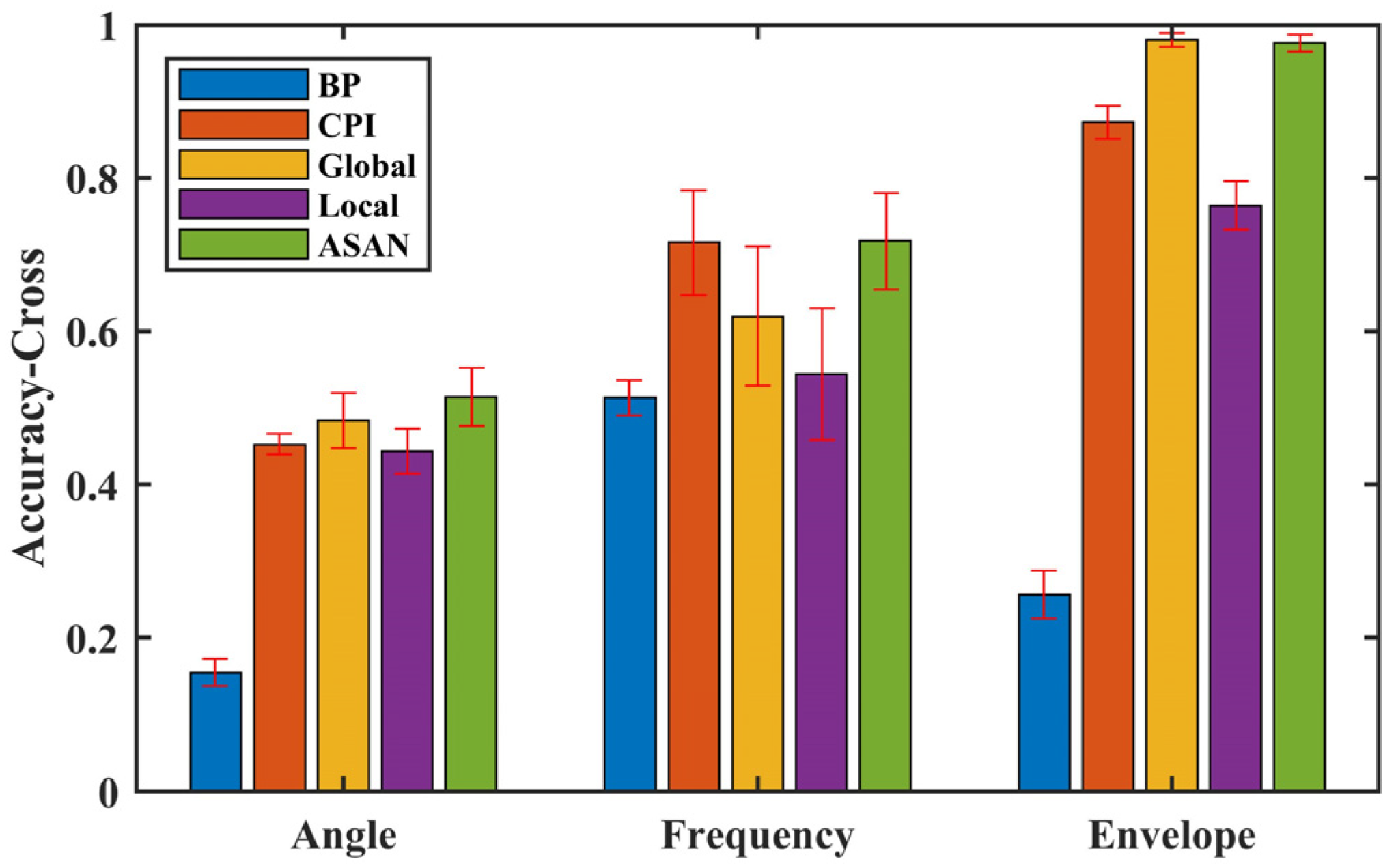
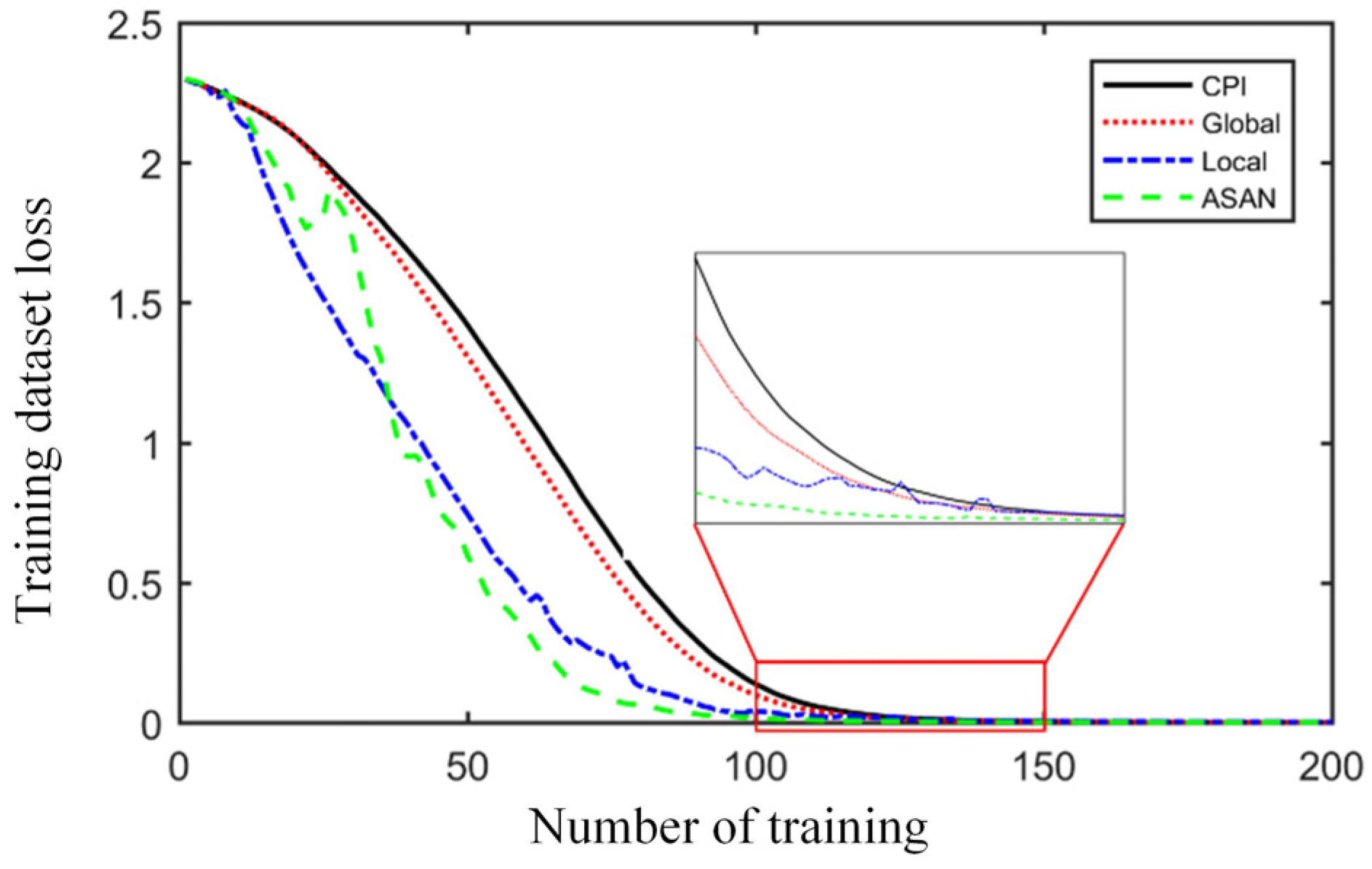
In this paper, a fault diagnosis model based on an adaptive sparse attention network is proposed. Through the soft threshold filtering of attention network weight, the diagnostic weight of the signals is adaptive and sparsely represented, and the signals of different representation domains are used as the model input for comparative analysis. The results show that the envelope spectrum of the bearing vibration signal has a more effective representation ability for fault information, and the proposed sparse attention model can automatically screen out the characteristic information that is more sensitive to faults. In addition, the proposed adaptive sparse network model achieves 97.6% accuracy and 196.54 s convergence time, which is 21.2% more accurate and 113.47 s shorter than the local method, and 193.24 s shorter than the global method, although the accuracy decreases by 0.4%. Therefore, the proposed model has better comprehensive performance, and the visualization has a better interpretation.
In the future, the knowledge screening network model can be used to further explore the differences in weights of sensitive features corresponding to different faults and their variation patterns with working conditions, etc., in order to provide directional guidance for an in-depth explanation of the fault mechanism and achieve the purpose of feedback maintenance. The problem of collaborative updating of the model and real-time data will be studied later and validated in real industrial fields.














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}