


Applying Machine Learning in Retail Demand Prediction—A Comparison of Tree-Based Ensembles and Long Short-Term Memory-Based Deep Learning

Abstract
:1. Introduction
- Feature diversity: Our study goes beyond historical demand data by incorporating a wide array of diverse features, including price and external factors, such as weather and COVID-19-related data. This enriched dataset enhances our understanding of demand behavior;
- Real-world applicability: We utilize a substantial dataset from a prominent supermarket, demonstrating the real-world applicability of our findings. This authenticity adds credibility to our research and enhances its practical relevance;
- Advanced machine learning models: We leverage advanced machine learning techniques by employing two state-of-the-art models selected for their ability to handle complex datasets and capture intricate demand patterns effectively to improve forecast accuracy in an uncertain environment;
- Category-based analysis: To comprehensively evaluate our forecasting models, we conduct category-based analyses across three distinct perishable product categories. This approach showcases the models’ effectiveness in handling diverse consumer behaviors and demand patterns.
2. Background
3. Research Methodology
3.1. Initial Dataset
- (i)
- Historical demand data: Our dataset comprises historical demand data, which is also our target variable, covering a 76-month period from January 2016 to February 2022. It includes daily demand amounts for over 330 products across 3 main product categories: fruits (A), fresh meat (B), and soft drinks (C). In total, the dataset spans more than 6 years, resulting in over 5.2 million available records for training and testing. The data are extracted from a sales transaction dataset from a supermarket located in Austria;
- (ii)
- Internal data: This component includes data that results from business decisions, such as pricing and promotions. Key components of these internal data include pricing information and promotional activities. This dataset includes daily price values for each product;
- (iii)
- External data: In addition to internal factors, our dataset incorporates external variables that are beyond the direct control of the retail company. These external variables encompass various factors, including calendar-related data, weather conditions, and COVID-19-related data. Calendar-related data provide information for each day, including the month of the year, week of the year, day of the week, day of the month, and any special day or event. Weather data include temperature in Celsius, wind speed in m/s, amount of precipitation in mm, and precipitation type (no precipitation, rain, snow, rain–snow). COVID-19-related data include information about the type of lockdown, including no lockdown and lockdown.
3.2. Data Preparation
3.3. Feature Creation
3.4. Input Dataset
3.5. Feature Scaling and Encoding
3.6. Feature Selection
3.7. Model Training
3.7.1. Model 1—Extra Tree Regressor (ETR)
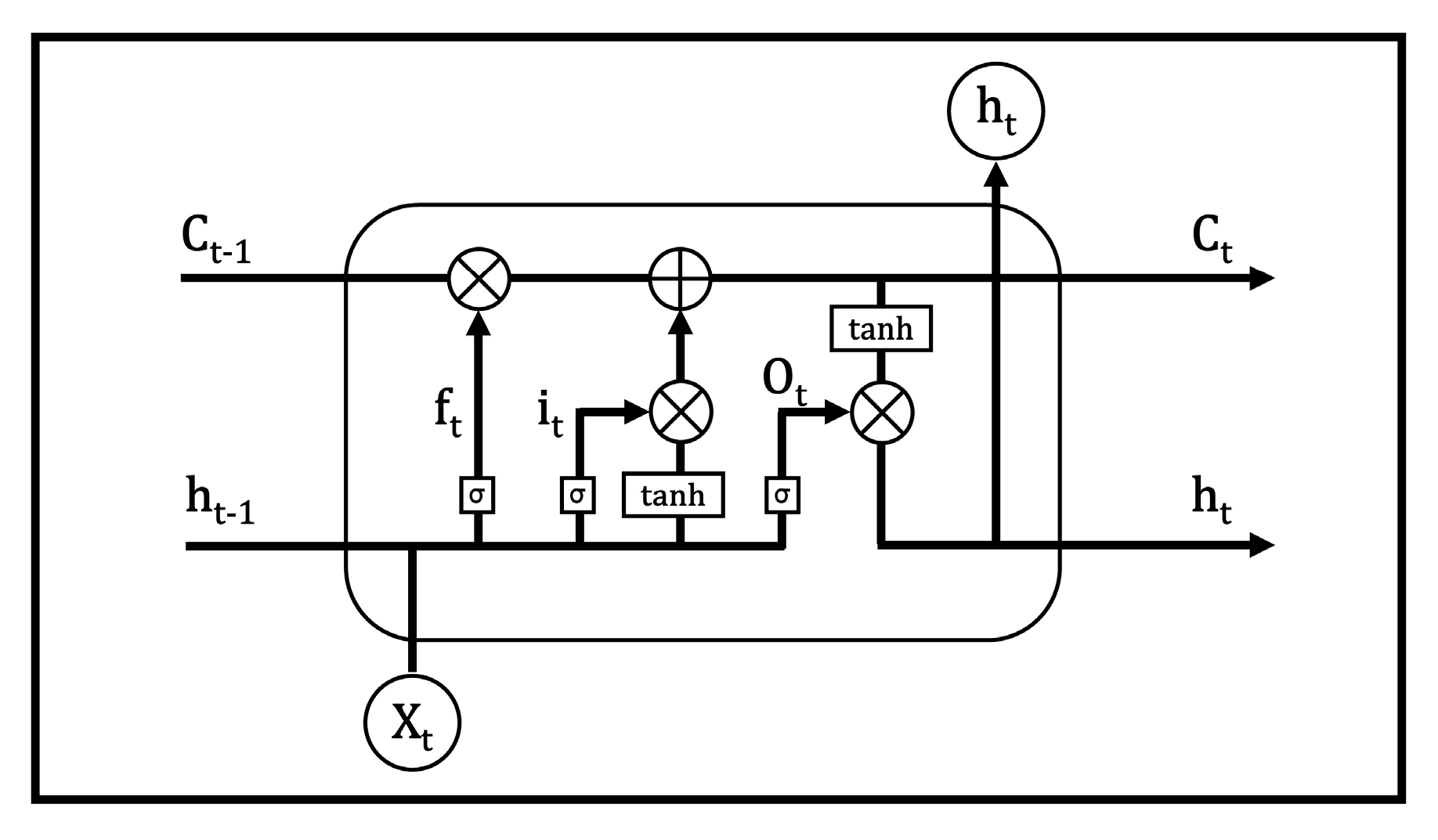
3.7.2. Model 2—LSTM-Based Deep Learning (DL)
3.8. Model Evaluation and Tuning
3.9. Trained Model
3.9.1. Model 1—ETR
3.9.2. Model 2—DL
3.10. Final Evaluation
4. Results and Discussion
4.1. Comparison of ETR and DL
4.2. Comparison of ETR and Other Tree-Based Ensembles
- Random forest regressor (RFR): the RFR is another ensemble model, like ETR, which leverages a collection of decision trees to make predictions using the bagging method. It combines predictions from multiple trees to enhance accuracy and robustness. In previous research, random forests emerged as the top performer in retail sale prediction considering calendar dimensions [33];
- Gradient Boosting Regressor (GBR): the GBR is an algorithm that sequentially constructs decision trees to minimize prediction errors using the boosting method. It iteratively refines the model’s predictions by focusing on correcting mistakes in subsequent iterations, leading to strong predictive performance. The GBR has been found to perform especially well in demand prediction when both numerical and categorical features are involved [53];
- XGBoost: XGBoost is another gradient-boosting algorithm known for its efficiency and high performance. It incorporates regularization techniques, parallel processing, and optimized tree construction to achieve high accuracy while maintaining computational speed. In combination with Convolutional Neural Networks (CNNs), XGBoost (XGB) was identified as the most suitable choice for predicting purchase probabilities [32].
5. Conclusions, Limitations, and Outlook
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Petropoulos, F.; Apiletti, D.; Assimakopoulos, V.; Babai, M.Z.; Barrow, D.K.; Ben Taieb, S.; Bergmeir, C.; Bessa, R.J.; Bijak, J.; Boylan, J.E.; et al. Forecasting: Theory and practice. Int. J. Forecast. 2022, 38, 705–871. [Google Scholar] [CrossRef]
- Brandtner, P.; Udokwu, C.; Darbanian, F.; Falatouri, T. Applications of Big Data Analytics in Supply Chain Management: Findings from Expert Interviews. In Proceedings of the ICCMB 2021: 2021 the 4th International Conference on Computers in Management and Business, Singapore, 30 January–1 February 2021; ACM: New York, NY, USA, 2021; pp. 77–82. [Google Scholar]
- Brandtner, P. Predictive Analytics and Intelligent Decision Support Systems in Supply Chain Risk Management—Research Directions for Future Studies. In Proceedings of the Seventh International Congress on Information and Communication Technology, London, UK, 21–24 February 2022; Yang, X.-S., Sherratt, S., Dey, N., Joshi, A., Eds.; Lecture Notes in Networks and Systems; Springer Nature: Singapore, 2023; Volume 464, pp. 549–558. [Google Scholar]
- Brandtner, P. Requirements for Value Network Foresight-Supply Chain Uncertainty Reduction. In ISPIM Conference Proceedings; LUT Scientific and Expertise Publications: Lappeenranta, Finland, 2020; pp. 1–12. [Google Scholar]
- Falatouri, T.; Darbanian, F.; Brandtner, P.; Udokwu, C. Predictive Analytics for Demand Forecasting—A Comparison of SARIMA and LSTM in Retail SCM. Procedia Comput. Sci. 2022, 200, 993–1003. [Google Scholar] [CrossRef]
- Fildes, R.; Ma, S.; Kolassa, S. Retail forecasting: Research and practice. Int. J. Forecast. 2022, 38, 1283–1318. [Google Scholar] [CrossRef]
- Ma, S.; Fildes, R. Retail sales forecasting with meta-learning. Eur. J. Oper. Res. 2021, 288, 111–128. [Google Scholar] [CrossRef]
- Akyuz, A.O.; Bulbul, B.A.; Uysal, M.O. Ensemble approach for time series analysis in demand forecasting: Ensemble learning. In Proceedings of the 2017 IEEE International Conference on Innovations in Intelligent Systems and Applications (INISTA), Gdynia, Poland, 3–5 July 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 7–12. [Google Scholar] [CrossRef]
- Wang, X.; Hyndman, R.J.; Li, F.; Kang, Y. Forecast combinations: An over 50-year review. Int. J. Forecast. 2022, 39, 1518–1547. [Google Scholar] [CrossRef]
- Januschowski, T.; Wang, Y.; Torkkola, K.; Erkkilä, T.; Hasson, H.; Gasthaus, J. Forecasting with trees. Int. J. Forecast. 2022, 38, 1473–1481. [Google Scholar] [CrossRef]
- Kotu, V.; Deshpande, B. Classification. In Data Science; Elsevier: Amsterdam, The Netherlands, 2019; pp. 65–163. [Google Scholar]
- Djarum, D.H.; Ahmad, Z.; Zhang, J. River Water Quality Prediction in Malaysia Based on Extra Tree Regression Model Coupled with Linear Discriminant Analysis (LDA). In Proceedings of the 31st European Symposium on Computer Aided Process Engineering, Computer Aided Chemical Engineering, Istanbul, Turkey, 6–9 June 2021; Elsevier: Amsterdam, The Netherlands, 2021; Volume 50, pp. 1491–1496. [Google Scholar]
- Sumaiya Farzana, G.; Prakash, N. (Eds.) Machine Learning in Demand Forecasting—A Review. In Proceedings of the 2nd International Conference on IoT, Social, Mobile, Analytics & Cloud in Computational Vision & Bio-Engineering, Thoothukudi, India, 29–30 October 2020. [Google Scholar]
- Arunraj, N.S.; Ahrens, D.; Fernandes, M. Application of SARIMAX model to forecast daily sales in food retail industry. Int. J. Oper. Res. Inf. Syst. (IJORIS) 2016, 7, 1–21. [Google Scholar] [CrossRef]
- Da Marques, F.; Alexandre, R. A Comparison on Statistical Methods and Long Short Term Memory Network Forecasting the Demand of Fresh Fish Products. Master’s Thesis, Faculty of Engineering of the University of Porto, Porto, Portugal, 2020. [Google Scholar]
- Alon, I.; Qi, M.; Sadowski, R.J. Forecasting aggregate retail sales: A comparison of artificial neural networks and traditional methods. J. Retail. Consum. Serv. 2001, 8, 147–156. [Google Scholar] [CrossRef]
- Cankurt, S. Tourism demand forecasting using ensembles of regression trees. In Proceedings of the 2016 IEEE 8th International Conference on Intelligent Systems (IS), Sofia, Bulgaria, 4–6 September 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 702–708. [Google Scholar] [CrossRef]
- Seyedan, M.; Mafakheri, F.; Wang, C. Cluster-based demand forecasting using Bayesian model averaging: An ensemble learning approach. Decis. Anal. J. 2022, 3, 100033. [Google Scholar] [CrossRef]
- Liu, Z.; Jiang, P.; Wang, J.; Zhang, L. Ensemble forecasting system for short-term wind speed forecasting based on optimal sub-model selection and multi-objective version of mayfly optimization algorithm. Expert Syst. Appl. 2021, 177, 114974. [Google Scholar] [CrossRef]
- Yu, L.; Dai, W.; Tang, L. A novel decomposition ensemble model with extended extreme learning machine for crude oil price forecasting. Eng. Appl. Artif. Intell. 2016, 47, 110–121. [Google Scholar] [CrossRef]
- Ribeiro, G.T.; Mariani, V.C.; Coelho, L.d.S. Enhanced ensemble structures using wavelet neural networks applied to short-term load forecasting. Eng. Appl. Artif. Intell. 2019, 82, 272–281. [Google Scholar] [CrossRef]
- Zhang, F.; Fleyeh, H.; Bales, C. A hybrid model based on bidirectional long short-term memory neural network and Catboost for short-term electricity spot price forecasting. J. Oper. Res. Soc. 2022, 73, 301–325. [Google Scholar] [CrossRef]
- da Silva, R.G.; Ribeiro, M.H.D.M.; Moreno, S.R.; Mariani, V.C.; dos Santos Coelho, L. A novel decomposition-ensemble learning framework for multi-step ahead wind energy forecasting. Energy 2021, 216, 119174. [Google Scholar] [CrossRef]
- Yang, K.; Tian, F.; Chen, L.; Li, S. Realized volatility forecast of agricultural futures using the HAR models with bagging and combination approaches. Int. Rev. Econ. Finance 2017, 49, 276–291. [Google Scholar] [CrossRef]
- Dai, X.; Sun, L.; Xu, Y. Short-Term Origin-Destination Based Metro Flow Prediction with Probabilistic Model Selection Approach. J. Adv. Transp. 2018, 2018, 5942763. [Google Scholar] [CrossRef]
- Ribeiro, M.H.D.M.; dos Santos Coelho, L. Ensemble approach based on bagging, boosting and stacking for short-term prediction in agribusiness time series. Appl. Soft Comput. 2020, 86, 105837. [Google Scholar] [CrossRef]
- Raju, S.M.T.U.; Sarker, A.; Das, A.; Islam, M.; Al-Rakhami, M.S.; Al-Amri, A.M.; Mohiuddin, T.; Albogamy, F.R. An Approach for Demand Forecasting in Steel Industries Using Ensemble Learning. Complexity 2022, 2022, 9928836. [Google Scholar] [CrossRef]
- Das Adhikari, N.C.; Garg, R.; Datt, S.; Das, L.; Deshpande, S.; Misra, A. Ensemble methodology for demand forecasting. In Proceedings of the 2017 International Conference on Intelligent Sustainable Systems (ICISS), Palladam, India, 7–8 December 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 846–851. [Google Scholar] [CrossRef]
- Wang, L.; Duan, W.; Qu, D.; Wang, S. What matters for global food price volatility? Empir. Econ. 2018, 54, 1549–1572. [Google Scholar] [CrossRef]
- Priyadarshi, R.; Panigrahi, A.; Routroy, S.; Garg, G.K. Demand forecasting at retail stage for selected vegetables: A performance analysis. J. Model. Manag. 2019, 14, 1042–1063. [Google Scholar] [CrossRef]
- Arora, T.; Chandna, R.; Conant, S.; Sadler, B.; Slater, R. Demand Forecasting In Wholesale Alcohol Distribution: An Ensemble Approach. SMU Data Sci. Rev. 2020, 3, 7. [Google Scholar]
- Sharma, A.; Shafiq, M.O. Predicting purchase probability of retail items using an ensemble learning approach and historical data. In Proceedings of the 2020 19th IEEE International Conference on Machine Learning and Applications (ICMLA), Miami, FL, USA, 14–17 December 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 723–728. [Google Scholar] [CrossRef]
- Zhang, Y.; Zhu, H.; Wang, Y.; Li, T. Demand Forecasting: From Machine Learning to Ensemble Learning. In Proceedings of the 2022 IEEE Conference on Telecommunications, Optics and Computer Science (TOCS), Dalian, China, 11–12 December 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 461–466. [Google Scholar] [CrossRef]
- Raizada, S.; Saini, J.R. Comparative Analysis of Supervised Machine Learning Techniques for Sales Forecasting. Int. J. Adv. Comput. Sci. Appl. 2021, 12, 102–110. [Google Scholar] [CrossRef]
- Ma, X.; Yin, Y.; Jin, Y.; He, M.; Zhu, M. Short-Term Prediction of Bike-Sharing Demand Using Multi-Source Data: A Spatial-Temporal Graph Attentional LSTM Approach. Appl. Sci. 2022, 12, 1161. [Google Scholar] [CrossRef]
- Chen, R.-C.; Dewi, C.; Huang, S.-W.; Caraka, R.E. Selecting critical features for data classification based on machine learning methods. J. Big Data 2020, 7, 52. [Google Scholar] [CrossRef]
- Khalid, S.; Khalil, T.; Nasreen, S. A survey of feature selection and feature extraction techniques in machine learning. In Proceedings of the 2014 Science and Information Conference (SAI), London, UK, 27–29 August 2014; IEEE: Piscataway, NJ, USA, 2014; pp. 372–378. [Google Scholar] [CrossRef]
- Grömping, U. Variable Importance Assessment in Regression: Linear Regression versus Random Forest. Am. Stat. 2009, 63, 308–319. [Google Scholar] [CrossRef]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Punia, S.; Nikolopoulos, K.; Singh, S.P.; Madaan, J.K.; Litsiou, K. Deep learning with long short-term memory networks and random forests for demand forecasting in multi-channel retail. Int. J. Prod. Res. 2020, 58, 4964–4979. [Google Scholar] [CrossRef]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V. Scikit-learn: Machine learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Geurts, P.; Ernst, D.; Wehenkel, L. Extremely randomized trees. Mach. Learn. 2006, 63, 3–42. [Google Scholar] [CrossRef]
- Almuhammadi, S.; Alnajim, A.; Ayub, M. QUIC Network Traffic Classification Using Ensemble Machine Learning Techniques. Appl. Sci. 2023, 13, 4725. [Google Scholar] [CrossRef]
- Abadi, M.; Agarwal, A.; Barham, P.; Brevdo, E.; Chen, Z.; Citro, C.; Corrado, G.S.; Davis, A.; Dean, J.; Devin, M.; et al. TensorFlow: Large-Scale Machine Learning on Heterogeneous Distributed Systems. arXiv 2016, arXiv:1603.04467. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Dou, Z.; Sun, Y.; Zhu, J.; Zhou, Z. The Evaluation Prediction System for Urban Advanced Manufacturing Development. Systems 2023, 11, 392. [Google Scholar] [CrossRef]
- Dou, Z.; Sun, Y.; Zhang, Y.; Wang, T.; Wu, C.; Fan, S. Regional Manufacturing Industry Demand Forecasting: A Deep Learning Approach. Appl. Sci. 2021, 11, 6199. [Google Scholar] [CrossRef]
- Shi, Y.; Zhang, L.; Lu, S.; Liu, Q. Short-Term Demand Prediction of Shared Bikes Based on LSTM Network. Electronics 2023, 12, 1381. [Google Scholar] [CrossRef]
- Salih, A.; Raisi-Estabragh, Z.; Galazzo, I.B.; Radeva, P.; Petersen, S.E.; Menegaz, G.; Lekadir, K. Commentary on explainable artificial intelligence methods: SHAP and LIME. arXiv 2023, arXiv:2305.02012. [Google Scholar]
- Brusa, E.; Cibrario, L.; Delprete, C.; Di Maggio, L.G. Explainable AI for Machine Fault Diagnosis: Understanding Features’ Contribution in Machine Learning Models for Industrial Condition Monitoring. Appl. Sci. 2023, 13, 2038. [Google Scholar] [CrossRef]
- Cordeiro-Costas, M.; Villanueva, D.; Eguía-Oller, P.; Martínez-Comesaña, M.; Ramos, S. Load Forecasting with Machine Learning and Deep Learning Methods. Appl. Sci. 2023, 13, 7933. [Google Scholar] [CrossRef]
- Wang, J.; Chong, W.K.; Lin, J.; Hedenstierna, C.P.T. Retail Demand Forecasting Using Spatial-Temporal Gradient Boosting Methods. J. Comput. Inf. Syst. 2023, 1–13. [Google Scholar] [CrossRef]
- Panda, S.K.; Mohanty, S.N. Time Series Forecasting and Modeling of Food Demand Supply Chain Based on Regressors Analysis. IEEE Access 2023, 11, 42679–42700. [Google Scholar] [CrossRef]
- Udokwu, C.; Brandtner, P.; Darbanian, F.; Falatouri, T. Improving Sales Prediction for Point-of-Sale Retail Using Machine Learning and Clustering. In Machine Learning and Data Analytics for Solving Business Problems. Unsupervised and Semi-Supervised Learning; Alyoubi, B., Ben Ncir, C.-E., Alharbi, I., Jarboui, A., Eds.; Springer International Publishing: Cham, Switzerland, 2022; pp. 55–73. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
| Publication | Year | Domain | Ensemble Algorithms | Features |
|---|---|---|---|---|
| [20] | 2016 | Crude oil price forecasting | EEMD and EELM | |
| [17] | 2016 | Tourism demand forecasting | Bagging, boosting, randomization, and stacking | |
| [8] | 2017 | Retail demand forecasting | Boosting | Daily sale, special days, and promotion days |
| [28] | 2017 | Supply chain demand forecasting | Averaging ensemble model | |
| [24] | 2017 | Agriculture commodities forecasting | Bagging | |
| [36] | 2017 | Hog price forecasting | EEMD | |
| [25] | 2018 | Metro passenger flow forecasting | Averaging ensemble model | Eight neighboring origin–destination (OD) flows are utilized as features for a single target OD flow |
| [29] | 2018 | Food price volatility forecasting | EEMD | |
| [30] | 2019 | Retail demand forecasting | Bagging (RFR) and boosting (GBR and XGBR) | Daily sales |
| [21] | 2019 | Electricity load time series forecasting | . | |
| [37] | 2020 | Energy load forecasting | ETB | Hour, DayOfWeek, IsWorking, Dewpnt, Drybulb, prior 1 h, prior 1 day, prior 1 week, and season |
| [31] | 2020 | Wholesale distribution demand forecasting | Weighted and non-weighted, depending on product | Monthly sales, product type, local weather, price promotions, marketing campaigns, holidays, and special events |
| [32] | 2020 | Retail purchase probability forecasting | RF, CNN, XGBoost, and voting classifier | Transactional data and newly generated features |
| [22] | 2022 | Electricity price forecasting | CatBoost | Hourly electricity price, hour of the day, weekend (the current day is weekend or not), and the day name |
| [26] | 2020 | Agribusiness prediction | Bagging (RFR), boosting (GBR and XGBR), and stacking (STACK) | |
| [38] | 2021 | Food and raw materials in restaurant forecasting | Stacking | Independent variables (year, month, date, day, weather conditions, public holidays, and festive season). Dependent variables (chicken niryani, mutton biryani, dal tadka, paneer lababdar, and curd rice) |
| [34] | 2021 | Retail demand forecasting | Extra tree regression | Date, weekly sales, holiday, temperature, fuel price, CPI, and unemployment |
| [33] | 2022 | Retail demand forecasting | Stacking | State, weekly sales, price |
| [27] | 2022 | Steel demand forecasting | Bagging (RFR), boosting (GBR and XGBR), and stacking (STACK) | Availability, raw materials, workers, working days, holidays, down time, and demand level |
| [18] | 2022 | Retail demand forecasting | Majority voting | Fifty-two features related to stores, customers, products, sales, orders, shipping, and delivery |
| Feature | Type |
|---|---|
| Demand value | Numeric |
| Price value | Numeric |
| Month of the year | Categorical–Nominal |
| Week of the year | Categorical–Nominal |
| Day of the week | Categorical–Nominal |
| Day of month | Categorical–Nominal |
| Special day status | Categorical–Nominal |
| Day after status | Categorical–Nominal |
| Day before status | Categorical–Nominal |
| COVID-19 lockdown type | Categorical–Nominal |
| Temperature | Numeric |
| Wind speed | Numeric |
| Precipitation | Numeric |
| Precipitation type | Categorical–Nominal |
| Product Category | Model Name | MAPE | MAE | RMSE | R2 |
|---|---|---|---|---|---|
| A | MA | 22.53% | 2053.06 | 2728.39 | 0.06 |
| ETR | 12.29% | 1141.47 | 1794.09 | 0.60 | |
| DL | 12.33% | 1199.89 | 1840.46 | 0.59 | |
| B | MA | 35.00% | 963.48 | 1216.12 | 0.05 |
| ETR | 12.48% | 431.92 | 805.47 | 0.58 | |
| DL | 16.63% | 569.69 | 922.02 | 0.45 | |
| C | MA | 27.08% | 5299.60 | 7745.05 | 0.01 |
| ETR | 10.56% | 2344.92 | 5193.20 | 0.55 | |
| DL | 12.33% | 2768.68 | 5549.90 | 0.48 |
| Product Category | Model Name | MAPE | MAE | RMSE | R2 |
|---|---|---|---|---|---|
| A | ETR | 12.29% | 1141.47 | 1794.09 | 0.60 |
| RFR | 12.44% | 1144.24 | 1828.58 | 0.58 | |
| GBR | 12.80% | 1179.25 | 1816.42 | 0.58 | |
| XGBOOST | 12.68% | 1157.18 | 1763.33 | 0.60 | |
| B | ETR | 12.48% | 431.92 | 805.47 | 0.58 |
| RFR | 12.66% | 432.70 | 796.95 | 0.59 | |
| GBR | 13.02% | 440.08 | 788.16 | 0.60 | |
| XGBOOST | 12.78% | 436.63 | 789.01 | 0.60 | |
| C | ETR | 10.56% | 2344.92 | 5193.20 | 0.55 |
| RFR | 10.71% | 2355.70 | 5215.72 | 0.54 | |
| GBR | 10.13% | 2224.36 | 5029.83 | 0.57 | |
| XGBOOST | 10.33% | 2269.65 | 5064.17 | 0.57 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Nasseri, M.; Falatouri, T.; Brandtner, P.; Darbanian, F. Applying Machine Learning in Retail Demand Prediction—A Comparison of Tree-Based Ensembles and Long Short-Term Memory-Based Deep Learning. Appl. Sci. 2023, 13, 11112. https://doi.org/10.3390/app131911112
Nasseri M, Falatouri T, Brandtner P, Darbanian F. Applying Machine Learning in Retail Demand Prediction—A Comparison of Tree-Based Ensembles and Long Short-Term Memory-Based Deep Learning. Applied Sciences. 2023; 13(19):11112. https://doi.org/10.3390/app131911112
Chicago/Turabian StyleNasseri, Mehran, Taha Falatouri, Patrick Brandtner, and Farzaneh Darbanian. 2023. "Applying Machine Learning in Retail Demand Prediction—A Comparison of Tree-Based Ensembles and Long Short-Term Memory-Based Deep Learning" Applied Sciences 13, no. 19: 11112. https://doi.org/10.3390/app131911112