
TransRFT: A Knowledge Representation Learning Model Based on a Relational Neighborhood and Flexible Translation


Abstract
:1. Introduction
2. TransRFT Model Principle and Training
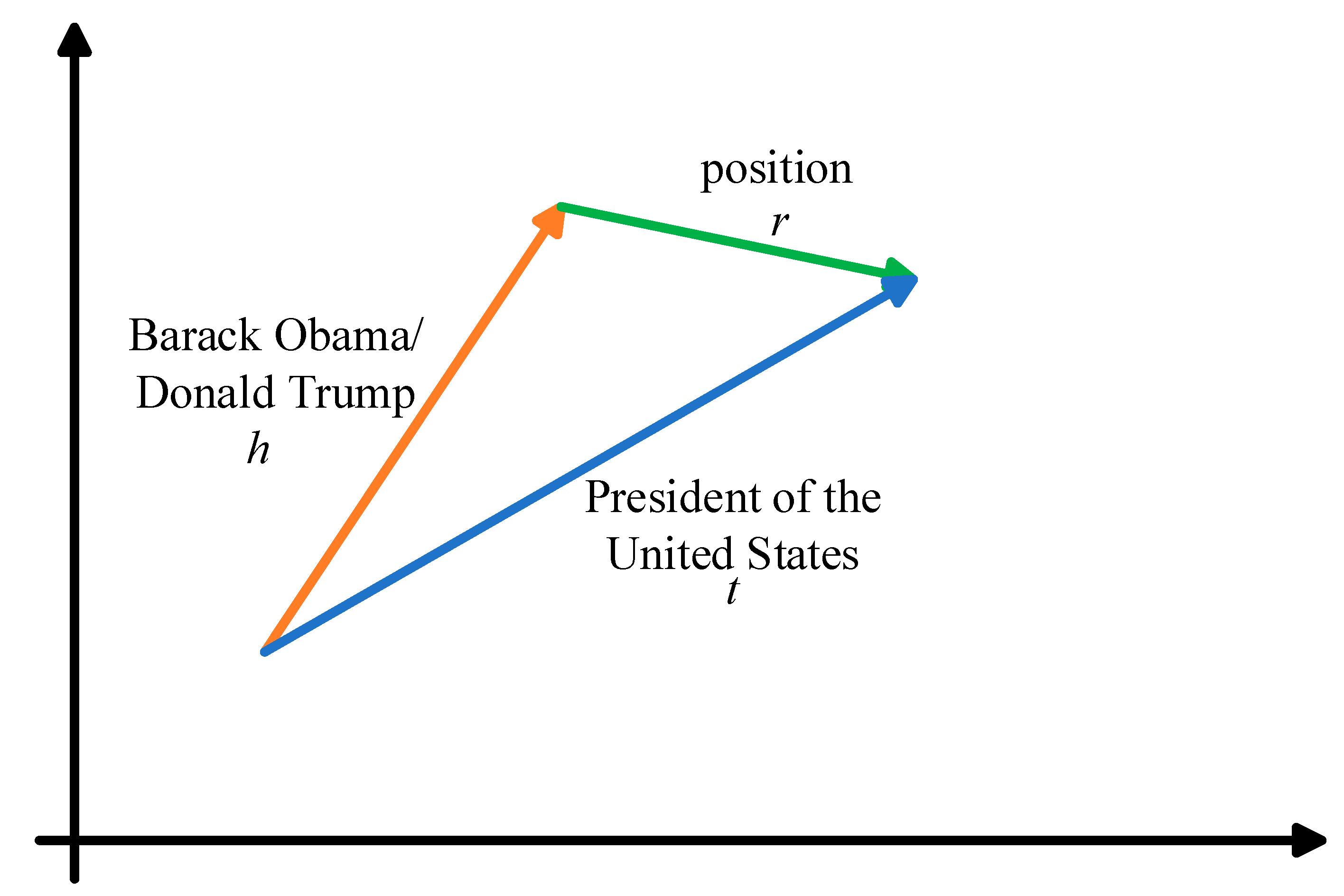
2.1. The TransRFT Model
2.2. Model Training
3. Experimental Results and Analysis
3.1. Dataset
3.2. Link Prediction
3.3. Triplet Classification
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Liang, K.; Liu, Y.; Zhou, S.; Tu, W.; Wen, Y.; Yang, X.; Dong, X.; Liu, X. Knowledge Graph Contrastive Learning Based on Relation-Symmetrical Structure. IEEE Trans. Knowl. Data Eng. 2023, 1, 1–12. [Google Scholar] [CrossRef]
- Jin, X.; Wah, B.W.; Cheng, X.; Wang, Y. Significance and challenges of big data research. Big Data Res. 2015, 2, 59–64. [Google Scholar] [CrossRef]
- Xiaohan, Z. A survey on application of knowledge graph. J. Phys. Conf. Ser. 2020, 1487, 012016. [Google Scholar]
- Amador-Domínguez, E.; Serrano, E.; Manrique, D. GEnI: A framework for the generation of explanations and insights of knowledge graph embedding predictions. Neurocomputing 2023, 521, 199–212. [Google Scholar] [CrossRef]
- Singhal, A. Introducing the knowledge graph: Things, not strings. Official Google Blog 6 May 2012.
- Gutiérrez, C.; Sequeda, J.F. Knowledge graphs. Commun. ACM 2021, 64, 96–104. [Google Scholar] [CrossRef]
- Lu, R.; Jin, X.; Zhang, S.; Qiu, M.; Wu, X. A study on big knowledge and its engineering issues. IEEE Trans. Knowl. Data Eng. 2018, 31, 1630–1644. [Google Scholar] [CrossRef]
- Wu, X.; Chen, H.; Wu, G.; Liu, J.; Zheng, Q.; He, X.; Zhou, A.; Zhao, Z.-Q.; Wei, B.; Li, Y.; et al. Knowledge engineering with big data. IEEE Intell. Syst. 2015, 30, 46–55. [Google Scholar] [CrossRef]
- Hugo, L.; Singh, P. ConceptNet—A practical commonsense reasoning tool-kit. BT Technol. J. 2004, 22, 211–226. [Google Scholar]
- Suchanek, F.M.; Kasneci, G.; Weikum, G. Yago: A core of semantic knowledge. In Proceedings of the 16th International Conference on World Wide Web, Banff, AB, Canada, 8–12 May 2007. [Google Scholar]
- Hoffart, J.; Suchanek, F.M.; Berberich, K.; Lewis-Kelham, E.; De Melo, G.; Weikum, G. YAGO2: Exploring and querying world knowledge in time, space, context, and many languages. In Proceedings of the 20th International Conference Companion on World Wide Web, Hyderabad, India, 28 March–1 April 2011. [Google Scholar]
- Biega, J.; Kuzey, E.; Suchanek, F.M. Inside YAGO2s: A transparent information extraction architecture. In Proceedings of the 22nd International Conference on World Wide Web, Rio de Janeiro, Brazil, 13–17 May 2013. [Google Scholar]
- Mahdisoltani, F.; Biega, J.; Suchanek, F.M. Yago3: A knowledge base from multilingual wikipedias. In Proceedings of the 7th Biennial Conference on Innovative Data Systems Research (CIDR 2015), Asilomar, CA, USA, 4–7 January 2013. [Google Scholar]
- Xu, B.; Xu, Y.; Liang, J.; Xie, C.; Liang, B.; Cui, W.; Xiao, Y. CN-DBpedia: A never-ending Chinese knowledge extraction system. In Proceedings of the 30th International Conference on Industrial Engineering and Other Applications of Applied Intelligent Systems (IEA/AIE 2017), Arras, France, 27–30 June 2017; Springer International Publishing: Cham, Switzerland, 2017. [Google Scholar]
- Mikolov, T.; Chen, K.; Corrado, G.; Dean, J. Efficient estimation of word representations in vector space. arXiv 2013, arXiv:1301.3781. [Google Scholar]
- Pennington, J.; Socher, R.; Manning, C.D. Glove: Global vectors for word representation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Bordes, A.; Weston, J.; Collobert, R.; Bengio, Y. Learning structured embeddings of knowledge bases. In Proceedings of the AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 7–11 August 2011; Volume 25. [Google Scholar]
- Socher, R.; Chen, D.; Manning, C.D.; Ng, A. Reasoning with neural tensor networks for knowledge base completion. In Proceedings of the 27th Conference on Neural Information Processing Systems, Lake Tahoe, NV, USA, 5–8 December 2013. [Google Scholar]
- Shi, B.; Weninger, T. Proje: Embedding projection for knowledge graph completion. In Proceedings of the AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017; Volume 31. [Google Scholar]
- Sun, Z.; Huang, J.; Hu, W.; Chen, M.; Guo, L.; Qu, Y. Transedge: Translating relation-contextualized embeddings for knowledge graphs. In Proceedings of the Semantic Web–ISWC 2019: 18th International Semantic Web Conference, Auckland, New Zealand, 26–30 October 2019; Proceedings Part I 18. Springer International Publishing: Berlin/Heidelberg, Germany, 2019. [Google Scholar]
- Yuan, J.; Gao, N.; Xiang, J. TransGate: Knowledge graph embedding with shared gate structure. In Proceedings of the 33rd AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; Volume 33. [Google Scholar]
- Cai, L.; Wang, W.Y. Kbgan: Adversarial learning for knowledge graph embeddings. arXiv 2017, arXiv:1711.04071. [Google Scholar]
- Bordes, A.; Glorot, X.; Weston, J.; Bengio, Y. A semantic matching energy function for learning with multi-relational data: Application to word-sense disambiguation. Mach. Learn. 2014, 94, 233–259. [Google Scholar] [CrossRef]
- Jenatton, R.; Roux, N.; Bordes, A.; Obozinski, G.R. A latent factor model for highly multi-relational data. In Proceedings of the 26th Annual Conference on Neural Information Processing Systems (NIPS), Lake Tahoe, NV, USA, 3–8 December 2012. [Google Scholar]
- Zolfaghari, M.; Zhu, Y.; Gehler, P.; Brox, T. Crossclr: Cross-modal contrastive learning for multi-modal video representations. In Proceedings of the IEEE/CVF 2021 International Conference on Computer Vision, Virtual Conference, 11–17 October 2021. [Google Scholar]
- Liu, Y. Contrastive multimodal fusion with tupleinfonce. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Virtual Conference, 11–17 October 2021. [Google Scholar]
- Liu, C.; Cheng, S.; Chen, C.; Qiao, M.; Zhang, W.; Shah, A.; Bai, W.; Arcucci, R. M-flag: Medical vision-language pre-training with frozen language models and latent space geometry optimization. arXiv 2023, arXiv:2307.08347. [Google Scholar]
- Wan, Z.; Liu, C.; Zhang, M.; Fu, J.; Wang, B.; Cheng, S.; Ma, L.; Quilodrán-Casas, C.; Arcucci, R. Med-UniC: Unifying Cross-Lingual Medical Vision-Language Pre-Training by Diminishing Bias. arXiv 2023, arXiv:2305.19894. [Google Scholar]
- Bordes, A.; Usunier, N.; Garcia-Duran, A.; Weston, J.; Yakhnenko, O. Translating embeddings for modeling multi-relational data. In Proceedings of the 26th International Conference on Neural Information Processing Systems (NIPS’13), Lake Tahoe, NV, USA, 5–10 December 2013. [Google Scholar]
- Wang, Z.; Zhang, J.; Feng, J.; Chen, Z. Knowledge graph embedding by translating on hyperplanes. In Proceedings of the AAAI Conference on Artificial Intelligence, Québec City, QC, Canada, 27–31 July 2014; Volume 28. [Google Scholar]
- Lin, Y.; Liu, Z.; Sun, M.; Liu, Y.; Zhu, X. Learning entity and relation embeddings for knowledge graph completion. In Proceedings of the AAAI Conference on Artificial Intelligence, Austin, TX, USA, 25–30 January 2015; Volume 29. [Google Scholar]
- Ji, G.; He, S.; Xu, L.; Liu, K.; Zhao, J. Knowledge graph embedding via dynamic mapping matrix. In Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing, Beijing, China, 26–31 July 2015; Volume 1: Long papers. [Google Scholar]
- Xiao, H.; Huang, M.; Hao, Y.; Zhu, X. TransA: An adaptive approach for knowledge graph embedding. arXiv 2015, arXiv:1509.05490. [Google Scholar]
- Zhou, X.; Niu, L.; Zhu, Q.; Zhu, X.; Liu, P.; Tan, J.; Guo, L. Knowledge graph embedding by double limit scoring loss. IEEE Trans. Knowl. Data Eng. 2021, 34, 5825–5839. [Google Scholar] [CrossRef]
- Zou, X.; Wang, X.; Cen, S.; Dai, G.; Liu, C. Knowledge graph embedding with self adaptive double-limited loss. Knowl. Based Syst. 2022, 252, 109310. [Google Scholar] [CrossRef]
- Zhu, J.-Z.; Jia, Y.-T.; Xu, J.; Qiao, J.-Z.; Cheng, X.-Q. Modeling the correlations of relations for knowledge graph embedding. J. Comput. Sci. Technol. 2018, 33, 323–334. [Google Scholar] [CrossRef]
- Baalbaki, H.; Hazimeh, H.; Harb, H.; Angarita, R. TransModE: Translational Knowledge Graph Embedding Using Modular Arithmetic. Procedia Comput. Sci. 2022, 207, 1154–1163. [Google Scholar] [CrossRef]
- Song, D.; Zhang, F.; Lu, M.; Yang, S.; Huang, H. DTransE: Distributed translating embedding for knowledge graph. IEEE Trans. Parallel Distrib. Syst. 2021, 32, 2509–2523. [Google Scholar] [CrossRef]
- Bordes, A.; Glorot, X.; Weston, J.; Bengio, Y. Joint learning of words and meaning representations for open-text semantic parsing. In Proceedings of the Artificial Intelligence and Statistics, Fifteenth International Conference on Artificial Intelligence and Statistics, La Palma, Canary Islands, 21–23 April 2012. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Entities | Relationships | Train | Verify | Test |
|---|---|---|---|---|---|
| WN18 | 40,943 | 18 | 141,442 | 5000 | 5000 |
| WN11 | 38,696 | 11 | 112,581 | 2609 | 10,544 |
| FB15K | 14,951 | 1345 | 483,142 | 50,000 | 59,071 |
| FB13 | 75,043 | 13 | 316,232 | 5908 | 23,733 |
| Date Sets | WN18 | FB15K | ||||||
|---|---|---|---|---|---|---|---|---|
| Metric | MeanRank | Hits@10/% | MeanRank | Hits@10/% | ||||
| Raw | Filt | Raw | Filt | Raw | Filt | Raw | Filt | |
| Unstructured [40] | 315 | 304 | 35.3 | 38.2 | 1074 | 979 | 4.5 | 6.3 |
| SE [18] | 1011 | 985 | 68.5 | 80.5 | 273 | 162 | 28.8 | 39.8 |
| SME (Linear) [24] | 545 | 533 | 65.1 | 74.1 | 274 | 154 | 30.7 | 40.8 |
| SME (Bilinear) [24] | 526 | 509 | 54.7 | 61.3 | 284 | 158 | 31.3 | 41.3 |
| LFM [25] | 469 | 456 | 71.4 | 81.6 | 283 | 164 | 26.0 | 33.1 |
| TransE [30] | 263 | 251 | 75.4 | 89.2 | 243 | 125 | 34.9 | 47.1 |
| TransH [31] | 401 | 388 | 73.0 | 82.3 | 212 | 87 | 45.7 | 64.4 |
| TransRFT (unif) | 307 | 290 | 78.3 | 93.0 | 171 | 24.1 | 53.1 | 83.1 |
| TransRFT (bern) | 304 | 288 | 78.4 | 92.8 | 140 | 37.5 | 53.9 | 80.0 |
| Method | Predicting Left (Hits@10) | Predicting Right (Hits@10) | ||||||
|---|---|---|---|---|---|---|---|---|
| 1-to-1 | 1-to-N | N-to-1 | N-to-N | 1-to-1 | 1-to-N | N-to-1 | N-to-N | |
| Unstructured [40] | 34.5 | 2.5 | 6.1 | 6.6 | 34.3 | 4.2 | 1.9 | 6.6 |
| SE [18] | 35.6 | 62.6 | 17.2 | 37.5 | 34.9 | 14.6 | 68.3 | 41.3 |
| SME (linear) [24] | 35.1 | 53.7 | 19.0 | 40.3 | 32.7 | 14.9 | 61.6 | 43.3 |
| SME (Bilinear) [24] | 30.9 | 69.6 | 19.9 | 38.6 | 28.2 | 13.1 | 76.0 | 41.8 |
| TransE [30] | 43.7 | 65.7 | 18.2 | 47.2 | 43.7 | 19.7 | 66.7 | 50.0 |
| TransH (unif) [31] | 66.7 | 81.7 | 30.2 | 57.4 | 63.7 | 30.1 | 83.2 | 67.2 |
| TransH (bern) [31] | 66.8 | 87.6 | 28.7 | 64.5 | 65.5 | 39.8 | 83.3 | 67.2 |
| TransRFT (unif) | 92.7 | 96.7 | 65.4 | 76.2 | 92.4 | 71.2 | 95.4 | 78.9 |
| TransRFT (bern) | 92.4 | 97.1 | 56.1 | 75.4 | 91.8 | 58.7 | 96.0 | 78.6 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wan, B.; Niu, Y.; Chen, C.; Zhou, Z. TransRFT: A Knowledge Representation Learning Model Based on a Relational Neighborhood and Flexible Translation. Appl. Sci. 2023, 13, 10864. https://doi.org/10.3390/app131910864
Wan B, Niu Y, Chen C, Zhou Z. TransRFT: A Knowledge Representation Learning Model Based on a Relational Neighborhood and Flexible Translation. Applied Sciences. 2023; 13(19):10864. https://doi.org/10.3390/app131910864
Chicago/Turabian StyleWan, Boyu, Yingtao Niu, Changxing Chen, and Zhanyang Zhou. 2023. "TransRFT: A Knowledge Representation Learning Model Based on a Relational Neighborhood and Flexible Translation" Applied Sciences 13, no. 19: 10864. https://doi.org/10.3390/app131910864