

Prediction and Comparison of In-Vehicle CO2 Concentration Based on ARIMA and LSTM Models

Abstract
:1. Introduction
- There are fewer studies on in-vehicle CO2 concentrations compared to studies on in-vehicle particulates.
- The models for in-vehicle CO2 concentration primarily rely on computational models that consider physical influencing factors, but these models still have some limitations.
- Due to their similar application domains, ARIMA and LSTM are frequently employed for comparative analysis of forecasting accuracy.
2. Materials and Methods
2.1. In-Vehicle CO2 Concentration by Field Dynamic Testing
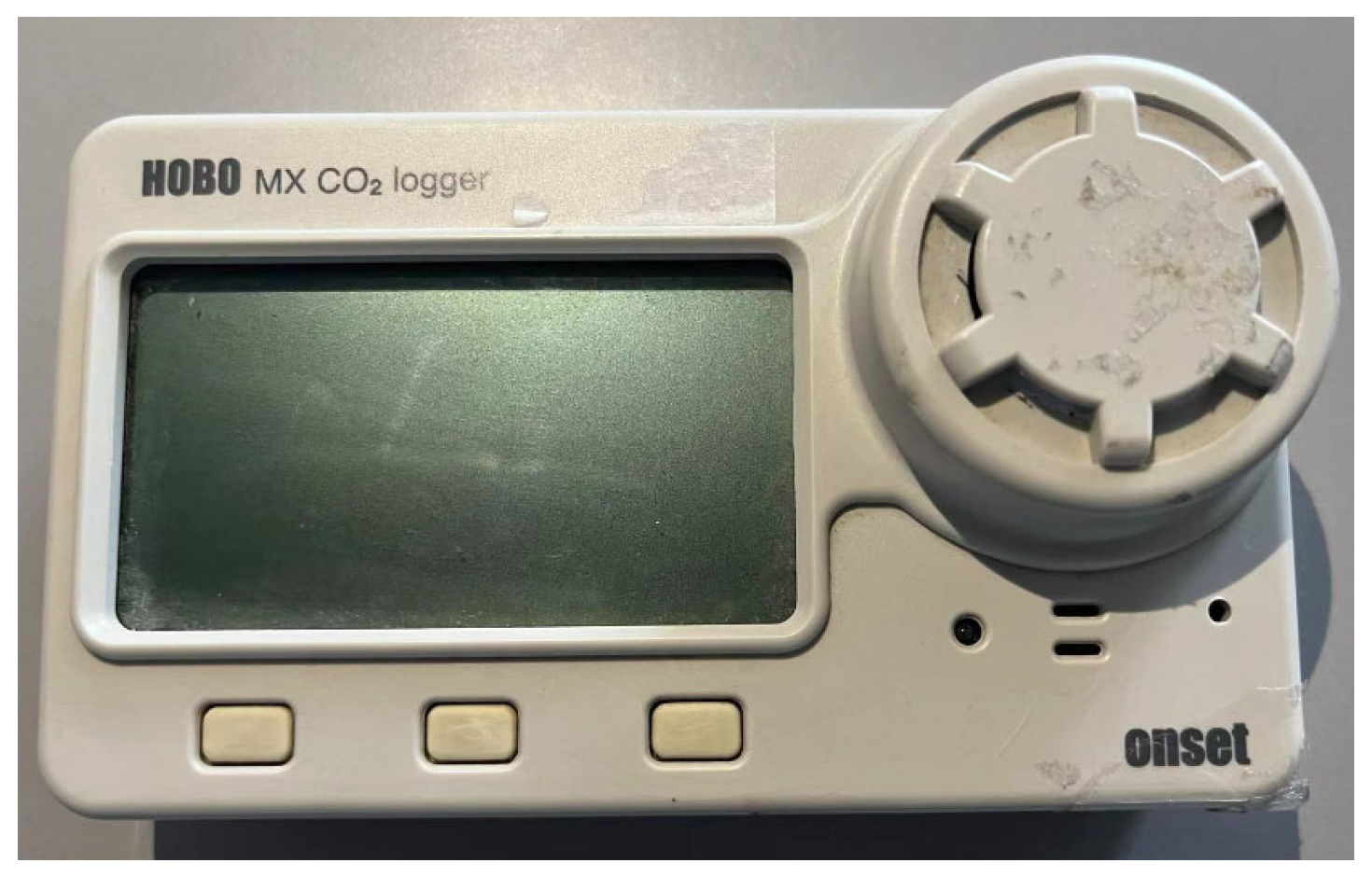
2.1.1. Test Subjects and Instrument Layout
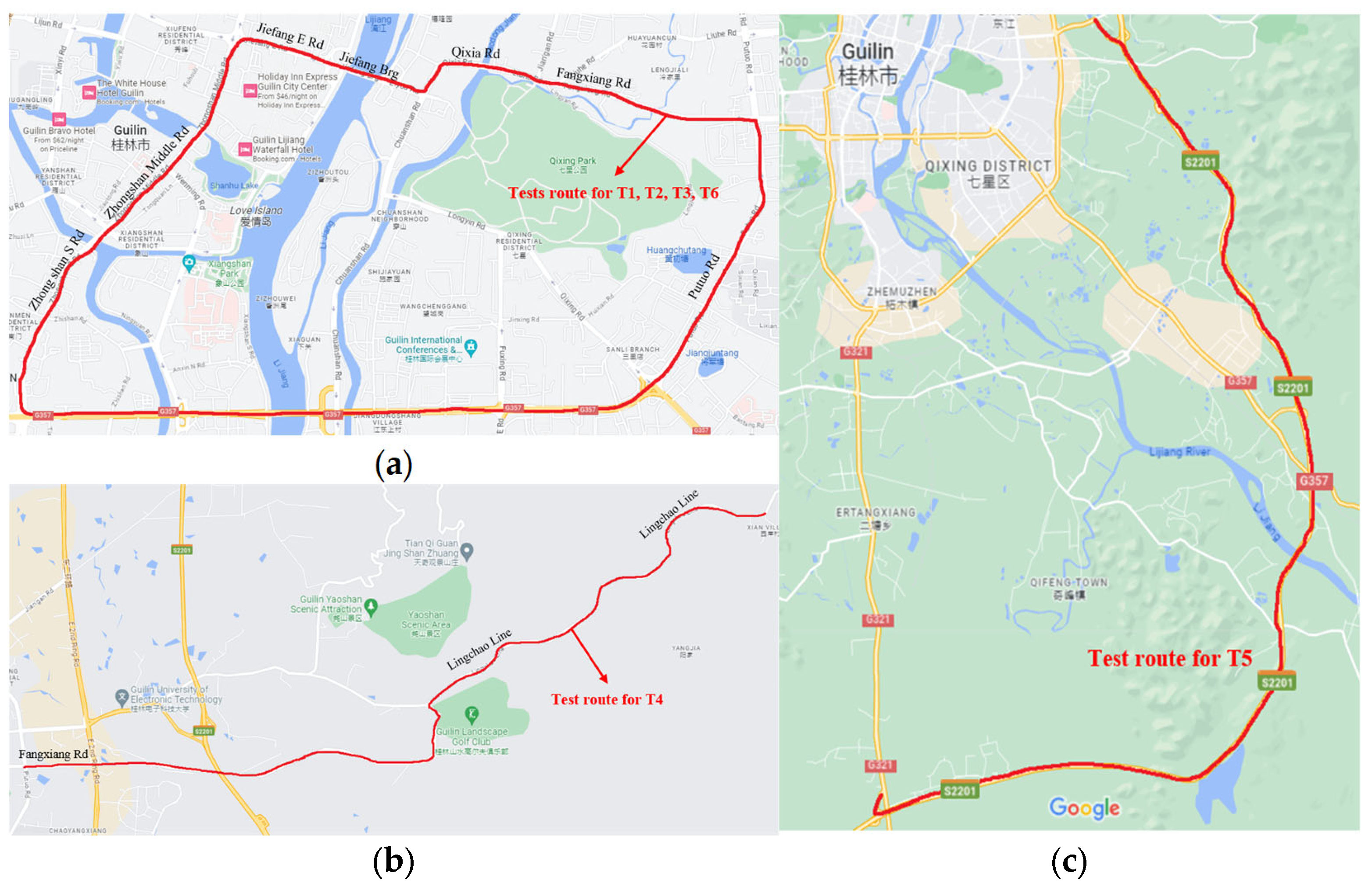
2.1.2. Test Location and Process
2.2. Prediction Models
2.2.1. ARIMA Model
- Data stationarity analysis: Prior to establishing an ARIMA prediction model, it is imperative to evaluate the stationarity of the data. The augmented Dickey–Fuller test (ADF) is employed to estimate whether the data are stationary or not in this research. If the data exhibit stability, the significance p-value should be less than 0.05; otherwise, differencing must be applied to non-stationary data until they achieve stationarity.
- Estimation of model hyperparameters: The stationary time series data are further processed to obtain the autocorrelation coefficient (ACF) and partial autocorrelation coefficient (PACF). After determining the range of hyperparameters p and q, it is necessary to continuously try to determine the combination of model hyperparameters with the highest accuracy, but this method has an interference of certain human factors. Therefore, the “auto. arima” function in Python can be utilized to automatically determine the optimal combination of hyperparameters, selecting the optimal model by means of the Akaike Information Criterion (AIC) and Bayesian Information Criterion (BIC), thereby eliminating any potential influence from human factors during the selection process. The range of AIC and BIC values is not fixed but varies across different datasets. Usually, the combination of hyperparameter p and q that yields the smallest AIC and BIC values represents the most suitable model. The calculation method for AIC and BIC is shown in Equations (4) and (5):
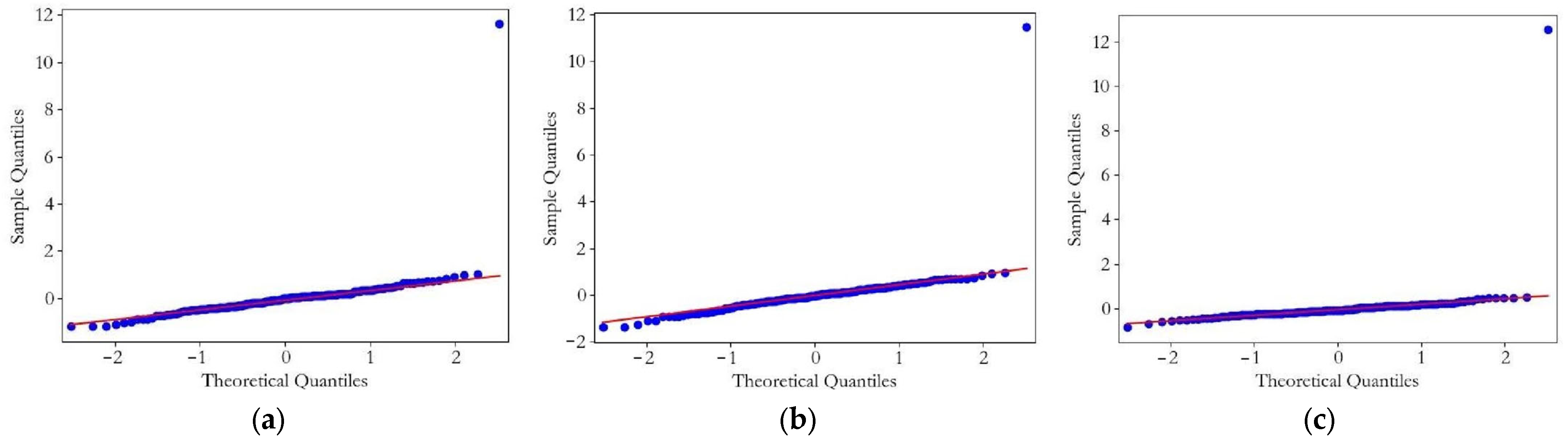
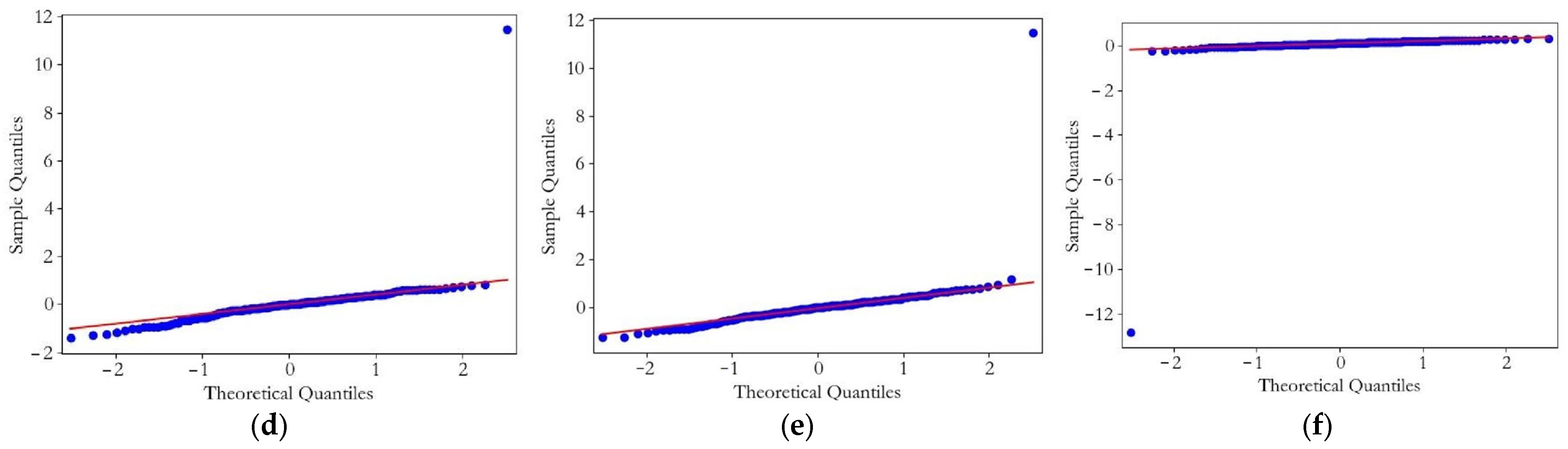
- Test the validity of the optimal model: Before forecasting, the effectiveness of the optimal model needs to be tested. Firstly, the Ljung–Box test method is used to judge whether the residual of the prediction model is a white noise sequence. If p-value > 0.05, it can be considered that the residual is a white noise sequence. Then, the Q test is used to check the normal distribution of the model residuals, and a Q–Q diagram is drawn to observe the distribution of the residuals.
- Forecast the data: After completing the aforementioned actions, predictions can be made.
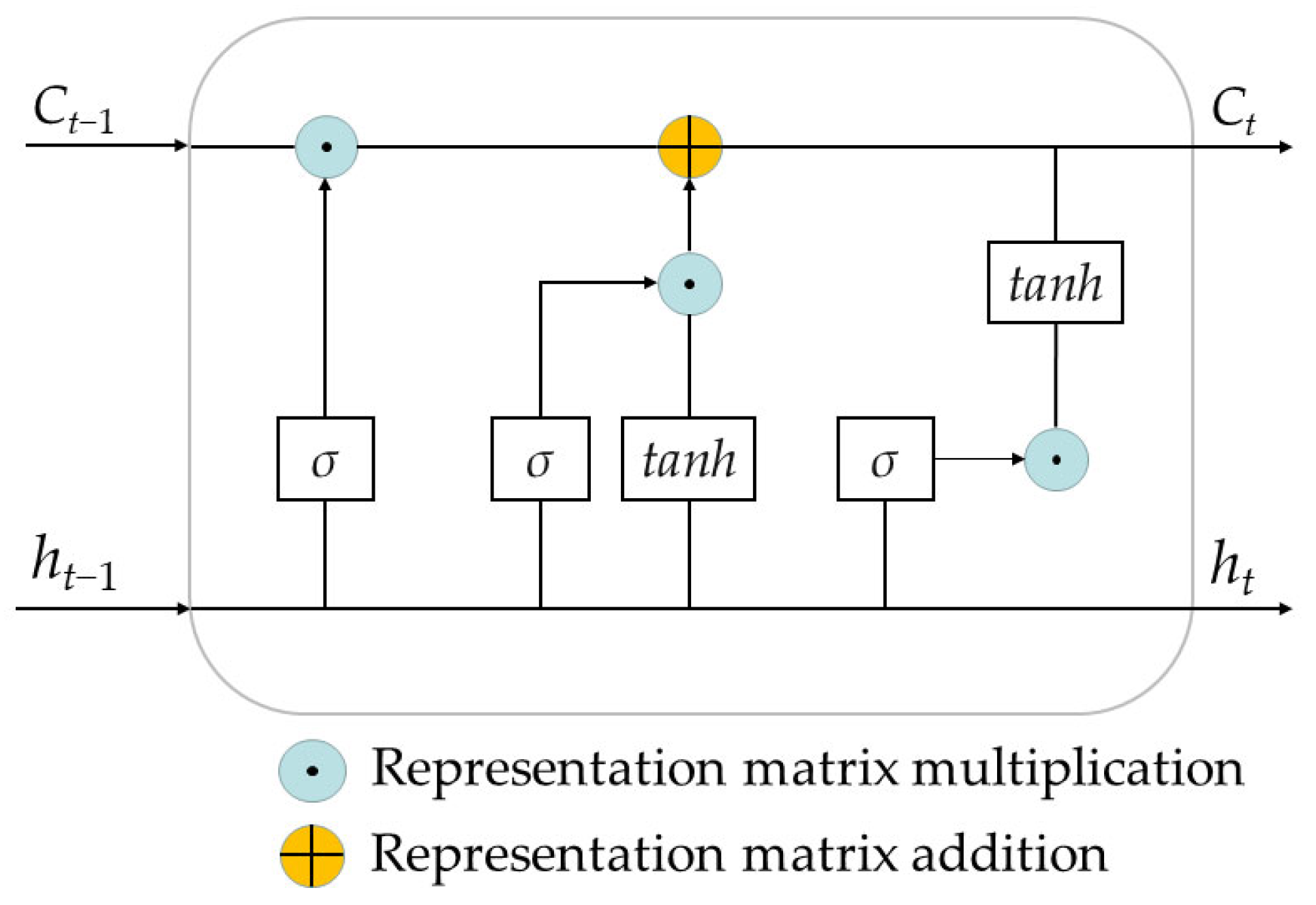
2.2.2. LSTM Model
- Data preprocessing: Data preprocessing can effectively reduce noise, eliminate redundant information, and extract key features from data to enhance the training and prediction performance of neural network models. This research employs the max-min normalization method for data preprocessing. This process ensures that all data values are reflected within the [0, 1] interval. The calculation method for normalization is as follows:
- Determining the neural network structure: Determine the inputs and outputs of the neural network and the number of neurons in the hidden layer.
- Network training: Determine the loss function, activation function, optimizer, and other parameters utilized for training the LSTM network. The loss function adopts the mean squared error (MSE) as the criterion for evaluation. The computation of the MSE is illustrated below:
- Make predictions: After the aforementioned steps have been completed, the trained model can be utilized for predictions.
2.3. Evaluation Indicators
3. Results
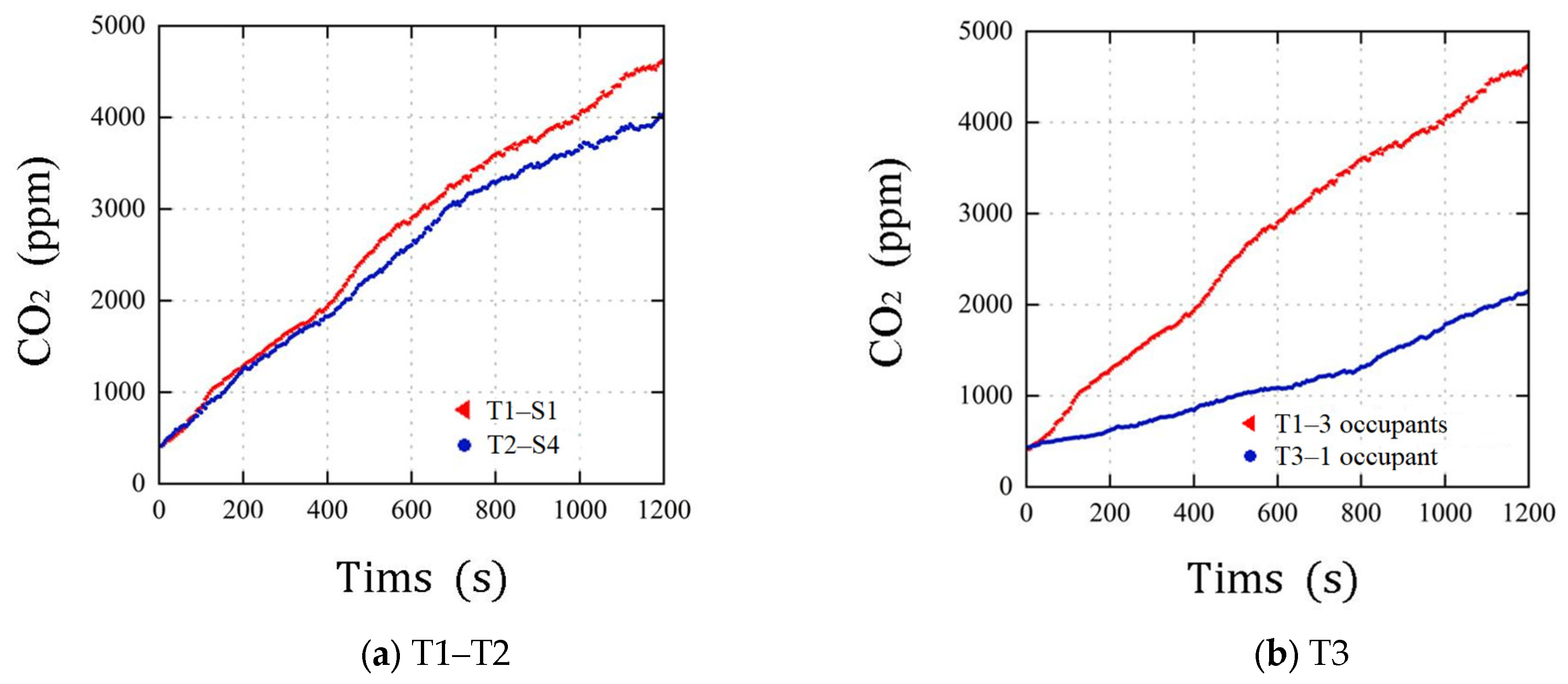
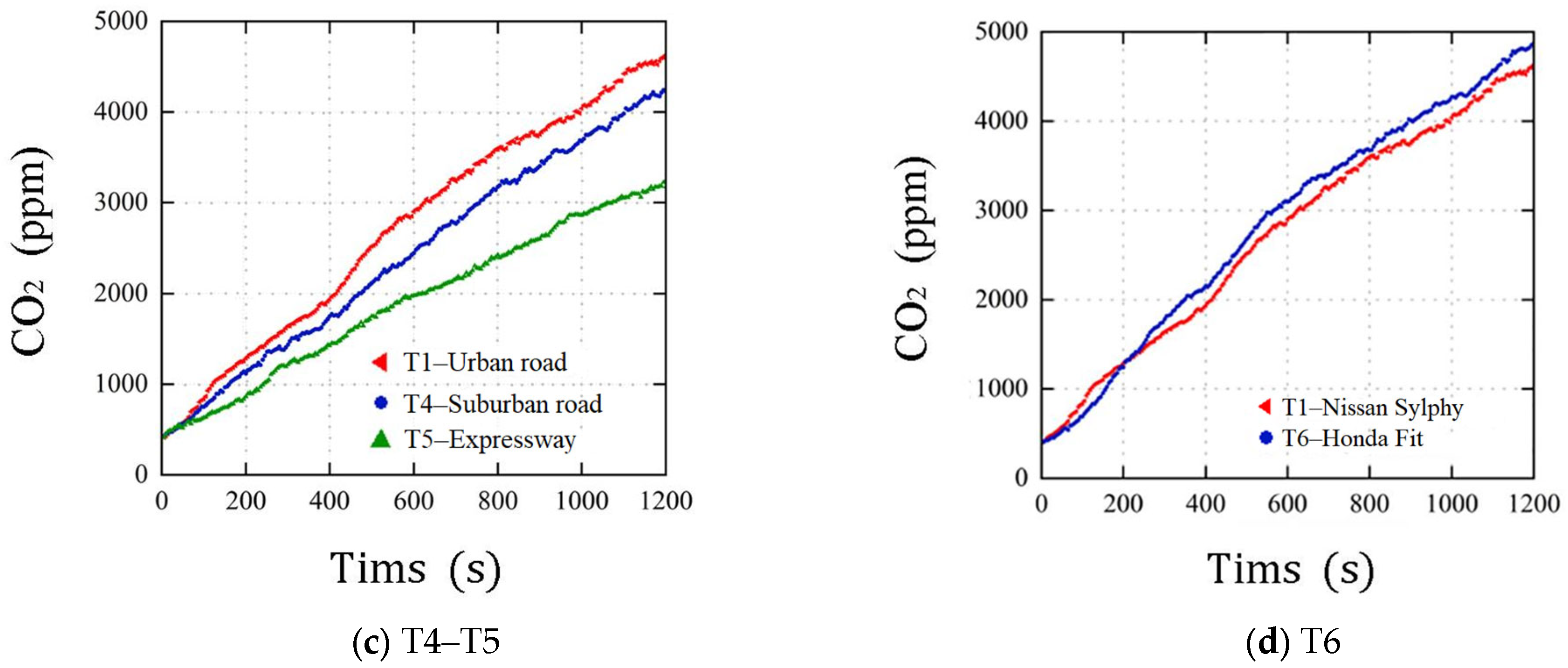
3.1. Analysis of In-Vehicle CO2 Concentration
3.2. Fitting Models and Prediction Result Analysis
3.2.1. ARIMA Model
3.2.2. LSTM Model
- Input layer: After continuous debugging of the size of the time window, it was found that the error is the smallest when the number of time windows is three. Therefore, the neuron dimension of three has been selected for our input layer.
- Output layer: Since our goal is to forecast CO2 concentration for future moments, the number of neurons in the output layer is therefore determined to be one.
- Hidden layer: In this research, we utilized a sequential model in Keras, which is comprised of one LSTM layer and one dense layer. The neuron dimension of the first hidden layer is 64, and the second hidden layer has a neuron dimension of 1.
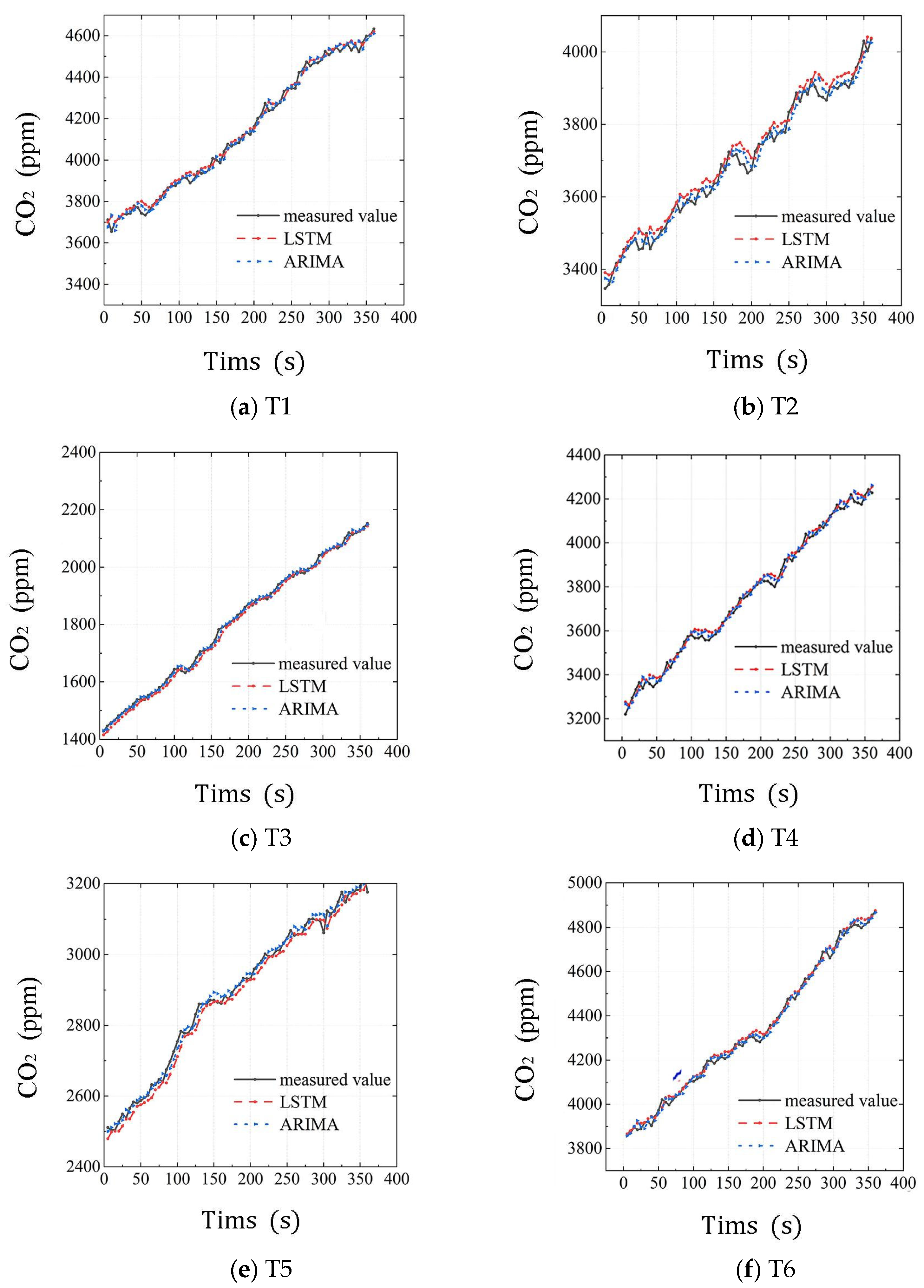
3.2.3. Results of Model Predictions and Comparative Analysis
4. Discussion
5. Conclusions and Future Work
- The measured data indicate that with closed vehicle windows and internal circulation turned on, the concentration of CO2 in a vehicle increases proportionally to driving time. Under all test conditions, the average CO2 concentration within 20 min exceeds the standard limit of 1000 ppm. During driving, it is necessary to improve vehicle ventilation by opening windows, switching to outside air mode, and using other methods.
- Both the ARIMA and LSTM models are capable of accurately predicting changes in the CO2 concentration within a vehicle. However, the MAPE and RMSE values obtained from the ARIMA model’s predictions are lower than those produced by the LSTM model. Therefore, the ARIMA model is more accurate in predicting changes in the CO2 concentration within a vehicle compared to the LSTM model.
- The prediction performance of LSTM is not always better than the ARIMA model, and the two models need to be selected according to the characteristics of the data. When the amount of data used for training reaches 1000, it is better to use LSTM, and it is more appropriate to use ARIMA when the amount of data is within 100, but comparative analysis is required when the amount of data is within 100–1000.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Nomenclature
| c | Constant |
| p | p–order of autoregressive model |
| Yt | Time series |
| α1, α2, α3, …, αp | Autoregressive coefficient |
| εt | White noise sequence (uncorrelated with the previous moment value) |
| q | q–order of moving average |
| β1, β2, β3, …, βq | The moving average coefficient |
| d | The number of differencing required to achieve stationarity in the data |
| k | The number of model parameters |
| n | Sample size |
| L | Likelihood function |
| xt | The input value of the network at the current moment |
| ht−1 | The output value of the LSTM at the previous moment |
| [ht−1, xt] | The two vectors are joined to form a longer vector |
| Wo | Weight |
| bo | Bias term |
| σ | Sigmoid function |
| ft | The output value of the forget gate |
| Ct−1 | The state of the unit at the previous moment |
| Ct | The state of the unit at the current moment |
| The updated value of the input gate | |
| tanh | Tanh activation function |
| min(xi) | The minimum value of the i–th attribute in x |
| max(xi) | The maximum value of the i–th attribute in x |
| yi | Measured value |
| ŷi | Predicted value |
| air change rate | The rate at which air is exchanged between the enclosed environment and the surrounding environment |
| air leakage | The uncontrolled exchange of air between in-vehicle environment and the external environment |
References
- Gladyszewska-Fiedoruk, K. Concentrations of carbon dioxide in a car. Transp. Res. Part D Transp. Environ. 2011, 16, 166–171. [Google Scholar] [CrossRef]
- Jones, A.P. Indoor air quality and health. Atmos. Environ. 1999, 33, 4535–4564. [Google Scholar] [CrossRef]
- ASHRAE. Position Document on Indoor Air Quality. Available online: https://www.ashrae.org/file%20library/about/position%20documents/pd_indoor-air-quality-2020-07-01.pdf (accessed on 18 September 2023).
- Jayasankar, P.; Subbaian, J. Optimization of in-Vehicle Carbon Dioxide Level in a 5-Seat Car. Strojniški Vestnik J. Mech. Eng. 2022, 68, 471–484. [Google Scholar] [CrossRef]
- Lim, S.; Mudway, I.; Molden, N.; Holland, J.; Barratt, B. Identifying trends in ultrafine particle infiltration and carbon dioxide ventilation in 92 vehicle models. Sci. Total Environ. 2022, 812, 152521. [Google Scholar] [CrossRef]
- Luangprasert, M.; Vasithamrong, C.; Pongratananukul, S.; Chantranuwathana, S.; Pumrin, S.; De Silva, I. In-vehicle carbon dioxide concentration in commuting cars in Bangkok, Thailand. J. Air Waste Manag. Assoc. 2017, 67, 623–633. [Google Scholar] [CrossRef]
- Tolis, E.I.; Karanotas, T.; Svolakis, G.; Panaras, G.; Bartzis, J.G. Air quality in cabin environment of different passenger cars: Effect of car usage, fuel type and ventilation/infiltration conditions. Environ. Sci. Pollut. Res. 2021, 28, 51232–51241. [Google Scholar] [CrossRef]
- Moreno, T.; Pacitto, A.; Fernández, A.; Amato, F.; Marco, E.; Grimalt, J.O.; Buonanno, G.; Querol, X. Vehicle interior air quality conditions when travelling by taxi. Environ. Res. 2019, 172, 529–542. [Google Scholar] [CrossRef]
- Barnes, N.M.; Ng, T.W.; Ma, K.K.; Lai, K.M. In-cabin air quality during driving and engine idling in air-conditioned private vehicles in Hong Kong. Int. J. Environ. Res. Public Health 2018, 15, 611. [Google Scholar] [CrossRef]
- Chan, A.T. Commuter exposure and indoor-outdoor relationships of carbon oxides in buses in Hong Kong. Atmos. Environ. 2003, 37, 3809–3815. [Google Scholar] [CrossRef]
- Chiu, C.; Chen, M.; Chang, F. Carbon dioxide concentrations and temperatures within tour buses under real-time traffic conditions. PLoS ONE 2015, 10, e125117. [Google Scholar] [CrossRef]
- Querol, X.; Alastuey, A.; Moreno, N.; Minguillón, M.C.; Moreno, T.; Karanasiou, A.; Jimenez, J.L.; Li, Y.; Morguí, J.A.; Felisi, J.M. How can ventilation be improved on public transportation buses? Insights from CO2 measurements. Environ. Res. 2022, 205, 112451. [Google Scholar] [CrossRef]
- Zhao, Y.; Jiang, C.; Song, X. Seasonal patterns and semi-empirical modeling of in-vehicle exposure to carbon dioxide and airborne particulates in Dalian, China. Atmos. Environ. 2022, 274, 118968. [Google Scholar] [CrossRef]
- Tong, Z.; Li, Y.; Westerdahl, D.; Adamkiewicz, G.; Spengler, J.D. Exploring the effects of ventilation practices in mitigating in-vehicle exposure to traffic-related air pollutants in China. Environ. Int. 2019, 127, 773–784. [Google Scholar] [CrossRef]
- ASHRAE. Position Document on Indoor Carbon Dioxide. Available online: https://www.ashrae.org/File%20Library/About/Position%20Documents/PD_IndoorCarbonDioxide_2022.pdf (accessed on 18 September 2023).
- OSHA Technical Manual (OTM). Section III: Chapter 2. Available online: https://www.osha.gov/otm/section-3-health-hazards/chapter-2 (accessed on 18 September 2023).
- GB/T 18883-2022; Standards for Indoor Air Quality. Standards Press of China: Beijing, China, 2022.
- Constantin, D.; Mazilescu, C.-A.; Nagi, M.; Draghici, A.; Mihartescu, A.-A. Perception of Cabin Air Quality among Drivers and Passengers. Sustainability 2016, 8, 852. [Google Scholar] [CrossRef]
- Zhang, X.; Wargocki, P.; Lian, Z. Effects of exposure to carbon dioxide and human bioeffluents on cognitive performance. Procedia Eng. 2015, 121, 138–142. [Google Scholar] [CrossRef]
- Satish, U.; Mendell, M.J.; Shekhar, K.; Hotchi, T.; Sullivan, D.; Streufert, S.; Fisk, W.J. Is CO2 an indoor pollutant? Direct effects of low-to-moderate CO2 concentrations on human decision-making performance. Environ. Health Perspect. 2012, 120, 1671–1677. [Google Scholar] [CrossRef]
- Allen, J.G.; MacNaughton, P.; Satish, U.; Santanam, S.; Vallarino, J.; Spengler, J.D. Associations of cognitive function scores with carbon dioxide, ventilation, and volatile organic compound exposures in office workers: A controlled exposure study of green and conventional office environments. Environ. Health Perspect. 2016, 124, 805–812. [Google Scholar] [CrossRef]
- Hudda, N.; Fruin, S.A. Carbon dioxide accumulation inside vehicles: The effect of ventilation and driving conditions. Sci. Total Environ. 2018, 610, 1448–1456. [Google Scholar] [CrossRef]
- Goh, C.C.; Kamarudin, L.M.; Zakaria, A.; Nishizaki, H.; Ramli, N.; Mao, X.; Zakaria, S.M.M.S.; Kanagaraj, E.; Sukor, A.S.A.; Elham, F. Real-time in-vehicle air quality monitoring system using machine learning prediction algorithm. Sensors 2021, 21, 4956. [Google Scholar] [CrossRef]
- Tefft, B.C. Prevalence of motor vehicle crashes involving drowsy drivers, United States, 1999–2008. Accid. Anal. Prev. 2012, 45, 180–186. [Google Scholar] [CrossRef]
- Han, H.; Li, K.; Li, Y. Monitoring driving in a monotonous environment: Classification and recognition of driving fatigue based on long short-term memory network. J. Adv. Transp. 2022, 2022, 6897781. [Google Scholar] [CrossRef]
- Jung, H. Modeling CO2 Concentrations in Vehicle Cabin. SAE Tech. Pap. 2013, 1, 1497. [Google Scholar]
- Mathur, G.D. Development of a Model to Predict Build-Up of Cabin Carbon Dioxide Concentrations in Automobiles for Indoor Air Quality. SAE Tech. Pap. 2017, 1, 163. [Google Scholar]
- Lohani, D.; Barthwal, A.; Acharya, D. Modeling vehicle indoor air quality using sensor data analytics. J. Reliab. Intell. Environ. 2022, 8, 105–115. [Google Scholar] [CrossRef]
- Lee, S.J.; Kim, J.M.; Keum, H.R.; Kim, S.W.; Baek, H.S.; Byun, J.C.; Kim, Y.K.; Kim, S.; Lee, J.M. Seasonal Trends in the Prevalence and Incidence of Viral Encephalitis in Korea (2015–2019). J. Clin. Med. 2023, 12, 2003. [Google Scholar] [CrossRef]
- Al-Rashedi, A.; Al-Hagery, M.A. Deep Learning Algorithms for Forecasting COVID-19 Cases in Saudi Arabia. Appl. Sci. 2023, 13, 1816. [Google Scholar] [CrossRef]
- Zhang, B. Research on fixed assets investment forecast based on arima model. In Proceedings of the 2019 International Conference on Economic Management and Model Engineering (ICEMME), Malaysia, Malacca, 6–8 December 2019. [Google Scholar]
- Wang, Y.; Guo, Y. Forecasting method of stock market volatility in time series data based on mixed model of ARIMA and XGBoost. China Commun. 2020, 17, 205–221. [Google Scholar] [CrossRef]
- Lin, W.; Shi, Y. A Study on the Development of China’s Financial Leasing Industry Based on Principal Component Analysis and ARIMA Model. Sustainability 2023, 15, 9913. [Google Scholar] [CrossRef]
- Tatarintsev, M.; Korchagin, S.; Nikitin, P.; Gorokhova, R.; Bystrenina, I.; Serdechnyy, D. Analysis of the Forecast Price as a Factor of Sustainable Development of Agriculture. Agronomy 2021, 11, 1235. [Google Scholar] [CrossRef]
- El Amri, A.; M’nassri, S.; Nasri, N.; Nsir, H.; Majdoub, R. Nitrate concentration analysis and prediction in a shallow aquifer in central-eastern Tunisia using artificial neural network and time series modelling. Environ. Sci. Pollut. Res. 2022, 29, 43300–43318. [Google Scholar] [CrossRef]
- Merdasse, M.; Hamdache, M.; Peláez, J.A.; Henares, J.; Medkour, T. Earthquake Magnitude and Frequency Forecasting in Northeastern Algeria using Time Series Analysis. Appl. Sci. 2023, 13, 1566. [Google Scholar] [CrossRef]
- Kumar, P.B.; Hariharan, K. Time Series Traffic Flow Prediction with Hyper-Parameter Optimized ARIMA Models for Intelligent Transportation System. J. Sci. Ind. Res. 2022, 81, 408–415. [Google Scholar]
- Chen, J.; Li, D.; Zhang, G.; Zhang, X. Localized space-time autoregressive parameters estimation for traffic flow prediction in urban road networks. Appl. Sci. 2018, 8, 277. [Google Scholar] [CrossRef]
- Acar, B.; Yiğit, S.; Tuzuner, B.; Özgirgin, B.; Ekiz, İ.; Özbiltekin-Pala, M.; Ekinci, E. Electricity Consumption Forecasting in Turkey. In Digitizing Production Systems: Selected Papers from ISPR2021, Online, Turkey, 7–9 October 2022; Springer: Cham, Switzerland, 2022. [Google Scholar]
- De Santos, D.S.O., Jr.; de Mattos Neto, P.S.; de Oliveira, J.F.; Siqueira, H.V.; Barchi, T.M.; Lima, A.R.; Madeiro, F.; Dantas, D.A.; Converti, A.; Pereira, A.C.; et al. Solar irradiance forecasting using dynamic ensemble selection. Appl. Sci. 2022, 12, 3510. [Google Scholar]
- Wang, X.G.; Zhu, J.W.; Zhang, A.X. Method of Voiceprint ldentity Based on ARIMA Prediction of MFCC Features. Comput. Sci. 2022, 49, 92–97. (In Chinese) [Google Scholar]
- Kaur, J.; Parmar, K.S.; Singh, S. Autoregressive models in environmental forecasting time series: A theoretical and application review. Environ. Sci. Pollut. Res. 2023, 30, 19617–19641. [Google Scholar] [CrossRef]
- Graves, A.; Graves, A. Long Short-Term Memory. In Supervised Sequence Labelling with Recurrent Neural Networks; Springer: Berlin/Heidelberg, Germany, 2012; pp. 37–45. [Google Scholar]
- Guo, Y.; Feng, Y.; Qu, F.; Zhang, L.; Yan, B.; Lv, J. Prediction of hepatitis E using machine learning models. PLoS ONE 2020, 15, e237750. [Google Scholar] [CrossRef]
- Long, B.; Tan, F.; Newman, M. Forecasting the Monkeypox Outbreak Using ARIMA, Prophet, NeuralProphet, and LSTM Models in the United States. Forecasting 2023, 5, 5. [Google Scholar] [CrossRef]
- Gu, J.; Liang, L.; Song, H.; Kong, Y.; Ma, R.; Hou, Y.; Zhao, J.; Liu, J.; He, N.; Zhang, Y. A method for hand-foot-mouth disease prediction using GeoDetector and LSTM model in Guangxi, China. Sci. Rep. 2019, 9, 17928. [Google Scholar] [CrossRef]
- Wang, G.; Wei, W.; Jiang, J.; Ning, C.; Chen, H.; Huang, J.; Liang, B.; Zang, N.; Liao, Y.; Chen, R.; et al. Application of a long short-term memory neural network: A burgeoning method of deep learning in forecasting HIV incidence in Guangxi, China. Epidemiol. Infect. 2019, 147, e194. [Google Scholar] [CrossRef]
- Majeed, M.A.; Shafri, H.Z.M.; Zulkafli, Z.; Wayayok, A. A Deep Learning Approach for Dengue Fever Prediction in Malaysia Using LSTM with Spatial Attention. Int. J. Environ. Res. Public Health 2023, 20, 4130. [Google Scholar] [CrossRef]
- Peng, Z.; Guo, P. A data organization method for LSTM and transformer when predicting Chinese banking stock prices. Discret. Dyn. Nat. Soc. 2022, 2022, 7119678. [Google Scholar] [CrossRef]
- Chen, S.; Ge, L. Exploring the attention mechanism in LSTM-based Hong Kong stock price movement prediction. Quant. Financ. 2019, 19, 1507–1515. [Google Scholar] [CrossRef]
- Fu, X.; Wu, M.; Ponnarasu, S.; Zhang, L. A Hybrid Deep Learning Approach for Real-Time Estimation of Passenger Traffic Flow in Urban Railway Systems. Buildings 2023, 13, 1514. [Google Scholar] [CrossRef]
- Choi, J. Predicting the Frequency of Marine Accidents by Navigators’ Watch Duty Time in South Korea Using LSTM. Appl. Sci. 2022, 12, 11724. [Google Scholar] [CrossRef]
- Coto-Jiménez, M. Improving post-filtering of artificial speech using pre-trained LSTM neural networks. Biomimetics 2019, 4, 39. [Google Scholar] [CrossRef]
- Liu, Y.; Zhang, W.; Yan, Y.; Li, Z.; Xia, Y.; Song, S. An Effective Rainfall–Ponding Multi-Step Prediction Model Based on LSTM for Urban Waterlogging Points. Appl. Sci. 2022, 12, 12334. [Google Scholar] [CrossRef]
- Xu, T.; Zhou, Z.; Li, Y.; Wang, C.; Liu, Y.; Rong, T. Short-Term Prediction of Global Sea Surface Temperature Using Deep Learning Networks. J. Mar. Sci. Eng. 2023, 11, 1352. [Google Scholar] [CrossRef]
- Tsan, Y.-T.; Chen, D.-Y.; Liu, P.-Y.; Kristiani, E.; Nguyen, K.L.P.; Yang, C.-T. The prediction of influenza-like illness and respiratory disease using LSTM and ARIMA. Int. J. Environ. Res. Public Health 2022, 19, 1858. [Google Scholar] [CrossRef]
- Xiao, D.; Su, J. Research on Stock Price Time Series Prediction Based on Deep Learning and Autoregressive Integrated Moving Average. Sci. Program. 2022, 2022, 4758698. [Google Scholar] [CrossRef]
- Elsaraiti, M.; Merabet, A. A comparative analysis of the arima and lstm predictive models and their effectiveness for predicting wind speed. Energies 2021, 14, 6782. [Google Scholar] [CrossRef]
- Xu, Y.M.; Chen, Y. Comparison Between Seasonal ARIMA Model and LSTM Neural Network Forecast. Stat. Decis. 2021, 37, 46–50. (In Chinese) [Google Scholar]
- Ning, Y.; Kazemi, H.; Tahmasebi, P. A comparative machine learning study for time series oil production forecasting: ARIMA, LSTM, and Prophet. Comput. Geosci. 2022, 164, 105126. [Google Scholar] [CrossRef]
- Peng, H.X.; Zheng, K.H.; Huang, G.B.; Lin, D.S.; Yang, Z.C.; Liu, H.D. Vegetable price prediction based on BP LSTM and ARIMA models. J. Chin. Agric. Mech. 2020, 41, 193–199. (In Chinese) [Google Scholar]
- Zhang, R.; Song, H.; Chen, Q.; Wang, Y.; Wang, S.; Li, Y. Comparison of ARIMA and LSTM for prediction of hemorrhagic fever at different time scales in China. PLoS ONE 2022, 17, e262009. [Google Scholar] [CrossRef]
- Wang, Y.; Mi, X. A comparative study on demand forecast of car sharing users based on ARIMA and LSTM. In Proceedings of the 2020 5th International Conference on Electromechanical Control Technology and Transportation (ICECTT), Nanchang, China, 15–17 May 2020. [Google Scholar]
- Parameter Configuration of Nissan-Sylphy. Available online: https://car.autohome.com.cn/config/spec/57275.html#pvareaid=3454495 (accessed on 18 September 2023). (In Chinese).
- Parameter Configuration of Honda-Fit. Available online: https://car.autohome.com.cn/config/spec/47239.html#pvareaid=3454495 (accessed on 18 September 2023). (In Chinese).
- Government Service Platform of the Ministry of Industry and Information Technology in China-Inquiry of Vehicle Energy Consumption. Available online: https://yhgscx.miit.gov.cn/fuel-consumption-web/mainPage (accessed on 23 September 2023). (In Chinese)
- Box, G.E.P.; Jenkins, G.M. Time Series Analysis: Forecasting and Control/Holden Day, San Francisco, California, 1970; John Wiley & Sons: Hoboken, NJ, USA, 2015. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Gers, F.A.; Schmidhuber, J.; Cummins, F. Learning to forget: Continual prediction with LSTM. Neural Comput. 2000, 12, 2451–2471. [Google Scholar] [CrossRef]
- Moustafa, S.S.R.; Khodairy, S.S. Comparison of different predictive models and their effectiveness in sunspot number prediction. Phys. Scr. 2023, 98, 45022. [Google Scholar] [CrossRef]
- Fan, D.; Sun, H.; Yao, J.; Zhang, K.; Yan, X.; Sun, Z. Well production forecasting based on ARIMA-LSTM model considering manual operations. Energy 2021, 220, 119708. [Google Scholar] [CrossRef]
- Zhou, C.; Fang, Z.; Xu, X.; Zhang, X.; Ding, Y.; Jiang, X.; Ji, Y. Using long short-term memory networks to predict energy consumption of air-conditioning systems. Sustain. Cities Soc. 2020, 55, 102000. [Google Scholar] [CrossRef]
- Saqib, M.; Şentürk, E.; Sahu, S.A.; Adil, M.A. Comparisons of autoregressive integrated moving average (ARIMA) and long short term memory (LSTM) network models for ionospheric anomalies detection: A study on Haiti (Mw = 7.0) earthquake. Acta Geod. Geophys. 2022, 57, 195–213. [Google Scholar] [CrossRef]
- Rguibi, M.A.; Moussa, N.; Madani, A.; Aaroud, A.; Zine-Dine, K. Forecasting COVID-19 Transmission with ARIMA and LSTM Techniques in Morocco. SN Comput. Sci. 2022, 3, 133. [Google Scholar] [CrossRef]
- Kobiela, D.; Krefta, D.; Król, W.; Weichbroth, P. ARIMA vs. LSTM on NASDAQ stock exchange data. Procedia Comput. Sci. 2022, 207, 3836–3845. [Google Scholar] [CrossRef]
- Ahnaf, M.S.; Kurniawati, A.; Anggana, H.D. Forecasting pet food item stock using ARIMA and LSTM. In Proceedings of the 2021 4th International Conference of Computer and Informatics Engineering (IC2IE), Jakarta, Indonesia, 14–15 September 2021. [Google Scholar]
- Temür, A.S.; Akgün, M.; Temür, G. Predicting housing sales in turkey using ARIMA, LSTM and hybrid models. J. Bus. Econ. Manag. 2019, 20, 920–938. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Institution | Regulated or Suggested Concentration of CO2 (ppm) |
|---|---|
| The American Society of Heating, Refrigerating, and Air-Conditioning Engineers (ASHRAE) | 1000 [15] |
| U.S. Occupational Safety and Health Administration (OSHA) | 1000–1500 [16] |
| National Bureau of Disease Control and Prevention of China | 1000 (1 h average) [17] |
| French rules | 1000 (Non-residential buildings) 1300 (No smoking area) [18] |
| Taiwan Environmental Protection Administration in China | 1000 (8 h CO2) [11] |
| Hong Kong Environmental Protection Administration in China | 2500 (1 h CO2 for level 1 for buses) [11] |
| Literatures | Comparison of Model Prediction Results | Advantages | Limitations |
|---|---|---|---|
| Tsan [56] | LSTM better than ARIMA | The prediction model was established using air pollutants as input variables and the number of diseases as the output variable | Only supports univariate input |
| Xiao and Su [57] | LSTM better than ARIMA | Developed a hybrid ARIMA-LSTM model for accurate stock price prediction | The analysis was limited to data collected from 2010 onwards |
| Elsaraiti and Merabet [58] | LSTM better than ARIMA | Comparing the predictive accuracy of ARIMA and LSTM in wind speed | The conclusions need to be confirmed through comparisons with other studies |
| Long et al. [45] | ARIMA better than LSTM | The first application of machine learning to predict monkeypox cases | The influence of temperature and air passenger traffic on cases was not taken into account |
| Xu and Chen [59] | ARIMA better than LSTM | Utilizing time series forecasting models to predict the trend in macroeconomic indicators | The influencing factors were not taken into consideration |
| Ning et al. [60] | ARIMA better than LSTM | Considering the seasonal impact on oil production | R-squared is not appropriate in evaluating nonlinear regression |
| Peng et al. [61] | ARIMA better than LSTM | Establishing an accurate vegetable price prediction model | Forecast accuracy needs to be improved |
| Zhang et al. [62] | Monthly and weekly incidence prediction: ARIMA better than LSTM Daily incidence prediction: LSTM better than ARIMA | Compared the prediction models based on data at different time scales | The influencing factors were not taken into consideration |
| Wang and Mi [63] | Predicting the overall demand: ARIMA better than LSTM Predicting the individual demand: LSTM better than ARIMA | Anticipating future demand for shared cars among users | The data preprocessing stage exhibits certain inadequacies |
| Vehicle Parameters | Nissan-Sylphy [64] | Honda-Fit [65] |
|---|---|---|
| Engine | Type: petrol engine, model: HR16 Displacement: 1.6 L Number of cylinders: 4 Maximum power: 90 KW Maximum torque: 155 n·m | Type: petrol engine, model: L15BU Displacement: 1.5 L Number of cylinders: 4 Maximum power: 96 KW Maximum torque: 155 n·m |
| Transmission | Continuously variable transmission (CVT, no gear number) | Continuously variable transmission (CVT, no gear number) |
| Vehicle body features | Length, width, and height: 4631 mm × 1760 mm × 1503 mm Wheelbase: 2700 mm Vehicle weight: 1230 kg Age of vehicle: 2 years Approximate cabin volume: 3.5 m3 Odometer: 58,682 km | Length, width, and height: 4109 mm × 1694 mm × 1537 mm Wheelbase: 2530 mm Vehicle weight: 1107 kg Age of vehicle: 1.5 years Approximate cabin volume: 3.2 m3 Odometer: 52,439 km |
| Performance parameters | Acceleration time from 0 to 100 km/h: 12.1 s Maximum speed: 182 km/h Fuel consumption of official WLTC: 6.09 (L/100 km), 45.07(g/km) [66] Fuel consumption of our testing: 7.12 (L/100 km), 52.61 (g/km, per hour) | Acceleration time from 0 to 100 km/h: 10.6 s Maximum speed: 190 km/h Fuel consumption of official WLTC: 5.57 (L/100 km), 41.22 (g/km) [66] Fuel consumption of our testing: 6.85 (L/100 km), 50.69 (g/km, per hour) |
| Suspension and braking systems | Type of front suspension: MacPherson independent suspension Type of rear suspension: torsion beam non-independent suspension Front brake system: ventilated disc brakes; rear brake system: disc brakes | Type of front suspension: MacPherson independent suspension Type of rear suspension: torsion beam non-independent suspension Front brake system: ventilated disc brakes; rear brake system: drum brakes |
| Fuel type and tank capacity | Fuel type: gasoline fuel, tank volume: 50 L | Fuel type: gasoline fuel, tank volume: 40 L |
| Security configuration | Main and passenger airbags, ABS | Main and passenger airbags, ABS |
| Number of seats and seat configuration | Number of seats: 5-person seat configuration; fabric, manual adjustment, no heating or cooling equipment | Number of seats: 5-person seat configuration; fabric, manual adjustment, no heating or cooling equipment |
| Instrument Name | Model Measuring | Parameters | Measuring Range | Measuring Accuracy |
|---|---|---|---|---|
| HOBO CO2 concentration recorder | MX1102A | CO2 Temperature Relative humidity | 0–5000 ppm −20–70 °C 5–95% | CO2: ±50 ppm +5% of reading at 25 °C (77 °F), less than 90% RH (noncondensing) and 1013 mbar Temperature: ±0.21 °C from 0° to 50 °C (±0.38 °F form 32° to 122 °F) Relative humidity: ±2% from 20% to 80% typical to a maximum of 14.5% including hysteresis at 25 °C (77 °F); below 20% and above 80% ± 6% typical |
| Sigma digital wind speed and volume meter | AS856 | Outlet air speed | 0.0–45.0 m/s | ± (0.5 m/s + 0.05 × indicated wind speed) |
| Test Variable | Test Number | Test Vehicle | Fan Speed | Driving Road | Number of Occupants |
|---|---|---|---|---|---|
| Fan speed | T1 | Nissan-Sylphy | S1 | Urban road | 3 |
| T2 | Nissan-Sylphy | S4 | Urban road | 3 | |
| Number of occupants | T3 | Nissan-Sylphy | S1 | Urban road | 1 |
| Driving speed | T4 | Nissan-Sylphy | S1 | Suburban road | 3 |
| T5 | Nissan-Sylphy | S1 | Expressway | 3 | |
| Vehicle volume | T6 | Honda-Fit | S1 | Urban road | 3 |
| Test Number | Temperature (°C) | Relative Humidity (%) | CO2 (ppm) |
|---|---|---|---|
| T1 | 22.78 | 32.07 | 2734 |
| T2 | 25.10 | 37.69 | 2489 |
| T3 | 17.14 | 38.84 | 1161 |
| T4 | 18.49 | 36.75 | 2427 |
| T5 | 25.21 | 28.69 | 1905 |
| T6 | 23.82 | 28.70 | 2866 |
| Datasets | The Order of Diffrence | t | p-Value | Critical Value | ||
|---|---|---|---|---|---|---|
| 1% | 5% | 10% | ||||
| T1 | 1 | −3.717 | 0.004 *** | −3.459 | −2.874 | −2.573 |
| T2 | 1 | −6.516 | 0.000 *** | −3.459 | −2.874 | −2.573 |
| T3 | 1 | −15.166 | 0.000 *** | −3.458 | −2.874 | −2.573 |
| T4 | 1 | −17.375 | 0.000 *** | −3.458 | −2.874 | −2.573 |
| T5 | 1 | −4.575 | 0.000 *** | −3.459 | −2.874 | −2.573 |
| T6 | 1 | −5.11 | 0.000 *** | −3.459 | −2.874 | −2.573 |
| Datasets | Optimal Model | AIC | BIC | p-Value |
|---|---|---|---|---|
| T1 | ARIMA (3, 1, 1) | 1401.47 | 1417.06 | 0.74 |
| T2 | ARIMA (4, 1, 3) | 1433.24 | 1458.19 | 0.62 |
| T3 | ARIMA (1, 1, 1) | 1186.36 | 1195.72 | 0.93 |
| T4 | ARIMA (5, 1, 4) | 1446.43 | 1477.61 | 0.57 |
| T5 | ARIMA (5, 1, 3) | 1427.32 | 1455.38 | 0.36 |
| T6 | ARIMA (3, 1, 3) | 1405.53 | 1427.36 | 0.68 |
| Datasets | MAPE (%) | RMSE (ppm) | ||
|---|---|---|---|---|
| ARIMA | LSTM | ARIMA | LSTM | |
| T1 | 0.48 | 0.49 | 25.37 | 25.11 |
| T2 | 0.52 | 0.65 | 23.02 | 29.37 |
| T3 | 0.42 | 0.65 | 9.25 | 13.51 |
| T4 | 0.54 | 0.52 | 23.34 | 24.57 |
| T5 | 0.49 | 0.65 | 17.55 | 23.09 |
| T6 | 0.35 | 0.39 | 19.19 | 20.93 |
| Average value | 0.46 | 0.56 | 19.62 | 22.76 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Han, J.; Lin, H.; Qin, Z. Prediction and Comparison of In-Vehicle CO2 Concentration Based on ARIMA and LSTM Models. Appl. Sci. 2023, 13, 10858. https://doi.org/10.3390/app131910858
Han J, Lin H, Qin Z. Prediction and Comparison of In-Vehicle CO2 Concentration Based on ARIMA and LSTM Models. Applied Sciences. 2023; 13(19):10858. https://doi.org/10.3390/app131910858
Chicago/Turabian StyleHan, Jie, Han Lin, and Zhenkai Qin. 2023. "Prediction and Comparison of In-Vehicle CO2 Concentration Based on ARIMA and LSTM Models" Applied Sciences 13, no. 19: 10858. https://doi.org/10.3390/app131910858