1. Introduction
Reduction in th maternal mortality ratio (MMR) has been a priority issue on the global health agenda for decades. For instance, the World Health Organization (WHO) has proposed several strategies for ending preventable maternal mortality (EPMM) [
1]. The strategies called for improvements along the continuum of care approach for pregnant women and focus on high-risk obstetrics diseases.
The WHO strategies for EPMM include a call for action to improve metrics, measurement systems, and data quality that account for all maternal and newborn deaths. Also, another objective laid out in these strategies is to address all causes of maternal mortality, reproductive and maternal morbidities, and related disabilities. One important stepping stone for reducing the preventable maternal mortality is to identify and reduce severe maternal morbidity (SMM). Conditions such as obstetric hemorrhage, preeclampsia, sepsis, cardiovascular disorders, and placental disorders, among others [
2], fall within the ambit of SMM. Frequently, identification and reporting of SMM are performed retrospectively, so corrective actions may be delayed. Therefore, there is an impending need to have a near real-time, or just-in-time approach to identify SMM cases.
In recent years, the adoption of electronic health records (EHRs) has increased exponentially in the world. In the EHRs, large numbers of registers are saved chronologically. Their database contains structured elements such as vital signs, drugs, etc. Such records also incorporate narratives written by health personnel including outpatient notes, nursing notes, discharge notes, and progress notes, among others, which usually contain unstructured text. It is estimated that 80% of the health data remain unstructured [
3]. However, nowadays most of the clinical decisions are based on structured EHR fields. Furthermore, social, behavioral, and other determinants of health are commonly captured in narrative fields. Therefore, there is an opening alternative for natural language processing (NLP) to contribute to improve the causal and predictive models of diseases.
Although advances in NLP in maternal health has been reported, these are mostly made on applications and analyses of social networks [
4,
5,
6,
7]. A smaller proportion has been identified on Electronic Medical Records, but for other health conditions. English is the predominant language of corpus, and those existing studies are focused mainly on the mental health domain [
8,
9,
10]. Both in English and in Spanish, there is a dearth of information on the role of NLP in the prediction of maternal morbidity and mortality. In this study, we hypothesize that NLP and Machine Learning (ML) may help identify SMM from clinical notes, which would increase the likelihood of a timely diagnosis and the subsequent clinical intervention, as well as simplify administrative tasks such as reporting and surveillance. Thus, our main goal is to develop a novel pipeline testing different word-embedding schemes, algorithms for document representation, and machine learning classifiers to identify SMM of pregnant women on progress notes in Spanish extracted from electronic health records.
To achieve our objective, we examine various word-embedding approaches, including Word2Vec, GloVe, and FastText, employing different preprocessing techniques and classification methods. Furthermore, we assess two pretrained language models, fine-tuning them to determine the relevance of employing word-embedding techniques in today’s context. The main contributions of our paper are as follows:
The first attempt to classify Severe Maternal Morbidity from unstructured notes.
The use of pretrained word-embeddings schemes improved the classification performance.
Typos and misspelling correction increased the performance of the pipelines in general.
Hypertensive disorders and miscarriage complications show true positive rates over 83%.
2. Related Work
Word-embeddings are an important part of NLP and have become an inescapable choice for text representation for NLP tasks. The representations based on word frequency and others usually are high dimensional, ignore the order of the text, are sparse, etc.
To deal with the problems of word frequency representation, different approaches were tested. In a previous study, authors used a bag of words with word weighting by TF-IDF scores. They tested different classifiers including support vector machines (SVM), random forest (RF), and extreme gradient boosting (XGB). They tested on 2-, 3-, or 7-stage cancer labels with an F1-score from 0.80 to 0.99 [
11]. Similarly, another group used skip-gram and paragraph vectors-distributed bag of words (PV-DBOW) with multiple discriminant analysis (MDA) to generate document embeddings. Regarding multiclass classification (five classes), they obtained an F1-score ranging from 0.68 to 0.97 using an extreme learning machine (ELM) [
12].
The use of word-embeddings for classification is common in the health sector to classify different diseases and other challenges. For instance, in the mental field [
13], researchers have used weighted document vectors as a combination of TF-IDF with Word2Vec for challenging behavior classification. They report an accuracy of 84.3–98.5% in a binary class between challenging behaviors in Autism Spectrum Disorder (ASD) using SVM. In [
14], researchers focused on comparing different word representations, including TF-IDF, Word2Vec, batch-Word2Vec, and Doc2Vec. The objective was to classify cardiovascular diseases according to eight ICD codes. They obtained a better result in representation based on word frequency. In [
15], the authors compared three different representations of the EHR notes, with a convolutional neural network classifier to predict a visual prognosis. They obtained an F1-score on this model of 67%.
Most of the previous works focus on EHRs in English. Nevertheless, there are some reports using NLP on EHRs in other languages. For instance, in [
16], researchers developed different pipelines for the identification of adverse drug reactions (ADRs) in Dutch clinical notes. Likewise, there are a few studies using Spanish that use EHR notes to classify different health conditions. For example, in [
17], they classified cancer diagnoses using different word-embedding techniques and machine learning. The results for the binary classification was an F1-score of 98%. In [
18], they developed a predictive model for early and late progression to first-line treatment of HR+/HER2-negative metastatic breast cancer. According to their results, the best NLP-based model achieved an AUC of 0.752. In addition, we identified works focused on other problems such as the ICD-10 coding in Spanish, which included word-embeddings like the one presented in [
19], or using a contextualized language model (BioBERT) with rule-based approaches [
20].
To our best knowledge, there are no studies to classify SMM using NLP neither in English nor Spanish.
3. Methods
In this study, we adopted a novel approach, exploring whether it is possible to classify SMM by building different pipelines of NLP methods combined with machine learning classifiers applied on the progress notes of the episodes before the mother is discharged from the hospital. For the purpose of this work, a clinical episode starts with the admission of a pregnant woman into the hospital by outpatient or emergency consultation. In this time frame, we can find both ambulatory encounters and inpatient encounters. The episode concludes when the women have been discharged from the hospital or have a delivery.
3.1. Severe Maternal Morbidity (SMM)
There is not a single, comprehensive definition of SMM; it is also recognized as severe acute maternal morbidity [
21] and also known as “near miss” [
2]. But, in general, it is considered a complication that puts the life of the pregnant woman at risk and requires urgent medical intervention [
22]. Colombia’s National Epidemiological Surveillance System (SIVIGILA) uses ICD-10 codes to report SMM. They use eight groups with the purpose of following the conditions that require more action from the government [
23].
Table 1 presents the definitions of the groups according to the ICD-10 aggrupation.
These events are reported to the government according to the data recorded on the EHRs. For our purposes, all ICD-10 classifications in discharge notes that do not fit in the grouping system of SIVIGILA were considered to be without SMM (WS).
3.2. Data Source and Data Quality
Clinica Universitaria Bolivariana (CUB) is a university general hospital with an important focus in obstetrics. CUB has provided more than 80,000 deliveries in the city of Medellín, with a mean of 5200 deliveries per year which was approximately 13.5% of the city’s total in 2020. The Hospital Information System and EHR system used by the clinic is Servinte Clinical Suite (Carvajal SA, Medellín, Colombia, v1.3, 2019). According with de Data Dictionary, we queried the EHR system to extract clinical records of patients who gave birth in the institution during the period 2015 to 2019. CUB did not provide demographic data; due to privacy constraints, the dataset was limited to extracted unstructured patient notes. The data were obtained using Oracle SQL Developer and stored in binary format for processing and analysis. We used tables containing information about progress notes corresponding on SOAP (Subjective-Objective-Analysis-Plan) forms performed by clinicians in each encounter. Patients’ data were assigned an internal identification number to match the progress notes and their corresponding ICD-10 code at discharge.
To assess the document quality, we conducted an Exploratory Data Analysis (EDA) on the progress notes. Different aspects were examined, including note length, vocabulary size, word frequency distribution, structural patterns, sparsity, punctuation usage, and formatting conventions. Subsequently, we decide the steps for preprocessing.
The content of the progress notes is separated into various fields according to the design of the form in the EHR system. As a consequence, we found duplicate information in the fields of the same progress notes. Then, before processing the text we eliminated the duplicated data and joined all the content of each field into a single document. Lastly, episodes without progress notes or notes with fewer than 10 words were discarded.
To assess the performance of our model, we divided the dataset into two independent subsets: a training set and a test set. Specifically, we allocated 20% of the total dataset as the test set. To ensure that both sets maintained a proportional representation of classes, we employed a stratified sampling. Stratification helps preserve the distribution of target labels in each subset; this methodology ensures that our model is subjected to a representative test set.
3.3. Preprocessing
To comply with Colombia’s rules (Law 1581) about Protected Health Information (PHI) [
24], we applied a basic ruled-based approach to identify first and last names in the dataset. To accomplish this, we used a library in Python developed by Colombia’s National Planning Department (DNP), named
Contexto [
25], that contains lists of Colombian first and last names. This list includes some names that could have an important meaning in our context, for instance:
bueno (good),
bien (well),
rojas (reds),
cama (bed),
rojo (red),
cesárea (c-section),
rosa (pink),
dolor (pain),
olores (pains), and
blanco (white), etc. Those words were excluded from the dictionary.
We continued the preprocessing of the text with typical sequential steps that contained the following methods: tokenization, remove numbers, lower case, remove punctuation, remove stop words, and remove accent marks. We stored these tokens in a list and used a matching dictionary to change the tokens that corresponded to PHI instances using the label <NOMBRE> or <APELLIDO> as appropriate. Finally, we reconstructed the text with all the tokens. In our rules-based approach to de-identification, we did not take into account the numbers of IDs, telephone numbers, and addresses, because they are removed in the sequential steps above.
For the stop words removal step, we implemented two schemes. First, we used the set of Spanish stop words from NLTK for default. Second, we customized a dictionary of stop words including the most common words detected in our dataset without an important meaning in the medical context by a data exploration analysis. A total of 2000 tokens were stored in an .xls file. To build the final customized dictionary of customized stop words, a health informatics physician analyzed the file and selected 168 tokens to create the customized stop words list. Some of the tokens considered as customized stop words were
paciente (patient),
años (years),
embarazo (pregnant),
horas (hours),
refiere (refers),
eco (echo),
cada (each),
fetal (fetal),
sem (contraction of weeks),
si (yes),
mg (mg),
extremidades (extrimities),
semana (week),
momento (the time),
dia (day),
madre (mother),
instrucciones (instructions),
eps (insurance company),
materna (maternal),
ecografía (echography),
consulta (consultation),
gestacional (gestational),
bebé (baby),
am (at morning),
minutos (minutes),
residente (resident),
clínica (clinic),
encuentra (find),
materno (maternal),
derecha (righ),
pone (to put),
debe (should),
entiende (understand),
sexo (gender),
pediatria (pediatrician),
médico (doctor),
tarde (late),
gestación (gestation),
xmin (per minute). Note that, for instance, the maternal or medical words, appear many times in the documents; however, they were not important to differentiate between patients with or without SMM. The repository can be found at the following link:
https://github.com/sruap1214/SMM_NLP, (accessed on 14 August 2023).
3.4. Word-Embedding Schemes
After the text preprocessing stages, we used word-embedding to generate a vector representation of each word. We explored six different word-embedding schemes with the aim of evaluating which was the best scheme to represent the episodes in the EHRs.
First, we trained a Word2Vec model using a continuous bag of words (CBOW) to obtain a vector representation for each word in the dictionary constructed by all the words contained in our EHR database. We trained the model from scratch using a neural network with 300 neurons in the hidden layer. Once the data were preprocessed, we created our own word-embeddings representation using the training data with 300 dimensions and a context windows of 5 tokens. To differentiate if there is a change in the sense of the paragraph, we added the special token
<> after each period or before a new line according to [
26]. At the end of the training stage, we obtained
vectors with 300 dimensions.
Second, we used a pretrained Word2Vec model in the Spanish Billion Word Corpus (SBWC) [
27]. The pretrained word embedding models employed in this study were chosen due to their pretraining being carried out in Spanish. In particular, this model contains 1,000,653 vectors with
, where
m is the vector size. Taking into account that the progress notes analyzed from EHRs contain a huge amount of words with typos and misspellings, there is a high probability that those words will not be found in the dictionary of the SBWC. We implemented a method to be able to assign a vector value to words with typos or misspellings based on searching the closest word in the dictionary. This adjustment was implemented by computing the Levenshtein distance between the misspelling or typo words and the vocabulary of the SBWC. The minimum Levenshtein distance was found using a searching technique based on a tree data structure, which is faster than a traditional search. The Word2Vec model was implemented with and without the misspelling and typos adjustment.
To compare different word-embedding approaches, we implemented three additional embeddings schemes. First, the GloVe Vectors (GloVe) embeddings were used with a model pretrained from the SBWC. Second, the GloVe was used with and without the misspelling and typos adjustment (same algorithm as in Word2Vec). And third, we implemented FastText using a model pretrained in Common Crawl and Wikipedia. The FastText model was trained using CBOW, with dimension 300, a character n-grams of length 5, a window of size 5, and 10 negatives. We did not use the misspelling adjustment in FastText because it works with subword information.
The six embedding schemes used in this work are listed below:
Word2Vec from scratch trained in our dataset.
Pretrained Word2Vec.
Pretrained Word2Vec with typos and spelling correction.
Pretrained GloVe.
Pretrained GloVe with typos and spelling correction.
FastText.
3.5. Features Extraction
Word-embeddings can be faster to implement and provide good results alternatively to feature engineering for classification and prediction tasks in the clinical domain [
28]. The use of word-embeddings assigns a vector for each word. However, all the documents have different length. Therefore, it is necessary to have a mechanism that allows one to have a combination of the representations of each document. In this section, we describe three different mechanisms to obtain only one feature vector that represents all the information of each document under analysis. Each document representation was tested with the six word-embeddings schemes described previously in
Section 3.4.
Average: In this approach, we represent each document by averaging vectors of all the words contain in each episode, similar to [
29].
Clustering: Unlike the average approach, in the present technique, the idea is to represent episodes using word clusters. For that purpose, we followed the bag-of-centroids approach presented in [
30]. First, we defined the number of clusters to use due to the proportion of word vectors in the documents. We selected the number of clusters
k in such a way that on average the clusters had 10 words. As a consequence, the value of k must be set to 1155; this value is the result of dividing the total number of words between the number of words per cluster. Second, we applied the k-means algorithm to obtain the centroids of each cluster. Third, we represented each word using an embedding model and obtained the cluster to which its word vector belongs, increasing its count by one. Finally, we will obtain a
k-dimensional vector, where each element represents one of the clusters. The corresponding value of each element is the number of words in the record belonging to this cluster.
Principal Component Analysis (PCA): As an alternative approach, we proposed using the principal component analysis (PCA) method, which seeks to rotate the space in the direction where the highest variance is presented. We represented each document as the first eigenvector resulting from applying the PCA method on the set of words that make up a document from an episode. In this way, regardless of the number of words in the document, we can guarantee that the resulting representation vector will have a fixed dimension of 300 features.
3.6. Classification Schemes
We defined different pipelines by the combination of the six different word-embedding approaches described in
Section 3.4, the three representation methods defined in
Section 3.5, and the following five well-known classifiers: logistic regression (LR), multilayer perceptron (MLP), support vector machine (SVM), random forest (RF), and k nearest neighbor (kNN). The different pipelines were tested using macro average F1-score (F1-macro) with a 5-fold cross-validation scheme.
We used the implementation from the Python library
scikit-learn [
31] for training and testing each pipeline. The parameters of the classifier were instantiated following a grid search scheme. In particular, for the MLP various combinations of neurons organized in 1 to 3 hidden layers were tested using the Adam solver and the values
for the
. For the SVM, the polynomial, radial basis, and sigmoid kernels were tested with their default values together with an exponential growth sequence
for the penalty. For the logistic regression, we varied the penalty term C (
). In
kNN we assessed the values 1, 3, …, 9 for the number of nearest neighbors k. Finally, in RF we varied the number of estimators (
), the minimum number of samples in a leaf node (
), and the minimum number of samples required to split a node (
).
Our dataset is imbalanced, mainly associated with the class without SMM (WS). To limit the class imbalance impact, we undersampled the majority class (WS) over the training set. Instead of using undersampling in the rest of the dataset in a one-vs-rest scheme, we randomly removed samples from the majority class so that the size of the majority class had the same number of samples as the class with the second-highest number of samples. We chose this method because the classifiers do not always use the one-vs-rest strategy to deal with multiclass classification problems as is the case for MLP and kNN.
For surveillance of SMM, both precision and recall are important. A high precision allows the system to assign the correct group to SMM; meanwhile, a high recall is intended to not miss a correct classification when the episode corresponds to a real condition associated with SMM. For that reason, we used the F1-macro as an evaluation measure, because it includes the precision and recall metrics and considers each class in the model.
3.7. Language Model Schemes
In addition to the representation schemes and classification models discussed in
Section 3.5 and
Section 3.6, we assessed the performance of two language models for the purpose of comparison with the proposed classification schemes using word-embedding.
RoBERTa [
32] is a transformer-based masked language model for the Spanish language. It has been pretrained using a Spanish corpus with a total of 570 GB of data.
Longformer-es [
33] is the Longformer version of the
RoBERTa.
Longformer-es employs a blend of sliding window (local) attention and global attention mechanisms that scales linearly with sequence length that allows it to process documents with thousands of tokens.
Our experiments are performed on a Nvidia Quadro RTX5000 GPU with 16 GB, for which a pretraining process was carried out involving 15 epochs. We trained the model with a learning rate of
, dropout rate of 0.1, and AdamW optimizer for both models; the other parameters are set by default. The models are available at hugging face
https://huggingface.co/PlanTL-GOB-ES/roberta-base-bne, (accessed on 20 August 2023)
https://huggingface.co/PlanTL-GOB-ES/longformer-base-4096-bne-es, (accessed on 20 August 2023). Given the length of the clinical notes, we chose to use
longformer-es, which supports a maximum input length of up to 4096 tokens. For batch processing, we utilized the
padding longest option, guaranteeing a uniform sequence length within each batch, aligning with the longest sequence in that batch. The batch size was configured as 6 for both models, and the remaining parameters retained their default values.
We fine-tuned the language models using the same preprocessing steps described in
Section 3.3. We performed the pretraining and evaluation of the transformer models using the documents without typos or misspelling adjustment because, like in FastText, those models works with subword information. In addition, the ability of BERT-based models to consider context from both directions helps it capture the meaning of words, even in the presence of typos or misspellings.
4. Results
4.1. Dataset Characterization
We identified 22,937 patients from the EHRs, most of them with more than one progress note. We built a dataset by grouping all the progress notes per episode into one document. A total of 43,529 documents were built. We assigned the ICD-10 discharge code to each document.
Figure A1 shows the distribution of ICD-10 codes in our dataset by its chapters.
These documents have a mean of 4.15 progress notes.
Table 2 presents the number of documents per class and the mean progress notes in such documents. Due to the low frequency of pulmonary sepsis after validating with physicians, we merged this class into non-obstetrics sepsis for analysis.
Despite the query being targeted for women that have a delivery in the study time-frame, we found ICD-10 codes associated to the episodes in almost all chapters of ICD-10. As expected, the most frequent chapter was the XV, corresponding to a pregnancy, childbirth, and puerperium. In this chapter, the most frequent code found was the single spontaneous delivery followed by single delivery by cesarean section and false labor. The second most frequent chapter was XXI, which is related to the factors influencing health status and contact with health services. In this chapter, the most frequent code is related to the supervision of normal pregnancy. The third most frequent chapter was XVIII, which is related to symptoms, signs, and abnormal clinical and laboratory findings; the most frequent codes in this chapter were pelvic pain and headache. Lastly, the fourth most frequent chapter was the XIV, associated to diseases of the genitourinary system, where the most frequent code were other disorders of the urinary system.
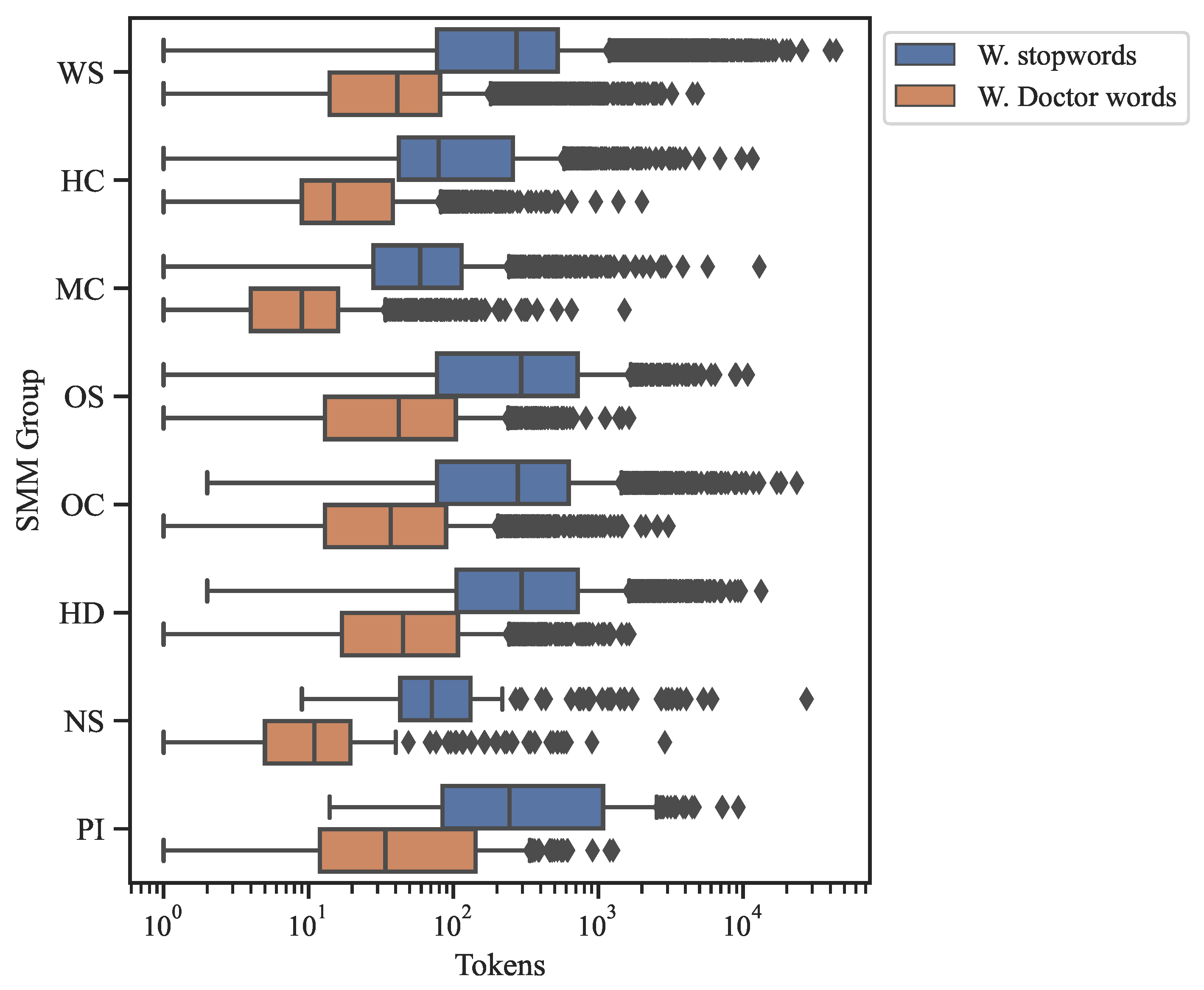
We analyzed the number of tokens for each document at two moments. First, after removing the common stop words, and second, after the elimination of customized stop words identified by the health informatician of the research team. Additionally, MC and NS were the classes most affected by the removal of stop words. Without common stop words the average number of tokens per document is 431. After removing the customized stop words, the average tokens per documents decreases to 64.
Figure 1 shows the distribution of the number of tokens differentiated by SMM classes. Importantly, the documents left empty after removing stop words were discarded.
When compared to the GloVe and Word2Vec vocabularies, the percentage of typos and misspelled words in our entire dataset was between 10.85% and 14.13%. Also, the average percentage of missing words per document was 10.58% in GloVe and 13.77% in Word2Vec. We consider that these spelling errors occur due to the time assigned to physicians to fill out the EHR and the lack of an autocorrection functionality in the EHR system. Our numbers were similar with the results of Ruch [
34] in follow-up notes.
4.2. Classification
Table 3 presents the detailed classification results of SMM groups in the validation sets defined in the cross-validation step, comparing the different pipelines proposed. In general, all the pipelines have similar performances in the validation set. The best performance in the validation set was achieved using clustering representation followed by average. The best performance was found by MLP with the pretrained Word2Vec with the typos and spelling adjustment. The poorest performance was obtained by the LR classifier using the Word2Vec trained in our dataset with the average representation. In general, the worst classifier using a different representation and characterization approach was kNN.
Table 4 shows the F1-macro of the same pipelines used in the training set applied to the test set. The test set was not under-sampled and reflects the reality of the studied population. Consequently, we experienced considerable reduction in the performance in all pipelines as expected because the groups were not balanced in the test set (in comparison with the training set where the groups were balanced). However, due to there being a multi-class problem with eight classes, these results are promising, and each class could be distinguished from the rest.
The pipeline with better performance was the one that included Word2Vec, typos and misspelling adjustment, PCA, and the SVM classifier. The second was the same pipeline but with an MLP classifier, which achieved a similar F1-macro. The third was the one that included GloVe, typos and misspelling adjustment, average representation , and the LR classifier. The most effective algorithm for obtaining a single feature vector was the clustering, showing a possible overfitting. This effect was evidenced in the k-NN classifier by [
35] showing a reduction in the performance on imbalanced data.
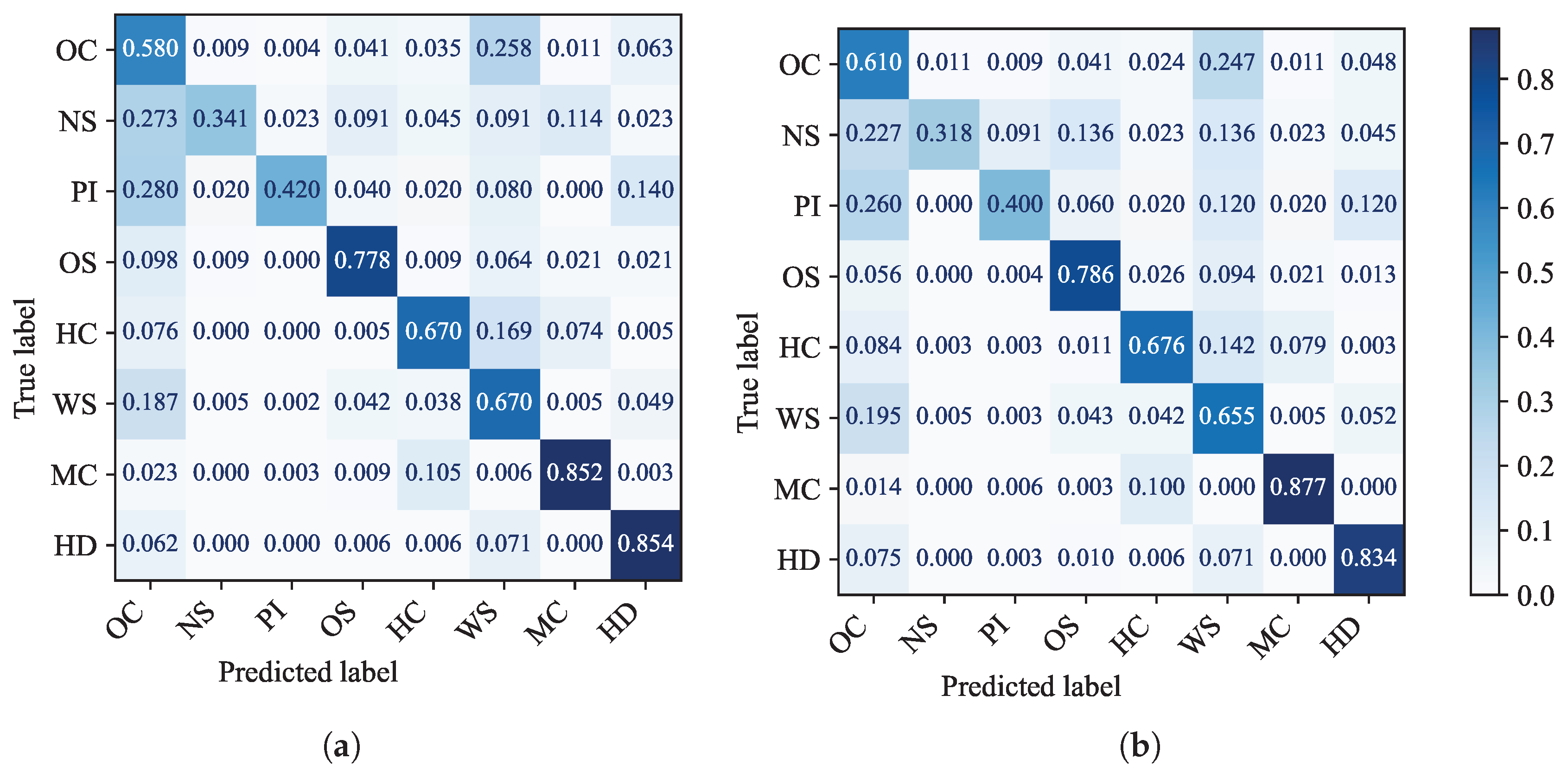
In addition, thetwo confusion matrices with the best performances on the algorithm of PCA and average representation of the document in the test set are shown in
Figure 2. These confusion matrices provide a breakdown of the actual groups, which are listed vertically, and the predicted groups, which are listed horizontally. The normalized outcome of the correct prediction is listed diagonally. We noticed the best performances in the groups of MC and HD, and the worst performances were found in the categories with the least number of documents, such as NS and PI. In addition, most of miss-classification occurs in the groups of OC and WS.
To offer a more comprehensive assessment of the model’s clinical utility [
36],
Table 5 presents the calculated positive predictive values (PPVs) and true positive rates (TPRs) for the best-performing models on the test set. Our emphasis on these metrics is due to the model’s role as a potential screening solution. We have chosen not to report metrics dependent on true negative values. This decision is based on the substantial sample imbalance, which results in markedly higher true negative values compared to false negative values. We can highlight that, further to WS, the classes MC and HD have the best performance in terms of TPR.
4.3. Language Model Results
We assessed the
RoBERTa and
longformer-es models applyied to the test set with 20% of the documents. For comparative purposes, we used the identical test database employed for evaluating the different pipelines proposed in the previous sections. Taking into account the distribution of the number of tokens for each clinical note presented in
Figure 1, it can be seen that most clinical records have fewer than 1000 tokens. We configured the maximum input length to be 512 tokens for
RoBERTa and 1024 tokens for
longformer-es.
We conducted evaluations for the initial 15 epochs in both models. However, we specifically present findings from the epoch with the lowest training loss value, along with its corresponding F1-macro performance. Here, epoch 10 in the longformer-es model obtained 0.485, while epoch 12 in the RoBERTa model obtained 0.461.
4.4. Error Analysis
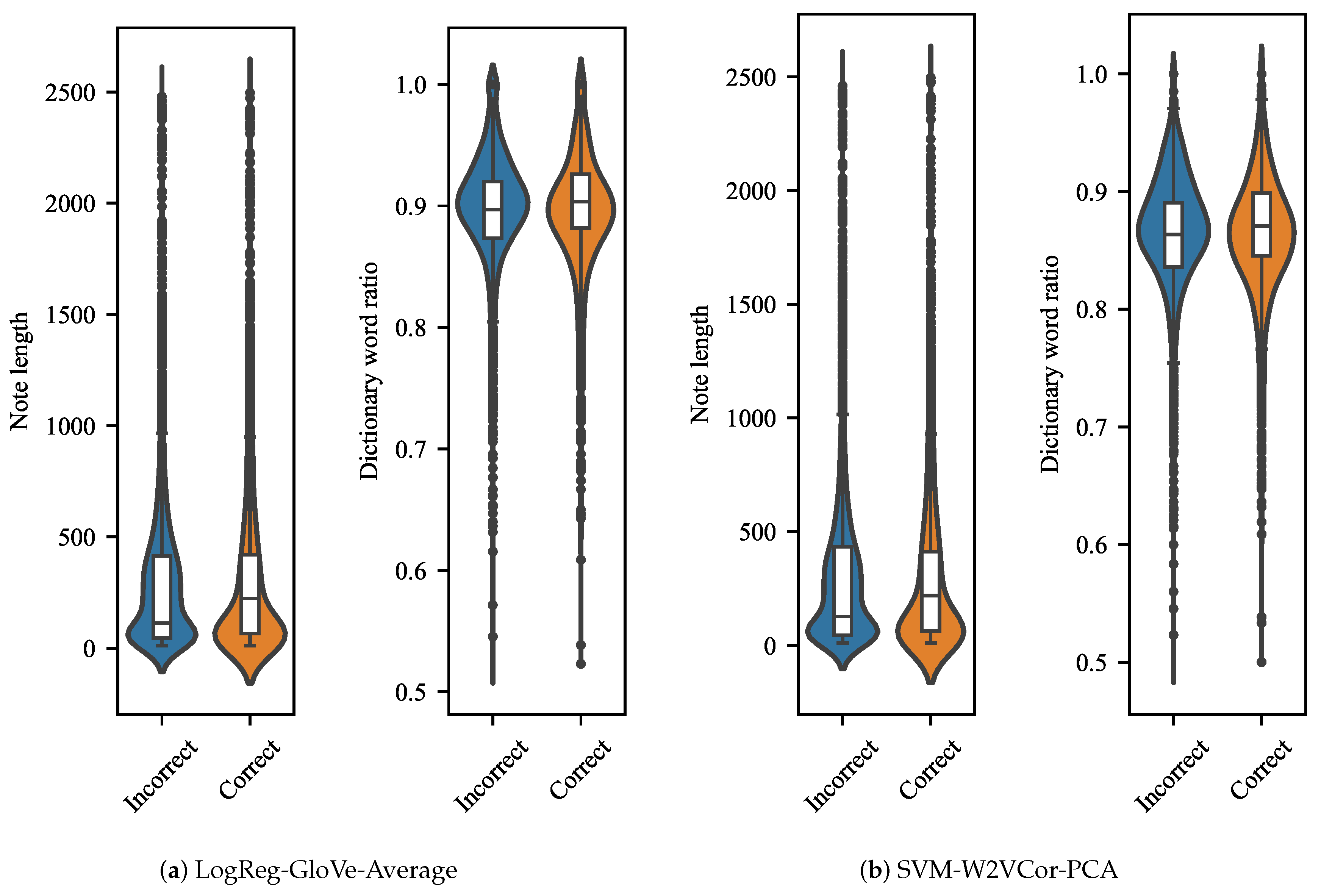
In order to identify the dependencies of the documents classification with their length and their ratio of words present in the GloVe’s and Wor2Vec’s dictionaries, we applied a set of statistical tests over two groups of data, the well-classified documents and the miss-classified documents. For calculating the ratio of words present in the dictionary for each document, we count words belonging to the dictionary and divide them by the length of the note. The average word ratio in the dictionary for the whole dataset was . We used a Mann–Whitney–Wilcoxon test, given the nature of the data, where each electronic note is independent one each other. The t-test was discarded because the length of the documents and words ratio in dictionary did not have a normal distribution. The Mann–Whitney–Wilcoxon (MWW) test is a non-parametric test that contrasts whether two samples come from equidistributed populations.
For the error analysis, we used the results given by the two pipelines with top performance: (1) the one that included the LR classifier and the average of GloVe vector for document representation, and (2) the one that included the SVM classifier and PCA computed on Wor2Vec characterization.
Figure 3a shows that the distribution of documents that were correctly classified present higher medians than incorrect ones; the MWW test confirms that there are significant differences between both groups with a
p-value of
. Additionally, the dictionary word ratio presents a significant difference between documents classified as correct and incorrect (
p-value =
). Similar behavior was observed in pipeline (2) where the documents of a correctly classified document tended to contain more words (
p-value =
) and tended to have a higher dictionary word ratio (
p-value =
).
5. Discussion
Despite the fact that SMM is a major public health issue worldwide, there is scarce evidence on the use of NLP to assist in SMM classification. In fact, to the best of our knowledge, this is the first attempt to classify SMM using NLP on Spanish EHRs.
Since the number of studies related to NLP of medical records in Spanish is limited, we tested different approaches of feature representations of clinical notes with different conventional classifiers. This is a necessary step to establish a baseline that allows us to propose new strategies in the future.
Some classes in our dataset have a smaller amount of tokens, such as MC and NS. However, it is not possible to differentiate any class by the number of tokens in the documents. There is a great variability in the number of tokens as in the number of notes per episode, since no treatment was carried out to eliminate outliers.
Some authors claim that the used of a word-embedding training in a corpus on the specific domain can achieve better performance in domain-specific tasks. However, our results showed that the Word2Vec model trained in our dataset from scratch exhibited the worst performance in comparison with the used of pretrained word-embedding models. This result can be due to the insufficient number of documents in our dataset, taking in account that the pretrained models used datasets with billions of words. Our experiments are in line with [
37], indicating that a biomedical domain corpus does not necessarily have better performance than a general domain corpus. However, there is a need for more word-embedding models applied to low-resource languages and domains[
38], including clinical Spanish.
The preprocessing of the text can play an important role in the performance of the classifiers; it is a little-explored field and it depends on the domain [
39]. The high frequency of typos and misspellings in the EHRs could be improved with corrections; however, there is a risk of changing the meaning of some words, due to the abundant lexical variants. Our results show that adjusting of typography and spelling, in general, increased the models’ performances. Testing new manners of correction of typos and spellings could have a better improvement in the classification task [
40].
Regarding the document representation techniques, PCA exhibited the best performance and clustering representation the worst performance in the test set. Although average representation had a performance similar to that of PCA in the test set, it performed better than PCA in the validation set. PCA and average give a representation by a vector that summarized the whole document, while clustering gives a representation based on word counting, which gives a vector with many zeros. This behavior can affect the performance of the classifiers. This supports the conclusions made by [
41], which indicate that the text classification algorithms are more efficient with a better understanding of feature extraction methods and that document cleaning could help the accuracy and robustness.
As for the performance of the classifiers, the best classifier achieves a macro F1-score of 70.54% in the validation set (which is balanced) and the macro F1-score falls to 52.54 in the best pipeline in the test set (which is imbalanced). The imbalance of the test set has an important role and affects the performance; however, in a real context, we have to deal with imbalanced classes because most of the encounters are with patients with some alarm signs but not with a severe outcome.
We implemented two classifiers based on pretrained language models to have a comparison with the classifiers based on features extracted from word-embedding schemes. The results show that the Longformer model achieves better results than
RoBERTa, which could be due to its handling of a larger number of tokens, causing
RoBERTa to truncate some notes. However, it is evident that neither of the two fine-tuned models surpassed the results obtained with the word-embedding schemes. This outcome is support by [
42], who found that the performance of binary classification for ICD-9 codes exhibited similarity when employing word-embedding schemes compared to transformer-based models. These results might stem from the fact that for particular tasks that do not require extensive context, such as text classification, the complexity of language models might not be necessary. In such cases, word-embeddings can provide more efficient solutions. Future work should be aimed at testing different large language models with a larger dataset in the fitting process, especially in those classes with fewer samples.
According with the confusion matrix, the most false positives are present in the other causes (OC) class. The reason for this is that this group incorporates a large number of ICD-10 codes distributed in the different chapters. A similar situation occurs in the WS category, since all the ICD-10s that did not fit into the SMM grouping were aggregated here. Note that WS and OC are classes that comprise a large amount of ICD-10 codes. In contrast, more defined categories such as hypertensive disorders (HD), miscarriage complications (MC), and obstetric sepsis (OS) show a performance of around 80% of true positive rates. Taking in account that the objective is to detect groups with a high risk of SMM, this is a promising result.
As shown in
Table 5, the results suggest that our premise and model proposed can be used as screening tool for classes such as HD and MC. These classes exhibit the highest TPR. Nevertheless, it is worth noting that only the MC class displays higher values for both TPR and PPV. For instance, the performance of class HD, despite its strong TPR, has a low PPV. Even so, the model was effective at correctly identifying instances with performance above 85% in this class. This means that while it correctly identifies instances of the HD class, it also generates a notable number of false positives for this class, primarily from the without-SMM class (WS). This disparity arises from the substantial class imbalance, where a considerable number of samples belong to WS. As a result, even though the model’s performance in these classes is suitable, there is a relatively higher count of false negatives in comparison to true positives. Regardless, in a potential future application of these models as screening tools for generating alerts related to maternal mortality risk, emphasizing TPR remains crucial. The issue of potential false positives can be addressed through a secondary evaluation conducted by a specialist.
Limitations
The use of proprietary databases makes it difficult to carry out external validations and requires more time to understand the infrastructure and structure of the records. Furthermore, the schemes of the health record databases in a Colombian context focus the most on administrative topics and usually lack schemes for research. For that reason, we needed a long time to understand the native structure and extract, transform, and load the data required for this study. This could be more efficient with the standardization of conditions and the analysis of data through common data models such as OMOP.
There was a high frequency of typos and misspellings in the narratives that were treated compared with the vocabulary of a corpus not specialized in the biomedical or clinical domain. This required a better approach to treat these special tokens and be careful with the impact that removing words could have, or changing the meaning of the sentence [
43].
The choice of the ICD-10 code can vary in different institutions, is influenced by the school where the doctors were trained, and it depends on their level of knowledge and other multiple elements, as described in [
44]. In addition to these factors, the different electronic medical record software can influence the quality of classification depending on the usability and functionality [
45]. For this reason, using a supervised validation system for the medical records labeling, the quality of the data can be increased and, therefore, the performance of the model.
Concerning pretrained deep learning models, we applied identical preprocessing steps as those used with the word-embedding schemes, including the removal of stop words. Although eliminating stop words could potentially result in the loss of specific contextual nuances, we expect that, due to the nature of the classification task, the impact on outcomes will not be substantial. However, future works can address this concern by exploring various preprocessing pipelines.

 ,
, 





{kind=link}
{kind=link}
{kind=link}
{kind=link}