
Generating Structurally Complete Stylish Chinese Font Based on Semi-Supervised Model



Abstract
:1. Introduction
- This paper proposes a semi-supervised method for generating Chinese characters with a more complete structure. Stroke encoding is employed to capture fine-grained details, while a small quantity of paired data is integrated to offer supervised information regarding the overall structural characteristics of Chinese characters. This enables the model to effectively capture the structural intricacies of Chinese characters. To assist the model in accurately capturing stroke and structure information from these character images, we incorporate two additional loss functions.
- This paper involves the introduction of an attention module in the generator model. To enhance the model’s ability to capture the relationship between local features and overall structure while maintaining the model as a lightweight module and improving the efficiency of Chinese character generation, we have implemented several enhancements to this module. These improvements are reflected in the addition of pooling operations to obtain information in the feature map while enhancing the connection between feature information and original features.
- This paper involves a comparative analysis and evaluation of the model’s performance, utilizing six font datasets for generating Chinese characters. Various methodologies are employed to assess the quality of the images generated after converting Chinese character styles. Quantitative results demonstrate that incorporating stroke encoding and the semi-supervised scheme effectively alleviates inherent challenges associated with the model. Furthermore, the attention module exhibits improved precision in capturing the interplay between individual strokes and the overall structure of Chinese characters.
2. Related Work
3. Stylish Chinese Font Generation
3.1. Font Generation Model Architecture
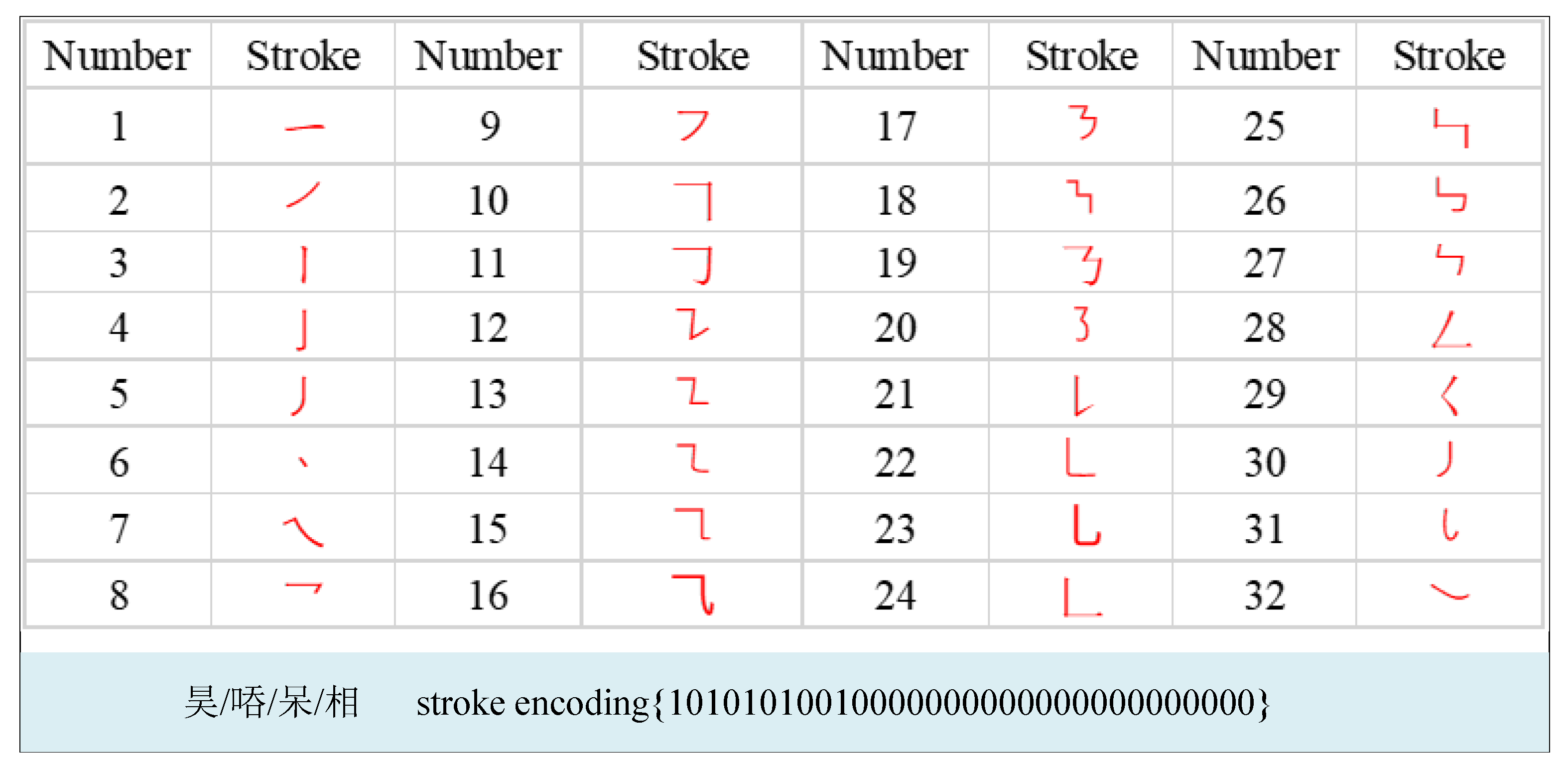
3.2. SE and Semi-Supervised Scheme
3.3. Improved Attention Module
- Three embedded feature spaces are used in this module. , , and are all constructed by 1 × 1 convolution. n is the size of the feature map, and c is the number of channels.
- To simplify the parameters of the attention module, accelerate the speed of the model, and obtain some feature information of Chinese characters and strokes, the average pool and maximum pool are used to obtain some feature information in the feature map. Average pooling and maximum pooling are used to obtain feature information in the two feature spaces and , respectively.
- The feature correlation matrix F is obtained by simple matrix multiplication of the two feature information and obtained earlier. Each element in the feature correlation matrix signifies the association between the average feature in and the significant feature in .In this context, each channel map can be considered as a response specific to Chinese character features, and these feature responses exhibit correlations among themselves. Consequently, the resulting feature correlation matrix carries significant physical meaning, where the row represents the statistical correlation between channel i and all other channels. By capitalizing on these inter-dependencies, we can effectively highlight the interdependent feature maps.
- The feature map m is derived by performing matrix multiplication between the feature correlation matrix and the feature space . This matrix effectively measures the response of each location to the overall characteristics present in the Chinese character image. This design establishes a linkage between the strokes and the overall structure of the Chinese image.The aforementioned mechanism strives to augment the channel features at every position by leveraging the amalgamation of all channels and integrating the inter-dependencies among them. Consequently, with the inclusion of the attention module in the model, the feature map gains the ability to transcend its local perceptual domain and discern the holistic structural characteristics of the Chinese character by gauging the response to global features.
- In order to make the attention module also pay better attention to the original features, based on inspiration from the residual network, we have summed the original feature x with obtained non-local feature mapping m to yield the perceptually enhanced features. In order to allow the attention module not to affect the pre-trained model and at the same time to better regulate the weight relationship between the two features, we limit the coefficients to the non-local feature mappings, which can solve some problems perfectly. Additionally, it will automatically adjust its size according to the training of the model.Chinese character images are different from natural images, so we improved their attention module. The module can pay good attention to the features of Chinese characters while alleviating the parameters of the module and improving the efficiency of model generation. Moreover, it has been shown in the literature [35] that nonlinear operations are not essential in attention modules.
3.4. Training Loss for Our Model
3.4.1. Adversarial Loss
3.4.2. Cycle Consistency Loss
3.4.3. SE Reconstruction Loss
3.4.4. Semi-Supervised Loss
3.4.5. Total Training Loss
4. Experiments
4.1. Experimental Setting
4.1.1. Data Preparation
4.1.2. Network Framework and Optimizer
4.1.3. Evaluation Metrics
4.2. Experimental Results
4.2.1. Effectiveness of Our Model
4.2.2. Ablation Experiments
4.2.3. Comparison with Advanced Methods
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Lin, J.W.; Hong, C.Y.; Chang, R.I.; Wang, Y.C.; Lin, S.Y.; Ho, J.M. Complete font generation of Chinese characters in personal handwriting style. In Proceedings of the 2015 IEEE 34th International Performance Computing and Communications Conference (IPCCC), Nanjing, China, 14–16 December 2015; pp. 1–5. [Google Scholar]
- Zhu, J.Y.; Park, T.; Isola, P.; Efros, A.A. Unpaired image-to-image translation using cycle-consistent adversarial networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2223–2232. [Google Scholar]
- Isola, P.; Zhu, J.Y.; Zhou, T.; Efros, A.A. Image-to-image translation with conditional adversarial networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–16 July 2017; pp. 1125–1134. [Google Scholar]
- Goodfellow, I.J.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative Adversarial Nets. Stat 2014, 1050, 10. [Google Scholar]
- Mirza, M.; Osindero, S. Conditional generative adversarial nets. arXiv 2014, arXiv:1411.1784. [Google Scholar]
- Chang, B.; Zhang, Q.; Pan, S.; Meng, L. Generating handwritten chinese characters using cyclegan. In Proceedings of the 2018 IEEE Winter Conference on Applications of Computer Vision (WACV), Lake Tahoe, NV, USA, 12–15 March 2018; pp. 199–207. [Google Scholar]
- Zeng, J.; Chen, Q.; Liu, Y.; Wang, M.; Yao, Y. Strokegan: Reducing mode collapse in chinese font generation via stroke encoding. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtually, 2–9 February 2021; Volume 35, pp. 3270–3277. [Google Scholar]
- Zhang, H.; Goodfellow, I.; Metaxas, D.; Odena, A. Self-attention generative adversarial networks. In Proceedings of the International Conference on Machine Learning, PMLR, Long Beach, CA, USA, 9–15 June 2019; pp. 7354–7363. [Google Scholar]
- Xu, S.; Lau, F.C.; Cheung, W.K.; Pan, Y. Automatic generation of artistic Chinese calligraphy. IEEE Intell. Syst. 2005, 20, 32–39. [Google Scholar]
- Chang, J.; Gu, Y. Chinese typography transfer. arXiv 2017, arXiv:1707.04904. [Google Scholar]
- Jiang, Y.; Lian, Z.; Tang, Y.; Xiao, J. Scfont: Structure-guided Chinese font generation via deep stacked networks. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; Volume 33, pp. 4015–4022. [Google Scholar]
- Zhang, J.; Chen, D.; Han, G.; Li, G.; He, J.; Liu, Z.; Ruan, Z. SSNet: Structure-Semantic Net for Chinese typography generation based on image translation. Neurocomputing 2020, 371, 15–26. [Google Scholar] [CrossRef]
- Tian, Y. zi2zi: Master Chinese Calligraphy with Conditional Adversarial Networks. 2017, Volume 3, p. 2. Available online: https://github.com/kaonashi-Tyc/zi2zi (accessed on 16 January 2023).
- Chen, J.; Ji, Y.; Chen, H.; Xu, X. Learning one-to-many stylised Chinese character transformation and generation by generative adversarial networks. IET Image Process. 2019, 13, 2680–2686. [Google Scholar] [CrossRef]
- Wu, S.J.; Yang, C.Y.; Hsu, J.Y.J. Calligan: Style and structure-aware chinese calligraphy character generator. arXiv 2020, arXiv:2005.12500. [Google Scholar]
- Liu, X.; Meng, G.; Xiang, S.; Pan, C. Handwritten Text Generation via Disentangled Representations. IEEE Signal Process. Lett. 2021, 28, 1838–1842. [Google Scholar] [CrossRef]
- Jiang, Y.; Lian, Z.; Tang, Y.; Xiao, J. DCFont: An end-to-end deep Chinese font generation system. In SIGGRAPH Asia 2017 Technical Briefs; ACM Digital Library’: New York, NY, USA, 2017; pp. 1–4. [Google Scholar]
- Kong, Y.; Luo, C.; Ma, W.; Zhu, Q.; Zhu, S.; Yuan, N.; Jin, L. Look Closer to Supervise Better: One-Shot Font Generation via Component-Based Discriminator. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 13482–13491. [Google Scholar]
- Chen, X.; Xie, Y.; Sun, L.; Lu, Y. DGFont++: Robust Deformable Generative Networks for Unsupervised Font Generation. arXiv 2022, arXiv:2212.14742. [Google Scholar]
- Liu, W.; Liu, F.; Ding, F.; He, Q.; Yi, Z. XMP-Font: Self-Supervised Cross-Modality Pre-training for Few-Shot Font Generation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 7905–7914. [Google Scholar]
- Zhu, X.; Lin, M.; Wen, K.; Zhao, H.; Sun, X. Deep deformable artistic font style transfer. Electronics 2023, 12, 1561. [Google Scholar] [CrossRef]
- Xue, M.; Ito, Y.; Nakano, K. An Art Font Generation Technique using Pix2Pix-based Networks. Bull. Netw. Comput. Syst. Softw. 2023, 12, 6–12. [Google Scholar]
- Yuan, S.; Liu, R.; Chen, M.; Chen, B.; Qiu, Z.; He, X. Se-gan: Skeleton enhanced gan-based model for brush handwriting font generation. In Proceedings of the 2022 IEEE International Conference on Multimedia and Expo (ICME), Taipei, Taiwan, 18–22 July 2022; pp. 1–6. [Google Scholar]
- Qin, M.; Zhang, Z.; Zhou, X. Disentangled representation learning GANs for generalized and stable font fusion network. IET Image Process. 2022, 16, 393–406. [Google Scholar] [CrossRef]
- Gao, Y.; Wu, J. Gan-based unpaired chinese character image translation via skeleton transformation and stroke rendering. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 646–653. [Google Scholar]
- Wen, C.; Pan, Y.; Chang, J.; Zhang, Y.; Chen, S.; Wang, Y.; Han, M.; Tian, Q. Handwritten Chinese font generation with collaborative stroke refinement. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikola, HI, USA, 5–9 January 2021; pp. 3882–3891. [Google Scholar]
- Tang, L.; Cai, Y.; Liu, J.; Hong, Z.; Gong, M.; Fan, M.; Han, J.; Liu, J.; Ding, E.; Wang, J. Few-Shot Font Generation by Learning Fine-Grained Local Styles. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 7895–7904. [Google Scholar]
- Zhang, Y.; Man, J.; Sun, P. MF-Net: A Novel Few-shot Stylized Multilingual Font Generation Method. In Proceedings of the 30th ACM International Conference on Multimedia, Lisbon, Portugal, 10 October 2022; pp. 2088–2096. [Google Scholar]
- Wen, Q.; Li, S.; Han, B.; Yuan, Y. Zigan: Fine-grained chinese calligraphy font generation via a few-shot style transfer approach. In Proceedings of the 29th ACM International Conference on Multimedia, Virtual Event, 20–24 October 2021; pp. 621–629. [Google Scholar]
- Huang, H.; Yang, D.; Dai, G.; Han, Z.; Wang, Y.; Lam, K.M.; Yang, F.; Huang, S.; Liu, Y.; He, M. AGTGAN: Unpaired Image Translation for Photographic Ancient Character Generation. In Proceedings of the 30th ACM International Conference on Multimedia, Lisbon, Portugal, 10 October 2022; pp. 5456–5467. [Google Scholar]
- Zeng, J.; Wang, Y.; Chen, Q.; Liu, Y.; Wang, M.; Yao, Y. StrokeGAN+: Few-Shot Semi-Supervised Chinese Font Generation with Stroke Encoding. arXiv 2022, arXiv:2211.06198. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Schroff, F.; Adam, H. Rethinking atrous convolution for semantic image segmentation. arXiv 2017, arXiv:1706.05587. [Google Scholar]
- Wang, F.; Jiang, M.; Qian, C.; Yang, S.; Li, C.; Zhang, H.; Wang, X.; Tang, X. Residual attention network for image classification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 3156–3164. [Google Scholar]
- Zhang, Y.; Tian, Y.; Kong, Y.; Zhong, B.; Fu, Y. Residual dense network for image restoration. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 43, 2480–2495. [Google Scholar] [CrossRef] [PubMed]
- Wang, Z.; Li, J.; Song, G.; Li, T. Less memory, faster speed: Refining self-attention module for image reconstruction. arXiv 2019, arXiv:1905.08008. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In Proceedings of the International Conference on Machine Learning, PMLR, Lille, France, 7–9 July 2015; pp. 448–456. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going Deeper with Convolutions. arXiv 2014, arXiv:1409.4842. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Encode | Kernel Size | Connection Method | Stride | Number of Filters |
|---|---|---|---|---|
| 7 × 7 | Conv-Norm-ReLU | 1 | 64 | |
| 3 × 3 | Conv-Norm-ReLU | 2 | 128 | |
| 3 × 3 | Conv-Norm-ReLU | 2 | 256 | |
| Transform | Residual blocks | |||
| Resbet block1 | ||||
| … | ||||
| Resbet block9 | ||||
| Improved attention module | ||||
| Decoder | Kernel Size | Connection Method | Stride | Number of Filters |
| 3 × 3 | Conv-Norm-ReLU | 2 | 128 | |
| 3 × 3 | Conv-Norm-ReLU | 2 | 64 | |
| 7 × 7 | Conv-Norm-ReLU | 1 | 3 |
| Font Type | Content Acc (%) | Stroke Error () | ||
|---|---|---|---|---|
| StrokeGAN | Ours | StrokeGAN | Ours | |
| 89.5 | 93.8 | 5.94 | 3.07 | |
| 84.3 | 88.8 | 6.83 | 4.54 | |
| 86.1 | 89.3 | 7.47 | 6.25 | |
| 87.3 | 89.4 | 7.14 | 5.79 | |
| 86.4 | 90.9 | 6.22 | 3.98 | |
| Character Style Translation | Shu | Hanyi Linbo | ||
|---|---|---|---|---|
| Content Acc | Stroke Error | Content Acc | Stroke Error | |
| Ours | 93.1 | 3.58 | 88.6 | 6.40 |
| Ours | 93.8 | 3.07 | 89.3 | 6.25 |
| Character Style Translation | Hanyi Linbo | Shu | ||
|---|---|---|---|---|
| Content Acc | Stroke Error | Content Acc | Stroke Error | |
| StrokeGAN | 86.1 | 7.47 | 89.5 | 5.94 |
| Without S-S+SE | 86.9 | 7.01 | 90.3 | 5.55 |
| Without Atten | 88.7 | 6.53 | 92.9 | 4.28 |
| Ours | 89.3 | 6.25 | 93.8 | 3.07 |
| Methods | Zi2zi | CycleGAN | StrokeGAN | Ours |
|---|---|---|---|---|
| Content acc (%). | 91.0 | 86.2 | 89.5 | 93.8 |
| Stroke error(). | 4.89 | 6.83 | 5.94 | 3.01 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tian, X.; Yang, F.; Tang, F. Generating Structurally Complete Stylish Chinese Font Based on Semi-Supervised Model. Appl. Sci. 2023, 13, 10650. https://doi.org/10.3390/app131910650
Tian X, Yang F, Tang F. Generating Structurally Complete Stylish Chinese Font Based on Semi-Supervised Model. Applied Sciences. 2023; 13(19):10650. https://doi.org/10.3390/app131910650
Chicago/Turabian StyleTian, Xianqing, Fang Yang, and Fan Tang. 2023. "Generating Structurally Complete Stylish Chinese Font Based on Semi-Supervised Model" Applied Sciences 13, no. 19: 10650. https://doi.org/10.3390/app131910650