
LCA-YOLOv8-Seg: An Improved Lightweight YOLOv8-Seg for Real-Time Pixel-Level Crack Detection of Dams and Bridges

Abstract
:1. Introduction
- A crack detection method based on an improved one-stage instance segmentation model LCA-YOLOv8n-seg is proposed. Our method is able to frame cracks and depict crack regions at the pixel level. Our method is real-time, highly accurate, small in volume and friendly to low performance devices.
- A new backbone network LCANet and a novel ProtoC1 module are proposed, which reduces the model volume drastically and has high detection accuracy.
2. Method
2.1. Crack Detection Network Architecture
2.1.1. Overview of YOLOv8-Seg
2.1.2. LCA-YOLOv8-Seg
2.2. New Backbone: Lightweight Channel Attention Network (LCANet)
2.3. More Efficient Prototype Mask Branch: ProtoC1
2.4. The Transfer Learning Strategy
3. Training and Testing Results
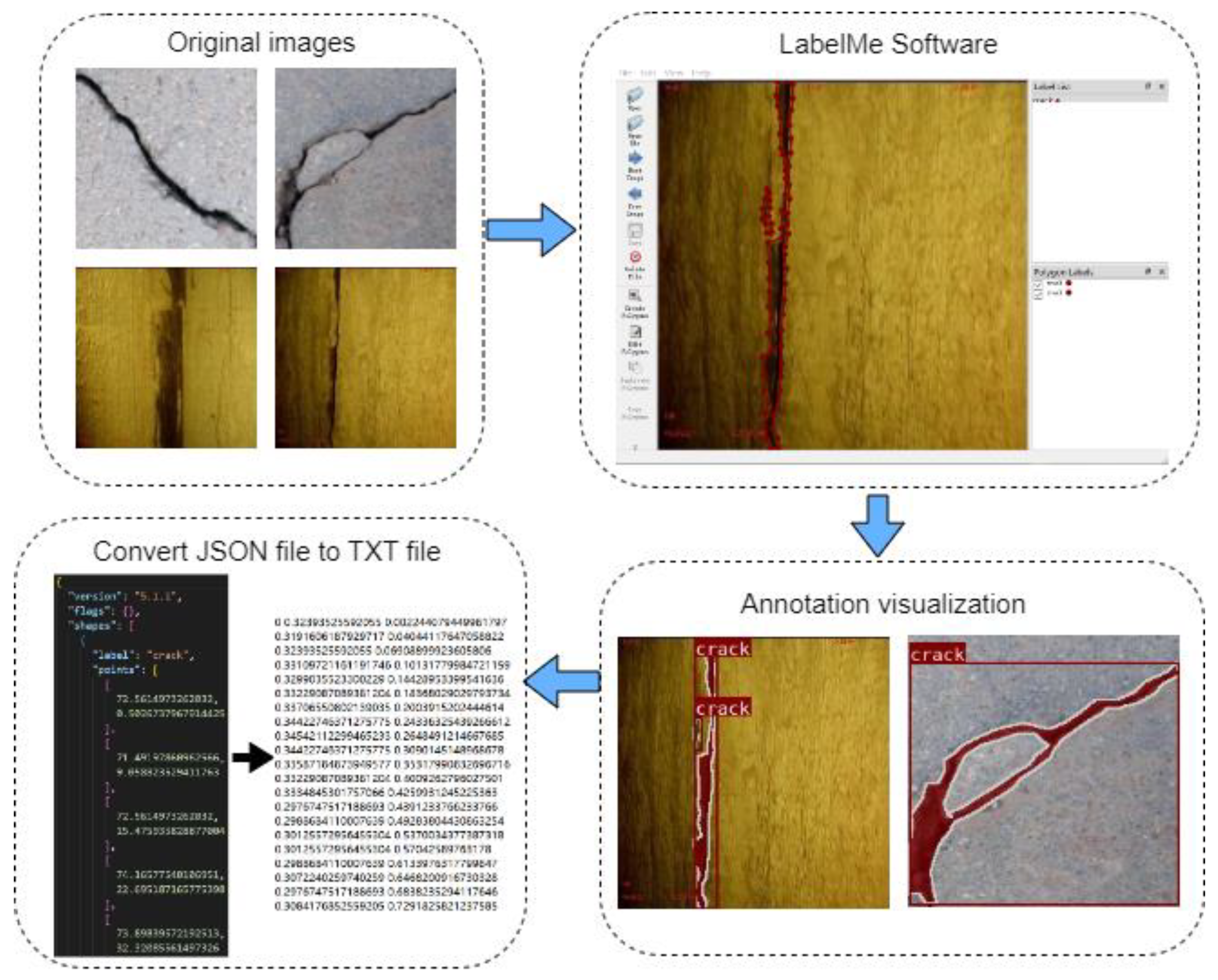
3.1. Crack Dataset
3.1.1. Underwater Dam Crack Images
3.1.2. Concrete Crack Images for Classification [27]
3.2. Data Pre-Processing and Data Augmentation
3.3. Implementation Details
3.4. Evaluations Metrics
3.5. Experimental Results
3.6. Crack Detection Results
4. Comparative Experiment and Ablation Study
4.1. Comparison of Different Crack Detection Method
4.2. Comparison of Performance and Instance Mask of Different Prototype Branches
4.2.1. Comparison of Performance of Different Proto Modules
4.2.2. Comparison of Instance Mask of Different Proto Modules
4.3. Ablation Study
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Stricker, R.; Eisenbach, M.; Sesselmann, M.; Debes, K.; Gross, H.-M. Improving visual road condition assessment by extensive experiments on the extended gaps dataset. In Proceedings of the International Joint Conference on Neural Networks (IJCNN), Budapest, Hungary, 14–19 July 2019; pp. 1–8. [Google Scholar] [CrossRef]
- Li, Z. Global sensitivity analysis of the static performance of concrete gravity dam from the viewpoint of structural health monitoring. Arch. Comput. Methods Eng. 2021, 28, 1611–1646. [Google Scholar] [CrossRef]
- Xiang, Y.; Sheng, J.; Wang, L.; Cai, Y.; Meng, Y.; Cai, W. Research progresses on equipment technologies used in safety inspection, repair, and reinforcement for deepwater dams. Sci. China Technol. Sci. 2022, 65, 1059–1071. [Google Scholar] [CrossRef]
- Tan, Y.; Li, S.; Liu, H.; Chen, P.; Zhou, Z. Automatic inspection data collection of building surface based on BIM and UAV. Autom. Constr. 2021, 131, 103881. [Google Scholar] [CrossRef]
- Lund-Hansen, L.C.; Juul, T.; Eskildsen, T.D.; Hawes, I.; Sorrell, B.; Melvad, C.; Hancke, K. A low-cost remotely operated vehicle (ROV) with an optical positioning system for under-ice measurements and sampling. Cold Reg. Sci. Technol. 2018, 151, 148–155. [Google Scholar] [CrossRef]
- Capocci, R.; Dooly, G.; Omerdić, E.; Coleman, J.; Newe, T.; Toal, D. Inspection-class remotely operated vehicles—A review. J. Mar. Sci. Eng. 2017, 5, 13. [Google Scholar] [CrossRef]
- Kheradmandi, N.; Mehranfar, V. A critical review and comparative study on image segmentation-based techniques for pavement crack detection. Constr. Build. Mater. 2022, 321, 126162. [Google Scholar] [CrossRef]
- Wang, C.-Y.; Bochkovskiy, A.; Liao, H.-Y.M. YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 7464–7475. [Google Scholar] [CrossRef]
- Qin, X.; Zhang, Z.; Huang, C.; Dehghan, M.; Zaiane, O.R.; Jagersand, M. U2-Net: Going deeper with nested U-structure for salient object detection. Pattern Recognit. 2020, 106, 107404. [Google Scholar] [CrossRef]
- Li, F.; Zhang, H.; Xu, H.; Liu, S.; Zhang, L.; Ni, L.M.; Shum, H.-Y. Mask dino: Towards a unified transformer-based framework for object detection and segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 3041–3050. [Google Scholar] [CrossRef]
- Chen, H.; Sun, K.; Tian, Z.; Shen, C.; Huang, Y.; Yan, Y. Blendmask: Top-down meets bottom-up for instance segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 8573–8581. [Google Scholar] [CrossRef]
- Cardellicchio, A.; Ruggieri, S.; Nettis, A.; Renò, V.; Uva, G. Physical interpretation of machine learning-based recognition of defects for the risk management of existing bridge heritage. Eng. Fail. Anal. 2023, 149, 107237. [Google Scholar] [CrossRef]
- Cardellicchio, A.; Ruggieri, S.; Nettis, A.; Mosca, N.; Uva, G.; Renò, V. On the use of YOLOv5 for detecting common defects on existing RC bridges. In Proceedings of the Multimodal Sensing and Artificial Intelligence: Technologies and Applications III, Munich, Germany, 26–30 June 2023; pp. 134–141. [Google Scholar] [CrossRef]
- Uzar, M.; Öztürk, Ş.; Bayrak, O.C.; Arda, T.; Öcalan, N.T. Performance analysis of YOLO versions for automatic vehicle detection from UAV images. Adv. Remote Sens. 2021, 1, 16–30. [Google Scholar]
- Bayramoğlu, Z.; Melis, U. Performance analysis of rule-based classification and deep learning method for automatic road extraction. Int. J. Eng. Geosci. 2023, 8, 83–97. [Google Scholar] [CrossRef]
- Zhang, Q.; Barri, K.; Babanajad, S.K.; Alavi, A.H. Real-time detection of cracks on concrete bridge decks using deep learning in the frequency domain. Engineering 2021, 7, 1786–1796. [Google Scholar] [CrossRef]
- Wang, W.; Su, C. Semi-supervised semantic segmentation network for surface crack detection. Autom. Constr. 2021, 128, 103786. [Google Scholar] [CrossRef]
- Xiang, X.; Wang, Z.; Qiao, Y. An improved YOLOv5 crack detection method combined with transformer. IEEE Sens. J. 2022, 22, 14328–14335. [Google Scholar] [CrossRef]
- Zhou, Z.; Zhang, J.; Gong, C. Automatic detection method of tunnel lining multi-defects via an enhanced You Only Look Once network. Comput. Aided Civ. Infrastruct. Eng. 2022, 37, 762–780. [Google Scholar] [CrossRef]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar] [CrossRef]
- Zhang, J.; Qian, S.; Tan, C. Automated bridge surface crack detection and segmentation using computer vision-based deep learning model. Eng. Appl. Artif. Intell. 2022, 115, 105225. [Google Scholar] [CrossRef]
- Xu, X.; Zhao, M.; Shi, P.; Ren, R.; He, X.; Wei, X.; Yang, H. Crack detection and comparison study based on faster R-CNN and mask R-CNN. Sensors 2022, 22, 1215. [Google Scholar] [CrossRef] [PubMed]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar] [CrossRef]
- Wang, Q.; Wu, B.; Zhu, P.; Li, P.; Zuo, W.; Hu, Q. ECA-Net: Efficient channel attention for deep convolutional neural networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 11534–11542. [Google Scholar] [CrossRef]
- Ultralytics YOLOV8. Available online: https://github.com/ultralytics/ultralytics (accessed on 5 September 2023).
- Bolya, D.; Zhou, C.; Xiao, F.; Lee, Y.J. Yolact: Real-time instance segmentation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 9157–9166. [Google Scholar] [CrossRef]
- Concrete Crack Images for Classification. Available online: https://data.mendeley.com/datasets/5y9wdsg2zt/2 (accessed on 5 September 2023).

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Module | Input | Output | Mid | k | s | NL |
|---|---|---|---|---|---|---|
| Conv | 3 | 8 | - | 3 | 2 | RE |
| dblock | 8 | 8 | 12 | 3 | 2 | RE |
| dblock | 8 | 12 | 54 | 3 | 2 | RE |
| dblock | 12 | 12 | 66 | 3 | 1 | RE |
| dblock | 12 | 24 | 72 | 5 | 2 | RE |
| dblock | 24 | 24 | 180 | 5 | 1 | RE |
| dblock | 24 | 24 | 90 | 5 | 1 | RE |
| dblock | 24 | 24 | 108 | 5 | 1 | RE |
| dblock | 24 | 48 | 216 | 5 | 2 | RE |
| dblock | 48 | 48 | 432 | 5 | 1 | RE |
| dblock | 48 | 48 | 432 | 5 | 1 | RE |
| Model | Weight | Parameters | GFLOPs | FPS | ||
|---|---|---|---|---|---|---|
| YOLOv8n-seg | 7.15 M | 3409 K | 12.4 | 0.974 | 0.967 | 125 |
| YOLOv8s-seg | 23.62 M | 11,863 K | 41.9 | 0.992 | 0.989 | 113 |
| YOLOv8m-seg | 56.83 M | 27,286 K | 109.6 | 0.997 | 0.995 | 92 |
| YOLOv7-seg | 72.58 M | 37,847 K | 149 | 0.998 | 0.997 | 56 |
| Mask R-CNN | 169.45 M | 43,970 K | 134 | 0.996 | 0.998 | 39 |
| LCA-Yolov8-seg | 4.36 M | 2045 K | 6.1 | 0.945 | 0.933 | 129 |
| Module | Layer | Weight | Parameters | GFLOPs | ||
|---|---|---|---|---|---|---|
| YOLOv8m-seg(Proto) | 331 | 41.82 M | 27,286 K | 109.6 | 0.995 | 0.785 |
| +ProtoC1 | 325 | 40.51 M | 26,671 K | 90.8 | 0.993 | 0.778 |
| YOLOv8n-seg(Proto) | 261 | 7.15 M | 3409 K | 12.4 | 0.967 | 0.716 |
| +ProtoC1 | 255 | 7.04 M | 3352 K | 10.7 | 0.966 | 0.713 |
| +ProtoC1(k = 1) | 255 | 7.01 M | 3336 K | 9.9 | 0.928 | 0.638 |
| Module | Layers | Weight | Parameters | GFLOPs | FPS | ||
|---|---|---|---|---|---|---|---|
| YOLOv8n-seg | 261 | 7.15 M | 3409 K | 12.4 | 0.974 | 0.967 | 125 |
| +ProtoC1 | 255 | 7.04 M | 3352 K | 10.7 | 0.974 | 0.966 | 125 |
| +LCANet | 276 | 4.48 M | 2113 K | 7.8 | 0.943 | 0.932 | 128 |
| LCA-YOLOv8-seg | 270 | 4.36 M | 2045 K | 6.1 | 0.942 | 0.929 | 129 |
| +TL | 270 | 4.36 M | 2045 K | 6.1 | 0.945 | 0.933 | 129 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wu, Y.; Han, Q.; Jin, Q.; Li, J.; Zhang, Y. LCA-YOLOv8-Seg: An Improved Lightweight YOLOv8-Seg for Real-Time Pixel-Level Crack Detection of Dams and Bridges. Appl. Sci. 2023, 13, 10583. https://doi.org/10.3390/app131910583
Wu Y, Han Q, Jin Q, Li J, Zhang Y. LCA-YOLOv8-Seg: An Improved Lightweight YOLOv8-Seg for Real-Time Pixel-Level Crack Detection of Dams and Bridges. Applied Sciences. 2023; 13(19):10583. https://doi.org/10.3390/app131910583
Chicago/Turabian StyleWu, Yang, Qingbang Han, Qilin Jin, Jian Li, and Yujing Zhang. 2023. "LCA-YOLOv8-Seg: An Improved Lightweight YOLOv8-Seg for Real-Time Pixel-Level Crack Detection of Dams and Bridges" Applied Sciences 13, no. 19: 10583. https://doi.org/10.3390/app131910583