
Visual Ranging Based on Object Detection Bounding Box Optimization

Abstract
:1. Introduction
2. Research Content and Works
- (1)
- To address the issue of ranging error caused by the non-fit phenomenon between the object detection bounding box and the object, an object detection bounding box optimization method is proposed which can eliminate pixel spacing and improve the fit degree of the bounding box and the object, thereby improving ranging accuracy.
- (2)
- In response to the lack of practical methods for measuring the distance to an object of unknown size in monocular visual ranging, a similar triangle ranging method based on height difference is proposed. This method can realize the distance measurement of an object of unknown size and also provides a new method for monocular visual distance measurement.
3. Methods
3.1. YOLOv5 Object Detection
3.1.1. Methods and Evaluation Indicators
3.1.2. Data Set Preparation
3.2. Object Detection Bounding Box Optimization
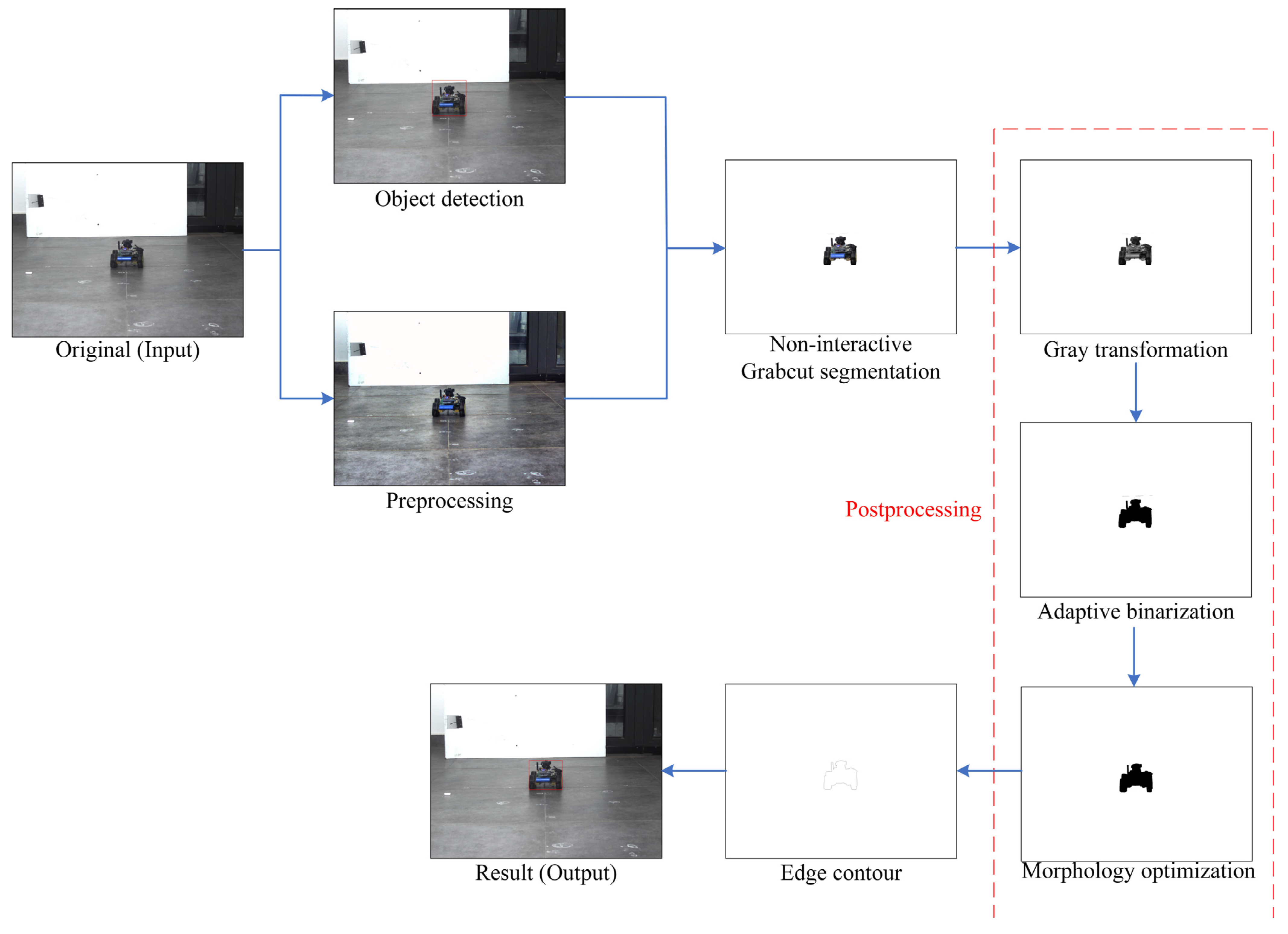
3.2.1. Methods and Principles
- (1)
- Object detection. The object in the image is detected using the detection model, and the bounding box data for the detected object is obtained.
- (2)
- Image preprocessing. First, the original RGB image is converted to an HSV image, and then divided into three single-channel images: Hue (H), Saturation (S), and Value (V), respectively. Then, the S image and the V image are processed using contrast limited adaptive histogram equalization (CLAHE). The processed single-channel images are merged into an HSV image and converted to an RGB image.
- (3)
- Non-interactive GrabCut foreground segmentation. The bounding box information from object detection in step (1) and the preprocessed image from step (2) are used as the input parameters for the GrabCut algorithm to achieve automatic non-interactive foreground segmentation, eliminating the need to manually set the foreground area in traditional interactive GrabCut segmentation.
- (4)
- Segmentation postprocessing. The segmentation postprocessing includes gray transformation, adaptive binarization and morphological optimization. The adaptive binarization threshold is generated automatically based on the background pixel value set after foreground segmentation.
- (5)
- Scanning the edge contour to obtain the optimized bounding box. The object contour is scanned by row and column pixels using the object detection bounding box from step (1) as the boundary, and the optimized object detection bounding box is obtained based on the column and row index.
3.2.2. Evaluation Indicator
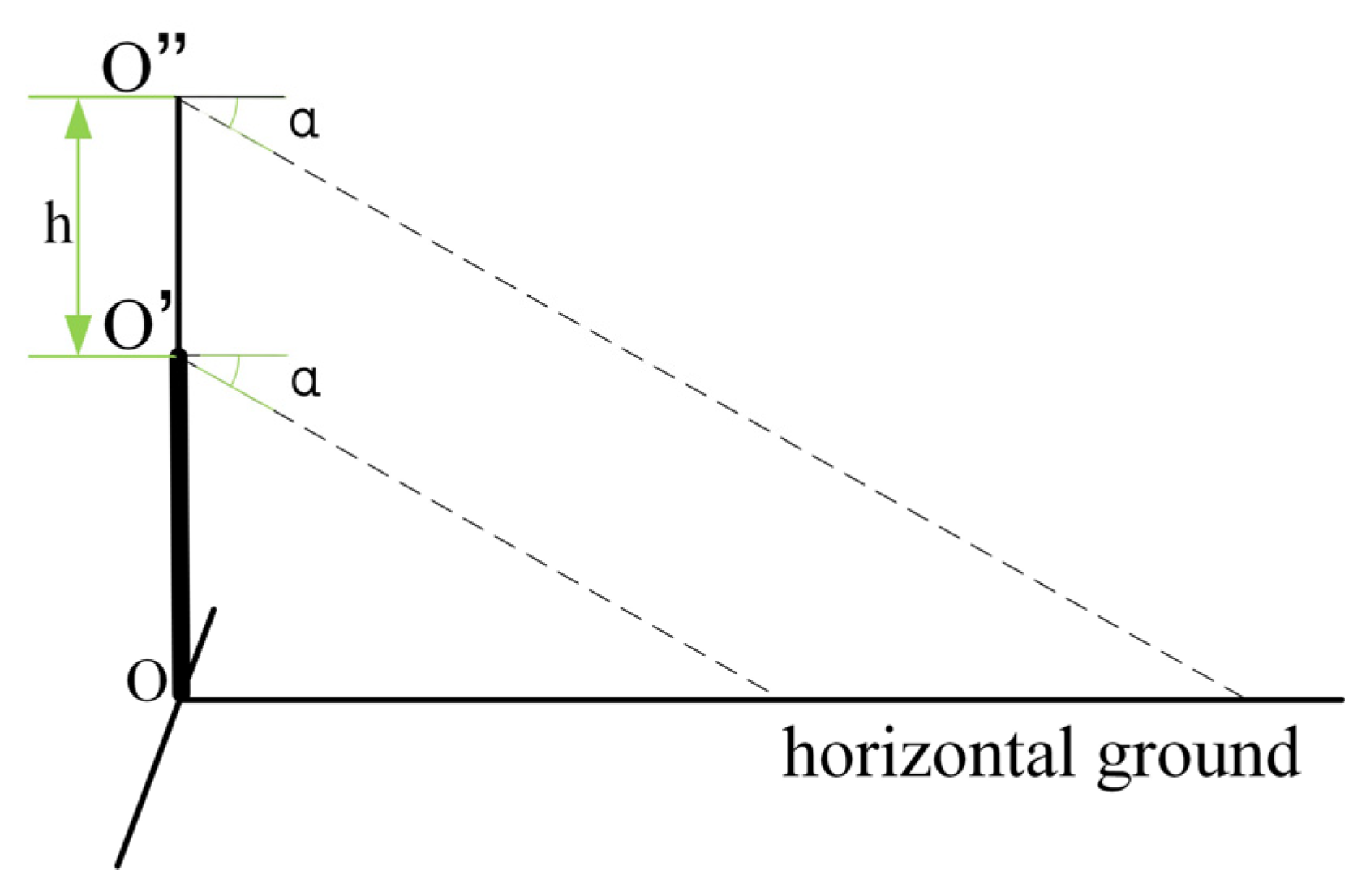
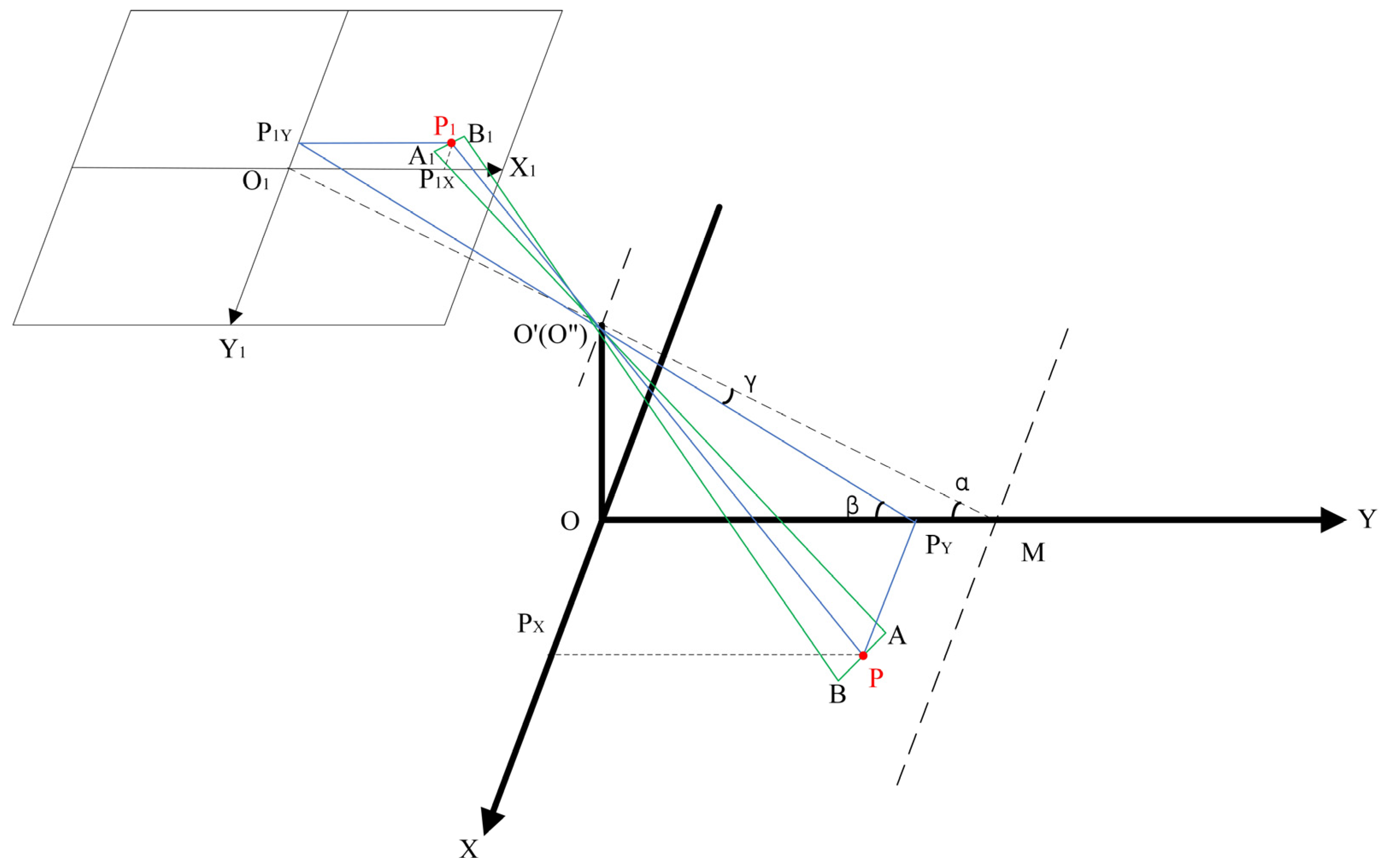
3.3. Similar Triangle Ranging Method Based on Height Difference
4. Experimental Results and Analysis
4.1. Object Detection
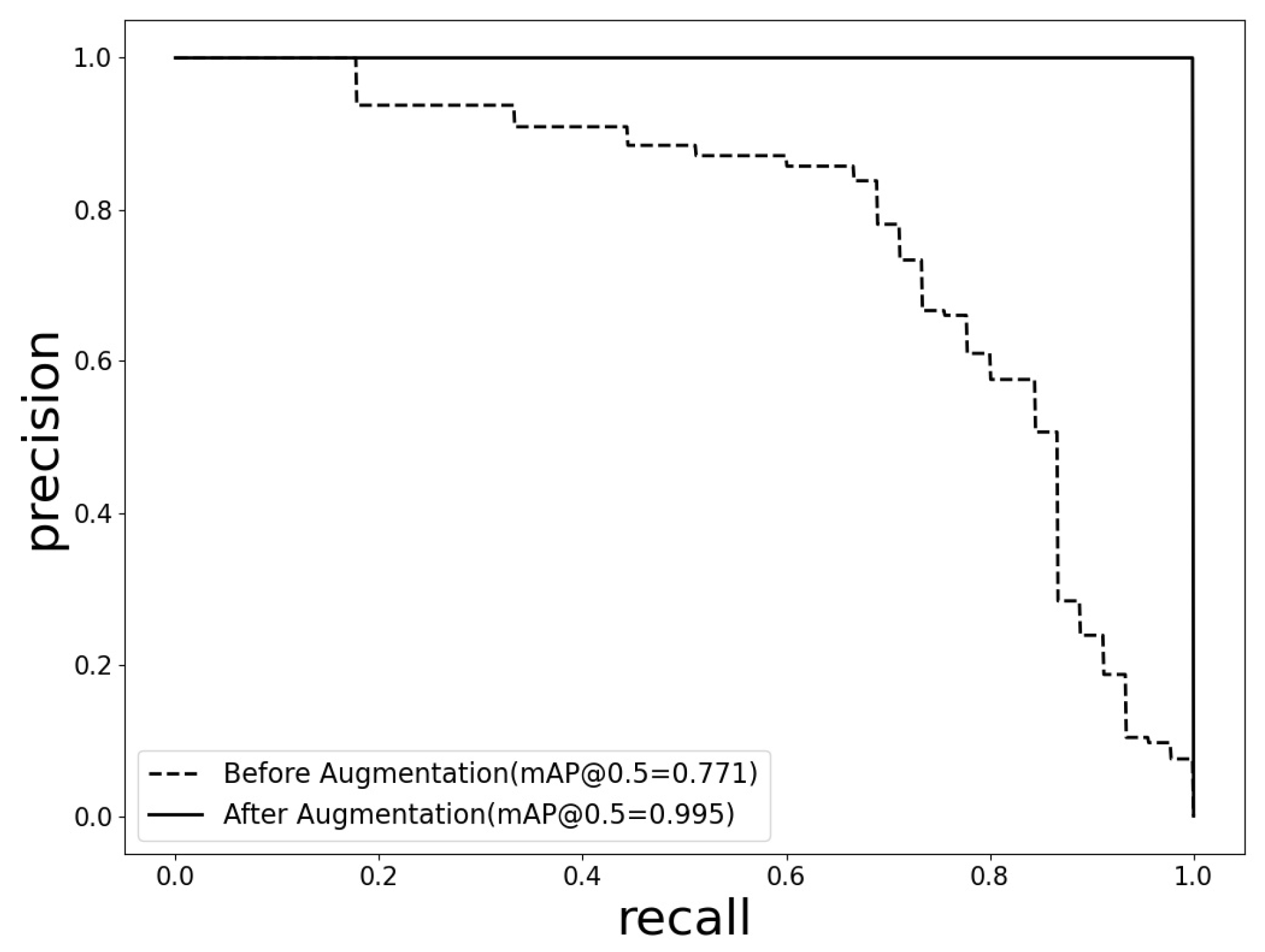
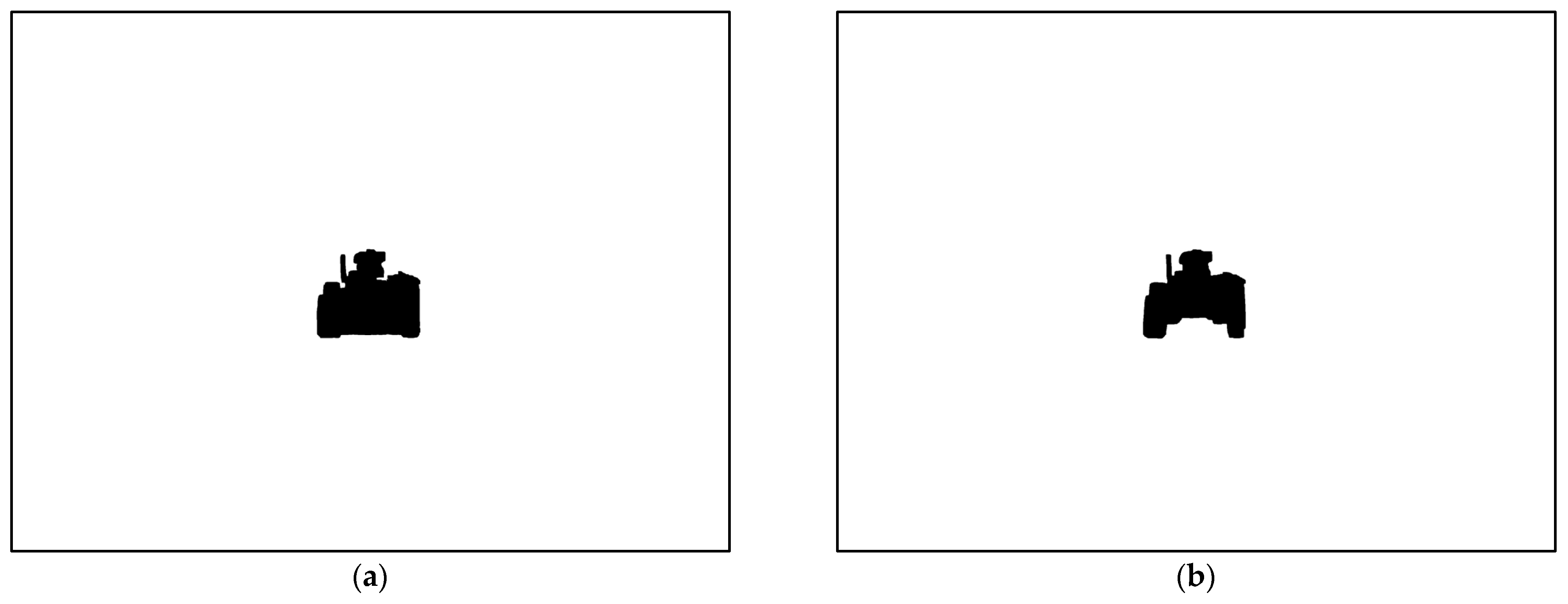
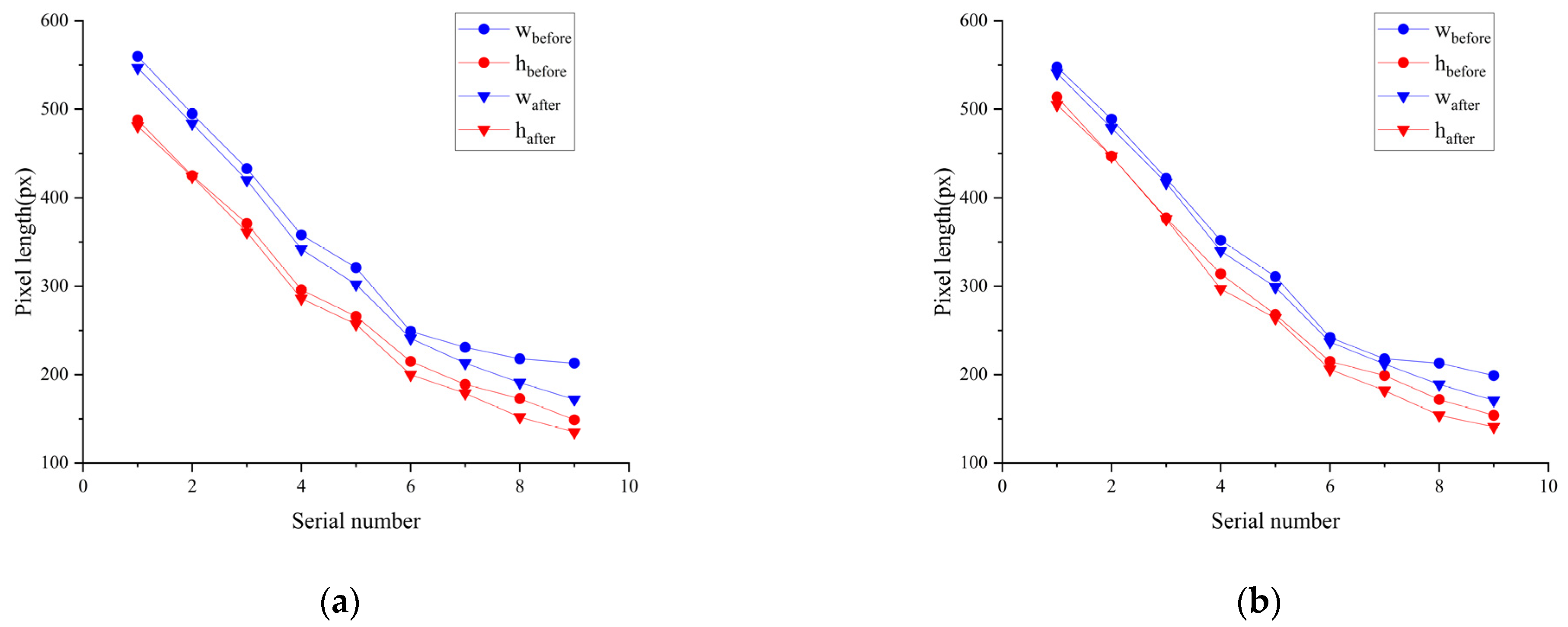
4.2. Object Detection Bounding Box Optimization Results
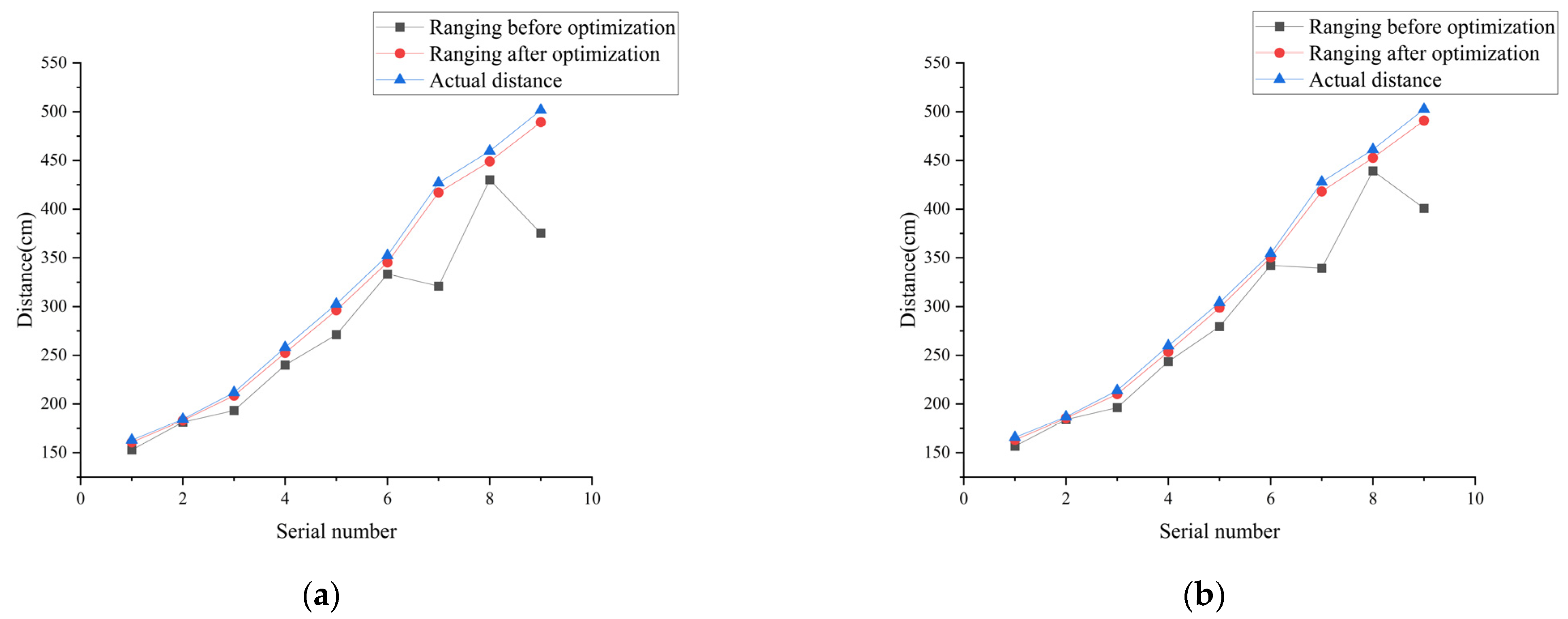
4.3. Ranging Results and Analysis
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Varuna, D.S.; Jamie, R.; Ahmet, K. Robust Fusion of LiDAR and Wide-Angle Camera Data for Autonomous Mobile Robots. Sensors 2018, 18, 2730. [Google Scholar]
- Tippetts, B.J.; Lee, D.J.; Archibald, J.K. An on-board vision sensor system for small unmanned vehicle applications. Mach. Vis. Appl. 2012, 23, 403–415. [Google Scholar] [CrossRef]
- Frag, A.L.; Yu, X.R.; Yi, W.J.; Saniie, J. Indoor Navigation System for Visually Impaired People using Computer Vision. In Proceedings of the 2022 IEEE International Conference on Electro Information Technology (eIT), Mankato, MN, USA, 19–21 May 2022; pp. 257–260. [Google Scholar]
- Li, S.; Zhao, Q. Research on the Emergency Obstacle Avoidance Strategy of Intelligent Vehicles Based on a Safety Distance Model. IEEE Access 2023, 11, 7124–7134. [Google Scholar] [CrossRef]
- Nunes, D.; Fortuna, J.; Damas, B.; Ventura, R. Real-time Vision Based Obstacle Detection in Maritime Environments. In Proceedings of the 2022 IEEE International Conference on Autonomous Robot Systems and Competitions (ICARSC), Santa Maria da Feira, Portugal, 29–30 April 2022; pp. 243–248. [Google Scholar]
- Xue, L.; Li, M.; Fan, L.; Sun, G.; Gao, T. Monocular Vision Ranging and Camera Focal Length Calibration. Sci. Program. 2021, 2021, 9979111. [Google Scholar] [CrossRef]
- Wang, H.; Sun, Y.; Wu, Q.M.J.; Lu, X.; Wang, X.; Zhang, Z. Self-supervised monocular depth estimation with direct methods. Neurocomputing 2021, 421, 340–348. [Google Scholar] [CrossRef]
- Arabi, S.; Sharma, A.; Reyes, M.; Hamann, C.; Peek-Asa, C. Farm vehicle following distance estimation using deep learning and monocular camera images. Sensors 2022, 22, 2736. [Google Scholar] [CrossRef]
- Li, Z.Q.; Gao, J.D.; Peng, K.; Liu, Q.Z.; Xu, X.W. Method of measurement vehicle distance based on PnP. Foreign. Electron. Meas. Technol. 2020, 39, 104–108. [Google Scholar]
- Zhang, Z.Z. Review of vehicle distance measurement based on monocular vision. Automot. Appl. Technol. 2022, 47, 153–157. [Google Scholar]
- Shen, Z.X.; Huang, X.Y. Monocular vision distance detection algorithm based on data regression modeling. Comput. Eng. Appl. 2007, 42, 15–18. [Google Scholar]
- Zhao, M.H.; Wang, J.H.; Zheng, X.; Zhang, S.J.; Zhang, C. Monocular vision based water-surface object distance measurement method for unmanned surface vehicles. Transducer Microsyst. Technol. 2021, 40, 47–104. [Google Scholar]
- Taigman, Y.; Yang, M.; Ranzato, M.; Wolf, L. DeepFace: Closing the Gap to Human-Level Performance in Face Verification. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 1701–1708. [Google Scholar]
- Ouyang, W.L.; Wang, X.G. Joint Deep Learning for Pedestrian Detection. In Proceedings of the 2013 IEEE International Conference on Computer Vision, Sydney, Australia, 1–8 December 2013; pp. 2056–2063. [Google Scholar]
- Kang, K.; Li, H.S.; Yan, J.J.; Zeng, X.Y.; Yang, B.; Xiao, T.; Zhang, C.; Wang, Z.; Wang, R.H.; Wang, X.G.; et al. Tubelets with Convolutional Neural Networks for Object Detection from Videos. IEEE Trans. Circuits Syst. Video Technol. 2017, 28, 2896–2907. [Google Scholar] [CrossRef]
- Li, Z.W.; Pang, C.X.; Dong, C.H.; Zeng, X.H. R-YOLOv5: A Lightweight Rotational Object Detection Algorithm for Real-Time Detection of Vehicles in Dense Scenes. IEEE Access 2023, 11, 61546–61559. [Google Scholar] [CrossRef]
- Felzenszwalb, P.F.; Girshick, R.B.; McAllester, D.; Ramanan, D. Object detection with discriminatively trained part-based models. IEEE Trans. Pattern Anal. Mach. Intell. 2009, 32, 1627–1645. [Google Scholar] [CrossRef]
- Uijlings, J.R.R.; Van De Sande, K.E.A.; Gevers, T.; Smeulders, A.W.M. Selective search for object recognition. Int. J. Comput. Vis. 2013, 104, 154–171. [Google Scholar] [CrossRef]
- Vedaldi, A.; Gulshan, V.; Varma, M.; Zisserman, A. Multiple kernels for object detection. In Proceedings of the 2009 IEEE 12th International Conference on Computer Vision, Kyoto, Japan, 29 September–2 October 2009; pp. 606–613. [Google Scholar]
- Yu, Y.N.; Zhang, J.G.; Huang, Y.Z.; Zheng, S.A.; Ren, W.Q.; Wang, C. Object detection by context and boosted HOG-LBP. In Proceedings of the ECCV Workshop on PASCAL VOC, CAS, Beijing, China, 10 September 2010. [Google Scholar]
- Huang, M.; Zhang, Y.; Chen, Y. Small Object Detection Model in Aerial Images Based on TCA-YOLOv5m. IEEE Access 2022, 11, 3352–3366. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. SSD: Single Shot MultiBox Detector. In Proceedings of the Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; pp. 21–37. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature Pyramid Networks for Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Meng, C.C.; Bao, H.; Ma, Y.; Xu, X.; Li, Y.Q. Visual Meterstick: Preceding Vehicle Ranging Using Monocular Vision Based on the Fitting Method. Symmetry 2019, 11, 1081. [Google Scholar] [CrossRef]
- Yang, R.; Yu, S.Y.; Yao, Q.H.; Huang, J.M.; Ya, F.M. Vehicle Distance Measurement Method of Two-Way Two-Lane Roads Based on Monocular Vision. Appl. Sci. 2023, 13, 3468. [Google Scholar] [CrossRef]
- Fu, Q.; Kong, J.M.; Ji, Y.F.; Ren, F.H. A method of UAV real-time ranging based on binocular vision. Electron. Opt. Control. 2023, 30, 94–99. [Google Scholar]
- Huang, T.Y.; Yang, X.J.; Xiang, G.H.; Chen, L. Study on small target pedestrian detection and ranging based on monocular vision. Comput. Sci. 2023, 30, 94–99. [Google Scholar]
- Halevy, A.; Norvig, P.; Pereira, F. The unreasonable effectiveness of data. IEEE. Intell. Syst. 2009, 24, 8–12. [Google Scholar] [CrossRef]
- Sun, C.; Shrivastava, A.; Singh, S.; Gupta, A. Revisiting Unreasonable Effectiveness of Data in Deep Learning Era. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 843–852. [Google Scholar]
- Mikołajczyk, A.; Grochowski, M. Data augmentation for improving deep learning in image classification problem. In Proceedings of the 2018 International Interdisciplinary PhD Workshop (IIPhDW), Świnouście, Poland, 9–12 May 2018; pp. 117–122. [Google Scholar]
- Shorten, C.; Khoshgoftaar, T.M. A survey on Image Data Augmentation for Deep Learning. JBD 2019, 6, 1–48. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameters | Parameter Settings |
|---|---|
| Camera model | MER-500-7UC |
| Image resolution (pixel) | 2592 × 1944 |
| Number of dataset images | 750 |
| Number of training set images | 525 |
| Number of testing set images | 225 |
| Image annotation tool | Labellmg |
| Network model | YOLOv5s |
| CPU | AMD EPYC 7601 |
| GPU | 3070-8G |
| Parameters | Precision | Recall | mAP@0.5 | FPS (f/s) |
| Result Values | 99.9% | 100% | 99.5% | 90.09 |
| Serial Number | Image at O′ Point | Image at O″ Point | ||
|---|---|---|---|---|
| WOV | HOV | WOV | HOV | |
| 1 | 2.32% | 1.43% | 1.28% | 1.75% |
| 2 | 2.22% | 0.24% | 2.05% | 0 |
| 3 | 3% | 2.7% | 1.19% | 0.27% |
| 4 | 4.47% | 3.38% | 3.41% | 5.41% |
| 5 | 8.92% | 3.38% | 3.86% | 1.49% |
| 6 | 3.21% | 6.98% | 2.07% | 4.19% |
| 7 | 7.79% | 5.29% | 2.75% | 8.54% |
| 8 | 12.38% | 12.14% | 11.27% | 10.46% |
| 9 | 19.24% | 9.39% | 14.07% | 8.44% |
| Serial Number | Image at O′ Point | Image at O″ Point | ||||||
|---|---|---|---|---|---|---|---|---|
| Actual Distance (cm) | Ranging before Optimization (cm) | Ranging after Optimization (cm) | Relative Error after Optimization | Actual Distance (cm) | Ranging before Optimization (cm) | Ranging after Optimization (cm) | Relative Error after Optimization | |
| 1 | 162.98 | 152.86 | 160.77 | 1.36% | 165.72 | 156.79 | 163.16 | 1.54% |
| 2 | 184.39 | 181.41 | 183.10 | 0.70% | 186.81 | 184.07 | 185.44 | 0.73% |
| 3 | 211.81 | 193.33 | 208.61 | 1.51% | 213.93 | 196.30 | 210.10 | 1.79% |
| 4 | 258.12 | 239.94 | 252.50 | 2.18% | 259.86 | 243.62 | 253.57 | 2.42% |
| 5 | 302.66 | 271.17 | 296.26 | 0.48% | 304.13 | 279.42 | 298.73 | 0.16% |
| 6 | 352.36 | 333.42 | 345.28 | 2.01% | 354.54 | 342.35 | 350.35 | 1.18% |
| 7 | 426.94 | 320.99 | 417.15 | 2.29% | 427.93 | 339.37 | 418.19 | 2.27% |
| 8 | 459.74 | 430.26 | 448.98 | 2.34% | 461.22 | 439.39 | 452.7 | 1.84% |
| 9 | 501.65 | 375.32 | 489.22 | 2.47% | 502.56 | 400.82 | 490.93 | 2.31% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shi, Z.; Li, Z.; Che, S.; Gao, M.; Tang, H. Visual Ranging Based on Object Detection Bounding Box Optimization. Appl. Sci. 2023, 13, 10578. https://doi.org/10.3390/app131910578
Shi Z, Li Z, Che S, Gao M, Tang H. Visual Ranging Based on Object Detection Bounding Box Optimization. Applied Sciences. 2023; 13(19):10578. https://doi.org/10.3390/app131910578
Chicago/Turabian StyleShi, Zhou, Zhongguo Li, Sai Che, Miaowei Gao, and Hongchuan Tang. 2023. "Visual Ranging Based on Object Detection Bounding Box Optimization" Applied Sciences 13, no. 19: 10578. https://doi.org/10.3390/app131910578