
Microbial Colony Detection Based on Deep Learning


Abstract
:1. Introduction
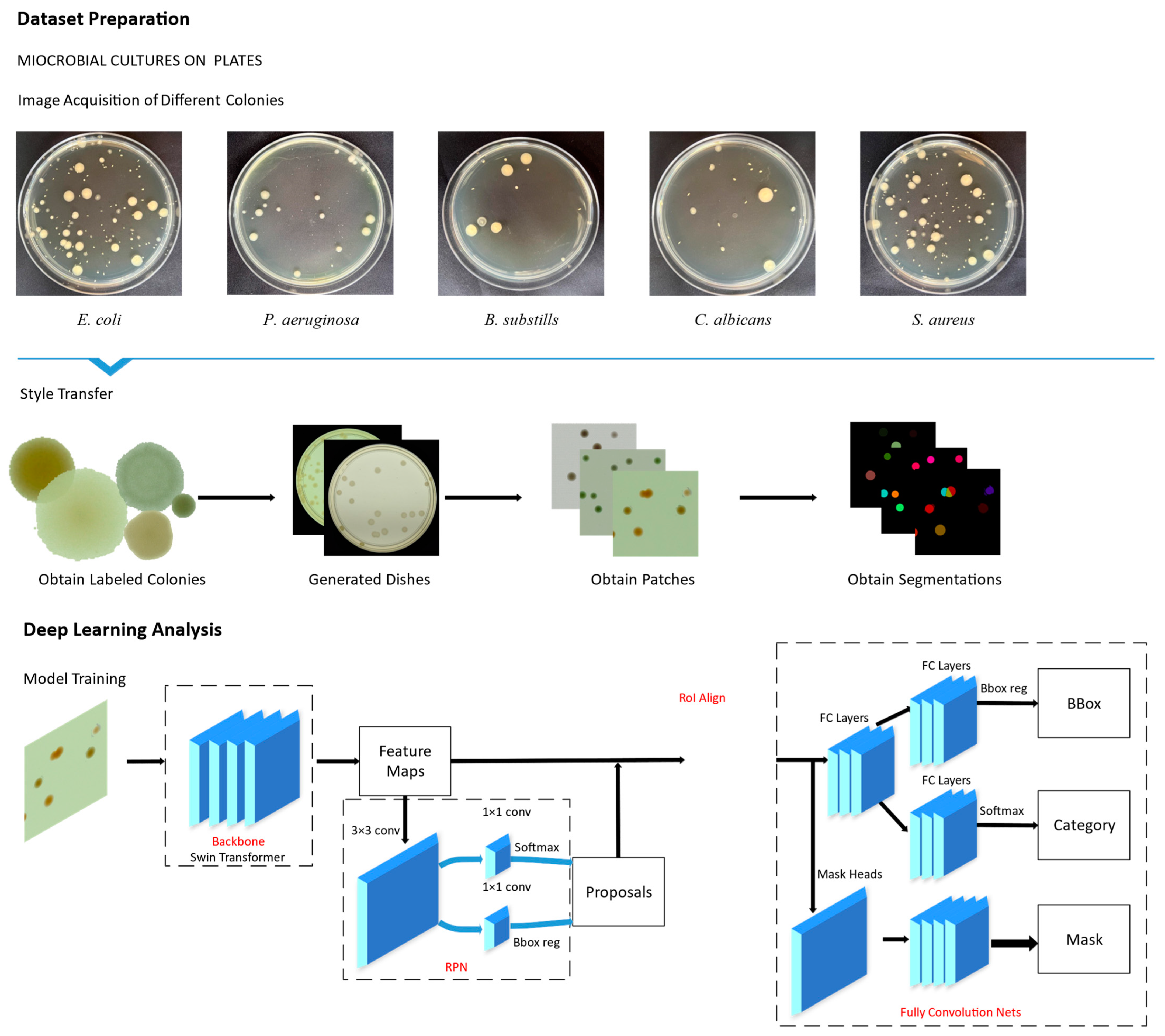
- We propose using style transfer to augment the microbial colony dataset, addressing challenges in acquisition due to contamination and unclear images, and reducing the manual effort required for handling a large number of colonies in the images.
- We combine style transfer and Swin Transformer for object detection on the AGAR datasets, where style transfer generates 4k images used for subsequent model training.
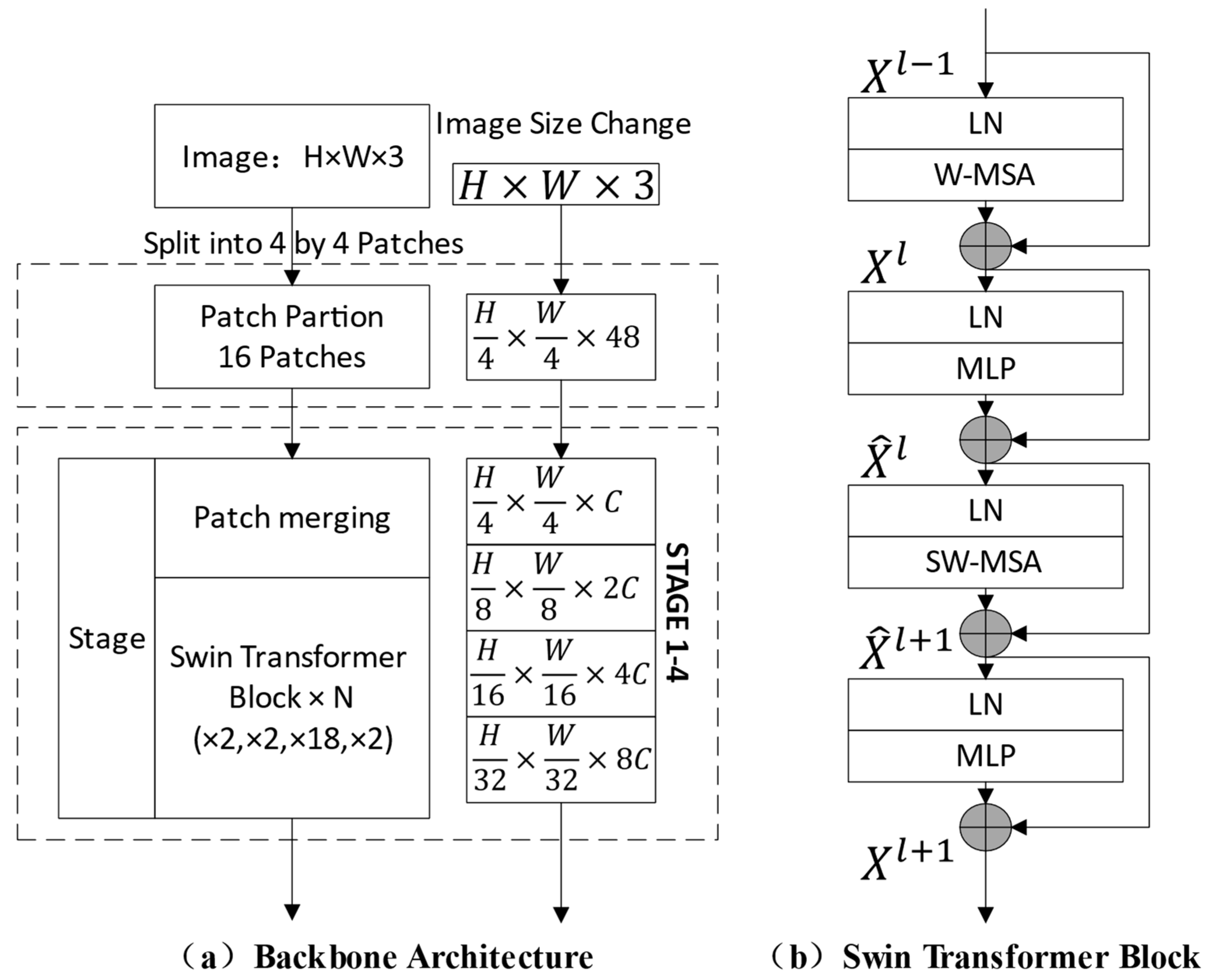
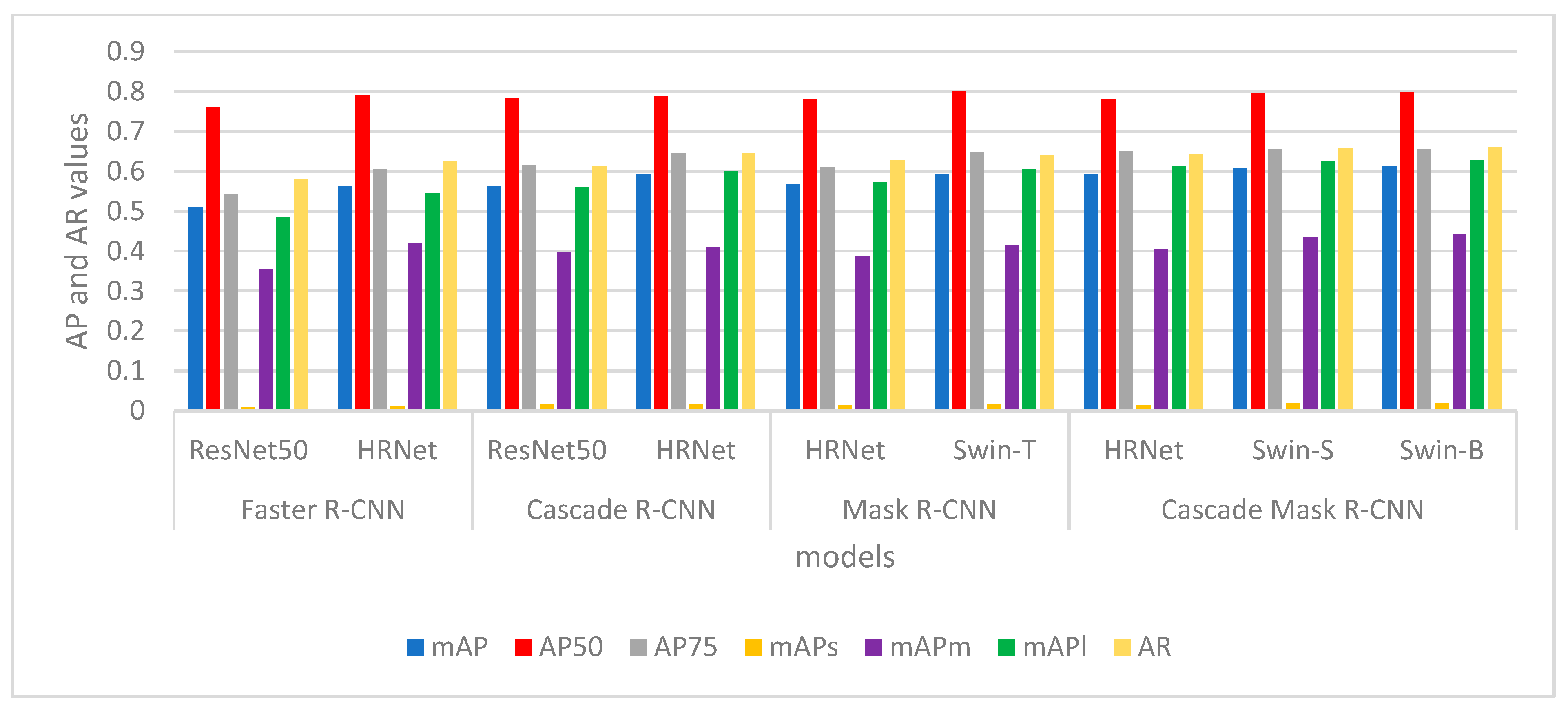
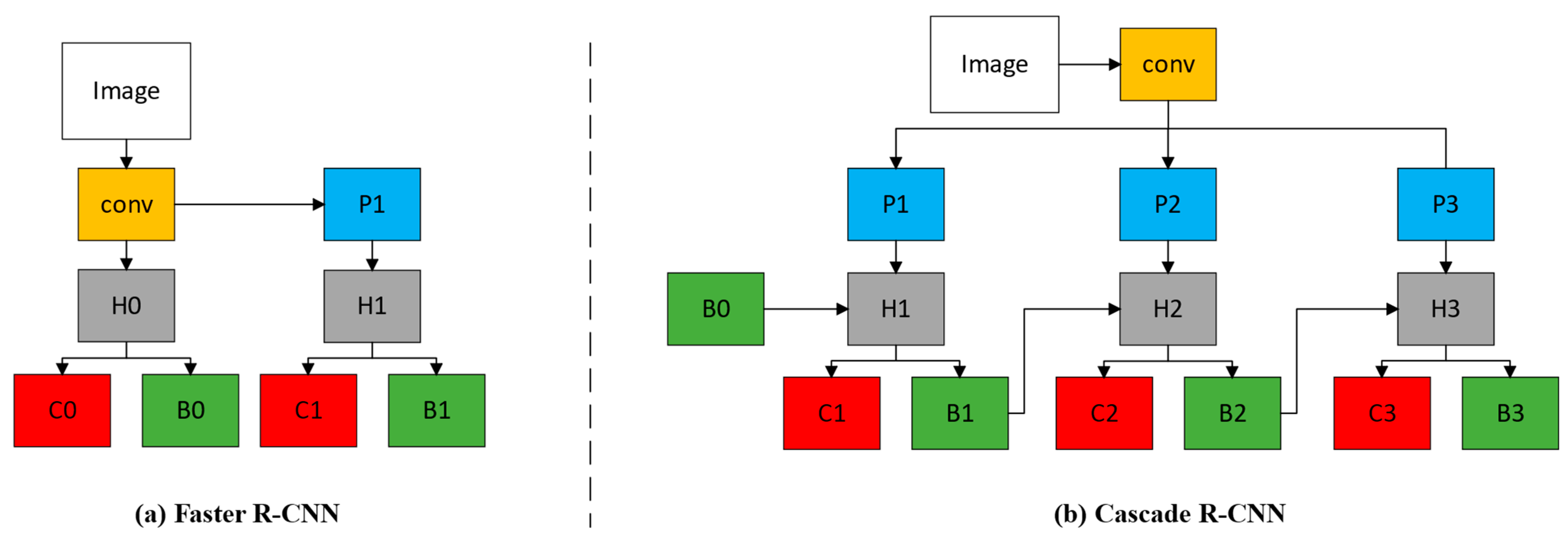
- We compare the model results of Faster R-CNN, Mask R-CNN, Cascade R-CNN, and Cascade Mask R-CNN with High-Resolution Network (HRNet) [23] and Swin Transformer backbone, and use the mAP, AR, etc., as the evaluation metrics for the model. While the traditional Transformer performs self-attentive computation on the entire input sequence, the Swin Transformer introduces a hierarchical attention mechanism. It decomposes the image into multiple small non-overlapping blocks and performs the self-attentive computation on these blocks. This layered design reduces the computational complexity and enables better handling of large-sized images.
2. Related Work
2.1. Object Detection
2.2. Microbial Colony Identification
3. Materials and Methods
3.1. The Dataset
3.2. Style Transfer
3.3. Swin Transformer
4. Experiment
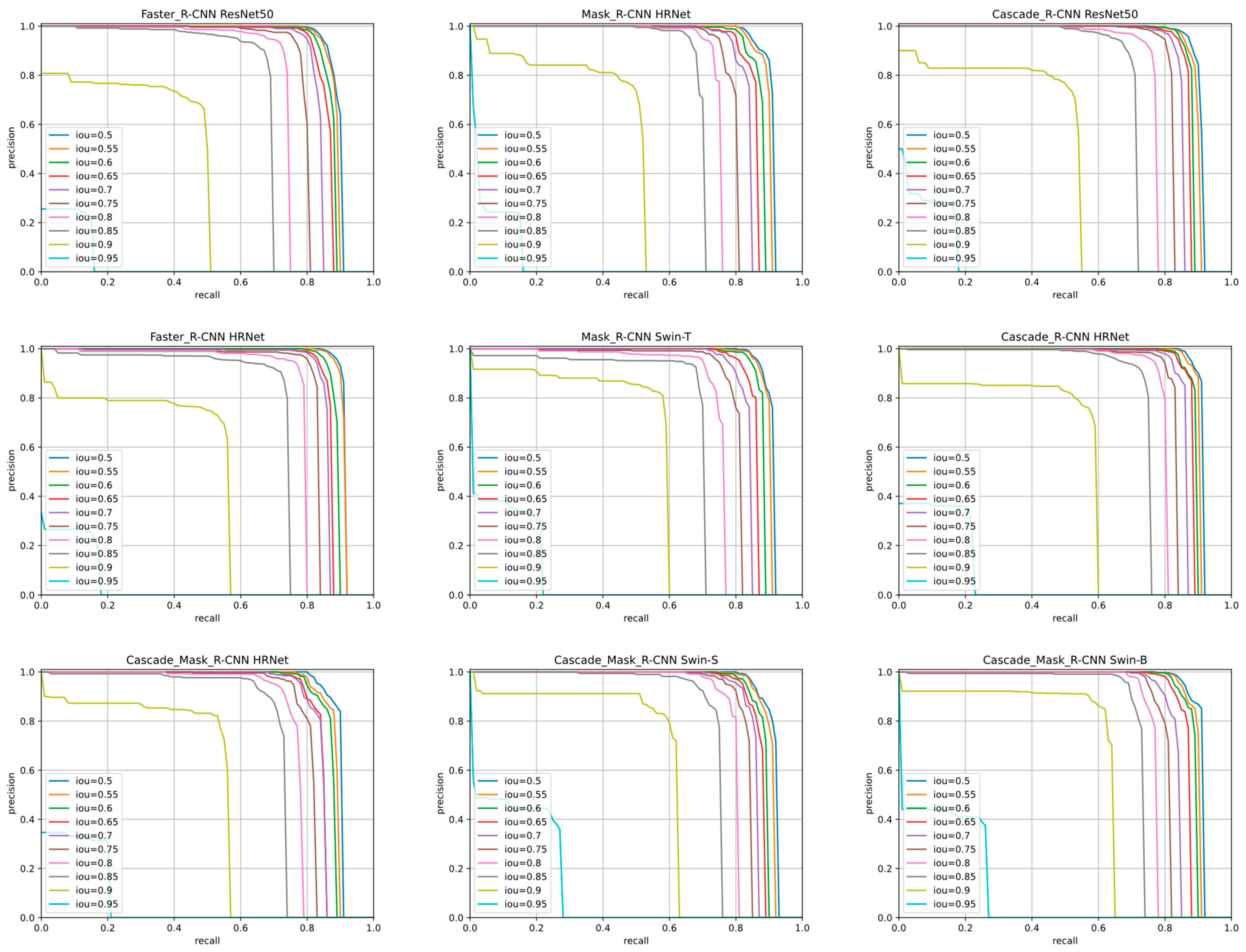
4.1. Evaluation Mertric
4.2. Training Configuration
4.3. Analysis and Evaluation
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Tsuchida, S.; Nakayama, T. MALDI-based mass spectrometry in clinical testing: Focus on bacterial identification. Appl. Sci. 2022, 12, 2814. [Google Scholar] [CrossRef]
- Gerhardt, P.; Murray, R.; Costilow, R.; Nester, E.W.; Wood, W.A.; Krieg, N.R.; Phillips, G.B. Manual of Methods for General Bacteriology; American Society for Microbiology: Washington, DC, USA, 1981; Volume 1. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Adv. Neural Inf. Process. Syst. 2012, 25, 1097–1105. [Google Scholar] [CrossRef]
- Cao, B.; Li, C.; Song, Y.; Qin, Y.; Chen, C. Network intrusion detection model based on CNN and GRU. Appl. Sci. 2022, 12, 4184. [Google Scholar] [CrossRef]
- Singh, V.; Gourisaria, M.K.; GM, H.; Rautaray, S.S.; Pandey, M.; Sahni, M.; Leon-Castro, E.; Espinoza-Audelo, L.F. Diagnosis of intracranial tumors via the selective CNN data modeling technique. Appl. Sci. 2022, 12, 2900. [Google Scholar] [CrossRef]
- Beznik, T.; Smyth, P.; de Lannoy, G.; Lee, J.A. Deep learning to detect bacterial colonies for the production of vaccines. Neurocomputing 2022, 470, 427–431. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. In Proceedings of the 3rd International Conference on Learning Representations (ICLR 2015), San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; p. 770. [Google Scholar]
- Tan, M.; Le, Q.V. EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks. In International Conference on Machine Learning; PMLR: London, UK, 2019; pp. 6105–6114. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30, 5998–6008. [Google Scholar]
- Han, K.; Wang, Y.; Chen, H.; Chen, X.; Guo, J.; Liu, Z.; Tang, Y.; Xiao, A.; Xu, C.; Xu, Y. A Survey on Vision Transformer. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 45, 87–110. [Google Scholar] [CrossRef]
- Zhang, J.; Ma, P.; Jiang, T.; Zhao, X.; Tan, W.; Zhang, J.; Zou, S.; Huang, X.; Grzegorzek, M.; Li, C. SEM-RCNN: A squeeze-and-excitation-based mask region convolutional neural network for multi-class environmental microorganism detection. Appl. Sci. 2022, 12, 9902. [Google Scholar] [CrossRef]
- Gillioz, A.; Casas, J.; Mugellini, E.; Abou Khaled, O. Overview of the Transformer-based Models for NLP Tasks. In Proceedings of the 2020 15th Conference on Computer Science and Information Systems (FedCSIS), Sofia, Bulgaria, 6–9 September 2020; pp. 179–183. [Google Scholar]
- Arnab, A.; Dehghani, M.; Heigold, G.; Sun, C.; Lučić, M.; Schmid, C. ViViT: A Video Vision Transformer. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Virtual, 11–17 October 2021; pp. 6816–6826. [Google Scholar]
- Hu, X.; Li, T.; Zhou, T.; Liu, Y.; Peng, Y. Contrastive learning based on transformer for hyperspectral image classification. Appl. Sci. 2021, 11, 8670. [Google Scholar] [CrossRef]
- Kolesnikov, A.; Dosovitskiy, A.; Weissenborn, D.; Heigold, G.; Uszkoreit, J.; Beyer, L.; Minderer, M.; Dehghani, M.; Houlsby, N.; Gelly, S. An Image is Worth 16 × 16 Words: Transformers for Image Recognition at Scale. arXiv 2021, arXiv:2010.11929. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin Transformer: Hierarchical Vision Transformer using Shifted Windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, New Orleans, LA, USA, 18–24 June 2022. [Google Scholar]
- Liu, Z.; Hu, H.; Lin, Y.; Yao, Z.; Xie, Z.; Wei, Y.; Ning, J.; Cao, Y.; Zhang, Z.; Dong, L. Swin Transformer V2: Scaling Up Capacity and Resolution. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 11999–12009. [Google Scholar]
- Cai, Z.; Vasconcelos, N. Cascade R-CNN: High quality object detection and instance segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 43, 1483–1498. [Google Scholar] [CrossRef]
- Wang, C.; Xia, Y.; Liu, Y.; Kang, C.; Lu, N.; Tian, D.; Lu, H.; Han, F.; Xu, J.; Yomo, T. CleanSeq: A pipeline for contamination detection, cleanup, and mutation verifications from microbial genome sequencing data. Appl. Sci. 2022, 12, 6209. [Google Scholar] [CrossRef]
- Majchrowska, S.; Pawlowski, J.; Gula, G.; Bonus, T.; Hanas, A.; Loch, A.; Pawlak, A.; Roszkowiak, J.; Golan, T.; Drulis-Kawa, Z. AGAR a Microbial Colony Dataset for Deep Learning Detection. arXiv 2021, arXiv:2108.01234. [Google Scholar]
- Gatys, L.; Ecker, A.; Bethge, M. A Neural Algorithm of Artistic Style. J. Vis. 2016, 16, 326. [Google Scholar] [CrossRef]
- Wang, J.; Sun, K.; Cheng, T.; Jiang, B.; Deng, C.; Zhao, Y.; Liu, D.; Mu, Y.; Tan, M.; Wang, X. Deep high-resolution representation learning for visual recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 43, 3349–3364. [Google Scholar] [CrossRef]
- Murthy, C.B.; Hashmi, M.F.; Bokde, N.D.; Geem, Z.W. Investigations of object detection in images/videos using various deep learning techniques and embedded platforms—A comprehensive review. Appl. Sci. 2020, 10, 3280. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.-Y.; Berg, A.C. SSD: Single Shot MultiBox Detector. In Proceedings of the Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Springer International Publishing: Cham, Switzerland, 2016. [Google Scholar]
- Ibrokhimov, B.; Kang, J.-Y. Two-stage deep learning method for breast cancer detection using high-resolution mammogram images. Appl. Sci. 2022, 12, 4616. [Google Scholar] [CrossRef]
- JitendraMalik, R.J.T. Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation; ACM: New York, NY, USA, 2014. [Google Scholar]
- Girshick, R. Fast R-CNN. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; p. 1440. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. Adv. Neural Inf. Process. Syst. 2015, 28, 1137–1149. [Google Scholar] [CrossRef]
- He, K.; Gkioxari, G.; Dollar, P.; Girshick, R. Mask R-CNN. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 386–397. [Google Scholar] [CrossRef]
- Mabrouk, A.; Díaz Redondo, R.P.; Dahou, A.; Abd Elaziz, M.; Kayed, M. Pneumonia detection on chest X-ray images using ensemble of deep convolutional neural networks. Appl. Sci. 2022, 12, 6448. [Google Scholar] [CrossRef]
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End-to-End Object Detection with Transformers. In European Conference on Computer Vision; Springer International Publishing: Cham, Switzerland, 2020. [Google Scholar]
- Bodla, N.; Singh, B.; Chellappa, R.; Davis, L.S. Soft-NMS–Improving Object Detection with One Line of Code. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017. [Google Scholar]
- Han, K.; Xiao, A.; Wu, E.; Guo, J.; Xu, C.; Wang, Y. Transformer in transformer. Adv. Neural Inf. Process. Syst. 2021, 34, 15908–15919. [Google Scholar]
- Hussain, M. YOLO-v1 to YOLO-v8, the Rise of YOLO and Its Complementary Nature toward Digital Manufacturing and Industrial Defect Detection. Machines 2023, 11, 677. [Google Scholar] [CrossRef]
- Patel, S. Bacterial colony classification using atrous convolution with transfer learning. Ann. Rom. Soc. Cell Biol. 2021, 25, 1428–1441. [Google Scholar]
- Wang, H.; Niu, B.; Tan, L. Bacterial colony algorithm with adaptive attribute learning strategy for feature selection in classification of customers for personalized recommendation. Neurocomputing 2021, 452, 747–755. [Google Scholar] [CrossRef]
- Huang, L.; Wu, T. Novel neural network application for bacterial colony classification. Theor. Biol. Med. Model. 2018, 15, 22. [Google Scholar] [CrossRef]
- Zhao, P.; Li, C.; Rahaman, M.M.; Xu, H.; Yang, H.; Sun, H.; Jiang, T.; Grzegorzek, M. A comparative study of deep learning classification methods on a small environmental microorganism image dataset (EMDS-6): From convolutional neural networks to visual transformers. Front. Microbiol. 2022, 13, 792166. [Google Scholar] [CrossRef]
- Chen, K.; Wang, J.; Pang, J.; Cao, Y.; Xiong, Y.; Li, X.; Sun, S.; Feng, W.; Liu, Z.; Xu, J. MMDetection: Open mmlab detection toolbox and benchmark. arXiv 2019, arXiv:1906.07155. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.-J.; Li, K.; Fei-Fei, L. ImageNet: A Large-Scale Hierarchical Image Database. In Proceedings of the 2009 IEEE Conference on Computer Vision And Pattern Recognition, Miami, FL, USA, 20–25 June 2009. [Google Scholar]
- Lin, T.-Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft coco: Common objects in context. In Proceedings of the Computer Vision–ECCV 2014: 13th European Conference, Zurich, Switzerland, 6–12 September 2014; pp. 740–755. [Google Scholar]
- Loshchilov, I.; Hutter, F. Decoupled Weight Decay Regularization. In Proceedings of the International Conference on Learning Representations, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Backbone | Flops (G) | Params (M) | mAP | AP50 | AP75 | mAPs | mAPm | mAPl | AR |
|---|---|---|---|---|---|---|---|---|---|---|
| Faster R-CNN | ResNet50 | 50.38 | 41.14 | 0.511 | 0.760 | 0.542 | 0.008 | 0.354 | 0.484 | 0.581 |
| HRNet | 70.44 | 46.90 | 0.564 | 0.791 | 0.605 | 0.012 | 0.421 | 0.545 | 0.626 | |
| Cascade R-CNN | ResNet50 | 52.41 | 68.94 | 0.563 | 0.783 | 0.615 | 0.016 | 0.397 | 0.560 | 0.613 |
| HRNet | 72.47 | 74.69 | 0.592 | 0.789 | 0.646 | 0.017 | 0.409 | 0.601 | 0.645 | |
| Mask R-CNN | HRNet | 122.00 | 49.52 | 0.567 | 0.782 | 0.611 | 0.013 | 0.386 | 0.572 | 0.628 |
| Swin-T | 103.85 | 47.39 | 0.593 | 0.801 | 0.648 | 0.017 | 0.414 | 0.606 | 0.642 | |
| Cascade Mask R-CNN | HRNet | 227.15 | 82.56 | 0.592 | 0.782 | 0.651 | 0.013 | 0.406 | 0.612 | 0.644 |
| Swin-S | 576.35 | 105.74 | 0.609 | 0.796 | 0.656 | 0.018 | 0.434 | 0.626 | 0.659 | |
| Swin-B | 613.78 | 143.77 | 0.614 | 0.798 | 0.655 | 0.019 | 0.443 | 0.628 | 0.660 |
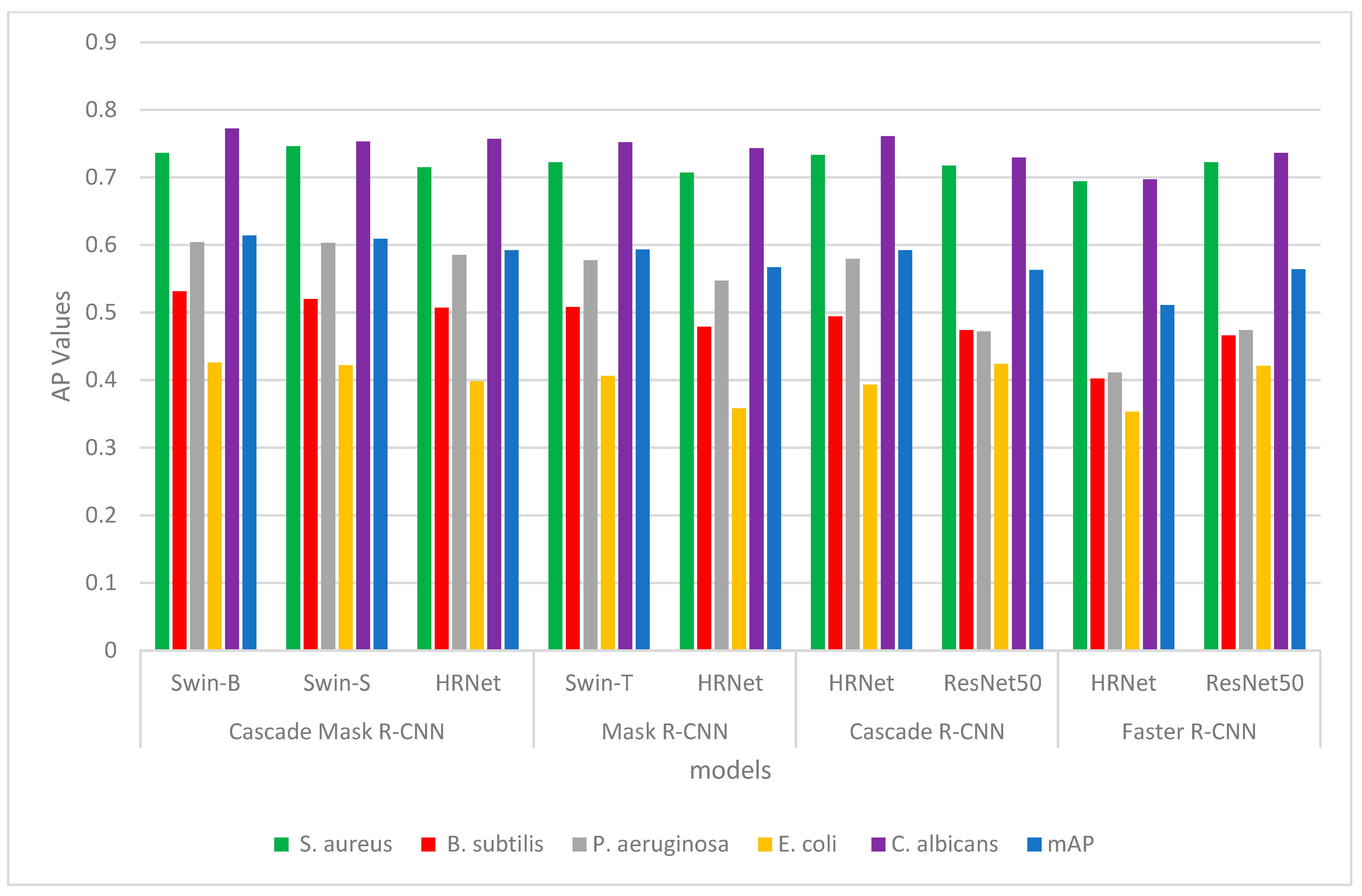
| Model | Cascade Mask R-CNN | Mask R-CNN | Cascade R-CNN | Faster R-CNN | |||||
|---|---|---|---|---|---|---|---|---|---|
| Backbone | Swin-B | Swin-S | HRNet | Swin-T | HRNet | HRNet | ResNet50 | HRNet | ResNet50 |
| S. aureus | 0.736 | 0.746 | 0.715 | 0.722 | 0.707 | 0.733 | 0.717 | 0.694 | 0.722 |
| B. subtilis | 0.531 | 0.520 | 0.507 | 0.508 | 0.479 | 0.494 | 0.474 | 0.402 | 0.466 |
| P. aeruginosa | 0.604 | 0.603 | 0.585 | 0.577 | 0.547 | 0.579 | 0.472 | 0.411 | 0.474 |
| E. coli | 0.426 | 0.422 | 0.398 | 0.406 | 0.358 | 0.393 | 0.424 | 0.353 | 0.421 |
| C. albicans | 0.772 | 0.753 | 0.757 | 0.752 | 0.743 | 0.761 | 0.729 | 0.697 | 0.736 |
| mAP | 0.614 | 0.609 | 0.592 | 0.593 | 0.567 | 0.592 | 0.563 | 0.511 | 0.564 |
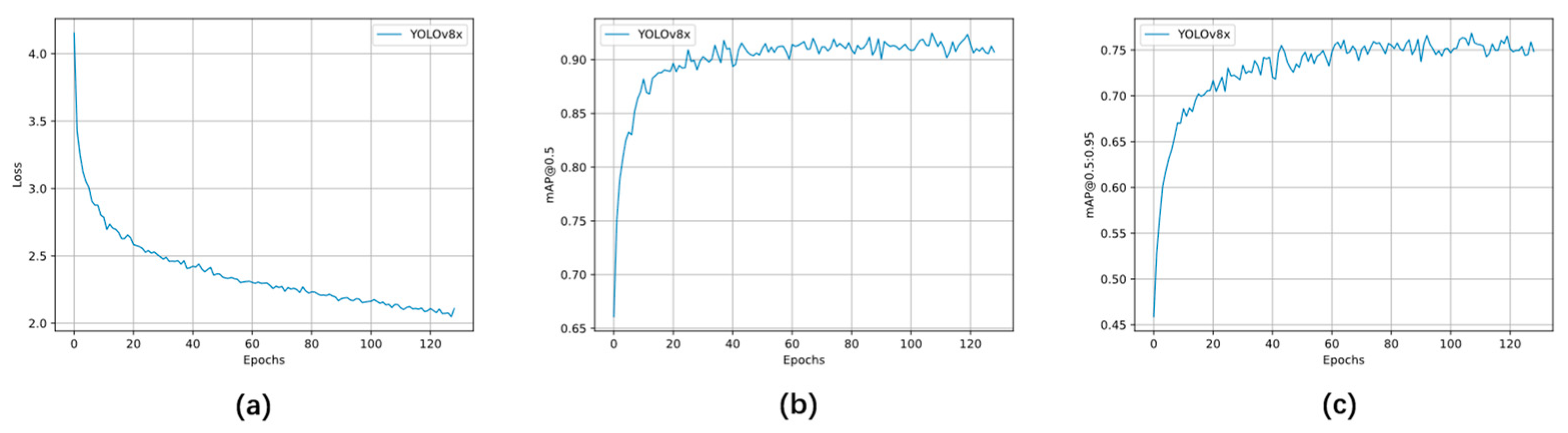
| Training Settings | Results | ||
|---|---|---|---|
| epochs | 300 | S. aureus | 0.849 |
| batch | 4 | B. subtilis | 0.727 |
| iou | 0.7 | P. aeruginosa | 0.696 |
| lr0 | 0.00001 | E. coli | 0.698 |
| lrf | 0.0001 | C. albicans | 0.866 |
| momentum | 0.9 | AP50 | 0.925 |
| weight decay | 0.05 | mAP | 0.767 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yang, F.; Zhong, Y.; Yang, H.; Wan, Y.; Hu, Z.; Peng, S. Microbial Colony Detection Based on Deep Learning. Appl. Sci. 2023, 13, 10568. https://doi.org/10.3390/app131910568
Yang F, Zhong Y, Yang H, Wan Y, Hu Z, Peng S. Microbial Colony Detection Based on Deep Learning. Applied Sciences. 2023; 13(19):10568. https://doi.org/10.3390/app131910568
Chicago/Turabian StyleYang, Fan, Yongjie Zhong, Hui Yang, Yi Wan, Zhuhua Hu, and Shengsen Peng. 2023. "Microbial Colony Detection Based on Deep Learning" Applied Sciences 13, no. 19: 10568. https://doi.org/10.3390/app131910568