

A Hybrid Human Activity Recognition Method Using an MLP Neural Network and Euler Angle Extraction Based on IMU Sensors

Abstract
:1. Introduction
- A human feature extraction model is introduced to convert multi-dimensional sensor data into one-dimensional features;
- An approach for feature group division and classifier network construction is proposed to improve group correlation analysis and human action recognition accuracy;
- The impact of the K-nearest neighbors algorithm (KNN) and sliding window size on evaluation results is examined;
- The study investigates the influence of GAM, transformer block, and classifier block on the experimental accuracy.
2. Related Work
3. Methods
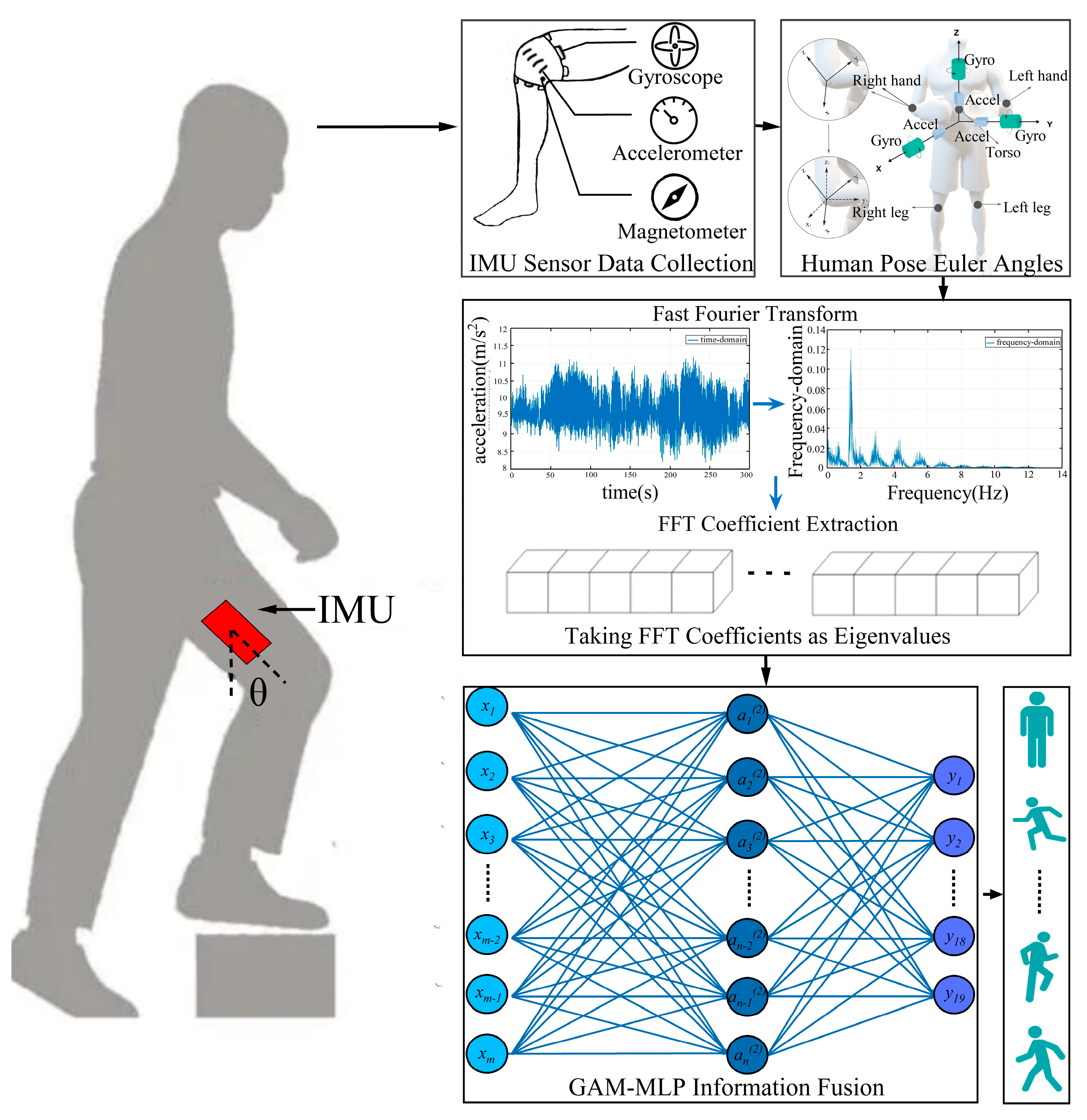
3.1. Enhancing the Human Pose Recognition Model Structure
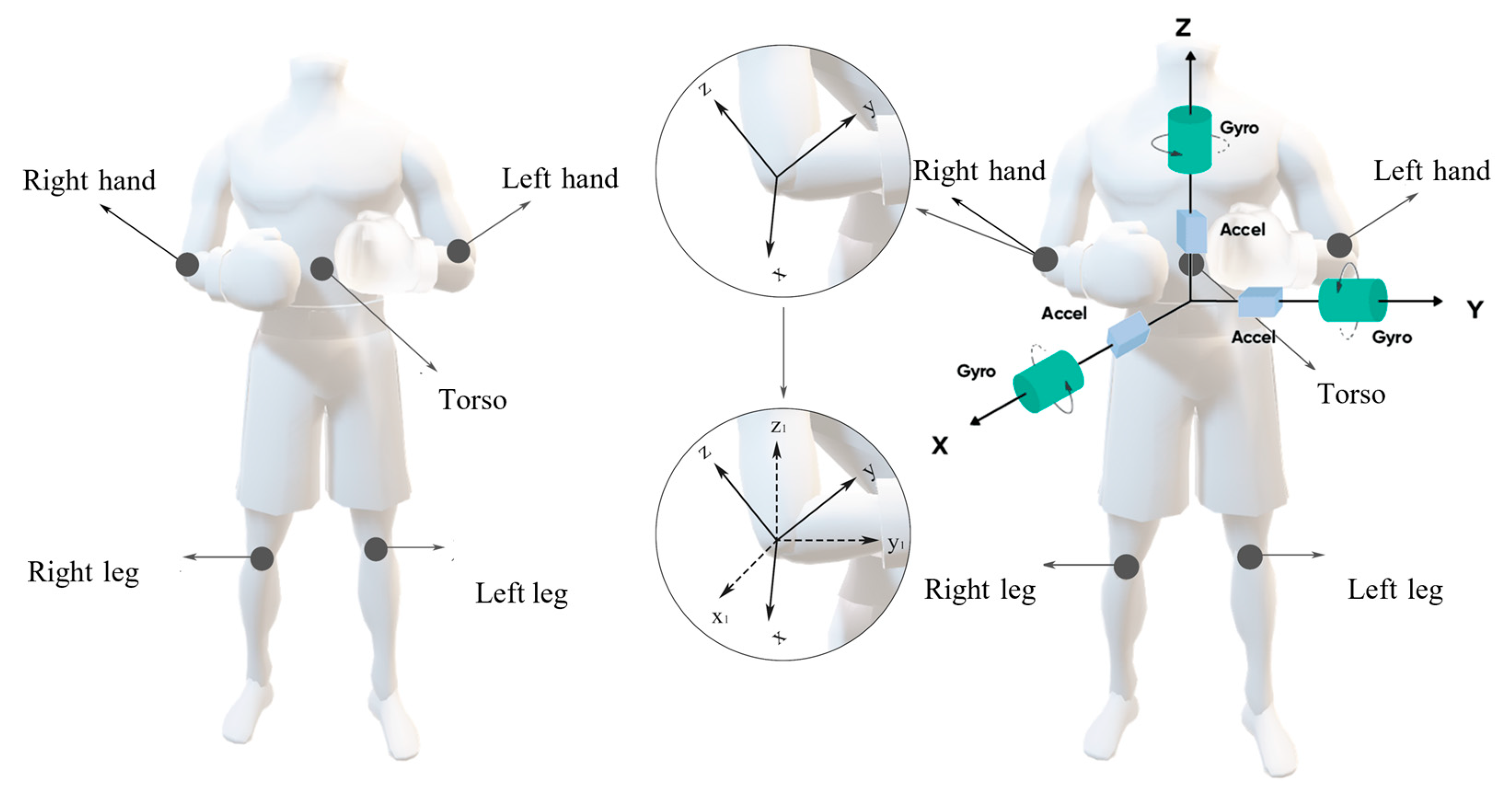
3.2. Extraction of Human Pose Euler Angles
3.2.1. Initial Attitude Angle Calculation
3.2.2. Euler Angle Correction for Quaternion and Rodriguez Parameters
3.2.3. Attitude Angle Calculation Algorithm Design
| Algorithm 1: The human attitude angle calculation method based on multiple attitude parameters | |
| Input: Sample time series T, Acceleration data Adata (ax, ay, az), Gyroscope data Gdata, | |
| Magnetometer data Mdata; | |
| Output: Attitude Angle attitude; | |
| (1) | Initialization Adata, Mdata, Quaternion Q and Rodrigues Parameters r; |
| (2) | Conversion unit of accelerometer data to the acceleration of gravity |
| (3) | for i = 0,0.04,0.08…T do: |
| (4) | Calculate roll angle t and pitch angle t |
| (5) | Compensate for Mdata to correct Attitude Angle with magnetometer |
| (6) | Calculate yaw angle t |
| (7) | Convert angles to radians |
| (8) | Update Euler Angle vector Eangle |
| (9) | Calculate the Gyroscope Euler Angle variation: |
| (10) | Gchange = Gdata * dt |
| (11) | Compensate the Euler Angle Ccomp: |
| (12) | Ccomp = Eangle + Gdata; |
| (13) | Transform Euler Angle vector to rotation matrix |
| (14) | Convert Euler Angle vector to quaternion |
| (15) | Convert quaternion to Rodrigues Parameters |
| (16) | Calculate Attitude Angle attitude |
| (17) | Convert radians to angles |
| (18) | end for |
| (19) | Output the final Attitude Angle attitude |
3.3. Human Pose Feature Extraction
3.4. GAM-MLP Information Fusion
3.4.1. Human Pose Feature Information Fusion
3.4.2. Activity Classification and Recognition
4. HAR Datasets and Experiment Settings
4.1. Experimental Environment and Data Acquisition
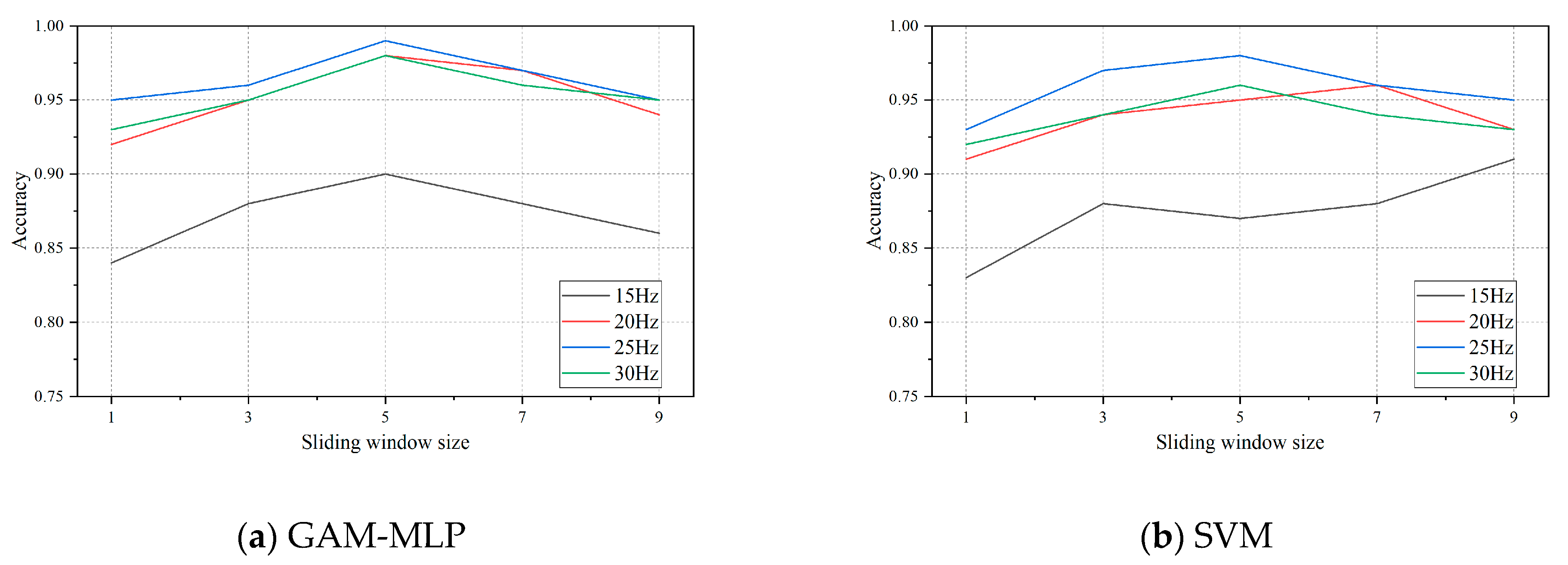
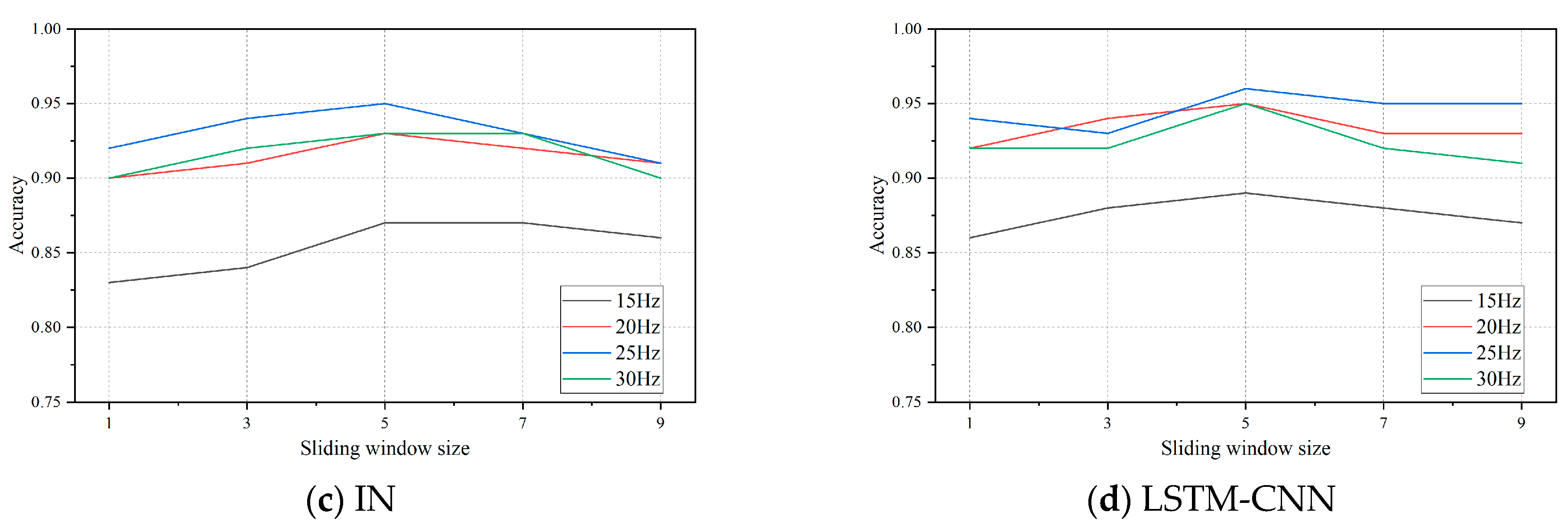
4.2. Sliding Window Segmentation Signal Processing
5. Result and Analysis
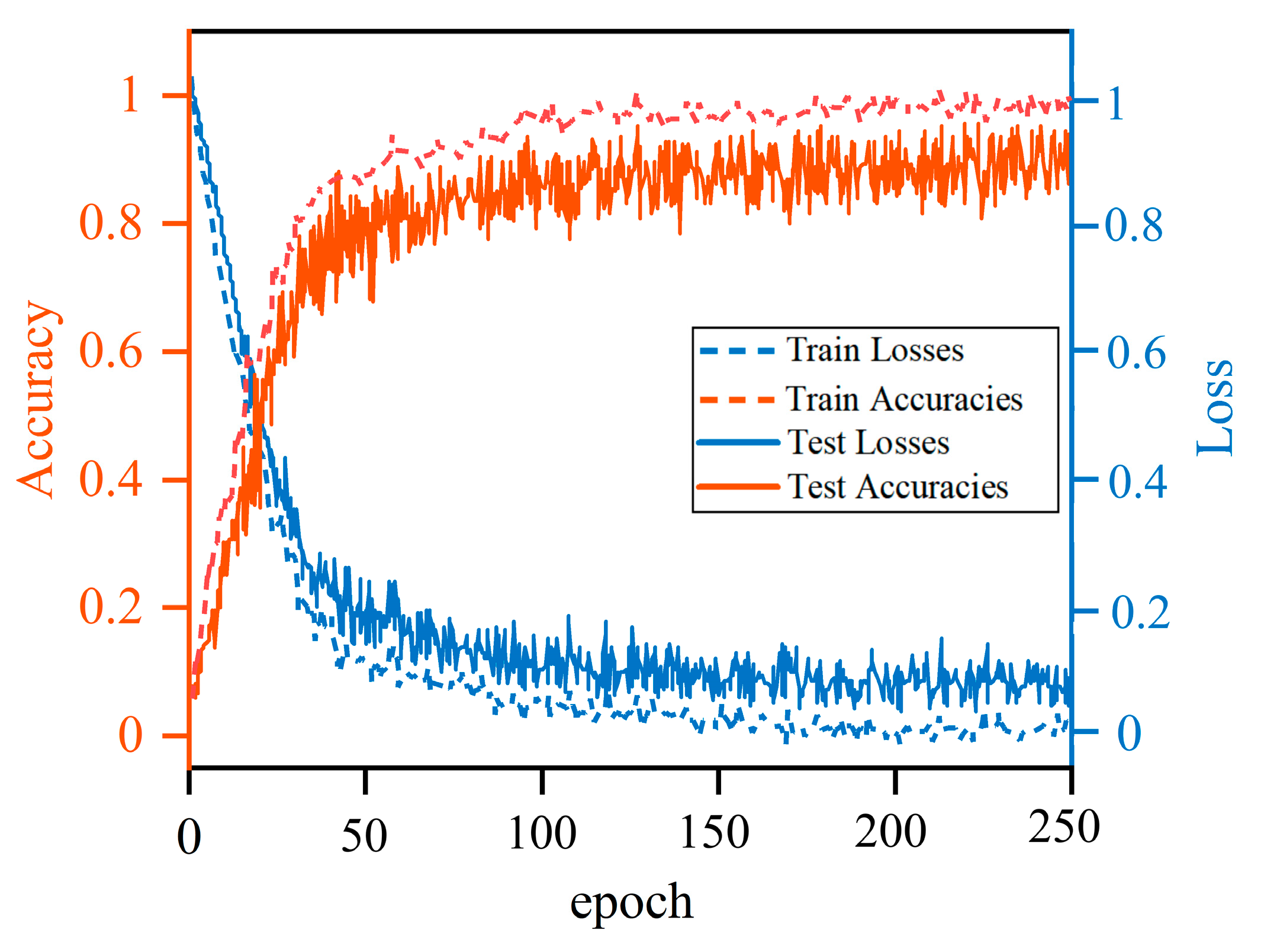
5.1. Accuracy and Loss of the 10-Fold Cross Validation on Both Training and Test Sets
5.2. Performance on Different Datasets
5.3. Recognition of Common Human Movements
5.4. GAM Ablation Comparison
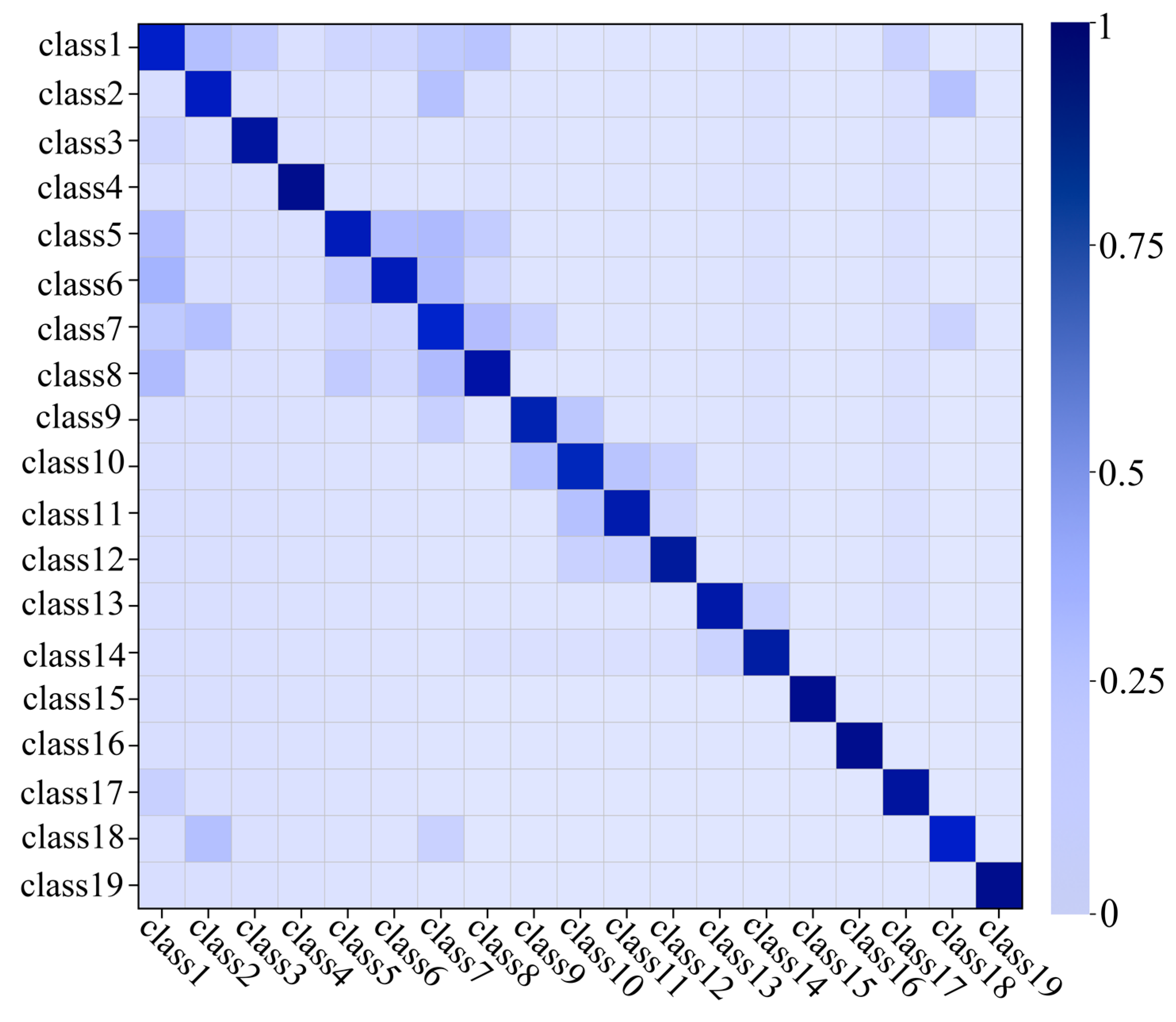
5.5. Identification of 19 Types of Diverse Actions
6. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Xiao, Z.; Fu, M.; Yi, Y.; Lv, N. 3D Human Postures Recognition Using Kinect. In Proceedings of the 2012 4th International Conference on Intelligent Human-Machine Systems and Cybernetics, Nanchang, China, 26–27 August 2012; pp. 344–347. [Google Scholar]
- Jaén-Vargas, M.; Reyes Leiva, K.; Fernandes, F.; Gonçalves, S.B.; Tavares Silva, M.; Lopes, D.S.; Serrano Olmedo, J. A Deep Learning Approach to Recognize Human Activity Using Inertial Sensors and Motion Capture Systems. In Fuzzy Systems and Data Mining VII; IOS Press: Amsterdam, The Netherlands, 2021. [Google Scholar]
- Forsman, M.; Fan, X.; Rhen, I.M.; Lind, C.M. Mind the gap—Development of conversion models between accelerometer- and IMU-based measurements of arm and trunk postures and movements in warehouse work. Appl. Ergon. 2022, 105, 103841. [Google Scholar] [CrossRef] [PubMed]
- Withanage, K.I.; Lee, I.; Brinkworth, R.; Mackintosh, S.; Thewlis, D. Fall Recovery Subactivity Recognition With RGB-D Cameras. IEEE Trans. Ind. Inform. 2016, 12, 2312–2320. [Google Scholar] [CrossRef]
- Hoang, M.L.; Pietrosanto, A. Yaw/Heading optimization by drift elimination on MEMS gyroscope. Sens. Actuators A Phys. 2021, 325, 112691. [Google Scholar] [CrossRef]
- Ito, C.; Cao, X.; Shuzo, M.; Maeda, E. Application of CNN for Human Activity Recognition with FFT Spectrogram of Acceleration and Gyro Sensors. In Proceedings of the 2018 ACM International Joint Conference and 2018 International Symposium on Pervasive and Ubiquitous Computing and Wearable Computers, Singapore, 8–12 October 2018; pp. 1503–1510. [Google Scholar]
- Bayraktar, E.; Yigit, C.B.; Boyraz, P. Object manipulation with a variable-stiffness robotic mechanism using deep neural networks for visual semantics and load estimation. Neural Comput. Appl. 2020, 32, 9029–9045. [Google Scholar] [CrossRef]
- Yigit, C.B.; Bayraktar, E.; Boyraz, P. Low-cost variable stiffness joint design using translational variable radius pulleys. Mech. Mach. Theory 2018, 130, 203–219. [Google Scholar] [CrossRef]
- Yigit, C.B.; Bayraktar, E.; Kaya, O.; Boyraz, P. External Force/Torque Estimation With Only Position Sensors for Antagonistic VSAs. IEEE Trans. Robot. 2021, 37, 675–682. [Google Scholar] [CrossRef]
- Meng, Z.Z.; Zhang, M.X.; Guo, C.X.; Fan, Q.R.; Zhang, H.; Gao, N.; Zhang, Z.H. Recent Progress in Sensing and Computing Techniques for Human Activity Recognition and Motion Analysis. Electronics 2020, 9, 19. [Google Scholar] [CrossRef]
- Anazco, E.V.; Lopez, P.R.; Park, H.; Park, N.; Kim, T.S. Human Activities Recognition with a Single Writs IMU via a Variational Autoencoder and Android Deep Recurrent Neural Nets. Comput. Sci. Inf. Syst. 2020, 17, 581–597. [Google Scholar]
- Abdelhafiz, M.H.; Awad, M.I.; Sadek, A.; Tolbah, F. Sensor positioning for a human activity recognition system using a double layer classifier. Proc. Inst. Mech. Eng. Part H J. Eng. Med. 2021, 236, 248–258. [Google Scholar] [CrossRef]
- Rivera, P.; Valarezo, E.; Kim, T.S. An Integrated ARMA-Based Deep Autoencoder and GRU Classifier System for Enhanced Recognition of Daily Hand Activities. Int. J. Pattern Recognit. Artif. Intell. 2021, 35, 19. [Google Scholar] [CrossRef]
- Hashim, B.A.M.; Amutha, R. Deep transfer learning based human activity recognition by transforming IMU data to image domain using novel activity image creation method. J. Intell. Fuzzy Syst. 2022, 43, 2883–2890. [Google Scholar] [CrossRef]
- Tahir, S.; Dogar, A.B.; Fatima, R.; Yasin, A.; Shafiq, M.; Khan, J.A.; Assam, M.; Mohamed, A.; Attia, E.A. Stochastic Recognition of Human Physical Activities via Augmented Feature Descriptors and Random Forest Model. Sensors 2022, 22, 20. [Google Scholar] [CrossRef] [PubMed]
- Chakraborty, A.; Mukherjee, N. A deep-CNN based low-cost, multi-modal sensing system for efficient walking activity identification. Multimed. Tools Appl. 2023, 82, 16741–16766. [Google Scholar] [CrossRef]
- Salem, Z.; Weiss, A.P. Improved Spatiotemporal Framework for Human Activity Recognition in Smart Environment. Sensors 2023, 23, 24. [Google Scholar] [CrossRef] [PubMed]
- Fan, Y.; Jin, H.; Ge, Y.; Wang, N. Wearable Motion Attitude Detection and Data Analysis Based on Internet of Things. IEEE Access 2020, 8, 1327–1338. [Google Scholar] [CrossRef]
- Wang, N.; Huang, J.; Yue, F.; Zhang, X. Attitude Algorithm and Calculation of Limb Length Based on Motion Capture Data. In Proceedings of the 2021 IEEE International Conference on Robotics and Biomimetics (ROBIO), Sanya, China, 27–31 December 2021; pp. 1004–1009. [Google Scholar]
- Heng, X.; Wang, Z.; Wang, J. Human activity recognition based on transformed accelerometer data from a mobile phone. Int. J. Commun. Syst. 2016, 29, 1981–1991. [Google Scholar] [CrossRef]
- Xiao, X.; Zarar, S. In A Wearable System for Articulated Human Pose Tracking under Uncertainty of Sensor Placement. In Proceedings of the 7th IEEE RAS/EMBS International Conference on Biomedical Robotics and Biomechatronics, BIOROB, Enschede, The Netherlands, 26–29 August 2018; IEEE Computer Society: Enschede, The Netherlands, 2018; pp. 1144–1150. [Google Scholar]
- Cui, C.; Li, J.; Du, D.; Wang, H.; Tu, P.; Cao, T. The Method of Dance Movement Segmentation and Labanotation Generation Based on Rhythm. IEEE Access 2021, 9, 31213–31224. [Google Scholar] [CrossRef]
- Shenoy, P.; Sompur, V.; Skm, V. Methods for Measurement and Analysis of Full Hand Angular Kinematics Using Electromagnetic Tracking Sensors. IEEE Access 2022, 10, 42673–42689. [Google Scholar] [CrossRef]
- Aasha, M.; Sivaranjani, S.; Sivakumari, S. An Effective reduction of Gait Recognition Time by using Gender Classification. In Proceedings of the International Conference on Advances in Information Communication Technology & Computing—AICTC ‘16, Bikaner, India, 12–13 August 2016; pp. 1–6. [Google Scholar]
- Chen, Y.; Tu, Z.; Kang, D.; Chen, R.; Bao, L.; Zhang, Z.; Yuan, J. Joint Hand-Object 3D Reconstruction From a Single Image With Cross-Branch Feature Fusion. IEEE Trans. Image Process. 2021, 30, 4008–4021. [Google Scholar] [CrossRef]
- Cui, Y.; Li, X.; Wang, Y.; Yuan, W.; Cheng, X.; Samiei, M. MLP-TLBO: Combining Multi-Layer Perceptron Neural Network and Teaching-Learning-Based Optimization for Breast Cancer Detection. Cybern. Syst. 2022, 53, 1–28. [Google Scholar] [CrossRef]
- Faundez-Zanuy, M.; Ferrer-Ballester, M.A.; Travieso-González, C.M.; Espinosa-Duro, V. Hand Geometry Based Recognition with a MLP Classifier. In Advances in Biometrics; Springer: Berlin/Heidelberg, Germany, 2005; pp. 721–727. [Google Scholar]
- Yuan, X.; Liang, N.; Fu, W.; Wang, Q.; Zhang, Y.; Cao, J.; Liu, H.; Liu, K.; Huang, Y.; Ren, X. A Wearable Gesture Recognition System With Ultrahigh Accuracy and Robustness Enabled by the Synergy of Multiple Fabric Sensing Devices. IEEE Sens. J. 2023, 23, 10950–10958. [Google Scholar] [CrossRef]
- Anwar, I.N.; Daud, K.; Samat, A.A.A.; Soh, Z.H.C.; Omar, A.M.S.; Ahmad, F. Implementation of Levenberg-Marquardt Based Multilayer Perceptron (MLP) for Detection and Classification of Power Quality Disturbances. In Proceedings of the 022 IEEE 12th International Conference on Control System, Computing and Engineering (ICCSCE), Penang, Malaysia, 21–22 October 2022; pp. 63–68. [Google Scholar]
- Guo, W.; Du, Y.; Shen, X.; Lepetit, V.; Alameda-Pineda, X.; Moreno-Noguer, F. Back to MLP: A Simple Baseline for Human Motion Prediction. In Proceedings of the 2023 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), Waikoloa, HI, USA, 3–7 January 2023; pp. 4798–4808. [Google Scholar]
- Mustaqeem; Kwon, S. Att-Net: Enhanced emotion recognition system using lightweight self-attention module. Appl. Soft Comput. 2021, 102, 107101. [Google Scholar] [CrossRef]
- Vasyltsov, I.; Chang, W. Efficient softmax approximation for deep neural networks with attention mechanism. arXiv 2021, arXiv:2111.10770. [Google Scholar]
- Ordonez, F.J.; Roggen, D. Deep Convolutional and LSTM Recurrent Neural Networks for Multimodal Wearable Activity Recognition. Sensors 2016, 16, 115. [Google Scholar] [CrossRef] [PubMed]
- Xu, C.; Chai, D.; He, J.; Zhang, X.T.; Duan, S.H. InnoHAR: A Deep Neural Network for Complex Human Activity Recognition. IEEE Access 2019, 7, 9893–9902. [Google Scholar] [CrossRef]
- Xia, K.; Huang, J.; Wang, H. LSTM-CNN Architecture for Human Activity Recognition. IEEE Access 2020, 8, 56855–56866. [Google Scholar] [CrossRef]
- Lv, T.; Wang, X.; Jin, L.; Xiao, Y.; Song, M. Margin-Based Deep Learning Networks for Human Activity Recognition. Sensors 2020, 20, 1871. [Google Scholar] [CrossRef]
- Wan, S.; Qi, L.; Xu, X.; Tong, C.; Gu, Z. Deep Learning Models for Real-time Human Activity Recognition with Smartphones. Mob. Netw. Appl. 2020, 25, 743–755. [Google Scholar] [CrossRef]
- Huang, W.; Zhang, L.; Wu, H.; Min, F.; Song, A. Channel-Equalization-HAR: A Light-weight Convolutional Neural Network for Wearable Sensor Based Human Activity Recognition. IEEE Trans. Mob. Comput. 2023, 22, 5064–5077. [Google Scholar] [CrossRef]
- Tang, Y.; Zhang, L.; Min, F.; He, J. Multiscale Deep Feature Learning for Human Activity Recognition Using Wearable Sensors. IEEE Trans. Ind. Electron. 2023, 70, 2106–2116. [Google Scholar] [CrossRef]
- Thakur, D.; Biswas, S.; Ho, E.S.L.; Chattopadhyay, S. ConvAE-LSTM: Convolutional Autoencoder Long Short-Term Memory Network for Smartphone-Based Human Activity Recognition. IEEE Access 2022, 10, 4137–4156. [Google Scholar] [CrossRef]


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Name | Specific Configuration |
|---|---|
| CPU | Intel Core i9-12900K@3.50 GHZ |
| Graphics card | Nvidia Geforce RTX 3080Ti (12 GB) GPU |
| Memory | 64 GB DDR4 3000 |
| Deep learning framework | TensorFlow 2.5 |
| Development language | Python 3.9 |
| Developing an IDE | Pycharm 2020.1 |
| Operating system | Window10 Professional |
| Dataset | Action Categories | Sample Size | Sensor Type | Acquisition Location |
|---|---|---|---|---|
| PAMAP2 Dataset | 18 | 65,052 | inertial measurement units, acceleration sensors, magnetometer, gyroscope | Ankle Chest Wrist |
| MultiportGAM Dataset | 19 | 11,034 | accelerometer, magnetometer, spirometer | Torso Left Arm Right Arm Left Leg Right Leg |
| Method | Accuracy (%) | Recall (%) | F1-Score (%) |
|---|---|---|---|
| GAM-MLP | 96.13 | 96.12 | 96.13 |
| SVM | 82.70 | 82.70 | 82.69 |
| DCL [33] | 92.11 | 92.10 | 92.11 |
| IN [34] | 92.72 | 92.72 | 92.71 |
| LSTM-CNN [35] | 94.23 | 94.10 | 94.17 |
| Method | Accuracy (%) | Recall (%) | F1-Score (%) |
|---|---|---|---|
| GAM-MLP | 93.96 | 93.89 | 93.91 |
| SVM | 82.84 | 82.43 | 82.58 |
| CNN-M [36] | 93.74 | 93.28 | 93.85 |
| LSTM-CNN | 92.63 | 92.61 | 92.89 |
| FE-CNN [37] | 91.66 | 91.43 | 91.40 |
| DCL | 92.49 | 92.42 | 92.30 |
| CE-HAR [38] | 92.14 | 92.43 | 92.18 |
| IN | 91.77 | 91.76 | 91.47 |
| TL-HAR [39] | 92.33 | 91.83 | 92.08 |
| ConvAE-LSTM [40] | 94.33 | - | 94.46 |
| Attention Module | Accuracy (%) | Recall (%) | F1-Score (%) |
|---|---|---|---|
| GAM-MLP | 96.13 | 96.12 | 96.13 |
| SE-MLP | 92.74 | 92.13 | 92.48 |
| CBAM-MLP | 91.11 | 92.02 | 92.08 |
| Attention Module | Accuracy (%) | Recall (%) | F1-Score (%) |
|---|---|---|---|
| GAM-MLP | 93.96 | 93.89 | 93.91 |
| SE-MLP | 89.34 | 88.75 | 89.16 |
| CBAM-MLP | 88.75 | 89.13 | 88.96 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mao, Y.; Yan, L.; Guo, H.; Hong, Y.; Huang, X.; Yuan, Y. A Hybrid Human Activity Recognition Method Using an MLP Neural Network and Euler Angle Extraction Based on IMU Sensors. Appl. Sci. 2023, 13, 10529. https://doi.org/10.3390/app131810529
Mao Y, Yan L, Guo H, Hong Y, Huang X, Yuan Y. A Hybrid Human Activity Recognition Method Using an MLP Neural Network and Euler Angle Extraction Based on IMU Sensors. Applied Sciences. 2023; 13(18):10529. https://doi.org/10.3390/app131810529
Chicago/Turabian StyleMao, Yaxin, Lamei Yan, Hongyu Guo, Yujie Hong, Xiaocheng Huang, and Youwei Yuan. 2023. "A Hybrid Human Activity Recognition Method Using an MLP Neural Network and Euler Angle Extraction Based on IMU Sensors" Applied Sciences 13, no. 18: 10529. https://doi.org/10.3390/app131810529