
Improving Collaborative Filtering Recommendations with Tag and Time Integration in Virtual Online Communities †

Abstract
:1. Introduction
2. Literature Review
2.1. CTS
2.2. CF
3. Computational Approach
3.1. Weight Calculation
3.1.1. Tag-Based Weight
3.1.2. Time-Based Weight
3.1.3. Hybrid Weight
3.1.4. Specific Example
- Tag-Based Weight
- 2.
- Time-Based Weight
- 3.
- Hybrid Weight
3.2. User Similarity Calculation
3.3. Resource Preference Generation
3.4. Algorithm Code
| Algorithm 1. Algorithm code. |
| rawlog = load(‘MarTraLog.txt’); rawtag = load(‘MarTraTag.txt’); rawtime = load(‘MarTraTime.txt’); Test01 = load(‘MarTraTest.txt’); % Iteration Experiment Start for hi = 1:11 rawmix = rawtag*(1–0.1*(hi-1)) + rawtime*0.1*(hi-1); for i = 1:id for j = 1:id simmix(i,j)=rawmix(i,:)*rawmix(j,:)’/(norm(rawmix(i,:))*norm(rawmix(j,:))); end end % Neighbor scale parameter = [3 6 9 12 15 18 21 24 27 30]; for j = 1:length(parameter) k = parameter(j); for i = 1:id [m n] = sort(simmix(i,:), ‘descend’); index = n(2:k + 1); Preefer_mat(i,:) = simmix(i,index)*rawmix(index,:)/k; Result{j} = prefer_mat; end end % Evaluation Part for j = 1:length(parameter) prefer01 = Result{j}; for i = 1:size(prefer01,1) [pm pn] = sort(prefer01(i,:),’descend’); index = pn(1:10); Recall01(i,1) = length(find(Test01(i,index) = =1))/length(find(Test01(i,:)~ = 0)); Precision01(i,1) = length(find(Test01(i,index) = =1))/10; end Recall_001(:,j + 10*(hi-1)) = Recall01; Precision_001(:,j + 10*(hi-1)) = Precision01; end end |
4. Experiment
4.1. Dataset and Experimental Procedure
4.2. Evaluation Metrics
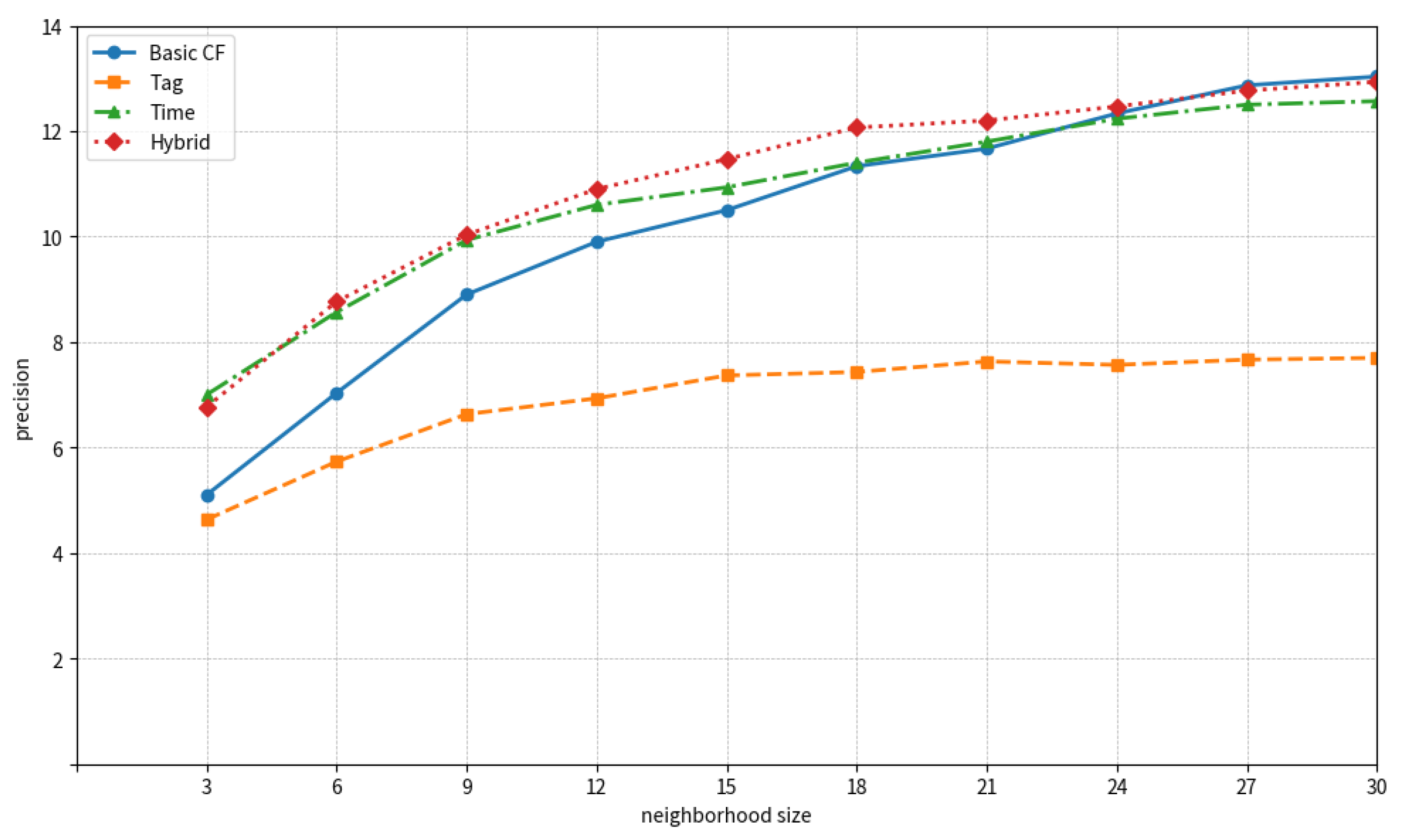
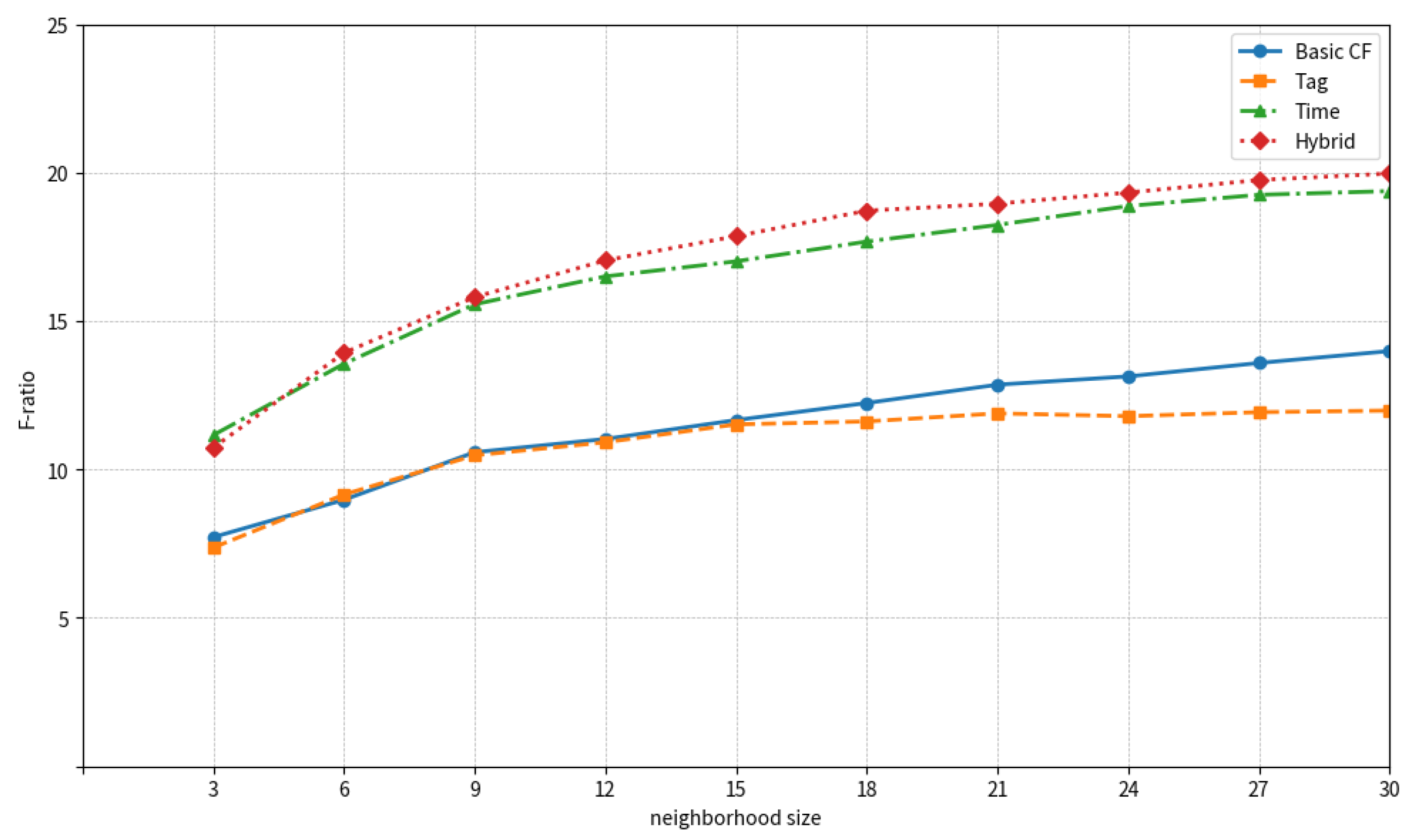
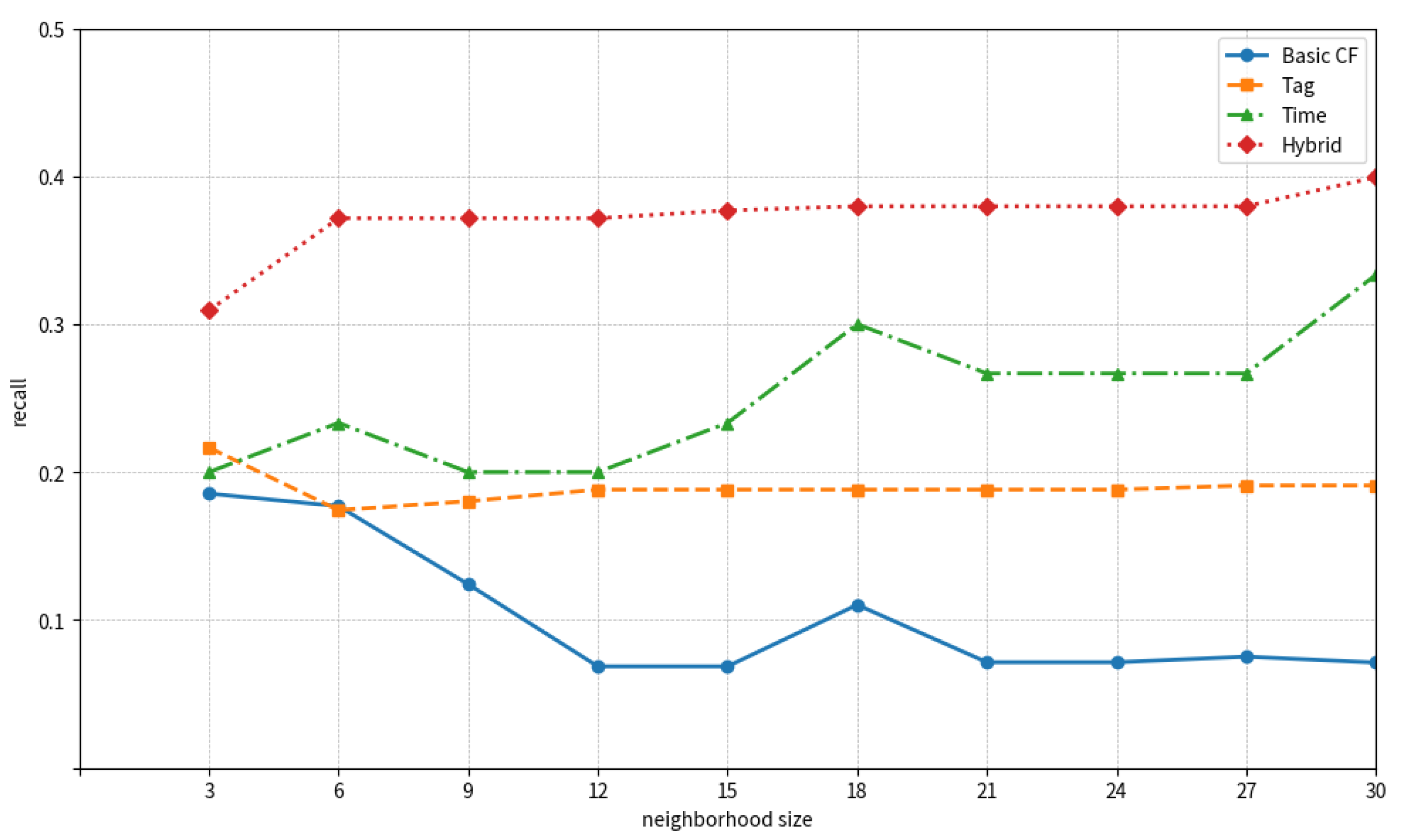
4.3. Results
4.3.1. Results of Margarin
4.3.2. Results of Delicious
5. Conclusions and Further Research
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Brown, A.; Reade, J.J. The wisdom of amateur crowds: Evidence from an online community of sports tipsters. Eur. J. Oper. Res. 2019, 272, 1073–1081. [Google Scholar] [CrossRef]
- Choi, J.Y.; Rosen, J.; Maini, S.; Pierce, M.E.; Fox, G.C. Collective collaborative tagging system. In Proceedings of the Grid Computing Environment Workshop, Austin, TX, USA, 16 November 2008; pp. 1–7. [Google Scholar]
- Golder, S.A.; Huberman, B.A. Usage patterns of collaborative tagging system. J. Inf. Sci. 2006, 32, 198–208. [Google Scholar] [CrossRef]
- Xu, Y.; Yin, D.; Zhou, D. Investigating users’ tagging behavior in online academic community based on growth model: Difference between active and inactive users. Inf. Syst. Front. 2019, 21, 761–772. [Google Scholar] [CrossRef]
- Wang, Y.; Deng, J.; Gao, J.; Zhang, P. A hybrid user similarity model for collaborative filtering. Inf. Sci. 2017, 418–419, 102–118. [Google Scholar] [CrossRef]
- Herlocker, J.L.; Konstan, J.A.; Terveen, L.G.; Riedl, J.T. Evaluating collaborative filtering recommender systems. ACM Trans. Inf. Syst. 2004, 22, 5–53. [Google Scholar] [CrossRef]
- Lops, P.; Jannach, D.; Musto, C.; Bogers, T.; Koolen, M. Trends in content-based recommendation. User Model. User-Adapt. Interact. 2019, 29, 239–249. [Google Scholar] [CrossRef]
- Shokeen, J.; Rana, C. A study on features of social recommender systems. Artif. Intell. Rev. 2020, 53, 965–988. [Google Scholar] [CrossRef]
- Cui, Z.; Xu, X.; Xue, F.; Cai, X.; Cao, Y.; Zhang, W.; Chen, J. Personalized Recommendation System Based on Collaborative Filtering for IoT Scenarios. IEEE Trans. Serv. Comput. 2020, 13, 685–695. [Google Scholar] [CrossRef]
- Qassimi, S.; Abdelwahed, E.H. The role of collaborative tagging and ontologies in emerging semantic of web resources. Computing 2019, 101, 1489–1511. [Google Scholar] [CrossRef]
- Mathes, A. Folksonomies: Cooperative Classification and Communication through Shared Metadata; University of Illinois Urbana: Urbana, IL, USA, 2004. [Google Scholar]
- Sen, A. Metadata management: Past, present and future. Decis. Support Syst. 2004, 37, 151–173. [Google Scholar] [CrossRef]
- Halpin, H.; Robu, V.; Shepherd, H. The complex dynamics of collaborative tagging. In Proceedings of the 16th International Conference on World Wide Web, Banff, AB, Canada, 8–12 May 2007; pp. 211–220. [Google Scholar]
- Dichev, C.; Xu, J.; Dicheva, D.; Zhang1, J. A Study on Community Formation in Collaborative Tagging Systems. In Proceedings of the IEEE/WIC/ACM International Conference on Web Intelligence and Intelligent Agent Technology, Washington, DC, USA, 9–12 December 2008. [Google Scholar]
- Li, X.; Guo, L.; Zhao, Y. Tag-based Social Interest discovery. In Proceedings of the Social Networks & Web 2.0 Conference, Geneva, Switzerland; Beijing, China, 21–25 April 2008; pp. 675–684. [Google Scholar]
- Xu, Z.; Fu, Y.; Mao, J.; Su, D. Towards the Semantic Web: Collaborative Tag Suggestions. In Proceedings of the Collaborative Web Tagging Workshop, Austin, TX, USA, 4 November 2006. [Google Scholar]
- Chuang, S.L.; Chein, L.F. Enriching web taxonomies through subject categorization of query terms from search engine logs. Decis. Support Syst. 2003, 35, 113–127. [Google Scholar] [CrossRef]
- Jacob, E. Classification and categorization: A difference that makes a difference. Libr. Trends 2004, 52, 515–540. [Google Scholar]
- Klašnja-Milićević, A.; Ivanović, M.; Vesin, B.; Budimac, Z. Enhancing e-learning systems with personalized recommendation based on collaborative tagging techniques. Appl. Intell. 2018, 48, 1519–1535. [Google Scholar] [CrossRef]
- Klašnja-Milićević, A.; Vesin, B.; Ivanović, M. Social tagging strategy for enhancing e-learning experience. Comput. Educ. 2018, 118, 166–181. [Google Scholar] [CrossRef]
- Balakrishnan, B. Motivating engineering students learning via monitoring in personalized learning environment with tagging system. Comput. Appl. Eng. Educ. 2018, 26, 700–710. [Google Scholar] [CrossRef]
- Beldjoudi, S.; Seridi, H.; Karabadji, N.E.I. Recommendation in collaborative e-learning by using linked open data and ant colony optimization. In Proceedings of the International Conference on Intelligent Tutoring Systems, Montreal, QC, Canada, 11–15 June 2018; pp. 23–32. [Google Scholar]
- Morrison, P.J. Tagging and searching: Search retrieval effectiveness of folksonomies on the World Wide Web. Inf. Process. Manag. 2008, 44, 1562–1579. [Google Scholar] [CrossRef]
- Wu, P.; Zhang, Z.-K. Enhancing personalized recommendations on weighted social tagging networks. Phys. Procedia 2010, 3, 1877–1885. [Google Scholar] [CrossRef]
- Zhang, C.; Yang, M.; Lv, J.; Yang, W. An improved hybrid collaborative filtering algorithm based on tags and time factor. Big Data Min. Anal. 2018, 1, 128–136. [Google Scholar]
- Brooks, C.H.; Montanez, N. Improved annotation of blogosphere via auto-tagging and hierarchical clustering. In Proceedings of the 15th international Conference on World Wide Web, Scotland, UK, 23–26 May 2006. [Google Scholar]
- Zheng, N.; Li, Q. A recommender system based on tag and time information for social tagging systems. Expert Syst. Appl. 2011, 38, 4575–4587. [Google Scholar] [CrossRef]
- Shang, M.-S.; Zhang, Z.-K.; Zhou, T.; Zhang, Y.-C. Collaborative filtering with diffusion-based similarity on tripartite graphs. Phys. A Stat. Mech. Its Appl. 2010, 389, 1259–1264. [Google Scholar] [CrossRef]
- Banda, L.; Singh, K.; Abdel-Basset, M.; Thong, P.H.; Huynh, H.X.; Taniar, D. Recommender Systems Using Collaborative Tagging. Int. J. Data Warehous. Min. 2020, 16, 183–200. [Google Scholar] [CrossRef]
- Wang, C.-D.; Deng, Z.-H.; Lai, J.-H.; Philip, S.Y. Serendipitous recommendation in e-commerce using innovator-based collaborative filtering. IEEE Trans. Cybern. 2018, 49, 2678–2692. [Google Scholar] [CrossRef]
- Kim, H.N.; Ji, A.T.; Ha, I.; Jo, G.S. Collaborative filtering based on collaborative tagging for enhancing the quality of recommendation. Electron. Commer. Res. Appl. 2010, 9, 73–83. [Google Scholar] [CrossRef]
- Shang, M.-S.; Lu, L.; Zhang, Y.-C.; Zhou, T. Empirical analysis of web-based user-object bipartite networks. Europhys. Lett. 2010, 90, 48006. [Google Scholar] [CrossRef]
- Najafabadi, M.K.; Mohamed, A.; Onn, C.W. An impact of time and item influencer in collaborative filtering recommendations using graph-based model. Inf. Process. Manag. 2019, 56, 526–540. [Google Scholar] [CrossRef]
- Bateman, S.; Brooks, C.; McCalla, G.; Brusilovksy, P. Applying Collaborative Tagging to E-learing. In Proceedings of the 16th International World Wide Web Conference, Banff, AB, Canada, 8 May 2007. [Google Scholar]
- Jo, H. A Recommendation System Based on Big Data: Separation of Preference and Similarity; Springer: Cham, Switzerland, 2023; pp. 390–398. [Google Scholar]
- Shardanand, U.; Maes, P. Social information filtering: Algorithms for automating “word of mouth”. In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems, New York, NY, USA, 7–11 May 1995; pp. 210–217. [Google Scholar]
- Sarwar, B.; Karypis, G.; Konstan, J.; Riedl, J. Analysis of recommendation algorithms for E-commerce. In Proceedings of the Second ACM Conference on Electronic Commerce, Minneapolis, MN, USA, 17–20 October 2000; pp. 158–167. [Google Scholar]
- Breese, J.S.; Heckerman, D.; Kadie, C. Empirical analysis of predictive algorithms for collaborative filtering. In Proceedings of the 14th Conference on Uncertainty in Artificial Intelligence, Vancouver, BC, Canada, 19–22 July 1998. [Google Scholar]
- Chen, A. ContextAware Collaborative Filtering System: Predicting the User’s Preferences in Ubiquitous Computing. In Proceedings of the ACM 2005, Los Angeles, CA, USA, 29–31 July 2005. [Google Scholar]
- Adomavicius, G.; Sankaranarayanan, R.; Sen, S.; Tuzhilin, A. Incorporating contextual information in recommender systems using a multidimensional approach. ACM Trans. Inf. Syst. 2005, 23, 103–145. [Google Scholar] [CrossRef]
- Palmisano, C.; Tuzhilin, A.; Gorgoglione, M. Using context to improve predictive modeling of customers in personalization applications. IEEE Trans. Knowl. Data Eng. 2008, 20, 1535–1549. [Google Scholar] [CrossRef]
- Wu, L.; He, X.; Wang, X.; Zhang, K.; Wang, M. A survey on accuracy-oriented neural recommendation: From collaborative filtering to information-rich recommendation. arXiv 2022, arXiv:2104.13030. [Google Scholar] [CrossRef]
- Srifi, M.; Oussous, A.; Ait Lahcen, A.; Mouline, S. Recommender systems based on collaborative filtering using review texts—A survey. Information 2020, 11, 317. [Google Scholar] [CrossRef]
- Wang, X.; He, X.; Wang, M.; Feng, F.; Chua, T.-S. Neural graph collaborative filtering. In Proceedings of the 42nd International ACM SIGIR Conference on Research and Development in Information Retrieval, Paris, France, 21–25 July 2019; pp. 165–174. [Google Scholar]
- Rendle, S.; Krichene, W.; Zhang, L.; Anderson, J. Neural collaborative filtering vs. matrix factorization revisited. In Proceedings of the 14th ACM Conference on Recommender Systems, Online, 22–26 September 2020; pp. 240–248. [Google Scholar]
- Duan, R.; Jiang, C.; Jain, H.K. Combining review-based collaborative filtering and matrix factorization: A solution to rating’s sparsity problem. Decis. Support Syst. 2022, 156, 113748. [Google Scholar] [CrossRef]
- Lin, Z.; Tian, C.; Hou, Y.; Zhao, W.X. Improving graph collaborative filtering with neighborhood-enriched contrastive learning. In Proceedings of the ACM Web Conference 2022, New York, NY, USA, 27 April 2022; pp. 2320–2329. [Google Scholar]
- Xia, L.; Huang, C.; Xu, Y.; Zhao, J.; Yin, D.; Huang, J. Hypergraph contrastive collaborative filtering. In Proceedings of the 45th International ACM SIGIR Conference on Research and Development in Information Retrieval, Madrid, Spain, 11–15 July 2022; pp. 70–79. [Google Scholar]
- Fkih, F. Similarity measures for Collaborative Filtering-based Recommender Systems: Review and experimental comparison. J. King Saud. Univ.-Comput. Inf. Sci. 2022, 34, 7645–7669. [Google Scholar] [CrossRef]
- Zarzour, H.; Maazouzi, F.; Soltani, M.; Chemam, C. An improved collaborative filtering recommendation algorithm for big data. In Proceedings of the IFIP International Conference on Computational Intelligence and Its Applications, Oran, Algeria, 8–10 May 2018; pp. 660–668. [Google Scholar]
- Shen, J.; Zhou, T.; Chen, L. Collaborative filtering-based recommendation system for big data. Int. J. Comput. Sci. Eng. 2020, 21, 219–225. [Google Scholar] [CrossRef]
- Sahoo, A.K.; Pradhan, C.; Barik, R.K.; Dubey, H. DeepReco: Deep learning based health recommender system using collaborative filtering. Computation 2019, 7, 25. [Google Scholar] [CrossRef]
- Najafabadi, M.K.; Mahrin, M.N.r. A systematic literature review on the state of research and practice of collaborative filtering technique and implicit feedback. Artif. Intell. Rev. 2016, 45, 167–201. [Google Scholar] [CrossRef]
- Nilashi, M.; Ahani, A.; Esfahani, M.D.; Yadegaridehkordi, E.; Samad, S.; Ibrahim, O.; Sharef, N.M.; Akbari, E. Preference learning for eco-friendly hotels recommendation: A multi-criteria collaborative filtering approach. J. Clean. Prod. 2019, 215, 767–783. [Google Scholar] [CrossRef]
- Wang, W.; Tang, T.; Xia, F.; Gong, Z.; Chen, Z.; Liu, H. Collaborative filtering with network representation learning for citation recommendation. IEEE Trans. Big Data 2020, 8, 1233–1246. [Google Scholar] [CrossRef]
- Boyack, K.; Klavans, R.; Börner, K. Mapping the backbone of science. Scientometrics 2005, 64, 351–374. [Google Scholar] [CrossRef]
- Nehete, S.P.; Devane, S.R. Improving Performance of Collaborative Filtering. In ICT for Competitive Strategies; CRC Press: Boca Raton, FL, USA, 2020; pp. 423–432. [Google Scholar]
- Moghadam, P.H.; Heidari, V.; Moeini, A.; Kamandi, A. An exponential similarity measure for collaborative filtering. SN Appl. Sci. 2019, 1, 1172. [Google Scholar] [CrossRef]
- Sarwar, B.; Karypis, G.; Konstan, J.; Riedl, J. Item-based collaborative filtering recommendation algorithms. In Proceedings of the 10th International Conference on World Wide Web, Hong Kong, 1–5 May 2001; pp. 285–295. [Google Scholar]
- Lathia, N.; Hailes, S.; Capra, L. kNN CF: A temporal social network. In Proceedings of the 2008 ACM Conference on Recommender Systems, Lausanne, Switzerland, 23–25 October 2008. [Google Scholar]
- Ding, Y.; Li, X. Time weight collaborative filtering. In Proceedings of the 14th ACM International Conference on Information and Knowledge Management, Bremen, Germany, 31 October–5 November 2005; pp. 485–492. [Google Scholar]
- Aggarwal, C.C.; Han, J.; Wang, J.; Yu, P.S. A framework for projected clustering of high dimensional data streams. In Proceedings of the Thirtieth International Conference on Very Large Data Bases, Toronto, ON, Canada, 31 August–3 September 2004; pp. 852–863. [Google Scholar]
- Salton, G.; Wong, A.; Yang, C.S. A vector space model for automatic indexing. Commun. ACM 1975, 18, 613–620. [Google Scholar] [CrossRef]
- Mar.gar.in. Margarin Is a Social Bookmark. Available online: http://mar.gar.in/ (accessed on 15 September 2023).
- DeliciousAI. Delicious. Available online: https://www.delicious.com/ (accessed on 15 September 2023).
- DAI-Lab. Distributed Artificial Intelligence Laboratory. Available online: http://www.dai-labor.de (accessed on 8 December 2021).
- Najafabadi, M.K.; Mahrin, M.N.; Chuprat, S.; Sarkan, H.M. Improving the accuracy of collaborative filtering recommendations using clustering and association rules mining on implicit data. Comput. Hum. Behav. 2017, 67, 113–128. [Google Scholar] [CrossRef]
- Tewari, A.S.; Barman, A.G. Sequencing of items in personalized recommendations using multiple recommendation techniques. Expert Syst. Appl. 2018, 97, 70–82. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| R1 | R2 | R3 | R4 | R5 | |
|---|---|---|---|---|---|
| U1 | Tag1, Tag2 (May 15) | Tag 1, Tag 3, Tag 4 (May 6) | Tag1, Tag4, Tag5 (May 11) | ||
| U2 | Tag4 (May 15) | Tag4, Tag6 (May 1) | |||
| U3 | Tag1, Tag7 (May 15) | Tag 8 (May 11) | Tag 4 (May 6) | Tag1, Tag 7 (May 6) |
| Tag | R1 | R2 | R3 | R4 | R5 |
|---|---|---|---|---|---|
| U1 | 0.5 | 0 | 0.75 | 0.75 | 0 |
| U2 | 0 | 0.67 | 0 | 1.0 | 0 |
| U3 | 0.67 | 0 | 0.17 | 0.17 | 0.67 |
| Time | R1 | R2 | R3 | R4 | R5 |
|---|---|---|---|---|---|
| U1 | 1.0 | 0 | 0.25 | 0.5 | 0 |
| U2 | 0 | 1.0 | 0 | 0.25 | 0 |
| U3 | 1.0 | 0 | 0.5 | 0.25 | 0.25 |
| Hybrid | R1 | R2 | R3 | R4 | R5 |
|---|---|---|---|---|---|
| U1 | 0.75 | 0 | 0.5 | 0.625 | 0 |
| U2 | 0 | 0.835 | 0 | 0.625 | 0 |
| U3 | 0.835 | 0 | 0.335 | 0.21 | 0.46 |
| Symbol | Meaning |
|---|---|
| u | User |
| v | Neighbor User |
| r | Resource |
| R | Set of Resources |
| i | A Certain User i |
| Wtag(u,r) | Weight from Tags by User ‘u’ for Resource ‘r’ |
| Wtime(u,r) | Temporal Weight of User ‘u’ towards Resource ‘r’ |
| Whybrid(u,r) | Combined Tag-Time Weight for User ‘u’ and Resource ‘r’ |
| Wi(u,r) | Composite Weight Profile of User ‘u’ for Resource ‘r’ |
| Wi(v,r) | Each Weight Vector of Neighbor User ‘v’ to Resource ‘r’ |
| λ | Parameter for Balancing Tag-Based and Time-Based Weights |
| simi(u,v) | Similarity Score Between User ‘u’ and User ‘v’ |
| Stag, Stime, Shybrid | Tag-Based, Time-Based, and Hybrid Similarities, respectively |
| KNN(u) | Set of ‘k’ Nearest Neighbors of User ‘u’ |
| Score(u,r) | Predicted Preference Score of User ‘u’ for Resource ‘r’ |
| t | Relative Time Point Value |
| ti | Tagging Day |
| tl | Last Tagging Day |
| tf | First Tagging Day |
| hlt | Half-Life for Each User |
| Data | Number of Resources | Number of Tags | Number of Bookmarks |
|---|---|---|---|
| Margarin | 15,765 | 11,065 | 18,850 |
| Delicious | 43,028 | 9383 | 104,687 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jo, H.; Hong, J.-h.; Choeh, J.Y. Improving Collaborative Filtering Recommendations with Tag and Time Integration in Virtual Online Communities. Appl. Sci. 2023, 13, 10528. https://doi.org/10.3390/app131810528
Jo H, Hong J-h, Choeh JY. Improving Collaborative Filtering Recommendations with Tag and Time Integration in Virtual Online Communities. Applied Sciences. 2023; 13(18):10528. https://doi.org/10.3390/app131810528
Chicago/Turabian StyleJo, Hyeon, Jong-hyun Hong, and Joon Yeon Choeh. 2023. "Improving Collaborative Filtering Recommendations with Tag and Time Integration in Virtual Online Communities" Applied Sciences 13, no. 18: 10528. https://doi.org/10.3390/app131810528