1. Introduction
Mechanical fault diagnosis is of paramount importance in modern industrial contexts as it significantly contributes to enhancing equipment reliability, operational safety, and cost reduction. The emergence of the Industrial Internet of Things (IIoT), big data, and AI has propelled the field of fault diagnosis, leading to notable advancements [
1,
2]. These advancements have demonstrated their effectiveness in utilizing condition-monitoring data. As a result, extensive research efforts have been conducted to employ conventional machine-learning techniques [
3], such as Support Vector Machines (SVM) [
4], k-Nearest Neighbors (KNN) [
5], decision trees [
6], etc. However, the diagnosing accuracy of these methods often relies on the expertise of specialists who manually select relevant features.
In light of the above limitations, deep-learning (DL) techniques have emerged as a prominent approach, offering the potential for end-to-end learning and the elimination of manual feature selection [
7]. However, industrial equipment generally operates under normal conditions, resulting in a limited availability of fault samples. Unfortunately, the conventional deep-learning approach requires a substantial amount of labeled data to achieve a significant level of accuracy. Consequently, numerous recent studies have concentrated on few-shot fault diagnosis [
8,
9]. Furthermore, due to the complex and variable working conditions of the equipment, the results of fault diagnosis vary across specific industrial scenarios, which divides fault samples into different domains based on their feature distribution and category space. To address the challenges posed by limited data availability and domain diversity, few-shot cross-domain fault diagnosis emerges as a compelling approach, often referred to as few-shot transfer learning [
10,
11]. This technique leverages knowledge from the source domain to the target domain by training a network using data from the source domain on one operational condition and subsequently fine-tuning it with the data from the target domain on different working conditions. This approach has exhibited significant potential to greatly enhance the efficacy of fault diagnosis within the target domain.
In recent years, a few scholars have embarked on the investigation of the few-shot cross-domain fault-diagnosis approach. For instance, Lin et al. [
12] introduced a novel cross-domain fault-diagnosis method for bearings, which relies on an enhanced semi-supervised meta-learning technique. Wu et al. [
11] presented a few-shot transfer learning method that leverages meta-learning for the diagnosis of few-shot samples under varying conditions. Feng et al. [
10] systematically summarized the application of deep meta-learning in the context of few-shot cross-domain fault diagnosis. However, the existing research on few-shot cross-domain fault diagnosis has primarily focused on transferring knowledge from a single source domain to the target domain. Nevertheless, several crucial issues remain unresolved: (1) Practical scenarios often still involve a shortage of all types of fault samples within a single source domain, making the utilization of data from multiple source domains a potentially effective solution. (2) Conducting few-shot machinery fault diagnosis across multiple source domains introduces several new challenges. First, the distinct source domains can be considered to be independent factories or data holders, who are reluctant to disclose or share their private data due to concerns related to industry competition, user privacy, and data security [
13,
14]. Second, fault samples acquired from multiple source domains may exhibit diverse distributions due to disparate working conditions or industrial scenarios [
15], therefore further complicating the complexities associated with few-shot fault diagnosis.
To address the aforementioned challenges, we present a novel federated few-shot learning-based machinery fault-diagnosis scheme, named FedCDAE-MN, which utilizes a combination of convolutional denoising auto-encoder and feature-space metric learning across multiple domains.
Figure 1 illustrates the basic framework of our proposal. In particular, we consider two primary scenarios: (1) a single source domain to target domain scenario, where the working conditions remain the same, but the fault types vary, and (2) multi-source domain scenarios, where the source domains exhibit varying working conditions while the fault type remains consistent. First, to enhance the model’s generalization performance under diverse conditions, we propose a few-shot learning method that relies on a convolutional denoising auto-encoder and feature-space metric learning. By effectively extracting fault features using the convolutional denoising auto-encoder, we improve the model’s domain generalization, robustness, and noise reduction capabilities. Furthermore, the metric embedding module encodes the extracted features, and the meta-learning training method exploits sample similarity information. Importantly, the entire metric learning process operates within the feature space, allowing for effective utilization of label information from the source domain. In addition, to address privacy concerns, the proposed model is developed within the federated learning framework, where individual factories are treated as distinct participants, representing multiple source domains in the few-shot fault diagnoses. The main contributions are summarized as follows:
- (1)
We proposed a federated few-shot learning-based fault-diagnosis framework, which leverages fault data from multiple source domains to construct a unified few-shot fault-diagnosis model. By doing so, we address the issue of limited fault samples in the target domain, therefore enhancing diagnosis accuracy. Moreover, our framework ensures privacy preservation by avoiding the need to share sensitive data.
- (2)
We proposed a novel few-shot fault-diagnosis method that utilizes a convolutional denoising auto-encoder and feature-space metric learning. This approach enhances the model’s generalization across various domains and exhibits strong adaptability to diverse working conditions, new fault types, and noises.
- (3)
We conduct extensive experiments on real-world datasets to evaluate the effectiveness of our approach. Experimental results demonstrate that FedCDAE-MN outperforms existing methods and significantly enhances the accuracy of fault diagnosis.
The rest of the paper is organized as follows. We review work related in
Section 2. In
Section 3, we state the preliminaries and problem definitions. In
Section 4, we introduce the details of our approach. We present the experimental results and analysis in
Section 5. Finally, we conclude our work in
Section 6.
2. Related Work
In this section, we present a comprehensive review of related studies on machinery fault diagnosis, specifically focusing on the techniques of deep learning, few-shot learning, and federated learning.
2.1. Deep Learning for Fault Diagnosis
Deep learning enables end-to-end training, eliminating the need for manual feature engineering by domain experts. Consequently, numerous researchers have adopted deep-learning approaches to effectively diagnose faults. For instance, Wang et al. [
16] successfully combine variational mode decomposition (VMD) with a one-dimensional convolutional network to diagnose bearing faults. VMD effectively removes random noise from the original signal and contributes to feature enhancement. Gao et al. [
17] employs a deep belief network to accurately identify bearing defects. The network is initially pre-trained using minimal batch random gradient descent and subsequently fine-tuned using conjugate gradient descent and backpropagation. Additionally, Zhang et al. [
18] proposes a method that leverages tiny convolution kernels in the second layer for multi-layer nonlinear mapping and larger kernels in the primary convolutional layer for feature extraction and noise reduction. An et al. [
19] suggest the utilization of a long-term and short-term memory network for diagnosing faults in time-varying working condition data. The loss function incorporates the outputs from each time step, and dropout regularization is employed to enhance training efficiency and diagnostic capability. Wang et al. [
20] also employs long-term and short-term memory networks for bearing fault diagnosis, integrating residual modules with long-term and short-term memory to leverage both deep local features and global time series features of bearing vibration signals.
Although deep learning has demonstrated its effectiveness in fault diagnosis, it heavily relies on a substantial volume of labeled data. However, due to security considerations, machines may halt immediately after a fault occurs, leading to an insufficient number of fault samples available for training deep-learning models.
2.2. Few-Shot Learning for Fault Diagnosis
To tackle the challenge of limited fault samples, recent research efforts have centered around few-shot fault-diagnosis techniques, which are generally categorized into three main approaches: data-based, algorithm-based, and model-based. (1) Data-based methods concentrate on improving the training dataset by employing data augmentation strategies, including data generation [
21,
22], oversampling [
23], and reweighting [
24]. (2) Model-based methods constrain the hypothesis space through prior knowledge, such as embedded learning [
25,
26] and generative adversarial modeling [
27]. (3) Algorithm-based methods primarily utilize prior knowledge to modify the search strategy within the hypothesis space. This category can be further divided into two subcategories: methods that provide good initialization parameters and those that directly train an optimizer to output the search step. Fine-tuning is an effective means of providing good initialization parameters [
28], while Model-Agnostic Meta-Learning (MAML) represents a framework for directly training an optimizer to determine the search step. For instance, Wu et al. [
11] introduced a few-shot transfer learning approach based on MAML for diagnosing faults in variable conditions. The effectiveness of the proposed method is verified based on a unified one-dimensional convolution network on three public datasets. Wang et al. [
29] propose a feature-space metric-based meta-learning model (FSM3) to overcome the challenge of the few-shot machinery fault diagnosis under multiple limited data conditions. FSM3 exploits both the attribute information from individual samples and the similarity information from sample groups. In contrast to FSM3, the model in [
30] is trained directly in the data space rather than the feature space. Notably, the approach presented in this study falls within the framework of MAML.
The aforementioned methods primarily concentrate on addressing the issue of fault diagnosis with limited samples within a single source domain. Although these methods exhibit satisfactory performance within the single source domain scenario, their effectiveness in accommodating multiple source domains requires further validation. Additionally, there is a lack of adequate attention paid to maximizing the utilization of fault information from each source domain to acquire additional prior knowledge and enhance the generalization capability of models in a multi-source domain scenario. Furthermore, most research efforts often overlook considerations related to user privacy and data security.
2.3. Federated Learning for Fault Diagnosis
To address concerns related to data dispersion and privacy protection, federated learning has gained attention from scholars as a promising approach for fault diagnosis in recent years. For instance, Wang et al. [
31] introduced a federated adversarial domain generalization network for mechanical fault diagnosis. This model achieves collaborative training between a central server and multiple clients, establishing a global fault-diagnosis model while ensuring data privacy. Zhao et al. [
32] proposed a multi-source domain adaptive method that combines transfer learning and federated learning. By leveraging user data while preserving data privacy, this approach achieves accurate identification performance. Chen et al. [
33] presented a federated transfer learning framework based on a weighted joint average of differences. This framework effectively coordinates well-trained global diagnostic models with privacy protection. Additionally, they developed a dynamic weighted average algorithm using the maximum mean difference (MMD) and integrated the updated local model using an automatically learned weight. Geng et al. [
34] proposed the FA-FedAVG algorithm, which optimizes the model weighting strategy to enhance the influence of high-quality local models. They also introduced a model aggregation strategy based on poor accuracy to reduce iteration count and accelerate convergence during training. Moreover, Chen et al. [
35] proposed a joint training method that incorporates meta-learning into a federated learning framework, aiming to enhance the performance of the global meta-learner.
Currently, the fault diagnosis with federated learning is typically accomplished through a combination of local training and cloud parameter aggregation. Building upon this foundation, certain methods mainly concentrate on assessing the distinct contributions of individual participants to the global model. Nevertheless, opportunities for optimization persist, offering the potential to investigate the allocation of varying weights to participants. This exploration could enhance the precision and personalization of model training.
In summary, unlike existing approaches, the method introduced in this paper, termed FedCDAE-MN, places its primary emphasis on elevating the accuracy of mechanical fault diagnosis within the framework of few-shot learning across multi-source domain scenarios. Simultaneously, it prioritizes safeguarding user data privacy through personalized federated learning.
Table 1 provides a comprehensive summary comparing our method with existing approaches.
3. Preliminary and Problem Definition
In this section, we provide the necessary preliminaries and the problem definition before introducing the specifics of our approach.
3.1. Few-Shot Learning
The few-shot learning approach primarily leverages auxiliary sets from the source domain to extract knowledge, aiding in model training using a given few-shot support set in the target domain. As illustrated in
Figure 2, the source domain (auxiliary set) consists of a substantial amount of labeled data, with a label space that does not intersect with that of the target domain. One approach to utilizing the source domain data involves the random selection of a series of few-shot learning tasks, adhering to the configuration of the target domain training set (support set). Specifically, each task comprises
N categories, and within each category,
K samples are included (referred to as
N-way,
K-shot). Prior knowledge is extracted from the interaction between these tasks and the model to enhance performance in the target domain, establishing an episodic training mechanism. Each few-shot learning task is treated as an episodic scenario, and the overall process can be viewed as meta-learning, as learning takes place at the task level rather than the data level.
In the field of small sample learning, two primary branches currently exist based on the forms of knowledge extracted from auxiliary tasks: metric-based meta-learning and optimization-based meta-learning. The metric-based meta-learning model aims to acquire a unified feature space that is independent of classes, ensuring that the intra-class distance between samples is smaller than the inter-class distance. Classification of a query sample is determined based on its distance from each supporting sample in the learning space. On the other hand, the optimized meta-learning model incorporates additional trainable models (meta models) to perform parameter updates on the primary model. The meta-model can be fine-tuned using the limited support set in the target domain to classify samples within the query set.
3.2. Convolutional Denoising Auto-Encoder
The auto-encoder (AE) is an unsupervised neural network designed for data reconstruction. It consists of an encoder and a decoder, both structured symmetrically. Given an input
x, the auto-encoder aims to learn a mapping function
that enables the middle layer to capture the hidden features of the input data. These hidden features can subsequently be fed into a supervised model.
Figure 3 illustrates the denoising auto-encoder (DAE), which introduces noise to the input of AE. By extracting robust features from the noisy data, the DAE reconstructs the original data. In our approach, we employ the Dropout method to incorporate noise into the input. Dropout is a commonly utilized regularization technique during neural network training, randomly setting network nodes to zero with a specific probability. This process can be interpreted as adding noise to the original data. We set the random deactivation rate, denoted as
, to
.
represents the input after adding noise,
denotes the hidden feature, and
y corresponds to the reconstructed input.
The Convolutional Denoising Auto-Encoder (CDAE) is an encoder network that enhances the feature extraction ability of the Denoising Auto-Encoder (DAE) specifically for temporal data. This is achieved by incorporating convolutional layers to create multiple hidden layers. In our approach, we utilize a one-dimensional convolutional neural network based on WDCNN (Wide-Depth Convolutional Neural Network) [
18] as the encoder. The first layer employs a 64 × 1 wide convolutional kernel to extract features for suppressing high-frequency noise. Subsequently, a 3 × 1 narrow convolutional kernel is used in the following layer to extract deep semantic features. For the decoder, we employ deconvolution and upsampling operations to restore the hidden layer features to the same dimensions as the input. The specific network structure of the CDAE is presented in
Table 2.
3.3. Problem Definition
This study focuses on addressing the few-shot fault-diagnosis problem in the federated scenario, and it is primarily based on the following two assumptions:
- (1)
Sufficient labeled data can be gathered from various source domains, whereas the target domain possesses only a limited amount of labeled data.
- (2)
Ensuring data privacy across different domains is essential, and it is imperative to prevent any interaction between local data of different domains.
The task is characterized as a few-shot learning fault-diagnosis problem in the target domain, including -way, K-shot, and M-test. This involves a labeled support set, denoted as , and an unlabeled query set, denoted as . In , each class consists of K samples, while each class in comprises M samples. The samples from the query set and support set are, respectively, represented as and . Here, equals , equals , and K is a small value. In the context of fault diagnosis, x represents the vibration acceleration signal obtained from specific mechanical equipment, with a length of L, while y represents the corresponding fault type. In each fully labeled source domain dataset, all included samples are denoted as , where is a large value. The ultimate objective is to train a model utilizing tasks from various source domains, enabling identification of the fault types for samples in the target domain’s query set based on the support set , which consists of only a small number of samples.
5. Experimental Study
In this section, we conduct extensive experiments on two benchmark datasets to evaluate the effectiveness of our model.
5.1. Experiment Settings
Considering the primary objective of this study is to enhance the accuracy of machinery fault diagnosis in various few-shot scenarios, we conduct experiments through simulations on a single device using multiple processes.
Table 3 summarizes the device configurations used in our simulation. In our experimental setup, we consider three distinct scenarios based on the relationships between the source domain and the target domain, as well as the relationships among different source domains. These scenarios are summarized in
Table 4 as follows:
SCDF (Same Working Condition with Different Fault Type): In this scenario, the working conditions (WC) of both the source and target domains are the same, while the fault types (FT) differ.
DCSF (Different Working Condition with Same Fault Type): In this scenario, we have multiple source domains, each with different working conditions, but they share the same fault types in the target domain.
DCDF (Different Working Condition with Different Fault Type): This scenario has multiple source domains, each with different working conditions. However, the source domains have the same fault type, while the target domain presents a new fault type.
5.2. Datasets
To evaluate the effectiveness of the proposed strategy, we utilized two datasets: the CWRU Rolling Bearing Dataset and the Gearbox Dataset.
CWRU Rolling Bearing Dataset [
36]. This dataset contains vibration acceleration data from the motor drive end, encompassing four distinct bearing health statuses: normal, inner race, ball, and outer race. For each issue location, we considered three separate fault severity levels. The fault diameters in different domains were measured at 7 mm, 14 mm, and 21 mm, respectively, while the corresponding loading speeds ranged from 1797 rpm to 1730 rpm, covering load conditions of 0 HP, 1 HP, 2 HP, and 3 HP.
Gearbox Dataset [
37].This dataset consists of gear acceleration data gathered from the gearbox under various conditions. It encompasses three types of gear faults: normal condition, tooth chipping, and tooth missing. Each gear fault category was meticulously examined under different loads and speeds, specifically at frequencies of 30 Hz, 35 Hz, and 40 Hz, and further classified as either low or high. The samples’ length in this dataset is 3300, and the sampling frequency is 66.67 KHz, with each instance comprising 500 samples.
5.3. Compared Methods
To assess the effectiveness of our method, we compare FedCDAE-MN with several existing approaches, including the baseline few-shot learning methods (i.e., Finetune, FeatureKNN1, and FeatureKNN2) and related state-of-art methods (i.e., DS-MN and FS-MN). Here is a specific introduction to these methods:
Finetune: The basic transfer learning method involves pre-training the model using source domain data and then fixing the feature extraction layer. Subsequently, the model is fine-tuned using target domain data.
FeatureKNN1: After pre-training with source domain data, FeatureKNN1 calculates similarity weights based on the feature distance between query samples and support samples. The weighted labels of all support samples are then utilized as the classification results.
FeatureKNN2: An extension of FeatureKNN1, FeatureKNN2 replaces the feature extractor with a convolutional denoising auto-encoder, building upon the initial approach.
DS-MN [
30]: A few-shot learning method based on metric learning. It differs from other approaches as it is directly trained in the data space rather than the feature space.
FS-MN [
29]: This method, tested only in a single source domain, focuses on metric learning in the feature space.
FedCAE-MN: Our proposed method, FedCAE-MN, is based on FS-MN. It modifies the feature extractor, employing a convolutional auto-encoder instead.
FedCDAE-MN: Our proposed method, FedCDAE-MN, is also based on FS-MN. It similarly replaces the feature extractor, but this time using a convolutional denoising auto-encoder.
5.4. Experiment Parameters Setting
We conducted experiments using 500 samples for each type. For supervised learning, we employed a learning rate of 0.001, a batch size of 16, and 80 iterations. For the fine-tuning approach, the learning rate and iterations were set to 0.0001 and 100, respectively. Similarly, for metric learning, we used a learning rate of 0.0001 and 100 iterations. In the support set, there was one sample for each type of few-shot task, and the query set contained 25 samples of each type. In each round, we randomly selected 100 tasks for training. The final result was calculated as the average accuracy across all 600 tasks, which were taken from the target domain to evaluate the effectiveness of our approach.
5.5. Analysis of Experimental Results
5.5.1. SCDF Experiments
This set of experiments focuses on a single source domain scenario, where the operating conditions are identical for both the source and target domains. However, the fault types in the target domain do not intersect with those in the source domain. This scenario corresponds to real-world situations where target domains may have domain-specific faults due to particular reasons, and leveraging common fault data from other factories with similar operating conditions can aid in diagnosis. The specific task settings in this set of experiments are presented in
Table 5.
The experimental results are presented in
Table 6, and the average accuracy of all tasks is shown in
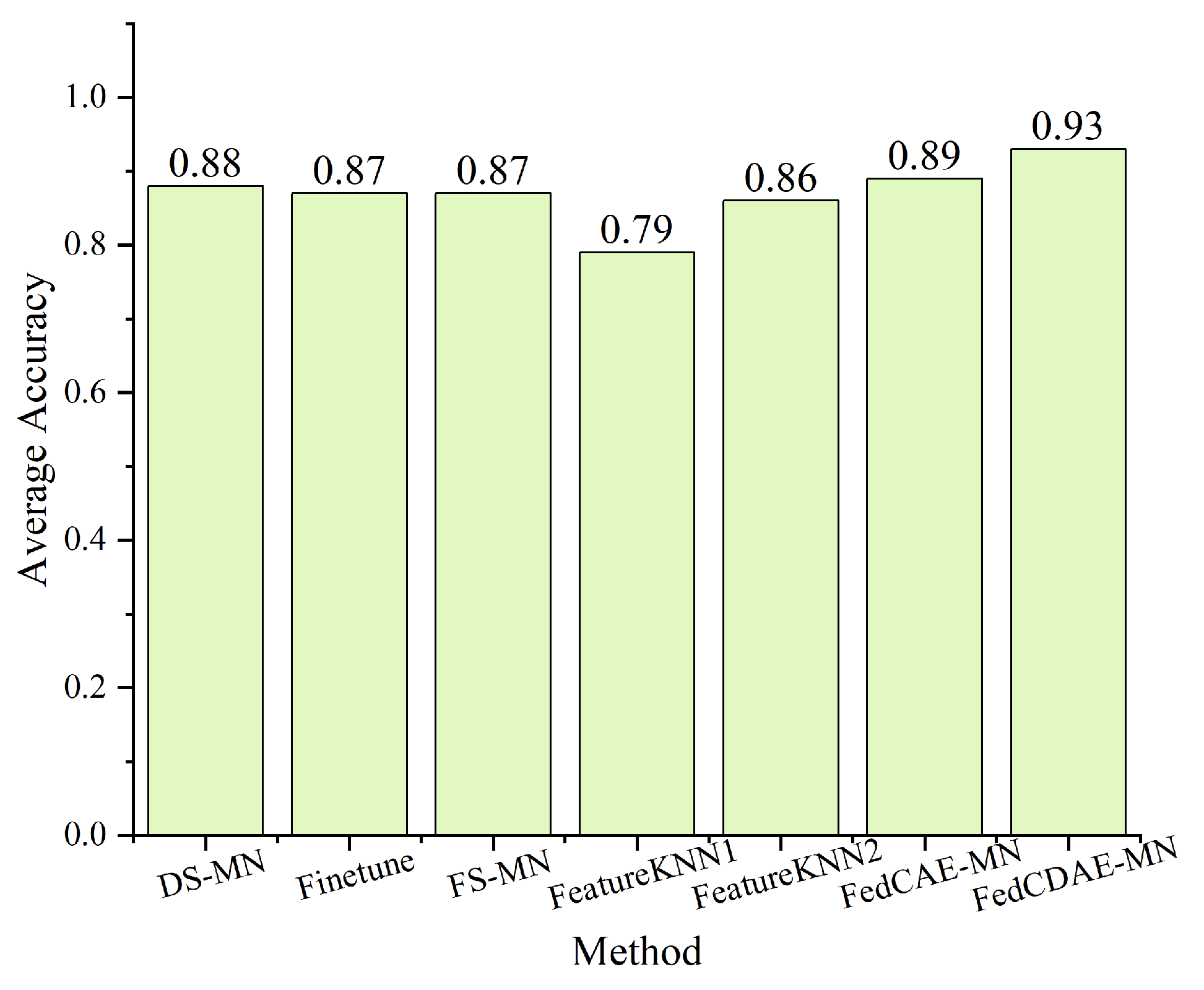
Figure 5. The results demonstrate that FedCDAE-MN outperforms other methods significantly under three distinct operating conditions: Load 0, Load 1, and Load 2. It exhibits superior accuracy across most tasks, indicating its excellent generalization capabilities for different fault types, particularly under low-load conditions. This ability to perform well across a wide range of tasks demonstrates the robustness and adaptability of FedCDAE-MN in accommodating diverse fault scenarios. However, it is worth noting that under the more challenging Load 3 condition, while FedCDAE-MN’s accuracy shows a slight decrease, it remains above average for most tasks, except for the ball (B) task. This observation suggests that while FedCDAE-MN maintains its effectiveness in diagnosing faults across a range of conditions, there may be room for fine-tuning or specialized adaptation to further enhance its performance in specific scenarios. Notably, FedCDAE-MN achieves the highest accuracy in the OuterRace (O) task across all operating conditions, showcasing its exceptional generalization performance for outer ring faults. The average accuracy of the final FedCDAE-MN method reaches 93%, whereas other methods fall below 90%, representing a substantial 3% improvement. These findings demonstrate the efficacy of FedCDAE-MN in addressing the challenges of few-shot fault diagnosis within single-source cross-domain scenarios. In summary, the experimental outcomes not only validate the superiority of FedCDAE-MN in diverse operating conditions but also highlight its potential for specialization in specific fault detection tasks.
5.5.2. DCSF Experiments
This group of experiments considers multiple source domains with different operating conditions from the target domain. However, all domains share the same fault types, reflecting common fault occurrences in practical scenarios. The target domain utilizes fault data from various operating conditions of other factories to aid in fault diagnosis. The experiments consist of four sets of tasks, each comprising 10 fault types. The target domain conditions are categorized as Load 3, Load 2, Load 1, and Load 0, respectively. For instance, when the target domain conditions are Load 3, the source domains are those with conditions of Load 0, Load 1, and Load 2 (denoted as Load 012).
The experimental results are presented in
Table 7. When the target domain experiences Load 3 conditions, the fault features learned from the source domain are relatively simple. Consequently, the generalization of Finetune, DS-MN, and FeatureKNN methods is poor, with an accuracy of less than 90%. In contrast, feature-space metric learning methods (FS-MN, FedCAE-MN, and FedCDAE-MN) exhibit outstanding performance, consistently achieving accuracies surpassing 95%. These results highlight the significance of leveraging label information from the source domain data to enhance feature extraction and the efficacy of few-shot metric learning strategies in improving generalization. Furthermore, the substantial improvement showcased by FeatureKNN2 in comparison to FeatureKNN1 highlights the effectiveness of convolutional denoising auto-encoders in elevating generalization within cross-domain scenarios. This improvement suggests that leveraging deep-learning techniques can significantly enhance the adaptability of fault-diagnosis methods to varying operating conditions, even when the source and target domains exhibit substantial differences. Notably, both FedCDAE-MN and FS-MN achieved an impressive average accuracy of 98%, indicating the efficacy of feature-space metric learning in addressing domain differences. In summary, our experiments indicate the pivotal role of load conditions in shaping fault feature complexity and its cascading impact on fault-diagnosis methods. It also reaffirms the value of leveraging source domain label information and the effectiveness of few-shot metric learning strategies in improving generalization.
5.5.3. DCDF Experiments
This group of experiments considers multiple source domains with distinct working conditions from the target domain. The fault types in the source domains are the same, but they do not overlap with the fault types in the target domain. This situation reflects a complex real-world scenario where the working conditions and fault types in the target domain differ from those in the source domains. Utilizing data from source domains with common working conditions and fault types can assist the target domain in fault diagnosis.
The experimental results are presented in
Table 8, and the average accuracy of all tasks is illustrated in
Figure 6. Remarkably, FedCDAE-MN achieves the highest accuracy in 10 out of the 16 tasks, with an impressive average accuracy of 96%, surpassing all other methods. Moreover, compared to previous single source domain experiments, FedCDAE-MN exhibits substantial growth, elevating its average accuracy from 93% to 96%, demonstrating its exceptional adaptability and effectiveness in confronting the challenges of few-shot fault diagnosis in multi-source domain scenarios. The success of FedCDAE-MN can be attributed to its adeptness in extracting relevant prior knowledge from source domains under distinct conditions. This capacity empowers it to achieve superior generalization within the target domain, even when faced with varying operational conditions and fault types. However, it is noteworthy that the average accuracy of DS-MN and Finetune methods decreased in the multi-source domain setting. Specifically, the average accuracy of DS-MN decreased from 88% to 82%, indicating that the performance of DS-MN may be influenced by domain shift resulting from the increase in the number of source domains. These findings contribute to our understanding of few-shot fault diagnosis in complex multi-source domain environments, paving the way for further research into optimizing methods for enhanced adaptability and robustness. In summary, our experimental results underscore the exceptional performance of FedCDAE-MN in multi-source domain fault-diagnosis scenarios. Its ability to leverage knowledge from various source domains under different operating conditions demonstrates its adaptability and effectiveness.
Furthermore, four transferring experiments were conducted on the Gearbox dataset for the DCDF scenario with two tasks. In this setting, CT represents the target domain fault types as normal state and clipped tooth, and the source domain fault types as normal state and missing tooth. On the other hand, MT represents the target domain fault types as normal state and missing tooth, and the source domain fault types as normal state and clipped tooth.
The experimental results are presented in
Table 9, and the average accuracy of all tasks is displayed in
Figure 7. Notably, FS-MN and Finetune methods only achieved an accuracy of approximately 50% on specific tasks, which is comparatively lower than that of other methods. This further emphasizes the inherent limitations of these two methods in multi-source domain scenarios, including potential issues related to domain shift, feature extraction, and generalization. Conversely, the remaining methods show remarkable resilience and effectiveness in this context, maintaining average accuracy levels consistently above 95%. This performance demonstrates their capacity to navigate the complexities of multi-source domain scenarios adeptly. It is worth noting that FedCDAE-MN and FeatureKNN2 achieves the highest accuracy of 97%. This achievement further highlights the power of convolutional denoising auto-encoders in feature extraction and domain generalization. In conclusion, the extensive examination of our experimental results sheds light on the performance disparities among various fault-diagnosis methods within the multi-source domain context. The limitations observed for FS-MN and Finetune methods underscore the formidable hurdles that need to be overcome in adapting to this environment. Conversely, the performance of FedCDAE-MN and FeatureKNN2 show the significance of advanced feature extraction techniques, particularly convolutional denoising auto-encoders, in enhancing domain generalization and diagnosis accuracy.
5.5.4. Performance under Different Shot
To evaluate the influence of varying sample sizes on the algorithm, we sequentially set the number of samples for each class in the target domain support set to 5, 10, 15, 20, 50, and 100. In this experiment, we chose a task from the DCDF scenario with lower accuracy for testing. The source domain operating conditions were Load 0, Load 2, and Load 3, with fault types being normal, inner circle fault, and outer circle fault, respectively. The target domain operated under Load 1 conditions, with fault types of normal and ball fault. We specifically selected this task to explore whether increasing the sample size could enhance the accuracy of more challenging diagnostic tasks.
The experimental results are depicted in
Figure 8. The observed trend reveals a noteworthy relationship as the number of samples in each class of the support set varies. Initially, as the sample size increases from 1 to 10, there is a discernible improvement in diagnostic accuracy, rising from 0.82 to 0.85. This correlation suggests that, up to a certain point, increasing the sample size indeed enhances the diagnostic performance of FedCDAE-MN. However, when the sample size is further increased to 100, a turning point emerges. In particular, the accuracy of diagnosis begins to gradually decrease and stabilize. This observation implies that, for FedCDAE-MN, a larger sample size does not necessarily translate into improved diagnostic performance. Instead, it suggests the presence of the optimal number of samples converging around 10. This finding carries practical implications for implementing FedCDAE-MN in real-world scenarios, as it highlights the importance of carefully considering the size of labeled data utilized. This observation suggests that, for FedCDAE-MN, a larger sample size does not necessarily lead to a better diagnostic performance. Moreover, the observed performance with a sufficient sample size highlights an essential aspect of FedCDAE-MN’s suitability. Specifically, it affirms that FedCDAE-MN is particularly well-suited for addressing fault-diagnosis problems characterized by limited samples. In these scenarios, where acquiring a vast amount of labeled data may be challenging or costly, FedCDAE-MN offers a robust and effective solution. In practical applications, the observed relationship between sample size and diagnostic accuracy emphasizes the critical need to consider the sample size wisely and select the appropriate algorithm accordingly.
5.5.5. Denoising Performance Analysis
To assess the denoising performance of the model, we introduced noise with various signal-to-noise ratios into the target domain data. The signal-to-noise ratio is formulated as Equation (
10), where
is the signal power and
is the noise power. We selected a task from the DCDF scenario with the source domain operating conditions as Load 0, Load 2, and Load 3, and fault types being normal state, ball fault (B), and outer ring fault (O). The target domain operated under Load 1 conditions, with the fault types being normal state and inner ring fault (I).
Figure 9 illustrates the experimental results of noise in the performance of various diagnostic methods. In particular, the accuracy of each method declines gradually as noise levels increase from right to left. This reduction in accuracy aligns with our expectations, as noise inherently introduces uncertainty and complexity into the diagnostic process. However, FedCDAE-MN exhibits a slower decrease in accuracy compared to other methods. Moreover, FedCDAE-MN maintains consistently high accuracy levels even under varying signal-to-noise ratios. Therefore, FedCDAE-MN has significant implications for practical fault-diagnosis applications. In real-world scenarios, noise is often an unavoidable aspect of data acquisition, stemming from various sources such as sensor inaccuracies, environmental conditions, or data transmission issues. Consequently, an algorithm’s ability to maintain high accuracy in noisy conditions is of paramount importance. In addition, these findings also inspire further research into strategies for enhancing noise tolerance in diagnostic methodologies and highlight the pivotal role of FedCDAE-MN in addressing the challenges posed by noise in real-world scenarios.
6. Conclusions and Future Work
This paper addresses the challenges of cross-domain few-shot fault diagnosis, which include limited samples, complex working conditions, and diverse fault types. To enhance the model’s generalization ability, we propose a federated few-shot fault-diagnosis method that leverages convolutional denoising auto-encoder and feature-space metric learning. The approach involves training the model using fault data from various source domains while ensuring data privacy through federated parameter aggregation. By incorporating convolutional denoising auto-encoder and feature-space metric learning, the model’s generalization across different working conditions and fault types is significantly improved, leading to enhanced diagnostic accuracy. The effectiveness of the proposed method is demonstrated through experimental results on the CWRU bearing and gearbox datasets.
In the future, our research will encompass several key objectives. First, we will explore the applicability of our FedCDAE-MN to various scenarios within the manufacturing process, such as process performance prediction, product defect detection, and more. Second, our efforts will be directed toward enhancing the interpretability of our model. To achieve this, we will explore the knowledge-data dual-driven method for fault diagnosis. Lastly, we intend to investigate the issues of federated few-shot learning-based fault diagnosis across multiple domains with heterogeneous resources, seeking the optimal trade-off between model utility and resource consumption.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}