1. Introduction
With the rapid development of intelligent information and related technologies, people’s daily lives and work increasingly rely on the transmission of information. As the most common form of information presentation, digital images help humans store, transmit, and analyze information, and have become an indispensable part of human communication. During the process of image acquisition, low-light images are often obtained due to factors such as poor lighting conditions during image capture and limitations in hardware facilities of intelligent capture devices. The images themselves exhibit overall darkness, blurred image details, and poor contrast, which not only increase the difficulty of obtaining image information but also diminish their usefulness in subsequent tasks such as image classification and segmentation [
1]. For such low-light images with multiple issues, it is necessary to employ image enhancement techniques to improve brightness and contrast, thereby obtaining more valuable information and facilitating further processing in computer vision systems. To tackle the mentioned concern, this investigation focuses on the exploration of algorithms aimed at enhancing low-light images.
During the early stages of image enhancement technology development, spatial domain image enhancement and frequency domain image enhancement were the two most commonly used approaches. Frequency domain image enhancement involves enhancing low-quality images using two-dimensional Fourier transforms, such as homomorphic filtering, high-pass filtering, and wavelet transformations. On the other hand, spatial domain image enhancement techniques involve filtering, smoothing, and sharpening operations applied to each neighborhood of image pixels, such as linear enhancement and histogram equalization [
2]. Low-light image enhancement algorithms based on histogram equalization effectively improve image brightness while suppressing image noise. However, these algorithms still suffer from issues such as underexposure, overexposure, or color distortion in certain local regions of the output image.
The original purpose of image dehazing algorithms was to enhance images captured in foggy weather conditions. However, Dong et al. [
3] discovered a substantial similarity between inverted low-light images and images captured in foggy conditions. Consequently, they applied image dehazing algorithms to process the low-light images, leading to the proposition of a low-light image enhancement algorithm based on the dark channel prior theory. While this algorithm yielded a certain level of enhancement, it introduced pronounced edge exaggeration and evident object-background segmentation artifacts in the enhanced images, thereby presenting new avenues of investigation for subsequent researchers. Later, Chandana et al. [
4] employed adaptive parameters to perform dehazing operations on blurry images, effectively addressing issues related to edge segmentation and enhancing the contrast of the resulting output images. While the low-light image enhancement algorithm rooted in dehazing models does enhance image brightness and contrast, the algorithm’s physical model lacks comprehensive experimental validation. Moreover, the improved images often exhibit reduced clarity of details, ultimately falling short of producing satisfactory visual outcomes.
In the late 20th century, Jobson et al. based their work on the Retinex theory [
5] and subsequently proposed several algorithms: the Single Scale Retinex (SSR) algorithm based on center-surround operations [
6], the Multi-Scale Retinex (MSR) algorithm [
7], and the Multi-Scale Retinex with Color Restoration (MSRCR) algorithm that incorporates color restoration factors [
8]. The SSR algorithm calculated the grayscale value by weighting the surrounding pixel values of a target point and then removed the illumination component using a Gaussian function to achieve image enhancement. The MSR algorithm built upon the foundation of SSR by incorporating multiscale Gaussian filtering, leading to advancements in aspects such as color enhancement and dynamic range compression. But it still had issues such as inadequate edge sharpening, color distortion, and unclear details in bright regions, leading to visual discrepancies in the overall appearance of the enhanced images. The MSRCR algorithm improved the overall visual perception of images by introducing color restoration factors. However, the issue of noise remained prominent. Kong et al. [
9] proposed an image enhancement algorithm that utilizes a Poisson noise-aware Retinex model, effectively suppressing noise during the enhancement process and improving the clarity of image details. The low-light image enhancement algorithms based on the Retinex theory enhance the contrast of input images while also moderately mitigating the impact of noise. Nonetheless, the improvement in terms of brightness enhancement is somewhat constrained, and there is room for enhancing real-time performance and general applicability. Furthermore, these algorithms require manually inputting parameters based on prior knowledge, resulting in inconsistent enhancement effects for different types of images.
Amid the progression of computer science and technology, deep learning has emerged as a predominant avenue of exploration within the realm of image enhancement. Employing this trend, the LLNet network [
10] leverages a pre-trained deep autoencoder to extract signal characteristics from low-light images. The network’s primary accomplishment is the enhancement of image contrast and the mitigation of noise. On the other hand, it also presented a notable issue of significant color distortion. MSR-Net [
11] performs end-to-end enhancement by mapping low-light images to normal-light images, offering a novel perspective on the research of image enhancement algorithms. RetinexNet [
12] first decomposes the input image into smoother illumination and reflectance components using a constrained loss function. It then enhances the illumination component and applies BM3D denoising. While the algorithm addresses color distortion issues, the enhanced images still lack sufficient clarity, thereby impacting the retrieval of fine details. KinDNet [
13] proposes a method for continuously adjusting illumination, which has greater applicability compared to traditional gamma correction. However, the issue of excessive sharpening and blurred details still persists. EnlightenGAN [
14] addresses the difficulty of collecting paired datasets by training a lighting enhancement network using unpaired data, effectively establishing the mapping correlation linking low-light images and reference images. Nevertheless, during the training process, challenges such as gradient vanishing and exploding tend to arise. Li et al. [
15] introduce a set of iterative mapping curves in their enhancement algorithm to increase the mapping’s scope and improve the effectiveness of the enhancement. Yang et al. [
16] employ generative adversarial networks to learn high-quality information from the dataset, resulting in improved overall image quality and enhanced details. Lee et al. [
17] present an unsupervised learning-based algorithm for enhancing low-light images. By incorporating saturation loss and self-attention mapping, the algorithm successfully improves image detail clarity, while the challenge of noise reduction remains to be addressed. The conceptual framework of DCC-Net [
18] involves decoupling each color image into grayscale images and color histograms. These components are then separately enhanced to mitigate discrepancies in color and content consistency between the enhanced and actual images. The grayscale images contribute to generating accurate structures and textures, while the color histograms facilitate image color correction. URetinex-Net [
19] transforms the principle of image decomposition into an implicitly regularized model guided by prior rules. It incorporates three modules responsible for data-dependent initialization, efficient unfolding optimization, and user-specified illumination enhancement, respectively. This algorithm demonstrates impressive outcomes in terms of preserving details and suppressing noise. D2BGAN [
20] integrates cycle consistency, geometric consistency, and illumination consistency into the training of the network model. Additionally, it employs three discriminators to individually learn the color, texture, and edges of the images. This approach ensures the alignment of structural and content aspects between input and generated images while continually enhancing image quality. This network demonstrates strong generalization capabilities across various datasets. Fan et al. established a network named LACN [
21] that incorporates a hybrid attention mechanism. By stacking and fusing parameter-free attention modules, this network achieves more efficient extraction of both global and local image information, leading to a significant reduction in the loss of image details and content. Deep learning-based low-light image enhancement algorithms offer advantages such as high flexibility and wide applicability. However, the enhancement results for fine details are not always ideal.
To address the various issues in existing mainstream algorithms, this paper proposes a low-light image enhancement algorithm based on deep learning and the Retinex theory. Firstly, residual connections and dilated convolutions are employed to improve the efficiency of image decomposition and reduce the loss of details during the decomposition process, resulting in the decomposition of the low-light image into an illumination map and a reflectance map. Secondly, a set of mapping functions are iteratively applied to enhance the illumination map, improving the brightness and contrast of the image. Then, a color restoration module is used to address color distortion and noise problems that may arise during the image enhancement process. Finally, subjective perception and objective metrics are used to compare the performance of different algorithms, demonstrating the effectiveness of the proposed algorithm.
2. Methods
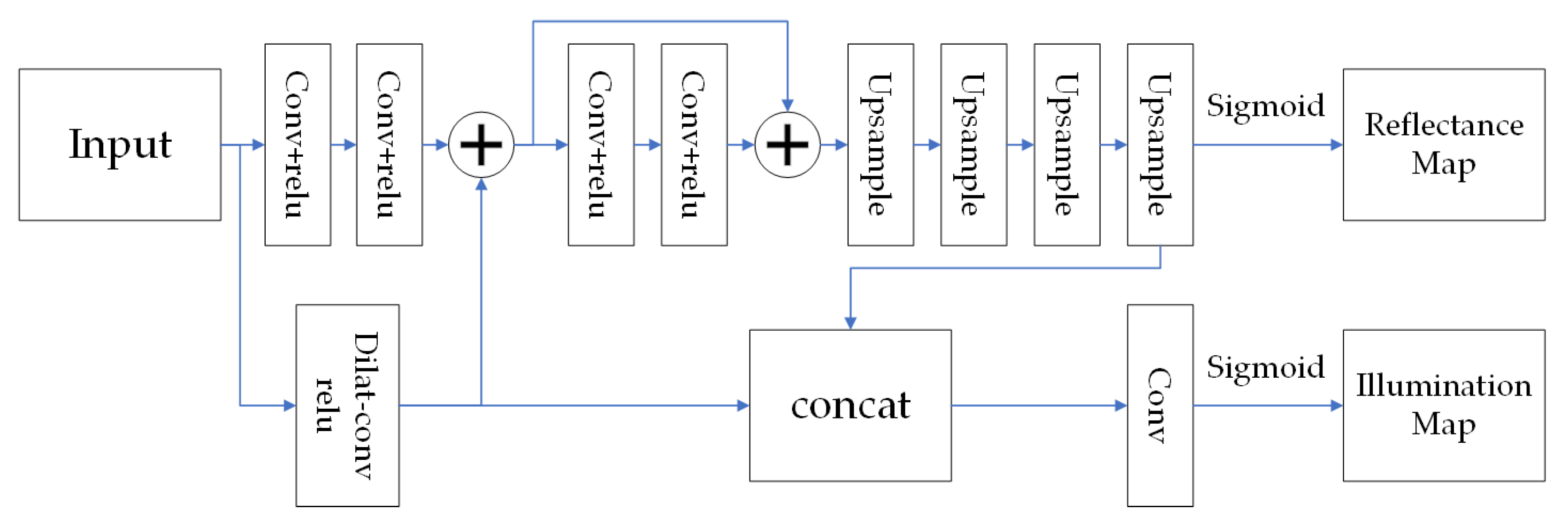
As shown in
Figure 1, the algorithm model is constructed based on deep learning and the Retinex theory consists of three sub-modules: the image decomposition network, the illumination map enhancement network, and the color restoration network. Firstly, the image decomposition network is used to decompose the input low-light image into a reflectance map and an illumination map. Secondly, the illumination map enhancement network is applied to enhance the illumination map. Then, the enhanced illumination map is fused with the reflectance map. Finally, the color restoration module is used to address color distortion and other issues in the image.
2.1. Image Decomposition Network
The Retinex theory suggests that an image can be deconstructed into a reflectance component and an illumination component. The reflectance component encapsulates the inherent attributes of objects, remaining uninfluenced by external illumination. The images we encounter in our daily lives are the result of the fusion of the reflectance and illumination components. Therefore, the primary task of a low-light image enhancement algorithm based on the Retinex theory is to investigate how to separate the illumination map and reflectance map from the input image while preserving the details as much as possible.
The specific structure of the image decomposition network module, as shown in
Figure 2, aims to decompose the input low-light image into a smooth illumination map and reflectance map. To preserve the details as much as possible during the decomposition process, the decomposition module incorporates residual connections and introduces dilated convolution layers to increase the receptive field for better information gathering. The network structure of the decomposition module consists of two branches: the reflectance branch and the illumination branch. In the reflectance branch, the enhanced result of the dilated convolution is coupled with the output of the second convolutional layer. The coupled result is then coupled again with the result of the fourth convolutional layer. Multiple upsampling operations are performed to obtain the final reflectance map. In the illumination branch, the result after one coupling operation is combined with the output reflectance map. After a convolutional operation, the final illumination map is obtained.
The loss function of the image decomposition module is designed as
, defined by Equation (1):
In the equation,
and
are the coefficients balancing the consistency of the reflectance map and the smoothness of the illumination map.
represents the reconstruction loss, ensuring the consistency between the decomposed reflectance map and the reconstructed image with the illumination map.
denotes the loss function for the similarity reconstruction of the reflectance map, guaranteeing the consistency between the reflectance components of the low-light and normal-light images.
represents the smoothness loss function for the illumination map. By solving the gradients of the reflectance components, the weights of the illumination map’s gradient map are allocated. This ensures that the smooth regions in the reflectance component correspond to the smooth regions in the illumination component, preserving the integrity of texture details and boundary information while achieving smoothness constraints. The mathematical formulas for
,
, and
are given as:
In the calculations, represents the image under low-light conditions, while represents the reference image under normal lighting conditions. and denote the decomposed reflectance map and illumination map obtained from the low-light image, respectively. Similarly, and represent the output reflectance map and illumination map from the decomposition module under normal lighting conditions. represents the adoption of the loss and represents the adoption of the loss. represents the gradients in the horizontal and vertical directions and represents the coefficient balancing the strength of structural perception.
2.2. Illumination Map Enhancement Network
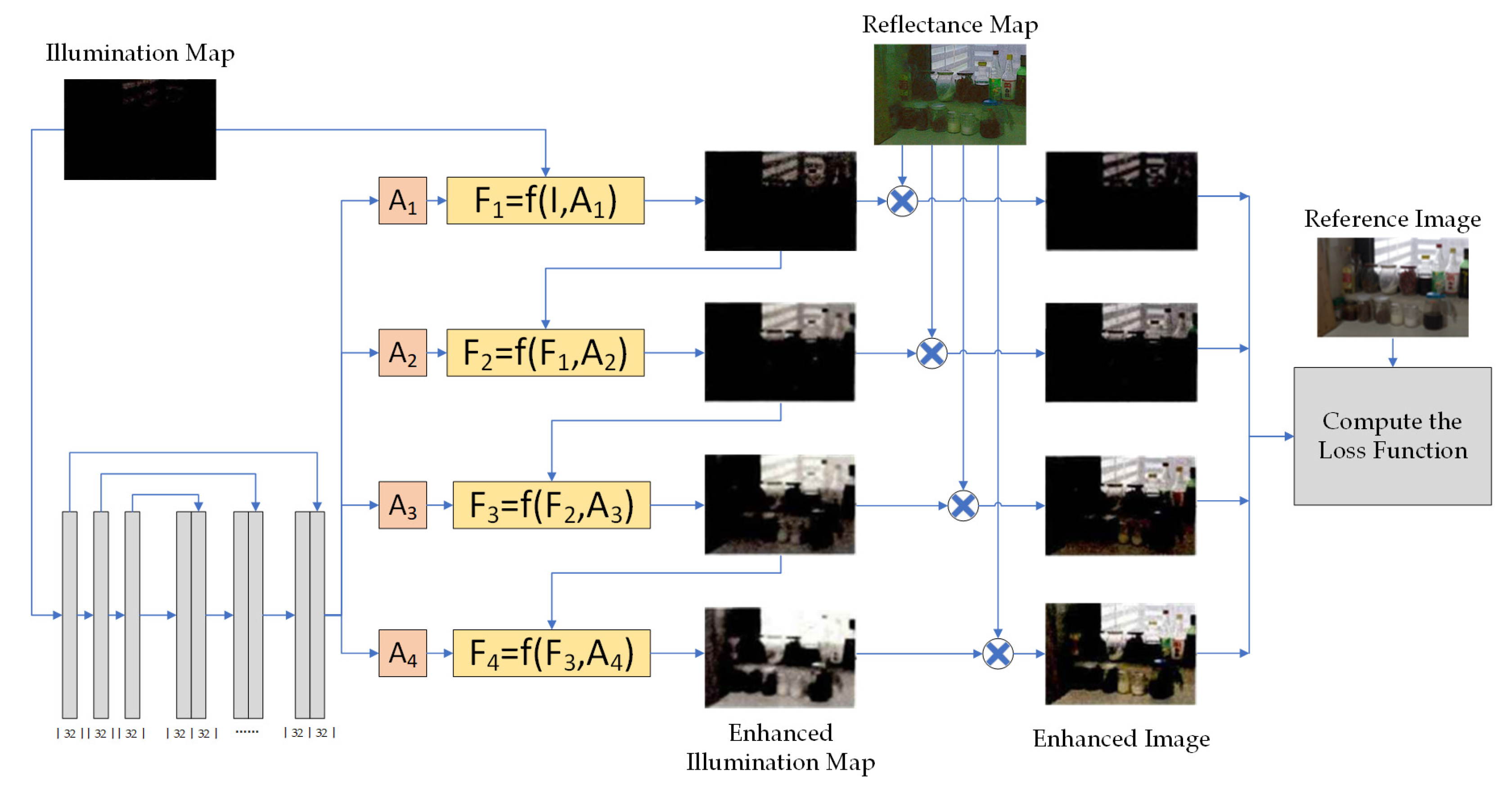
The input low-light image undergoes processing by the image decomposition network, resulting in decomposition into a smoother illumination map and reflectance map. The purpose of the illumination map enhancement network module is to enhance the decomposed illumination map. This module achieves enhancement by employing a suitable set of mapping functions for iterative enhancement of the illumination map. After the low-light input image is enhanced by the mapping functions, it significantly improves the image’s contrast and brightness while preserving details in the bright areas. Each iteratively enhanced illumination map is fused with the reflectance map to obtain a preliminary enhanced image. By computing the loss function, the preliminary enhanced image is compared and analyzed against the reference image to continually adjust experimental parameters and achieve better enhancement results.
Figure 3 presents the network structure of the illumination map enhancement module, where
represents the illumination map,
represents the relevant parameters of the mapping functions, and
represents the mapping functions.
In the process of enhancing the illumination map, selecting an appropriate mapping function to map the input image effectively improves the image’s contrast. The mapping function employed by this module is defined by Equation (5):
Here,
represents the illumination map and
denotes the entire mapping process of the curve,
. As shown in Equation (6), iteratively applying the function multiple times enhances the curve’s expressive capacity.
In the field of image processing, computers treat images as matrices for calculations. Hence, we can derive Equation (7):
In Equation (7), represents the illumination map, represents the relevant parameters of the adaptive curve, represents the mapping process, and represents the number of mappings.
The illumination map enhancement module employs a composite form of the loss function
. By adjusting the parameters of the mapping curve, the enhancement effect of the network is continually improved. The specific form of the loss function is given by Equation (8):
where
represents the number of image pixels,
represents the number of mappings,
represents the illumination map,
represents the reflectance map,
represents the reference image under normal lighting conditions, and
represents the process of mapping the illumination map.
2.3. Color Restoration Network
The low-light image enhancement algorithms based on Retinex theory often overlook color correction and noise removal. Therefore, this paper proposes a color restoration network module based on the 3D LUT theory.
Figure 4 illustrates the network architecture of the color restoration module. The input image on the left side of the network is the preliminary experimental result enhanced by the preceding two modules. The CNN weight predictor generates the corresponding weight values. The input image is then processed through weighted fusion and 3D LUT to achieve color restoration. The output image is compared with the reference image to compute the loss function and optimize the network parameters, continuously improving the color restoration performance of the network.
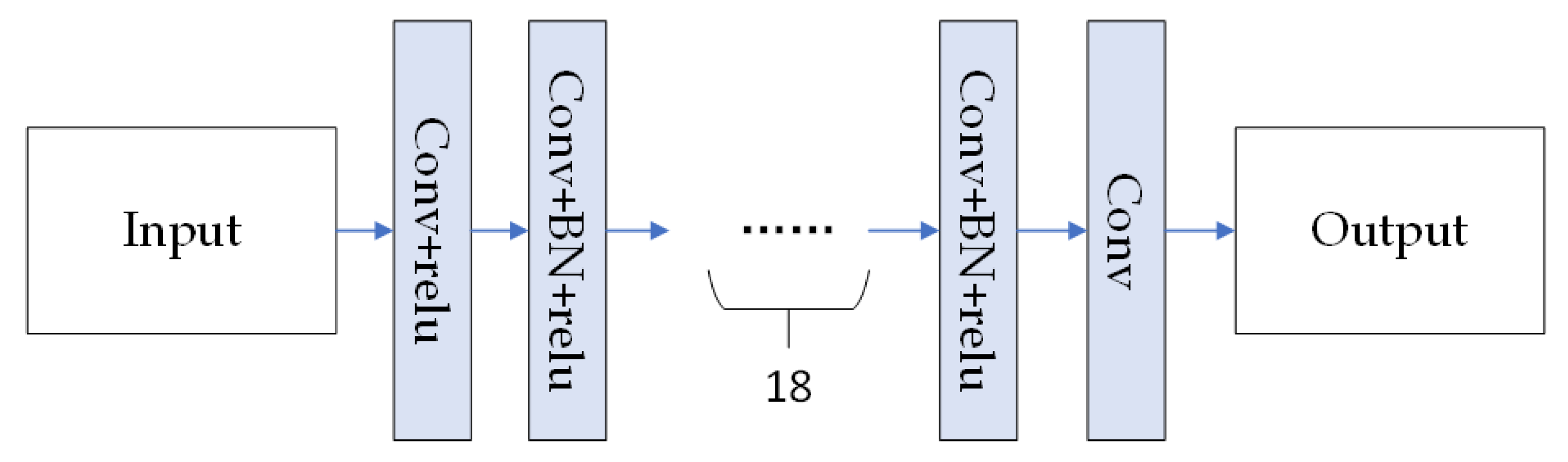
The low-light images, after being processed by the image decomposition network, are decomposed into illumination maps and reflectance maps. However, the reflectance maps often contain complex noise. To address this issue, a denoising network is incorporated into the module. By learning the noise patterns in the input images, the network aims to preserve the details while effectively removing the noise.
Figure 5 illustrates the structure of the denoising network.
After the enhancement by the color restoration module, the input image is compared with the reference image to calculate the loss, aiming to improve the module’s enhancement effect. The color restoration network module adopts a loss function denoted as
and given by Equation (9):
In the equation, represents the number of pixels, represents the preliminary enhanced result after the illumination enhancement module, represents the output image after the color restoration module, and represents the reference image under normal lighting conditions.
4. Results
4.1. Ablation Experiments
In this study, ablation experiments were conducted on the light enhancement network, color restoration network, and denoising network to analyze the impact of these three modules on the network’s enhancement performance. The experimental results are presented in
Figure 6 for comparison and analysis.
The function of the illumination enhancement module is to iteratively enhance the decomposed light map. The absence of this module would result in decreased image contrast and brightness. The denoising module aims to remove image noise while preserving as much detail as possible. The absence of this module would lead to noticeable noise artifacts and overall degraded image quality. The color restoration module is responsible for restoring the image colors. Without this module, there would be significant color deviations between the output image and the reference image. From the results of the ablation experiments, it is evident that each module plays a distinct role in enhancing the algorithm’s performance. The absence of any module would significantly deteriorate the quality of the output image.
4.2. Subjective Experiment
To demonstrate the effectiveness of the algorithm model, this paper selected 100 images from the low-light dataset as the test set, ensuring that these images did not appear in the training set. The enhanced results were compared with the enhancement effects of algorithms such as CLAHE [
22], LR3M [
23], DeepUPE [
24], Zero-DCE [
25], LIME [
26], RetinexNet, MSRCR, EnlightenGAN, and the algorithm proposed by Zhang et al. [
27]. The subjective experimental results are shown in
Figure 7 for comparison:
The experimental results indicate that the adaptive histogram equalization algorithm, CLAHE, which enhances images by limiting contrast, has limited effectiveness for low-light image enhancement. The LR3M algorithm, which enhances images based on illumination estimation, also fails to effectively improve the brightness and contrast of the images. DeepUPE, a deep learning-based algorithm for illumination estimation, exhibits poor overall enhancement in brightness and contrast, making it difficult to discern content in certain areas, which hinders overall image interpretation. The Zero-DCE algorithm controls image exposure using a loss function, which improves the overall brightness and contrast of the images but still results in numerous dark areas. The LIME algorithm, which achieves enhancement through illumination estimation, reduces the extent of dark areas but fails to address the significant noise issues present in the images. The enhanced results of the RetinexNet algorithm appear blurred, making it difficult to extract detailed information. Although the algorithm proposed by Zhang et al. further improves the brightness of the images, it still suffers from excessive noise, and the enhanced images exhibit color distortion. The MSRCR algorithm, which includes a color restoration module, mitigates color distortion to some extent but introduces severe noise problems and significant loss of detail information. The EnlightenGAN algorithm based on generative adversarial networks overcomes the dependency on paired low-light/normal-light image datasets and achieves overall impressive enhancement results. However, it exhibits less noticeable enhancement in extremely dark areas, resulting in less clarity in the details of such regions. In comparison to the aforementioned algorithms, the proposed low-light image enhancement algorithm in this paper effectively accomplishes the enhancement task. It enhances image brightness and contrast while suppressing color distortion and noise. The enhanced images have moderate brightness and clear details, resulting in favorable subjective visual effects.
4.3. Objective Experiment
In order to comprehensively analyze the image quality enhancement achieved by different algorithms, this study has chosen to employ three image quality evaluation metrics: Peak Signal-to-Noise Ratio (PSNR), Structural Similarity Index (SSIM), and Natural Image Quality Evaluator (NIQE).
PSNR quantifies the level of distortion between the original and reconstructed images by calculating the ratio of peak signal power to mean squared error. A higher PSNR value indicates lower distortion in the enhanced image, signifying superior algorithmic enhancement effectiveness and greater proximity to the reference image. While it excels in measuring pixel-level discrepancies in image comparison, its ability to assess image structural information is limited. To overcome the limitations of PSNR, SSIM has been referenced. This metric evaluates the reconstructed image from three aspects: luminance, contrast, and structural information. It measures the degree of similarity between the enhanced image and the reference image under normal lighting conditions, thereby demonstrating the algorithm’s performance. Generally, higher SSIM values indicate greater similarity to the reference image and improved enhancement outcomes. In tasks involving image decomposition and reconstruction, instances arise where some images exhibit higher PSNR or SSIM values but possess overall quality deviations. This discrepancy is due to the fact that images with high PSNR or SSIM values may not necessarily conform to human visual perception of texture details. To address this, the NIQE image quality assessment metric was also employed. NIQE considers factors such as noise and distortion, simulating the relationship between image quality features and perceived distortion to emulate the human visual system’s perception of image quality. Smaller output values from NIQE indicate higher quality in reconstructed images.
Objective evaluation results of various algorithms on the low-light dataset are presented in
Table 1. From the table, it is evident that the algorithm proposed in this paper achieves the best results across all three metrics.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}