1. Introduction
Air pollution is a concerning global issue, with approximately 1.3 million annual deaths attributed to it, according to the World Health Organization (WHO) [
1]. Air quality assessment plays a vital role in monitoring and managing pollution levels. WHO data reveal that air pollution exceeding the recommended limits affects nearly the entire global population (99%), with a significant impact in low- and middle-income countries. It is crucial to anticipate and prepare for fluctuations in pollution levels to effectively mitigate the adverse effects of air pollution. Improving air quality not only enhances public health but also contributes to mitigating climate change, as air quality is closely interconnected with our planet’s climate and the health of its ecosystems. By reducing air pollution, we can alleviate the burden of diseases associated with air pollution and make long-term contributions to climate change mitigation efforts.
Since 2005, the Common Air Quality Index (CAQI) has been employed in Europe as a comprehensive and standardized metric to evaluate and communicate air quality levels to the general public [
2]. It provides a simplified and easily understandable representation of air pollution levels, making it easier for individuals to make informed decisions regarding their health and well-being. The CAQI is based on the measurement of several air pollutants that are known to have detrimental effects on human health, including particulate matter (
PM2.5 and
PM10), nitrogen dioxide (
NO2), ozone (
O3), carbon monoxide (
CO), and sulfur dioxide (
SO2) [
3]. These pollutants are commonly monitored by air quality monitoring stations located in various regions. The CAQI is designed to provide a numerical value or color-coded scale that corresponds to the air quality level.
Typically, the CAQI scale ranges from 0 to 100 and it is divided into several categories, such as very low, low, medium, high, and very high [
4], and the visual color scale is presented from green to red. To calculate the CAQI value, individual pollutant concentrations are first converted into indexes using predefined equations that are based on value interpolation. These indexes are then combined, weighted, and transformed into a single CAQI value. The weighting factors assigned to each pollutant are determined based on their relative health impacts.
The CAQI is a valuable tool in terms of raising awareness about air pollution and its potential health risks. It enables policymakers, environmental agencies, and the general public to monitor and address air quality issues effectively. Additionally, the CAQI facilitates the comparison of air quality between different locations and allows for long-term trend analysis, aiding in the formulation of targeted strategies for air pollution control and mitigation.
The advancement of machine learning (ML) techniques, including deep learning, has opened up new opportunities to enhance air quality research [
5]. Among these techniques, the Support Vector Machine (SVM) has demonstrated promising outcomes in diverse domains. As a supervised learning algorithm, SVM is designed in the manner that it can identify optimal hyperplanes to enable the formation of data classes. In the context of air pollution prediction, SVM can learn complex patterns and relationships from historical pollution data and meteorological variables [
6]. On the other hand, LSTM represents a type of recurrent neural network known for its effectiveness in modeling sequential data [
7]. It can capture long-term dependencies and temporal patterns, making it suitable for time series forecasting tasks such as air pollution prediction.
The hybridization of ML algorithms with other techniques yields good results, especially when it comes to metaheuristic algorithms. Hybridization allows the faster convergence of algorithms and increases the prediction accuracy of ML algorithms. There is a wide range of metaheuristic algorithms [
8] and one of the most commonly used is the Genetic Algorithm (GA), which is inspired by the process of natural selection [
9]. It can effectively search for optimal or suboptimal solutions in a large solution space.
Bagging is an ensemble learning technique that enhances predictions by consolidating multiple models trained on diverse subsets of data. By aggregating the predictions of individual models, bagging reduces overfitting and increases the stability and robustness of the algorithms. It helps to capture different patterns and relationships present in the data, increasing the model’s overall performance by enhancing accuracy, handling data noise, and increasing robustness [
10].
This paper focuses on the development of an advanced hourly CAQI prediction model through the hybridization of metaheuristics, ML algorithms, and ensemble learning techniques. More precisely, three different techniques are combined: GA, the LSTM algorithm, and a bagging approach. To our knowledge, this combination of techniques has not been applied yet to air pollution analysis in Montenegro. Regarding the numerical results, a comparison with standard ML prediction algorithms (SVM) is made. Our results show that the proposed hybrid model significantly outperforms the SVM model in terms of accuracy and convergence.
2. Related Work
Recent studies have been focusing on sophisticated learning algorithms to enhance air quality evaluation and air pollution prediction. Drewil and Al-Bahadili [
11] used the LSTM model in conjunction with GA to enhance the performance of air prediction models. The performance of the GA-LSTM model was evaluated and compared with models employing manual criteria. The results showed a significant improvement in LSTM performance with the integration of GA. Waseem et al. [
12] chose to perform only
PM2.5 forecasting by applying deep learning techniques, among which the LSTM encoder–decoder variant showed promising results. In another study, Xayasouk et al. [
13] examined the methods of predicting PM levels and showed that LSTM combined with deep autoencoder techniques showed slightly better performance than the typical LSTM model.
Triana and Osowski [
14] employed bagging and boosting techniques for PM prediction. Their experiments demonstrated significant improvements in result quality when using bagging and boosting ensembles with weak predictors. The Mean Absolute Error was reduced by more than 30% for
PM10 and 20% for
PM2.5 compared to individual predictors. Liang et al. [
15] developed multiple ML models, including adaptive boosting (AdaBoost), an artificial neural network (ANN), random forest (RF), a stacking ensemble, and SVM, for the prediction of air quality index levels over different time intervals (1 h, 8 h, and 24 h). The stacking ensemble, AdaBoost, and RF models showed the best prediction performance, although their forecasting accuracy varied across geographical regions. Madhuri et al. [
16] used linear regression, SVM, decision tree, and RF models for air quality prediction. The RF model achieved the highest accuracy among the tested algorithms. Kumar and Pande [
17] applied five different ML models to predict air quality. The authors showed that the strongest correlation between predicted and actual data was achieved by the XGBoost model. Sanjeev [
18] conducted a study where a few standard classification models were applied to a dataset that included pollutant concentrations and meteorological data. Due to its robustness against overfitting, the RF classifier demonstrated superior performance compared to other classifiers.
In their review, Rybarczyk and Zalakeviciute [
19] examined a collection of 46 highly relevant journal papers. The authors found that there were more studies focused on pollutants such as
O3,
NO2,
PM10, and
PM2.5, while fewer studies covered CAQI prediction. We refer interested readers to a comprehensive review [
20] of 155 papers that provides a detailed analysis of air quality prediction using ML techniques.
3. Implementation Methodology
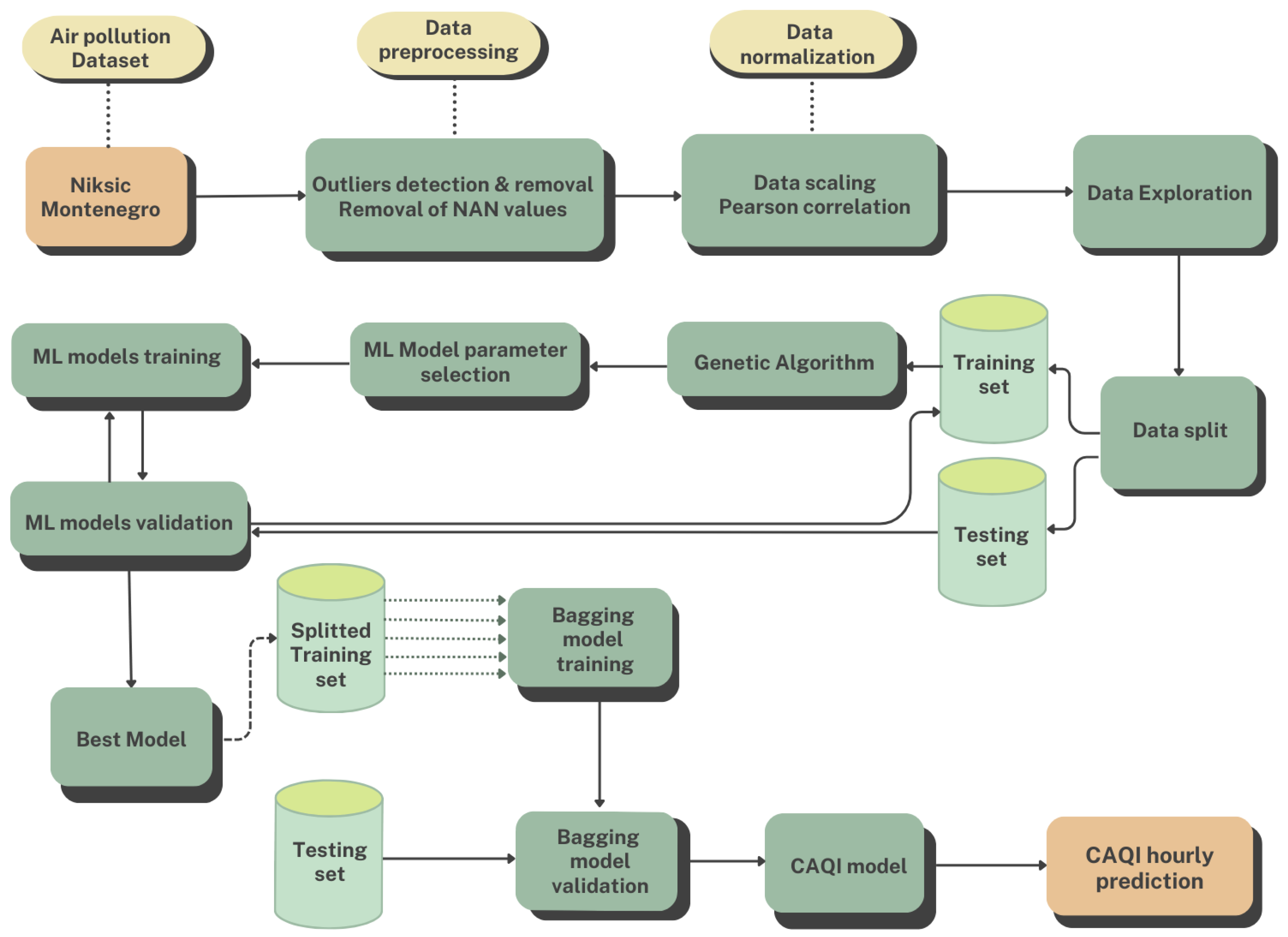
This paper focuses on the hybridization of multiple algorithms. To develop our hybrid model, the Python libraries Keras and Scikit-Learn and their modules
and
were used, as well as the necessary functions and algorithms contained in these modules. A comprehensive description of the proposed system architecture is represented in
Figure 1. The various phases employed to obtain hourly air pollution predictions in Niksic, Montenegro are presented. The first step involves collecting air quality data from an air monitoring station. The collected data undergo preprocessing and feature engineering procedures to ensure better training and testing results. After this, the data are partitioned, scaled, and fed into the proposed hybrid LSTM model for further analysis and prediction. In order to enhance the performance of the LSTM model, a GA is employed for parameter selection. This hybridization with the metaheuristic algorithm helps to find the best combination of hyperparameters for LSTM, resulting in the improved predictive capabilities of the model. The bagging technique is applied to the best-performing LSTM model. This approach involves training multiple instances of the LSTM model on distinct subsets of the data and combining their predictions, leading to improved overall accuracy and robustness. Based on its predictive performance, the implemented hybrid LSTM model is thoroughly tested and compared with the SVM approach. These two final models are evaluated and analyzed to provide insights into their suitability for air quality prediction.
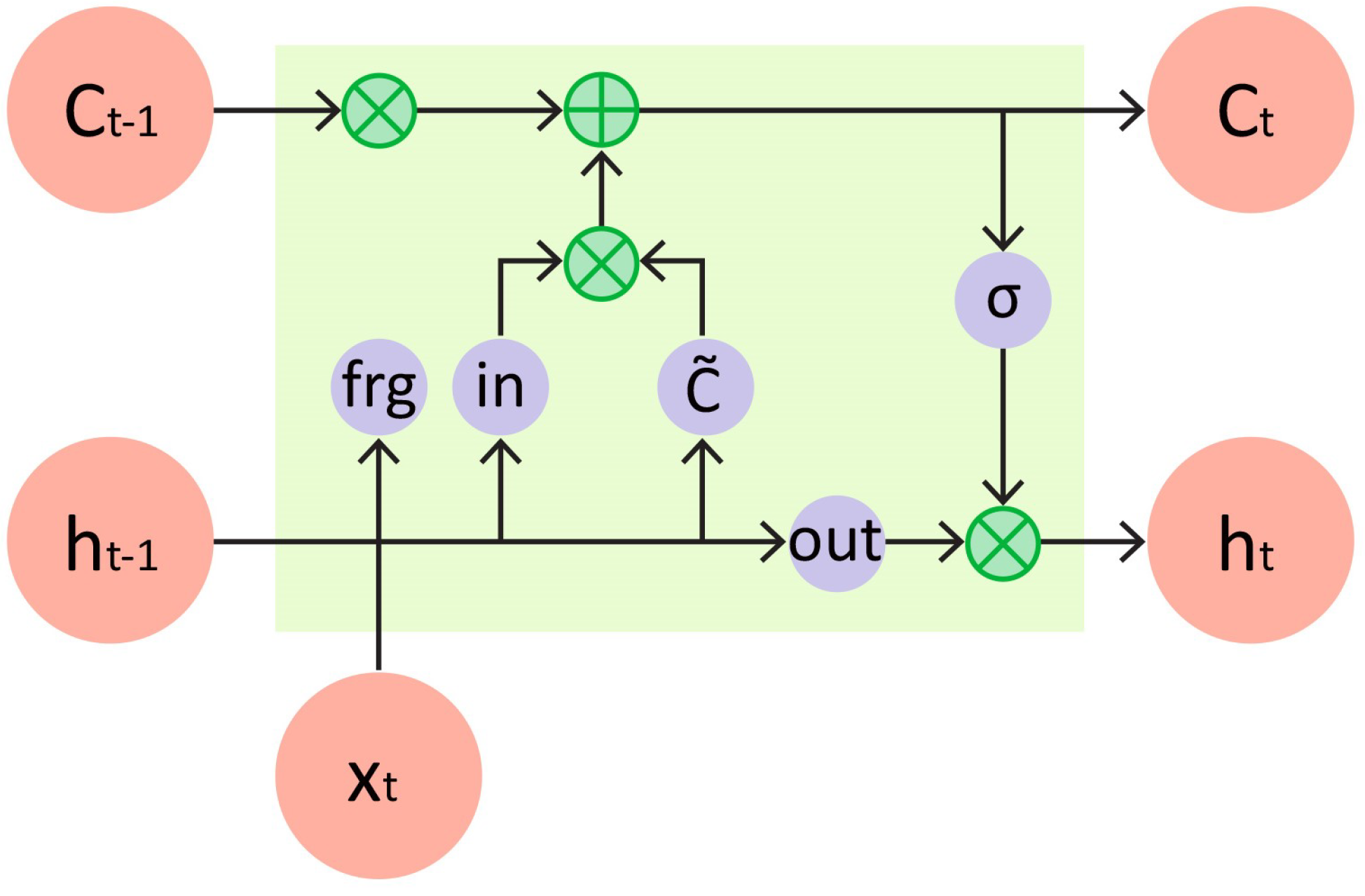
The LSTM algorithm is a type of RNN architecture specifically designed to handle sequential data and effectively capture long-term dependencies [
21]. LSTM networks use specialized memory cells and gates to effectively manage and control the flow of information at various time steps. This enables them to effectively model and retain important patterns and dependencies in the input data. The LSTM algorithm addresses the vanishing gradient problem that occurs in RNN algorithms, where gradients become too small to update weights effectively over long sequences. By using memory cells and gates, LSTM allows gradients to flow through time more easily.
Figure 2 illustrates the architecture of the LSTM unit, while the corresponding Equations (
1)–(
6) for the LSTM algorithm are provided below:
where the input gate (
), forget gate (
), and output gate (
) are controlled by the weights (
,
,
) connecting them to the input. The weights (
,
,
) connect the input, forget, and output gates to the hidden layer. The bias vectors (
,
,
) are associated with the input, forget, and output gates, respectively. The state of the cell at the previous time point is denoted by
and the current state of the cell by
. The outputs of the cell at the previous and current time points are denoted by
and
, respectively [
22].
The GA is an evolutionary-based metaheuristic algorithm that employs the principles of natural adaptation and selective breeding [
8]. It operates on a population of individuals, where each individual represents a potential solution to a specific problem. These individuals are characterized by a genetic code, which is a sequence of characters (genes) from some alphabet. By decoding each individual and assessing its fitness value, the algorithm determines the quality of solutions within the population. Through iterative processes of selection, crossover, and mutation, the GA seeks to optimize the solutions until a specific stopping criterion is met. This criterion can be a fixed number of generations or a condition where the algorithm terminates if there is no improvement in the best individual over a defined number of generations.
The SVM algorithm belongs to the class of well-known supervised ML algorithms. It shows good performance when it is required to fit functions to the training data and at the same time to minimize produced errors. To handle the demanding relationships between the input features and the target variable, and to ensure the detection of linear decision boundaries, SVM incorporates kernel functions, allowing the mapping of the input data into a multidimensional feature space. The optimization process in SVM involves minimizing the loss function, which consists of a margin violation error and a regularization term [
23]. The regularization term maintains a trade-off between the complexity of the model and the training error, thus mitigating the risk of overfitting. The SVM function is defined by Equation (
7):
where
describes the non-linear mapping function,
represents the input vector, and
represents the corresponding target value. The values
v and
are the weight factor and bias, respectively [
24]. The estimation of the parameters
w and
b is achieved through the minimization of the regularized risk function
, as denoted by Equation (
8):
The regularization term
balances the trade-off between the empirical risk and model flatness. The penalty coefficient
P determines the extent of this trade-off. The
e-insensitive loss function
is defined by Equation (
9) and is used to handle errors within a tolerance level
e:
If the predicted value falls within the threshold, its contribution to the loss function will be ignored. However, if the predicted value exceeds the threshold, the loss function will take on a value greater than
e. To measure the distance between the actual values and the corresponding boundary values of the
e-tube, two positive slack variables,
and
, are introduced. This transformation results in the constrained form of Equation (
8),
subject to
The Lagrangian function, defined by Equation (
11), is used to solve the previously defined optimization problem (
10),
subject to
Equation (
12) describes the method of calculating the regression function
,
where the Lagrangian multipliers satisfy the constraints
and
. The kernel function
allows for the non-linear mapping of the original data into a higher-dimensional feature space.
3.1. Data Collection and Preprocessing
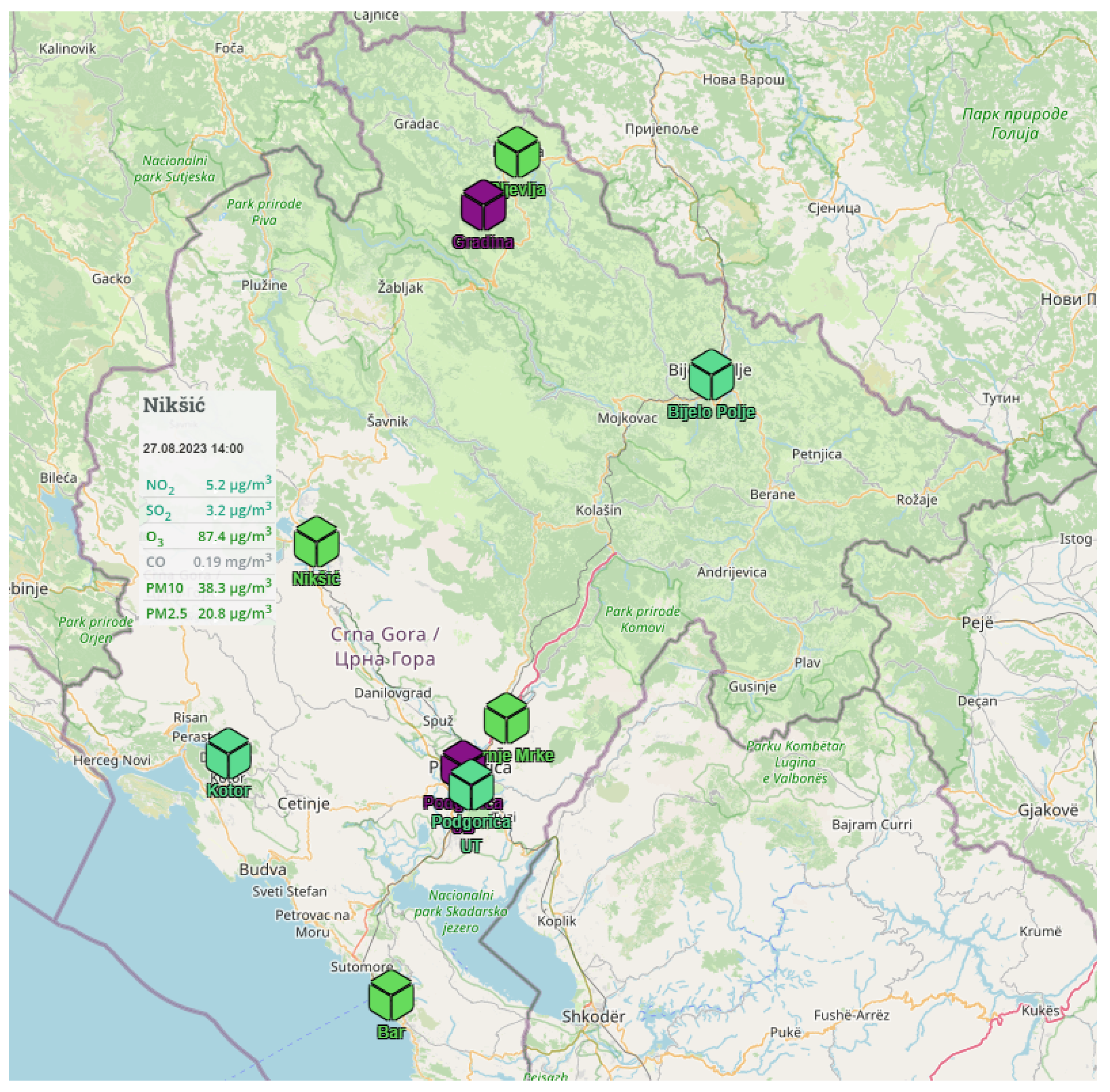
In the analysis described in this paper, data were provided by the Environmental Protection Agency (EPA) of Montenegro. The data were collected from the air quality monitoring station located in Niksic, Montenegro and are freely downloadable from the EPA website [
25]. There are 9 monitoring stations in Montenegro, located in Podgorica UT, Podgorica UB, Niksic, Bar, Pljevlja, Bijelo Polje, Kotor, Gornje Mrke, and Gradina, as shown in
Figure 3. The focus of the analysis was Niksic, since this town is recognized as one of Montenegro’s urban areas that consistently experiences high pollution levels throughout the year. Our selection was additionally guided by the fact that the datasets obtained from air monitoring stations in other cities in Montenegro were either incomplete or insufficient for our analysis. The air pollutant data from Niksic were recorded from 21 August 2019 until 17 December 2022, and consisted of hourly values of
,
,
,
,
, and
.
In general, data collected from monitoring stations, sensors, and other sources cannot be readily utilized for analysis without undergoing necessary preparatory steps. The raw data often contain inconsistencies, outliers, missing values, and other imperfections that need to be addressed. To ensure the accuracy and reliability of subsequent analyses and predictions of our model, multiple preprocessing techniques, including data cleaning, data scaling, and the removal of NAN values, were applied to the collected data. Invalid data (missing data) were simply ignored. To unify data on a common scale, we used a MinMax scaler. It works by transforming each feature independently, maintaining the relationships between the features while ensuring that they all fall within the interval
. For each feature value
x, the scaled value
is calculated using Equation (
13):
The initial dataset had values, which was reduced to after missing data elimination. With the outlier detection and removal, the dataset was additionally reduced to values. As with other ML techniques, our approach also requires a phase of training and testing. The final dataset of values, which is the number of continuous 24 h time series, was divided into training and testing datasets, with () and 4218 () data values, respectively.
3.2. Feature Engineering
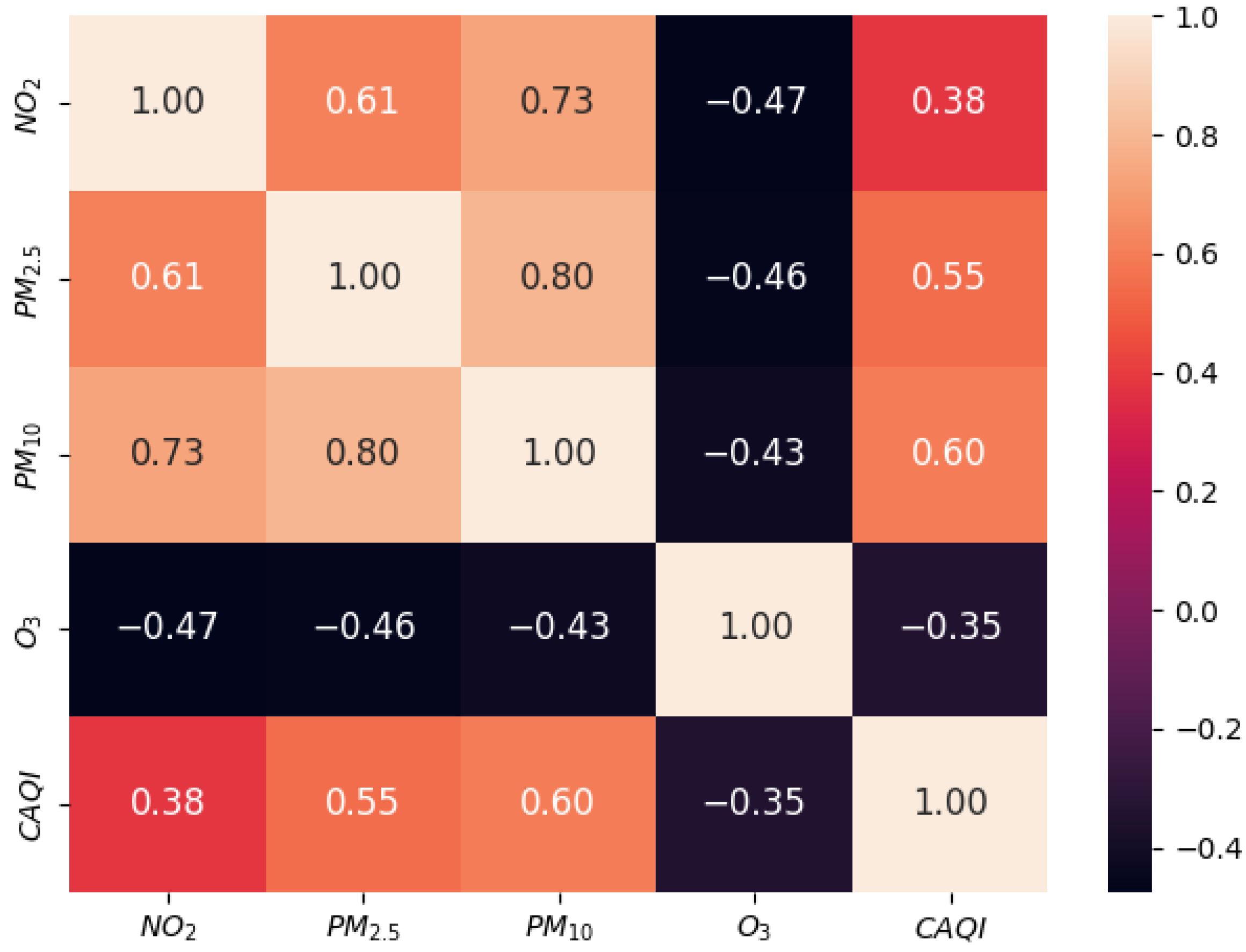
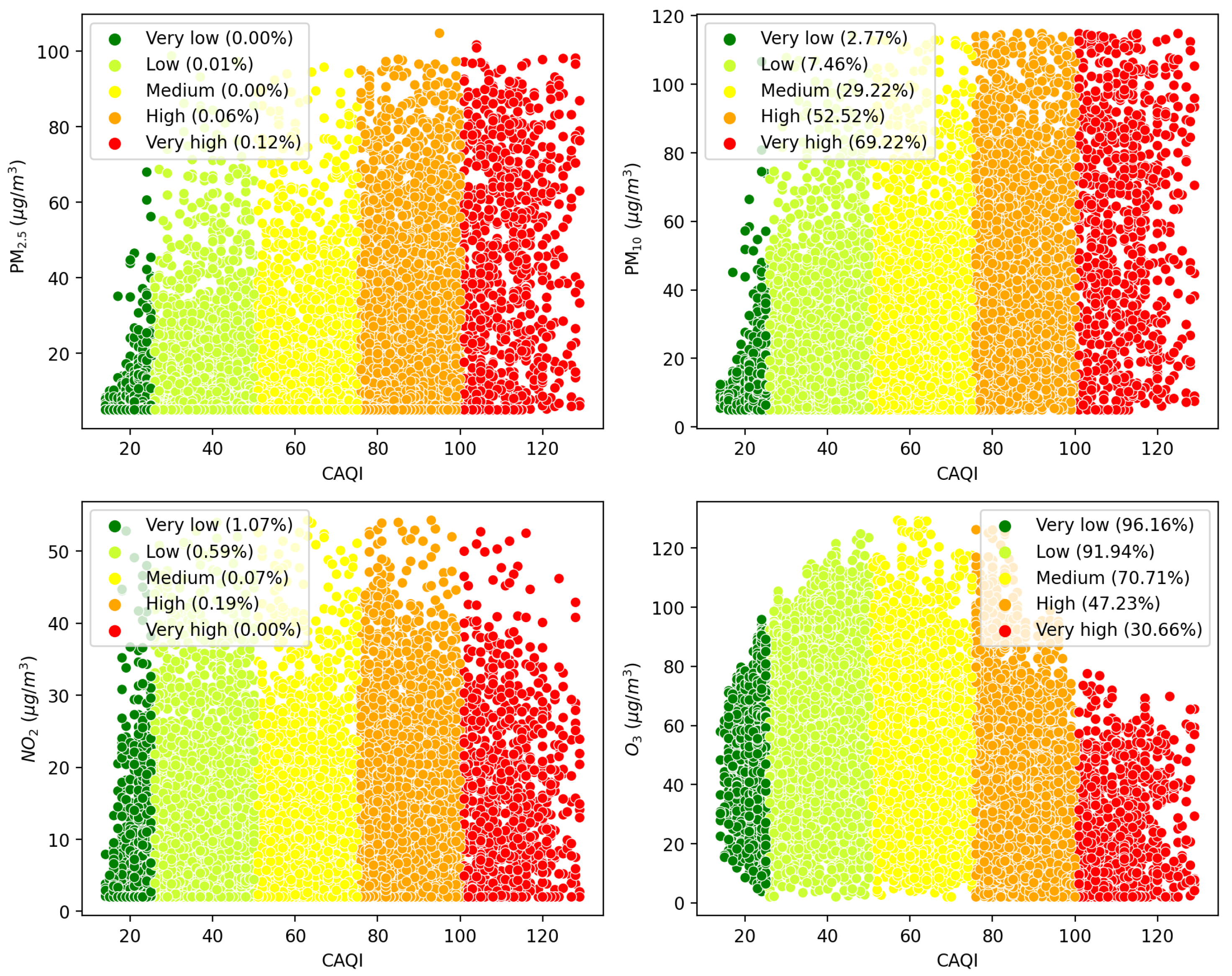
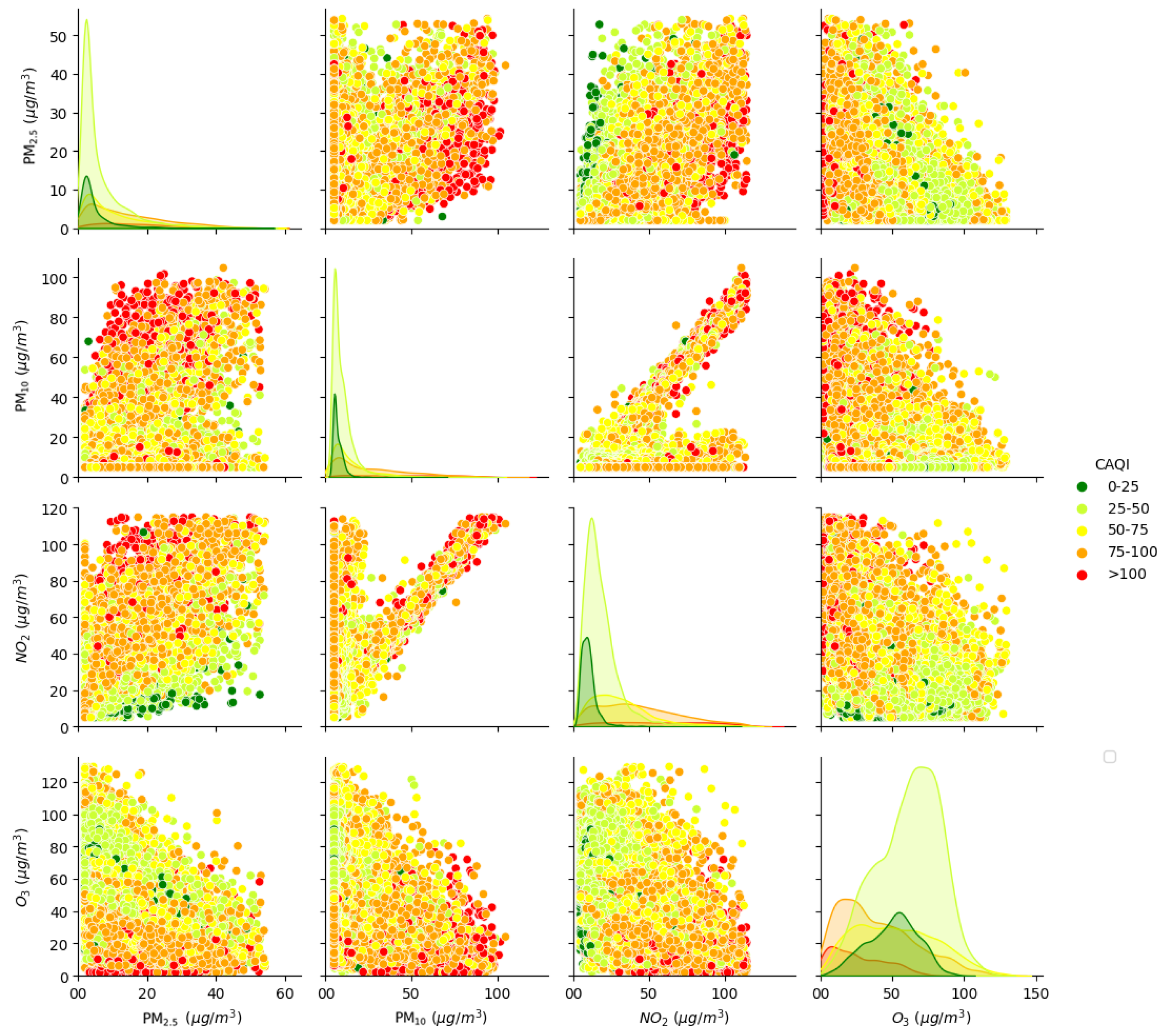
The CAQI value is based on the measurement of several air pollutants:
,
,
,
,
, and
. It provides a numerical value or color-coded scale that corresponds to the air quality level, i.e., very low, low, medium, high, and very high, as shown in
Table 1.
CAQI values are not available on the Montenegro EPA website; only the specific pollutant concentration values are provided, such as , , , , , and . Based on the preliminary statistical analysis, 4 pollutants were selected: , , , and . The selected pollutants were considered to be equally harmful. Consequently, their weighted factors were set to 1. Due to the low statistical significance, and were excluded from further analysis.
The CAQI values were calculated by applying Equation (
14) to the 4 selected input parameters:
where the pollutant concentration
is mapped to pollutant index
by applying the following equation:
where
i denotes the air pollutant. Values
and
denote the minimal and maximal 1-h concentration values of the CAQI category that corresponds to the concentration of the specific pollutant, while
and
denote the minimal and maximal air quality index values of the category shown in the second column of
Table 1. The following calculations are used in our work: maximum mean hourly values for
,
(in μg/m
3) and calculated daily mean value for
,
(in μg/m
3).
In addition, based on the EPA recommendation, in order for the measurement to be considered valid, it is necessary that there are at least three measured values of the input parameters at the same time, and that among them there is at least one measured value for , , or , which we also took into account.
As an example, based on the CAQI system provided by the Montenegro EPA website [
4], if the concentration of
is
= 82.2 μg/m
3, it will fall within the concentration interval of 50 and 90 and the index interval of 50 and 75, corresponding to a moderate pollutant level. The index value
is then calculated based on Equation (
15) as follows:
It is important to note that, while one pollutant may have the highest concentration value, another pollutant could be dominant, meaning it has the highest index value. This ambiguity comes from different concentrations of certain input quantities that are considered dangerous.
3.3. Performance Evaluation
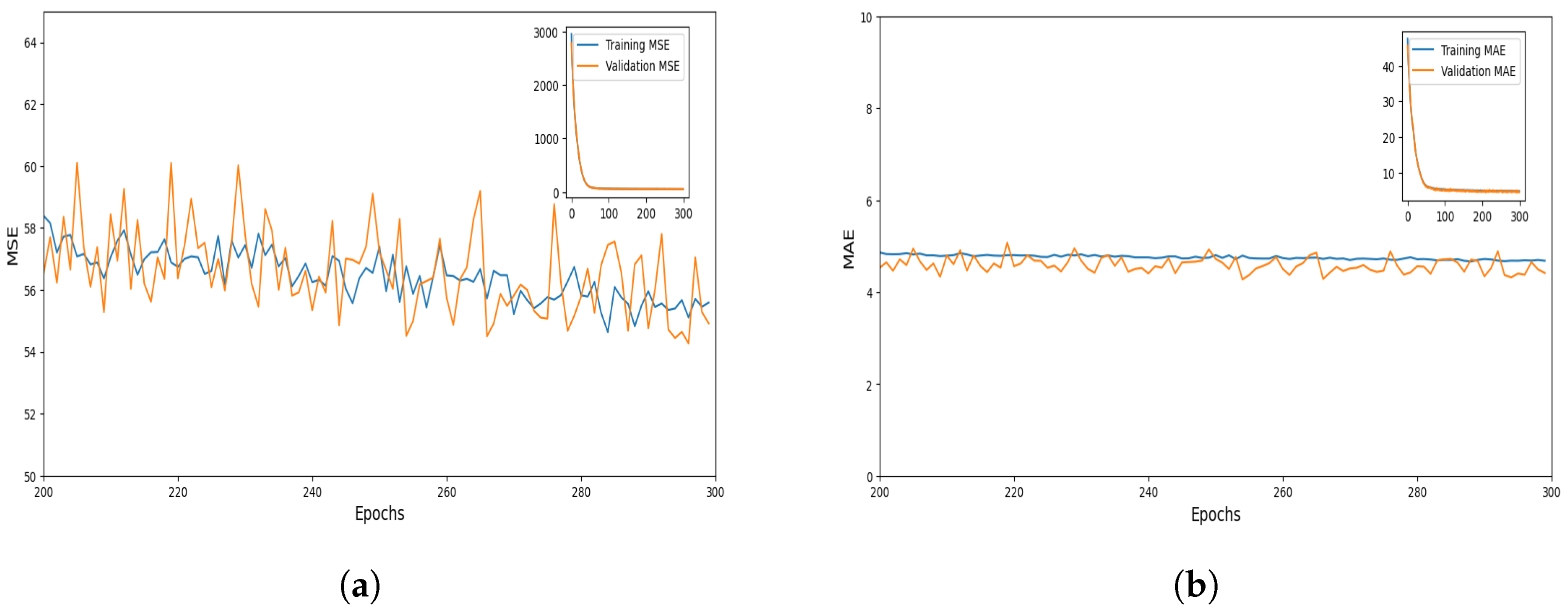
In order to provide a baseline for comparative analysis and to assess the proposed model’s performance, four standard evaluation metrics were applied: Mean Square Error (MSE), Mean Absolute Error (MAE), Mean Absolute Percentage Error (MAPE), and Coefficient of Determination .
MSE is a measure used to quantify the extent of deviation between the predicted values (
) and measured values (
). A lower MSE value indicates a smaller deviation. The MSE value is computed using Equation (
17):
MAE measures the extent of error between the predicted value and the measured value. The MAE value can be obtained by Equation (
18):
MAPE quantifies the error between the predicted and measured values as a percentage of the measured values. The MAPE value is computed based on Equation (
19):
The
measure indicates how well the air pollutant values in a regression model explain the variation in the CAQI value. It quantifies the proportion of the total variation in the CAQI values that can be accounted for by the air pollutants. The
value ranges from 0 to 1, and a higher
value indicates a better fit, meaning that a larger proportion of the variation in the CAQI values is captured by the air pollutants. The
measure is calculated as shown in Equation (
20):
where
represents the mean of the measured values and
n is the number of samples.
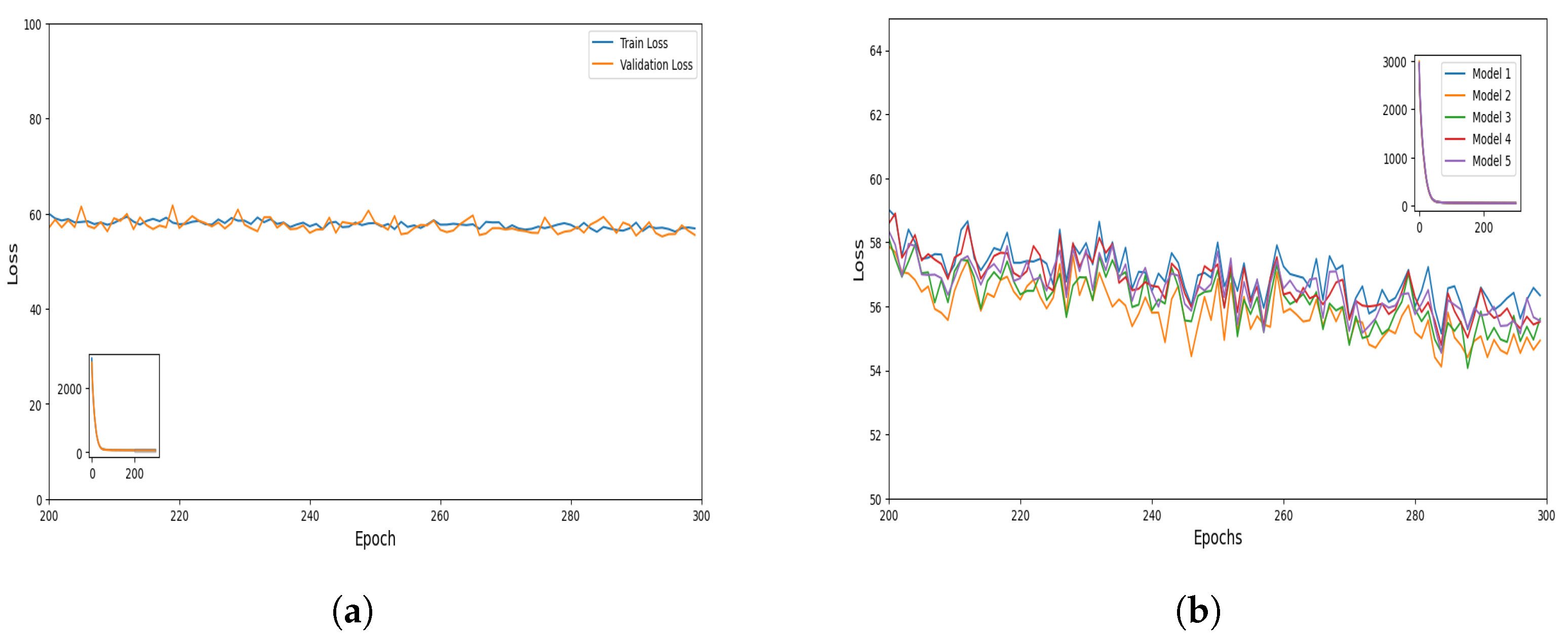
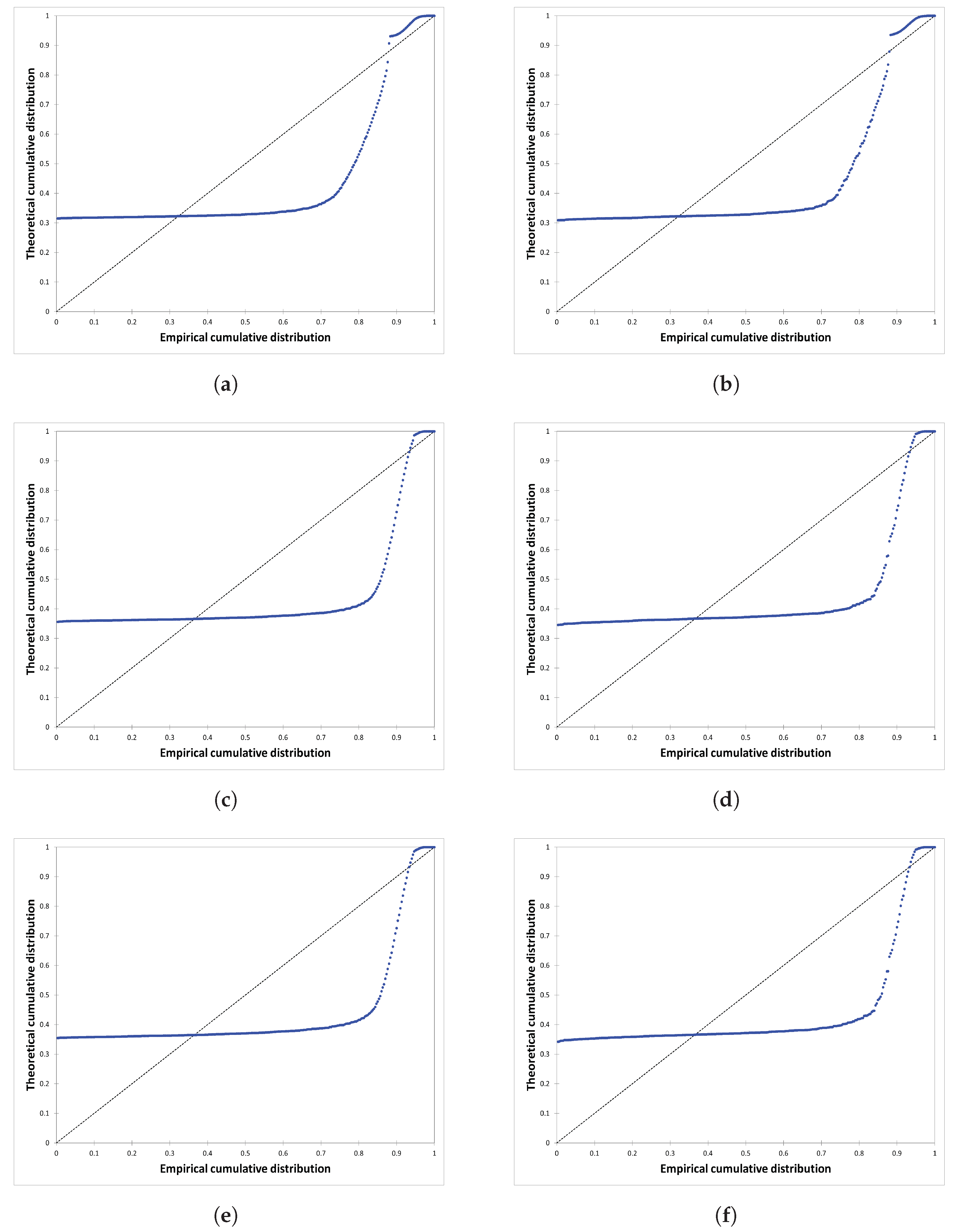
The issue of bias can arise in performance validation when the dataset is split, trained, and tested only once [
26]. This implies that the validity of the results obtained from the testing dataset may be affected when the testing subset is altered. To address this problem, each model in our work was rebuilt five times using different random subsets of training and testing samples, while maintaining a consistent splitting proportion of 75:25.
5. Conclusions
Air pollution is a global issue that affects countries and regions around the world. It has wide-ranging impacts on various aspects of the environment, public health, and the global climate system. This problem has been further aggravated due to the increase in the global population, urbanization, industrialization, and climate change. There is an urgent need to provide precise predictions of air pollution levels, which will contribute to improving public health and overall quality of life.
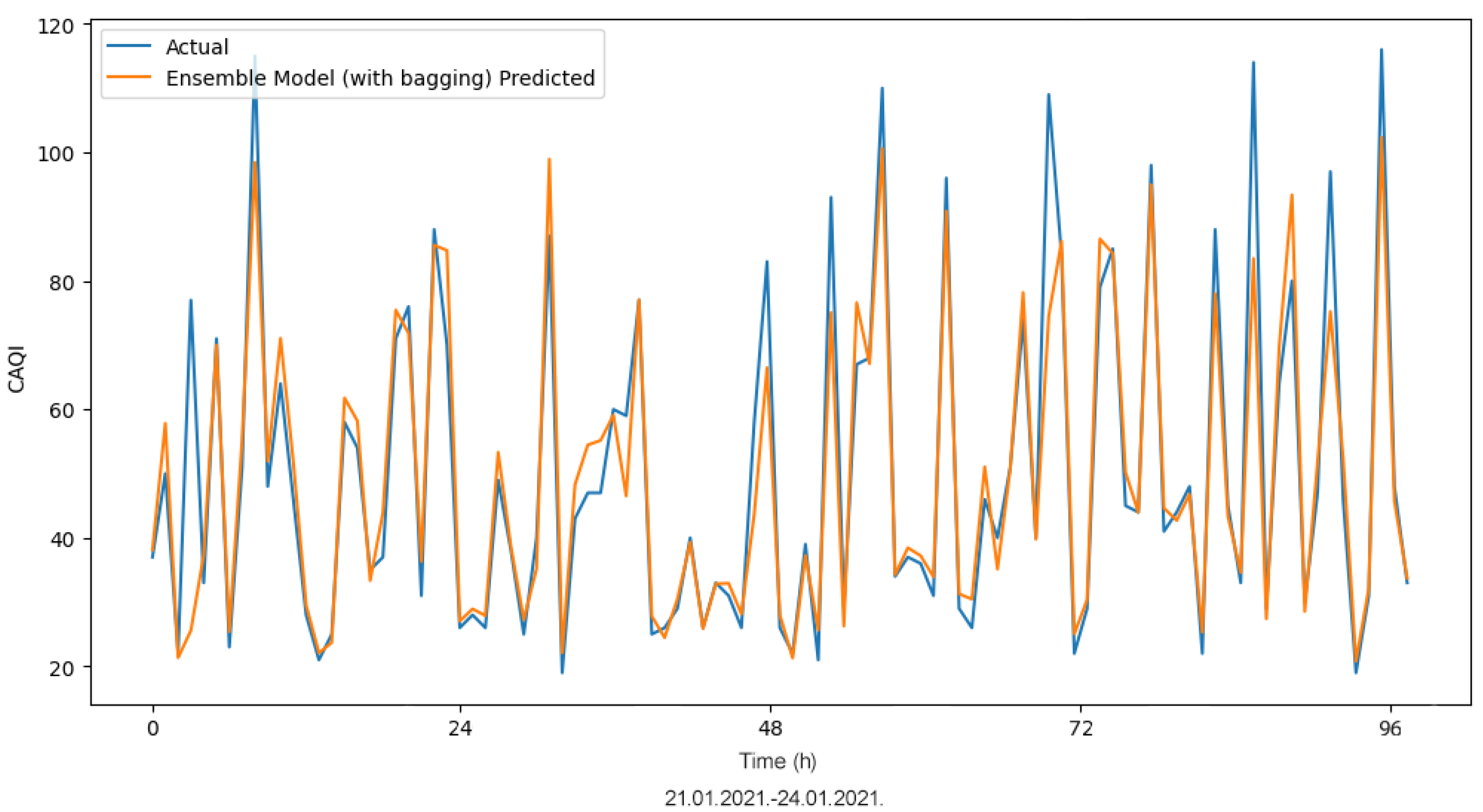
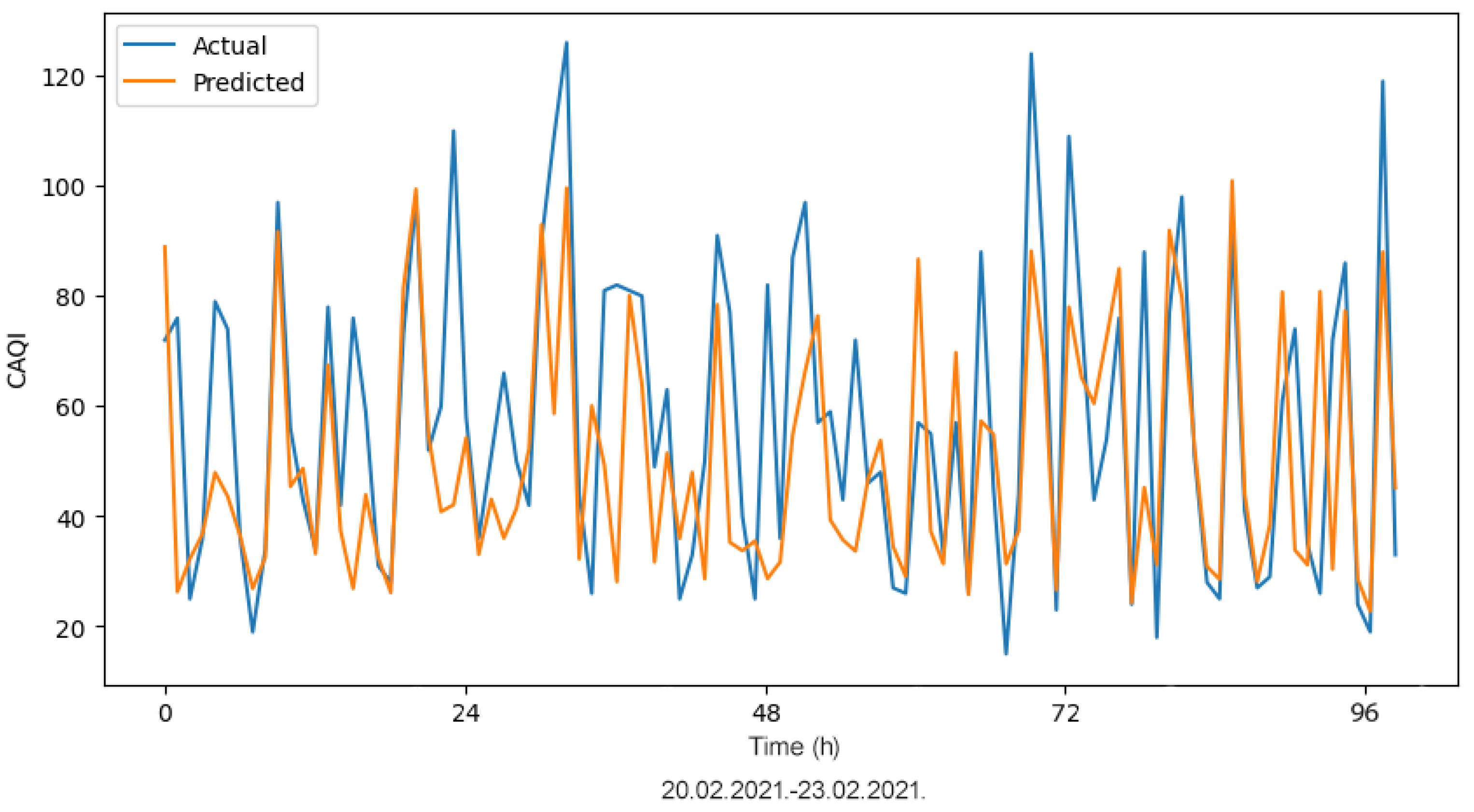
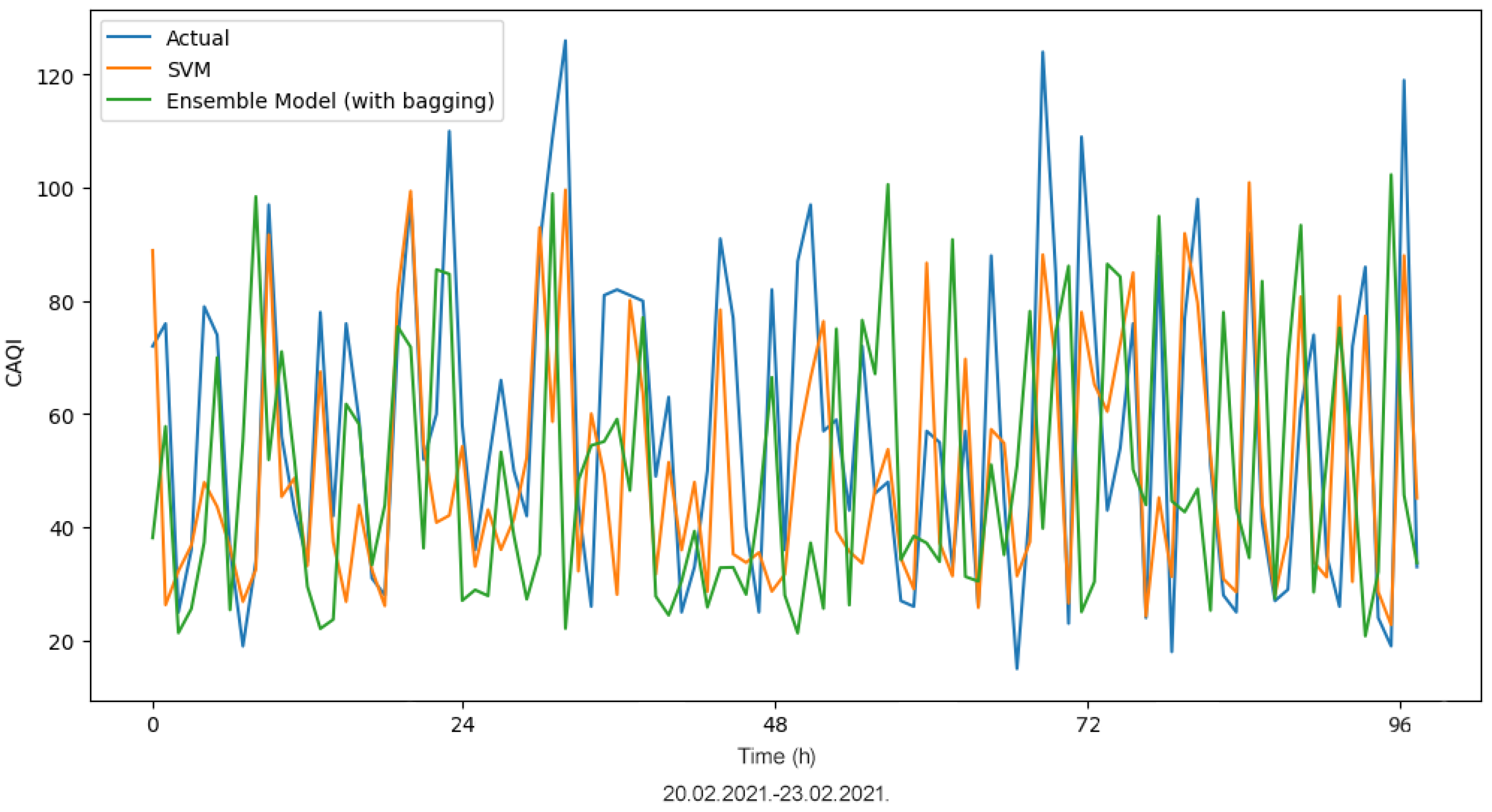
The application of ML algorithms provides promising results for CAQI prediction. The focus of this paper was to propose an advanced hybrid ML model for hourly CAQI prediction in the region of Niksic, Montenegro. The proposed hybrid LSTM model with bagging (i.e., the ensemble model) delivered significantly better performance when compared to the SVM model. A comprehensive statistical analysis was conducted on the calculated MAE values obtained from the training and testing of the LSTM model, the best LSTM model without bagging, and the ensemble model. The results showed that the ensemble model outperformed the other two compared models. This novel hybrid model can be considered as a new and superior alternative for hourly CAQI prediction. The application of such advanced ML analysis using the hybrid approach has not been previously employed in the context of air pollution in Montenegro.
Although our analysis showed that the ensemble model outperformed SVM as a technique to predict CAQI values, we draw the reader’s attention to the fact that SVM is still a promising technique that is worth considering. In particular, it has been shown in the literature that SVM is applicable to CAQI classification problems [
29] as well as to regression problems [
30], while, in some other papers [
31], as in our analysis, SVM has shown slightly worse results. It is evident that the prediction of CAQI values is an extremely complex problem and that the performance of the applied algorithms depends significantly on the characteristics of the dataset; thus, it is important to apply various ML algorithms in modeling, without a priori assumptions that some are inefficient and inapplicable.
The findings of this paper open up several possibilities for future research, such as exploring alternative optimization techniques, incorporating additional variables, considering long-term predictions, conducting comparative studies, and validating the proposed models in different regions, which could contribute to advancing the accuracy and applicability of air quality prediction models. Our future research will also explore the performance of the suggested model in the context of diverse data patterns.
In particular, the potential of other metaheuristic algorithms can be investigated, as well as the hybridization of the existing techniques with additional optimization strategies. Future research could consider incorporating additional variables such as meteorological data (temperature, humidity, wind speed) to enhance the precision and robustness of the predictive models. Predictions with larger time steps, such as 8 h and 24 h predictions, can be considered as well. Further extending the analysis to long-term predictions, such as weekly or monthly forecasts, could provide valuable insights for air quality management and policy planning. Long-term predictions can help to identify patterns, trends, and potential mitigation strategies for sustained improvements in air quality. While this paper compared the performance of the hybrid LSTM, GA, and bagging approach with the SVM model, there may be other ML algorithms or hybrid models that could be included in comparative studies. Assessing the strengths and weaknesses of different models can help to identify the most effective techniques for air pollution prediction. Finally, future works could validate the proposed hybrid model in other regions of Montenegro with varying air pollution characteristics, to assess its transferability and performance in diverse settings.
Monitoring air quality, raising awareness, and implementing effective policies are essential in safeguarding public health and preserving the environment. The proposed model can support efforts to mitigate and reduce air pollution, including the adoption of pollution control measures, the promotion of cleaner energy sources, the improvement of industrial processes, and the adoption of sustainable transportation systems.



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}