1. Introduction
Although videos are widely used in social life, they remain incomplete and indistinct in many situations. Therefore, video restoration is significant in these cases. However, no existing models can perform both video inpainting (also known as video completion or video hole filling) and super resolution (SR) synchronously. In this paper, we aim to reconstruct the missing region and increase the resolution in frames with a generalized model, leading to coherent and high-resolution results spatially in each frame and temporally along different frames.
In the situation of inpainting, pixels in the video frame may be corrupted during transmission, or some undesirable situations, such as watermarks or objects, need to be removed. Image inpainting has been extensively studied in the literature, which is consistent with video inpainting tasks. Texture synthesis methods in early works [
1,
2] match and copy background patches to fill the hole. However, they cannot handle the challenging cases where inpainting regions are complex and non-stationary. The major obstacle is that these methods cannot learn to understand the semantics of images and rely heavily on matching low-level, human-crafted features. Recently, deep generative inpainting methods based on convolutional neural networks (CNN) [
3] and generative adversarial networks (GANs) [
4,
5] have demonstrated great improvements over traditional methods. These methods learn to understand the semantics of images by training on large datasets and perform much better on non-stationary cases, such as incomplete objects, faces, complex scenes and many others. However, these methods for image inpainting have inferior performance when applied to the task of video inpainting, where the missing content in frames is required to be spatially coherent (in each frame) and temporally consistent (across frames). Although some work has attempted to extend image inpainting methods to videos, their methods perform poorly when both the background and holes are not static [
6]. As a result, it is essential to combine spatio-temporal information not only from the current frame but also from the nearby frames.
The existing video inpainting algorithms can be divided into object-based and patch-based methods. In the object-based method, a video is divided into its background and foreground, which are inpainted separately and merged at the end of the algorithm [
7,
8]. However, these algorithms are not robust and produce artifacts when objects are in motion. On the other hand, patch-based methods search for suitable patches from global and local frames based on both 2D patches [
9] and 3D patches [
10,
11,
12]. Although patch-based methods have some successful cases, they still have some drawbacks, such as heavy computation and unstable performance in videos with motion and occlusion.
In the situation of super-resolution reconstruction, a non-linear mapping is used to reconstruct high-resolution (HR) images from low-resolution (LR) images. Although several methods have achieved good performance, they still remain intractable for the following ill-posed problem: how to model the mapping relationship from LR to HR images. Especially, an LR image with identical representation can be obtained from an infinite number of HR images by downscaling, resulting in a large space of possible functions during mapping. It is particularly difficult to learn an appropriate function in such a large space, which ultimately limits the capability of the model. Although several recent models have significantly improved SR performance, such as SRGAN [
13], SRNTT [
14], and RDN [
15], they still suffer from the fact that the space of the possible mapping functions remains large.
Furthermore, the direct application of the above methods to video super resolution is not appropriate due to the particularities of videos. Previous research [
16,
17,
18] on video SR still represents a simple extension of image super-resolution methods. Recent research [
19,
20,
21,
22] addresses the above challenges with more efficient methods consisting of alignment and fusion. However, these methods still suffer from poor performance when there is a lot of motion or severe blur in the video.
Based on the above discussions, there are still significant challenges in the existing techniques of video inpainting and video super resolution. Moreover, there is a significant disparity in the design of algorithmic models in these two domains, leading to the lack of a universal model. As a result, we introduce a generalized Video-Restoration-Net (VRN), supported by a non-local operation, to perform both tasks successively. Firstly, due to the lack of suitable datasets, we propose an automatic algorithm to synthesize full video datasets for super-resolution reconstruction, while another incomplete-complete dataset is constructed using large and varied hole-mask sequences simulating different real-world use cases. Specifically, some frames of the incomplete-complete datasets are shown in
Figure 1. From top to bottom, we show examples of the collected videos, masks, and a mask sequence that we generated from a single mask. Based on the two synthetic datasets, we design a WGAN-style framework [
23] to train a non-local deep generative network for inpainting and SR tasks. During inpainting tasks, we use an encoder–decoder model in the generator to extract the feature of each frame in the video and to restore frames based on the predicted feature, respectively. Between the encoder and decoder, we stack the feature maps of the frames and introduce a non-local network module [
24] that models long-range, spatio-temporal dependencies to fill in the missing part of the inpainting task, while the frames should be input in an unstacked situation to recombine the non-local information from different locations of a given frame in the SR task. The recombined feature maps are then unstacked and inputted frame-by-frame to the decoder to generate a coarse video. After the encoder–nonlocal-decoder construction, we design a network to refine each frame separately. On the other hand, we employ both global and local discriminators for frame inpainting [
25]. Meanwhile, we perform the video SR task by adopting another VRN based on the full video datasets frame-wisely, assisting with a similar training course adopted in the video inpainting task. Both
reconstruction loss and adversarial loss are used in supervision during training.
Overall, we first present experiments on the complete-incomplete datasets we synthesize to demonstrate the effectiveness of our proposed method in video inpainting. Moreover, we adopt the full video datasets we synthesize as training datasets for SR reconstruction to explore the performance of our proposed method and validate it on public datasets, proving the universality of our Video-Restoration-Net. Our contributions can be summarized as follows:
We present a deep generative non-local network for the task of video inpainting and frame-by-frame video SR reconstruction as an effective and generalized baseline. The proposed model is able to deal with various shapes of masks with divergent motion while reconstructing the generated low-resolution videos frame by frame.
We propose an automatic algorithm to synthesize incomplete videos from complete ones, motivated by real-use cases of video inpainting.
We present experiments through inpainting and SR results supported by ablation studies compared with several deep-learning-based baselines and show that our method based on a non-local module produces higher quality results in both video inpainting and frame-by-frame video SR tasks.
3. Materials and Methods
In this section, we introduce our data generation method and the proposed algorithm for the video inpainting and SR tasks.
To generate the data for two tasks, we collect some suitable videos from several existing datasets. We also select several appropriate masks for video inpainting. The details of the method are described in
Section 3.1.
Our model is a WGAN-style [
47] neural network. During the video inpainting task, we adopt an incomplete video,
, and its mask sequence,
, as inputs, the generator,
, outputs a restored coarse video as an intermediate output,
, and then a network refines the coarse video and outputs the final result,
, which should be as consistent as possible with the complete video,
. Similar to the image inpainting methods [
25,
27], two global–local discriminative networks are trained with
in an adversarial manner to help
produce more qualified results. One discriminates the quality of the restored missing regions and the other one evaluates the consistency of the restored missing parts in each frame. Our model for video inpainting is shown in
Figure 3, and the details are shown in
Table 1,
Table 2,
Table 3 and
Table 4. It takes an incomplete video and its mask sequence as input. The encoder–nonlocal-decoder part outputs a coarse inpainted video. The refinement network first restores only the missing region and then reconstructs the whole inpainted video. The input is also concatenated to the coarse video and the restored missing region.
During the SR task, we adopt low-resolution videos generated by downsampling with a scaling factor of ×4 and conduct the input frame-wisely. We utilize a 2D non-local block instead of the 3D block adopted in inpainting in order to reduce parameters and improve computational efficiency. Moreover, we use a global discriminator to evaluate the consistency of reconstructed high-resolution images, while other operations and model architecture are kept consistent with the video inpainting task, as shown in
Figure 3.
3.1. Data Acquisition for Video Inpainting and SR
The performance of the neural network relies on reliable datasets. However, the property of the model is limited by the lack of datasets for video inpainting. To solve this problem, we need to build artificial video datasets with good diversity. The videos in our datasets should be in multiple scenes to ensure that the network will not be overfitted. In addition, the videos for the inpainting task should have the following characteristics: the masks should be different in size and shape to ensure that the network is able to handle a variety of masks rather than just one type. Secondly, the masks should be moving rather than static, and the moving track should be random.
Following the above principles, we collect 340 suitable videos for training from three datasets, UCF101 [
48], MOT16 [
49], and FCVID [
50]. The datasets we build are rich in diversity, containing outdoor and indoor videos, sports and landscape videos, videos with and without camera motion, and with other difference characteristic. From these videos, we extract 937 clips, and each clip contains 32 frames with a 160 × 240 resolution as complete videos.
During the training course of the video SR task, the complete videos acquired above can be directly adopted as ground truth datasets, while they are treated as low-resolution input by conducting downsampling. Moreover, we adopt BSD100 [
51] and Urban100 [
50] as the test datasets for the SR task.
For the video inpainting task, we need to simulate the various shapes of the holes in the video by selecting some suitable video segmentation labels from the A2D datasets and moving them randomly to synthesize the hole mask sequence. As a result, the hole mask sequences are stochastic, regardless of shape, size, or motion tendency. Furthermore, in some sequences, there are even two or more holes. We synthesize the incomplete video using the video clips and the mask sequences; the pixels in the video are constrained between 0 and 1 and the pixels in the hole are set to 1. Finally, we generate 937 videos, of which 900 are for training and the rest are for testing. Some examples of collected masks, synthetic mask sequences, and videos are shown in
Figure 1. Based on these datasets, it is possible to train a neural network using a supervised method and to quantificationally compare the inpainting results with other algorithms.
3.2. Generator Architecture Design
The proposed generator consists of four parts: an encoder, a non-local block, a decoder, and a refinement network. Since the encoder–decoder architecture has been used in the image algorithms [
25,
27], we also adopt this model in our work. The encoder, which contains seven convolutional layers, is used to extract the features of each frame of the video. The strides of the second, fourth, and sixth layer of the encoder are set to 2 for downsampling. The kernel sizes of the encoder are set to 3, and Elu [
52] is adopted as the activation function. Moreover, the decoder, which has a corresponding structure with the encoder and uses resize-convolution for upsampling, is used to restore the inpainting and LR frames from the processed features.
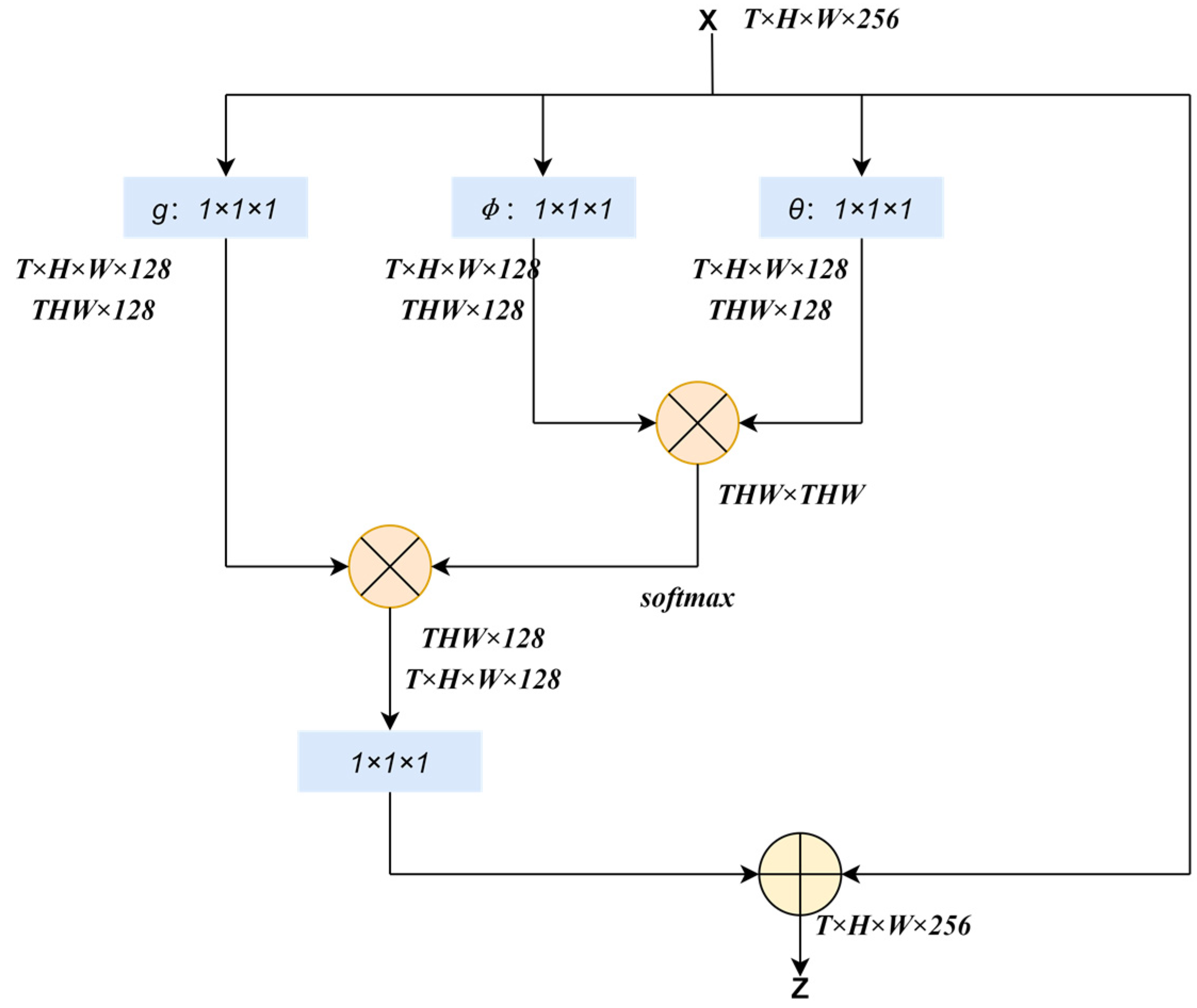
During the inpainting task, we stack the feature map outputs of the encoder between the encoder and the decoder, and then the non-local block is used to combine the spatio-temporal features. Finally, we unstack the feature maps and feed them into the decoder to restore the inpainted frames, respectively. Due to the fact that a missing part of the current frame potentially could appear in other frames in the video, especially in the far frames where the missing part and low resolution case have coherence in spatio-temporal data, we need to consider a long dependency during the inpainting task. Therefore, the non-local neural network becomes very suitable for this task because the non-local block takes the feature maps of the whole video as input and computes the relationship between all positions. As shown in
Figure 2, the feature maps are parallelly input into three 1 × 1 × 1 3D convolution layers,
,
and
, and then we can obtain an affinity representation of the relationship between each position,
, in the video and its corresponding position,
, through matrix multiplication and softmax operation. The convolution layer,
, outputs a representation of the input feature at the position
. These two results are added to the input feature maps to produce the final result after matrix multiplication and 3D convolution. In this way, the receptive field is extended to the entire video rather than the field of the convolution kernel. Thus, the information of all the other positions is considered not only in the current frame but also in the others. The details are shown in
Table 1 and
Table 2.
Different from the encoder and decoder architecture adopted in the inpainting task, several modifications are implemented in the SR task. The main distinction is that we adopt 2D convolutional layers due to the fact that we conduct the input frame-wisely during the training course, while the other configuration of the network keeps consistent with that in the inpainting task.
The last part of the generator is a refining network, which is a dual-task network that takes the output of the decoder and the incomplete video as input during the inpainting task while taking the individual output of the decoder as input during the SR task. First, a U-net takes the ground truth frame as a label, reconstructing the inpainting and high-resolution frames, respectively. In this part, we continuously downsample and upsample the input four times by using convolution layers with stride 2 and resize-convolution layers. Then, 5 convolution layers are applied to restore the final result. The details are shown in
Table 3.
3.3. Discriminator Architecture Design
Our discriminator is built at the frame level; we evaluate one video at each step and treat the number of frames as the batch size. The architecture of the network is similar to that of SRGAN [
13]. There are 8 convolutional layers in the architecture and half of them are with stride 2. We also use batch normalization and leaky ReLU in this architecture. The details of the discriminator are shown in
Table 4.
In the video inpainting task, we use the above two networks as the global–local [
25,
27] discriminator during training, which is different from the SR task where only the global discriminator is used. Furthermore, the global–local discriminator is used in different training steps, which are introduced in
Section 3.5. The local discriminator takes the restored missing region as input to evaluate its quality, and the global one takes the restored whole image as input to judge the consistency between the restored part and the complete part.
3.4. The WGAN Style Training Loss
Since the original GAN is always faced with the problem of disappearing gradients, the WGAN is proposed as a solution, which uses the Wasserstein distance to measure the gap between the real data distribution and the fake data distribution. The WGAN can be described as:
where
and
represent the discriminator and generator, respectively.
is random noise in the WGAN, but it is the incomplete video with its mask sequence in our work.
As mentioned above, the same model is adopted in both video inpainting and SR tasks and trained in two separate courses. The training loss of the video inpainting and SR tasks can be described as follows.
During the video inpainting task, the discriminator we design contains two parts: the global one evaluates the consistency of the restored missing part with the entire frame, and the local one judges the quality of the restored missing part.
For the global discriminator, we put the restored missing region back into the incomplete video; it can be described as:
where
is the mask sequence, whose pixels are 1 in the missing region and 0 in the rest of the video.
We use
as the input of the global discriminator, and the label for complete video is
in both tasks. So the loss of global discriminator
is
For the local WGAN, we only focus on the quality of the restored missing-part frame. Therefore, the loss of local discriminator,
, can be written as:
On the other hand, we combine the
loss with the loss of WGAN to train our generator. We tried 3 forms of L1 loss. The first one is
where we only want to compute the gap in the mask. However, this loss is not able to guide the network in learning how to restore the video. The output is chaotic and the loss does not decrease during training.
Whereafter, we realize that it is necessary to compute the loss of the full video, so we simply compute the Manhattan distance between the inpainting video and the ground truth, which can be described as:
Nevertheless, we finally find that increasing the loss of the hole region 10 times to increase the attention to the area is helpful in training the network. Consequently, the
loss between the restored video,
, and the ground truth (GT),
, can be written as:
and the loss of generator in the video inpainting task is:
Intuitively, we use the loss to directly regress the missing region to the complete video, and at the same time, WGAN trains the generator with adversarial gradients to make the result much more real.
During the video SR task, the discriminator we design contains only the global one, different from the inpainting task, which evaluates the consistency of the reconstructed high-resolution part with the entire frame.
In detail, we directly adopt the generated high-resolution frame,
, as the input of the global discriminator and the label for the ground truth is
. The loss of the global discriminator,
, is
Furthermore, we calculate the Manhattan distance between the generated high-resolution frame and ground truth with Equation (7) and obtain the loss of generator in the video SR task, formulated as:
3.5. Training Methods
Although we set a series of loss functions to guide the training, it is still not easy to train our model directly due to the deep architecture of our model and the complexity of the video inpainting and SR tasks. As a result, we train our model in two separate situations, each with 3 identical steps.
In the first step, we train the encoder–decoder with Mean Square Error loss for 100 epochs. The network takes each frame in our datasets as input and restores it. As a result, the encoder is able to extract reliable features for restoration, and the decoder can restore the frame based on these features.
Subsequently, we add the non-local block between the encoder and decoder and train them for 500 epochs. We adopt the incomplete video and its mask sequence as input for the video inpainting task and the low-resolution video as input for the SR task and output a corresponding restored and high-resolution video. We use the global–local discriminator in the inpainting task and the global discriminator in SR task, respectively, to judge the gap between the output video and the ground truth. We mainly desire to train the non-local block to learn to recombine the features from incomplete to complete. In this step, the parameters of the non-local decoder are optimized.
Finally, we train the whole encoder–nonlocal-decoder refinement model for 500 epochs. In the first 300 epochs of this step, we only update the parameters of the refined network and then the whole model is updated.
Since WAGN cannot be trained by momentum-based algorithms such as the Adam optimizer, we train our model on the RMSProp optimizer with a learning rate of 0.0001.
4. Results and Discussions
Our model is implemented on TensorFlow v1.13.1, CUDNN v7.4, and CUDA v10.0, and it runs on hardware with a GPU Nvidia GTX2080.
In the video inpainting task, we train the proposed model on 900 videos and evaluate it on 37 videos. Due to the face that the non-local block occupies a large amount of GPU memory, we restrict the video to 32 frames with a size of 160 × 240. It takes more than ten hours per epoch. In the SR task, we adopt the full video datasets for training and further evaluate our model on BSD100 and Urban100.
4.1. Quantitative Comparisons
During the inpainting task, as there were no datasets for video inpainting before, the evaluation is always based on qualitative comparisons. Although the inpainting result is not unique, which means that every result is acceptable as long as it is natural and realistic, the gap between the inpainting result, and the ground truth can still be used as a standard to evaluate the quality of the algorithms.
To evaluate our algorithm quantitatively, we compare our model with a typical patch-based algorithm [
11]. This approach is considered canonical in terms of versatility, enabling us to confirm the versatility of our algorithm, while recent models are incapable of handling both inpainting and SR tasks. In addition, the code for [
11] is publicly available online, so we can compare it with our synthetic test data.
However, the recent models lack universality, have limited improvement in PSNR and SSIM index and have little improvement in visual effect. Thus, our work is focused on introducing a universal model capable of restoring both images and videos. Since the method used in [
11] is a canonical method in terms of versatility, we select it as the baseline model for the inpainting task.
We employ five assessment criteria, namely peak signal-to-noise ratio (PSNR), structural similarity index (SSIM), mean L1 error, mean L2 error, and perceptual loss. The L1 and L2 errors intuitively reflect the gap between two images at the pixel level. PSNR is based on error sensitivity, and SSIM evaluates the image in terms of brightness, contrast, and structure. Perceptual loss, which is widely used in super-resolution tasks, is a function that evaluates the similarity between two images based on high-level features. Here, we use the feature of the second full connection layer of the VGG16 model as the standard. For L1 error, L2 error, and perceptual loss, a smaller value means better image quality. However, the opposite is true for PSNR and SSIM.
The average results of the five indexes on the synthetic test datasets are shown in
Table 5. Our model performs better on PSNR, SSIM, L1 loss, and L2 loss, while the performance on perceptual loss is similar. This is mainly due to the non-local architecture, which considers mostly the spatio-temporal features in each frame. Moreover, as the recent models [
47,
48,
49,
50,
51] have limited improvement in PSNR and SSIM index and little improvement in visual effect, the results of our model can already meet the application requirements of most scenarios, and our approach has greater universality.
Long computing times are an always-standing problem in video inpainting tasks. This is because a large amount of time is spent on patch seeking, matching, and any other options. For the deep learning algorithms, the parameters have been confirmed in training stage. Correspondingly, the calculation becomes extremely simple in the testing step. When inpainting a 32-frame video with a size of 160 × 240, the patch-based algorithm [
11], when implemented on Matlab, takes about 6.5 min, but our model only consumes about 1.5 s on TensorFlow. Furthermore, the time of inpainting an incomplete sample frame cost about 0.05 s on our proposed model, while that of [
11] costs about 12 s. Although the implement platform is different, the operation time is cut down greatly.
During the SR task, we conduct quantitative comparisons to demonstrate the advantages of our proposed model. All of the LR images are generated by bicubic downscaling with a scaling factor of ×4 from the HR images according to the standard protocol. We conduct the comparisons on benchmark datasets using the quality metrics of PSNR and SSIM. We compare our proposed model with several representative methods, including SRGAN [
13], SRNTT [
14], and RDN [
15], as shown in
Table 6. For the BSD100 and Urban100 datasets, our method yields excellent properties and outperforms the other methods on PSNR and SSIM. It reveals that the non-local architecture paid more attention to the different locations within a particular frame. Moreover, the above results also demonstrate the universality of our method in video inpainting and SR tasks, while no existing methods can deal with both situations.
4.2. Qualitative Comparisons
During the inpainting task, we show five inpainted frames of the test datasets in
Figure 4. The top row is the ground-truth complete frame. The middle row is the result of the method used in [
11], while the bottom row is the result of ours. Both [
11]’s and our model can successfully inpaint the frame, as shown in (a). However, the method of [
11] misses the fence in (d), so obviously our result is much closer to the ground truth, although their result is also acceptable.
However, the method proposed in [
11] also has the problem that the inpainted hole region has an obvious boundary. We magnify the inpainted holes of (b), (c), and (e) in
Figure 5 to compare the details. The red boxes in the image describe the parts that need to be inpainted. In
Figure 5a, the boundary of the image of [
11] is apparently disharmonious. Our result is much better but a little lacking in texture. In example (b), a profile of the missing region can be clearly observed in the result of [
11], and our result has the same problem but looks brighter. As (c) shows, the result of [
11] loses some details of the frame, but we restore them successfully. The above results further verify that the non-local mechanism is efficient through learning spatio-temporal features from each frame.
In [
26], a texture pyramid and approximate nearest neighbor (ANN) search are used to extract patches to restore the hole, but this model is still not as reliable as ours. In our model, we first train the encoder–decoder to ensure that the encoder is able to extract reliable features for reconstruction and the non-local block is able to find useful information from non-local positions. As a result, under the reliable features and non-local information recombination, the following units will go in the right direction.
During the SR task, we also conduct qualitative analyses in terms of visual quality and texture enrichment, making comparisons between bicubic interpolation, ground truth (GT), SRGAN [
13], SRNTT [
14], RDN [
15], and our model. The results of two images are shown in
Figure 6 and
Figure 7 with a scaling factor of ×4. The corresponding quality metrics of PSNR and SSIM and the mean square error (MSE) belonging to each SR image are also exhibited below. The exhibited images are from BSD100 and Urban100, respectively.
As shown in
Figure 6 and
Figure 7, the red box in the image describe the parts that need to be restored. The compared methods produce blurred edges and noticeable artifacts, while our model achieves higher visual quality by recovering and presenting sharper and clearer edges. In addition, the three quality metrics of two images achieved by our model also outperform the other methods. The reconstructed images generated by our model are more faithful to the GT images, demonstrating that the non-local architecture we adopt is much more efficient by combining non-local information.
All these qualitative comparisons of video inpainting and SR tasks further indicate the powerful versatility of our method in completing a variety of tasks, and the results are very competitive.
This is of great significance to the development of a general model in the field of video restoration.
4.3. Validity of Non-Local Block
To evaluate the validity of the non-local block in our model, we conduct a comparison between the non-local block and 3D convolution, which is a widely used strategy in video processing. This part is performed on an inpainting task to evaluate the global and local performance. Based on the trained encoder–decoder model, we replace the non-local block with a 3D convolution layer and train the encoder–3D-Conv–decoder model for 100 epochs. The loss of the generator during the 100 epochs is shown in
Figure 8.
The non-local block always gains a lower loss than the 3D convolution. The non-local block performs better as long as the non-local block has a larger respective field. Although the 3D convolution can combine the information from different frames, it is only able to combine the local features, which are limited by the size of the convolution kernel. However, the non-local block explores the relationship between different frames and positions at the pixel level by combining non-local spatio-temporal information. As a result, the non-local block has a stronger ability to find the useful information from distant frames and positions.
In addition, we are also inquisitive about how many non-local blocks are sufficient for this task. We adopt one, three, and five non-local blocks, respectively, in our encoder–nonlocal-decoder model and train the model adequately. The comparison result of the test datasets is shown in
Table 7. We find that the performance becomes better when more blocks are used. Nevertheless, the calculation quantity also increases dramatically; the five-block version requires about 1.2 h for each epoch during training. The three-block version gains a similar performance with only 35 min. Therefore, we take up the three-block version in our work.
4.4. Validity of Refinement Network
During the research of the inpainting task, we find that the encoder–nonlocal-decoder model is only able to restore a coarse result, as shown in
Figure 9 shows. The top row is the result of the decoder and the bottom row is the refined result. This is caused by the damage of the image texture in the deep network. To solve this problem, we design an additional refinement network. The U-net architecture is first used to restore the hole region only for refining the texture of this region. Subsequently, four convolution layers are adopted to fill the refined region back into the video and ensure coherence. As shown in
Figure 7, the red box in the image describe the parts that need to be restored. It can be easily found that the texture in the hole region is successfully restored after the refinement of the network.
5. Conclusions
In this paper, we propose a method to generate the data for the video inpainting and SR task, making it possible to train a neural network in a supervised way. We design a deep model and introduce non-local blocks to our work to combine the non-local features, further proposing a generalized model that efficiently deals with the inpainting and super-resolution reconstruction tasks, which is also the first generalized model. The proposed model is able to successfully inpaint an incomplete video and generate SR frames. The comprehensive benchmark evaluations demonstrate that our model performs superiorly over representative methods, revealing the powerful versatility of our method in video inpainting and SR tasks.
Although our model may not perform as well as a model that is dedicated to handling a single task, we may compromise some single-task performance due to our pursuit of universality. However, the recent models have limited improvement in PSNR and SSIM index and little improvement in visual effect. The results of our model can already meet the application requirements of most scenarios, while pioneering the field of research on model universality, which is of great significance. In the future, our work will primarily concentrate on two elements. Firstly, we will modify our proposed model to enhance performance on a single task. Secondly, we will continue to explore more efficient universal models for video restoration.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}