
Speaker Recognition Based on Dung Beetle Optimized CNN

Abstract
:1. Introduction
2. Background
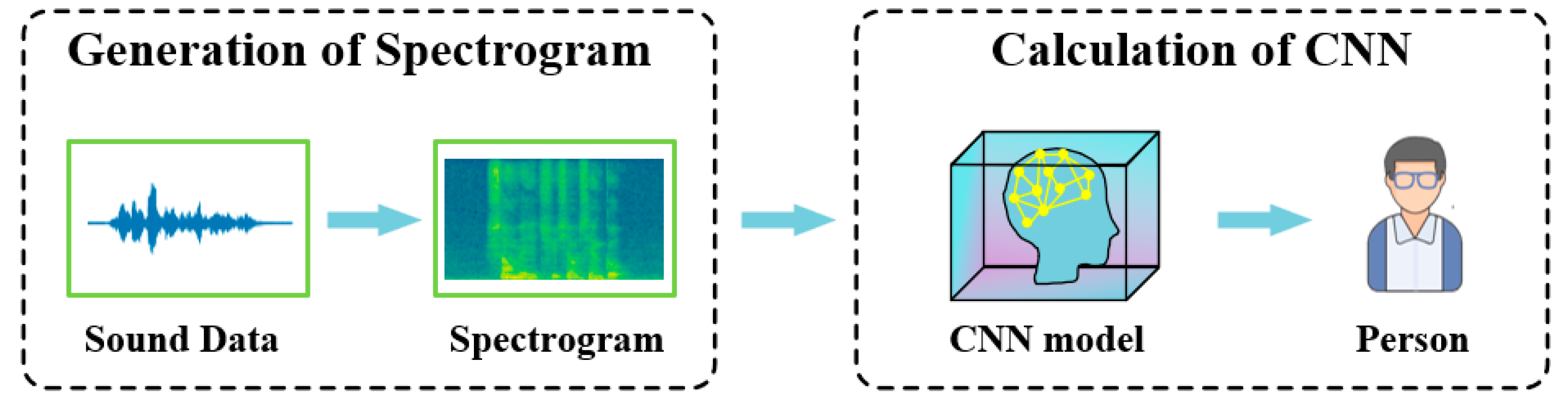
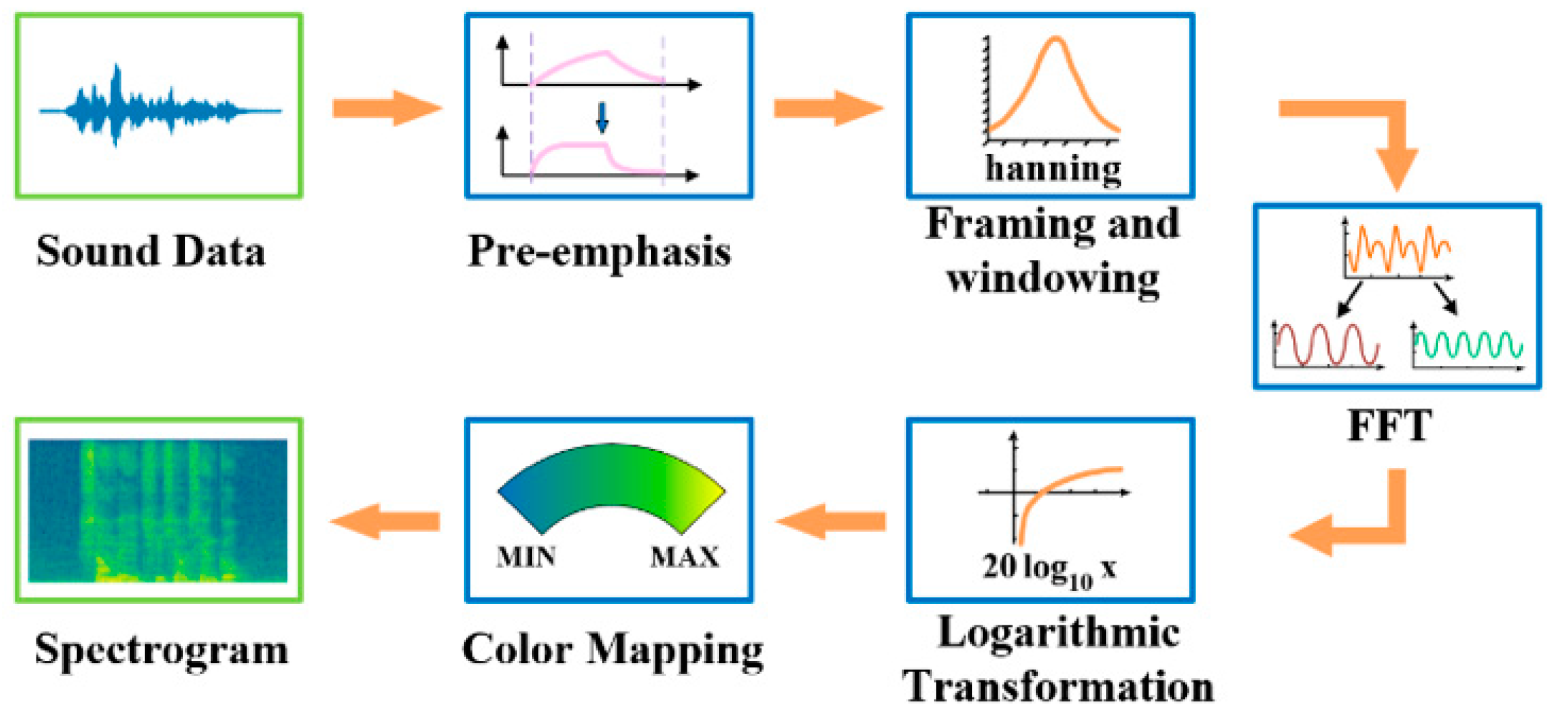
2.1. Generation of Spectrogram
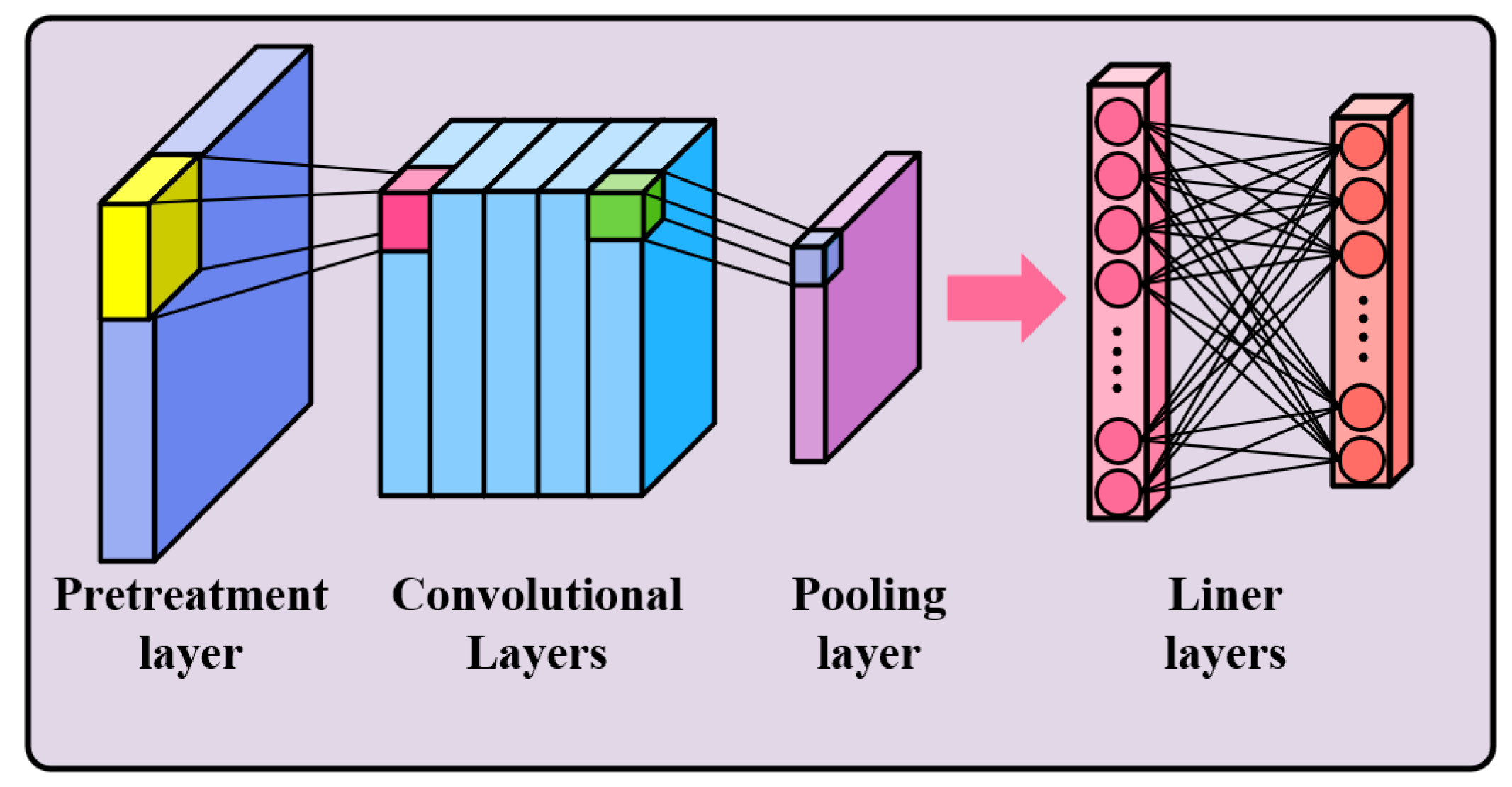
2.2. CNN Architecture
- The number of filters per convolution layer; this parameter determines the abstraction ability of the network and the number of features to be eventually extracted
- The number of neurons in the fully connected layer; too few neurons may result in failure to train a model that meets the requirements, while numerous neurons may lead to overfitting
- Learning rate: If the learning rate is too low, it is easy for the model to fall into a local optimum, and if it is too high, it is easy to miss the global optimum and fail to complete the training.
3. Materials and Methods
3.1. Dataset
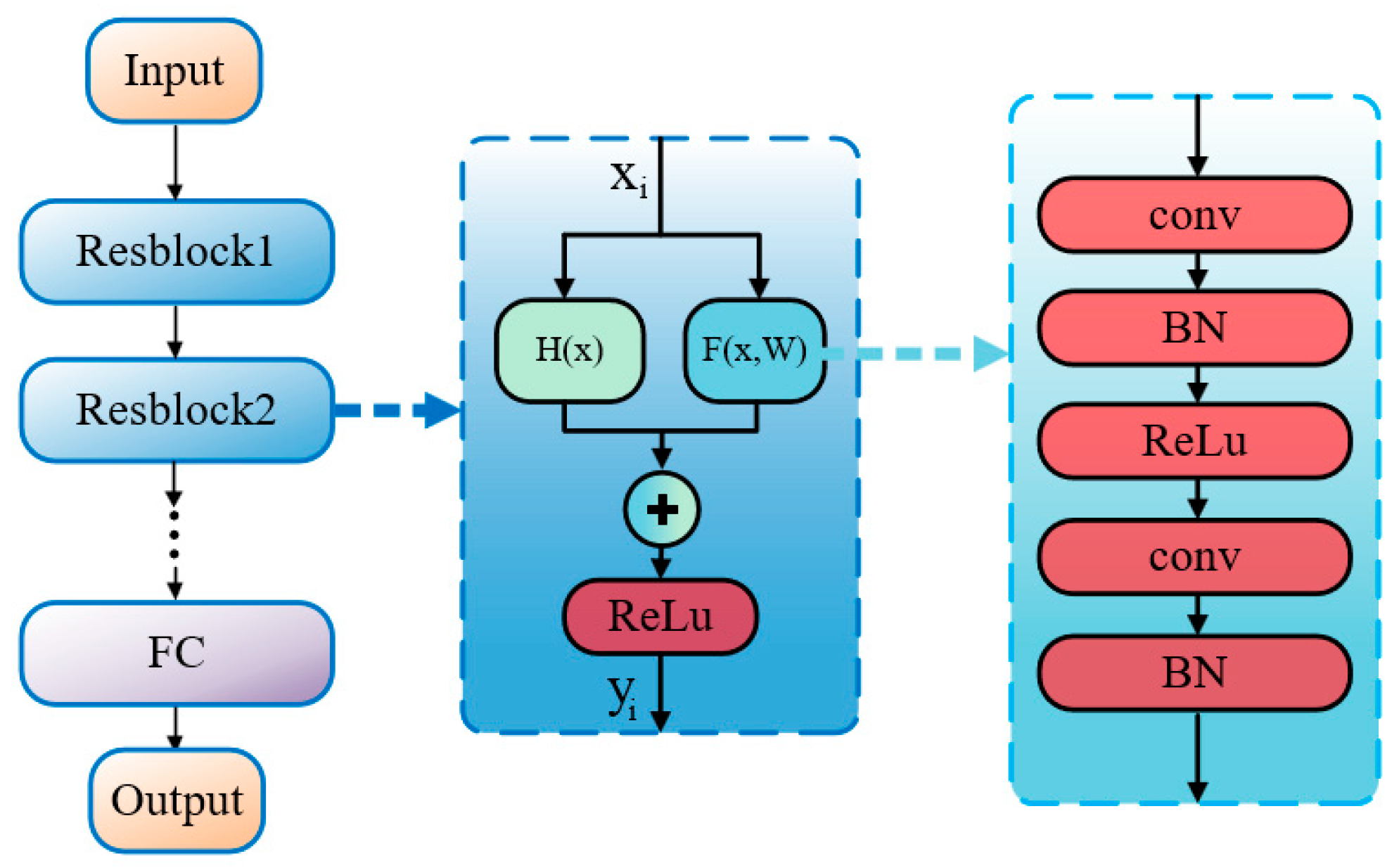
3.2. Residual Network (ResNet)
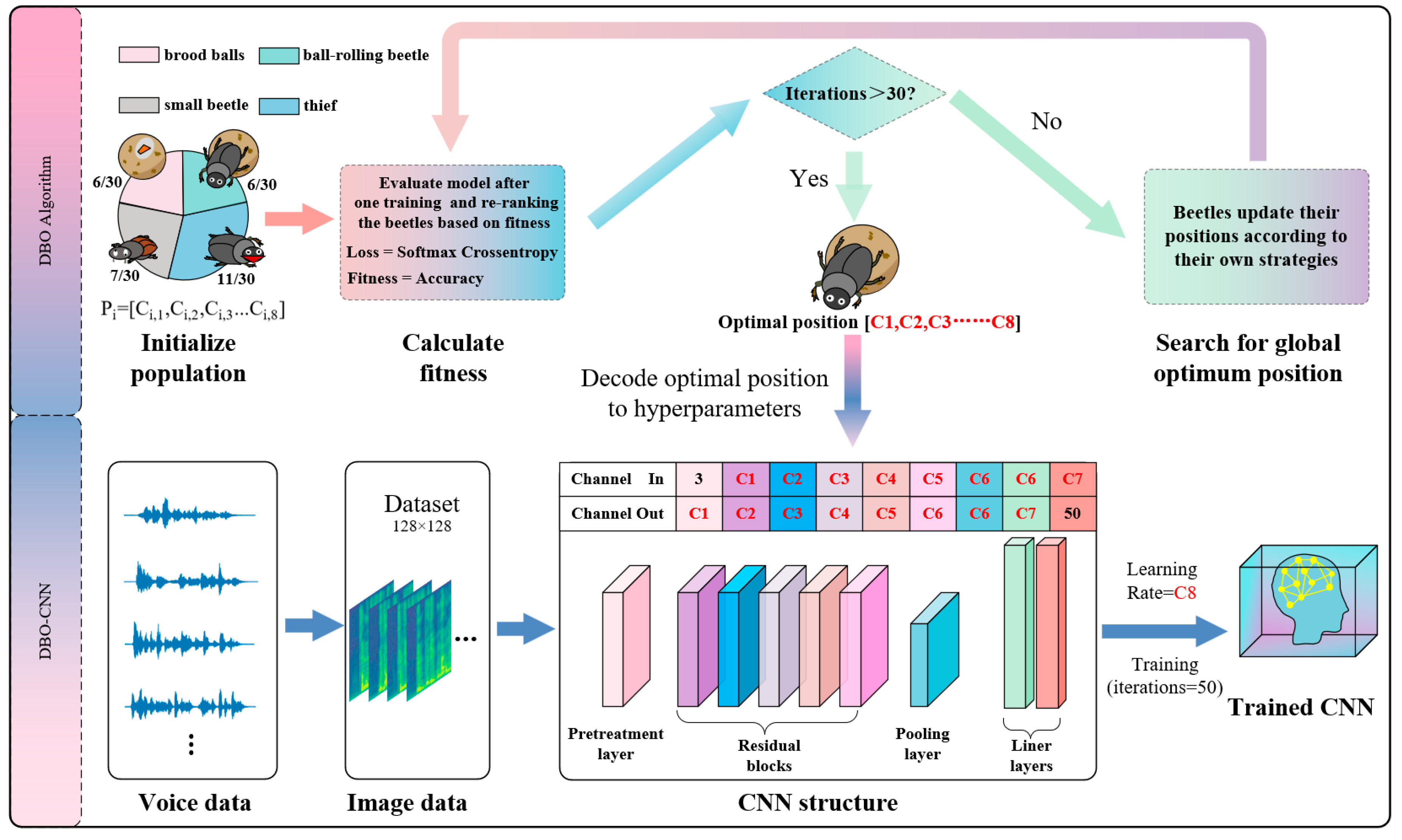
3.3. Dung Beetle Optimization (DBO)
3.4. Optimization Process
- Step I: Divide the data set into a training set and a test set in a ratio of about 8:2
- Step II: Initialize the population to 50 and divide them into different beetle roles according to the fitness ranking. Among them, the proportion of ball-rolling beetles is 6/30(10), the proportion of brood balls is 6/30(10), the proportion of small beetles is 7/30(12) and the proportion of thief beetles is 11/30(18)
- Step III: The beetles search for the optimal hyperparameter group according to their own strategies of position adjustment
- Step IV: Build a convolutional neural network for speaker recognition by using the optimal hyperparameters
- Step V: Evaluate the model on the test set after training.
4. Experiments and Results
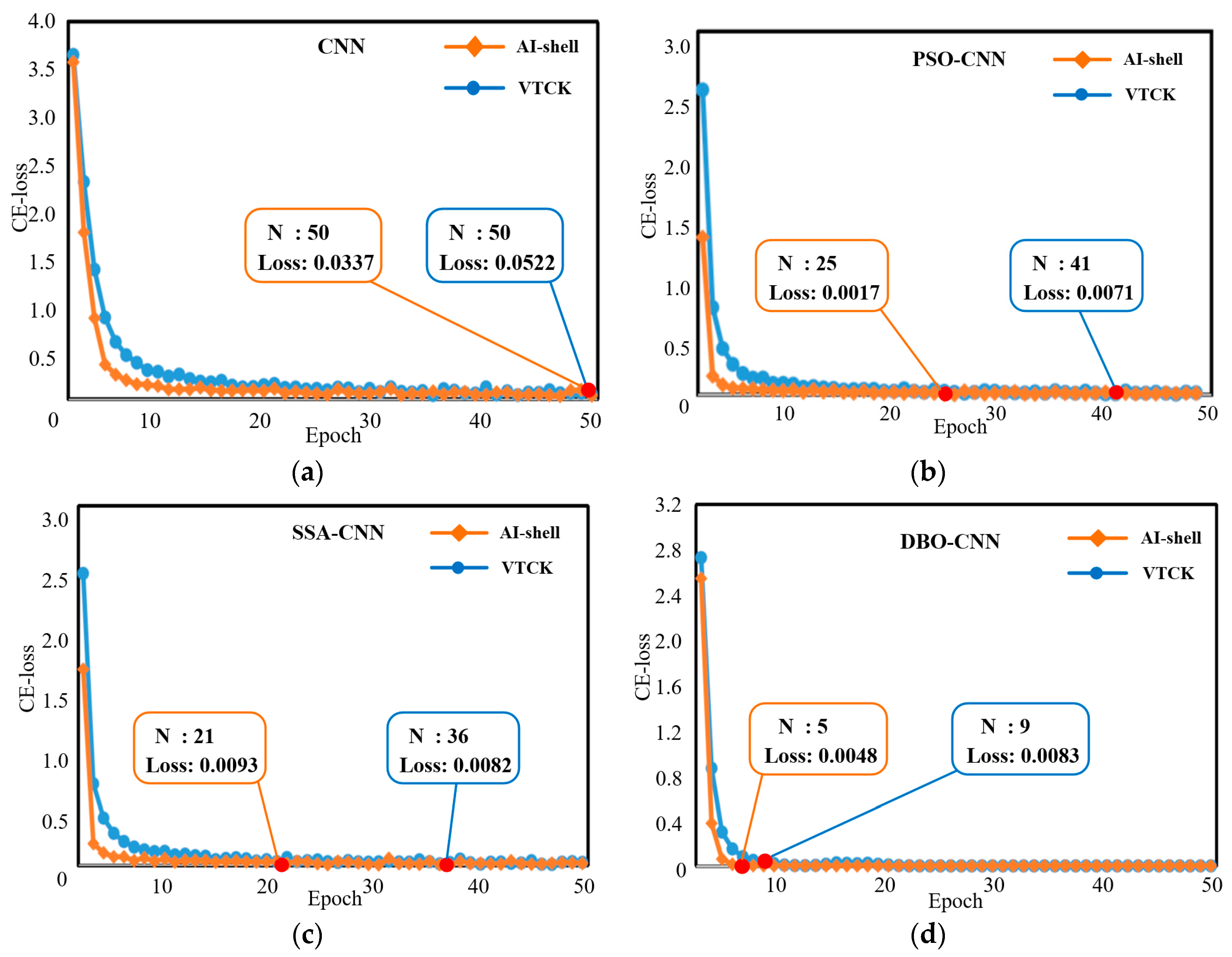
4.1. Hyperparameters Optimization
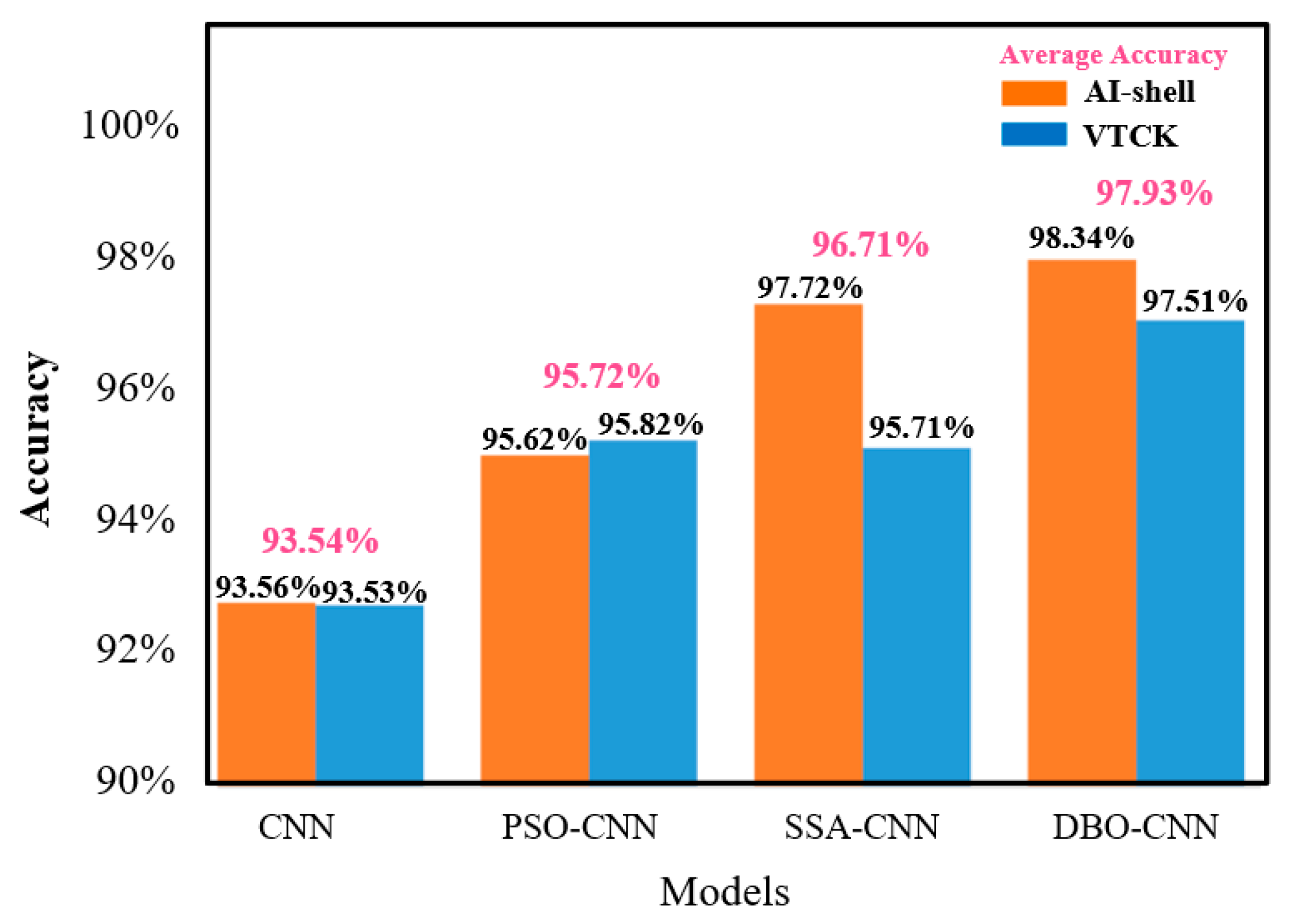
4.2. Recognition Performance
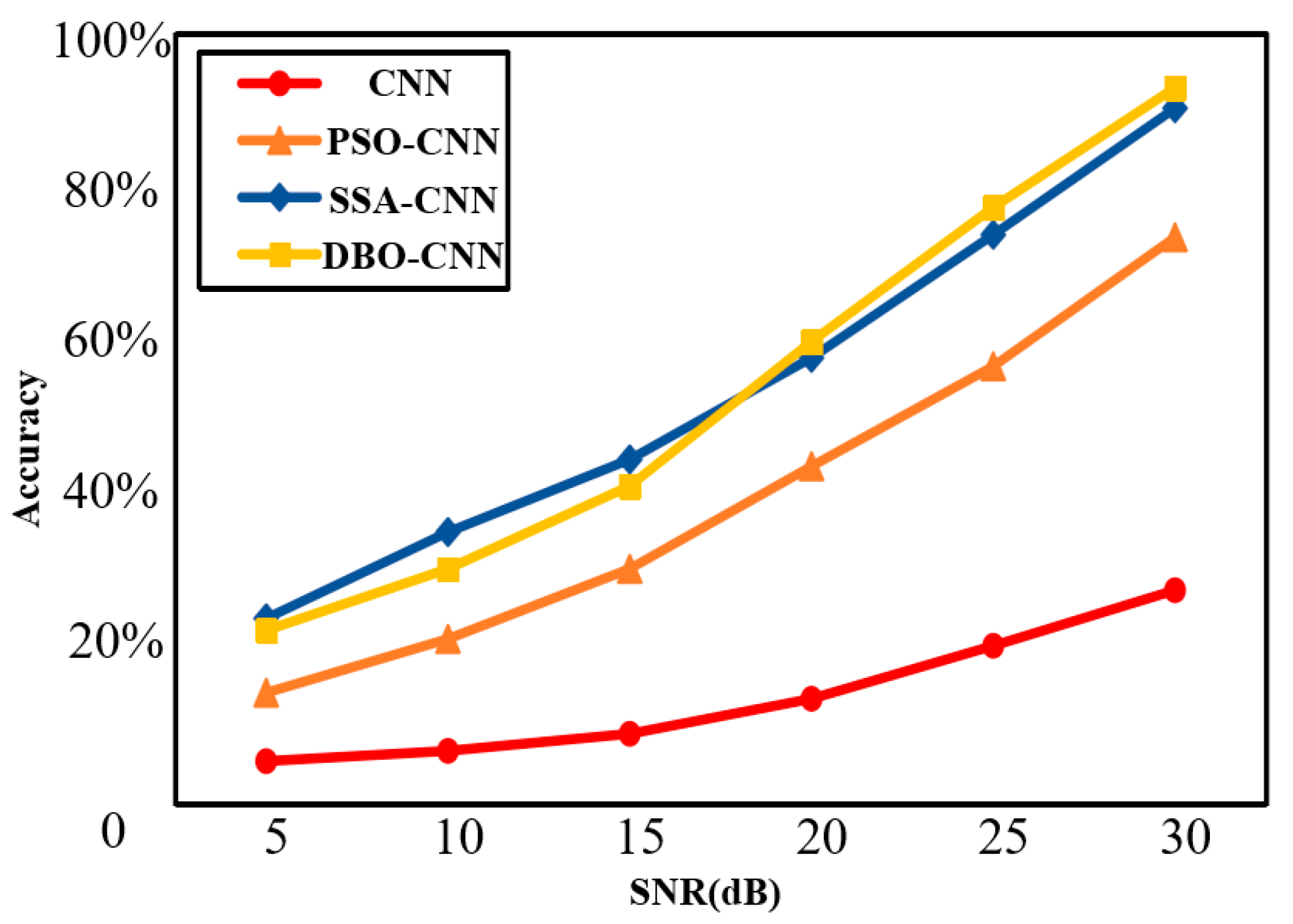
4.3. Noise Resistance Test
5. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Thullier, F.; Bouchard, B.; Menelas, B.-A.J. A Text-Independent Speaker Authentication System for Mobile Devices. Cryptography 2017, 1, 16. [Google Scholar] [CrossRef]
- Gupta, H.; Gupta, D. LPC and LPCC method of feature extraction in Speech Recognition System. In Proceedings of the 2016 6th International Conference—Cloud System and Big Data Engineering (Confluence), Noida, India, 14–15 January 2016; pp. 498–502. [Google Scholar]
- Chia Ai, O.; Hariharan, M.; Yaacob, S.; Sin Chee, L. Classification of speech dysfluencies with MFCC and LPCC features. Expert Syst. Appl. 2012, 39, 2157–2165. [Google Scholar] [CrossRef]
- Tripathi, A.; Singh, U.; Bansal, G.; Gupta, R.; Singh, A.K. A Review on Emotion Detection and Classification using Speech. In Proceedings of the International Conference on Innovative Computing & Communications (ICICC) 2020, New Delhi, India, 21–23 February 2020. [Google Scholar]
- Tiwari, V. MFCC and its applications in speaker recognition. Int. J. Emerg. Technol. 2010, 1, 19–22. [Google Scholar]
- Bhadragiri, J.M.; Ramesh, B.N. Speech recognition using MFCC and DTW. In Proceedings of the 2014 International Conference on Advances in Electrical Engineering (ICAEE), Vellore, India, 9–11 January 2014; pp. 1–4. [Google Scholar]
- Nakagawa, S.; Zhang, W.; Takahashi, M. Text-independent speaker recognition by combining speaker-specific GMM with speaker adapted syllable-based HMM. In Proceedings of the 2004 IEEE International Conference on Acoustics, Speech, and Signal Processing, Montreal, QC, Canada, 30 August 2004; pp. 1–81. [Google Scholar]
- Matsui, T.; Kanno, T.; Furui, S. Speaker recognition using HMM composition in noisy environments. Comput. Speech Lang. 1996, 10, 107–116. [Google Scholar] [CrossRef]
- Limkar, M.; Rao, B.R.; Sagvekar, V. Speaker Recognition using VQ and DTW. Int. J. Comput. Appl. 2012, 3, 975–8887. [Google Scholar]
- Keogh, E.; Ratanamahatana, C.A. Exact indexing of dynamic time warping. Knowl. Inf. Syst. 2005, 7, 358–386. [Google Scholar] [CrossRef]
- Hanifa, R.M.; Isa, K.; Mohamad, S. A review on speaker recognition: Technology and challenges. Comput. Electr. Eng. 2021, 90, 107005. [Google Scholar] [CrossRef]
- Zheng, R.; Zhang, S.; Xu, B. Text-independent speaker identification using GMM-UBM and frame level likelihood normalization. In Proceedings of the 2004 International Symposium on Chinese Spoken Language Processing, Hong Kong, China, 15–18 December 2004; pp. 289–292. [Google Scholar]
- Liu, Z.; Wu, Z.; Li, T.; Li, J.; Shen, C. GMM and CNN Hybrid Method for Short Utterance Speaker Recognition. IEEE Trans. Ind. Inform. 2018, 14, 3244–3252. [Google Scholar] [CrossRef]
- McLaren, M.; Lei, Y.; Scheffer, N.; Ferrer, L. Application of convolutional neural networks to speaker recognition in noisy conditions. In Proceedings of the 15th Annual Conference of the International Speech Communication Association, Singapore, 14–18 September 2014; pp. 1990–9770. [Google Scholar]
- Abdel-Hamid, O.; Mohamed, A.; Jiang, H.; Penn, G. Applying Convolutional Neural Networks concepts to hybrid NN-HMM model for speech recognition. In Proceedings of the 2012 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Kyoto, Japan, 25–30 March 2012; pp. 4277–4280. [Google Scholar]
- Campbell, W.M.; Sturim, D.E.; Reynolds, D.A. Support vector machines using GMM supervectors for speaker verification. IEEE Signal Process. Lett. 2006, 13, 308–311. [Google Scholar] [CrossRef]
- Wang, S.; Zhao, B.; Du, J. Research on transformer fault voiceprint recognition based on Mel time-frequency spectrum-convolutional neural network. J. Phys. Conf. Ser. 2022, 2378, 12–89. [Google Scholar] [CrossRef]
- Ashar, A.; Bhatti, M.S.; Mushtaq, U. Speaker Identification Using a Hybrid CNN-MFCC Approach. In Proceedings of the 2020 International Conference on Emerging Trends in Smart Technologies (ICETST), Karachi, Pakistan, 26–27 March 2020; pp. 1–4. [Google Scholar]
- Chung, J.S.; Nagrani, A.; Zisserman, A. Voxceleb2: Deep speaker recognition. arXiv 2018, arXiv:1806.05622. [Google Scholar]
- Jagiasi, R.; Ghosalkar, S.; Kulal, P.; Bharambe, A. CNN based speaker recognition in language and text-independent small scale system. In Proceedings of the 2019 Third International conference on I-SMAC (IoT in Social, Mobile, Analytics and Cloud) (I-SMAC), Palladam, India, 12–14 December 2019; pp. 176–179. [Google Scholar]
- İnik, Ö.; Altıok, M.; Ülker, E.; Koçer, B. MODE-CNN: A fast converging multi-objective optimization algorithm for CNN-based models. Appl. Soft Comput. 2021, 109, 107582. [Google Scholar] [CrossRef]
- Yoo, J.H.; Yoon, H.I.; Kim, H.G.; Yoon, H.S.; Han, S.S. Optimization of Hyper-parameter for CNN Model using Genetic Algorithm. In Proceedings of the 2019 1st International Conference on Electrical, Control and Instrumentation Engineering (ICECIE), Kuala Lumpur, Malaysia, 25–25 November 2019; pp. 1–6. [Google Scholar]
- Ishaq, A.; Asghar, S.; Gillani, S.A. Aspect-Based Sentiment Analysis Using a Hybridized Approach Based on CNN and GA. IEEE Access 2020, 8, 135499–135512. [Google Scholar] [CrossRef]
- Chen, J.; Jiang, J.; Guo, X.; Tan, L. A self-Adaptive CNN with PSO for bearing fault diagnosis. Syst. Sci. Control Eng. 2020, 9, 11–22. [Google Scholar] [CrossRef]
- Bhuvaneshwari, K.S.; Venkatachalam, K.; Hubálovský, S.; Trojovský, P.; Prabu, P. Improved Dragonfly Optimizer for Intrusion Detection Using Deep Clustering CNN-PSO Classifier. Comput. Mater. Contin. 2022, 70, 5949–5965. [Google Scholar] [CrossRef]
- Mirjalili, S.; Lewis, A. The whale optimization algorithm. Adv. Eng. Softw. 2016, 95, 51–67. [Google Scholar] [CrossRef]
- Mirjalili, S.; Mirjalili, S.M.; Lewis, A. Grey wolf optimizer. Adv. Eng. Softw. 2014, 69, 46–61. [Google Scholar] [CrossRef]
- Xue, J.; Shen, B. A novel swarm intelligence optimization approach: Sparrow search algorithm. Syst. Sci. Control Eng. 2020, 8, 22–34. [Google Scholar] [CrossRef]
- Peraza-Vázquez, H.; Peña-Delgado, A.; Ranjan, P.; Barde, C.; Choubey, A.; Morales-Cepeda, A.B. A bio-inspired method for mathematical optimization inspired by arachnida salticidade. Mathematics 2021, 10, 102. [Google Scholar] [CrossRef]
- Xie, Q.; Zhou, W.; Ma, L.; Chen, Z.; Wu, W.; Wang, X. Improved whale optimization algorithm for 2D-Otsu image segmentation with application in steel plate surface defects segmentation. Signal Image Video Process. 2023, 17, 1653–1659. [Google Scholar] [CrossRef]
- Hou, Y.; Gao, H.; Wang, Z.; Du, C. Improved Grey Wolf Optimization Algorithm and Application. Sensors 2022, 22, 3810. [Google Scholar] [CrossRef] [PubMed]
- Tuerxun, W.; Xu, C.; Guo, H.; Jin, Z.; Zhou, H. Fault Diagnosis of Wind Turbines Based on a Support Vector Machine Optimized by the Sparrow Search Algorithm. IEEE Access 2021, 9, 69307–69315. [Google Scholar] [CrossRef]
- Muthuramalingam, L.; Chandrasekaran, K.; Xavier, F.J. Electrical parameter computation of various photovoltaic models using an enhanced jumping spider optimization with chaotic drifts. J. Comput. Electron. 2022, 21, 905–941. [Google Scholar] [CrossRef]
- Xue, J.; Shen, B. Dung beetle optimizer: A new meta-heuristic algorithm for global optimization. J. Supercomput. 2023, 79, 7305–7336. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar]
- Wang, P.; Zhang, J.; Xu, L.; Wang, H.; Feng, S.; Zhu, H. How to measure adaptation complexity in evolvable systems–A new synthetic approach of constructing fitness functions. Expert Syst. Appl. 2011, 38, 10414–10419. [Google Scholar] [CrossRef]
- Reilly, N.; Arena1, S.; Lamba, S.; Bartolini, A.; Amodio, V.; Magrì, A.; Novara, L.; Sarotto, I.; Nagel, Z.D.; Piett, C.G.; et al. Adaptive mutability of colorectal cancers in response to targeted therapies. Science 2019, 366, 1473–1480. [Google Scholar]
- Pan, Z.; Yao, Y.; Yin, H.; Cai, Z.; Wang, Y.; Bai, L.; Kern, C.; Halstead, M.; Chanthavixay, G.; Trakooljul, N.; et al. Pig genome functional annotation enhances the biological interpretation of complex traits and human disease. Nat. Commun. 2021, 12, 5848. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Layer | Range |
|---|---|
| preprocessing layer | 16~32 |
| residual block 1 | 32~64 |
| residual block 2 | 64~128 |
| residual block 3 | 128~256 |
| residual block 4 | 256~512 |
| residual block 5 | 512~1024 |
| extra linear layer | 256~512 |
| learning rate | 1 × 102~1 × 10−3 |
| Layer | CNN | PSO-CNN | SSA-CNN | DBO-CNN | ||||
|---|---|---|---|---|---|---|---|---|
| AI-Shell | VTCK | AI-Shell | VTCK | AI-Shell | VTCK | AI-Shell | VTCK | |
| preprocessing layer | 32 | 32 | 24 | 30 | 27 | 19 | 21 | 32 |
| residual block 1 | 64 | 64 | 32 | 49 | 54 | 51 | 63 | 43 |
| residual block 2 | 128 | 128 | 117 | 92 | 107 | 75 | 71 | 127 |
| residual block 3 | 256 | 256 | 230 | 239 | 143 | 135 | 256 | 201 |
| residual block 4 | 512 | 512 | 386 | 504 | 424 | 278 | 272 | 256 |
| residual block 5 | 1024 | 1024 | 424 | 997 | 904 | 555 | 653 | 512 |
| extra linear layer | 512 | 512 | 272 | 403 | 394 | 352 | 259 | 512 |
| learning rate | 1 × 10−2 | 1 × 10−2 | 1 × 10−3 | 1 × 10−3 | 1 × 10−3 | 1 × 10−3 | 1 × 10−3 | 1 × 10−3 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Guo, X.; Qin, X.; Zhang, Q.; Zhang, Y.; Wang, P.; Fan, Z. Speaker Recognition Based on Dung Beetle Optimized CNN. Appl. Sci. 2023, 13, 9787. https://doi.org/10.3390/app13179787
Guo X, Qin X, Zhang Q, Zhang Y, Wang P, Fan Z. Speaker Recognition Based on Dung Beetle Optimized CNN. Applied Sciences. 2023; 13(17):9787. https://doi.org/10.3390/app13179787
Chicago/Turabian StyleGuo, Xinhua, Xiao Qin, Qing Zhang, Yuanhuai Zhang, Pan Wang, and Zhun Fan. 2023. "Speaker Recognition Based on Dung Beetle Optimized CNN" Applied Sciences 13, no. 17: 9787. https://doi.org/10.3390/app13179787