1. Introduction
The rise of intelligent transportation systems (ITSs) [
1] has led to the increased importance of traffic prediction in urban management [
2,
3,
4,
5]. As a core component of the aforementioned traffic applications, traffic prediction, which is a classical spatial–temporal prediction, has attracted the attention of many researchers. Spatial–temporal prediction mines future trends through learning historical data in time and space. Improving the accuracy of spatial-temporal prediction, especially long-term prediction, is of great significance. However, the intricate spatial–temporal dependencies pose a significant obstacle to achieving accurate spatial–temporal series prediction.
Early mathematical spatial-temporal prediction models make predictions based on statistical methods [
6,
7,
8] failed to deal with the dynamic correlations among variable parts in both the spatial and temporal dimensions. To address the weakness of statistical prediction methods, traditional shallow machine learning methods [
9,
10] emphasize the linear mapping relation that can better capture the complex inherent laws in spatial-temporal data. However, they ignore the sequence connections that perform poorly in both spatial and temporal dependencies extraction. In contrast, deep learning methods perform better in complex spatial-temporal correlation capturing.
Most existing spatial–temporal deep learning models cannot capture the fixed spatial dependencies in neighborhoods with an appropriate size and ignore multi-scale important temporal attributes, leading to a failure to match the accurate spatial correlations. To overcome the limitations, we propose the multi-scale spatial–temporal transformer network (MSSTTN) to extract information of various scales to improve spatial–temporal prediction. First, we introduce and improve the GWNN to capture multi-scale fixed spatial dependencies using different scaling parameters. Second, series decomposition and an Auto-Correlation mechanism are introduced to analyze the historical temporal patterns. Moreover, we propose to decompose the time series into different local trends, which facilitates the acquisition of temporal information at multiple scales and augments the precision of capturing temporal dependencies. The contributions of the paper are summarized as follows:
We introduced and improved the GWNN to the spatial–temporal transformer network. By making the scaling parameter learnable, the improved GWNN can aggregate the spatial features adaptively that strengthens the fixed spatial dependencies extraction.
We proposed a novel series multi-scale decomposition to enhance time series analysis by trend-cyclical parts at various scales, making MSSTTN powerful in capturing long-term dependencies.
We conducted experiments on three datasets, PEMS03, PEMS04, and PEMS08 [
11], and the results demonstrate the superiority of MSSTTN in long-term spatial–temporal prediction.
In the rest of this paper,
Section 2 discusses the related work of spatial–temporal prediction. The architecture of MSSTTN is constructed in
Section 3.
Section 4 describes the experimental settings, conducts a series of experiments, and analyzes the results. Finally, the conclusions are discussed in
Section 5.
2. Related Work
In the realm of spatial–temporal series prediction, the two primary categories of methods are statistical methods and machine learning methods.
Statistical prediction methods such as vector autoregressive (VAR) [
6], Kalman filtering model (KM) [
7], and k-nearest neighbor (KNN) [
8] can be used for the development of suitable mathematical models. However, they are limited in their capacity to extract dynamic and fixed spatial dependencies. As an upgraded version of autoregressive (AR) [
12], the VAR achieves spatial–temporal series prediction by constructing multiple equations to calculate the dynamic relationship of all endogenous variables. However, the VAR model’s limitations are evident in its inability to effectively predict spatial–temporal series due to it cannot leverage the dynamic dependencies among multiple variables. Anyway, statistical prediction methods often encounter challenges in making long-term predictions and are unable to capture dynamic spatial–temporal dependencies.
To address the weakness of these statistical prediction methods, traditional shallow machine learning methods, such as support vector machine (SVM) [
9] and random forest [
10], can better capture inherent laws but not for multivariate prediction because they emphasize nonlinear mapping relationships rather than sequence connections. As highly complex systems, recurrent neural networks (RNNs) [
13] and their variations, including long short-term memory (LSTM) [
14] and gated recurrent unit (GRU) [
15], are capable of capturing temporal correlations. The diffusion convolutional recurrent neural network (DCRNN) [
16] is a model that integrates diffusion convolution and recurrent neural networks (RNNs) to capture spatial–temporal dependencies to make a prediction. Tian et al. [
17] proposed the CNN-LSTM model by fusing the LSTM and convolutional neural network (CNN), achieving great performance in short-term prediction. Wang et al. [
18] proposed multiple CNN models for periodic multivariate time prediction. Nevertheless, limited by convolution kernel size, it is difficult to capture long-term temporal dependencies with CNNs. The proposal of a self-attention mechanism was verified as a powerful tool for long-term prediction. Spatial–temporal transformer networks (STTNs) [
19] adopts self-attention to model the temporal dependencies and achieve competitive results. The attention-based spatial–temporal graph neural network (ASTGNN) [
20] embeds CNN in self-attention to enable temporal dynamics and obtain global receptive fields that significantly improve long-term prediction accuracy. LogTrans [
21] adopts local convolution and LogSparse attention to reduce the complexity to
. Informer [
22] achieves complexity
by introducing KL-divergence-based ProbSparse attention. Autoformer [
23] presents series decomposition and utilizes a custom-designed Auto-Correlation mechanism that dramatically improves long-term prediction accuracy.
Spatial dependencies modeling is also a significant part of spatial–temporal prediction. The deep multi-view spatial–temporal network (DMVST-Net) [
24] applies local CNNs to capture the local characteristics of regions about the neighbors of each node. However, the CNNs [
25] cannot be adaptive to graph-based spatial data. Subsequent to the emergence of graph neural networks (GNNs) [
26], graph convolution networks such as ChebNet [
27] were proposed later. The temporal graph convolutional network (T-GCN) [
28] extracts spatial–temporal dependencies simultaneously through combining the GCN [
29] with GRU. Spatio-temporal graph convolutional networks (STGCN) [
30] develops a complete convolutional structure composed of the GCN and CNN that replaces convolutional and recurrent units and outperformed the baselines. STTNs introduces ChebNet to extract fixed spatial dependencies.
Nevertheless, it is challenging for GCNs to deal with hidden and dynamic spatial dependencies. GraphWaveNet [
31] learns a self-adaptive adjacent matrix for hidden spatial dependencies. ASTGNN [
20] designs a dynamic graph convolution net (DGCN) for dynamic dependencies. For calculating spatial correlations at both local and global scales, the utilization of an attention mechanism is prevalent in capturing dynamic spatial dependencies. Spatial–temporal prediction models, such as attention-based spatial–temporal graph convolutional network (ASTGCN) [
32] and STTNs, adopt attention mechanisms for dynamic spatial dependencies. Meta graph transformer (MGT) [
33] employs a multi-graph with a self-attention mechanism that achieves outstanding performance. ASTGCN [
32] applies spatial–temporal attention and spatial–temporal CNNs to make a prediction. STTNs proposes a spatial transformer structured by a self-attention layer and a ChebNet to extract the dynamic and fixed spatial dependencies simultaneously.
As mentioned before, GCNs are extensively utilized in spatial–temporal prediction. Bruna et al. [
34] adopt spectral CNN to implement the convolution on graph by graph Fourier transform. For lacking enough flexibility on feature aggregation, Xu et al. [
35] proposed graph wavelet neural network (GWNN) by substituting the graph Fourier basis with the graph wavelet basis, which results in feature aggregation within a particular neighborhood range.
3. Methodology
In this section, we describe the preliminaries and propose the multi-scale spatial–temporal transformer network (MSSTTN). Specifically, we analyze the MSSTTN by showing the overall architecture at first and then elaborating on the main components of the model: spatial transformer and temporal autoformer.
3.1. Preliminaries
We use the graph to describe the spatial topological network. V denotes the set of nodes which represent the spatial–temporal data collectors, such as traffic sensors, meteorological observation stations. is the quantity of nodes, E denotes the set of edges in the spatial networks, and is the quantity of edges. is the adjacent matrix of the spatial networks. represents the features of every node in the spatial graph at time t, where is the feature vector of node v at time t, and C is the quantity of features.
The spatial–temporal prediction is defined as follows: given the historical spatial–temporal matrices from the past time slices, the task is to predict the sequence of future spatial–temporal matrices over the next time slices.
3.2. Overall Architecture
MSSTTN is improved based on STTNs [
19], which is structured by stacked spatial–temporal blocks (ST-Blocks). Each of the ST-Blocks are comprised of a spatial transformer and a temporal transformer. The spatial transformer extracts the dynamic spatial dependencies using self-attention mechanism and fixed dependencies using a GCN layer. For long-range temporal dependencies, the temporal transformer employs self-attention mechanism to utilize more information in the time series history. In addition, MSSTTN makes multi-step predictions directly that alleviate the propagated error.
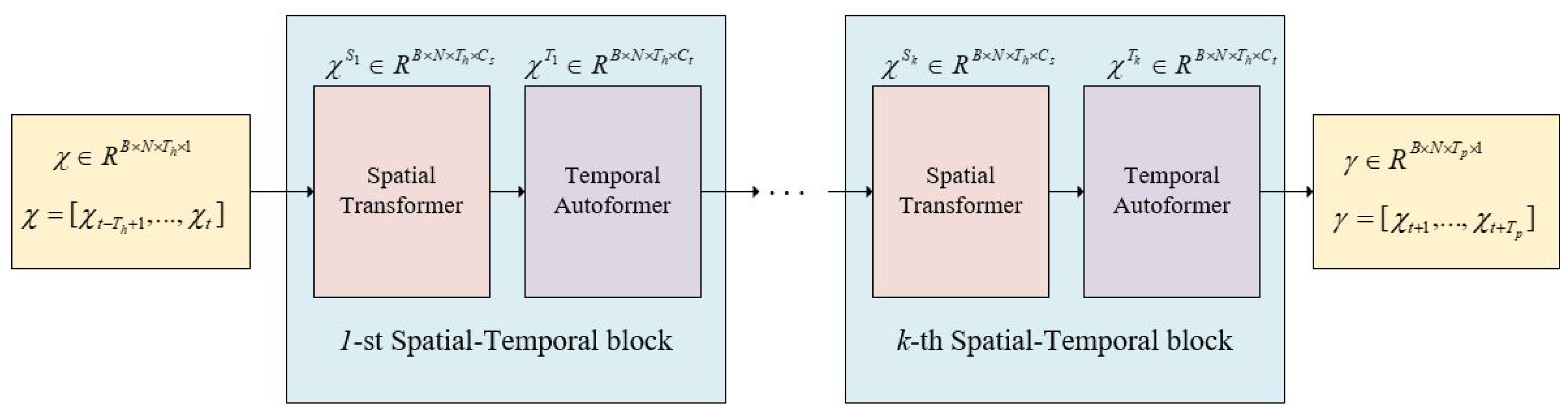
Inspired by STTNs [
19], MSSTTN learns the complicated spatial and temporal dependencies by constructing a series of spatial–temporal blocks in which every block contains both a spatial and temporal module. The comprehensive structure is presented in
Figure 1. The spatial–temporal block comprises a spatial transformer and temporal autoformer that enable the extraction of both spatial and temporal dependencies. After the extraction operations from the stacked spatial–temporal blocks, the model makes the prediction using the last block. We use
and
to denote the input and output of the
i-th spatial–temporal block. The input to the first spatial–temporal block
is the historical spatial–temporal data, where
B denotes the batch size. Then, the
k spatial–temporal blocks will be used to extract spatial–temporal dependencies from
. For the
i-th spatial–temporal block, the input
is equal to
.
and
are the spatial and temporal dependencies extraction results of the spatial transformer and temporal autoformer in the
i-th spatial–temporal block. Due to
being the input of the temporal autoformer of the
i-th spatial–temporal block,
also contains the spatial dependencies extraction results. The output of the
i-th spatial–temporal block can be described as
. The prediction results can be described as
, where
is a convolution layer and
k denotes the number of spatial–temporal blocks. By utilizing stacked spatial–temporal blocks, the MSSTTN captures the spatial–temporal dependencies and then makes predictions in the last block.
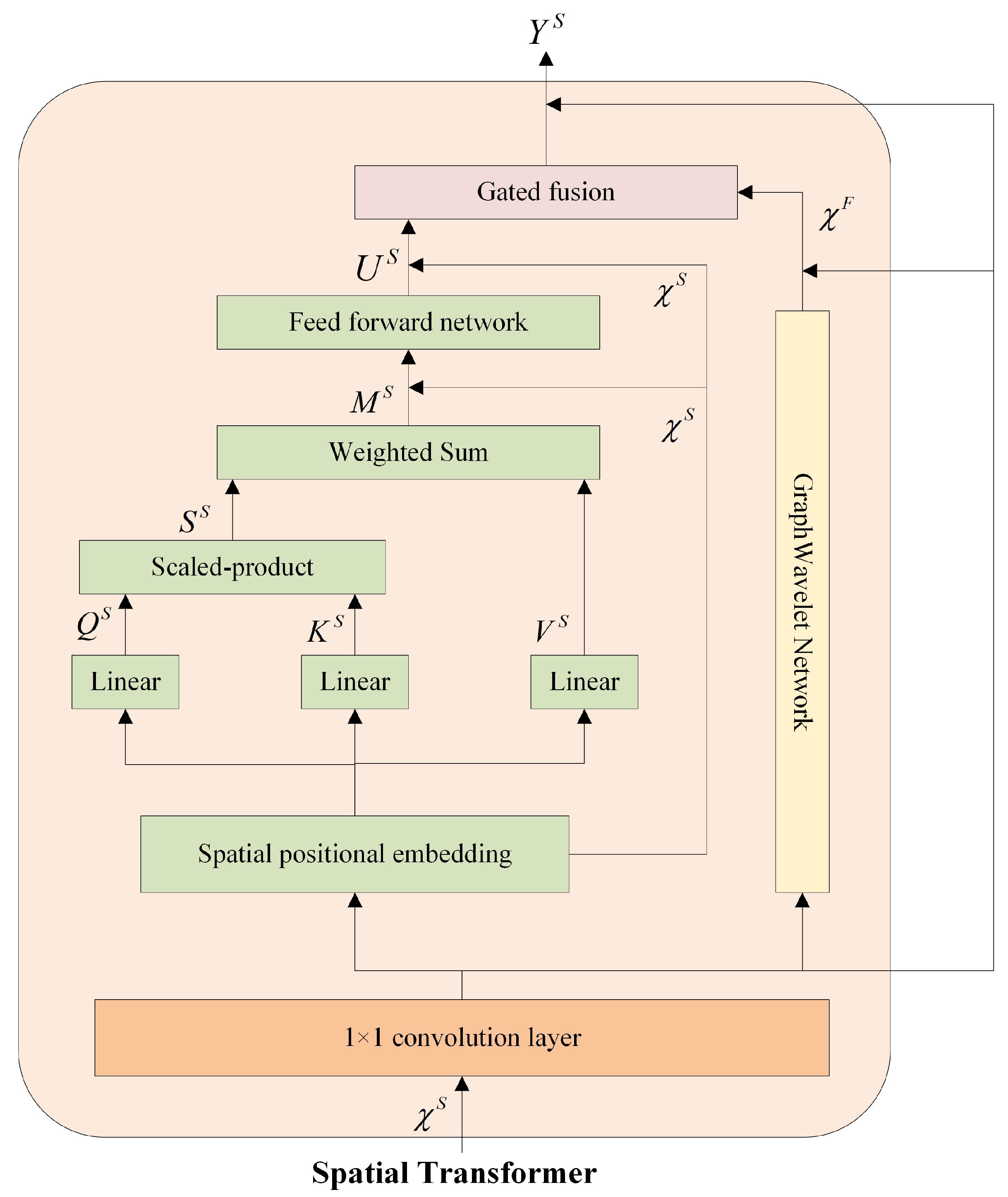
3.3. Spatial Transformer
We employ a self-attention layer to model the dynamic spatial dependencies. Furthermore, we adopt and improve the GWNN to replace the GCN to model the fixed spatial dependencies. The spatial transformer consists of the self-attention layer and improved GWNN. As illustrated in
Figure 2, the input features of the spatial transformer will be mapped to a latent high-dimensional subspace by a
convolution layer and then be utilized by the self-attention layer and the improved GWNN as the basis for computation.
3.3.1. Self-Attention Layer
As mentioned before, the self-attention mechanism is effective in capturing dynamic spatial dependencies. During the calculating process, the sizes of the queries, keys, and values are identical. We use a learnable linear function to map each node to latent high-dimensional subspaces
,
,
and then compute the spatial dependencies
:
After obtaining the spatial dependencies, we can obtain the updated spatial features
using the following formulation:
In addition, a multi-head attention mechanism can be adopted to learn different dynamic spatial dependencies by projecting the input features to various query, key, and value subspaces.
3.3.2. Improved Graph Wavelet Neural Network
Early works of convolution on graphs tended to utilize graph Fourier transform as a means of projecting graph signals into the spectral domain. The technique relies on the eigenvectors of the Laplacian matrix to facilitate the aggregation of signals on the graph. In the graph Fourier transform, the convolution operation can be described as [
27]:
where
x denotes the features on graph,
denotes the convolution operator,
y denotes the convolution kernel, ⊙ denotes the element-wise Hadamard product, and
U denotes the eigenvectors of the Laplacian matrix. Subsequently, it is feasible to replace
by a diagonal matrix
and ⊙ by matrix multiplication. So we rewrite Equation (
3) as
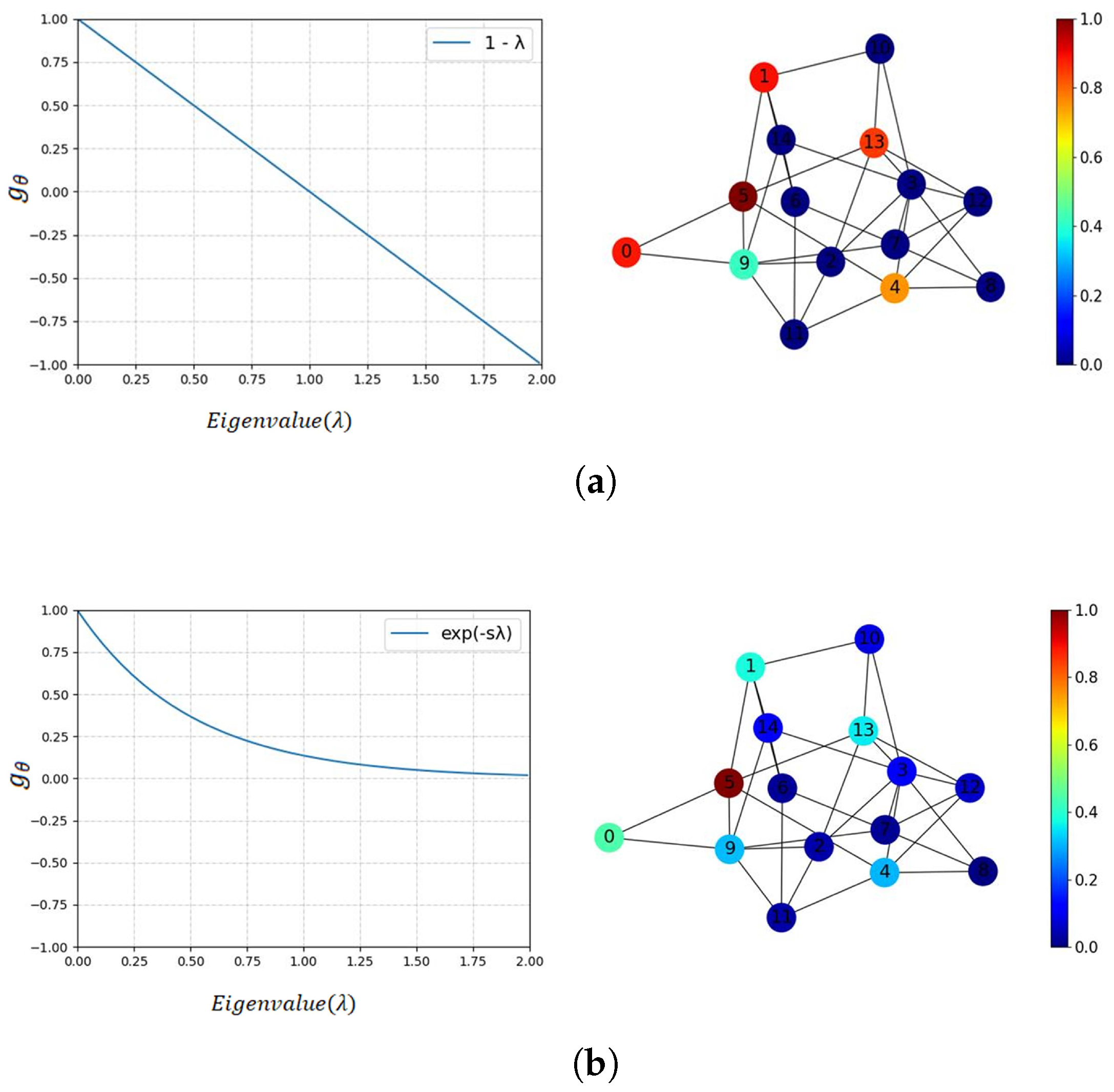
. Many kinds of spectral graph convolution neural networks (e.g., ChebNet, GCN) are based on this formulation. STTNs adopts ChebNet to extract the fixed spatial dependencies.
Xu et al. pointed out that graph convolution based on Fourier transform suffers from a restriction in graph flexibility that hinders the ability to establish suitable convolution on the graph. Thus, they proposed the GWNN, which aggregates features not only locally but flexibly. Taking the GCN (a simplified version of ChebNet) as an example, the GCN aggregates the graph signals via a Laplacian renormalization trick:
, where
,
, thus, its graph signal passing process can be described as:
where
U is the matrix of eigenvectors of the Laplacian matrix
and
is the diagonal matrix of eigenvalues. The signal passing can be described as
in the spectral domain so that it is fixed in the first-order neighborhood, as shown in
Figure 3a [
35].
In the present study, we adopt the GWNN to extract the fixed spatial dependencies and improve it by making the scaling parameter “s” learnable, enabling multi-scale graph signal passing, as shown in
Figure 4. Analogous to the graph Fourier transform, GWNN projects graph signals into the spectral domain by a set of graph wavelet basis. The graph wavelet basis are defined as
, where
is equivalent to a signal on a graph diffused away from the node
i, and
s is the scaling parameter of the graph wavelets [
35].
can be obtained using the following formulation:
where
is the scaling matrix and
,
is the eigenvalue of the Laplacian matrix. Meanwhile,
can be obtained by replacing
with
corresponding to a heat kernel [
36]. Otherwise,
and
can be efficiently calculated using a Chebyshev polynomials approximation [
35,
37]. By adjusting the scaling parameters, the neighborhood of feature aggregation can expand or shrink flexibly, as shown in
Figure 3b.
With graph wavelet bases, Equation (
3) can be replaced by:
The formulation of a GWNN layer is:
where
is the learnable weight matrix for feature transformation,
is the diagonal matrix for the graph convolution kernel, and
h is a nonlinear activation function.
The neighborhood of the original GWNN is static during the learning process. We propose a new learnable method to adjust the scaling parameter, and it assign special weights for graph signals with multi-scale frequencies. This method process feature aggregation in an adaptive neighborhood in the spatial domain.
Inspired by the self-adaptive adjacent matrix of GraphWaveNet [
31], we make the scaling parameter learnable. During the learning process, the model can adjust the scaling parameter adaptively so that the improved GWNN can assign the weights on graph signals of frequencies of multi-scale as appropriately as possible. To learn the scale parameter stably, we use two learnable vectors
and
to obtain it:
Through the learnable scaling parameter, the GWNN can explore multi-scale graph signals propagation and learn the most suitable feature aggregation scale. In this paper, we use a two-layer improved GWNN to capture the fixed spatial dependencies.
3.4. Temporal Autoformer
Compared with the self-attention mechanism, autoformer performs better in long-term dependencies capturing by adopting series decomposition and the period-based Auto-Correlation mechanism. So we introduce and improve the framework of autoformer to extract the temporal dependencies.
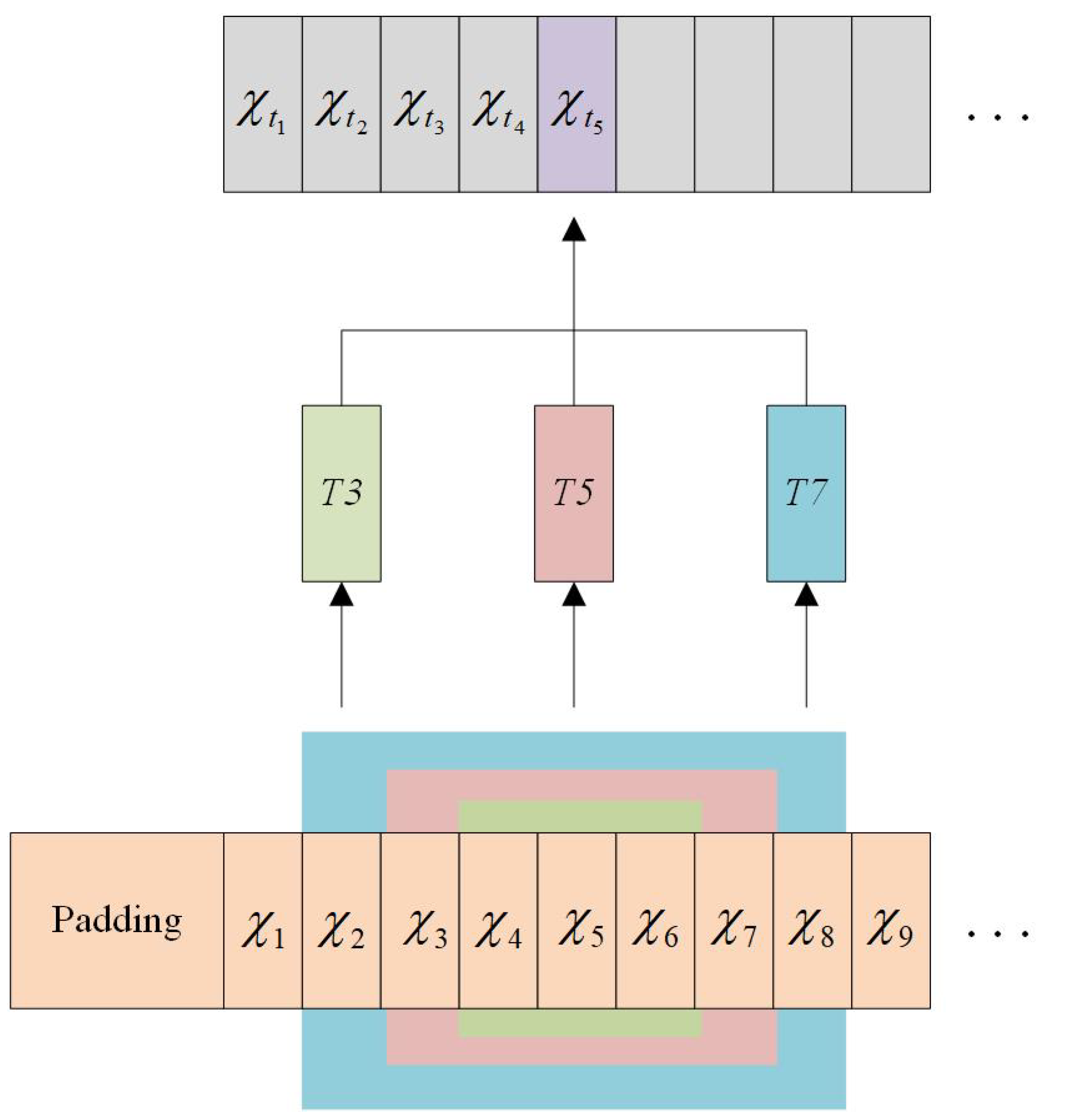
3.4.1. Series Multi-Scale Decomposition
The series decomposition block is an intrinsic operation of autoformer [
23], which uses the moving average technique to mitigate cyclic fluctuations and accentuate prolonged patterns. Suppose that there is an input series
, the original series decomposition can be described as:
where
,
refer to the extracted trend-cyclical and seasonal part, respectively, and
k denotes the kernel size of the
operation. The original series decomposition in autoformer only utilizes a single kernel to extract the trend-cyclical part of the time series. So the series decomposition can only be aware of a certain fixed local trend and the series analysis may be inadequate. In this paper, we propose multi-scale decomposition, which can analyze the series in a multi-scale manner. As shown in
Figure 5, the series is decomposed into various sized windows with different scales 3, 5, and 7, so that the series decomposition can be analyzed at various scales. Then, the formulation can be redefined as:
where
K is the set of various scales of the average pooling windows, and
is the size of
K. We use
to summarize Equation (
10).
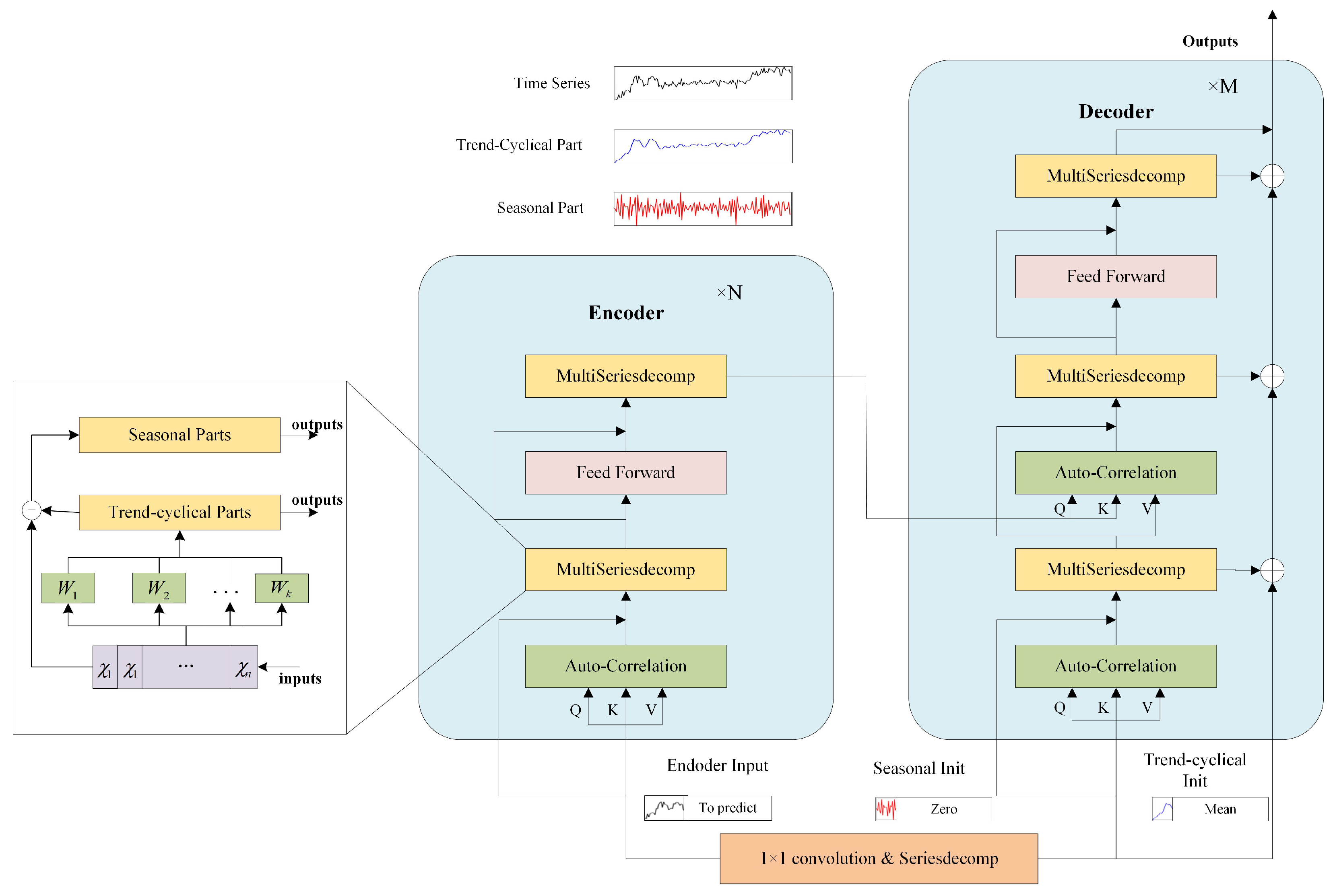
3.4.2. The Overall Architecture of Improved Autoformer
The architecture of improved temporal autoformer is shown in
Figure 6 [
23]. It is obvious that the temporal autoformer adopts the encoder–decoder structure. For the encoder, the inputs are the processed features in the past
I time steps
. For the decoder, the inputs contain both the seasonal and trend-cyclical parts of the processed features
.
O represents the future length. The details are:
where
are the placeholders filled with 0 and
are the placeholders populated with the mean values of
.
Both encoder and decoder consist of Auto-Correlation, multi-scale series decomposition, and feed forward networks. Auto-Correlation mechanism employs the connection of sub-series exhibiting similar characteristics through the application of time delay aggregation. The encoder only retains the seasonal part after multi-scale series decomposition. The equation denoting the formulation of the
l-th encoder layer can be expressed as
, where N represents the total number of encoder layers. The decoder is composed of an accumulation structure to handle multi-scale trend-cyclical components, as well as a stacked Auto-Correlation mechanism to address seasonal components. Extracting temporal trend features at different scales through automatic multi-scale series decomposition, the model can obtain more comprehensive temporal information, then strengthen the ability of encoders and decoders to extract temporal dependencies of different scales and achieve multi-scale temporal feature fusion. Assuming the existence of
M decoder layers, the formulation of the
l-th decoder layer can be succinctly summarized by
. Then, the output of the decoder can be obtained by:
where
and
is the weight matrix for seasonal and trend-cyclical components, respectively.
4. Experiment
In this section, we evaluate the newly proposed MSSTTN model with three real-world spatial–temporal datasets, and then compare its performance with classic models. Furthermore, we conduct ablation experiments to validate the effectiveness of the improvements in MSSTTN.
4.1. Datasets
The MSSTTN model is assessed on real-world datasets, namely, PEMS03, PEMS04, and PEMS08. These three traffic datasets pertain to the flow of highway traffic and was procured from the PeMS (performance measurement system) of the California Department of Transportation [
11]. The datatype of the datasets is traffic flow, and the flow data of each dataset were collected every five minutes. The number of sensors and the time range are depicted in
Table 1. The road topology information will be represented by an adjacency matrix in the experiments.
4.2. Metrics and Baselines
The evaluation metrics we applied for the performance of the models were mean absolute error (MAE), mean absolute percentage error (MAPE), and root mean square error (RMSE). Suppose that
are the actual values and
are the corresponding prediction values. The formulations of MAE, MAPE, and RMSE are as follows:
To conduct the comparison experiments, we selected the following proposed models:
FC-LSTM. A network that combines long- and short-term memory networks with full connection [
38].
STGCN. Spatio-temporal graph convolutional network, a network that integrates graph convolution with one-dimensional convolutional units [
30].
DCRNN. Diffusion convolutional recurrent neural network, a network that integrates an RNN with diffusion convolution [
16].
ASTGCN. Attention-based spatio-temporal graph convolutional network, a network that adopts spatio-temporal attention for spatial–temporal prediction [
32].
GraphWaveNet. A network that proposes an adaptive adjacency matrix with 1-D diffusion convolution in graph convolution [
31].
STTNs. Spatial–temporal transformer network, a network which is based on the self-attention mechanism and makes prediction by stacked spatial–temporal blocks [
19].
ASTGNN. Attention-based spatial–temporal graph neural network, a network that adopts dynamic GCN and a trend-aware attention mechanism [
20].
FOGS. First-order gradient supervision, a spatial–temporal model that utilizes first-order gradients to train and a learning-based spatial–temporal correlation graph to make predictions [
39].
4.3. Experimental Settings
The datasets are divided into training and testing sets at an 8:2 ratio. The data inputs for the model are subjected to min–max normalization. The learning rate during the training process is set to 0.001 and decayed by 5% for PEMS03&08 and 4% for PEMS04 every 100 generations. The batch sizes for PEMS03, PEMS04, and PEMS08 are 32, 32, and 48, respectively. The dropout rate is set at 0.03, and the models are trained for 40 epochs. The optimization algorithm used is Adam [
40], and the loss function employed is mean squared error (MSE). The model utilized three spatial–temporal blocks. In the spatial transformer, the channel size is 48, and a single head is used. The initial scaling parameter of GWNN is set to 1.0. In the autoformer, the parameter and multi-scale windows
K are set to 256 and [3, 5, 7], respectively, and the number of layers of the encoder and decoder are set to 1, 2. For a comprehensive comparison of all methods, we input the past 12 time steps (60 min) of data and forecast the subsequent 12 time steps (60 min), followed by evaluating performance on the predicted data at 3, 6, and 12 time steps (15, 30, and 60 min) for all datasets. Additionally, the data from the 9th time step for PEMS03 is taken into account for evaluation. In each training epoch, the datasets are shuffled, resulting in a disordering of the input data distribution in the temporal domain.
4.4. Experiment Results
The experimental environment is depicted in
Table 2. The comparisons on three datasets are depicted in
Table 3,
Table 4 and
Table 5, respectively. The best results are bold and the second-best results are italic. We can make the following conclusions:
FC-LSTM performs worst among all the methods. This method models the spatial features via a fully connected layer, so it performs worse with increasing prediction length compared with other models.
As another typical RNN-based spatial–temporal prediction model, the performance of DCRNN is unsatisfactory compared with the others. The reason is that RNN is limited by its short and long-term dependencies extraction.
ASTGCN and GraphWaveNet perform better than STGCN overall because the former introduces attention mechanism and the latter adopts the adaptive adjacent matrix. This verifies that the attention mechanism and dynamic spatial dependencies modeling are effective.
STTNs is mainly composed of the self-attention mechanism and outperforms the ASTGCN, which fuses the attention mechanism with CNNs. This demonstrates that the self-attention mechanism captures the inner correlations in the series, improving the weights of important parameters that can better extract features of various scale.
Making the self-attention mechanism trend-aware and predicting the future data autoregressively, ASTGNN performs best in short-term prediction but is inferior in long-term prediction compared to the proposed MSSTTN and STTNs. It demonstrates that an autoregressive manner accumulates more errors in prediction.
Adopting learned graph and first-order gradients, FOGS performs relatively better on short-term than long-term predictions.
The MSSTTN model proposed in this study exhibits superior performance in long-term prediction across all datasets, achieving state-of-the-art results. Specifically, it is evident that the longer the future time steps, the better the prediction performances are. This verifies that MSSTTN is a powerful model for long-term spatial–temporal prediction. For the third step data prediction, MSSTTN fails to outperform all the baselines. This is because short-term patterns in spatial-temporal data are not complex, and the self-attention mechanism and CNNs can obtain their trend of change more accurately without excessive information exploitation. For the long-term patterns in spatial-temporal data, the GWNN improved by the multi-scale manner and autoformer improved by multi-scale series decomposition can enhance the spatial-temporal information utilization enormously compared to pure deep learning. MSSTTN has best performance in dealing with long-term spatial–temporal prediction.
MSSTTN is improved based on STTNs, and the result that MSSTTN outperforms STTNs demonstrates that the improvements through multi-scale manners we make are practical. MSSTTN remains the dynamic spatial dependencies extraction module and then applies the scaling-learnable GWNN and autoformer with multi-scale series decomposition to improve the ability to capture fixed spatial dependencies and long-term temporal dependencies in a multi-scale manner. The results of the comparison experiments verify this.
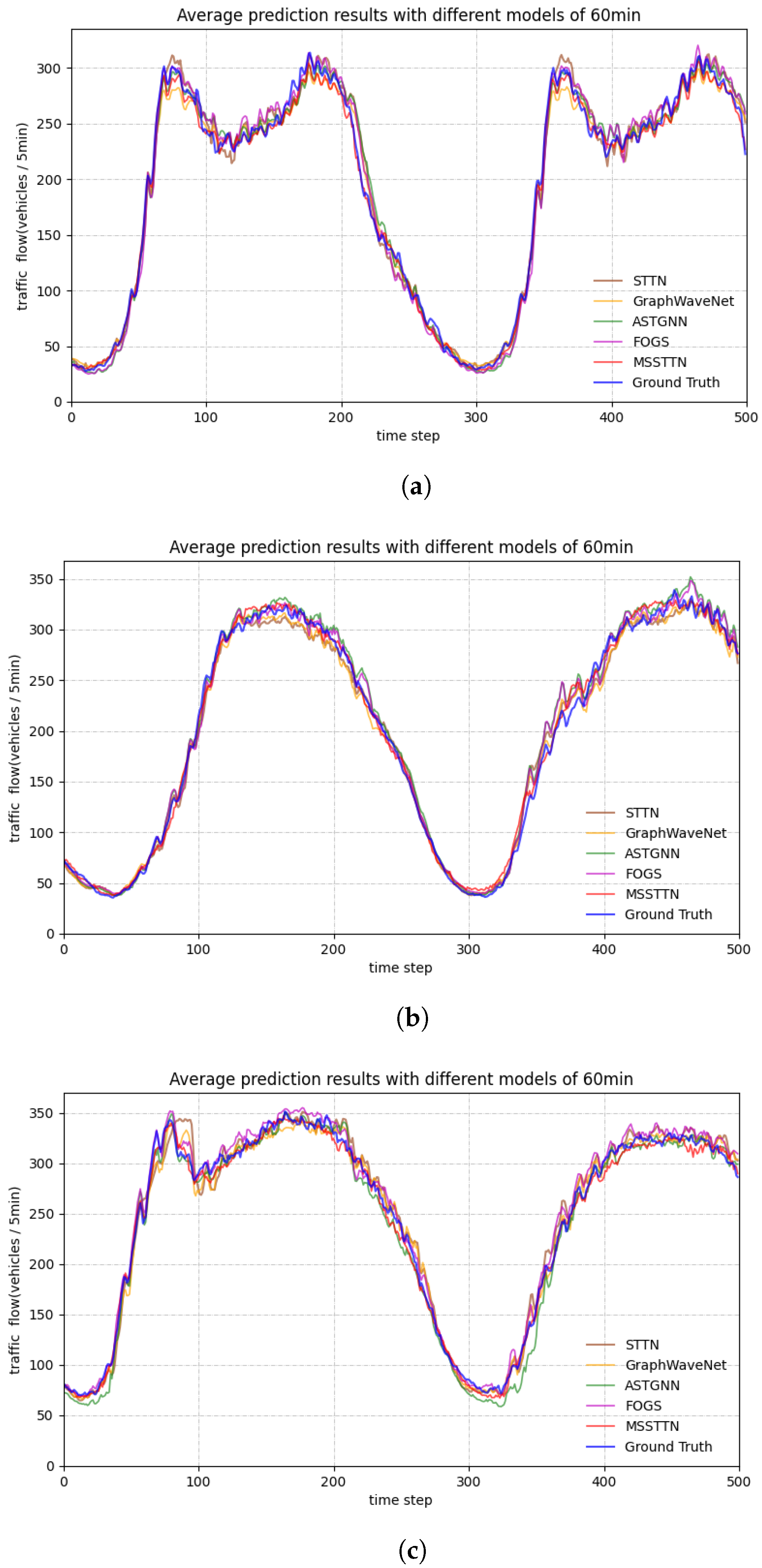
Figure 7 shows the 60 min prediction results on three datasets as examples, and it is obvious that the prediction data made by MSSTTN is closest to the actual real-world data.
4.5. Ablation Experiments
This section presents a comprehensive analysis of the proposed MSSTTN model through extensive experiments conducted on the PEMS04 dataset. The aim is to verify the aforementioned improvement.
For the temporal aspect, we design two ablation versions of MSSTTN:
- (1)
MSSTTN-attn. This model removes the improved autoformer and replaces it with a self-attention-based transformer structure.
- (2)
MSSTTN-single-i. This model extracts the trend-cyclical part by a single scale i that removes the multi-scale series decomposition.
For the spatial aspect, we also design two ablation versions of MSSTTN:
- (1)
MSSTTN-GCN. This model replaces the improved GWNN with a two-layer GCN.
- (2)
MSSTTN-fixed. This model disables the scaling parameter learning so that the GWNN doesn’t learn adaptive weights on graph signals of multi-scale frequencies.
Table 6 shows the MAE, MAPE, and RMSE of 3, 6, 9, and 12 (15, 30, 45, and 60 min) prediction results of MSSTTN and the ablation models. Every hyperparameter setting in the unablated modules are the same as described in
Section 4.2. From
Table 6, we can conclude that:
From the spatial aspect, the MSSTTN-fixed outperforms the MSSTTN-GCN, demonstrating that for capturing the fixed spatial dependencies, the GWNN is naturally more appropriate than GCN, which aggregates the features inflexibly. Then, paying attention to the comparison of MSSTTN and MSSTTN-fixed, the overall performances of MSSTTN are all better. This validates that learning adaptive neighborhoods to enable graph signals passed in a multi-scale manner can improve the prediction precision.
From the temporal aspect, MSSTTN-attn performs worst, verifying that the time series analysis and period-based operation can strengthen the temporal dependencies modeling, especially in the long-term. Comparing all the MSSTTN(single-i), we can observe that the appropriate long-term trend is more valuable than the short-term trend for capturing temporal dependencies. MSSTTN outperforms all the MSSTTN(single-i), demonstrating that each of the various scale trend-cyclical parts is helpful for time series analysis, so the multi-scale series decomposition we propose is an effective method. Through all the ablation experiments, we can easily understand the usefulness of all the improvements we have made.
4.6. Hyperparameter Analysis
We conduct a series of experiments on PEMS04 to analyze the impact of hyperparameter tuning. The investigated hyperparameters are the number of encoder and decoder layers of the temporal autoformer, the number of spatial–temporal blocks, and the learning rate decay.
Table 7 exhibit the results. The hyperparameter settings are the same as depicted in
Section 4.2 except for the investigated changes. We can see that the proposed model is not sensitive to the number of encoder and decoder layers of temporal autoformer and is relatively sensitive to the number of spatial–temporal blocks.
4.7. Comparison on Rush Hours
We compare the results on rush hours in PEMS04 of MSSTTN and the four state-of-the-art baselines in
Table 8. The rush hours are considered 8:00–20:00. It is obvious that MSSTTN performs relatively poorly on short-term prediction (15 min) but still outperforms the baselines on long-term prediction. This verifies that the robustness of MSSTTN is excellent.
5. Conclusions
This paper proposes a novel model for long-term spatial–temporal prediction called multi-scale spatial–temporal transformer network that is based on an improved STTNs. Introducing the GWNN and autoformer, MSSTTN models spatial–temporal dependencies in a multi-scale manner. We enable the scaling parameter to be learnable to pass the graph signals and construct a trend-cyclical part extraction method in a multi-scale manner to enhance the time series analysis. Otherwise, the series decomposition and Auto-Correlation mechanism in autoformer endow MSSTTN with powerful time series analysis ability. Based on series decomposition, this paper proposes a multi-scale decomposition method using windows of various scales to enhance the time series analysis ability. Experiments on three real-world datasets demonstrate that MSSTTN is superior in long-term spatial–temporal prediction.
Nevertheless, the complexity of autoformer gives MSSTTN a relatively high complexity, and graph wavelets must be recomputed during scaling the parameter learning. These result in certain computations. In future work, how to reduce the model complexity and simplify the recomputing of the graph wavelets while maintaining the prediction effect is a problem worth studying.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}