
Generating Chinese Event Extraction Method Based on ChatGPT and Prompt Learning
Abstract
:1. Introduction
2. Related Work
3. Model
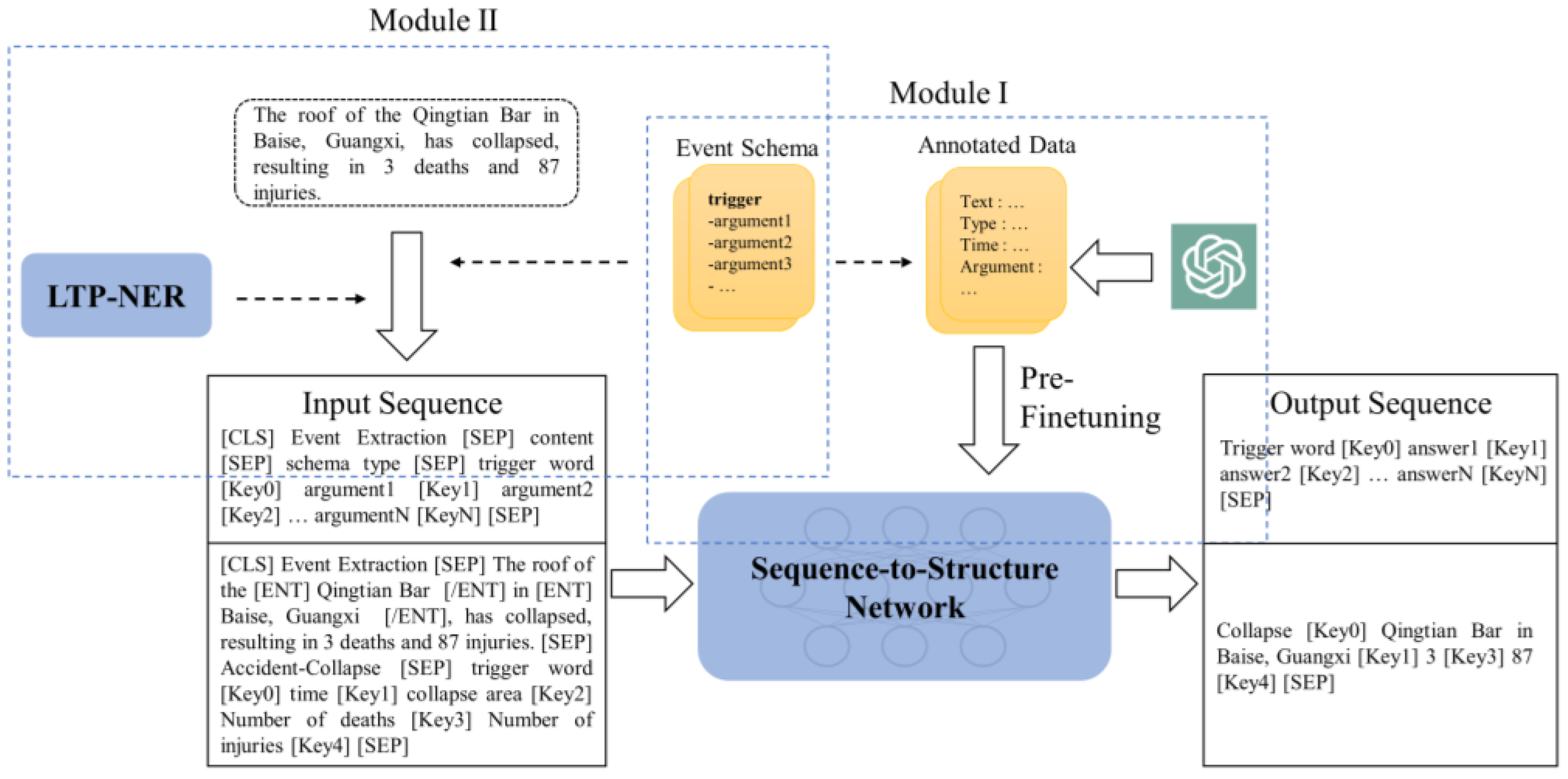
3.1. Generative Event Extraction Framework
- Based on known event knowledge, through the interaction with ChatGPT under the rule template, the event extraction annotation corpus is used to pre-train the model through supervised learning, adapting it to downstream tasks (pre-finetuning).
- Combining prompt learning and construct input templates for generative models, in these templates they explicitly incorporate entity markers and event knowledge to fully leverage the pre-trained language model’s prior knowledge.
3.2. Annotation Data Generation Based on ChatGPT
- Recall module: A continuous dialogue is established to allow ChatGPT to recall the event extraction knowledge it acquired during training. During this phase, questions related to event extraction and requests for data generation are posed to ChatGPT while continuously guiding and correcting its answers. Through extensive training on a large amount of textual data, ChatGPT learns the inherent logic of language and improves its generative ability by predicting the next word or sentence, accumulating a significant amount of semantic knowledge. In the first phase, an “activation question library” related to event extraction is created after multiple attempts. By continuously asking ChatGPT questions from the “activation question library”, the model is guided to recall the knowledge it acquired during training regarding event extraction. The “activation question library” includes the basic definition of event extraction tasks, particularly the meaning of trigger words and event arguments, the construction of commonly used datasets for event extraction, and relevant examples. Correct answers are encouraged and supported, while incorrect answers are corrected and guided, thus activating ChatGPT’s relevant knowledge on event extraction and establishing sufficient contextual connections.
- Generation module: To enable ChatGPT to generate sentences that meet the task requirements in various contexts based on given trigger words and event arguments, the process begins with the random extraction of event trigger words. A trigger word is randomly selected from a schema event library as the trigger word for the current task. Then, a question-and-answer filling mechanism based on rules is used to ask ChatGPT about the corresponding event arguments for the newly initiated conversation based on the trigger word. The randomly extracted trigger word and its related event arguments are combined to form the task requirements for the current iteration. The task requirements and different contextual prompts are then inputted into ChatGPT. Through leveraging prior knowledge and guided by the dialogue, ChatGPT is directed to generate sentences in various contexts that fulfill the task requirements. Finally, the generated corpus is manually reviewed and edited to ensure quality and accuracy. Human intervention allows for better control over the content and logic of the generated corpus while eliminating potential errors or inappropriate text.
3.3. Generative Input Template Construction
- Entity prompts are introducing to encode entities in the text explicitly. Namely, the Named Entity Recognition (NER) technique from the LTP (Language Technology Platform) is employed to identify entities in the input text. Afterwards, semantic entity markers are explicitly added on both sides of the entities, incorporating entity information into the input sequence. Taking Figure 3 as an example, for the sentence “NIO has laid off 62 employees in the United States, affecting multiple departments.” the entity “NIO” is recognized. While constructing the input template, an entity semantic marker is added as “[ENT] NIO [/ENT]”.
- The event schema is introduced as event information and added to the input sequence. Specifically, at the beginning of the text, “Event Extraction” is added as a task prompt to indicate the current task mode to the model. Then, the event schema, including the trigger words and event arguments, is enumerated and concatenated to the end of the text, constraining the generated label content.
- Negative samples are randomly generated in two ways during training. Firstly, incorrect event schemas are intentionally added as event information to the input sequence, making it impossible for the text to correspond effectively to the event schema. For example, they are combining the topic “Lay off” with the event type “Strike”. Secondly, incorrect event arguments are added to the correct event schema and included as event information in the input sequence, causing the model to fail to find the correct label corresponding to the incorrect event argument and, for instance, adding the wrong event argument “Suspension period.” to the event information for “Lay off”. By introducing negative samples into the training data, the model can learn to differentiate between correct and incorrect answers and become more inclined to generate the copyrighters during the generation process.
4. Experimental Analysis
4.1. Experimental Datasets
4.2. Experimental Results
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Hogenboom, F.; Frasincar, F.; Kaymak, U.; de Jong, F.; Caron, E. A Survey of Event Extraction Methods from Text for Decision Support Systems. Decis. Support Syst. 2016, 85, 12–22. [Google Scholar] [CrossRef]
- Garofolo, J. Automatic Content Extraction (ACE); University of Pennsylvanial: Philadelphia, PA, USA, 2005. Available online: http://itl.gov/iad/mig/-tests/ace/2005 (accessed on 3 October 2021).
- Walker, C.; Strassel, S.; Medero, J.; Maeda, K. ACE 2005 Multilingual Training Corpus LDC2006T06; Web Download; Linguistic Data Consortium: Philadelphia, PA, USA, 2006. [Google Scholar]
- Satyapanich, T.; Ferraro, F.; Finin, T. CASIE: Extracting Cybersecurity Event Information from Text. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 8749–8757. [Google Scholar] [CrossRef]
- Lewis, M.; Liu, Y.; Goyal, N.; Ghazvininejad, M.; Mohamed, A.; Levy, O.; Stoyanov, V.; Zettlemoyer, L. BART: Denoising Sequence-to-Sequence Pre-Training for Natural Language Generation, Translation, and Comprehension. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 5–10 July 2020; Association for Computational Linguistics: Cedarville, OH, USA, 2020; pp. 7871–7880. [Google Scholar]
- Riloff, E. Automatically Constructing a Dictionary for Information Extraction Tasks. In Proceedings of the Eleventh National Conference on Artificial Intelligence, Washington, DC, USA, 11 July 1993; AAAI Press: Washington, DC, USA, 1993; pp. 811–816. [Google Scholar]
- Kim, J.-T.; Moldovan, D.I. Acquisition of Linguistic Patterns for Knowledge-Based Information Extraction. IEEE Trans. Knowl. Data Eng. 1995, 7, 713–724. [Google Scholar] [CrossRef]
- Riloff, E.; Shoen, J. Automatically Acquiring Conceptual Patterns without an Annotated Corpus. In Proceedings of the Third Workshop on Very Large Corpora, Boston, MA, USA, 30 June 1995. [Google Scholar]
- Yangarber, R. Scenario Customization for Information Extraction. Ph.D. Thesis, New York University, New York, NY, USA, 2000. [Google Scholar]
- Jiang, J. An Event IE Pattern Acquisition Method. Comput. Eng. 2005, 31, 96–98. [Google Scholar]
- Chieu, H.L.; Ng, H.T. A Maximum Entropy Approach to Information Extraction from Semi-Structured and Free Text. In Proceedings of the Eighteenth National Conference on Artificial Intelligence, Edmonton, AB, Canada, 28 July 2002; American Association for Artificial Intelligence: Washington, DC, USA, 2002; pp. 786–791. [Google Scholar]
- Llorens, H.; Saquete, E.; Navarro-Colorado, B. TimeML Events Recognition and Classification: Learning CRF Models with Semantic Roles. In Proceedings of the 23rd International Conference on Computational Linguistics (Coling 2010), Coling 2010 Organizing Committee, Beijing, China, 23–27 August 2010; pp. 725–733. [Google Scholar]
- Li, Q.; Ji, H.; Huang, L. Joint Event Extraction via Structured Prediction with Global Features. In Proceedings of the 51st Annual Meeting of the Association for Computational Linguistics, Long Papers, Sofia, Bulgaria, 4–9 August 2013; ACL: Stroudsburg, PA, USA, 2013; pp. 73–82. [Google Scholar]
- Ahn, D. The Stages of Event Extraction. In Proceedings of the Workshop on Annotating and Reasoning about Time and Events, Sydney, Australia, 23 July 2006; Association for Computational Linguistics: Stroudsburg, PA, USA, 2006; pp. 1–8. [Google Scholar]
- Chen, Y.; Xu, L.; Liu, K.; Zeng, D.; Zhao, J. Event Extraction via Dynamic Multi-Pooling Convolutional Neural Networks. In Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), Beijing, China, 26–31 July 2015; Association for Computational Linguistics: Stroudsburg, PA, USA, 2015; pp. 167–176. [Google Scholar]
- Zeng, Y.; Yang, H.; Feng, Y.; Wang, Z.; Zhao, D. A Convolution BiLSTM Neural Network Model for Chinese Event Extraction. In Proceedings of the Natural Language Understanding and Intelligent Applications: 5th CCF Conference on Natural Language Processing and Chinese Computing, NLPCC 2016, and 24th International Conference on Computer Processing of Oriental Languages, ICCPOL 2016, Kunming, China, 2–6 December 2016; Volume 10102, pp. 275–287. [Google Scholar]
- Nguyen, T.H.; Grishman, R. Graph Convolutional Networks with Argument-Aware Pooling for Event Detection. In Proceedings of the Thirty-Second AAAI Conference on Artificial Intelligence and Thirtieth Innovative Applications of Artificial Intelligence Conference and Eighth AAAI Symposium on Educational Advances in Artificial Intelligence, New Orleans, LA, USA, 2 February 2018; AAAI Press: Washington, DC, USA, 2018; pp. 5900–5907. [Google Scholar]
- Li, F.; Peng, W.; Chen, Y.; Wang, Q.; Pan, L.; Lyu, Y.; Zhu, Y. Event Extraction as Multi-Turn Question Answering. In Proceedings of the Findings of the Association for Computational Linguistics: EMNLP 2020, Online, 16–20 November 2020; Association for Computational Linguistics: Stroudsburg, PA, USA, 2020; pp. 829–838. [Google Scholar]
- Du, X.; Cardie, C. Event Extraction by Answering (Almost) Natural Questions. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), Online, 16–20 November 2020; Association for Computational Linguistics: Stroudsburg, PA, USA, 2020; pp. 671–683. [Google Scholar]
- Yu, Y.F.; Zhang, Y.; Zuo, H.Y.; Zhang, L.F.; Wang, T.T. Multi-turn Event Argument Extraction Based on Role Information Guidance. Acta Sci. Nat. Univ. Pekin. 2023, 59, 83–91. [Google Scholar] [CrossRef]
- Ding, N.; Li, Z.; Liu, Z.; Zheng, H.; Lin, Z. Event Detection with Trigger-Aware Lattice Neural Network. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), Hong Kong, China, 3–7 November 2019; Association for Computational Linguistics: Stroudsburg, PA, USA, 2019; pp. 347–356. [Google Scholar]
- Lai, V.D.; Nguyen, T.N.; Nguyen, T.H. Event Detection: Gate Diversity and Syntactic Importance Scores for Graph Convolution Neural Networks. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), Online, 16–20 November 2020; Association for Computational Linguistics: Stroudsburg, PA, USA, 2020; pp. 5405–5411. [Google Scholar]
- Nguyen, T.H.; Cho, K.; Grishman, R. Joint Event Extraction via Recurrent Neural Networks. In Proceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, San Diego, CA, USA, 12–17 June 2016; Association for Computational Linguistics: Stroudsburg, PA, USA, 2016; pp. 300–309. [Google Scholar]
- Sha, L.; Qian, F.; Chang, B.; Sui, Z. Jointly Extracting Event Triggers and Arguments by Dependency-Bridge RNN and Tensor-Based Argument Interaction. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; Volume 32. [Google Scholar] [CrossRef]
- Sheng, J.; Guo, S.; Yu, B.; Li, Q.; Hei, Y.; Wang, L.; Liu, T.; Xu, H. CasEE: A Joint Learning Framework with Cascade Decoding for Overlapping Event Extraction. In Proceedings of the Findings of the Association for Computational Linguistics: ACL-IJCNLP 2021, Online, 1–6 August 2021; Association for Computational Linguistics: Stroudsburg, PA, USA, 2021; pp. 164–174. [Google Scholar]
- Nguyen, T.M.; Nguyen, T.H. One for All: Neural Joint Modeling of Entities and Events. Proc. AAAI Conf. Artif. Intell. 2019, 33, 6851–6858. [Google Scholar] [CrossRef]
- Lu, Y.; Lin, H.; Xu, J.; Han, X.; Tang, J.; Li, A.; Sun, L.; Liao, M.; Chen, S. Text2Event: Controllable Sequence-to-Structure Generation for End-to-End Event Extraction. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), Online, 1–6 August 2021; Association for Computational Linguistics: Stroudsburg, PA, USA, 2021; pp. 2795–2806. [Google Scholar]
- Lu, Y.; Liu, Q.; Dai, D.; Xiao, X.; Lin, H.; Han, X.; Sun, L.; Wu, H. Unified Structure Generation for Universal Information Extraction. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Dublin, Ireland, 22–27 May 2022; Association for Computational Linguistics: Stroudsburg, PA, USA, 2022; pp. 5755–5772. [Google Scholar]
- Huang, K.-H.; Hsu, I.-H.; Natarajan, P.; Chang, K.-W.; Peng, N. Multilingual Generative Language Models for Zero-Shot Cross-Lingual Event Argument Extraction. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Dublin, Ireland, 22–27 May 2022; Association for Computational Linguistics: Stroudsburg, PA, USA, 2022; pp. 4633–4646. [Google Scholar]
- Devlin, J.; Chang, M.-W.; Lee, K.; Toutanova, K. BERT: Pre-Training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), Minneapolis, MN, USA, 7 June 2019; Association for Computational Linguistics: Stroudsburg, PA, USA, 2019; pp. 4171–4186. [Google Scholar]
- Radford, A.; Narasimhan, K. Improving Language Understanding by Generative Pre-Training; OpenAI: San Francisco, CA, USA, 2018. [Google Scholar]
- Winata, G.I.; Madotto, A.; Lin, Z.; Liu, R.; Yosinski, J.; Fung, P. Language Models Are Few-Shot Multilingual Learners. In Proceedings of the 1st Workshop on Multilingual Representation Learning; Association for Computational Linguistics, Punta Cana, Dominican Republic, 11 November 2021; pp. 1–15. [Google Scholar]
- Li, X.; Li, F.; Pan, L.; Chen, Y.; Peng, W.; Wang, Q.; Lyu, Y.; Zhu, Y. DuEE: A Large-Scale Dataset for Chinese Event Extraction in Real-World Scenarios. In Proceedings of the Natural Language Processing and Chinese Computing: 9th CCF International Conference, NLPCC 2020, Zhengzhou, China, 14–18 October 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 534–545. [Google Scholar]
- Deng, H.; Zhang, Y.; Zhang, Y.; Ying, W.; Yu, C.; Gao, J.; Wang, W.; Bai, X.; Yang, N.; Ma, J.; et al. Title2Event: Benchmarking Open Event Extraction with a Large-Scale Chinese Title Dataset. In Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, Abu Dhabi, United Arab Emirates, 7–11 December 2022; Association for Computational Linguistics: Stroudsburg, PA, USA, 2022; pp. 6511–6524. [Google Scholar]
- Shao, Y.; Geng, Z.; Liu, Y.; Dai, J.; Yan, H.; Yang, F.; Zhe, L.; Bao, H.; Qiu, X. CPT: A Pre-Trained Unbalanced Transformer for Both Chinese Language Understanding and Generation. arXiv 2021, arXiv:2109.05729. [Google Scholar]
- Zhang, Z.Y.; Han, X.; Liu, Z.Y.; Jiang, X.; Sun, M.S.; Liu, Q. ERNIE: Enhanced Language Representation with Informative Entities. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 28 July–2 August 2019; Association for Computational Linguistics: Stroudsburg, PA, USA, 2019; pp. 1441–1451. [Google Scholar]
- Yang, S.; Feng, D.; Qiao, L.; Kan, Z.; Li, D. Exploring Pre-Trained Language Models for Event Extraction and Generation. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 28 July–2 August 2019; Association for Computational Linguistics: Stroudsburg, PA, USA, 2019; pp. 5284–5294. [Google Scholar]
- Xue, L.; Constant, N.; Roberts, A.; Kale, M.; Al-Rfou, R.; Siddhant, A.; Barua, A.; Raffel, C. MT5: A Massively Multilingual Pre-Trained Text-to-Text Transformer. In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Online, 6–11 June 2021; Association for Computational Linguistics: Stroudsburg, PA, USA, 2021; pp. 483–498. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Datasets | Number of Training Sets | Number of Validation Sets | Number of Test Sets | Number of Events |
|---|---|---|---|---|
| DuEE1.0 | 13,478 | 1790 | 4372 | 19,640 |
| Title2Event | 34,295 | 4286 | 4288 | 70,879 |
| Datasets | Trigger Word | Arguments | Sentence | Event Extraction |
|---|---|---|---|---|
| DuEE1.0 | layoffs | Time, Layoff Side, Number of Layoffs | 900 laid-off employees officially bid farewell to Oracle, where did those who left the foreign companies go? | {Layoff side: Oracle} {Number of Layoffs: 900} |
| Defeat | Time, loser, winner, name of the match | Atletico Madrid defeated Juve 2-0 at home, back to Juve, Crowe hat trick tease Atletico Madrid | {Winner: Atletico Madrid} {Loser: Juve} | |
| … | … | … | … | |
| Title2Event | Carry out | Subject, Object | Market supply is sufficient, prices are basically stable, consumption order is normal, Qingdao carries out special law enforcement action on price order. | {Subject: Qingdao} {Object: special law enforcement action on price order} |
| on the list | Subject, Object | Two cities in Zhejiang province on the list of China’s happiest provincial capitals and planned cities in 2021. | {Subject: Two cities in Zhejiang Province} {Object: China’s happiest provincial capitals and planned cities in 2021} | |
| … | … | … | … |
| Item No. | Trigger Word | Arguments | Sentence |
|---|---|---|---|
| 1 | Support | Participating Subjects, Participating Objects, Location | Donors generously support hospitals to expand beds and medical resources to better care for the health needs of vulnerable groups. |
| 2 | Support | Participating Subjects, Participating Objects, Location | The professional support of the maintenance staff guarantees the safety and operational efficiency of the Convention Center’s facilities and facilitates a wide variety of meetings and events for community development. |
| 3 | listing | Listing Body, Listing Date, Location | By the end of 2022, Huawei plans to list on the London Stock Exchange to strengthen its global capital markets participation and transparency. |
| … | … | … | … |
| Dataset | Model | P | R | F1 |
|---|---|---|---|---|
| DuEE1.0 | ERNIE + CRF [36] | - | - | 75.9 |
| Bert4keras [30] | 85.5 | 73.7 | 79.2 | |
| MRC [16] | 82.6 | 85.0 | 83.8 | |
| CPEE | 87.6 | 82.8 | 85.1 | |
| Title2Event | BERT-CRF [37] | 41.1 | 41.3 | 41.2 |
| MRC [16] | 44.5 | 44.8 | 44.7 | |
| Seq2seqMRC [38] | 49.8 | 50.1 | 49.9 | |
| CPEE | 62.3 | 57.8 | 59.9 |
| Model | P | R | F1 |
|---|---|---|---|
| Full model | 62.3 | 57.8 | 59.9 |
| Pre-finetuning | 59.0 | 56.6 | 57.7 |
| Prompt template | 60.8 | 55.9 | 58.2 |
| 0 | 4000 | 8000 | 12,000 | 16,000 | ||
|---|---|---|---|---|---|---|
| Title2Event | CPEE | 57.7 | 59.9 | 61.2 | 62.0 | 62.3 |
| BERT-CRF | 41.2 | 44.4 | 45.3 | 46.0 | 46.1 | |
| MRC | 44.7 | 47.9 | 49.9 | 50.9 | 51.4 | |
| Seq2seqMRC | 49.9 | 51.9 | 53.5 | 53.8 | 54.4 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, J.; Chen, P.; Wu, X. Generating Chinese Event Extraction Method Based on ChatGPT and Prompt Learning. Appl. Sci. 2023, 13, 9500. https://doi.org/10.3390/app13179500
Chen J, Chen P, Wu X. Generating Chinese Event Extraction Method Based on ChatGPT and Prompt Learning. Applied Sciences. 2023; 13(17):9500. https://doi.org/10.3390/app13179500
Chicago/Turabian StyleChen, Jianxun, Peng Chen, and Xuxu Wu. 2023. "Generating Chinese Event Extraction Method Based on ChatGPT and Prompt Learning" Applied Sciences 13, no. 17: 9500. https://doi.org/10.3390/app13179500