
A Stacking Machine Learning Method for IL-10-Induced Peptide Sequence Recognition Based on Unified Deep Representation Learning


Abstract
:1. Introduction
- To address IL-10-induced peptide recognition from sequences, we transformed arbitrary protein sequences into fixed-length vector representations using sequence-based unified representation (UniRep).
- We employed the powerful ensemble learning algorithm, stacking, to construct an IL-10-induced peptide prediction model, effectively enhancing the predictive accuracy.
- After modeling single or fused sequence features using various machine learning algorithms, we observed that the stacking model based on UniRep encoding yielded the best results. Therefore, we proposed a novel IL-10-induced peptide recognition method, IL10-Stack, with significantly superior performance compared to existing methods.
2. Materials and Methods
2.1. Computational Framework
2.2. Dataset Acquisition and Preprocessing
2.3. Feature Encoding
2.3.1. AAIndex Embedding Model
2.3.2. Pre-Trained UniRep Embedding Model
2.3.3. Feature Fusion
2.4. Feature Selection Method
2.5. Balancing Strategy
2.6. ML Algorithms
2.7. Performance Evaluation
3. Results and Discussion
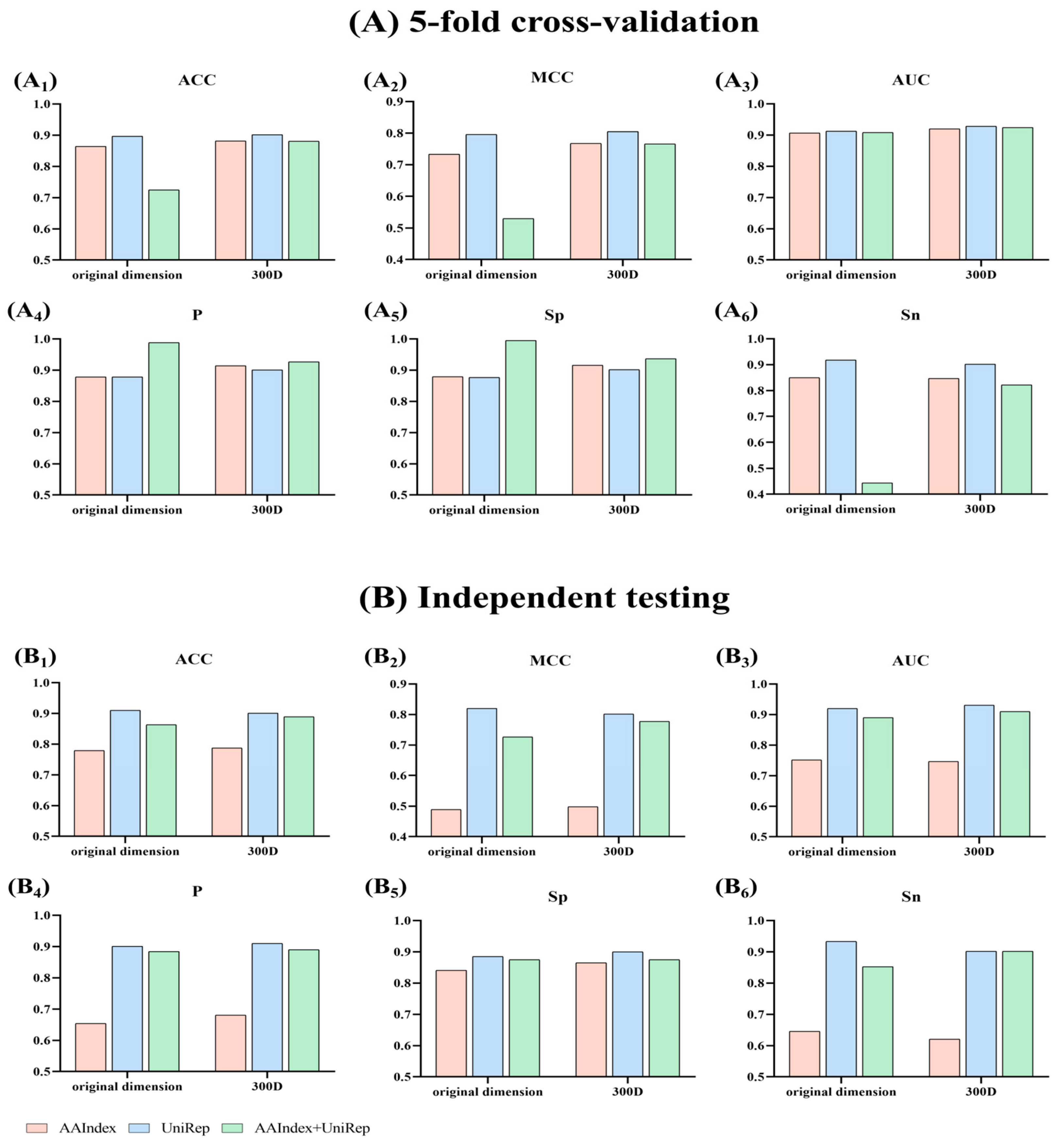
3.1. Analysis of Three Different Feature Models Based on Non-Stacking Algorithms
3.2. Analysis of Three Different Feature Models Based on Stacking
3.3. Comparison with Existing Methods
3.4. Web Server Development
4. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Hervas-Salcedo, R.; Fernandez-Garcia, M.; Hernando-Rodriguez, M.; Suarez-Cabrera, C.; Bueren, J.A.; Yanez, R.M. Improved efficacy of mesenchymal stromal cells stably expressing CXCR4 and IL-10 in a xenogeneic graft versus host disease mouse model. Front. Immunol. 2023, 14, 1062086. [Google Scholar]
- Maynard, C.L.; Weaver, C.T. Diversity in the contribution of interleukin-10 to T-cell-mediated immune regulation. Immunol. Rev. 2008, 226, 219–233. [Google Scholar] [PubMed]
- Mannino, M.H.; Zhu, Z.W.; Xiao, H.P.; Bai, Q.; Wakefield, M.R.; Fang, Y.J. The paradoxical role of IL-10 in immunity and cancer. Cancer Lett. 2015, 367, 103–107. [Google Scholar] [PubMed]
- Fiorentino, D.F.; Bond, M.W.; Mosmann, T.R. Two types of mouse T helper cell, I.V. Th2 clones secrete a factor that inhibits cytokine production by Th1 clones. J. Exp. Med. 1989, 170, 2081–2095. [Google Scholar]
- Tanaka, Y.; Nakai, T.; Suzuki, A.; Kagawa, Y.; Noritake, O.; Taki, T.; Hashimoto, H.; Sakai, T.; Shibata, Y.; Izumi, H.; et al. Clinicopathological significance of peritumoral alveolar macrophages in patients with resected early-stage lung squamous cell carcinoma. Cancer Immunol. Immunother. 2023, 72, 2205–2215. [Google Scholar]
- Zuurveld, M.; Ayechu-Muruzabal, V.; Folkerts, G.; Garssen, J.; Van’t Land, B.; Willemsen, L.E.M. Specific Human Milk Oligosaccharides Differentially Promote Th1 and Regulatory Responses in a CpG-Activated Epithelial/Immune Cell Coculture. Biomolecules 2023, 13, 263. [Google Scholar]
- Geladaris, A.; Hausser-Kinzel, S.; Pretzsch, R.; Nissimov, N.; Lehmann-Horn, K.; Hausler, D.; Weber, M.S. IL-10-providing B cells govern pro-inflammatory activity of macrophages and microglia in CNS autoimmunity. Acta Neuropathol. 2023, 145, 461–477. [Google Scholar]
- Riquelme-Neira, R.; Walker-Vergara, R.; Fernandez-Blanco, J.A.; Vergara, P. IL-10 Modulates the Expression and Activation of Pattern Recognition Receptors in Mast Cells. Int. J. Mol. Sci. 2023, 24, 9875. [Google Scholar]
- Ahmed, A.; Kohler, S.; Klotz, R.; Giese, N.; Hackert, T.; Springfeld, C.; Jager, D.; Halama, N. Sex Differences in the Systemic and Local Immune Response of Pancreatic Cancer Patients. Cancers 2023, 15, 1815. [Google Scholar] [PubMed]
- Ao, C.; Jiao, S.; Wang, Y.; Yu, L.; Zou, Q. Biological Sequence Classification: A Review on Data and General Methods. Research 2022, 2022, 0011. [Google Scholar]
- Wang, H.; Guo, F.; Du, M.; Wang, G.; Cao, C. A novel method for drug-target interaction prediction based on graph transformers model. BMC Bioinform. 2022, 23, 459. [Google Scholar]
- Zhang, Z.; Cui, F.; Wang, C.; Zhao, L.; Zou, Q. Goals and approaches for each processing step for single-cell RNA sequencing data. Brief. Bioinform. 2020, 22, bbaa314. [Google Scholar]
- Zhang, Z.; Cui, F.; Cao, C.; Wang, Q.; Zou, Q. Single-cell RNA analysis reveals the potential risk of organ-specific cell types vulnerable to SARS-CoV-2 infections. Comput. Biol. Med. 2021, 140, 105092. [Google Scholar] [PubMed]
- Chao, W.; Quan, Z. A Machine Learning Method for Differentiating and Predicting Human-Infective Coronavirus Based on Physicochemical Features and Composition of the Spike Protein. Chin. J. Electron. 2021, 30, 815–823. [Google Scholar]
- Cui, F.; Li, S.; Zhang, Z.; Sui, M.; Cao, C.; El-Latif Hesham, A.; Zou, Q. DeepMC-iNABP: Deep learning for multiclass identification and classification of nucleic acid-binding proteins. Comput. Struct. Biotechnol. J 2022, 20, 2020–2028. [Google Scholar]
- Zhang, Z.; Cui, F.; Zhou, M.; Wu, S.; Zou, Q.; Gao, B. Single-cell RNA Sequencing Analysis Identifies Key Genes in Brain Metastasis from Lung Adenocarcinoma. Curr. Gene Ther. 2021, 21, 338–348. [Google Scholar] [CrossRef]
- Mendes, M.; Mahita, J.; Blazeska, N.; Greenbaum, J.; Ha, B.; Wheeler, K.; Wang, J.Y.; Shackelford, D.; Sette, A.; Peters, B. IEDB-3D 2.0: Structural data analysis within the Immune Epitope Database. Protein Sci. 2023, 32, e4605. [Google Scholar]
- Tirziu, A.; Avram, S.; Mada, L.; Crișan-Vida, M.; Popovici, C.; Popovici, D.; Faur, C.; Duda-Seiman, C.; Paunescu, V.; Vernic, C. Design of a Synthetic Long Peptide Vaccine Targeting HPV-16 and -18 Using Immunoinformatic Methods. Pharmaceutics 2023, 15, 1798. [Google Scholar]
- Nagpal, G.; Usmani, S.S.; Dhanda, S.K.; Kaur, H.; Singh, S.; Sharma, M.; Raghava, G.P.S. Computer-aided designing of immunosuppressive peptides based on IL-10 inducing potential. Sci. Rep. 2017, 7, 42851. [Google Scholar] [CrossRef]
- Singh, O.; Hsu, W.-L.; Su, E.C.-Y. ILeukin10Pred: A Computational Approach for Predicting IL-10-Inducing Immunosuppressive Peptides Using Combinations of Amino Acid Global Features. Biology 2022, 11, 5. [Google Scholar]
- Liu, H.; Xu, Y.; Chen, F. Sketch2Photo: Synthesizing photo-realistic images from sketches via global contexts. Eng. Appl. Artif. Intell. 2023, 117, 105608. [Google Scholar] [CrossRef]
- Liu, M.; Zhang, X.; Yang, B.; Yin, Z.; Liu, S.; Yin, L.; Zheng, W. Three-Dimensional Modeling of Heart Soft Tissue Motion. Appl. Sci. 2023, 13, 2493. [Google Scholar] [CrossRef]
- Yang, B.; Li, Y.; Zheng, W.; Yin, Z.; Liu, M.; Yin, L.; Liu, C. Motion prediction for beating heart surgery with GRU. Biomed. Signal Process. Control 2023, 83, 104641. [Google Scholar] [CrossRef]
- Yang, S.; Li, Q.; Li, W.; Li, X.; Liu, A.A. Dual-Level Representation Enhancement on Characteristic and Context for Image-Text Retrieval. IEEE Trans. Circ. Syst. Video Technol. 2022, 32, 8037–8050. [Google Scholar] [CrossRef]
- Waziry, S.; Wardak, A.B.; Rasheed, J.; Shubair, R.M.; Rajab, K.; Shaikh, A. Performance comparison of machine learning driven approaches for classification of complex noises in quick response code images. Heliyon 2023, 9, e15108. [Google Scholar] [CrossRef] [PubMed]
- Farooq, M.S.; Khalid, H.; Arooj, A.; Umer, T.; Asghar, A.B.; Rasheed, J.; Shubair, R.M.; Yahyaoui, A. A Conceptual Multi-Layer Framework for the Detection of Nighttime Pedestrian in Autonomous Vehicles Using Deep Reinforcement Learning. Entropy 2023, 25, 135. [Google Scholar] [CrossRef]
- Le, H.D.; Lee, G.S.; Kim, S.H.; Kim, S.; Yang, H.J. Multi-Label Multimodal Emotion Recognition With Transformer-Based Fusion and Emotion-Level Representation Learning. IEEE Access 2023, 11, 14742–14751. [Google Scholar] [CrossRef]
- Yang, L.; Yu, X.Y.; Zhang, S.P.; Zhang, H.H.; Xu, S.; Long, H.B.; Zhu, Y.W. Stacking-based and improved convolutional neural network: A new approach in rice leaf disease identification. Front. Plant Sci. 2023, 14, 1165940. [Google Scholar] [CrossRef] [PubMed]
- Kalule, R.; Abderrahmane, H.A.; Alameri, W.; Sassi, M. Stacked ensemble machine learning for porosity and absolute permeability prediction of carbonate rock plugs. Sci. Rep. 2023, 13, 9855. [Google Scholar] [CrossRef] [PubMed]
- Li, Y.J.; Ma, D.; Chen, D.; Chen, Y. ACP-GBDT: An improved anticancer peptide identification method with gradient boosting decision tree. Front. Genet. 2023, 14, 1165765. [Google Scholar] [CrossRef]
- Mardikoraem, M.; Woldring, D. Protein Fitness Prediction Is Impacted by the Interplay of Language Models, Ensemble Learning, and Sampling Methods. Pharmaceutics 2023, 15, 1337. [Google Scholar] [CrossRef]
- Bao, W.Z.; Gu, Y.J.; Chen, B.T.; Yu, H.P. Golgi_DF: Golgi proteins classification with deep forest. Front. Neurosci. 2023, 17, 1197824. [Google Scholar] [CrossRef]
- Nath, A.; Subbiah, K. The role of pertinently diversified and balanced training as well as testing data sets in achieving the true performance of classifiers in predicting the antifreeze proteins. Neurocomputing 2018, 272, 294–305. [Google Scholar] [CrossRef]
- Elreedy, D.; Atiya, A.F.; Kamalov, F. A theoretical distribution analysis of synthetic minority oversampling technique (SMOTE) for imbalanced learning. Mach. Learn. 2023, 112. [Google Scholar] [CrossRef]
- Mursalim, M.K.N.; Mengko, T.L.E.R.; Hertadi, R.; Purwarianti, A.; Susanty, M. BiCaps-DBP: Predicting DNA-binding proteins from protein sequences using Bi-LSTM and a 1D-capsule network. Comput. Biol. Med. 2023, 163, 107241. [Google Scholar] [CrossRef] [PubMed]
- Kawashima, S.; Pokarowski, P.; Pokarowska, M.; Kolinski, A.; Katayama, T.; Kanehisa, M. AAindex: Amino acid index database, progress report 2008. Nucleic Acids Res. 2008, 36, D202–D205. [Google Scholar] [CrossRef] [PubMed]
- Alley, E.C.; Khimulya, G.; Biswas, S.; AlQuraishi, M.; Church, G.M. Unified rational protein engineering with sequence-based deep representation learning. Nat. Methods 2019, 16, 1315–1322. [Google Scholar] [CrossRef] [PubMed]
- Gao, Y.; Lewis, N.; Calhoun, V.D.; Miller, R.L. Interpretable LSTM model reveals transiently-realized patterns of dynamic brain connectivity that predict patient deterioration or recovery from very mild cognitive impairment. Comput. Biol. Med. 2023, 161, 107005. [Google Scholar] [CrossRef]
- Zhao, S.; Meng, J.; Wekesa, J.S.; Luan, Y. Identification of small open reading frames in plant lncRNA using class-imbalance learning. Comput. Biol. Med. 2023, 157, 106773. [Google Scholar] [CrossRef] [PubMed]
- Cao, C.; Kossinna, P.; Kwok, D.; Li, Q.; He, J.; Su, L.; Guo, X.; Zhang, Q.; Long, Q. Disentangling genetic feature selection and aggregation in transcriptome-wide association studies. Genetics 2022, 220, iyab216. [Google Scholar] [CrossRef]
- Ao, C.; Ye, X.; Sakurai, T.; Zou, Q.; Yu, L. m5U-SVM: Identification of RNA 5-methyluridine modification sites based on multi-view features of physicochemical features and distributed representation. BMC Biol. 2023, 21, 93. [Google Scholar] [CrossRef]
- Imakura, A.; Kihira, M.; Okada, Y.; Sakurai, T. Another use of SMOTE for interpretable data collaboration analysis. Expert Syst. Appl. 2023, 228, 120385. [Google Scholar] [CrossRef]
- Jia, H.C. Simulation of English part-of-speech classification based on artificial intelligence and additive logistic regression. Soft Comput. 2023, 27. [Google Scholar] [CrossRef]
- Wang, J.F.; Huang, S.H.; Wang, Z.W.; Huang, D.; Qin, J.; Wang, H.; Wang, W.Z.; Liang, Y. A calibrated SVM based on weighted smooth GL(1/2)for Alzheimer’s disease prediction. Comput. Biol. Med. 2023, 158, 106752. [Google Scholar] [CrossRef]
- Zhang, H.; Zou, Q.; Ju, Y.; Song, C.; Chen, D. Distance-based Support Vector Machine to Predict DNA N6-methyladenine Modification. Curr. Bioinform. 2022, 17, 473–482. [Google Scholar] [CrossRef]
- Zhang, Z.; Cui, F.; Lin, C.; Zhao, L.; Wang, C.; Zou, Q. Critical downstream analysis steps for single-cell RNA sequencing data. Brief. Bioinform. 2021, 22, bbab105. [Google Scholar] [CrossRef] [PubMed]
- Li, Z.M.; Zhao, Y.; Duan, T.; Dai, J.Q. Configurational patterns for COVID-19 related social media rumor refutation effectiveness enhancement based on machine learning and fsQCA. Inf. Process. Manag. 2023, 60, 103303. [Google Scholar] [CrossRef] [PubMed]
- Hurtado, M.; Mora-Marquez, F.; Soto, A.; Marino, D.; Goicoechea, P.G.; de Heredia, U.L. DEGoldS: A Workflow to Assess the Accuracy of Differential Expression Analysis Pipelines through Gold-standard Construction. Curr. Bioinform. 2023, 18, 296–309. [Google Scholar] [CrossRef]
- Cevik, T.; Cevik, N.; Rasheed, J.; Abu-Mahfouz, A.M.; Osman, O. Facial Recognition in Hexagonal Domain—A Frontier Approach. IEEE Access 2023, 11, 46577–46591. [Google Scholar] [CrossRef]
- Cao, C.; Wang, J.; Kwok, D.; Cui, F.; Zhang, Z.; Zhao, D.; Li, M.J.; Zou, Q. webTWAS: A resource for disease candidate susceptibility genes identified by transcriptome-wide association study. Nucleic Acids Res. 2022, 50, D1123–D1130. [Google Scholar] [CrossRef]
- Zhang, Z.; Cui, F.; Su, W.; Dou, L.; Xu, A.; Cao, C.; Zou, Q. webSCST: An interactive web application for single-cell RNA-sequencing data and spatial transcriptomic data integration. Bioinformatics 2022, 38, 3488–3489. [Google Scholar] [CrossRef] [PubMed]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Classifier | ACC | MCC | AUC | P | Sp | Sn |
|---|---|---|---|---|---|---|
| IL-10Pred | 0.812 | 0.590 | 0.880 | 0.674 | 0.819 | 0.797 |
| ILeukin10Pred | 0.875 | 0.755 | 0.931 | 0.927 a | 0.947 | 0.804 |
| IL10-Fuse | 0.896 | 0.792 | 0.948 | 0.905 | 0.895 | 0.897 |
| IL10-Stack | 0.910 | 0.820 | 0.920 | 0.901 | 0.885 | 0.933 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, J.; Jiang, J.; Pei, H.; Lv, Z. A Stacking Machine Learning Method for IL-10-Induced Peptide Sequence Recognition Based on Unified Deep Representation Learning. Appl. Sci. 2023, 13, 9346. https://doi.org/10.3390/app13169346
Li J, Jiang J, Pei H, Lv Z. A Stacking Machine Learning Method for IL-10-Induced Peptide Sequence Recognition Based on Unified Deep Representation Learning. Applied Sciences. 2023; 13(16):9346. https://doi.org/10.3390/app13169346
Chicago/Turabian StyleLi, Jiayu, Jici Jiang, Hongdi Pei, and Zhibin Lv. 2023. "A Stacking Machine Learning Method for IL-10-Induced Peptide Sequence Recognition Based on Unified Deep Representation Learning" Applied Sciences 13, no. 16: 9346. https://doi.org/10.3390/app13169346