
Resizer Swin Transformer-Based Classification Using sMRI for Alzheimer’s Disease

Abstract
:1. Introduction
2. Background and Related Work
2.1. CNN-Based Classification for AD
2.2. Transformer-Based Classification for AD
2.3. Limitations of Current Methods
3. Methodology
3.1. Slice Options
3.2. Model Structure
3.2.1. Overview of Resizer Swin Transformer Network
3.2.2. CNN Module
3.2.3. Resizer Module
3.2.4. Swin Transformer
4. Evaluation
4.1. Introduction of the Datasets
4.2. Training Setup
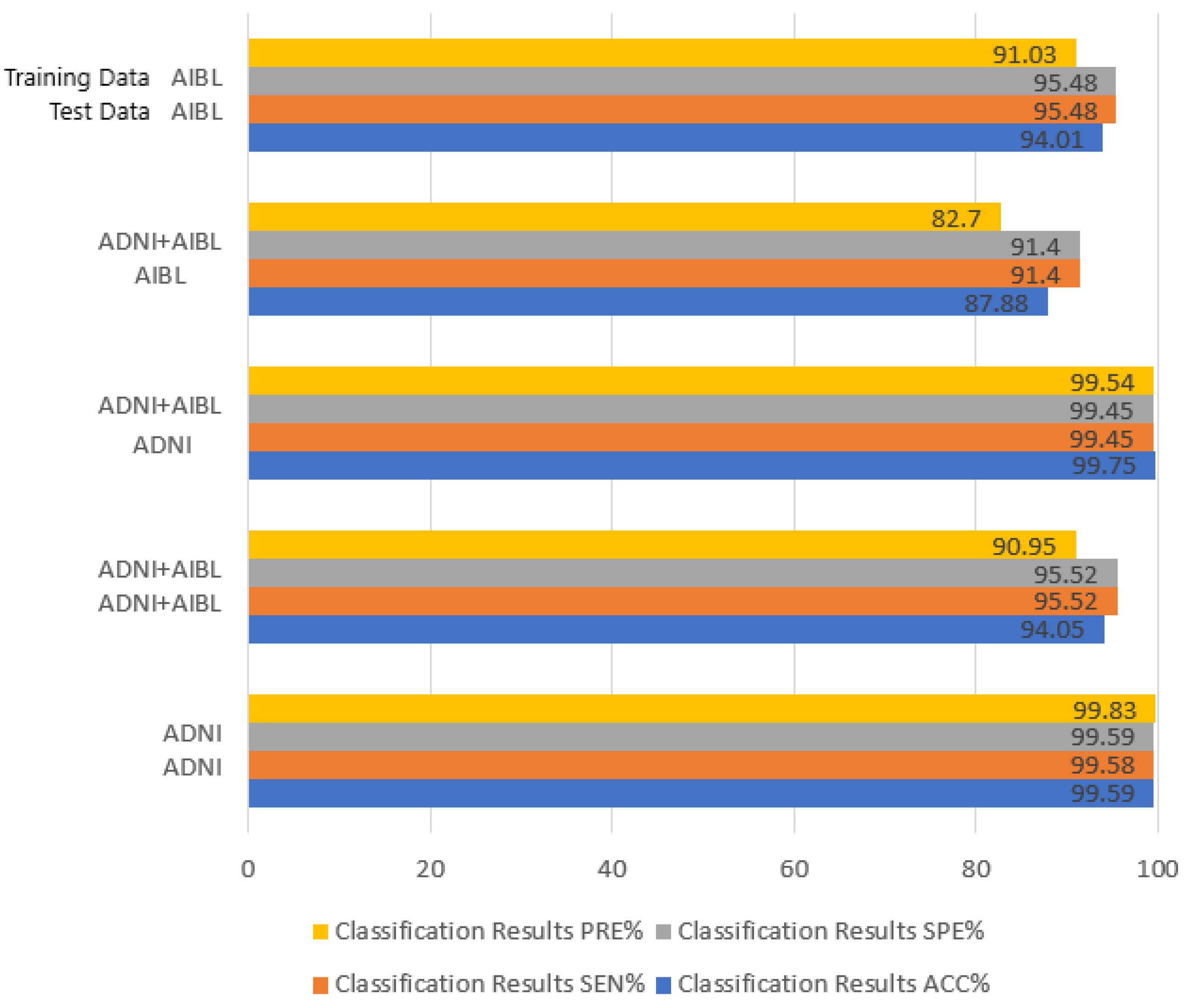
4.3. Experimental Results
4.4. Ablation Experiments
5. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Ahmed, S.T.; Kumar, V.; Kim, J. AITel: eHealth Augmented Intelligence based Telemedicine Resource Recommendation Framework for IoT devices in Smart cities. IEEE Internet Things J. 2023. [Google Scholar] [CrossRef]
- Burgos, N.; Colliot, O. Machine learning for classification and prediction of brain diseases: Recent advances and upcoming challenges. Curr. Opin. Neurol. 2020, 33, 439–450. [Google Scholar] [CrossRef] [PubMed]
- Segato, A.; Marzullo, A.; Calimeri, F.; De Momi, E. Artificial intelligence for brain diseases: A systematic review. APL Bioeng. 2020, 4, 041503. [Google Scholar] [PubMed]
- Cai, L.; Gao, J.; Zhao, D. A review of the application of deep learning in medical image classification and segmentation. Ann. Transl. Med. 2020, 8, 1–15. [Google Scholar] [CrossRef] [PubMed]
- Ahmed, S.T.; Koti, M.S.; Muthukumaran, V.; Joseph, R.B. Interdependent Attribute Interference Fuzzy Neural Network-Based Alzheimer Disease Evaluation. Int. J. Fuzzy Syst. Appl. (IJFSA) 2022, 11, 1–13. [Google Scholar] [CrossRef]
- Vemuri, P.; Jack, C.R. Role of structural MRI in Alzheimer’s disease. Alzheimer’s Res. Ther. 2010, 2, 23. [Google Scholar] [CrossRef]
- Dharwada, S.; Tembhurne, J.; Diwan, T. Multi-channel Deep Model for Classification of Alzheimer’s Disease Using Transfer Learning. In Proceedings of the Distributed Computing and Intelligent Technology: 18th International Conference, ICDCIT 2022, Bhubaneswar, India, 19–23 January 2022; Springer International Publishing: Cham, Switzerland, 2022; pp. 245–259. [Google Scholar]
- Yamanakkanavar, N.; Choi, J.Y.; Lee, B. MRI segmentation and classification of human brain using deep learning for diagnosis of Alzheimer’s disease: A survey. Sensors 2020, 20, 3243. [Google Scholar] [CrossRef]
- Druzhinina, P.; Kondrateva, E. The effect of skull-stripping on transfer learning for 3D MRI models: ADNI data. In Proceedings of the Medical Imaging with Deep Learning 2022, Zürich, Switzerland, 6–8 July 2022. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 10012–10022. [Google Scholar]
- Hu, Z.; Wang, Z.; Jin, Y.; Hou, W. VGG-TSwinformer: Transformer-based deep learning model for early Alzheimer’s disease prediction. Comput. Methods Programs Biomed. 2023, 229, 107291. [Google Scholar] [CrossRef]
- Zou, L.; Lam, H.F.; Hu, J. Adaptive resize-residual deep neural network for fault diagnosis of rotating machinery. Struct. Health Monit. 2023, 22, 2193–2213. [Google Scholar] [CrossRef]
- Zhang, R.; Isola, P.; Efros, A. Colorful image colorization. In Proceedings of the Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Proceedings, Part III 14. Springer International Publishing: Cham, Switzerland, 2016; pp. 649–666. [Google Scholar]
- Wang, Q.; Li, Y.; Zheng, C.; Xu, R. DenseCNN: A Densely Connected CNN Model for Alzheimer’s Disease Classification Based on Hippocampus MRI Data. In AMIA Annual Symposium Proceedings; American Medical Informatics Association: Bethesda, MD, USA, 2020; Volume 2020, p. 1277. [Google Scholar]
- Pan, D.; Zou, C.; Rong, H.; Zeng, A. Early diagnosis of Alzheimer’s disease based on three-dimensional convolutional neural networks ensemble model combined with genetic algorithm. J. Biomed. Eng. 2021, 38, 47–55. [Google Scholar]
- Huang, H.; Zheng, S.; Yang, Z.; Wu, Y.; Li, Y.; Qiu, J.; Wu, R. Voxel-based morphometry and a deep learning model for the diagnosis of early Alzheimer’s disease based on cerebral gray matter changes. Cereb. Cortex 2023, 33, 754–763. [Google Scholar] [CrossRef] [PubMed]
- Hazarika, R.A.; Kandar, D.; Maji, A.K. An experimental analysis of different deep learning-based models for Alzheimer’s disease classification using brain magnetic resonance images. J. King Saud Univ.-Comput. Inf. Sci. 2022, 34, 8576–8598. [Google Scholar] [CrossRef]
- Morid, M.A.; Borjali, A.; Del Fiol, G. A scoping review of transfer learning research on medical image analysis using ImageNet. Comput. Biol. Med. 2021, 128, 104115. [Google Scholar] [CrossRef]
- Zhang, F.; Pan, B.; Shao, P.; Liu, P.; Shen, S.; Yao, P.; Xu, R.X. An explainable two-dimensional single model deep learning approach for Alzheimer’s disease diagnosis and brain atrophy localization. arXiv 2017, arXiv:2107.13200. [Google Scholar]
- Liu, M.; Zhang, J.; Nie, D.; Yap, P.T.; Shen, D. Anatomical landmark based deep feature representation for MR images in brain disease diagnosis. IEEE J. Biomed. Health Inform. 2018, 22, 1476–1485. [Google Scholar] [CrossRef] [PubMed]
- Liu, M.; Zhang, J.; Adeli, E.; Shen, D. Landmark-based deep multi-instance learning for brain disease diagnosis. Med. Image Anal. 2018, 43, 157–168. [Google Scholar] [CrossRef]
- Zhang, Y.; Teng, Q.; Liu, Y.; Liu, Y.; He, X. Diagnosis of Alzheimer’s disease based on regional attention with sMRI gray matter slices. J. Neurosci. Methods 2022, 365, 109376. [Google Scholar] [CrossRef]
- Han, K.; Xiao, A.; Wu, E.; Guo, J.; Xu, C.; Wang, Y. Transformer in transformer. Adv. Neural Inf. Process. Syst. 2021, 34, 15908–15919. [Google Scholar]
- Li, C.; Cui, Y.; Luo, N.; Liu, Y.; Bourgeat, P.; Fripp, J.; Jiang, T. Trans-ResNet: Integrating Transformers and CNNs for Alzheimer’s disease classification. In Proceedings of the 2022 IEEE 19th International Symposium on Biomedical Imaging (ISBI), Kolkata, India, 28–31 March 2022; pp. 1–5. [Google Scholar]
- Jang, J.; Hwang, D. M3T: Three-dimensional Medical image classifier using Multi-plane and Multi-slice Transformer. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 20718–20729. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Fei-Fei, L. Imagenet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Lyu, Y.; Yu, X.; Zhu, D.; Zhang, L. Classification of Alzheimer’s Disease via Vision Transformer: Classification of Alzheimer’s Disease via Vision Transformer. In Proceedings of the 15th International Conference on PErvasive Technologies Related to Assistive Environments, Corfu, Greece, 29 June–1 July 2022; pp. 463–468. [Google Scholar]
- Zhang, Z.; Gong, Z.; Hong, Q.; Jiang, L. Swin-transformer based classification for rice diseases recognition. In Proceedings of the 2021 International Conference on Computer Information Science and Artificial Intelligence (CISAI), Kunming, China, 17–19 September 2021; pp. 153–156. [Google Scholar]
- Nawaz, W.; Ahmed, S.; Tahir, A.; Khan, H.A. Classification of breast cancer histology images using alexnet. In Proceedings of the Image Analysis and Recognition: 15th International Conference, ICIAR 2018, Póvoa de Varzim, Portugal, 27–29 June 2018; Proceedings 15. Springer International Publishing: Cham, Switzerland; pp. 869–876. [Google Scholar]
- Sarwinda, D.; Paradisa, R.H.; Bustamam, A.; Anggia, P. Deep learning in image classification using residual network (ResNet) variants for detection of colorectal cancer. Procedia Comput. Sci. 2021, 179, 423–431. [Google Scholar] [CrossRef]
- Marques, G.; Agarwal, D.; de la Torre Díez, I. Automated medical diagnosis of COVID-19 through EfficientNet convolutional neural network. Appl. Soft Comput. 2020, 96, 106691. [Google Scholar] [CrossRef]
- Wang, Y.; Yan, W.Q. Colorizing Gray-scale CT images of human lungs using deep learning methods. Multimed. Tools Appl. 2022, 81, 37805–37819. [Google Scholar] [CrossRef] [PubMed]
- Talebi, H.; Milanfar, P. Learning to resize images for computer vision tasks. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 497–506. [Google Scholar]
- Petersen, R.C.; Aisen, P.S.; Beckett, L.A.; Donohue, M.C.; Gamst, A.C.; Harvey, D.J.; Weiner, M.W. Alzheimer’s disease neuroimaging initiative (ADNI): Clinical characterization. Neurology 2010, 74, 201–209. [Google Scholar] [CrossRef] [PubMed]
- Ellis, K.A.; Bush, A.I.; Darby, D.; De Fazio, D.; Foster, J.; Hudson, P.; AIBL Research Group. The Australian Imaging, Biomarkers and Lifestyle (AIBL) study of aging: Methodology and baseline characteristics of 1112 individuals recruited for a longitudinal study of Alzheimer’s disease. Int. Psychogeriatr. 2009, 21, 672–687. [Google Scholar] [CrossRef] [PubMed]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Image Dataset | AD | NC | Age | Sex (F/M) |
|---|---|---|---|---|
| ADNI (N = 1188) | 388 | 800 | 75.76 ± 6.75 [56–96] | 574/614 |
| AIBL (N = 847) | 196 | 651 | 74.56 ± 6.88 [52–96] | 463/384 |
| Models | Types | Classification Results | |||
|---|---|---|---|---|---|
| ACC% | SEN% | SPE% | PRE% | ||
| DenseCNN [12] | ROI | 89.80 | 98.50 | 85.20 | -- |
| CNN [17] | Whole | 93.00 | 92.00 | 94.00 | -- |
| LDMIL [19] | Patch | 92.02 ± 0.93 | 90.76 ± 2.72 | 92.40 ± 1.10 | -- |
| ResNet+Attention [20] | Attention | 90.00 | 92.80 | 87.50 | -- |
| ResNet+ViT [22] | Transformer | 92.26 | 88.98 | 94.04 | -- |
| CNN+ViT [23] | Transformer | 90.58 | -- | -- | -- |
| CNN+ViT [24] | Transformer | 96.80 | -- | -- | 97.20 |
| Ours | Transformer | 99.59 | 99.58 | 99.59 | 99.83 |
| Types | Classification Results | |||
|---|---|---|---|---|
| ACC% | SEN% | SPE% | PRE% | |
| Sagittal | 99.69 | 99.74 | 99.67 | 99.54 |
| Coronal | 99.07 | 99.46 | 98.79 | 98.50 |
| Axial | 99.59 | 99.58 | 99.59 | 99.83 |
| Models | Data | ACC |
|---|---|---|
| RST | No skull stripping | 98.74% |
| RST | 2.5D skull stripping | 96.36% |
| RST | Skull stripping | 98.99% |
| CNN+RST | Skull stripping | 99.98% |
| ST | No skull stripping | 95.87% |
| CNN+ST | No skull stripping | 98.87% |
| CNN+RST | No skull stripping | 99.62% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Huang, Y.; Li, W. Resizer Swin Transformer-Based Classification Using sMRI for Alzheimer’s Disease. Appl. Sci. 2023, 13, 9310. https://doi.org/10.3390/app13169310
Huang Y, Li W. Resizer Swin Transformer-Based Classification Using sMRI for Alzheimer’s Disease. Applied Sciences. 2023; 13(16):9310. https://doi.org/10.3390/app13169310
Chicago/Turabian StyleHuang, Yihang, and Wan Li. 2023. "Resizer Swin Transformer-Based Classification Using sMRI for Alzheimer’s Disease" Applied Sciences 13, no. 16: 9310. https://doi.org/10.3390/app13169310