
Crop Prediction Model Using Machine Learning Algorithms
 , , , , and
, , , , and
Abstract
:1. Introduction
2. Literature Review
- Presenting experimental results that demonstrate the impact of changing labels on the accuracy of data analysis algorithms.
- The research outcome recommends that farmers could make more informed verdicts about factors that affect crop growth by analyzing wide-ranging data collected from farms, including real-time data from IoT sensors.
- As per the provided analysis in this research work, the machine learning algorithms demonstrate a high level of classification accuracy. Notably, the Bayes Net algorithm achieved an impressive accuracy of 99.59%, while both the Naïve Bayes Classifier and Hoeffding Tree algorithms yielded a remarkable accuracy of 99.46%. These results highlight the efficacy and reliability of these algorithms in accurately classifying the given data.
- Therefore, by integrating different technologies, the achieved results can be used as an indicator for the farmers to have early and informed decisions regarding crop prediction to improve productivity, and hence the overall economy will be improved, accordingly.
3. Machine Learning in Smart Farming
4. Crop Analysis and Prediction Benefits and Challenges
4.1. Benefits
- More effectiveness: This approach is more effective and accurate in identifying patterns and saving farmers time and resources because a larger volume of data can be evaluated by machine learning in a shorter amount of time than with previous methods.
- Increased crop yield: Using many data sources for analysis, including weather patterns, soil quality, and historical machine learning algorithms, can help farmers make more informed decisions that increase crop yields.
- Lower costs: Machine learning may assist farmers in maximizing the use of resources, such as water, fertilizer, and pesticides, by offering insights into crop development and health. This can save expenses while lowering how much of an impact agriculture has on the environment.
- Early disease detection: Farmers can take preventative measures to stop the spread of illness and reduce crop loss by identifying early indicators of crop diseases with machine learning. Once the model is sufficiently trained, it can detect anomalies such as discoloration on growth size in the early stages of disease much faster than humans would notice.
- Improved crop management: By offering insights into variables such as soil moisture, temperature, and nutrient levels, ML algorithms can assist farmers in improving their crop management tactics. This can assist farmers in making data-driven decisions regarding the best time to water, fertilize, and sow their crops.
4.2. Challenges
- Data quality: The accuracy and dependability of machine learning models depend on the caliber of the training data. Obtaining high-quality data in agriculture can be challenging because of changes in the soil, climate, geography, and other environmental factors. As a result, gathering and cleansing data might be difficult. Ref. [51] discusses the main challenges related to fruit detection and recognition based on deep learning. They have concluded that most of the factors leading to low accuracy, slow speed, and poor robustness of fruit detection and recognition are related to the scarcity of high-quality fruit datasets, detection of small target fruits, fruit detection in occluded and dense scenarios, detection of multi-scale and multi-species fruits, and lightweight fruit detection models.
- Data volume: ML models frequently need a large amount of data for efficient training. Large data management and collection in agriculture can be complex, especially for small farms. Ref. [52] considers volume, velocity, variety, and veracity as the main challenges of big data.
- Model complexity: Because agricultural systems are intricate, it can be challenging to develop machine learning models that account entirely for all the important variables affecting crop development and output. Selecting the best model architecture for a specific crop analysis or forecast activity can be difficult and requires extensive knowledge [53]. Additionally, the most common use of ML techniques provides analysis for prediction, recommendations, situation determination, and automation. NN, RF, SVM, DT, and Naïve Bayes algorithms are the most popular techniques used in agronomy. The main challenges for these algorithms are the large volume of data, which increases the complexity of the training time and computation for SVM [53], and the need to tailor the algorithm for each specific problem in the case of RF [54]. The design of big data architecture is one of the most complex challenges, considering that it must be flexible and highly scalable [55]. Ref. [56] analyzed the factors affecting soil temperature and concluded that the relationship between variables affecting the soil temperature is quite complex and challenging, leading to the estimation of it using physically and statistically based models with a tradeoff between resolution, accuracy, and computational efficiency. According to them, the best ML technique for soil temperature retrieval generally depends on training datasets, model structure, and target level of accuracy.
- Interpretability: Analyzing the outcomes of ML models, particularly those that use deep learning techniques, which are quite complex, can be challenging. Because of this, it may be difficult for farmers to comprehend the elements that go into making a particular crop prediction or suggestion.
- Accessibility: In situations with limited resources, obtaining access to the hardware and software infrastructure required for developing and deploying ML models may be challenging.
- Privacy and security: These concerns exist around collecting, storing, and using sensitive agricultural data. It can be challenging to ensure privacy and security while still allowing access to the data for ML research.
- Human factors: It is possible that farmers and other interested parties need more time to be ready to adopt new methods and technology, such as ML-based systems. For technology to be used more widely, it must be made accessible, user-friendly, and capable of providing real benefits.
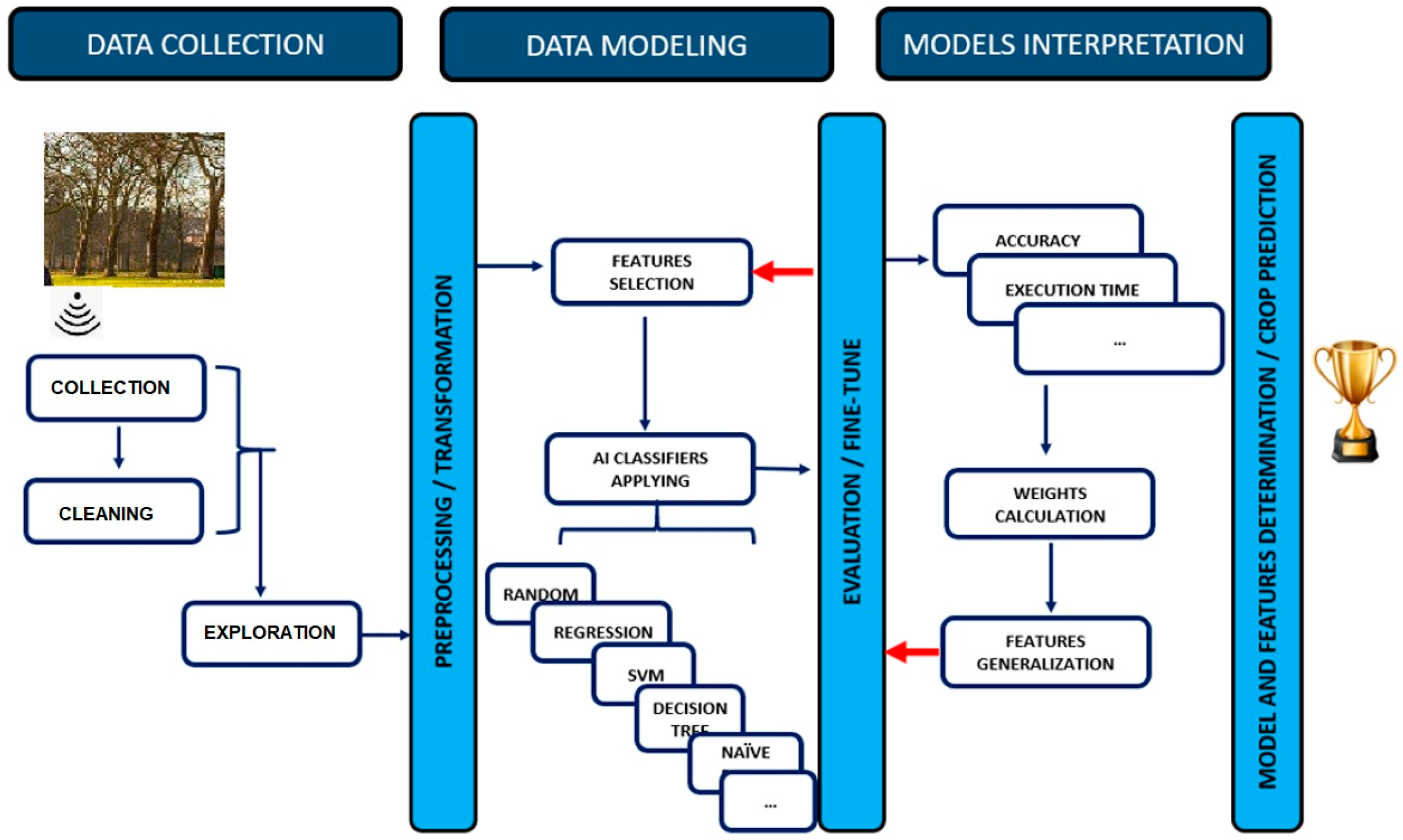
5. Methodology
- –
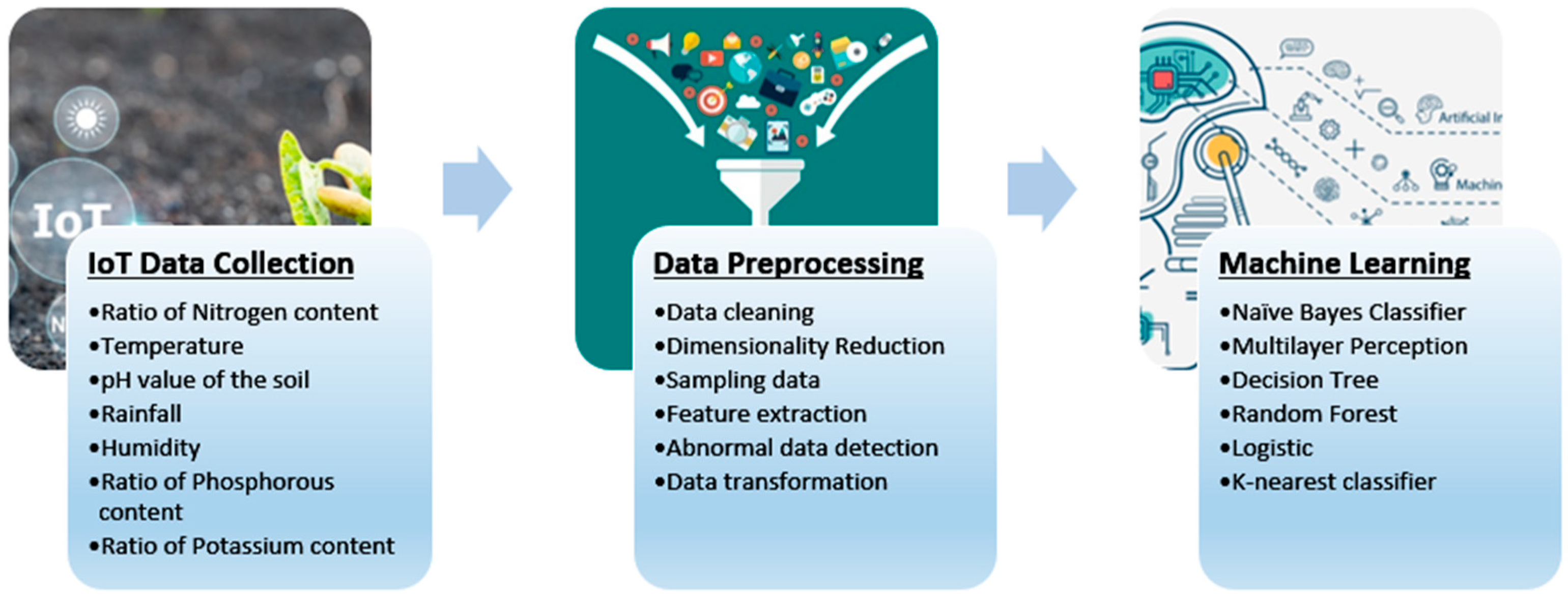
- Data Collection: The collection of data from IoT devices on farms is vital for conducting machine learning analysis. By gathering crucial information on crop usage, crop type, water requirements, and harvest methods for agriculture, we can significantly increase productivity on smart farms.
- –
- Data Modeling: The accuracy of data analysis was tested through experiments that involved altering labels. To group crops, we categorized them into four broad groups based on various factors, rather than predicting individual crop types. We analyzed a dataset of crop types using machine learning, utilizing seven different features to classify them. Additionally, we determined the minimum number of features necessary for precise learning and prediction.
- –
- Model Evaluation and Interpretation: We want to achieve precise crop detection by selecting appropriate features for our machine learning algorithms. To ensure optimal results, we considered parameter properties on the relevant properties. This allowed us to obtain accurate and reliable data for our agricultural operations. During our experiments, we analyzed the effects of modifying the labels on the accuracy of our data analysis algorithm. This enabled us to understand the impact of minor label changes better and helped us optimize our approach toward achieving greater accuracy in our results. To achieve success in crop classification, it is vital to utilize broader labels. It is crucial to thoroughly investigate and ascertain the most efficient classification techniques within this domain.
- –
- Naïve Bayes Classifier is a supervised learning algorithm that uses Bayes’ theorem to classify objects. It is used in machine learning and data mining applications for text analysis, medical diagnosis, spam filtering, and other similar tasks. Naïve Bayes assumes that features in a class are considered independent of each other. In practice, the Naïve Bayes algorithm performs well, especially when the data are sparse, and the number of features is extensive. Below is the pseudocode for Naïve Bayes Classifier:
- For each unique class value c in y, calculate the prior probability for class c
- For each feature i in X and each unique class value c in y, calculate the conditional probability of feature i given class c as follows:
- Calculate the posterior probability for each class given the new data point x:
- ◦
- Initialize the posterior probability P(c|x) to P(c)
- ◦
- For each feature i in x: =, multiply P(c|x) by P(i|c) if x[i] is observed in the training data, otherwise ignore the term.
- Choose the class with the highest posterior probability as the predicted class for x.
- –
- Random Forest is a type of supervised machine learning algorithm that is used in regression and classification problems. It is an ensemble learning algorithm that uses Decision Trees to make a prediction. Random Forest creates many Decision Trees and combines their predictions to make a final prediction. More trees created yield high accuracy and robust results. Below is the pseudocode for the Random Forest algorithm:
- For each tree in the Random Forest:
- ◦
- Select a bootstrap sample from the training data set.
- ◦
- Create a Decision Tree T_t with a maximum depth of d.
- ◦
- Randomly select f features to consider at each split of T_t.
- ◦
- Use the selected features to find the best split at each node of T_t.
- Create the list of Decision Trees T_1, T_2, ..., T_T.
- For each input data:
- ◦
- For each decision, find the prediction.
- ◦
- Obtain predictions of all the trees.
- ◦
- Calculate the final predicted class.
- –
- Multilayer Neural Network is a machine learning algorithm consisting of multiple layers of interconnected nodes between the input and output layers.
- Define the number of layers and the number of neurons per layer.
- Initialize the weights and biases for each neuron in the network randomly.
- Forward propagate the input through the neural network to obtain the predicted output.
- Calculate the error rate between the predicted output and the actual output.
- Backward propagate the error through the neural network to adjust the weights and biases using the optimization algorithm.
- Repeat until the error converges to a satisfactory level.
6. Experimental Results
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Li, L.; Wang, B.; Feng, P.; Liu, D.L.; He, Q.; Zhang, Y.; Wang, Y.; Li, S.; Lu, X.; Yue, C.; et al. Developing machine learning models with multi-source environmental data to predict wheat yield in China. Comput. Electron. Agric. 2022, 194, 106790. [Google Scholar] [CrossRef]
- van Klompenburg, T.; Kassahun, A.; Catal, C. Crop yield prediction using machine learning: A systematic literature review. Comput. Electron. Agric. 2020, 177, 105709. [Google Scholar] [CrossRef]
- Kuradusenge, M.; Hitimana, E.; Hanyurwimfura, D.; Rukundo, P.; Mtonga, K.; Mukasine, A.; Uwitonze, C.; Ngabonziza, J.; Uwamahoro, A. Crop Yield Prediction Using Machine Learning Models: Case of Irish Potato and Maize. Agriculture 2023, 13, 225. [Google Scholar] [CrossRef]
- Xu, W.; Kaili, Z.; Tianlei, W. Smart Farm Based on Six-Domain Model. In Proceedings of the IEEE 4th International Conference on Electronics Technology (ICET), Chengdu, China, 7–10 May 2021; pp. 417–421. [Google Scholar]
- Moysiadis, V.; Tsakos, K.; Sarigiannidis, P.; Petrakis, E.G.M.; Boursianis, A.D.; Goudos, S.K. A Cloud Computing web-based application for Smart Farming based on microservices architecture. In Proceedings of the 11th International Conference on Modern Circuits and Systems Technologies (MOCAST), Bremen, Germany, 8–10 June 2022; pp. 1–5. [Google Scholar]
- Ranjan, P.; Garg, R.; Rai, J.K. Artificial Intelligence Applications in Soil & Crop Management. In Proceedings of the IEEE Conference on Interdisciplinary Approaches in Technology and Management for Social Innovation (IATMSI), Gwalior, India, 21–23 December 2022; pp. 1–5. [Google Scholar]
- Oré, G.; Alcântara, M.S.; Góes, J.A.; Oliveira, L.P.; Yepes, J.; Teruel, B.; Castro, V. Crop Growth Monitoring with Drone-Borne DInSAR. Remote Sens. 2020, 12, 615. [Google Scholar] [CrossRef]
- Gehlot, A.; Sidana, N.; Jawale, D.; Jain, N.; Singh, B.P.; Singh, B. Technical analysis of crop production prediction using Machine Learning and Deep Learning Algorithms. In Proceedings of the International Conference on Innovative Computing, Intelligent Communication and Smart Electrical Systems (ICSES), Chennai, India, 24–25 September 2022; pp. 1–5. [Google Scholar]
- Vashisht, S.; Kumar, P.; Trivedi, M.C. Improvised Extreme Learning Machine for Crop Yield Prediction. In Proceedings of the 3rd International Conference on Intelligent Engineering and Management (ICIEM), London, UK, 27–29 April 2022; pp. 754–757. [Google Scholar]
- OpenAI. New and Improved Content Moderation Tooling. OpenAI. 2022. Available online: https://openai.com/blog/new-and-improved-content-moderation-tooling/ (accessed on 1 April 2023).
- Google. Bard Chatbox. Google. Available online: https://bard.google.com (accessed on 2 April 2023).
- Dean, J. The deep learning revolution and its implications for computer architecture and chip design. In Proceedings of the IEEE International Solid-State Circuits Conference-(ISSCC), San Francisco, CA, USA, 16–20 February 2020. [Google Scholar]
- Cui, Y.W.; Henrickson, K.; Ke, R.; Pu, Z.; Wang, Y. Traffic graph convolutional recurrent neural network: A deep learning framework for network-scale traffic learning and forecasting. IEEE Trans. Intell. Transp. Syst. 2019, 21, 4883–4894. [Google Scholar] [CrossRef]
- Shahrin, F.; Zahin, L.; Rahman, R.; Hossain, A.J.; Kaf, A.H.; Abdul Malek Azad, A.K.M. Agricultural Analysis and Crop Yield Prediction of Habiganj using Multispectral Bands of Satellite Imagery with Machine Learning. In Proceedings of the 11th International Conference on Electrical and Computer Engineering (ICECE), Dhaka, Bangladesh, 17–19 December 2020; pp. 21–24. [Google Scholar]
- Tawseef, A.S.; Tabasum, R.; Faisal, R.L. Towards leveraging the role of machine learning and artificial intelligence in precision agriculture and smart farming. Comput. Electron. Agric. 2022, 198, 107119. [Google Scholar]
- Senthil KS, D.; Mary, D.S. Smart farming using Machine Learning and Deep Learning techniques. Decis. Anal. J. 2022, 3, 100041. [Google Scholar]
- Senthil, K.M.; Akshaya, R.; Sreejith, K. An Internet of Things-based Efficient Solution for Smart Farming. Procedia Comput. Sci. 2023, 218, 2806–2819. [Google Scholar]
- Vivek, S.; Ashish, K.T.; Himanshu, M. Technological revolutions in smart farming: Current trends, challenges & future directions. Comput. Electron. Agric. 2022, 201, 107217. [Google Scholar]
- Mamatha, J.C.K. Machine learning based crop growth management in greenhouse environment using hydroponics farming techniques. Meas. Sens. 2023, 25, 100665. [Google Scholar] [CrossRef]
- Rashid, M.; Bari, B.S.; Yusup, Y.; Kamaruddin, M.A.; Khan, N. A Comprehensive Review of Crop Yield Prediction Using Machine Learning Approaches with Special Emphasis on Palm Oil Yield Prediction. IEEE Access 2021, 9, 63406–63439. [Google Scholar] [CrossRef]
- Babber, J.; Malik, P.; Mittal, V.; Purohit, K.C. Analyzing Supervised Learning Algorithms for Crop Prediction and Soil Quality. In Proceedings of the 6th International Conference on Computing Methodologies and Communication (ICCMC), Erode, India, 29–31 March 2022; pp. 969–973. [Google Scholar]
- Ishak, M.; Rahaman, M.S.; Mahmud, T. FarmEasy: An Intelligent Platform to Empower Crops Prediction and Crops Marketing. In Proceedings of the 13th International Conference on Information & Communication Technology and System (ICTS), Surabaya, Indonesia, 17–20 April 2021; pp. 224–229. [Google Scholar]
- Patel, K.; Patel, H.B. A Comparative Analysis of Supervised Machine Learning Algorithm for Agriculture Crop Prediction. In Proceedings of the Fourth International Conference on Electrical, Computer and Communication Technologies (ICECCT), Erode, India, 15–17 September 2022; pp. 1–5. [Google Scholar]
- Memon, R.; Memon, M.; Malioto, N.; Raza, M.O. Identification of growth stages of crops using mobile phone images and machine learning. In Proceedings of the International Conference on Computing, Electronic and Electrical Engineering (ICE Cube), Quetta, Pakistan, 26–27 October 2021; pp. 1–6. [Google Scholar]
- Chandraprabha, M.; Dhanaraj, R.K. Soil Based Prediction for Crop Yield using Predictive Analytics. In Proceedings of the 3rd International Conference on Advances in Computing, Communication Control and Networking (ICAC3N), Greater Noida, India, 17–18 December 2021; pp. 265–270. [Google Scholar]
- Ray, R.K.; Das, S.K.; Chakravarty, S. Smart Crop Recommender System-A Machine Learning Approach. In Proceedings of the 12th International Conference on Cloud Computing, Data Science & Engineering (Confluence), Noida, India, 27–28 January 2022; pp. 494–499. [Google Scholar]
- Priyadharshini, K.; Prabavathi, R.; Devi, V.B.; Subha, P.; Saranya, S.M.; Kiruthika, K. An Enhanced Approach for Crop Yield Prediction System Using Linear Support Vector Machine Model. In Proceedings of the International Conference on Communication, Computing and Internet of Things (IC3IoT), Chennai, India, 10–11 March 2022; pp. 1–5. [Google Scholar]
- Malathy, S.; Vanitha, C.N.; Kotteswari, S.; Mohankkanth, E. Rainfall Prediction for Enhancing Crop-Yield based on Machine Learning Techniques. In Proceedings of the International Conference on Applied Artificial Intelligence and Computing (ICAAIC), Salem, India, 9–11 May 2022; pp. 437–442. [Google Scholar]
- Chowdary, V.T.; Robinson Joel, M.; Ebenezer, V.; Edwin, B.; Thanka, R.; Jeyaraj, A. A Novel Approach for Effective Crop Production Using Machine Learning. In Proceedings of the International Conference on Electronics and Renewable Systems (ICEARS), Tuticorin, India, 16–18 March 2022; pp. 1143–1147. [Google Scholar]
- Yamparla, R.; Shaik, H.S.; Guntaka, N.; Marri, P.; Nallamothu, S. Crop Yield Prediction using Random Forest Algorithm. In Proceedings of the 7th International Conference on Communication and Electronics Systems (ICCES), Coimbatore, India, 22–24 June 2022; pp. 1538–1543. [Google Scholar]
- Apeksha, R.G.; Swati, S.S. A brief study on the prediction of crop disease using machine learning approaches. In Proceedings of the 2021 International Conference on Computational Intelligence and Computing Applications (ICCICA), Nagpur, India, 18–19 June 2021; pp. 1–6. [Google Scholar]
- Kumar, R.; Shukla, N.; Princee. Plant Disease Detection and Crop Recommendation Using CNN and Machine Learning. In Proceedings of the International Mobile and Embedded Technology Conference (MECON), Noida, India, 10–11 March 2022; pp. 168–172. [Google Scholar]
- Bhosale, S.V.; Thombare, R.A.; Dhemey, P.G.; Chaudhari, A.N. Crop Yield Prediction Using Data Analytics and Hybrid Approach. In Proceedings of the Fourth International Conference on Computing Communication Control and Automation (ICCUBEA), Pune, India, 16–18 August 2018. [Google Scholar]
- Alwis, S.D.; Hou, Z.; Zhang, Y.; Na, M.H.; Ofoghi, B.; Sajjanhar, A. A survey on smart farming data, applications and techniques. Comput. Ind. 2022, 138, 103624. [Google Scholar] [CrossRef]
- Lyu, Y.; Li, J.; Hou, R.; Zhang, Y.; Hang, S.; Zhu, W.; Zhu, H.; Ouyang, Z. Precision Feeding in Ecological Pig-Raising Systems with Maize Silage. Animals 2022, 12, 11. [Google Scholar] [CrossRef] [PubMed]
- Ghobadi, F.; Kang, D. Application of Machine Learning in Water Resources Management: A Systematic Literature Review. Water 2023, 15, 4. [Google Scholar] [CrossRef]
- Padarian, J.; Minasny, B.; McBratney, A.B. Machine learning and soil sciences: A review aided by machine learning tools. SOIL 2020, 6, 35–52. [Google Scholar] [CrossRef]
- Ramos, P.J.; Prieto, F.A.; Montoya, E.C.; Oliveros, C.E. Automatic fruit count on coffee branches using computer vision. Comput. Electron. Agric. 2017, 137, 9–22. [Google Scholar] [CrossRef]
- Sengupta, S.; Lee, W.S. Identification and determination of the number of immature green citrus fruit in a canopy under different ambient light conditions. Biosyst. Eng. 2014, 117, 51–61. [Google Scholar] [CrossRef]
- Su, Y.; Xu, H.; Yan, L. Support vector machine-based open crop model (SBOCM): Case of rice production in China. Saudi J. Biol. Sci. 2017, 24, 537–547. [Google Scholar] [CrossRef]
- Adankon, M.M.; Cheriet, M. Support Vector Machine. In Encyclopedia of Biometrics; Li, S.Z., Jain, A., Eds.; Springer: Boston, MA, USA, 2009; pp. 1303–1308. [Google Scholar]
- Ali, I.; Cawkwell, F.; Dwyer, E.; Green, S. Modeling Managed Grassland Biomass Estimation by Using Multitemporal Remote Sensing Data—A Machine Learning Approach. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2016, 10, 3254–3264. [Google Scholar] [CrossRef]
- Jadhav, M.; Kolambe, N.; Jain, S.; Chaudhari, S. Farming Made Easy using Machine Learning. In Proceedings of the 2nd International Conference for Emerging Technology (INCET), Belagavi, India, 21–23 May 2021; pp. 1–5. [Google Scholar] [CrossRef]
- How Is ML Is Used in Agriculture? Available online: https://www.dtn.com/how-is-machine-learning-used-in-agriculture/ (accessed on 1 August 2023).
- Sawhney, D. Redefining Agriculture through Artificial Intelligence: Predicting the Unpredictable. p9. GG—May 2022—M&C 19416. Available online: https://www.pwc.in/assets/pdfs/grid/agriculture/redefining-agriculture-through-artificial-intelligence.pdf (accessed on 1 August 2023).
- Pyingkodi, M.; Thenmozhi, K.; Karthikeyan, M.; Kalpana, T.; Palarimath, S.; Kumar, G.B.A. IoT-based Soil Nutrients Analysis and Monitoring System for Smart Agriculture. In Proceedings of the 3rd International Conference on Electronics and Sustainable Communication Systems (ICESC), Coimbatore, India, 17–19 August 2022; pp. 489–494. [Google Scholar]
- Pivoto, D.; Waquil, P.D.; Talamini, E.; Finocchio, C.P.S.; Corte, V.; Mores, G. Scientific development of smart farming technologies and their application in Brazil. Inf. Process. Agric. 2018, 5, 21–32. [Google Scholar] [CrossRef]
- Patel, N.S.; Kumar, H.P.M. Soil Quality Identifying and Monitoring Approach for Sugarcane Using Machine Learning Techniques. In Proceedings of the Fourth International Conference on Emerging Research in Electronics, Computer Science and Technology (ICERECT), Mandya, India, 26–27 December 2022; pp. 1–5. [Google Scholar]
- Puengsungwan, S. IoT-based Soil Moisture Sensor for Smart Farming. In Proceedings of the International Conference on Power, Energy, and Innovations (ICPEI), Chiangmai, Thailand, 14–16 October 2020; pp. 221–224. [Google Scholar]
- Sahu, P.; Singh, A.P.; Chug, A.; Singh, D. A Systematic Literature Review of Machine Learning Techniques Deployed in Agriculture: A Case Study of Banana Crop. IEEE Access 2022, 10, 87333–87360. [Google Scholar] [CrossRef]
- Xiao, F.; Wang, H.; Xu, Y.; Zhang, R. Fruit Detection and Recognition Based on Deep Learning for Automatic Harvesting: An Overview and Review. Agronomy 2023, 13, 1625. [Google Scholar] [CrossRef]
- Cravero, A.; Pardo, S.; Sepúlveda, S.; Muñoz, L. Challenges to Use Machine Learning in Agricultural Big Data: A Systematic Literature Review. Agronomy 2022, 12, 748. [Google Scholar] [CrossRef]
- L’heureux, A.; Grolinger, K.; Elyamany, H.; Capretz, M. Machine learning with Big Data: Challenges and approaches. IEEE Access 2017, 5, 7776–7797. [Google Scholar] [CrossRef]
- Del Río, S.; López, V.; Benítez, J.M.; Herrera, F. On the use of Map Reduce for imbalanced Big Data using Random Forest. Inf. Sci. 2014, 285, 112–137. [Google Scholar] [CrossRef]
- Salma, C.A.; Tekinerdogan, B.; Athanasiadis, I.N. Chapter 4—Domain-Driven Design of Big Data Systems Based on a Reference Architecture. In Software Architecture for Big Data and the Cloud; Morgan Kaufmann: Burlington, MA, USA, 2017; pp. 49–68. [Google Scholar]
- Taheri, M.; Schreiner, H.K.; Mohammadian, A.; Shirkhani, H.; Payeur, P.; Imanian, H.; Cobo, J.H. A Review of Machine Learning Approaches to Soil Temperature Estimation. Sustainability 2023, 15, 7677. [Google Scholar] [CrossRef]
- Maharana, K.; Mondal, S.; Nemade, M. A review: Data pre-processing and data augmentation techniques. Glob. Transit. Proc. 2022, 3, 91–99. [Google Scholar] [CrossRef]
- Available online: https://www.kaggle.com/code/theeyeschico/crop-analysis-and-prediction (accessed on 30 March 2023).
- Elbasi, E.; Mostafa, N.; AlArnaout, Z.; Zreikat, A.I.; Cina, E.; Varghese, G.; Shdefat, A.; Topcu, A.E.; Abdelbaki, W.; Mathew, S.; et al. Artificial Intelligence Technology in the Agricultural Sector: A Systematic Literature Review. IEEE Access 2023, 11, 171–202. [Google Scholar] [CrossRef]
- Elbasi, E.; Zreikat, A.I.; Mathew, S.; Topcu, A.E. Classification of influenza H1N1 and COVID-19 patient data using machine learning. In Proceedings of the 44th International Conference on Telecommunications and Signal Processing (TSP), Brno, Czech Republic, 26–28 July 2021; pp. 278–282. [Google Scholar]
- Shrestha, N. Detecting Multicollinearity in Regression Analysis. Am. J. Appl. Math. Stat. 2020, 8, 39–42. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
| Method | Accuracy (%) | Kappa (0~1) | MAE (0~1) | RMSE (0~1) | RAE (%) | RRSE (%) |
|---|---|---|---|---|---|---|
| Bayes Net | 99.59 | 0.995 | 0.0010 | 0.018 | 1.14 | 8.64 |
| Naïve Bayes Classifier | 99.46 | 0.994 | 0.0009 | 0.020 | 1.05 | 9.73 |
| Logistic | 97.99 | 0.979 | 0.0020 | 0.038 | 2.30 | 18.24 |
| Multilayer Perception | 98.79 | 0.987 | 0.0046 | 0.033 | 5.33 | 16.18 |
| Simple Logistic | 98.66 | 0.986 | 0.0025 | 0.029 | 2.88 | 14.03 |
| IBK | 97.86 | 0.977 | 0.0032 | 0.043 | 3.69 | 21.05 |
| KSTAR | 97.86 | 0.977 | 0.0036 | 0.038 | 4.11 | 18.47 |
| LWL | 76.74 | 0.756 | 0.0752 | 0.188 | 86.59 | 90.26 |
| Ada BoostM1 | 6.82 | 0.036 | 0.0829 | 0.203 | 95.51 | 97.79 |
| Regression | 98.38 | 0.983 | 0.0099 | 0.042 | 11.41 | 20.44 |
| Decision Table | 88.50 | 0.879 | 0.0565 | 0.145 | 65.10 | 69.61 |
| Hoeffding Tree | 99.46 | 0.994 | 0.0009 | 0.020 | 1.05 | 9.74 |
| J48 | 98.79 | 0.987 | 0.0012 | 0.032 | 1.35 | 15.36 |
| Random Forest | 99.46 | 0.994 | 0.0032 | 0.024 | 3.63 | 11.75 |
| Random Tree | 98.12 | 0.980 | 0.0017 | 0.041 | 1.96 | 19.79 |
| Method | Build Time (Seconds) | Test Time (Seconds) |
|---|---|---|
| Bayes Net | 0.48 | 0.25 |
| Naïve Bayes Classifier | 0.03 | 0.67 |
| Logistic | 4.83 | 0.06 |
| Multilayer Perception | 17.39 | 0.05 |
| Simple Logistic | 3.86 | 0.02 |
| IBK | 0.03 | 0.69 |
| KSTAR | 0 | 6.9 |
| LWL | 0 | 9.56 |
| Ada BoostM1 | 0.04 | 0 |
| Regression | 2.4 | 0.05 |
| Decision Table | 0.75 | 0.01 |
| Hoeffding Tree | 0.41 | 0.06 |
| J48 | 0.27 | 0.03 |
| Random Forest | 1.57 | 0.13 |
| Random Tree | 0.02 | 0 |
| Training Set | Accuracy (%) | Kappa (0~1) | MAE (0~1) | RMSE (0~1) | RAE (%) | RRSE (%) |
|---|---|---|---|---|---|---|
| 10% | 93.53 | 0.9323 | 0.0166 | 0.0726 | 19.06 | 34.69 |
| 20% | 95.39 | 0.9518 | 0.0096 | 0.0568 | 11.10 | 27.22 |
| 30% | 95.91 | 0.9571 | 0.0082 | 0.0545 | 9.47 | 26.14 |
| 40% | 97.87 | 0.9778 | 0.0065 | 0.0436 | 7.51 | 20.92 |
| 50% | 97.90 | 0.9790 | 0.0057 | 0.039 | 6.50 | 18.87 |
| 60% | 97.95 | 0.9786 | 0.0056 | 0.0433 | 6.41 | 20.76 |
| 70% | 98.63 | 0.9857 | 0.0043 | 0.033 | 4.95 | 15.83 |
| 80% | 98.41 | 0.9833 | 0.0038 | 0.0315 | 4.42 | 15.10 |
| 90% | 97.72 | 0.9761 | 0.0038 | 0.0331 | 4.41 | 15.88 |
| Training Set | Build Time (Seconds) | Test Time (Seconds) |
|---|---|---|
| 10% | 19.18 | 0.05 |
| 20% | 17.03 | 0.03 |
| 30% | 17.47 | 0.01 |
| 40% | 14.26 | 0.02 |
| 50% | 14.54 | 0.02 |
| 60% | 14.12 | 0 |
| 70% | 14.79 | 0.01 |
| 80% | 13.81 | 0 |
| 90% | 13.21 | 0 |
| Method | N, P, K | K, P, Rainfall | Temperature, Humidity, pH, Rainfall | N, Temperature, Humidity, pH |
|---|---|---|---|---|
| Bayes Net | 67.64 | 85.69 | 97.05 | 89.70 |
| Naïve Bayes Classifier | 65.37 | 85.16 | 96.39 | 87.03 |
| Logistic | 66.17 | 74.19 | 85.42 | 76.07 |
| Multilayer Perception | 66.84 | 80.34 | 89.17 | 82.88 |
| Simple Logistic | 66.84 | 72.86 | 85.16 | 74.73 |
| IBK | 66.57 | 79.27 | 91.04 | 81.02 |
| KSTAR | 65.10 | 81.14 | 91.71 | 80.74 |
| LWL | 42.11 | 46.39 | 61.23 | 50.26 |
| Ada BoostM1 | 6.81 | 6.81 | 6.81 | 6.81 |
| Regression | 65.37 | 84.22 | 95.98 | 86.49 |
| Decision Table | 63.77 | 79.27 | 74.73 | 72.19 |
| Hoeffding Tree | 65.37 | 85.29 | 96.52 | 86.89 |
| J48 | 65.10 | 83.55 | 94.65 | 84.49 |
| Random Forest | 66.57 | 82.88 | 97.32 | 87.03 |
| Random Tree | 68.04 | 79.27 | 94.92 | 83.15 |
| Item | Growth Characteristics | Use (Food, Feed, Fiber) | Type | Water Requirements | Harvest Method |
|---|---|---|---|---|---|
| Rice | Grass | Food | Cereals | Drought | By Hand Or Machine |
| Maize | Grass | Feed, Fiber | Cereals | Drought | By Hand Or Machine |
| Chickpea | Bush | Food | Legume | Drought | Machine |
| Kidney beans | Bush | Food | Legume | Drought | By Hand And Machine |
| Pigeon peas | Bush | Food | Legume | Drought Resistant | By Hand |
| Mothbeans | Bush | Fiber | Legume | Drought Resistant | Both |
| Mungbean | Bush | Food | Legume | Drought | Hand Picked |
| Black gram | Bush | Food | Legume | Drought Tolerance | Both |
| Lentil | Bush | Food | Legume | Drought | Hands |
| Pomegranate | Tree | Fiber | Fruit | Drought Tolerant | Hands |
| Banana | Tree | Fiber | Fruit | Water Loving | Hands |
| Mango | Tree | Fiber | Fruit | Drought Tolerance | Hands |
| Grapes | Tree | Fiber | Fruit | Drought Tolerance | Hand |
| Watermelon | Sprawling Vines | Fiber | Fruit | Drought Tolerance | Hands |
| Muskmelon | Bush | Fiber | Fruit | Drought Tolerance | Hands |
| Apple | Tree | Fiber | Fruit | Drought Tolerance | Hand |
| Orange | Tree | Fiber | Fruit | Water Loving | Hand |
| Papaya | Tree | Fiber | Fruit | Water Loving | Hand |
| Coconut | Tree | Fiber | Fruit | Water Loving | Hand |
| Cotton | Bush | Fiber | Plant | Drought Tolerant | Machine |
| Jute | Shrub | Fiber | Plant | Water Loving | Hands |
| Coffee | Shrub | Fiber | Fruit | Drought | Hands |
| Method | Accuracy | Growth Characteristics | Usage | Type | Water Requirements | Harvest Method |
|---|---|---|---|---|---|---|
| Bayes Net | 99.59 | 96.79 | 91.31 | 99.13 | 85.69 | 89.17 |
| Naïve Bayes Classifier | 99.46 | 79.41 | 85.69 | 90.59 | 65.90 | 76.33 |
| Logistic | 97.99 | 83.28 | 86.76 | 91.04 | 80.62 | 66.57 |
| Multilayer Perception | 98.79 | 97.99 | 98.12 | 97.41 | 87.16 | 95.72 |
| Simple Logistic | 98.66 | 82.08 | 87.71 | 90.91 | 80.08 | 67.51 |
| IBK | 97.86 | 98.53 | 98.66 | 98.72 | 97.99 | 97.99 |
| KSTAR | 97.86 | 99.19 | 99.19 | 98.86 | 97.86 | 97.86 |
| LWL | 76.74 | 83.02 | 88.23 | 67.27 | 57.75 | 70.18 |
| Ada BoostM1 | 6.82 | 76.87 | 82.08 | 45.32 | 44.11 | 61.23 |
| Regression | 98.38 | 99.19 | 99.06 | 99.09 | 98.93 | 98.93 |
| Decision Table | 88.50 | 96.12 | 95.58 | 95.04 | 93.04 | 94.65 |
| Hoeffding Tree | 99.46 | 79.41 | 85.43 | 89.82 | 66.31 | 76.60 |
| J48 | 98.79 | 98.26 | 97.86 | 98.63 | 98.39 | 99.33 |
| Random Forest | 99.46 | 99.33 | 99.73 | 99.45 | 99.73 | 99.59 |
| Random Tree | 98.12 | 98.66 | 99.33 | 98.36 | 97.59 | 98.66 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Elbasi, E.; Zaki, C.; Topcu, A.E.; Abdelbaki, W.; Zreikat, A.I.; Cina, E.; Shdefat, A.; Saker, L. Crop Prediction Model Using Machine Learning Algorithms. Appl. Sci. 2023, 13, 9288. https://doi.org/10.3390/app13169288
Elbasi E, Zaki C, Topcu AE, Abdelbaki W, Zreikat AI, Cina E, Shdefat A, Saker L. Crop Prediction Model Using Machine Learning Algorithms. Applied Sciences. 2023; 13(16):9288. https://doi.org/10.3390/app13169288
Chicago/Turabian StyleElbasi, Ersin, Chamseddine Zaki, Ahmet E. Topcu, Wiem Abdelbaki, Aymen I. Zreikat, Elda Cina, Ahmed Shdefat, and Louai Saker. 2023. "Crop Prediction Model Using Machine Learning Algorithms" Applied Sciences 13, no. 16: 9288. https://doi.org/10.3390/app13169288