
A Comparison of Monocular Visual SLAM and Visual Odometry Methods Applied to 3D Reconstruction

 , ,
, , 
Abstract
:1. Introduction
- A comparison of 10 SLAM and VO methods, following the main classification described in the taxonomy (sparse-indirect, dense-indirect, dense-direct, and sparse-direct), to identify the advantages and limitations of each method of those classifications.
- A comparison of three machine learning-based methods against their classic geometric versions to identify whether there are significant improvements in adding neuronal networks to classic approaches.
- An inferential statistical analysis describing the procedure to identify significant differences based on the most suitable metrics for testing monocular RGB methods.
1.1. Related Works
1.1.1. Sparse-Indirect Methods
1.1.2. Dense-Indirect Methods
1.1.3. Dense-Direct Methods
1.1.4. Sparse-Direct Methods
1.1.5. Machine-Learning-Based Approaches
1.1.6. Comparisons
2. Materials and Methods
2.1. Taxonomy
- Direct vs. indirect. Indirect methods refer to those algorithms that implement preprocessing steps, like feature extraction or optical flow estimation, before their pose and map estimation processes; so, the amount of information that moves into the following steps is considerably reduced, requiring less computational power but also reducing the density of the final 3D reconstruction [21]. Indirect methods typically perform their optimization steps by minimizing the reprojection error due to the feature type of information that the preprocessing step outputs [41]. On the other hand, direct methods work directly on the pixel intensity information without requiring preprocessing steps, implying that the algorithm has more information for estimation tasks allowing one to obtain denser reconstructions of the scene, requiring more computational power [41]. In addition, direct methods typically perform their optimization steps based on the photometric error due to the direct pixel availability information.
- Dense vs. sparse. Dense vs. sparse classification refers to the amount of information recovered in the final map as a 3D reconstruction [21]. Denser reconstructions have more definition and continuity in the reconstructed objects and surfaces. In contrast, sparser reconstructions are typically represented as largely separated point clouds, where the edges and corners are commonly the only objects that can be recognized clearly [7].
- Classic vs. machine learning. Classic methods have been proposed in the last three decades, typically basing their formulation on geometric, optimization, and probabilistic techniques without machine learning. However, in recent years, due to the impressive advances in artificial intelligence, especially in Convolutional Neural Networks (CNN), many techniques have been applied to improve the SLAM or VO estimation tasks [11,32,36,42]. The methods based on classic formulations enhanced with machine learning are called Machine-learning-based approaches (ML).
2.2. Selected Algorithms
- ORB-SLAM2. As a sparse-indirect representative, we selected ORB-SLAM2 [54], widely known as the gold standard of this category, as most of the currently available sparse-indirect methods are proposals inspired by this algorithm. The original ORB-SLAM [24] extracts ORB features as preprocessing of multiscale FAST corners with a 256-bit descriptor giving that algorithm information to perform a Bundle Adjustment for optimization and work in three threads for tracking, local mapping, and loop closure. In addition, the ORB-SLAM2 incorporates a fourth thread to perform full Bundle Adjustment after loop closure extending the original method and obtaining the scene optimal geometric representation. The ORB-SLAM2 is publicly available as an open source code in [55]; it may be implemented in its C++ version or ROS version, with minimum additional requirements, Pangolin, OpenCV (tested for 2.4.3 version), Eigen 3 (tested for 3.1.0 version), DBoW2, and g2o, which are included in the repository.
- DF-ORB-SLAM. Classic dense-indirect methods available in the literature, like [25,26], are not available as open-source code for implementation; so, they could not be considered for this evaluation. Instead, a well-known classic dense-direct version of ORB-SLAM2 exists, called DF-ORB-SLAM [16], with its code publicly available on GitHub. The DF-ORB-SLAM algorithm was built based on the ORB-SLAM2 algorithm, allowing the addition of depth map retrieval capabilities and incorporating optical flow to track the detected points; thus, this algorithm uses a large amount of information obtained through the input using most of the pixel values for optical flow estimation. Once the optical flow is estimated, the ORB-SLAM2 performs feature extraction on the optical flow domain executing the rest of its pipeline. The DF-ORB-SLAM is publicly available in [16], implemented in Ubuntu 18.04 in its ROS version using its official build_ros.sh script.
- LSD-SLAM. The LSD-SLAM [29] is one of the most popular methods of the dense-direct category, since it has been the basis and inspiration for a lot of the methods currently available [10,21,56]. The LSD-SLAM not only locally tracks the camera’s movement but also allows the construction of dense maps through a semi-dense geometric representation tracking the depth values only in high-gradient areas. The method has direct image alignment mechanisms and estimation based on the semi-dense depth map filtering technique [57]. The global depth map is rendered as a pose graph comprising keyframes represented as vertices that present feature 3D similarity transformations as edges, adding environment scaling ability and allowing the accumulated drift to be detected and corrected. Furthermore, the LSD-SLAM uses an appearance-based loop detection algorithm called FAB-MAP [58], introducing prominent loop closure candidates that extract their features without reusing any additional visual odometry information. The LSD-SLAM is publicly available in [59] and was implemented in Ubuntu 18.04 in its ROS version.
- DSO. The DSO [21] is widely known as the direct methods’ gold standard due to the impressive reconstruction and odometry results that it has achieved, inspiring other implementations and new proposals. The DSO works directly on the pixel intensity information but applies a point selection strategy to reduce the amount of information to be processed efficiently, continuously optimizing the photometric error applied to the last N-frames while optimizing the complete likelihood for the parameters involved in the model, including poses, intrinsics, extrinsics, and inverse depths, executing a windowed sparse bundle adjustment. The DSO is publicly available for implementation in [60]; its code runs entirely in C++, using minor requirements like Suitesparse, Eigen3, and Pangolin.
- SVO. We selected the most commonly known method, SVO [12], for the hybrid classification. The SVO efficiently combines the advantages of the direct and indirect approaches by using the feature correspondences obtained on the direct motion estimation for tracking and mapping. This procedure considerably reduces the number of required features and is only executed when a new keyframe is selected to insert new points in the map. First, camera motion is estimated by a sparse model-based image alignment algorithm, where sparse point features are used to estimate the feature correspondences. Next, this information is used to minimize the photometric error. Then the reprojected points, pose, and structure are refined by minimizing the reprojection error. The SVO is publicly available in [61] for testing and implementation running on C++ or ROS. Modern operating systems might find issues during implementation; so, Ubuntu 16.04 and ROS kinetic were used.
- LDSO. As an additional sparse direct system, the LDSO [30] was selected as an update of the DSO algorithm that includes loop-closure capabilities. The LDSO enables the DSO framework to detect the loop closure by ensuring point repeatability using corner features to detect loop candidates. For this purpose, the depth estimates for point features allow the algorithm to compute the constraints, to be combined with the pose-only bundle adjustment and point cloud alignment and fused with the relative pose DSO covisibility graph, sliding the window optimization stage. This way, the LDSO adds the loop closure to the DSO system, including a loop closure module based on a global pose graph optimization working over the last five to seven keyframes’ sliding window. The LDSO was made publicly available in [62], and for this comparison, it was implemented in Ubuntu 18.04 along with OpenCV 2.4.3, Sophus, DBoW3, and g2o.
- DSM. Another sparse-direct method we were interested in testing was the DSM [31], another update made to the DSO to create a complete SLAM system. The DSM aimed to include scene reobservation information to enhance the precision and reduce the drift and inconsistencies. In contrast to the LDSO, which considers a sparse set of reobservations, the DSM builds a persistent map allowing the algorithm to reuse existing information by a photometric formulation. The DSM uses local map covisibility window criteria to detect the active keyframes reobserving the same region, a coarse-to-fine strategy to process that point reobservation information and a robust nonlinear photometric bundle adjustment technique based on the photometric error for outlier detection. The DSM open-source code is publicly available in [63], which was implemented for comparisons on Ubuntu 18.04 with Eigen (v3.1.0), OpenCV (v2.4.3), and Ceres solver, which were provided in the official repository.
- DynaSLAM. The Dyna-SLAM algorithm [32] is a lighter version of ORB-SLAM2 exceeded by adding the detection, segmentation, and inpainting of dynamic information on scenes’ machine learning capabilities. In addition, the Mask R-CNN of [64] was integrated with the classic sparse-indirect method to detect and segment regions of each image that potentially belonged to movable objects. The authors also incorporated a multiview geometry approach calculating backprojections to define the key point parallax angles to detect additional information the CNN cannot recognize. The authors reported that this combination contributed to overcoming the ORB-SLAM2 initialization issues; so, it works in dynamic environments. The DynaSLAM is publicly available in [17], and it was implemented in Ubuntu 16.04 with ROS Kinetic, Cuda 9, Tensorflow 1.4.0, and Keras 2.0.8.
- CNN-DSO. In the literature, DSO neuronal methods like D3VO [65], MonoRec [14], and DDSO [66] can be found. Nevertheless, they are not publicly available, or in the case of MonoRec, its monocular VO pipeline is not available for testing; so, the CNN-DSO was selected for this comparison, which is publicly available in [15]. This method includes a CNN depth prediction module enabling the DSO system to execute its estimation modules using additional depth prior information obtained by the network. The CNN used for this study was the MonoDepth system of [67], a single image depth estimation network that outputs a depth value for each pixel position by chains of feature maps processing. The network was built over the ResNet backbone using a variant of its encoder–decoder architecture. The CNN-DSO requires building TensorFlow (v1.6.0) from source and MonoDepth from its official repository [68], and it was implemented in Ubuntu 18.04, with Eigen (v3.1.0) and OpenCV (v2.4.3).
- CNN-SVO. In the study of [11], an extension of the hybrid method SVO was proposed by fusing the same Single Image Depth Estimation (SIDE) CNN MonoDepth module used in the CNN-DSO with the original geometric-based hybrid method. In this case, MonoDepth was included to add preliminary depth information to the SVO pipeline, minimizing the uncertainty in the feature correspondence identification steps; then, the system is initialized, obtaining high uncertainty maps. Then, the SIDE CNN creates filters to approximate the current values’ mean and variance, considerably reducing the amount of information separating inliers/outliers in the depth map. The CNN-SVO is publicly available in [46] and was implemented in Ubuntu 16.04 to allow the SVO modules to work with ROS Kinetic.
2.3. Benchmarks
- The KITTI dataset in [74] contains 21 video sequences of a driving car, where the movement parameters are limited to forward driving. The available images have pre-rectification treatments, and the dataset provides a ground truth obtained through an assembly of GPS and INS.
- The EUROC-MAV dataset in [75] contains 11 inertial stereoscopic sequences of a quadcopter flying in different indoor environments providing groundtruth values of all frames and calibration parameters.
- The TUM-Mono dataset in [6] presents 50 sequences of indoor/outdoor environments obtained using monocular RBG cameras on monochrome uEye UI-3241LE-M-GL cameras equipped with Lensagon BM2420 (with 148° × 122° field of view) and Lensagon BM4018S118 (with 98° × 79° field of view) sensors. This benchmark includes the photometric calibration parameters, the ground truth, the timestamps for the execution of each image sequence, and the calibration file for the vignetting effect in each sequence, comprising more than 190,000 frames and more than 100 min of video.
- The ICL-NUIM benchmark in [8] has eight sequences in conjunction with its ray-tracing of two environments, providing the groundtruth values of each sequence and camera intrinsics; so, no photometric calibration is required. This dataset presents degenerative and purely rotational motion sequences, which are considered demanding for monocular algorithms.
2.4. Metrics
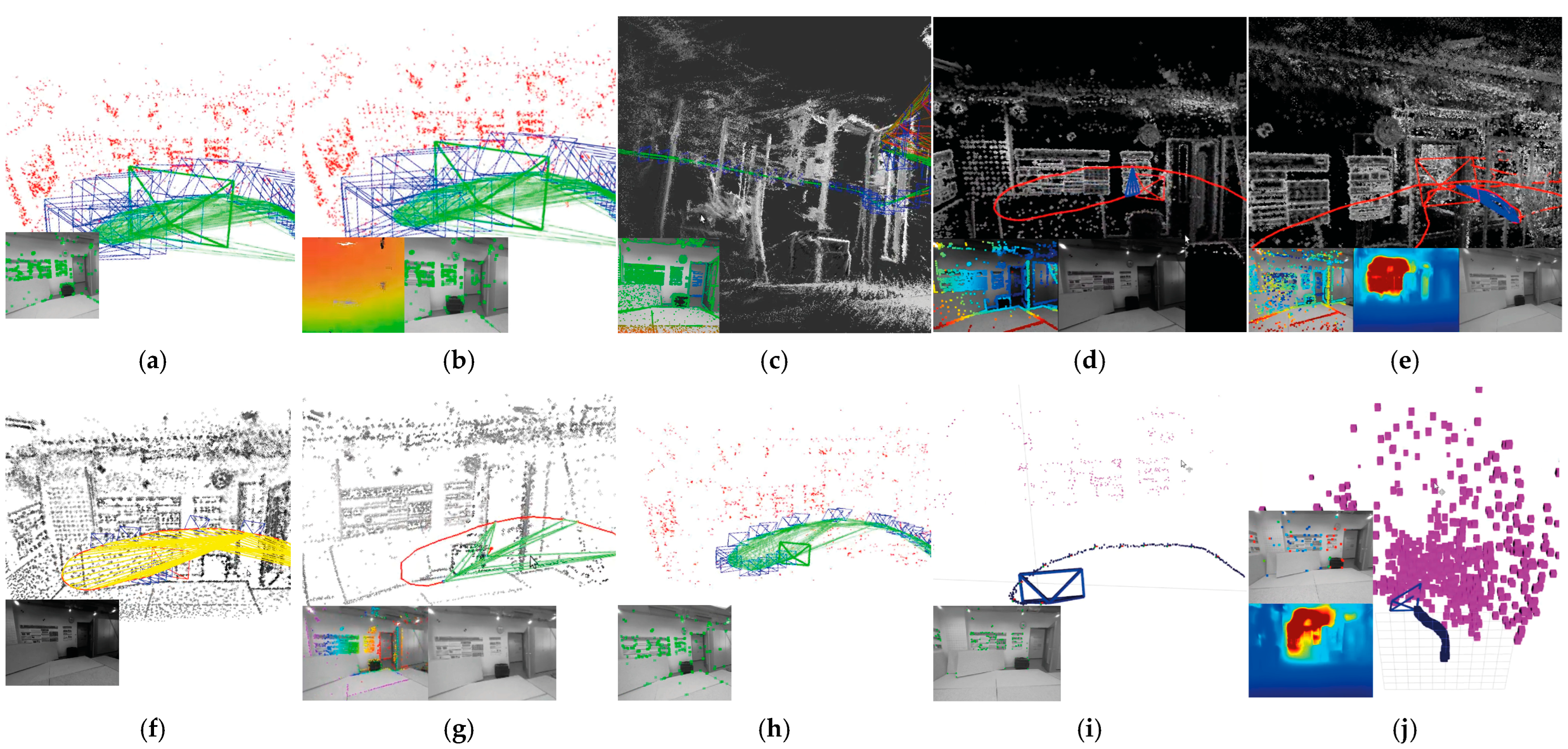
3. Results
3.1. Hardware Setup
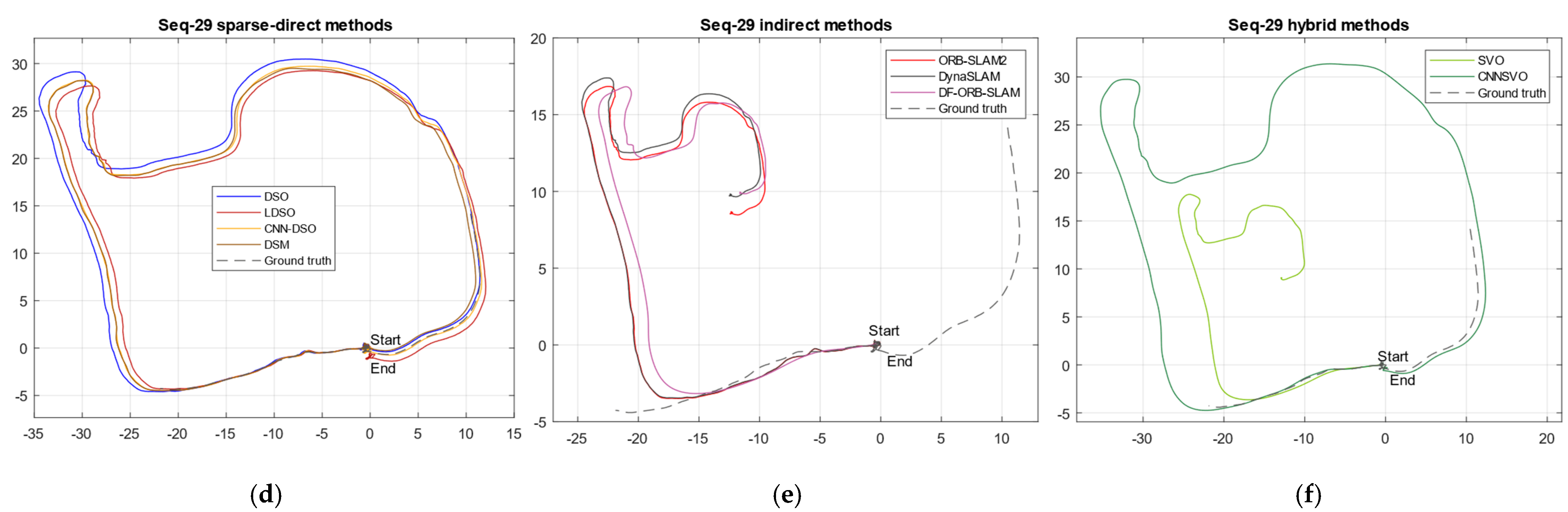
3.2. Comparative Analysis
4. Discussion
5. Conclusions
Author Contributions
Funding
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Lee, S.J.; Choi, H.; Hwang, S.S. Real-time Depth Estimation Using Recurrent CNN with Sparse Depth Cues for SLAM System. Int. J. Control. Autom. Syst. 2019, 18, 206–216. [Google Scholar] [CrossRef]
- Czarnowski, J.; Laidlow, T.; Clark, R.; Davison, A.J. DeepFactors: Real-Time Probabilistic Dense Monocular SLAM. IEEE Robot. Autom. Lett. 2020, 5, 721–728. [Google Scholar] [CrossRef]
- Aqel, M.O.A.; Marhaban, M.H.; Saripan, M.I.; Ismail, N.B. Review of visual odometry: Types, approaches, challenges, and applications. Springerplus 2016, 5, 1897. [Google Scholar] [CrossRef]
- Zollhöfer, M.; Thies, J.; Garrido, P.; Bradley, D.; Beeler, T.; Pérez, P.; Stamminger, M.; Nießner, M.; Theobalt, C. State of the Art on Monocular 3D Face Reconstruction, Tracking, and Applications. Comput. Graph. Forum 2018, 37, 523–550. [Google Scholar] [CrossRef]
- Aslan, M.F.; Durdu, A.; Yusefi, A.; Sabanci, K.; Sungur, C. A Tutorial: Mobile Robotics, SLAM, Bayesian Filter, Keyframe Bundle Adjustment and ROS Applications. In Robot Operating System (ROS): The Complete Reference; Koubaa, A., Ed.; Springer International Publishing: Cham, Switzerland, 2021; Volume 6, pp. 227–269. [Google Scholar]
- Engel, J.; Usenko, V.; Cremers, D. A Photometrically Calibrated Benchmark For Monocular Visual Odometry. arXiv 2016, arXiv:1607.02555. [Google Scholar]
- Barros, A.M.; Michel, M.; Moline, Y.; Corre, G.; Carrel, F. A Comprehensive Survey of Visual SLAM Algorithms. Robotics 2022, 11, 24. [Google Scholar] [CrossRef]
- Handa, A.; Whelan, T.; McDonald, J.; Davison, A.J. A benchmark for RGB-D visual odometry, 3D reconstruction and SLAM. In Proceedings of the 2014 IEEE International Conference on Robotics and Automation (ICRA), Hong Kong, China, 31 May 2014–7 June 2014; pp. 1524–1531. [Google Scholar]
- Herrera-Granda, E.P. An Extended Taxonomy for Monocular Visual SLAM, Visual Odometry, and Structure from Motion methods applied to 3D Reconstruction. GitHub Repository. 2023. Available online: https://github.com/erickherreraresearch/TaxonomyPureVisualMonocularSLAM/ (accessed on 16 June 2023).
- Tateno, K.; Tombari, F.; Laina, I.; Navab, N. CNN-SLAM: Real-time dense monocular SLAM with learned depth prediction. In Proceedings of the 30th IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2016; pp. 6565–6574. [Google Scholar]
- Loo, S.Y.; Amiri, A.J.; Mashohor, S.; Tang, S.H.; Zhang, H. CNN-SVO: Improving the Mapping in Semi-Direct Visual Odometry Using Single-Image Depth Prediction. In Proceedings of the 2019 International Conference on Robotics and Automation (ICRA), Montreal, QC, Canada, 20–24 May 2019. [Google Scholar] [CrossRef]
- Forster, C.; Zhang, Z.; Gassner, M.; Werlberger, M.; Scaramuzza, D. SVO: Semidirect Visual Odometry for Monocular and Multicamera Systems. IEEE Trans. Robot. 2016, 33, 249–265. [Google Scholar] [CrossRef]
- Forster, C.; Pizzoli, M.; Scaramuzza, D. SVO: Fast semi-direct monocular visual odometry. In Proceedings of the 2014 IEEE International Conference on Robotics and Automation (ICRA), Hong Kong, China, 31 May–7 June 2014; pp. 15–22. [Google Scholar]
- Wimbauer, F.; Yang, N.; von Stumberg, L.; Zeller, N.; Cremers, D. MonoRec: Semi-Supervised Dense Reconstruction in Dynamic Environments from a Single Moving Camera. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 6108–6118. [Google Scholar]
- Muskie. CNN-DSO: A Combination of Direct Sparse Odometry and CNN Depth Prediction. GitHub Repository. 2019. Available online: https://github.com/muskie82/CNN-DSO (accessed on 16 June 2023).
- Wang, S. DF-ORB-SLAM. GitHub Repository. 2020. Available online: https://github.com/834810269/DF-ORB-SLAM (accessed on 16 June 2023).
- Bescos, B. DynaSLAM. GitHub Repository. 2019. Available online: https://github.com/BertaBescos/DynaSLAM (accessed on 16 June 2023).
- Sun, J.; Wang, Y.; Shen, Y. Fully Scaled Monocular Direct Sparse Odometry with A Distance Constraint. In Proceedings of the 2019 5th International Conference on Control, Automation and Robotics (ICCAR), Beijing, China, 19–22 April 2019; pp. 271–275. [Google Scholar] [CrossRef]
- Sundar, A. CNN-SLAM. GitHub Repository. 2018. Available online: https://github.com/iitmcvg/CNN_SLAM (accessed on 16 June 2023).
- Tang, C.; Tan, P. BA-Net: Dense Bundle Adjustment Network. arXiv 2018, arXiv:1806.04807. [Google Scholar]
- Engel, J.; Koltun, V.; Cremers, D. Direct Sparse Odometry. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 611–625. [Google Scholar] [CrossRef]
- Davison, A.J.; Reid, I.D.; Molton, N.D.; Stasse, O. MonoSLAM: Real-Time Single Camera SLAM. IEEE Trans. Pattern Anal. Mach. Intell. 2007, 29, 1052–1067. [Google Scholar] [CrossRef] [PubMed]
- Klein, G.; Murray, D. Parallel Tracking and Mapping for Small AR Workspaces. In Proceedings of the 2007 6th IEEE and ACM International Symposium on Mixed and Augmented Reality, Nara, Japan, 13–16 November 2007; pp. 225–234. [Google Scholar]
- Mur-Artal, R.; Montiel, J.M.M.; Tardos, J.D. ORB-SLAM: A Versatile and Accurate Monocular SLAM System. IEEE Trans. Robot. 2015, 31, 1147–1163. [Google Scholar] [CrossRef]
- Valgaerts, L.; Bruhn, A.; Mainberger, M.; Weickert, J. Dense versus Sparse Approaches for Estimating the Fundamental Matrix. Int. J. Comput. Vis. 2011, 96, 212–234. [Google Scholar] [CrossRef]
- Ranftl, R.; Vineet, V.; Chen, Q.; Koltun, V. Dense Monocular Depth Estimation in Complex Dynamic Scenes. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 1–26 July 2016; pp. 4058–4066. [Google Scholar] [CrossRef]
- Stühmer, J.; Gumhold, S.; Cremers, D. Real-Time Dense Geometry from a Handheld Camera. In Proceedings of the 32nd DAGM Symposium, Darmstadt, Germany, 22–24 September 2010; pp. 11–20. [Google Scholar]
- Pizzoli, M.; Forster, C.; Scaramuzza, D. REMODE: Probabilistic, monocular dense reconstruction in real time. In Proceedings of the IEEE International Conference on Robotics and Automation, Hong Kong, China, 31 May–5 June 2014; pp. 2609–2616. [Google Scholar]
- Engel, J.; Schöps, T.; Cremers, D. LSD-SLAM: Large-Scale Direct monocular SLAM. In European Conference on Computer Vision; Springer International Publishing: Cham, Switzerland, 2014; pp. 834–849. [Google Scholar]
- Gao, X.; Wang, R.; Demmel, N.; Cremers, D. LDSO: Direct Sparse Odometry with Loop Closure. In Proceedings of the 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Madrid, Spain, 1–5 October 2018; pp. 2198–2204. [Google Scholar] [CrossRef]
- Zubizarreta, J.; Aguinaga, I.; Montiel, J.M.M. Direct Sparse Mapping. IEEE Trans. Robot. 2020, 36, 1363–1370. [Google Scholar] [CrossRef]
- Bescos, B.; Facil, J.M.; Civera, J.; Neira, J. DynaSLAM: Tracking, Mapping, and Inpainting in Dynamic Scenes. IEEE Robot. Autom. Lett. 2018, 3, 4076–4083. [Google Scholar] [CrossRef]
- Bloesch, M.; Czarnowski, J.; Clark, R.; Leutenegger, S.; Davison, A.J. CodeSLAM—Learning a Compact, Optimisable Representation for Dense Visual SLAM. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 2560–2568. [Google Scholar]
- Min, Z.; Dunn, E. VOLDOR+SLAM: For the Times When Feature-Based or Direct Methods Are Not Good Enough. In Proceedings of the 2021 IEEE International Conference on Robotics and Automation, Xi’an, China, 30 May–5 June 2021; pp. 13813–13819. [Google Scholar] [CrossRef]
- Teed, Z.; Deng, J. DROID-SLAM: Deep Visual SLAM for Monocular, Stereo, and RGB-D Cameras. Adv. Neural Inf. Process. Syst. 2021, 34, 16558–16569. [Google Scholar]
- Yang, C.; Chen, Q.; Yang, Y.; Zhang, J.; Wu, M.; Mei, K. SDF-SLAM: A Deep Learning Based Highly Accurate SLAM Using Monocular Camera Aiming at Indoor Map Reconstruction with Semantic and Depth Fusion. IEEE Access 2022, 10, 10259–10272. [Google Scholar] [CrossRef]
- Lang, R.; Fan, Y.; Chang, Q. SVR-Net: A Sparse Voxelized Recurrent Network for Robust Monocular SLAM with Direct TSDF Mapping. Sensors 2023, 23, 3942. [Google Scholar] [CrossRef]
- Yang, N.; Wang, R.; Gao, X.; Cremers, D. Challenges in Monocular Visual Odometry: Photometric Calibration, Motion Bias, and Rolling Shutter Effect. IEEE Robot. Autom. Lett. 2018, 3, 2878–2885. [Google Scholar] [CrossRef]
- Mingachev, E.; Lavrenov, R.; Magid, E.; Svinin, M. Comparative Analysis of Monocular SLAM Algorithms Using TUM and EuRoC Benchmarks. In Proceedings of the 15th International Conference on Electromechanics and Robotics” Zavalishin’s Readings” ER (ZR) 2020, Ufa, Russia, 15–18 April 2020; pp. 343–355. [Google Scholar] [CrossRef]
- Mingachev, E.; Lavrenov, R.; Tsoy, T.; Matsuno, F.; Svinin, M.; Suthakorn, J.; Magid, E. Comparison of ROS-Based Monocular Visual SLAM Methods: DSO, LDSO, ORB-SLAM2 and DynaSLAM. In Interactive Collaborative Robotics; Springer: Cham, Switzerland, 2020; pp. 222–233. [Google Scholar] [CrossRef]
- Servières, M.; Renaudin, V.; Dupuis, A.; Antigny, N. Visual and Visual-Inertial SLAM: State of the Art, Classification, and Experimental Benchmarking. J. Sensors 2021, 2021, 2054828. [Google Scholar] [CrossRef]
- Wimbauer, F.; Yang, N. MonoRec. GitHub Repository. 2017. Available online: https://github.com/Brummi/MonoRec (accessed on 16 June 2023).
- Czarnowski, J.; Kaneko, M. DeepFactors. GitHub Repository. 2020. Available online: https://github.com/jczarnowski/DeepFactors (accessed on 16 June 2023).
- Zhang, S. DVSO: Deep Virtual Stereo Odometry. GitHub Repository. 2022. Available online: https://github.com/SenZHANG-GitHub/dvso (accessed on 16 June 2023).
- Cheng, R. CNN-DVO. McGill Repository. McGill. 2020. Available online: http://www.cim.mcgill.ca/∼mrl/ran/crv2020 (accessed on 16 June 2023).
- Loo, S.Y. CNN-SVO. GitHub Repository. 2019. Available online: https://github.com/yan99033/CNN-SVO (accessed on 16 June 2023).
- Steenbeek, A. Sparse-to-Dense: Depth Prediction from Sparse Depth Samples and a Single Image. GitHub Repository. 2022. Available online: https://github.com/annesteenbeek/sparse-to-dense-ros (accessed on 16 June 2023).
- Ummenhofer, B. DeMoN: Depth and Motion Network. GitHub Repository. 2022. Available online: https://github.com/lmb-freiburg/demon (accessed on 16 June 2023).
- Teed, Z.; Deng, J. DeepV2D. GitHub Repository. 2020. Available online: https://github.com/princeton-vl/DeepV2D (accessed on 16 June 2023).
- Min, Z. VOLDOR: Visual Odometry from Log-logistic Dense Optical Flow Residual. GitHub Repository. 2020. Available online: https://github.com/htkseason/VOLDOR (accessed on 16 June 2023).
- Teed, Z.; Deng, J. DROID-SLAM. GitHub Repository. 2022. Available online: https://github.com/princeton-vl/DROID-SLAM (accessed on 16 June 2023).
- Zhou, H.; Ummenhofer, B.; Brox, T. DeepTAM. GitHub Repository. 2019. Available online: https://github.com/lmb-freiburg/deeptam (accessed on 16 June 2023).
- Troscot, S. CodeSLAM. GitHub Repository. 2022. Available online: https://github.com/silviutroscot/CodeSLAM (accessed on 16 June 2023).
- Mur-Artal, R.; Tardos, J.D. ORB-SLAM2: An Open-Source SLAM System for Monocular, Stereo, and RGB-D Cameras. IEEE Trans. Robot. 2017, 33, 1255–1262. [Google Scholar] [CrossRef]
- Mur-Artal, R. ORB-SLAM2. GitHub Repository. 2017. Available online: https://github.com/raulmur/ORB_SLAM2 (accessed on 16 June 2023).
- Matsuki, H.; von Stumberg, L.; Usenko, V.; Stueckler, J.; Cremers, D. Omnidirectional DSO: Direct Sparse Odometry with Fisheye Cameras. IEEE Robot. Autom. Lett. 2018, 3, 3693–3700. [Google Scholar] [CrossRef]
- Engel, J.; Sturm, J.; Cremers, D. Semi-dense visual odometry for a monocular camera. In Proceedings of the IEEE International Conference on Computer Vision, Sydney, Australia, 2–8 December 2013; pp. 1449–1456. [Google Scholar]
- Cummins, M.; Newman, P. FAB-MAP: Probabilistic Localization and Mapping in the Space of Appearance. Int. J. Robot. Res. 2008, 27, 647–665. [Google Scholar] [CrossRef]
- Engel, J. LSD-SLAM: Large-Scale Direct Monocular SLAM. GitHub Repository. 2014. Available online: https://github.com/tum-vision/lsd_slam (accessed on 16 June 2023).
- Engel, J. DSO: Direct Sparse Odometry. GitHub Repository. 2017. Available online: https://github.com/JakobEngel/dso (accessed on 16 June 2023).
- Forster, C. Semi-Direct Monocular Visual Odometry. GitHub Repository. 2017. Available online: https://github.com/uzh-rpg/rpg_svo (accessed on 16 June 2023).
- Demmel, N.; Xiang, G.; Erkam, U. LDSO: Direct Sparse Odometry with Loop Closure. GitHub Repository. 2020. Available online: https://github.com/tum-vision/LDSO (accessed on 16 June 2023).
- Zubizarreta, J. DSM: Direct Sparse Mapping. GitHub Repository. 2021. Available online: https://github.com/jzubizarreta/dsm (accessed on 16 June 2023).
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask R-CNN. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 27–29 October 2017; pp. 2980–2988. [Google Scholar]
- Yang, N.; von Stumberg, L.; Wang, R.; Cremers, D. D3VO: Deep Depth, Deep Pose and Deep Uncertainty for Monocular Visual Odometry. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 1278–1289. [Google Scholar]
- Zhao, C.; Tang, Y.; Sun, Q.; Vasilakos, A.V. Deep Direct Visual Odometry. IEEE Trans. Intell. Transp. Syst. 2021, 23, 7733–7742. [Google Scholar] [CrossRef]
- Godard, C.; Mac Aodha, O.; Brostow, G.J. Unsupervised Monocular Depth Estimation with Left-Right Consistency. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Loo, S.Y. MonoDepth CPP. 2021. Available online: https://github.com/yan99033/monodepth-cpp (accessed on 16 June 2023).
- Gurturk, M.; Yusefi, A.; Aslan, M.F.; Soycan, M.; Durdu, A.; Masiero, A. The YTU dataset and recurrent neural network based visual-inertial odometry. Measurement 2021, 184, 109878. [Google Scholar] [CrossRef]
- Chen, T.; Pu, F.; Chen, H.; Liu, Z. WHUVID: A Large-Scale Stereo-IMU Dataset for Visual-Inertial Odometry and Autonomous Driving in Chinese Urban Scenarios. Remote Sens. 2022, 14, 2033. [Google Scholar] [CrossRef]
- Wong, A.; Fei, X.; Tsuei, S.; Soatto, S. Unsupervised Depth Completion From Visual Inertial Odometry. IEEE Robot. Autom. Lett. 2020, 5, 1899–1906. [Google Scholar] [CrossRef]
- Cordts, M. The Cityscapes Dataset for Semantic Urban Scene Understanding. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 3213–3223. [Google Scholar]
- Huang, X. The ApolloScape Dataset for Autonomous Driving. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Salt Lake City, UT, USA, 18–22 June 2018; pp. 1067–10676. [Google Scholar]
- Geiger, A.; Lenz, P.; Urtasun, R. Are we ready for autonomous driving? The KITTI vision benchmark suite. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Providence, RI, USA, 16–21 June 2012; pp. 3354–3361. [Google Scholar] [CrossRef]
- Burri, M.; Nikolic, J.; Gohl, P.; Schneider, T.; Rehder, J.; Omari, S.; Achtelik, M.W.; Siegwart, R. The EuRoC micro aerial vehicle datasets. Int. J. Robot. Res. 2016, 35, 1157–1163. [Google Scholar] [CrossRef]
- Butler, D.J.; Wulff, J.; Stanley, G.B.; Black, M.J. A naturalistic open source movie for optical flow evaluation. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2012; pp. 611–625. [Google Scholar]
- Zamir, A.R.; Sax, A.; Shen, W.; Guibas, L.; Malik, J.; Savarese, S. Taskonomy: Disentangling Task Transfer Learning. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 3712–3722. [Google Scholar]
- Yin, W.; Liu, Y.; Shen, C. Virtual Normal: Enforcing Geometric Constraints for Accurate and Robust Depth Prediction. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 44, 7282–7295. [Google Scholar] [CrossRef]
- Cho, J.; Min, D.; Kim, Y.; Sohn, K. A Large RGB-D Dataset for Semi-supervised Monocular Depth Estimation. arXiv 2019, arXiv:1904.10230. [Google Scholar]
- Xian, K. Monocular Relative Depth Perception with Web Stereo Data Supervision. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 311–320. [Google Scholar]
- Sturm, J.; Engelhard, N.; Endres, F.; Burgard, W.; Cremers, D. A benchmark for the evaluation of RGB-D SLAM systems. In Proceedings of the 2012 IEEE/RSJ International Conference on Intelligent Robots and Systems, Algarve, Portugal, 7–12 October 2012; pp. 573–580. [Google Scholar]
- Horn, B.K.P. Closed-form solution of absolute orientation using unit quaternions. J. Opt. Soc. Am. A 1987, 4, 629–642. [Google Scholar] [CrossRef]
- Sarabandi, S.; Thomas, F. Accurate Computation of Quaternions from Rotation Matrices. In Advances in Robot Kinematics; Springer: Cham, Switzerland, 2018; pp. 39–46. [Google Scholar] [CrossRef]
- Devernay, F.; Faugeras, O. Straight lines have to be straight. Mach. Vis. Appl. 2001, 13, 14–24. [Google Scholar] [CrossRef]
- Castle, R. PTAM-GPL: Parallel Tracking and Mapping. GitHub Repository. 2013. Available online: https://github.com/Oxford-PTAM/PTAM-GPL (accessed on 16 June 2023).
- ROS.org. ROS Camera Calibration. 2020. Available online: http://wiki.ros.org/camera_calibration (accessed on 26 December 2022).
- Vision, O.S.C. Camera Calibration with OpenCV. 2019. Available online: https://docs.opencv.org/4.1.1/d4/d94/tutorial_camera_calibration.html (accessed on 26 December 2022).
- Ghorbani, H. MAHALANOBIS DISTANCE AND ITS APPLICATION FOR DETECTING MULTIVARIATE OUTLIERS. Facta Univ. Ser. Math. Inform. 2019, 34, 583–595. [Google Scholar] [CrossRef]
- Steenbeek, A.; Nex, F. CNN-Based Dense Monocular Visual SLAM for Real-Time UAV Exploration in Emergency Conditions. Drones 2022, 6, 79. [Google Scholar] [CrossRef]
- Sun, L.; Yin, W.; Xie, E.; Li, Z.; Sun, C.; Shen, C. Improving Monocular Visual Odometry Using Learned Depth. IEEE Trans. Robot. 2022, 38, 3173–3186. [Google Scholar] [CrossRef]
- Ummenhofer, B.; Zhou, H.; Uhrig, J.; Mayer, N.; Ilg, E.; Dosovitskiy, A.; Brox, T. DeMoN: Depth and Motion Network for Learning Monocular Stereo. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 5622–5631. [Google Scholar] [CrossRef]
- Teed, Z.; Deng, J. DeepV2D: Video to Depth with Differentiable Structure from Motion. arXiv 2018, arXiv:1812.04605. [Google Scholar]
- Zhou, H.; Ummenhofer, B.; Brox, T. DeepTAM: Deep Tracking and Mapping with Convolutional Neural Networks. Int. J. Comput. Vis. 2019, 128, 756–769. [Google Scholar] [CrossRef]
- Laidlow, T.; Czarnowski, J.; Leutenegger, S. DeepFusion: Real-Time Dense 3D Reconstruction for Monocular SLAM using Single-View Depth and Gradient Predictions. In Proceedings of the 2019 International Conference on Robotics and Automation (ICRA), Montreal, QC, Canada, 20–24 May 2019; pp. 4068–4074. [Google Scholar] [CrossRef]
- Yang, N.; Wang, R.; Stückler, J.; Cremers, D. Deep Virtual Stereo Odometry: Leveraging Deep Depth Prediction for Monocular Direct Sparse Odometry. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2018; pp. 835–852. [Google Scholar] [CrossRef]
- Tang, C. BA-Net: Dense Bundle Adjustment Network. GitHub Repository. 2020. Available online: https://github.com/frobelbest/BANet (accessed on 26 December 2022).














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Component | Specifications |
|---|---|
| CPU | AMD Ryzen™ 7 3800X, eight cores, 16 threads, 3.9–4.5 GHz. |
| GPU | NVIDIA GEFORCE GTX 1080 Ti. Pascal architecture, 1582 MHz, 3584 CUDA cores, 11 GB GDDR5X. |
| RAM | 16 GB, DDR 4, 3200 MHz |
| ROM | SSD NVME M.2 Western Digital 7300 MB/s |
| Power consumption | 750 W 1 |
| Method | Overall CPU Usage, Multicore | Current CPU Usage | GPU Usage | Memory Usage | Time (s) | FPS |
|---|---|---|---|---|---|---|
| ORB-SLAM2 | 1.8472% | 16.2374% | 1.2376% | 9.2147% | 128.4571 | 37 |
| DF-ORB-SLAM | 1.9254% | 17.4235% | 1.7861% | 12.4572% | 133.1217 | 36 |
| LSD-SLAM | 2.4578% | 18.4521% | 1.6423% | 10.3457% | 138.4172 | 34 |
| DSO | 1.2604% | 14.6818% | 1.8971% | 9.3892% | 91.2564 | 52 |
| SVO | 1.1286% | 10.4589% | 1.7852% | 8.5316% | 87.5241 | 55 |
| LDSO | 1.6909% | 15.4717% | 3.1588% | 14.2962% | 99.4758 | 48 |
| DSM | 1.8346% | 31.9216% | 2.7203% | 24.1591% | 315.4982 | 15 |
| DynaSLAM | 1.9247% | 21.4576% | 15.3467% | 20.3879% | 118.3245 | 40 |
| CNN-DSO | 4.0647% | 30.9091% | 27.5346% | 24.6742% | 161.2389 | 30 |
| CNN-SVO | 3.2579% | 27.8461% | 24.4732% | 23.5476% | 134.7583 | 35 |
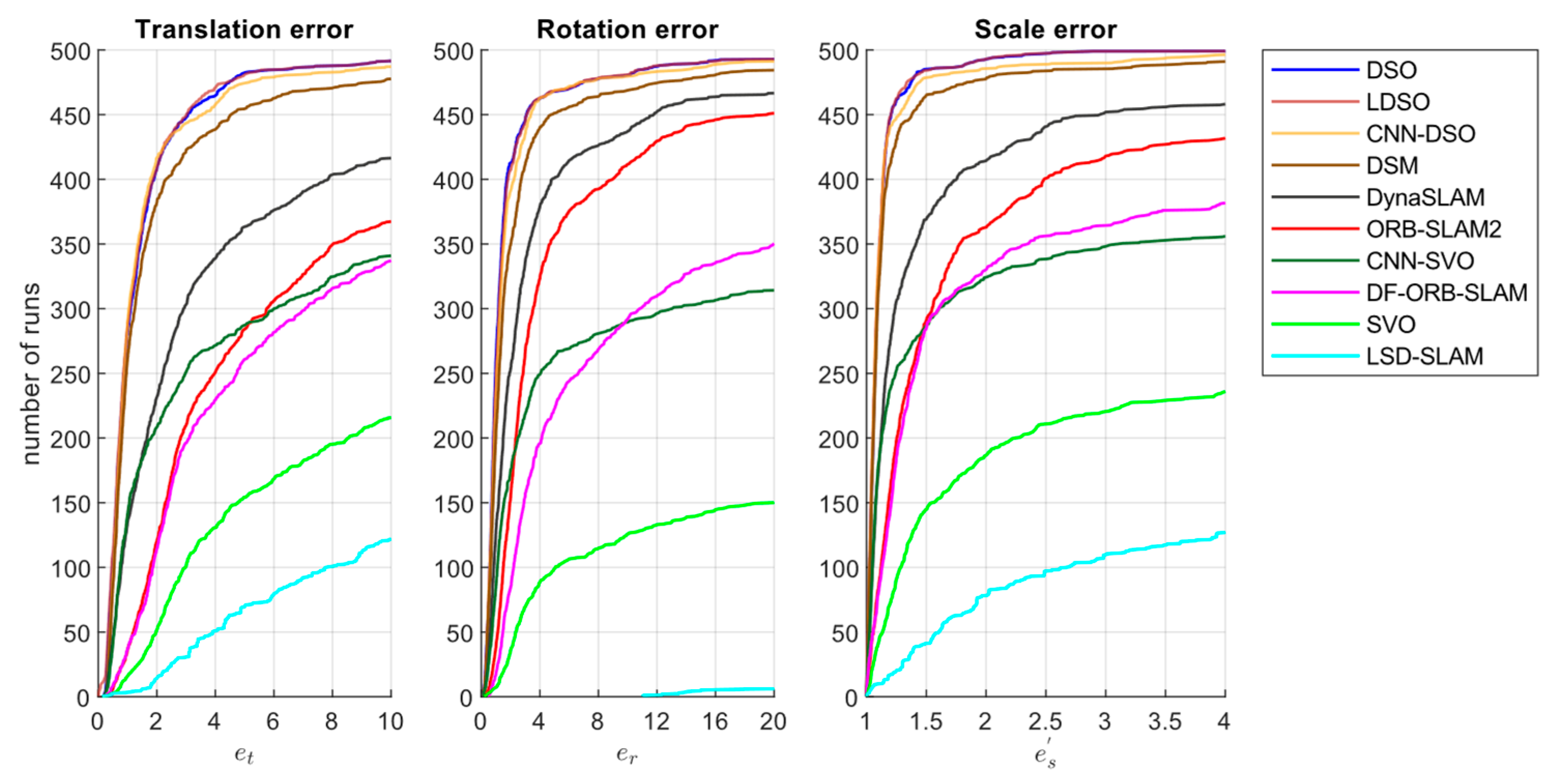
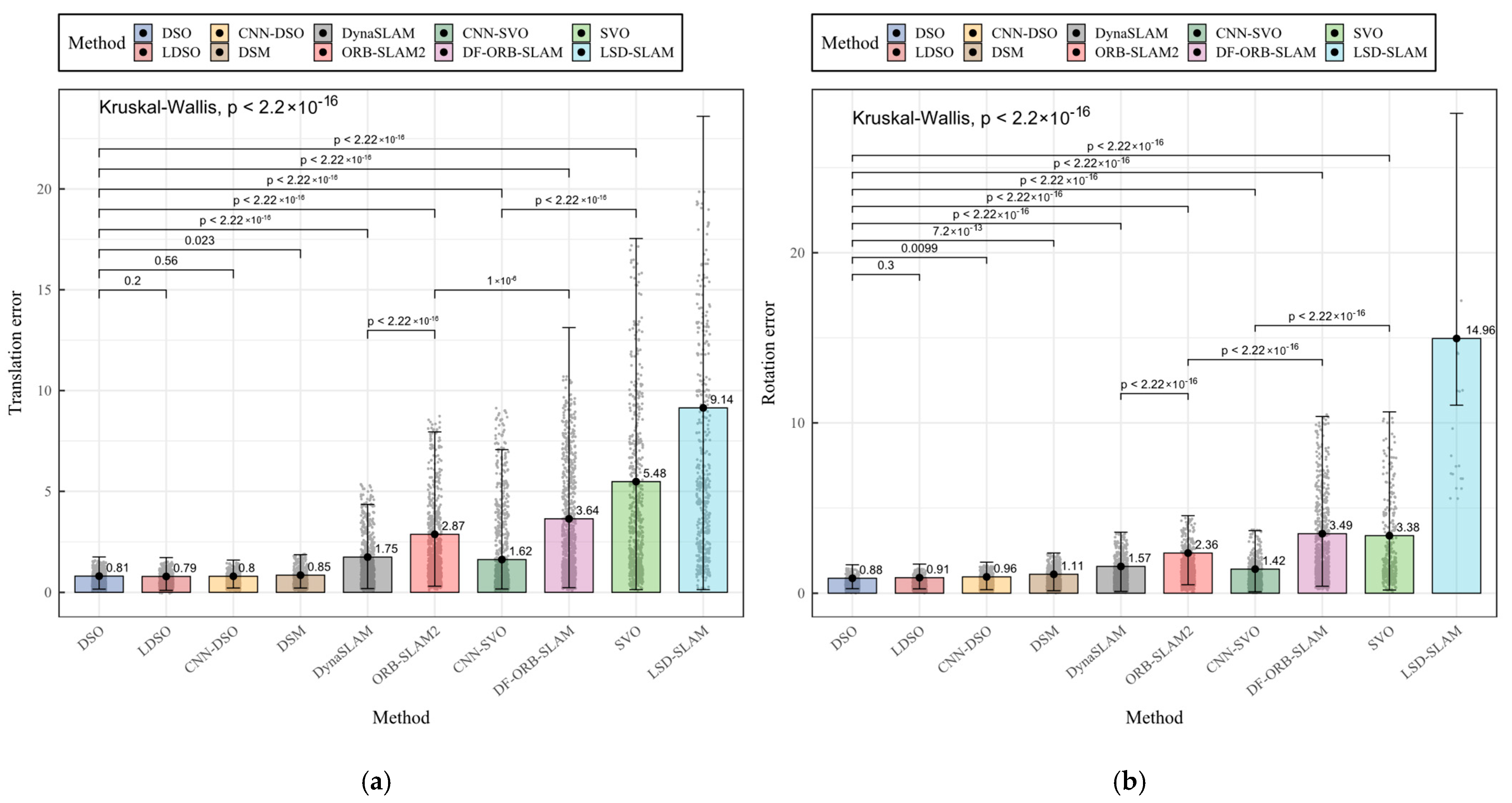
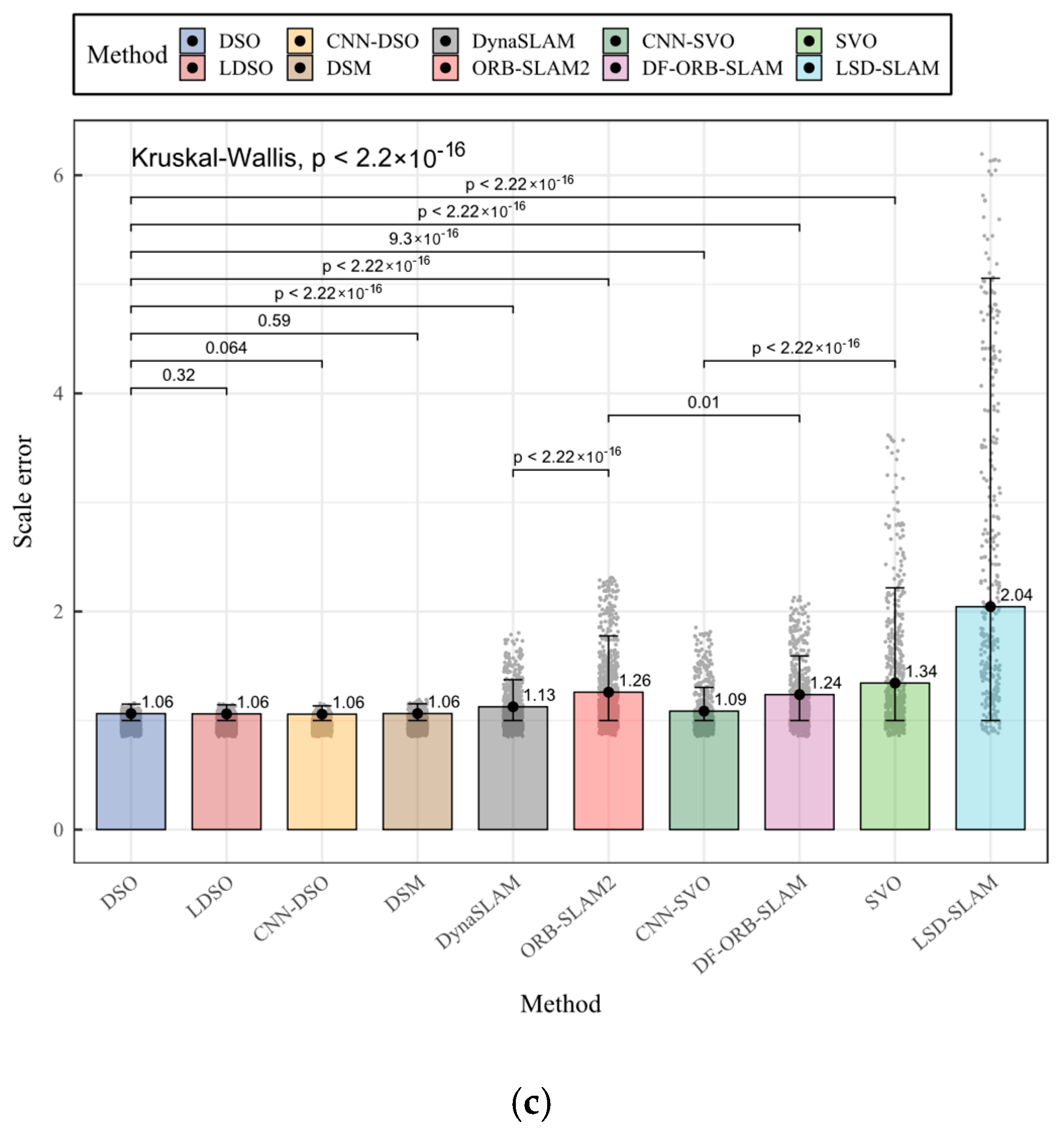
| Method | Translation Error | Rotation Error | Scale Error |
|---|---|---|---|
| Kruskal–Wallis general test | |||
| DSO | 0.8064585 a | 0.8800369 b | 1.064086 ab |
| LDSO | 0.7892125 a | 0.9135608 ab | 1.061302 ab |
| CNN-DSO | 0.7980411 a | 0.9618528 a | 1.058849 a |
| DSM | 0.8519143 b | 1.1117710 c | 1.064615 b |
| DynaSLAM | 1.7473504 c | 1.5730542 d | 1.126499 c |
| ORB-SLAM2 | 2.8738313 d | 2.3585843 e | 1.260155 d |
| CNN-SVO | 1.6248001 c | 1.4159545 d | 1.086399 e |
| DF-ORB-SLAM | 3.6423921 e | 3.4940400 f | 1.238232 f |
| SVO | 5.4819407 f | 3.3772024 f | 1.343603 g |
| LSD-SLAM | 9.1403348 g | 14.9621188 g | 2.044298 h |
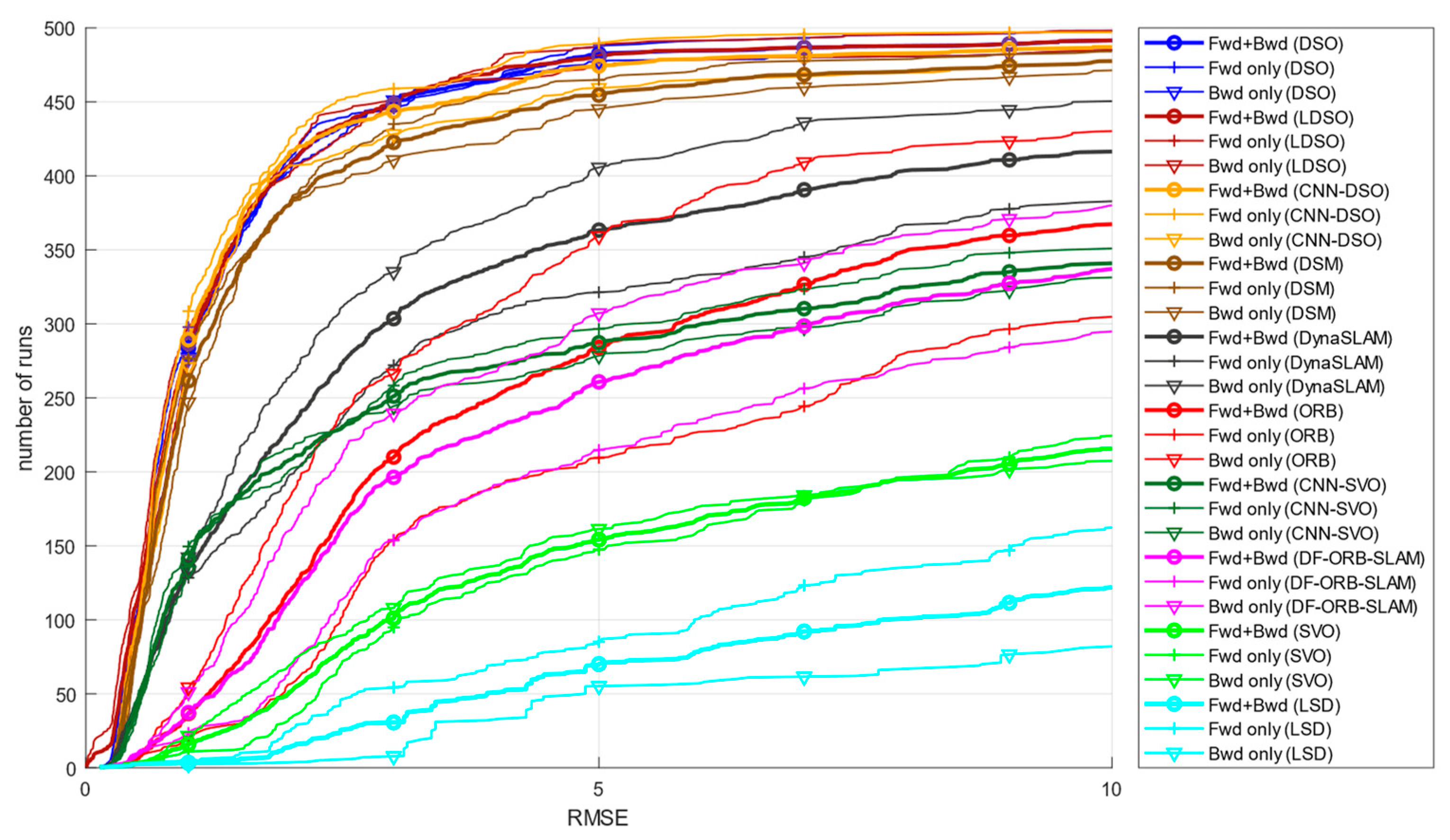
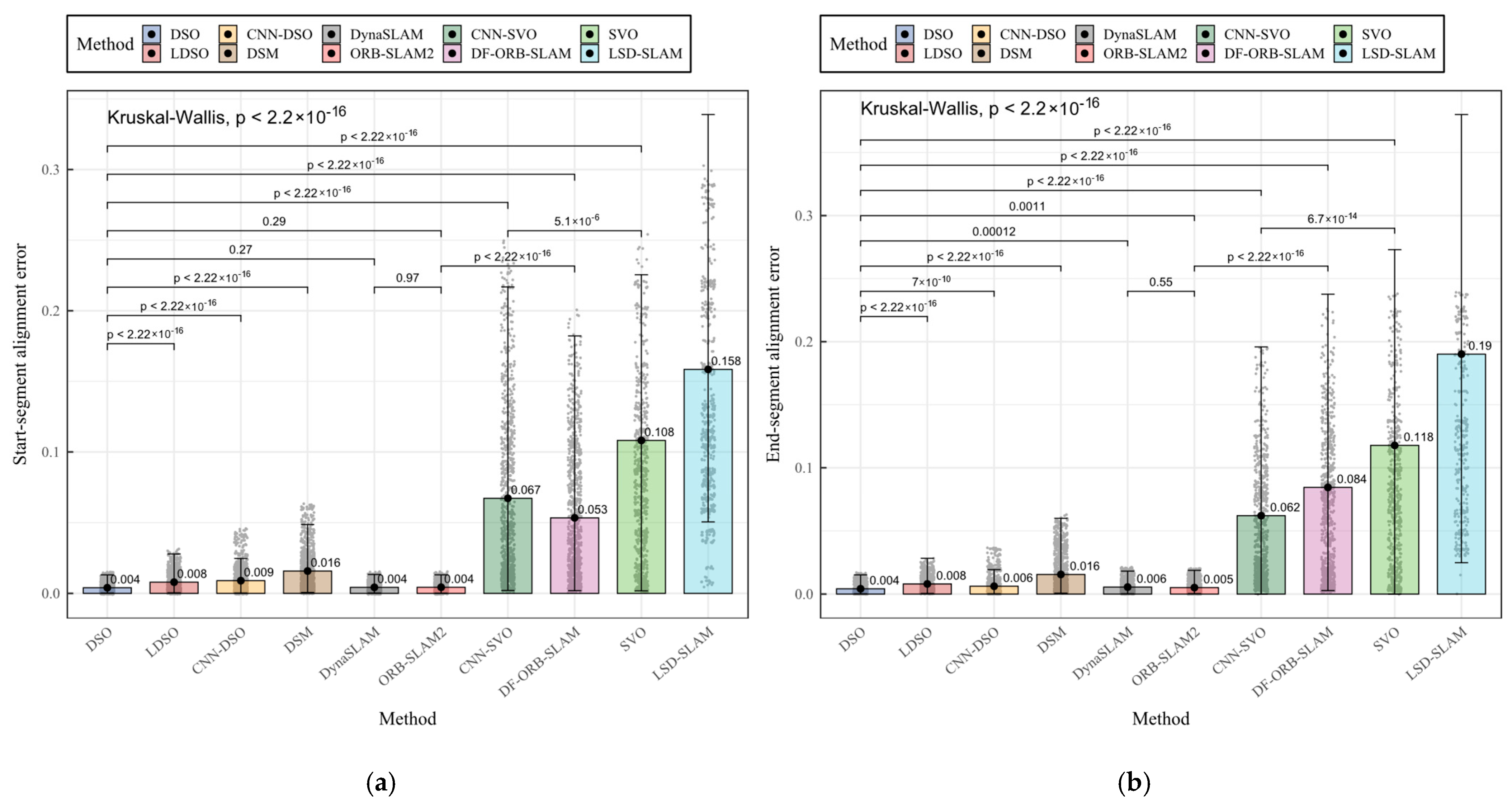
| Method | Start-Segment Alignment Error | End-Segment Alignment Error | RMSE |
|---|---|---|---|
| Kruskal–Wallis general test | |||
| DSO | 0.003974759 a | 0.004184367 a | 0.1950799 ab |
| LDSO | 0.007925665 b | 0.008009198 b | 0.1944492 a |
| CNN-DSO | 0.008987173 b | 0.006199582 c | 0.2083872 ab |
| DSM | 0.015794222 c | 0.015537213 d | 0.2167750 b |
| DynaSLAM | 0.004286919 a | 0.005516179 e | 0.2389837 cd |
| ORB-SLAM2 | 0.004311949 a | 0.005102672 e | 0.3165024 e |
| CNN-SVO | 0.067201999 d | 0.062036008 f | 0.2373532 c |
| DF-ORB-SLAM | 0.053360456 e | 0.084420570 g | 0.3643844 e |
| SVO | 0.108150349 f | 0.117753996 h | 0.3642558 e |
| LSD-SLAM | 0.158469383 g | 0.190127787 i | 0.3507099 d |
| Method | Category | Advantages | Limitations |
|---|---|---|---|
| ORB-SLAM2 [54] | Classic sparse-indirect | Low computational cost. Multiple input modes. Ease of implementation. Robustness to multiple environments. | Trajectory loss issues. Accumulation of drift while relocalizing. Sparse 3D reconstruction. |
| DF-ORB-SLAM [16] | Classic dense- indirect | Low computational cost. Reduction in trajectory loss issues. | Introduction of noise for trajectory estimation. Accumulation of drift on relocalization. Sparse 3D reconstruction. Significant reduction in the performance of ORB-SLAM2. |
| LSD-SLAM [29] | Classic dense-direct | Low computational cost. More detailed 3D reconstruction, but with the presence of outliers. More information in the final 3D reconstruction. | Poorest performance of the evaluated methods. Initialization issues. Trajectory loss issues. |
| DSO [21] | Classic sparse-direct | Low computational cost. Ease of implementation. More detailed and precise 3D reconstruction. Robust to multiple environments and motion patterns. Best performance of all methods in most of the metrics. | Requirement for a specific complex camera calibration. Slightly, but not significantly, lower performance than the LDSO in the translation and RMSE metrics. |
| SVO [13] | Classic hybrid | Low computational cost. Good documentation and open-source availability for implementation in diverse configurations. | Frequent trajectory loss issues. Initialization issues. Critical execution errors due to the absence of a relocalization module. |
| LDSO [30] | Classic sparse-direct | Low computational cost. Similar to DSO, detailed and precise 3D reconstruction. Ease of implementation. Loop closure module. Slightly but not significantly better performance than the DSO in translation and rotation error. Best performance in the translation and RMSE metrics (compared to DSO), but without considerable difference. | Requirement of a specific complex camera calibration. Significantly worse performance than the DSO in the end-segment error metric. |
| DSM [31] | Classic sparse-direct | Detailed and precise 3D reconstruction. Robust execution in most of the environments and motion patterns. Complete and interactive GUI. | Requirement of more computational capabilities than the rest of the sparse-direct methods. Significant underperformance compared to most of the sparse-direct methods. |
| CNN-DSO [15] | ML sparse-direct | Detailed and precise 3D reconstruction. Robust to multiple environments and motion patterns. Best performance in scale error metric. | Presence of outliers in the 3D reconstruction. Significantly better performance in the rotation error metric by the DSO. Difficult to implement. Specific hardware requirement. |
| DynaSLAM [32] | ML sparse-indirect | Multiple input modes. Ease of implementation. Robustness to multiple environments. Ability to detect, segment, and remove information of moving objects. Especially recommended for dynamic environments. Fewer trajectory loss issues than ORB-SLAM2. | Accumulation of drift while relocalizing. Sparse 3D reconstruction. Increase in complexity over the ORB-SLAM2. Specific hardware requirement. |
| CNN-SVO [11] | ML hybrid | Considerable reduction in the trajectory loss issues compared to the SVO. Initialization issues. Reduction in the number of execution issues compared to the SVO. Improved performance over the ORB-SLAM2 in the rotation, translation, scale, and RMSE metrics. Significant improvement over its classic version in all the metrics. | Considerable presence of outliers in the 3D reconstruction. Imprecise and sparser 3D reconstruction. Complex implementation. Specific hardware requirement. |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Herrera-Granda, E.P.; Torres-Cantero, J.C.; Rosales, A.; Peluffo-Ordóñez, D.H. A Comparison of Monocular Visual SLAM and Visual Odometry Methods Applied to 3D Reconstruction. Appl. Sci. 2023, 13, 8837. https://doi.org/10.3390/app13158837
Herrera-Granda EP, Torres-Cantero JC, Rosales A, Peluffo-Ordóñez DH. A Comparison of Monocular Visual SLAM and Visual Odometry Methods Applied to 3D Reconstruction. Applied Sciences. 2023; 13(15):8837. https://doi.org/10.3390/app13158837
Chicago/Turabian StyleHerrera-Granda, Erick P., Juan C. Torres-Cantero, Andrés Rosales, and Diego H. Peluffo-Ordóñez. 2023. "A Comparison of Monocular Visual SLAM and Visual Odometry Methods Applied to 3D Reconstruction" Applied Sciences 13, no. 15: 8837. https://doi.org/10.3390/app13158837