
Two Revised Deep Neural Networks and Their Applications in Quantitative Analysis Based on Near-Infrared Spectroscopy


Abstract
:1. Introduction
2. Materials and Methods
2.1. Data
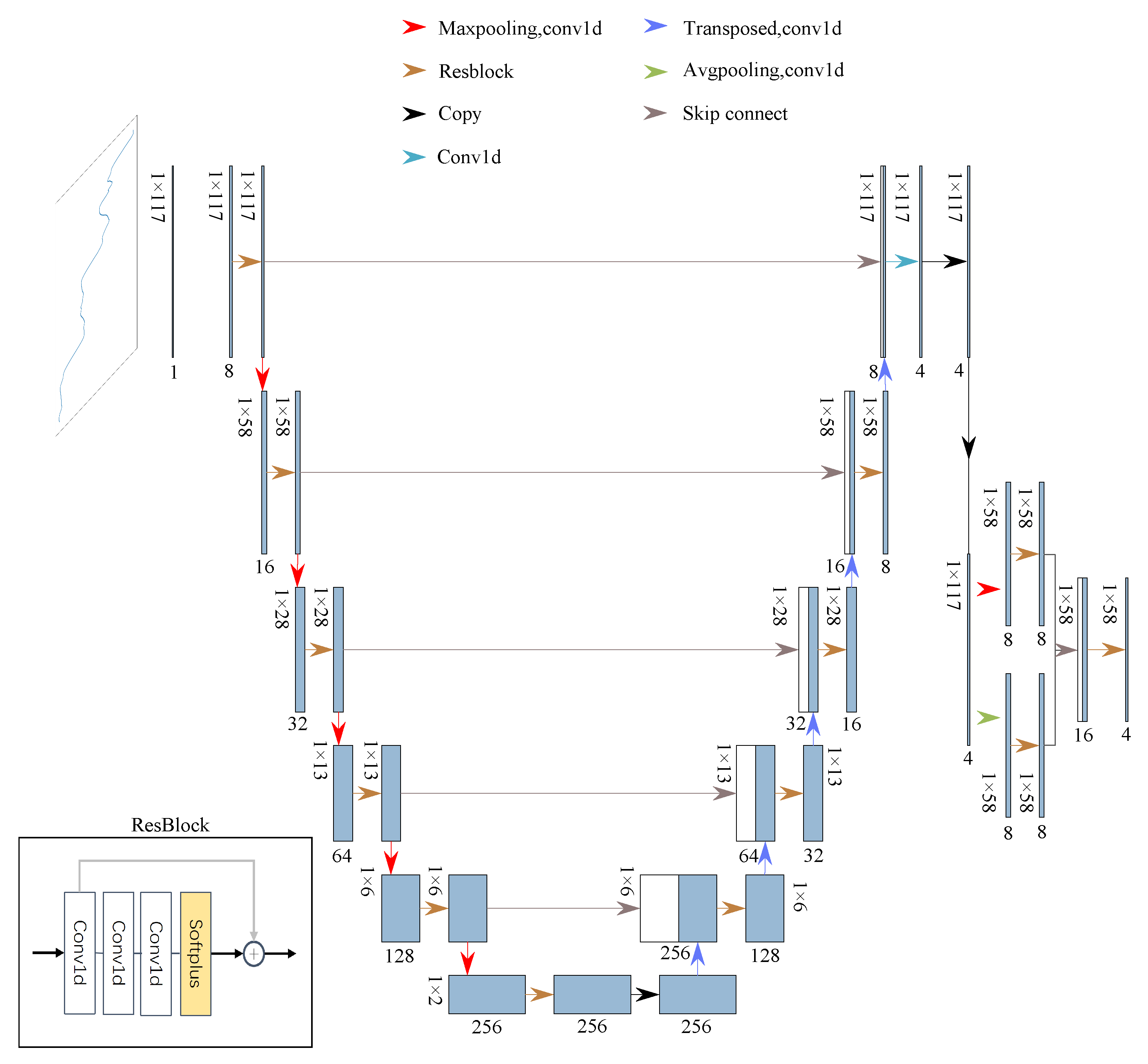
2.2. Revision of the U-Net
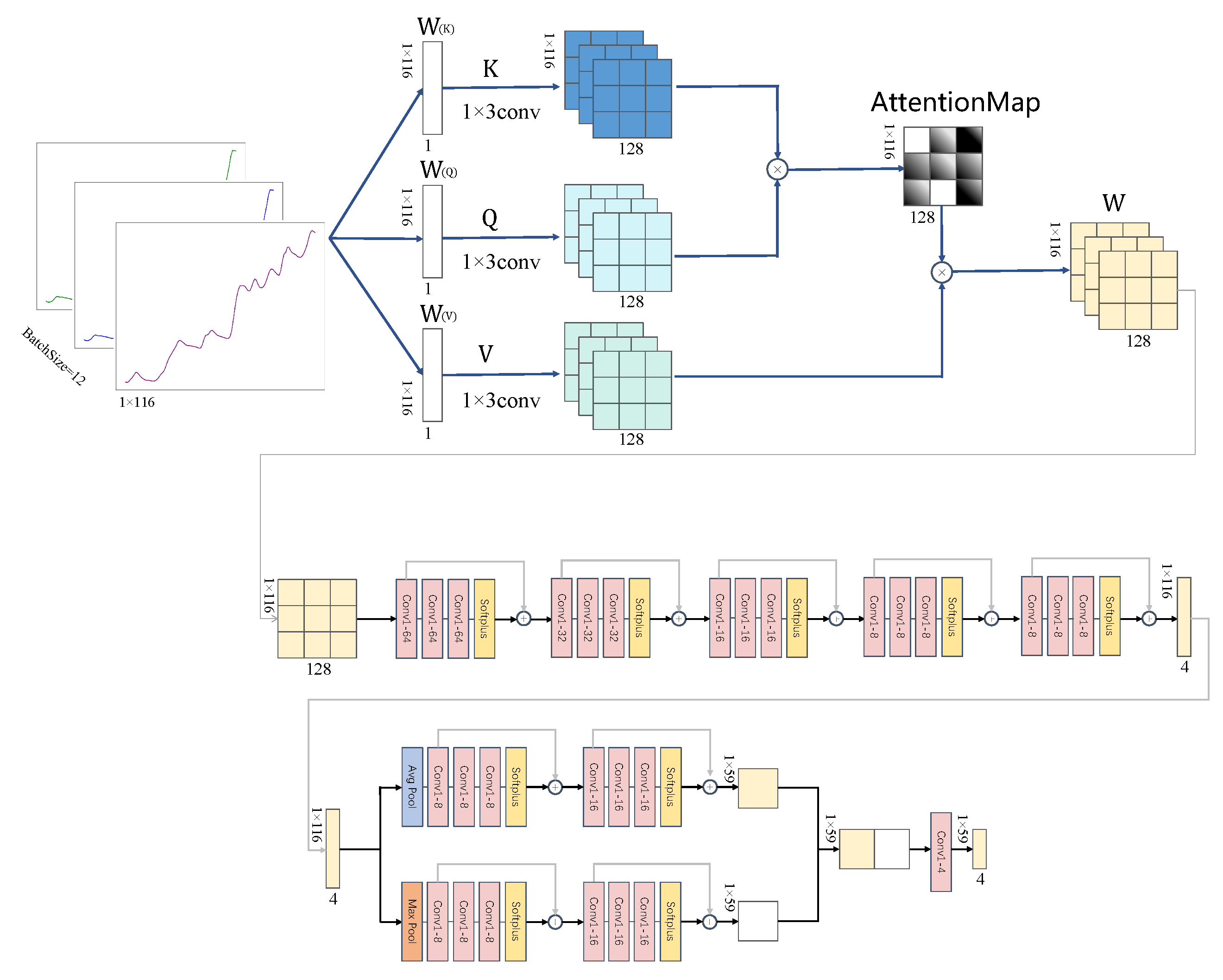
2.3. Revision of Attention Mechanism Network
2.4. Hyperparameters and Evaluation Criteria
3. Results and Discussion
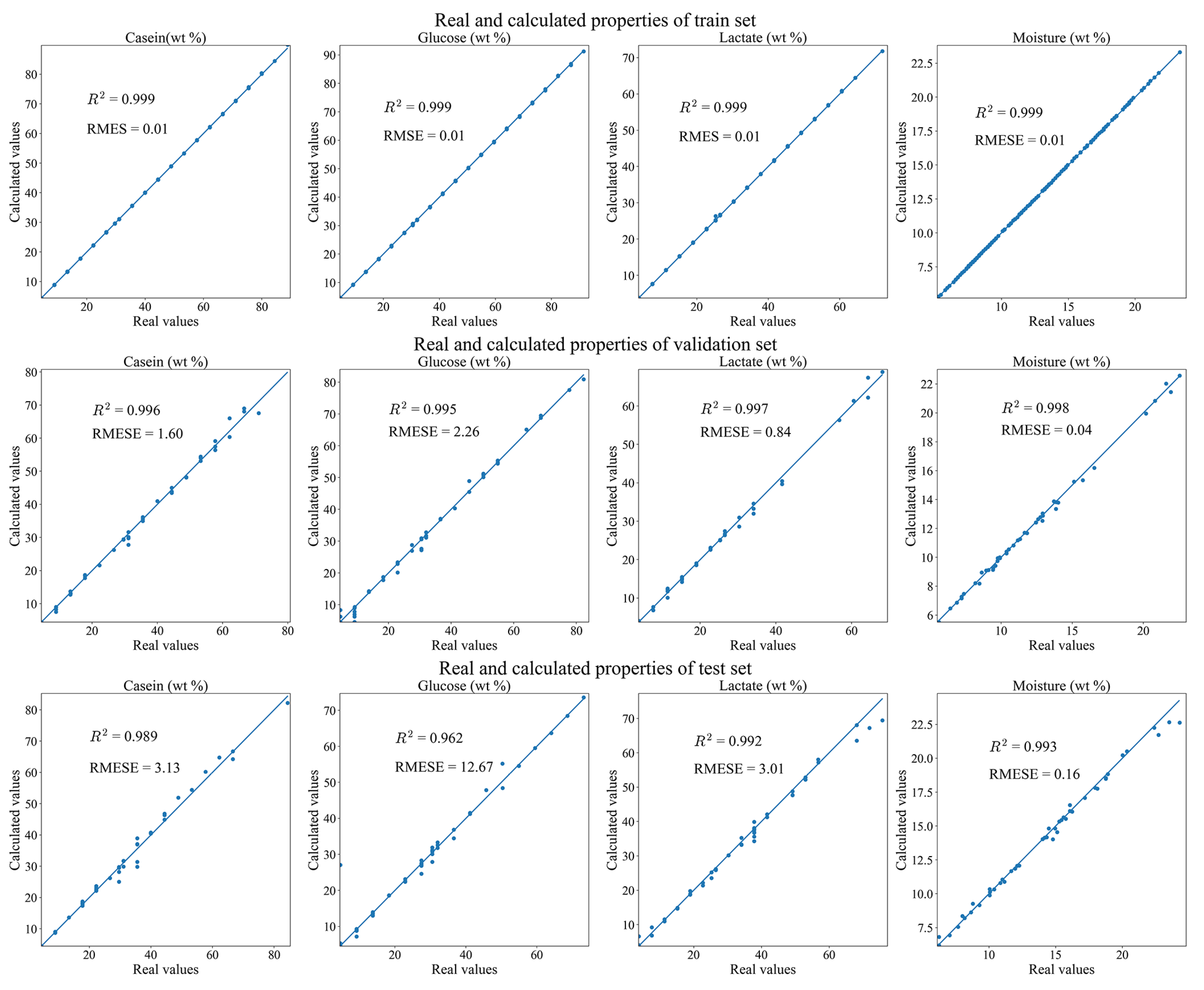
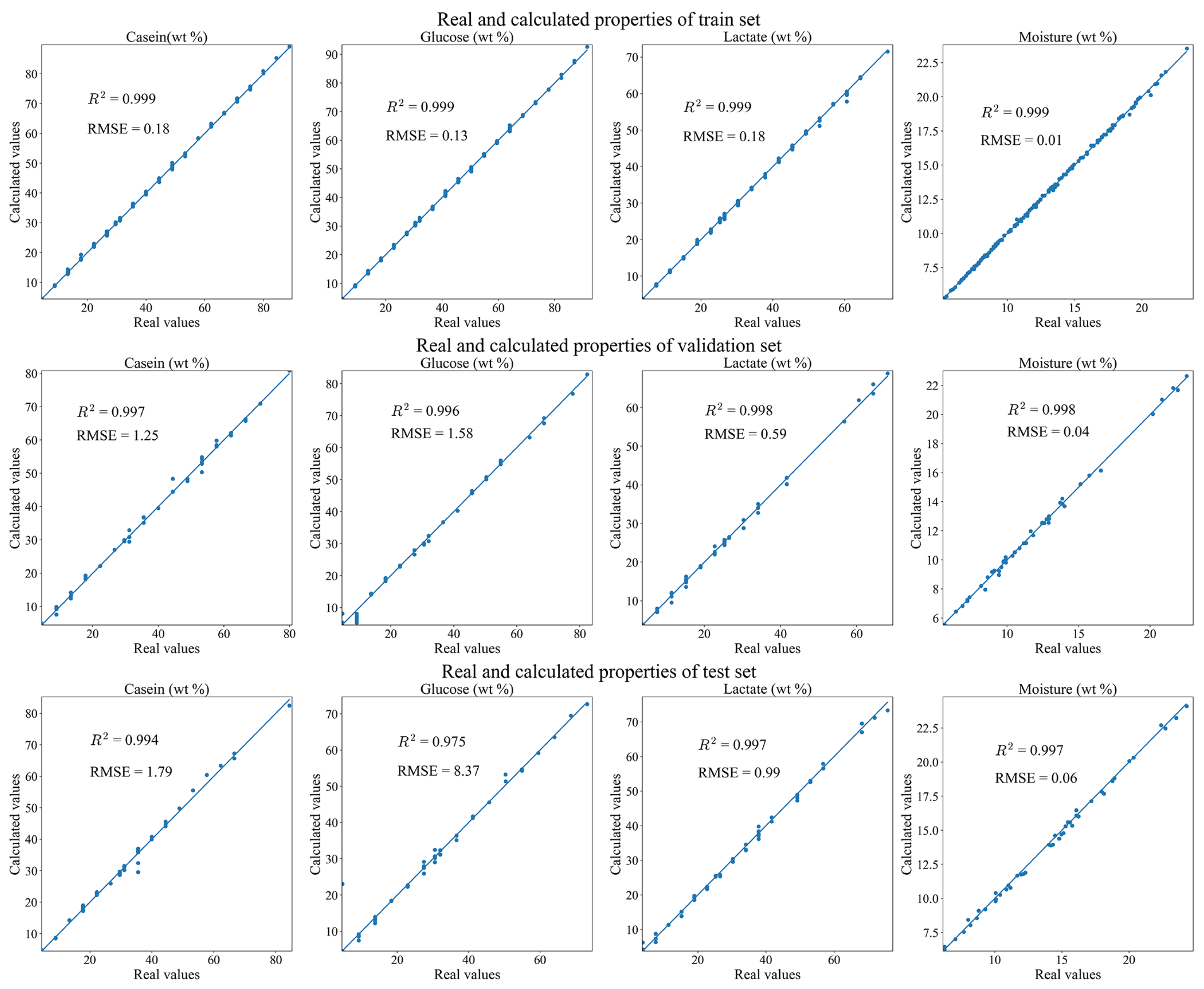
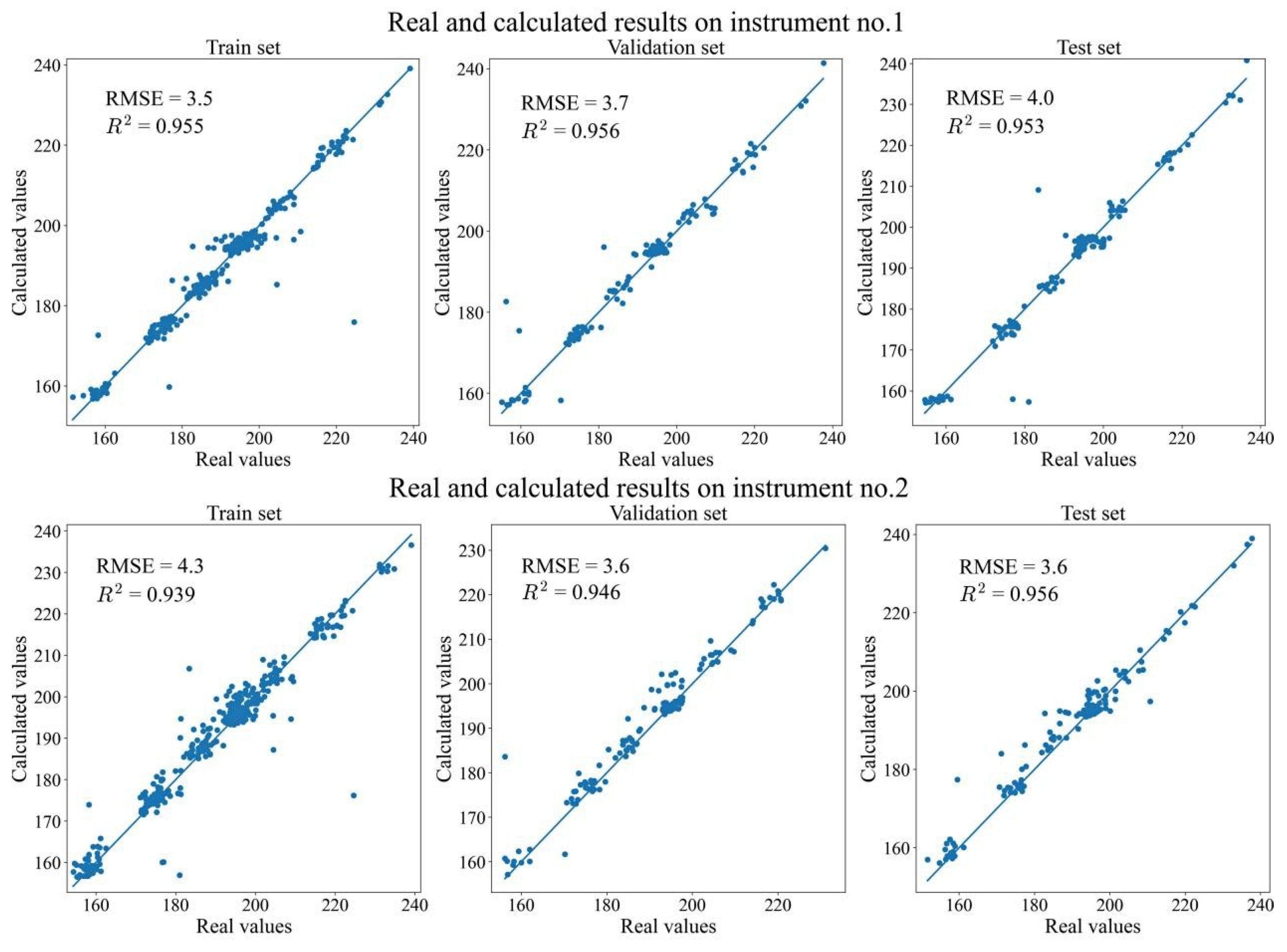
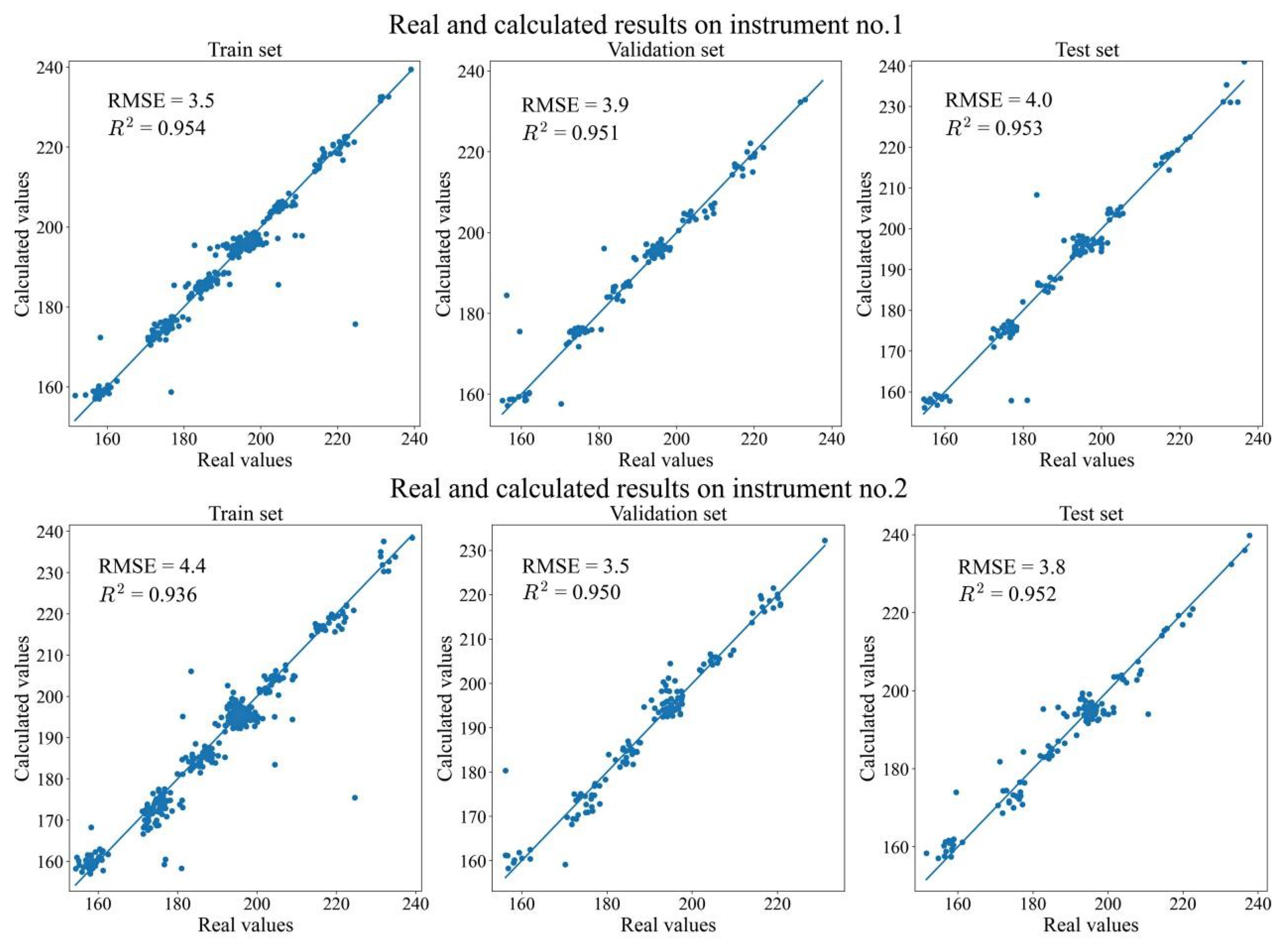
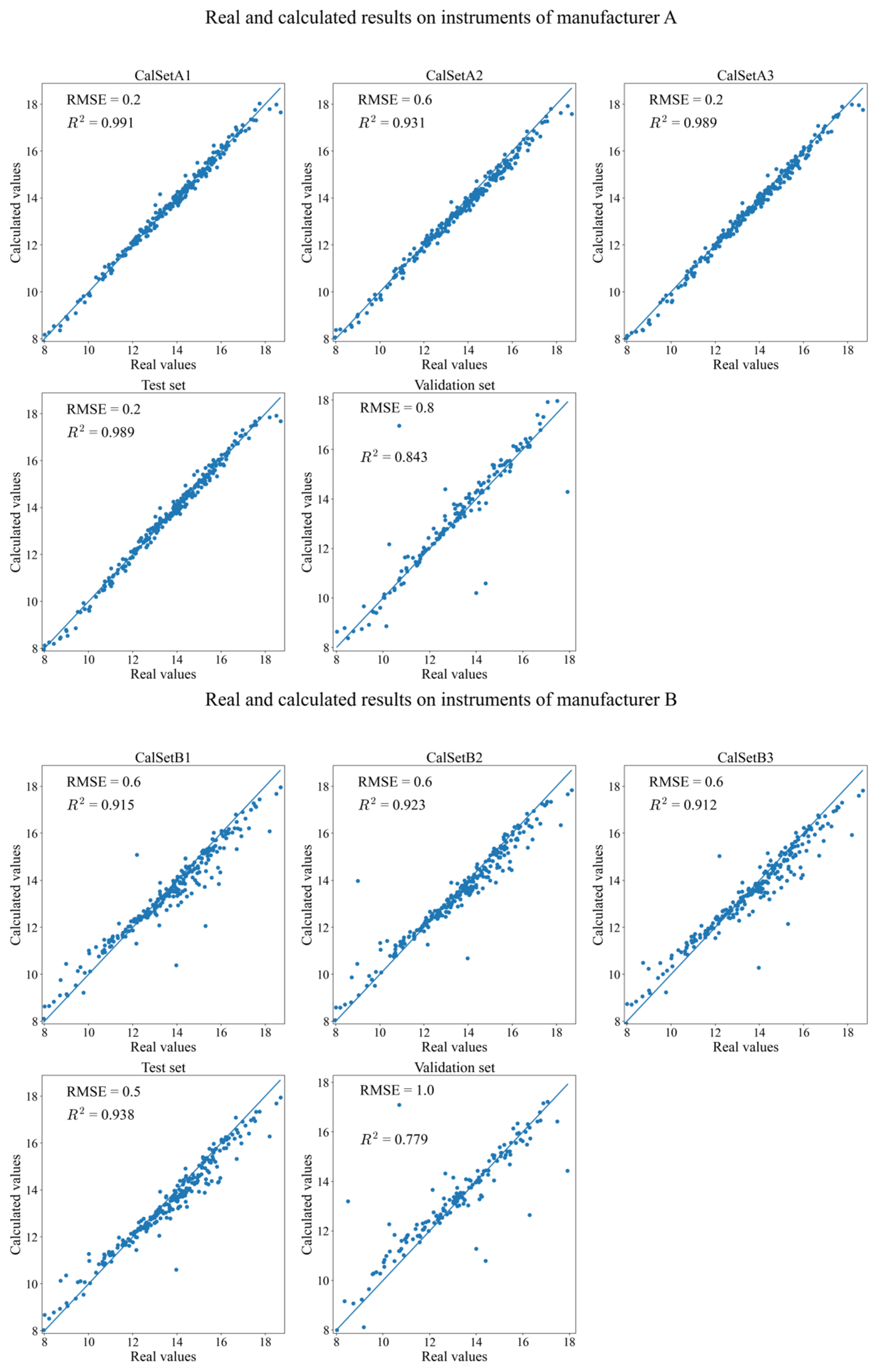
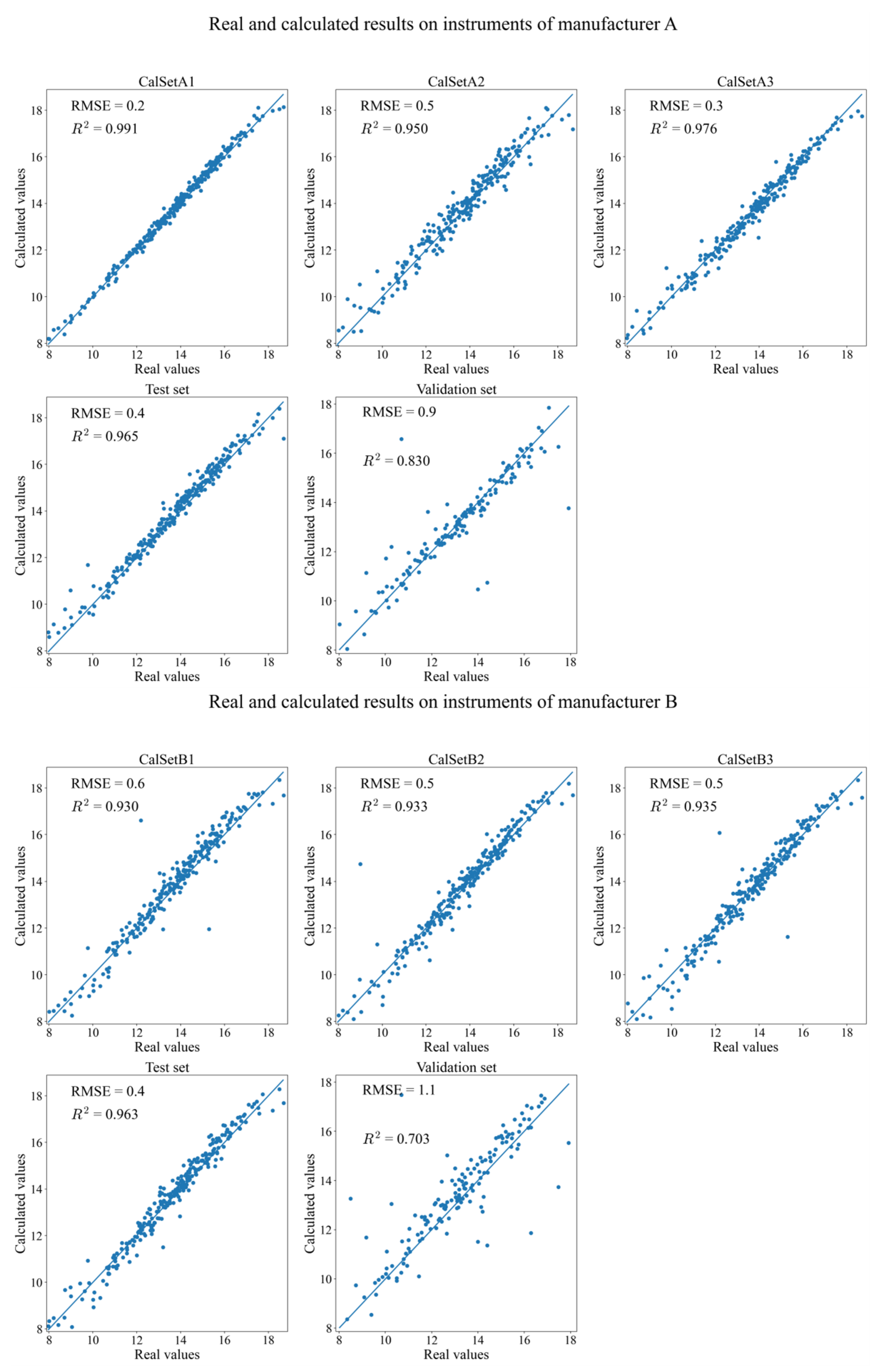
3.1. Two Revised DNNs Applied to the CGL Data Sets
3.2. Two Revised DNNs Applied to the IDRC 2002 Data Sets
3.3. Two Revised DNNs Applied to the IDRC 2016 Data Sets
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Dong, A.; Zhang, L.; Liu, Z.; Liu, J.; Wei, Y. Advances in infrared spectroscopy and hyperspectral imaging combined with artificial intelligence for the detection of cereals quality. Crit. Rev. Food Sci. Nutr. 2022. [Google Scholar] [CrossRef]
- Meza, C.P.; Santos, M.A.; Romañach, R.J. Quantitation of drug content in a low dosage formulation by transmission near infrared spectroscopy. AAPS Pharm. Sci. Tech. 2006, 7, 29. [Google Scholar] [CrossRef]
- Shadrin, D.; Pukalchik, M.; Uryasheva, A.; Tsykunov, E.; Yashin, G.; Rodichenko, N.; Tsetserukou, D. Hyper-spectral NIR and MIR data and optimal wavebands for detection of apple tree diseases. arXiv 2020, arXiv:2004.02325. [Google Scholar]
- Guo, Z.; Wang, M.; Agyekum, A.A.; Wu, J.; Chen, Q.; Zuo, M.; El-Seedi, H.R.; Tao, F.; Shi, J.; Ouyang, Q.; et al. Quantitative detection of apple watercore and soluble solids content by near infrared transmittance spectroscopy. J. Food Eng. 2020, 279, 109955. [Google Scholar] [CrossRef]
- Pasquini, C. Near infrared spectroscopy: A mature analytical technique with new perspectives—A review. Anal. Chim. Acta 2018, 1026, 8–36. [Google Scholar] [CrossRef] [PubMed]
- Chen, Y.Y.; Wang, Z.B. Quantitative analysis modeling of infrared spectroscopy based on ensemble convolutional neural networks. Chemom. Intell. Lab. Syst. 2018, 181, 1–10. [Google Scholar]
- Xu, K.; Guo, J.; Song, B.; Cai, B.; Sun, H.; Zhang, Z. Interpretability for reliable, efficient, and self-cognitive DNNs: From theories to applications. Neurocomputing 2023, 545, 126267. [Google Scholar]
- Zeng, J.; Guo, Y.; Han, Y.; Li, Z.; Yang, Z.; Chai, Q.; Wang, W.; Zhang, Y.; Fu, C. A Review of the Discriminant Analysis Methods for Food Quality Based on Near-Infrared Spectroscopy and Pattern Recognition. Molecules 2021, 26, 749. [Google Scholar] [CrossRef]
- Qu, X.; Huang, Y.; Lu, H.; Qiu, T.; Guo, D.; Agback, T.; Orekhov, V.; Chen, Z. Accelerated nuclear magnetic resonance spectroscopy with deep learning. Angew. Chem. Int. Ed. 2020, 59, 10297–10300. [Google Scholar] [CrossRef] [Green Version]
- Gabrieli, G.; Bizzego, A.; Neoh, M.J.Y.; Esposito, G. fNIRS-QC: Crowd-Sourced Creation of a Dataset and Machine Learning Model for fNIRS Quality Control. Appl. Sci. 2021, 11, 9531. [Google Scholar] [CrossRef]
- Rankine, C.D.; Madkhali, M.M.M.; Penfold, T.J. A deep neural network for the rapid prediction of X-ray absorption spectra. J. Phys. Chem. 2020, 124, 4263–4270. [Google Scholar] [CrossRef] [PubMed]
- Le, B.T. Application of deep learning and near infrared spectroscopy in cereal analysis. Vib. Spectrosc. 2020, 106, 103009. [Google Scholar] [CrossRef]
- Gan, F.; Luo, J. Simple dilated convolutional neural network for quantitative modeling based on near infrared spectroscopy techniques. Chemom. Intell. Lab. Syst. 2023, 232, 104710. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. arXiv 2015, arXiv:1505.04597. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is All you Need. arXiv 2017, arXiv:1706.03762. [Google Scholar]
- Guo, S.; Mayerhöfer, T.; Pahlow, S.; Hübner, U.; Popp, J.; Bocklitz, T. Deep learning for ’artefact’ removal in infrared spectroscopy. Analyst 2020, 145, 5213–5220. [Google Scholar] [CrossRef] [PubMed]
- Wang, Z.; Zhang, J.; Zhang, X.; Chen, P.; Wang, B. Transformer Model for Functional Near-Infrared Spectroscopy Classification. IEEE J. Biomed. Health Infor. 2022, 26, 2559–2569. [Google Scholar] [CrossRef]
- McClure, F. IDRC-2002. NIR News. 2002, 13, 3–5. [Google Scholar] [CrossRef]
- Igne, B.; Alam, M.A.; Bu, D.; Dardenne, P.; Feng, H.; Gahkani, A.; Hopkins, D.W.; Mohan, S.; Hurburgh, C.R.; Brenner, C. Summary of the 2016 IDRC software shoot-out. NIR News 2017, 28, 16–22. [Google Scholar] [CrossRef]
- He, K.M.; Zhang, X.Y.; Ren, S.Q.; Sun, J. Deep Residual Learning for Image Recognition. arXiv 2015, arXiv:1512.03385. [Google Scholar]
- Debus, B.; Parastar, H.; Harrington, P.; Kirsanov, D. Deep learning in analytical chemistry. TrAC-Trend Anal. Chem. 2021, 145, 116459. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Data Set | Total Samples | Training Set | Validation Set | Test Set | Features 1 |
|---|---|---|---|---|---|
| CGL | 231 | 139 | 46 | 46 | 116 |
| IDRC-2002 set 1 | 655 | 391 | 131 | 131 | 281 |
| IDRC-2002 set 2 | — | — | — | 655 | 281 |
| IDRC-2016 A1 | 248 | 248 | — | — | 740 |
| IDRC-2016 A2 | 248 | — | — | 248 | 740 |
| IDRC-2016 A3 | 248 | — | — | 248 | 740 |
| IDRC-2016 B1 | 646 | — | — | 646 | 740 |
| IDRC-2016 B2 | 248 | — | — | 248 | 740 |
| IDRC-2016 B3 | 248 | — | — | 248 | 740 |
| IDRC-2016 T | 248 | — | 248 | — | 740 |
| IDRC-2016 V | 248 | — | — | 248 | 740 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Huang, H.-H.; Luo, J.-F.; Gan, F.; Hopke, P.K. Two Revised Deep Neural Networks and Their Applications in Quantitative Analysis Based on Near-Infrared Spectroscopy. Appl. Sci. 2023, 13, 8494. https://doi.org/10.3390/app13148494
Huang H-H, Luo J-F, Gan F, Hopke PK. Two Revised Deep Neural Networks and Their Applications in Quantitative Analysis Based on Near-Infrared Spectroscopy. Applied Sciences. 2023; 13(14):8494. https://doi.org/10.3390/app13148494
Chicago/Turabian StyleHuang, Hong-Hua, Jian-Fei Luo, Feng Gan, and Philip K. Hopke. 2023. "Two Revised Deep Neural Networks and Their Applications in Quantitative Analysis Based on Near-Infrared Spectroscopy" Applied Sciences 13, no. 14: 8494. https://doi.org/10.3390/app13148494