1. Introduction
With the rapid developments in computer vision and machine learning methods, several algorithms have emerged that facilitate automatic object detection and recognition of various objects [
1]. These methods are also benefiting the fruit processing industries, where classification and grading of fruits freshness are crucial for the manufactures to produce high-quality products such as fruit juices or tin packs. In an open environment, fruits are sensitive to numerous viruses and fungi that worry the agricultural industry and thus result in economic pressure. Physical ordering of fruits to categorize its quality either fresh or rotten is a laborious procedure. Thus, an automated assessment of fruit quality is an active research topic, which is experiencing growing interest all over the world. Recently, several works have appeared in literature that use Deep Neural Networks (DNNs) and Convolutional Neural Networks (CNNs) to classify the fruit freshness. Fruit freshness classification methodology is primarily inspired by pattern recognition and object classification that ultimately produces features set in which fruits are categorized through extensive training and learning. Multi-fruit categorization has extensive practical applications such as multi-fruit identification tools can be utilized in self-service fruit purchasing in supermarkets. It can be handy to eliminate human selection mistakes in production lines and hence increase efficiency. Nowadays, in agriculture, multi-fruit classification can assist the breeding of various fruit species. Due to the extensive developments in deep learning architectures, computer vision-based approaches are thought to be the most intelligent and cost-effective solutions.
Studies on object classification use various approaches, for example, Support Vector Machines (SVMs), linear discriminant analysis, or k-nearest neighbors (k-NN) to improve accuracy or speed [
2]. Fruit freshness is a major factor in determining the quality of fruits as it can affect their shelf life and overall nutritious value.
Figure 1 shows an example of conditions of fruit from fresh to rotten stage of apples and bananas, respectively. Therefore, to determine the proper price, the customer must be able to identify the variety of the fruits that are intended to be purchased. Fruit freshness classification is also crucial for consumers, as it can help them make knowledgeable decisions about the worth of the fruit item they are purchasing. It is also important for producers and retailers as it can help them to accomplish inventory and ensure that their products are meeting quality standards.
Recently, several machine learning-based methods for fruit freshness classification have appeared in the literature [
3]. Few of them use CNNs, Deep CNNs, and Faster-RCNN to accomplish the fruits classification task [
4]. The CNN models are also implemented in a number of tasks, for instance, object detection, classification, and recognition [
3]. Over the past few years, various CNN architectures have been developed, and they have demonstrated excellent performance for image classification. Transfer learning is one of the techniques that uses previously developed architectures on various problems to produce more accurate results. Deep learning and machine learning techniques integrated with transfer learning could also be used for image classification. This study investigates the possibility of transfer learning with regard to CNN models for the quality assessment of fruits instead of using CNN architectures from starch. In real-life, classification of fruits is normally carried out by people that we believe is ineffective for fruit farmers and fruit sellers. Therefore, the development of an accurate classification method is desired, which will significantly reduce human efforts and costs. A robust fruit freshness classification method will also reduce the industry’s production time in the agriculture domain by correctly identifying fruit defects. Therefore, this study proposes a novel and automatic fruit freshness classification method using fine tuning and transfer learning of the AlexNet. The effectiveness of the proposed method is validated on three publicly available fruit datasets. Our main contributions to this manuscript are listed below.
We develop an automatic fruits classification method that accurately classifies whether the fruits are fresh or rotten. Our developed method is based on transfer learning, which uses classical convolutional architectures such as AlexNet. The introduction of transfer learning with the AlexNet yields higher accuracy than few of the recently published works with much lower computational complexity.
We propose an intelligent system that reliably recognizes fruits, for instance, apples, bananas, and oranges, which are later categorized as either fresh or rotten classes. Automatic and timely identification of fresh and rotten fruits will enable agriculturalists to produce large quantities of various fruits and thus put on great value to a country’s economy.
We report experiments on three well known and publicly available datasets in our simulations. Our findings are encouraging as we obtain over 99% fruit freshness classification accuracy. We are hopeful that our developed method will also be helpful to customers in supermarkets to identify fresh fruit.
Rest of this manuscript is organized as follows. In
Section 2, we briefly review the recently developed fruits freshness classification methods. In
Section 3, we describe our developed method. While simulation results and comparisons are listed in
Section 4 followed by
Section 5 that concludes our findings and also hints towards the possible future work.
2. Related Work
This section briefly discusses recent methods that aim to classify various fruits using machine learning and image processing-based methods.
In [
5], a deep learning-based method to classify fruits and vegetables is developed, which is primarily based on the YOLOv4 model. This method initially recognizes the object type in an image and then classifies the object either as fresh or rotten. This model also improves the backbone of the YOLOv4 version using the Mish activation function, which results in rapid detection of objects. In [
6], researchers analyze and proposed a novel design of computer vision-based method using deep learning with the Convolutional Neural Network (CNN) model to detect several fruit freshness level. The specially designed CNN model is later evaluated and extensively tested with public datasets of fruits fresh and rotten for classification. This is a nice effort and nicely handles the fruits’ freshness level instantly.
In [
7], published work focuses on classifying rotten and good apples. For the task of apple classification, initially texture features of apples are extracted. For instance, discrete wavelet feature, histogram of oriented gradients, and law’s texture energy along with the gray level co-occurrence. Later, various classifiers are applied, for instance the SVM, the k-NN, and Linear Discriminant. Researchers’ conclude that the SVM classifier yields 98.9% accuracy, which is better than few of the compared classifiers. In [
8], eight deep learning models namely AlexNet, Google Net, ResNet18, ResNet50, ResNet101, VGG16, VGG19, and NasNetMobile are fine-tuned to assess the quality of fruits and vegetables. The performance of deep learning models is based on the training and validation accuracy. The model’s outcome shows that the VGG19 model reached the highest validation accuracy over the original samples and the ResNet18 model achieved the highest validation accuracy based on the augmented data samples. In [
9], the authors investigate the maturity status of Papaya fruit by using machine learning. To classify the fruits, the LBP, the HOG, Gray Level co-occurrence Matrix (GLCM), SVM, K-Nearest neighbor (KNN), and Naive Bayes methods are applied and compared. Seven pre-trained models are fine-tuned on the given dataset of Papaya to evaluate the performance of the robust system. The K-Nearest neighbors (KNN) with the HOG features results high accuracy with much less training rate. In [
9], authors apply deep learning model on the banana different dataset. In this work, bananas’ freshness was analyzed by transfer learning and established the relationship between freshness and storage dates. Banana feature extraction were extracted by Google Net. The reported classification accuracy of this model is 98.92%, which is at par with normal human detection. In [
10], authors use k-means clustering along with colors, textures, and shape features to classify the apple freshness by investigating its disease. This work also uses multiclass SVM during classification stage.
In [
11], a system for classifying fruits and vegetables in supermarkets is implemented, which combines backdrop removal with a split-and-merge strategy to find fruits and vegetables in pictures. This model also employs color, shape, and texture as key identifying characteristics. The feature space was condensed using the PCA. Several kernel functions, such as the MWM-SVM, the MWV-SVM, and the DAG-SVM were used during the algorithm development. The maximum accuracy of 88.2%, was attained by MWV-SVMs utilizing Gaussian radial basis kernels. In [
12], authors published a method for identifying fruit flaws in retail. Cameras are positioned on the borders of a conveyor to capture orange data samples. They applied color as a feature in the RGB images and also produced color histograms. The Fisher-LDA is employed to decrease features size and to reduce noise. Next, the orange problematic zones are found using the SVM. The trial results showed that their proposed technique had a 96.7% recall rate. The automotive, commercial, and agricultural industries, as well as other worldwide businesses, have all made substantial use of it for object identification and picture categorization. Various image processing and deep learning methods are extensively used to extract and alter supervised or unsupervised features from several layers of non-linear data with the aim to classify objects to understand its patterns [
13]. In [
14], the developed method employed background subtraction modeling to handle diverse samples. They use a range of recent methods, which include decision trees, the k-NN, the LDA, and the SVM. Simulations showed that SVM performed better than a few techniques.
In [
15], CNN is used to detect various fruits. This work is performed on a relatively small dataset, and it produced an excellent performance by yielding 98.92% detection accuracy. In [
16], researchers compared performances of multi-task learning, domain adaptation, and sample selection bias. They also carried out a detailed review of the method that are used to detect and classify various objects. In [
17], a deep learning-based technique is used for the freshness classification of Hog Palm fruit. This work uses four CNN-based models, which were fine-tuned on imageNet Dataset. The Dataset was augmented and used for training and hyper parameter tuning for the purpose of grid search and k-fold cross validation the results were compared in terms of different parameters listed therein. In [
18], the proposed method uses VGG16 and the CNN to extract various robust fruits features. In this work, SVM, decision trees, and logistic regression models were also compared. The authors concluded that the SVM the achieved highest 99% classification accuracy than the compared methods. In [
19], fruit classification was achieved by using CNN and Softmax, which yielded 97.14% accurate classification.
The aforementioned is a brief review of the recent methods that handle fruit freshness detection and classification problems. To achieve accurate results and to facilitate the humans each of these works performed experiments on standard and publicly available datasets. While a few researchers, such as [
20], gathered their own dataset, which contains sixteen different species of fruits. The methods briefly described above are a nice addition to the research domain to tackle the fruits freshness problem. We believe that our work is latest addition in this domain, which aims to achieve high fruit freshness classification of different fruits. Our study indicates that machine learning algorithms are helpful to determine the freshness of perishable items, such as fruits as well vegetables. In addition, deep learning models focus to extract features. Ultimately, as we will see in the results section that testing the data on unseen data is a good indicator of the performance of the developed method. Below we detail our developed method.
3. Methodology
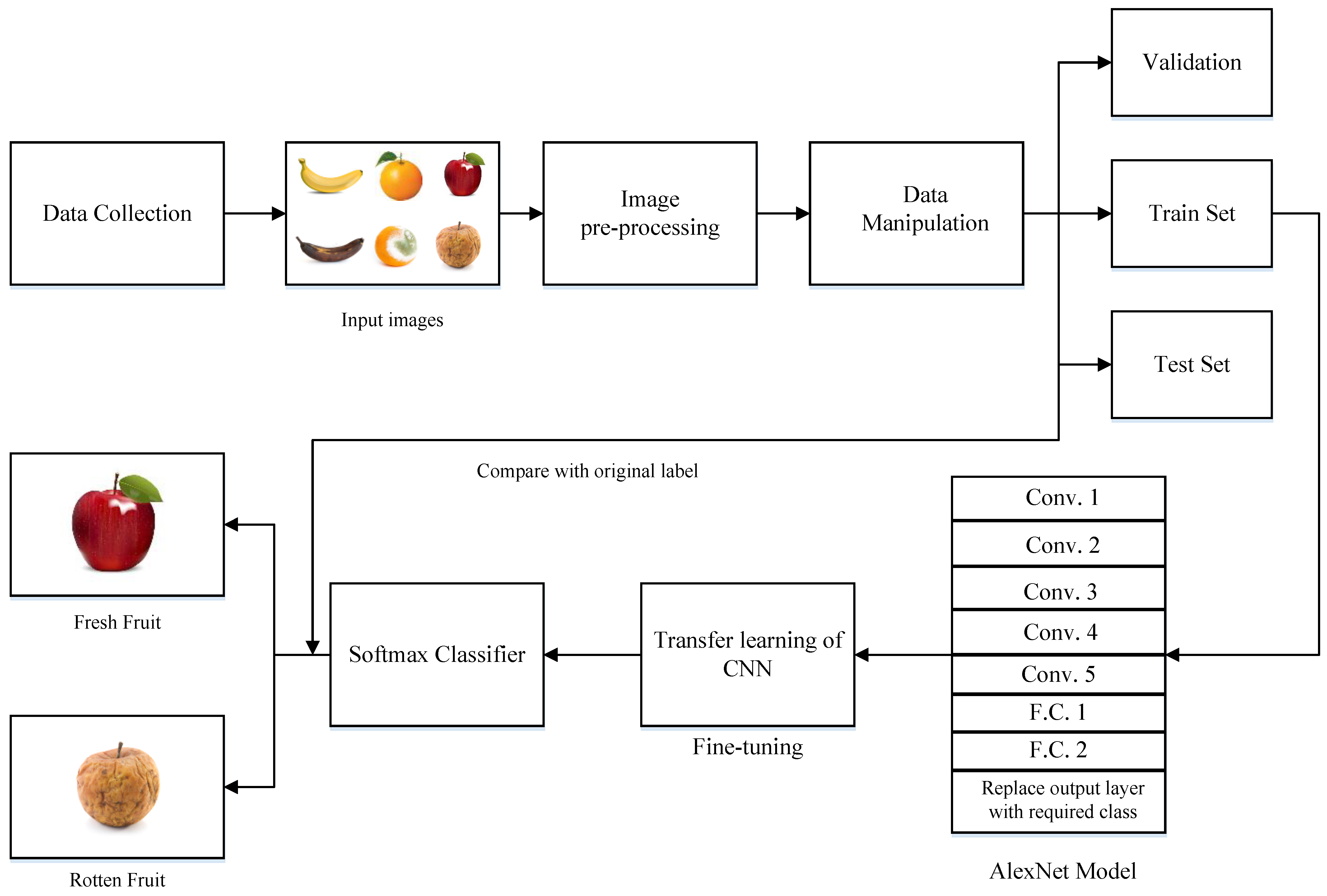
Our developed method has various interconnected modules as shown in
Figure 2. Below, we describe the various modules that are used in our developed algorithm.
3.1. Data Collection
To develop our fruits freshness classification method, we acquire different fruits images data from Kaggle (
www.kaggle.com, accessed on 5 June 2023). The Kaggle is a publicly available dataset and contains different classes of various fruits such as apples, bananas, or oranges. The fruits image dataset provided by Kaggle contains three kinds of fresh and rotten images. Moreover, the fruit dataset contains images in separate files, such as fresh apples, fresh bananas, fresh, oranges, rotten apples, rotten bananas, and rotten oranges. A few of such sample fruits images are shown in
Figure 2. These images are now pre-processed by the next module.
3.2. Pre-Processing
Data pre-processing is conducted earlier than data manipulation to fit the data for Convolutional Neural Network (CNN) and various filters are employed therein. In our method, we performed the pre-processing in following manner.
Color Uniformity: To maintain uniformity, we process all images in the RGB domain. This essentially creates uniformity in each channel of the image.
Image Resizing: Since, the original dataset contains colored images of different fruits in several formats and sizes. Therefore, we resize images one by one and label it and store in separate directory. Hence, we resize images to 227 × 227 × 3.
Image Augmentation: Augmentation is conducted by flipping all images to
x-axis and randomly rotating images. In our work, augmentation is conducted in parallel where each image was rotated at 90°, 180°, and 270°. Hence, each image created three new images, which made the size of dataset four times its original size shown in
Figure 3.
Image Labeling: Finally, the converted dataset is labelled according to each class they belong. Training and testing on the test set are conducted concurrently with validation. Meanwhile, the string labels were also changed into numeric format, which later helps the employed models to accurately predict the true labels. The pre-processed data is now further manipulated as listed below.
3.3. Data Manipulation
During this phase, each image in the dataset was remodeled into a single size and scale. We observe that this strategy maintained significant data uniformity. As shown in
Figure 4, we split the pre-processed datasets into three parts, which are validation, train set, and test set. In our work, 80% of the data is used for training, 10% for validation, and 10% is used in the test phase. We also state that in each class 100 images were taken randomly. Out of these 85 images of the single object contains the plane background. While 15 images of multiple objects contain complex background.
3.4. AlexNet Architecture
This is an eight layers weighted model in which the first five are convolutional layers, while the remaining three are fully connected layers [
21]. In AlexNet architecture, first layer processes the input image resolution of 150 × 150 × 3 and applies 96 convolutional filters 11 × 11 resolution. The output of first layer is processed as the input of the second layer and 256 convolutional filters of 5 × 5 resolution. Moreover, third and fourth layers apply 384 convolutional filters with a resolution of 3 × 3. While the 5th convolutional layer applies 256 kernels of 3 × 3 resolution. In AlexNet, all five layers apply maximum pooling of 2 × 2 resolution through batch normalization. The selection of an appropriate activation function encourages us to improve the accuracy of our method. Hence, while choosing the activation function, we make sure that the gradient function converges quickly and also at the infinity of the activation function is not 0. In our work, the ReLU activation function and its derivate are shown in Equations (1) and (2), respectively.
Equation (2) indicates that the derivative of the ReLU function is continually equal to 1 during the positive half-axis of , and is constantly 0 during the negative half-axis of . The ReLU function is used in the first five convolutional layers. In addition, the output from the first five layers is passed to three fully connected layers in which the first two fully connected layers contain 4096 units, and the last fully connected layer comprises 1000 units. Final output layer applies the Softmax activation function and consists of 6 units. After the AlexNet processes the data, in next step, transfer learning is performed as described below.
3.5. Transfer Learning of the CNN
The CNNs are networks that filter inputs for relevant information using constitutional layers. Constitutional filters along with the CNN layers are used to find neurons outputs that are linked to specific local input areas. It aids in the extraction of spatial and temporal visual characteristics. The CNN correctly extracts features from the input image of the given Dataset. There are three key components in the CNN, which are a convolution layer that learns features max pooling, which reduces the dimensionality, and finally, a fully connected layer that classifies the input image.
Transfer learning or knowledge transfer is a technique in which we use pre-trained network as a starting point to solve specified classification problems. During the transfer learning phase, we replaced a few upper layers of a fixed model base and added new layers. While a final layer of the output is replaced with the required classes and for fine tuning some of the parameters are changed such as epochs, size, and learning rate to achieve better performance. The parameters used for the experiments were set as:
3.6. SoftMax Classifier
Softmax or multinomial logistic regression has a unique advantage to deal the N-dimensional vectors. The Softmax is widely used in diverse fields including deep learning for various objects classification [
22]. The Softmax classifier determines the probability of extracted vectors for classification. For the same data set, it gives the sum of the probability equal to 1 for all vectors as indicated by Equation (3).
where
z is the input vector obtained from fine-tuned network in previous stage. These results are mapped to the probability domain from the exponential domain. We select Softmax loss function for fruits classification. Our study indicates that this Softmax function has good performance and converges quickly. Mathematically, the Softmax loss function is modelled as shown in Equation (4).
where
N represents the output value of last fully connected layer of the correct class
. Moreover,
is the output value of the last fully connected layer of the
class.
Equations (3) and (4) indicate that the
function uses the data from correct labels and maximizes the possibility of data. Meanwhile, it also ignores the information from the prevailing incorrect labels. Algorithm 1 shows the pseudo cod of our developed method. Algorithm 1 indicates that the fruits images, which are obtained from the Kaggle dataset, are pre-processed as described in the above section. In Algorithm 1, from lines (2) to (8) the gathered data is processed, which is later fed to the deep learning models. The data processed in initial stage is now processed by the AlexNet model as indicated in lines (9) to (15). During the AlexNet operation, all the eight layers are used. For first five convolution layers, the ReLU activation function is used. The other layers are utilized as described in above section. From lines (15) to (20), transfer learning of the CNN is performed. Meanwhile, the CNN is fine tuned in which epochs, batch sizes, and learning rate is set as shown in lines (18) and (19) of Algorithm 1.
| Algorithm 1: Pseudocode of fruits freshness classification method |
Input: Obtain colored fruits images ► Data Collection from Kaggle do: Process collected data obtained in step (1). ► Initial stage. Perform pre-processing operations as listed in Section 3.2. Process uni-channel images and make uniform image resizing. Perform image augmentation and image labeling. Perform data manipulation. ► Isolate into validation, train, and test set. end begin Load AlexNet model Activate 8-layers including 5 conv layers and 3 fully connected layers. Use ReLU for first 5 conv layers. Process and utilize 8-layers as depicted in Section 3.4. end begin Transfer learning of the CNN Apply fine tuning and set the parameters as: Epochs = 10 and Batch size = 32, Set the learn rate = 10−5 end Apply softmax classifier: Use Equations (1) and (2) for classification tasks. Output: Final classification result: Fresh fruit or Rotten fruit
|
In the final stages, the softmax classifier is used to predict the final status of the fruit. It will be shown in next section that our developed method is robust and accurately classifies the fruit condition instantly. Moreover, the steps shown in Algorithm 1 are simple and easy for readers to follow. In section below, we detail our findings along with useful images. In addition, we also discuss our observations during algorithm development stages.
4. Simulation Results
This section lists the experimental setup, used datasets brief description, fruits classification results, discussion, and observations in detail.
4.1. System Specifications and Experimental Setup
Our developed algorithm was executed on an Intel
® NY USA Core I-i53550 machine, which has a CPU@3.30 GHz along with the facility of a NVIDIA GTX1080 graphics card. The aforesaid machine has 16 GB of RAM, which is sufficient to investigate the fruits freshness classification results that are yielded by our developed algorithm. Moreover,
Table 1 lists the parameters and experimental setup that is used throughout the simulations during the transfer learning of the CNN. As shown in
Table 1, during our all simulations, the SGDM optimizer is used along with a learning rate of
. The L2 regularization was used in our method. Moreover, the validation frequency was set to 50 along with epochs and batch size were set to 10 and 32, respectively. The data was shuffled after the completion of every epoch. To achieve the classification output in a reasonable time, the pace of the momentum was set to 0.9. Training and test image resolution is 227 × 227 pixels.
In sections below, we describe the details of the datasets that we used during our algorithm execution along with detailed qualitative and quantitative analysis. For each of these sections, a detailed discussion is also carried out along with our findings and recommendations.
4.2. Datasets Description
To simulate and validate our developed fruits freshness classification method, we choose three publicly available datasets. Below, we briefly present the details of each of the dataset.
Dataset 1: This data set contains 12,000 diverse images of fresh and rotten categories of fruits and vegetables [
5]. Specifically, this dataset contains ten different classes. Prominent categories of fruits gathered in this dataset are apple, banana, orange, mango, strawberry, potato, carrot, tomato, cucumber, and bell peper. Each of the fresh categories in this dataset contain at least 600 images, while the rotten category contains minimum of 500 images. A few of the sample images from this dataset are shown in
Figure 4.
Dataset 2: This data set contains total of 13,346 images of fresh and rotten fruits [
19]. The foremost categories of this dataset are total of 6 classes, out of which are 3 classes for each fresh and rotten for apple, orange, and banana.
Table 2 depicts the details of this dataset. From
Table 2, it is clear that for fresh fruits category of apple, orange, and banana, this dataset contains at least 1400 images. While the rotten categories of apple and orange contain over 2200 images. Rotten banana in this case has the least gathering of 1595 bananas.
Dataset 3: This data set contains total of 3200 images in a duration of two weeks in March 2022 [
20]. This dataset has been organized into 16 major classes, which are fresh and rotten grapes, fresh and rotten guavas, fresh and rotten jujubes, fresh and rotten pomegranates, fresh and rotten strawberry, fresh and rotten apples, fresh and rotten bananas, and fresh and rotten oranges. Few sample images of this dataset are shown in
Figure 5. Developers of this dataset also provided the augmented images of these classes, which result in a total of 12,335 images.
4.3. Evaluation Parameters
In our method, we use two well-known parameters, which are theaccuracy and confusion matrix as briefly described below.
Confusion Matrix: it is a popular parameter that assesses the effectiveness of any classification model. Normally, a confusion matrix is a square matrix, which indicates the predicted classes against the actual classes. The rows in a confusion matrix denote true class labels, while columns indicate predicted class labels. In our work, we use the confusion matrix for each of the three datasets to analyze the performance of our developed fruits freshness classification method. A confusion matrix provides us the flexibility to compute several classification performance matrix, such as Accuracy, as described below.
Accuracy: it is a well-known parameter and is widely used in classification and recognition related tasks. In our work, we believe that Accuracy is a good indicator to evaluate our developed classification method as it is extensively used to measure the pixels, which are correctly classified by any model. Mathematical accuracy is formulated as shown by Equation (5)
where True Positives and True Negatives belong to the true fruits positive and negative classes, respectively. While False Positives are fruits that are incorrectly classified as positives and False Negatives are fruits, which are incorrectly classified as negatives.
4.4. Fruits Classification Analysis
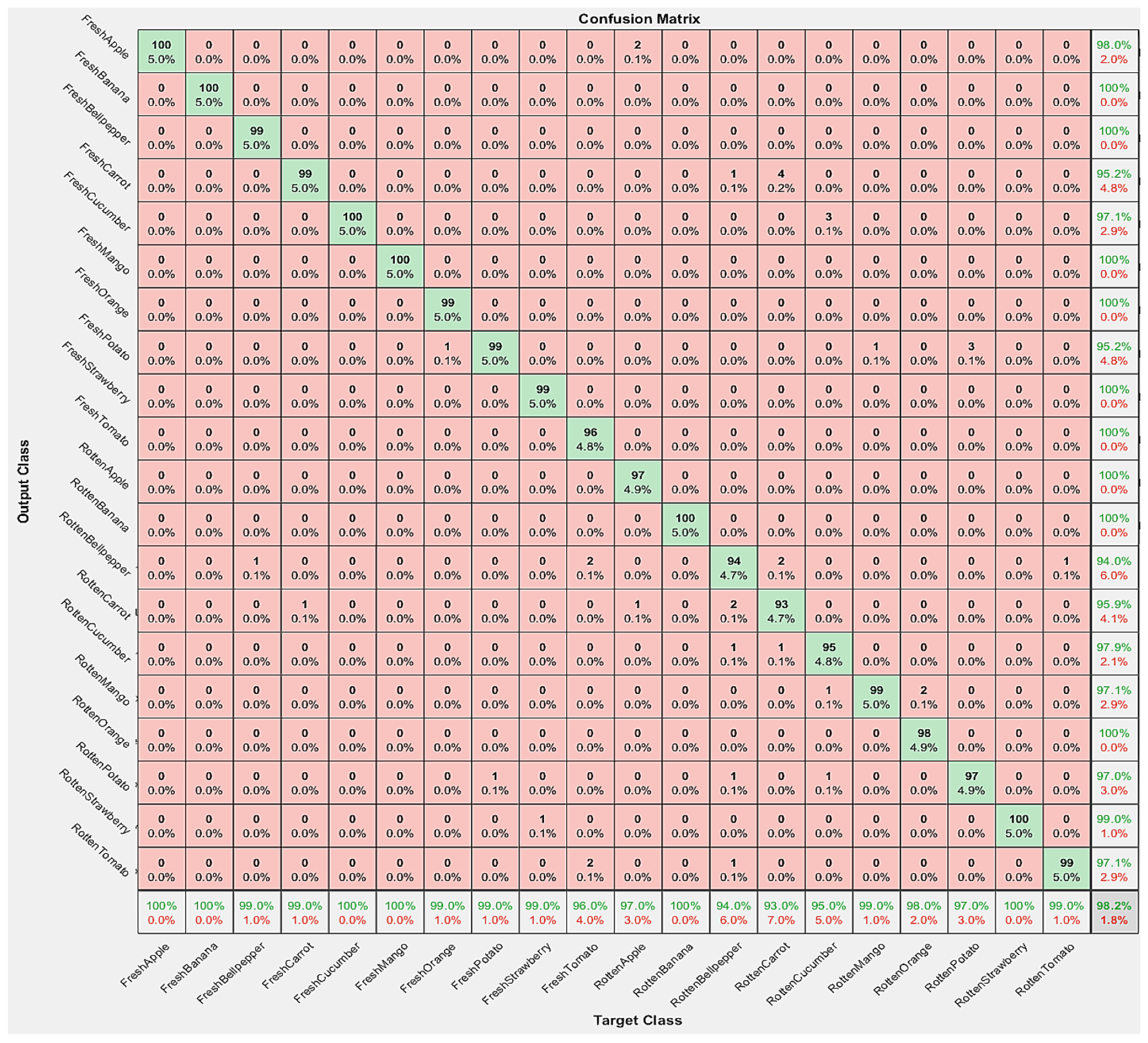
In this section, we discuss in detail the performance of our developed method through confusion matrixes for each of the datasets described earlier. For Dataset 1,
Figure 6 shows our developed classifier’s performance through a confusion matrix. The diagonal in the confusion matrix indicates true positives or actual values and shows the classification accuracy, which is achieved by our developed method. As discussed earlier that Dataset 1 contains 20 classes in which each of the fresh and rotten classes contains 10 items, respectively. For each of the fresh categories of apple, banana, and mango, 100% classification accuracy is obtained. Whereas for the fresh categories of orange and strawberry, our proposed method yields 99% accuracy.
For the rotten categories of banana and strawberry, our classification method yields 100% accuracy. While for the aforesaid categories of apple, mango, and orange, our developed method yields 97%, 99%, and 98% classification accuracy, respectively. We note that once the training of the CNN is completed almost 98.2% classification accuracy is obtained immediately.
Figure 6 also shows the accuracy of fresh and rotten vegetables, such as bell pepper, carrot, cucumber, potato, and tomato, respectively. Since our method is confined to fruit categories only, therefore, we believe that this provided accuracy comparison is useful for the research community.
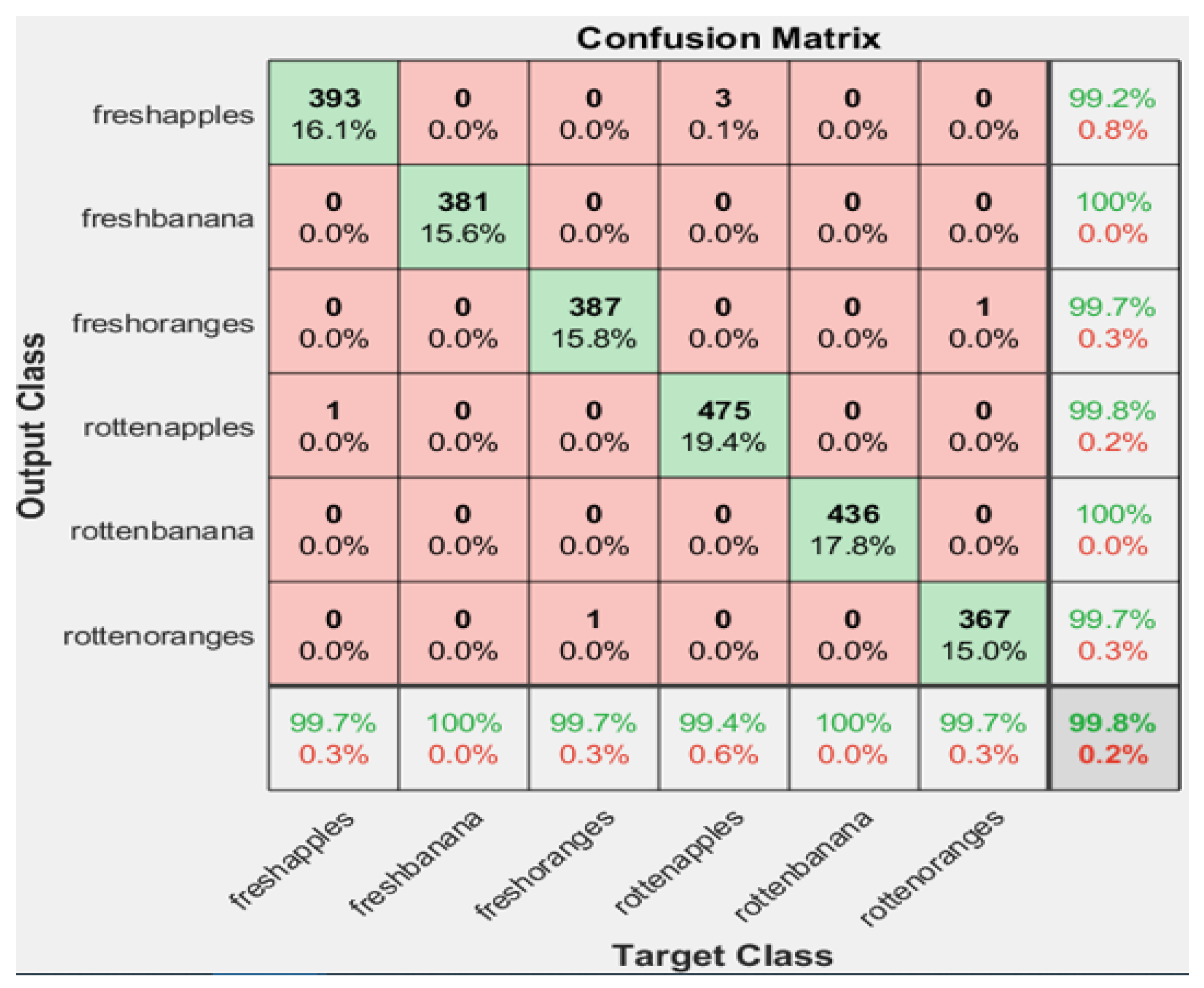
Figure 7 shows the classification accuracy obtained by our developed method on Dataset 2. Since this dataset contains total of three fruits with six classes. As shown in the diagonal of
Figure 7 that for each of the fresh apple, banana, and orange our developed method obtains 99.2%, 100%, and 99.7% accuracy, respectively. Similarly, for the rotten categories of these fruits, our proposed algorithm obtains 99.8%, 100%, and 99.7% classification accuracy for apple, banana, and orange, respectively. We believe that these findings are useful and encouraging. In the future, many food industries might also benefit from our findings.
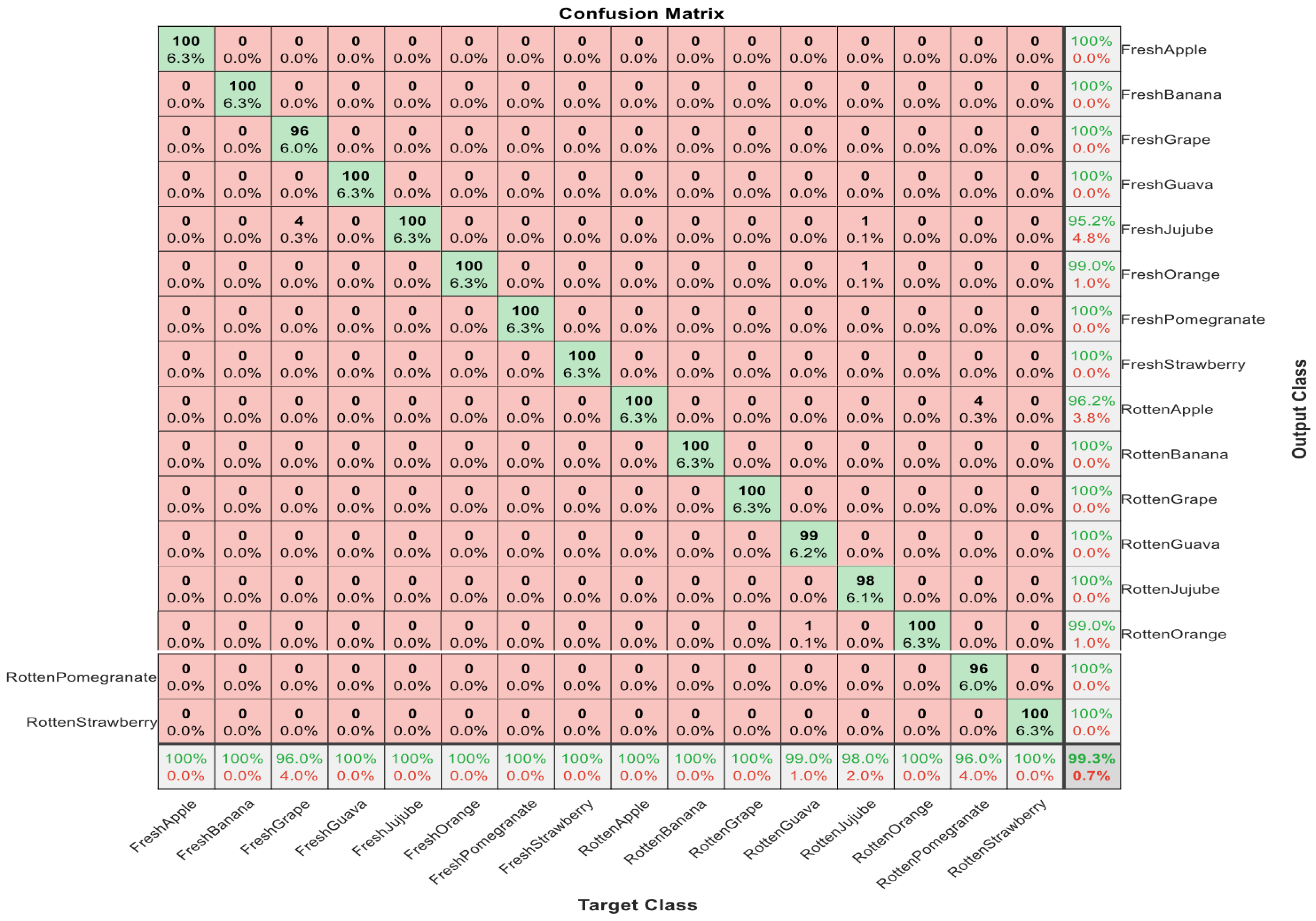
In our series of experiments,
Figure 8 reports our experiments on Dataset 3, which was briefly described earlier. This is a huge dataset and contains several classes. As can be seen in
Figure 8, for fresh categories of apple, banana, guava, jujube, orange, pomegranate, and strawberry, our developed method yields 100% classification accuracy. Moreover, for fresh category of grape, our developed algorithm yields 96% classification accuracy. Similarly, for the rotten categories of the aforementioned fruits, 100% classification accuracy is obtained for apple, banana, grape, orange, and strawberry. We are optimistic that our findings are encouraging and useful.
4.5. Comparison
In this section, we present the comparison of our developed method with several other methods on same datasets. We compare our work with three recently reported fruit freshness classification methods [
5,
19,
20,
23,
24,
25]. For fair comparison, we use the same training strategy as reported by above-described methods.
Table 3 shows the mean accuracy comparison. From
Table 3, a few important observations are listed below.
4.6. Discussion
The points discussed above give good insight about the fruit freshness classification performance of our developed method. However, the discussion below sheds more light on the performance of our developed algorithm.
Our study indicates that different networks achieve diverse accuracy outcomes on different algorithms. The MobileNetV2 trained by [
20] on Dataset 2 achieves 97.14% classification accuracy. Whereas VGG16 and InceptionV3 achieve 96.10% and 97.10% classification accuracy, respectively. On Dataset 2, the ResNet50 achieved the lowest classification accuracy of 73.26%.
Our method in general performs well on all the three datasets and achieves at least 98% classification accuracy as reported on Dataset 2 and also shown in
Table 3. We believe that for Dataset 2, our proposed method has almost solved the fruit freshness classification problem by achieving the 99.8% accuracy.
In general, all the compared methods perform well to handle the fruits freshness classification challenge and achieve at least 88% accuracy. One of the reasons for our developed method’s superior performance is employment of data augmentation in pre-processing stage, which significantly mitigates overfitting on small datasets. Similarly, while using the pre-trained CNN architecture model and replacing the last layer with required targeted class also are reasons for our model’s superior classification performance.
Our method achieves high accuracy and outperforms several recently published works [
5,
19,
20,
23,
24,
25] due to intelligent selection of the AlexNet architecture. Our study indicates that the training time of AlexNet architecture is five times faster as compared to others deeper architecture speed. Moreover, the AlexNet is computationally efficient and does not require high performance workstation [
26]. Similarly, in presence of other functions, for instance,
tanh, logistic, arctan, or Sigmoid as activation functions, the AlexNet uses the ReLU activation function that drastically reduces likelihood of vanishing gradient problem.
The layers in the AlexNet architecture contains more filters and each convolution layer is followed by a pooling layer. Such characteristics motivated us to utilize the AlexNet to address the fruits classification problem. Similarly, rotation and augmentation procedure as described in
Section 3 increases the fruits images that ultimately resulted in good training of the AlexNet architecture, which later yields high accuracy.
Recently published works, for instance, refs. [
26,
27,
28,
29,
30,
31] could also be investigated to develop a more robust fruits freshness classification method. Similarly, few of the [
32,
33] could also be investigated and optimized to develop a more robust and accurate algorithm that can detect and classify large species of several fruits.
4.7. Limitations
Although our proposed method achieves promising results in the aforementioned datasets. However, for the research community below, we briefly discuss the limitations faced by our developed algorithm.
Since our method uses the AlexNet architecture, during the preprocessing stage our method consumes a bit more time.
Since the AlexNet model was pre-trained on ImageNet dataset, which consists of 1000 object categories. Therefore, the model’s performance and features are biased towards the visual patterns and objects that are present in the dataset. If the targeted class is significantly different from ImageNet dataset, then the pretrained feature may not generalize well, which ultimately leads to the reduced performance.
The robustness of transfer learning depends on the similarity between the pre-training dataset and the target dataset. The AlexNet was trained on a large-scale dataset with millions of labeled images. If the target dataset is small or significantly different in terms of image content, style, or domain, then the pre-trained features may not capture the relevant patterns, which will also result in reduced classification performance.
We observe that fruit classification remains a difficult task for a machine learning algorithm due to several reasons. For example, fruits shape, colors, and texture similarity among various fruits species. Moreover, high variations in a single fruit class that is dependent on fruit maturity phase, and the actual condition when some fruit is presented such as fruits placed inside plastic bags, sliced, or unpicked from farm. In such scenarios, our developed method might struggle to accurately classify the fruits freshness.
4.8. Computational Complexity
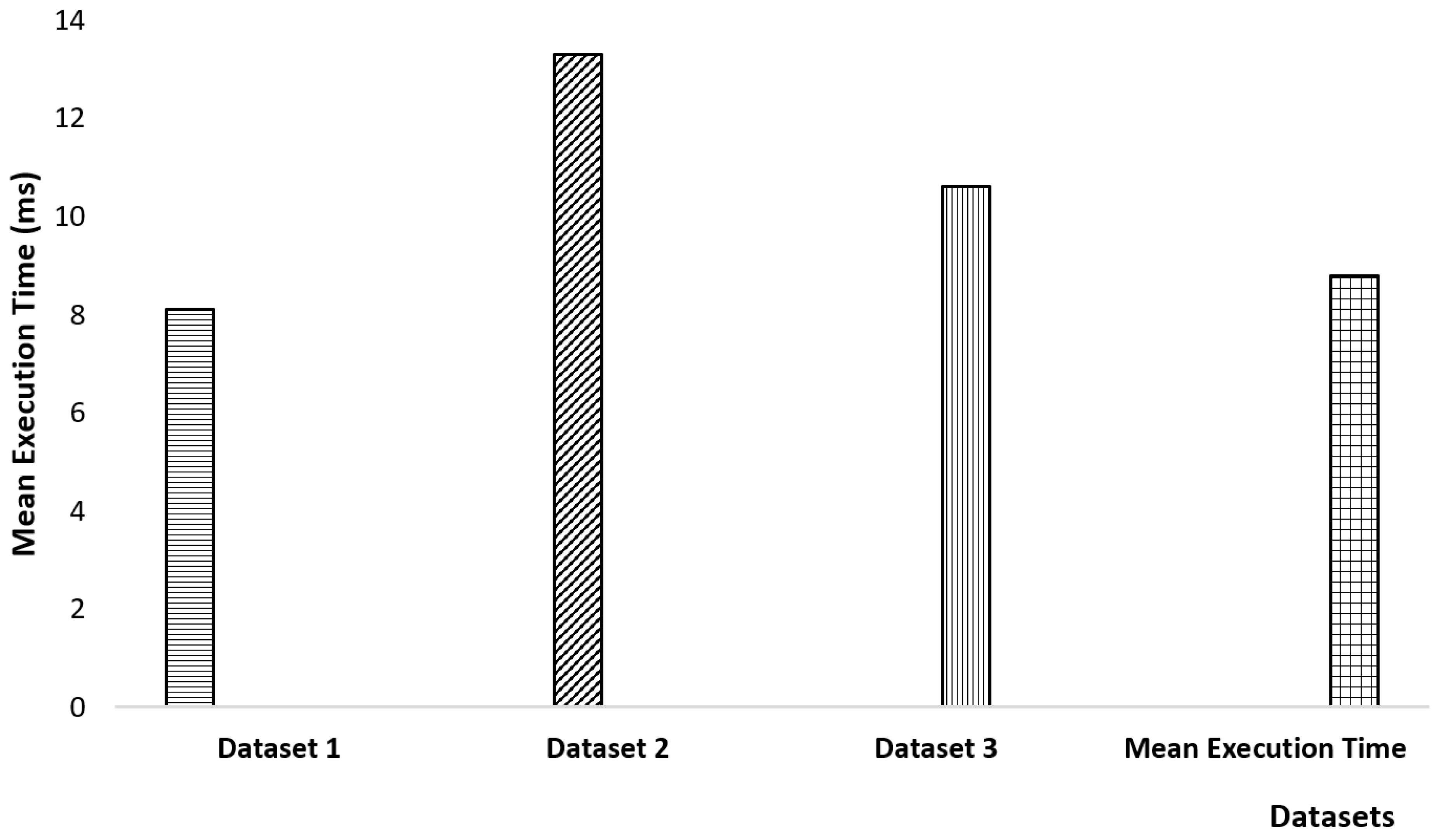
In
Figure 9, we show the computational complexity of our developed method. We work in three different databases in fresh and rotten fruit datasets. Training took almost 67 h on all three datasets. For Dataset 1, training took 31 h on 32,667 images and tests images are 1000. While for Dataset 2, almost 17 h were consumed on 10,901 images and tests images are 2445. Finally, for Dataset 3, our method consumed 19 h with 12,335 images and tests images are 1600. As shown in
Figure 9 in Dataset 1, test image consumes almost 8 ms to yield the final classification output. Similarly, for Dataset 2, slightly over 13 ms are consumed to obtain the final output. Our method requires almost 10 ms to yield the final classification result on Dataset 3. As shown in the last tower in
Figure 9, on the average, our method requires almost 8.8 ms to yield the final classification result.
5. Conclusions
This paper focused on the use of a deep convolutional neural networks model to propose a fully automated fruit freshness classification method. To check the quality standard of fruit, the consumer first manually checks the freshness of the fruit. We used transfer learning of CNN model AlexNet to develop a robust to assess the quality of fruits. We changed some hyper parameters while fine-tuning and obtained an enhanced performance of our algorithm. We also varied other parameters, such as learning rate and batch size. We achieved higher accuracy with our fine-tuned CNN model through transfer learning produce. Our proposed model achieved an average accuracy of 99% on three publicly available fruits datasets.
In the future, we aim to increase the variety of fruits so that the farmers will easily judge fresh and rotten fruit. This will essentially help them to purchase better quality fruits from the market. We also intend to develop a user-friendly mobile application that will display the classification results of more fruits and vegetables. Moreover, we also aim to generalize the evaluation of our developed method on more classes such as extra vegetable species. Furthermore, we also aim to investigate the effects of different parameters, for instance, the activation function, pooling function optimization, and a loss function. Finally, to handle the execution of complex machine learning and deep learning-based methods, our method can also be deployed into a cloud-based framework.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}