
Artificial Neural Network Model to Predict Final Construction Contract Duration
 ,
,  , ,
, ,
Abstract
:1. Introduction
2. Literature Review
2.1. Forecast Model Based on the Causes of the Time Delays
2.2. Forecast Model Based on Characteristics of a Contract or Project
2.3. Regression and ANN Models
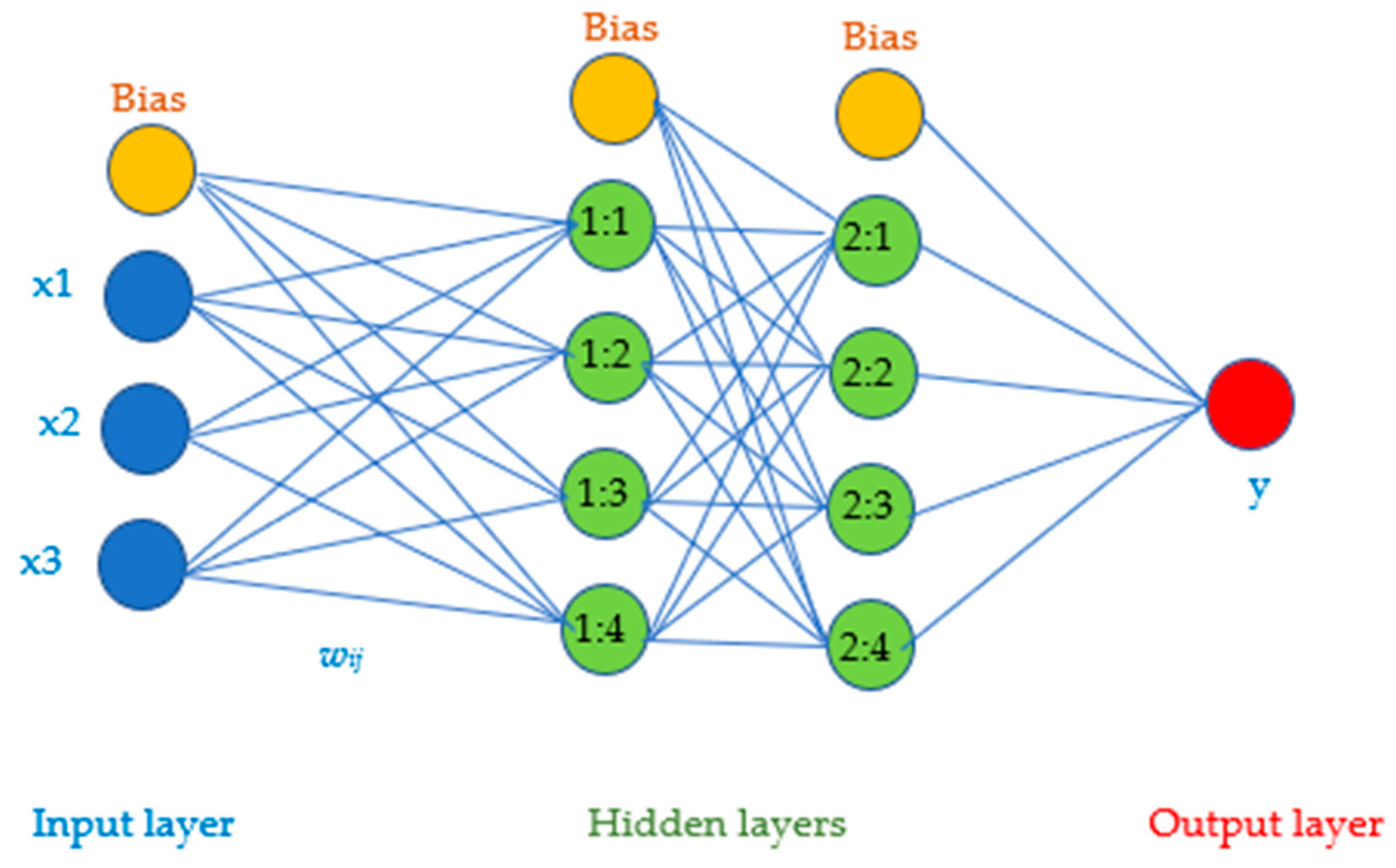
3. Artificial Neural Network (ANN) Model
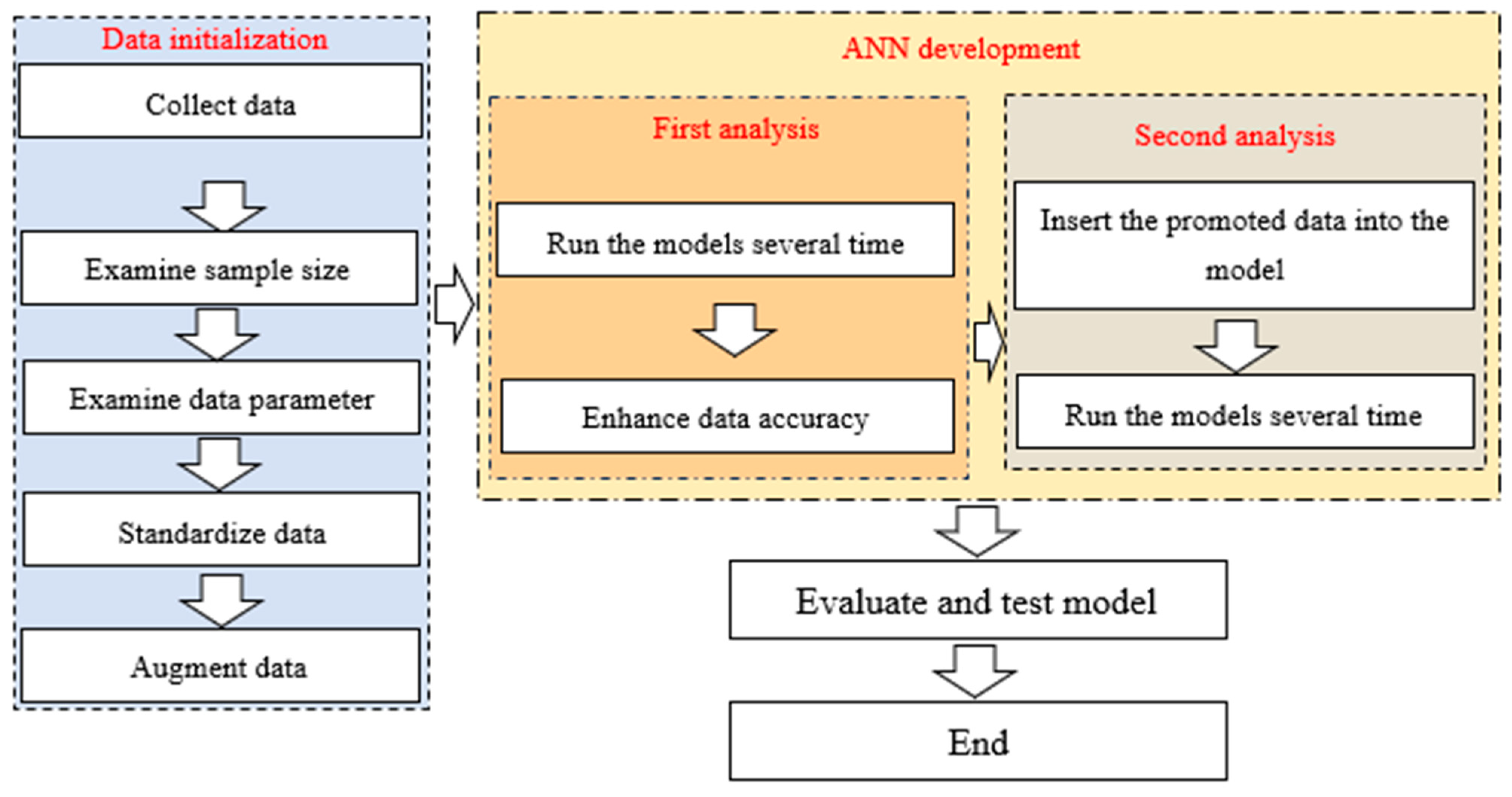
4. Methodology
4.1. Data Initialization
4.1.1. Data Collection
4.1.2. Sample Size Examine
4.1.3. Data Parameters Examination
4.1.4. Data Standardization
4.1.5. Data Augmentation
4.2. ANN Model Development
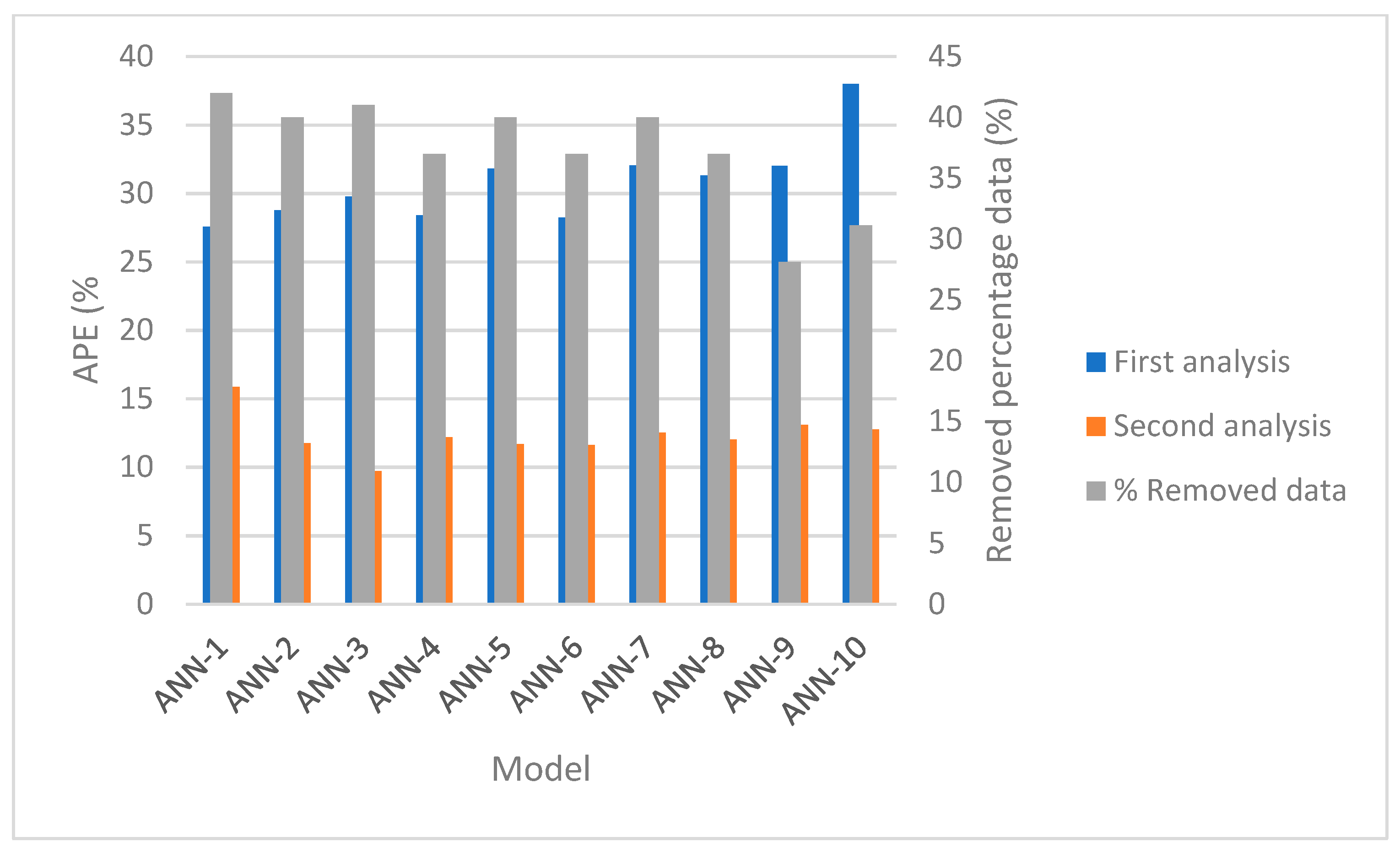
4.2.1. First Analysis
Running ANN Models
Enhance the Used Data Accuracy
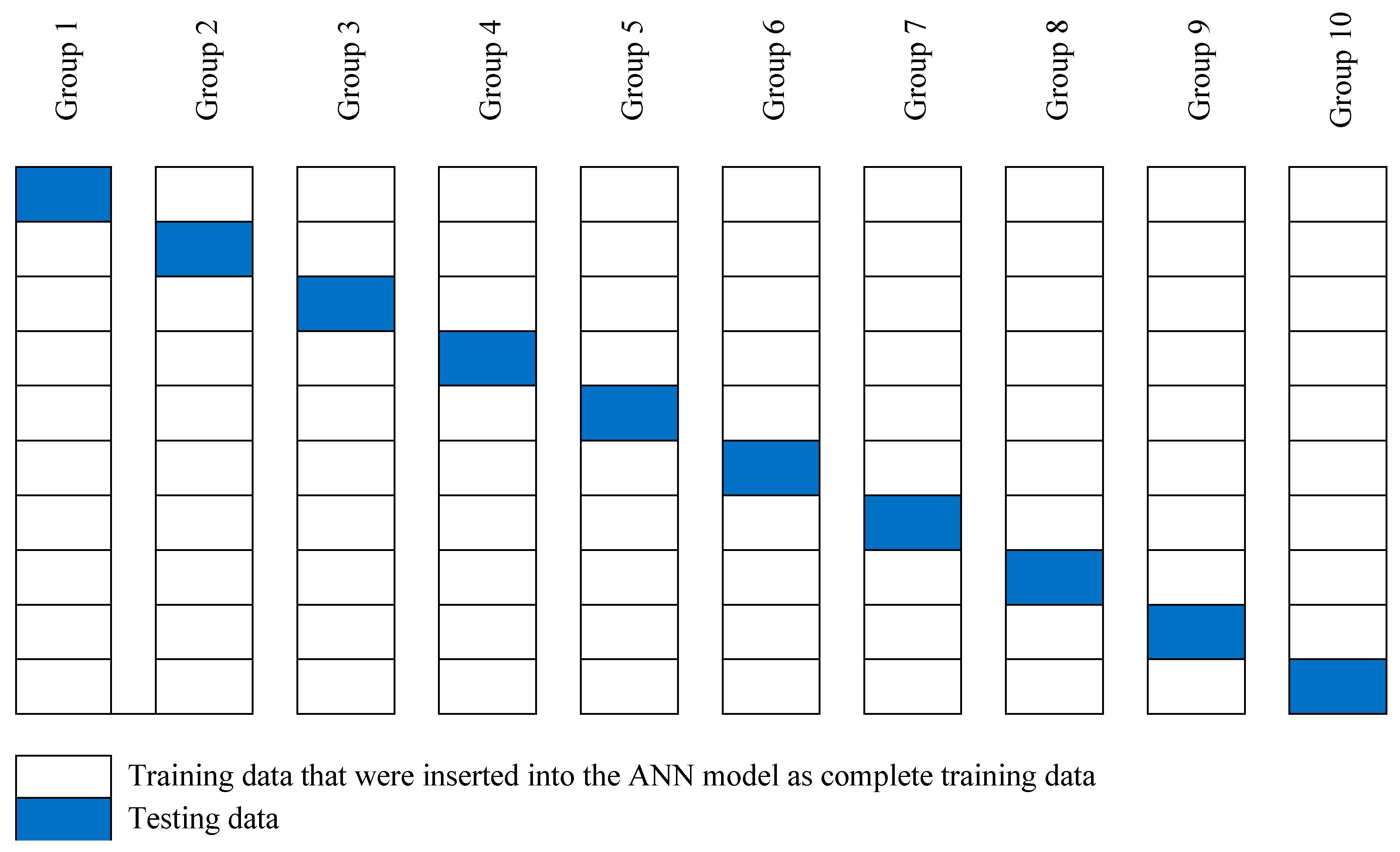
4.2.2. Second Analysis
4.3. Evaluation Model
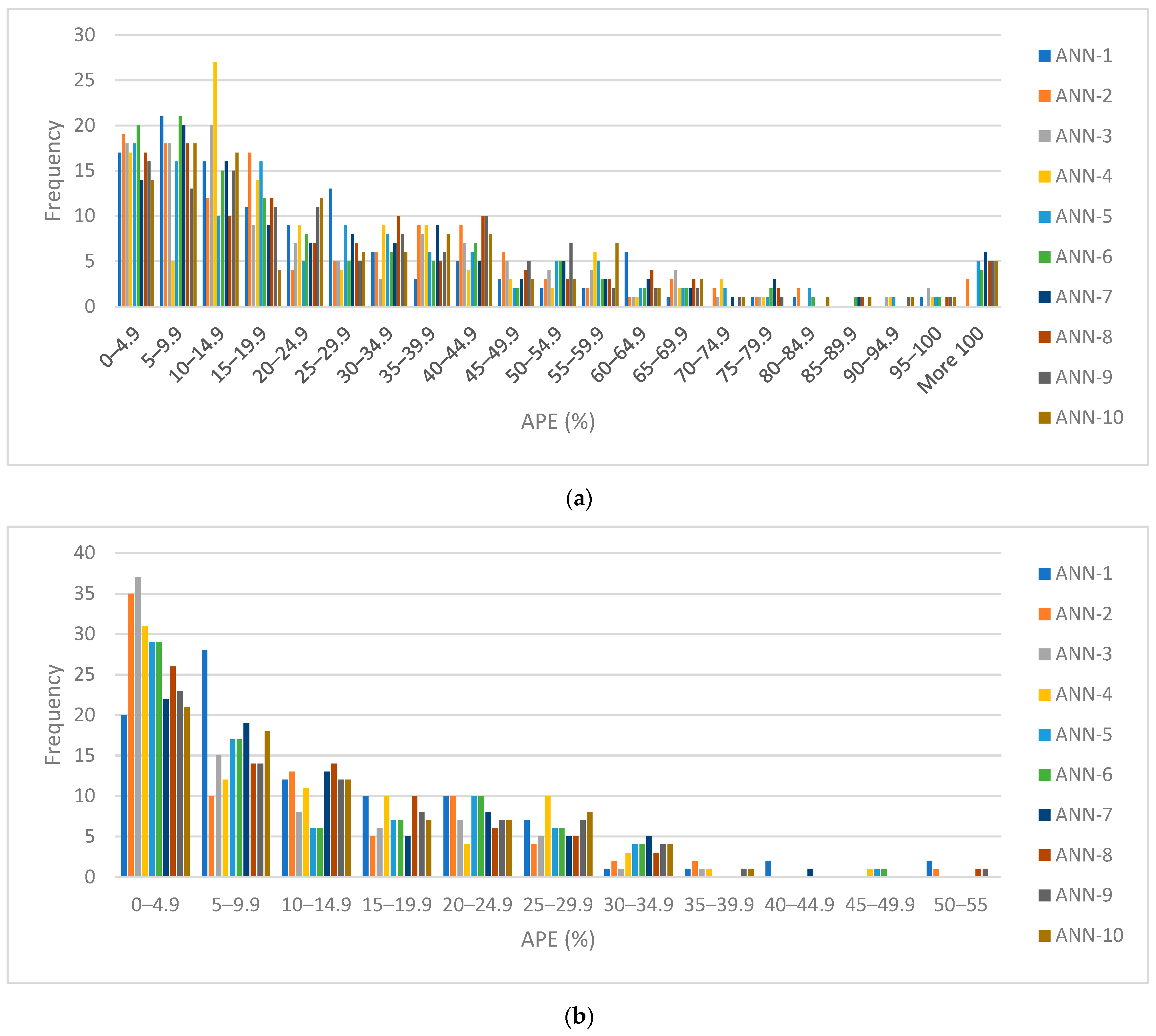
5. Results and Discussions
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| CC (SAR) | CD (Month) | FCCD (Month) | Public | Semi-Public | Private |
|---|---|---|---|---|---|
| 1,500,000 | 138.30 | 134.83 | 0.00 | 1.00 | 0.00 |
| 68,460,000 | 33.00 | 33.47 | 0.00 | 1.00 | 0.00 |
| 51,438,229 | 23.97 | 77.83 | 0.00 | 1.00 | 0.00 |
| 15,499,528 | 23.60 | 75.87 | 0.00 | 1.00 | 0.00 |
| 11,739,569 | 10.13 | 34.33 | 0.00 | 1.00 | 0.00 |
| 42,791,190 | 30.42 | 30.33 | 0.00 | 1.00 | 0.00 |
| 27,490,435 | 33.80 | 37.87 | 0.00 | 1.00 | 0.00 |
| 3,889,500 | 14.77 | 76.10 | 0.00 | 1.00 | 0.00 |
| 62,974,880 | 23.60 | 23.60 | 0.00 | 1.00 | 0.00 |
| 19,265,430 | 20.47 | 36.67 | 0.00 | 1.00 | 0.00 |
| 27,058,829 | 14.77 | 28.77 | 0.00 | 1.00 | 0.00 |
| 21,520,394 | 24.00 | 23.93 | 0.00 | 1.00 | 0.00 |
| 79,890,345 | 20.17 | 28.23 | 0.00 | 1.00 | 0.00 |
| 73,802,382 | 29.50 | 48.13 | 0.00 | 1.00 | 0.00 |
| 23,106,764 | 17.23 | 44.80 | 0.00 | 1.00 | 0.00 |
| 152,539,013 | 1.00 | 1.00 | 0.00 | 1.00 | 0.00 |
| 21,520,394 | 16.03 | 15.97 | 0.00 | 1.00 | 0.00 |
| 60,606,426 | 23.63 | 77.10 | 0.00 | 1.00 | 0.00 |
| 211,300,000 | 27.93 | 34.23 | 0.00 | 1.00 | 0.00 |
| 30,851,600 | 25.33 | 55.23 | 0.00 | 1.00 | 0.00 |
| 26,562,763 | 39.50 | 89.23 | 0.00 | 1.00 | 0.00 |
| 147,451,259 | 32.53 | 56.70 | 0.00 | 1.00 | 0.00 |
| 189,342,875 | 23.27 | 86.10 | 0.00 | 1.00 | 0.00 |
| 90,562,500 | 26.30 | 56.00 | 0.00 | 1.00 | 0.00 |
| 40,948,000 | 25.30 | 46.43 | 0.00 | 1.00 | 0.00 |
| 95,500,000 | 26.30 | 63.23 | 0.00 | 1.00 | 0.00 |
| 6,535,200 | 12.10 | 12.10 | 0.00 | 1.00 | 0.00 |
| 57,382,472 | 36.50 | 94.60 | 0.00 | 1.00 | 0.00 |
| 101,852,500 | 24.00 | 84.37 | 0.00 | 1.00 | 0.00 |
| 103,084,608 | 29.50 | 78.10 | 0.00 | 1.00 | 0.00 |
| 110,906,432 | 29.50 | 67.90 | 0.00 | 1.00 | 0.00 |
| 35,840,000 | 17.67 | 52.83 | 0.00 | 1.00 | 0.00 |
| 39,473,010 | 22.97 | 45.07 | 0.00 | 1.00 | 0.00 |
| 42,585,725 | 22.97 | 66.80 | 0.00 | 1.00 | 0.00 |
| 63,554,955 | 22.97 | 82.23 | 0.00 | 1.00 | 0.00 |
| 26,787,515 | 24.33 | 37.80 | 0.00 | 1.00 | 0.00 |
| 1,976,113 | 24.33 | 37.80 | 0.00 | 1.00 | 0.00 |
| 22,321,935 | 24.33 | 37.80 | 0.00 | 1.00 | 0.00 |
| 4,827,143 | 12.20 | 17.80 | 0.00 | 1.00 | 0.00 |
| 4,908,491 | 5.90 | 5.43 | 0.00 | 0.00 | 0.00 |
| 8,705,670 | 3.03 | 6.03 | 0.00 | 1.00 | 0.00 |
| 60,170,000 | 24.33 | 31.83 | 0.00 | 1.00 | 0.00 |
| 95,154,746 | 30.42 | 35.33 | 0.00 | 1.00 | 0.00 |
| 51,711,016 | 24.33 | 72.80 | 0.00 | 1.00 | 0.00 |
| 52,922,740 | 24.33 | 72.80 | 0.00 | 1.00 | 0.00 |
| 45,947,586 | 24.33 | 42.63 | 0.00 | 1.00 | 0.00 |
| 5,530,000 | 35.10 | 63.33 | 0.00 | 1.00 | 0.00 |
| 17,202,401 | 18.23 | 46.73 | 0.00 | 1.00 | 0.00 |
| 14,486,980 | 11.20 | 16.50 | 0.00 | 1.00 | 0.00 |
| 30,771,774 | 15.13 | 24.23 | 0.00 | 1.00 | 0.00 |
| 651,000,000 | 12.00 | 13.00 | 1.00 | 0.00 | 0.00 |
| 103,040,000 | 36.00 | 39.00 | 1.00 | 0.00 | 0.00 |
| 86,400,000 | 3.00 | 32.00 | 1.00 | 0.00 | 0.00 |
| 12,000,000 | 12.00 | 15.00 | 1.00 | 0.00 | 0.00 |
| 82,351,564 | 6.50 | 30.42 | 1.00 | 0.00 | 0.00 |
| 90,060,950 | 16.30 | 33.33 | 1.00 | 0.00 | 0.00 |
| 8,850,000 | 14.00 | 9.00 | 1.00 | 0.00 | 0.00 |
| 21,491,170 | 30.00 | 29.00 | 1.00 | 0.00 | 0.00 |
| 13,957,188 | 11.00 | 11.00 | 1.00 | 0.00 | 0.00 |
| 72,990 | 30.00 | 28.00 | 1.00 | 0.00 | 0.00 |
| 207,475 | 2.00 | 2.00 | 1.00 | 0.00 | 0.00 |
| 140,726,856 | 27.00 | 41.00 | 1.00 | 0.00 | 0.00 |
| 22,259,958 | 13.00 | 22.00 | 1.00 | 0.00 | 0.00 |
| 154,600 | 2.00 | 1.90 | 1.00 | 0.00 | 0.00 |
| 39,704,154 | 42.00 | 48.00 | 1.00 | 0.00 | 0.00 |
| 3,454,386 | 12.00 | 12.00 | 1.00 | 0.00 | 0.00 |
| 74,700 | 1.00 | 0.73 | 1.00 | 0.00 | 0.00 |
| 213,500 | 3.00 | 2.60 | 1.00 | 0.00 | 0.00 |
| 299,250 | 1.00 | 1.17 | 1.00 | 0.00 | 0.00 |
| 32,142,222 | 18.00 | 34.00 | 1.00 | 0.00 | 0.00 |
| 289,217 | 1.00 | 0.37 | 1.00 | 0.00 | 0.00 |
| 92,694 | 1.50 | 0.80 | 1.00 | 0.00 | 0.00 |
| 18,200 | 1.00 | 0.70 | 1.00 | 0.00 | 0.00 |
| 352,685 | 3.00 | 2.83 | 1.00 | 0.00 | 0.00 |
| 226,653 | 4.00 | 12.00 | 1.00 | 0.00 | 0.00 |
| 105,000 | 1.00 | 0.90 | 1.00 | 0.00 | 0.00 |
| 87,034 | 1.50 | 0.90 | 1.00 | 0.00 | 0.00 |
| 496,000 | 0.50 | 1.03 | 1.00 | 0.00 | 0.00 |
| 480,000 | 0.50 | 0.37 | 1.00 | 0.00 | 0.00 |
| 256,800 | 1.50 | 2.50 | 1.00 | 0.00 | 0.00 |
| 574,590 | 6.00 | 8.93 | 1.00 | 0.00 | 0.00 |
| 690,450 | 2.00 | 1.70 | 1.00 | 0.00 | 0.00 |
| 488,775 | 4.00 | 4.00 | 1.00 | 0.00 | 0.00 |
| 491,400 | 4.00 | 4.00 | 1.00 | 0.00 | 0.00 |
| 481,950 | 6.00 | 13.00 | 1.00 | 0.00 | 0.00 |
| 489,510 | 3.00 | 2.70 | 1.00 | 0.00 | 0.00 |
| 444,000 | 3.00 | 3.67 | 1.00 | 0.00 | 0.00 |
| 11,835,120 | 22.00 | 20.00 | 1.00 | 0.00 | 0.00 |
| 232,281 | 3.00 | 10.93 | 1.00 | 0.00 | 0.00 |
| 296,100 | 3.00 | 2.97 | 1.00 | 0.00 | 0.00 |
| 287,000 | 2.00 | 2.00 | 1.00 | 0.00 | 0.00 |
| 285,100 | 2.00 | 2.00 | 1.00 | 0.00 | 0.00 |
| 296,500 | 1.00 | 1.00 | 1.00 | 0.00 | 0.00 |
| 297,000 | 1.00 | 1.00 | 1.00 | 0.00 | 0.00 |
| 285,000 | 1.00 | 1.00 | 1.00 | 0.00 | 0.00 |
| 247,800 | 2.00 | 2.00 | 1.00 | 0.00 | 0.00 |
| 299,810 | 2.00 | 2.00 | 1.00 | 0.00 | 0.00 |
| 299,907 | 2.00 | 2.00 | 1.00 | 0.00 | 0.00 |
| 96,200 | 1.50 | 1.50 | 1.00 | 0.00 | 0.00 |
| 295,750 | 2.00 | 2.00 | 1.00 | 0.00 | 0.00 |
| 230,000 | 2.00 | 2.00 | 1.00 | 0.00 | 0.00 |
| 299,700 | 2.00 | 2.00 | 1.00 | 0.00 | 0.00 |
| 247,300 | 6.00 | 6.00 | 1.00 | 0.00 | 0.00 |
| 76,000 | 1.50 | 1.50 | 1.00 | 0.00 | 0.00 |
| 469,000 | 3.00 | 3.00 | 1.00 | 0.00 | 0.00 |
| 33,500,000 | 6.00 | 6.00 | 1.00 | 0.00 | 0.00 |
| 6,974,000 | 6.00 | 7.50 | 1.00 | 0.00 | 0.00 |
| 15,996,979 | 6.00 | 6.00 | 1.00 | 0.00 | 0.00 |
| 499,000 | 3.00 | 3.00 | 1.00 | 0.00 | 0.00 |
| 478,000 | 3.00 | 3.00 | 1.00 | 0.00 | 0.00 |
| 451,000 | 3.00 | 3.00 | 1.00 | 0.00 | 0.00 |
| 50,000,000 | 8.00 | 8.13 | 0.00 | 0.00 | 1.00 |
| 190,000,000 | 12.47 | 14.17 | 0.00 | 0.00 | 1.00 |
| 20,000,000 | 6.00 | 24.33 | 0.00 | 0.00 | 1.00 |
| 35,000,000 | 11.93 | 11.17 | 0.00 | 0.00 | 1.00 |
| 11,000,000 | 12.00 | 5.00 | 0.00 | 0.00 | 1.00 |
| 291,000 | 1.00 | 1.00 | 1.00 | 0.00 | 0.00 |
| 259,500 | 1.00 | 1.00 | 1.00 | 0.00 | 0.00 |
| 260,000 | 1.00 | 1.00 | 1.00 | 0.00 | 0.00 |
| 295,576 | 0.93 | 0.93 | 1.00 | 0.00 | 0.00 |
| 259,259 | 0.93 | 0.93 | 1.00 | 0.00 | 0.00 |
| 61,380 | 1.00 | 1.00 | 1.00 | 0.00 | 0.00 |
| 35,500 | 0.50 | 0.50 | 1.00 | 0.00 | 0.00 |
| 50,000 | 0.47 | 0.47 | 1.00 | 0.00 | 0.00 |
| 221,250 | 4.00 | 4.00 | 1.00 | 0.00 | 0.00 |
| 90,000 | 1.00 | 1.00 | 1.00 | 0.00 | 0.00 |
| 119,333 | 3.00 | 3.00 | 1.00 | 0.00 | 0.00 |
| 593,295 | 6.00 | 6.00 | 1.00 | 0.00 | 0.00 |
| 120,000 | 1.00 | 1.00 | 1.00 | 0.00 | 0.00 |
| 390,000 | 2.00 | 2.70 | 1.00 | 0.00 | 0.00 |
| 64,000,000 | 30.50 | 36.50 | 1.00 | 0.00 | 0.00 |
| 49,998,494 | 18.25 | 19.00 | 1.00 | 0.00 | 0.00 |
| 24,756,246 | 18.25 | 19.00 | 1.00 | 0.00 | 0.00 |
| 173,000,000 | 14.00 | 68.00 | 1.00 | 0.00 | 0.00 |
| 470,000,000 | 36.00 | 146.00 | 1.00 | 0.00 | 0.00 |
References
- Bertelsen, S.; Sacks, R. Towards a new understanding of the construction industry and the nature of its production. In Proceedings of the 15th Conference of the International Group for Lean Construction, East Lansing, MI, USA, 18–20 July 2007; Michigan State University: East Lansing, MI, USA, 2007; pp. 46–56. [Google Scholar]
- Ajayi, B.O.; Thanwadee, C. Impact of construction delay controlling parameters on project schedule: DEMATEL-System dynamics modelling approach. Front. Built Environ. 2022, 8, 799314. [Google Scholar] [CrossRef]
- Tafazzoli, M.; Shrestha, P.P. Investigating Causes of Delay in US Construction Projects. In Proceedings of the 53rd ASC Annual International Conference, Seattle, WA, USA, 5–8 April 2017. [Google Scholar]
- Gebrehiwet, T.; Luo, H. Analysis of Delay Impact on Construction Project Based on RII and Correlation Coefficient: Empirical Study. Procedia Eng. 2017, 196, 366–374. [Google Scholar] [CrossRef]
- Khattri, T.; Agarwal, S.; Gupta, V.; Pandey, M. Causes and Effects of Delay in Construction Project. Int. Res. J. Eng. Technol. 2016. Available online: www.irjet.net (accessed on 4 March 2023).
- Hecker, J.Z. Transportation Infrastructure: Cost and Oversight Issues on Major Highway and Bridge Projects; US General Accounting Office: Washington, DC, USA, 2002.
- Latham, S.M. Constructing the Team; HMSO: London, UK, 1994. [Google Scholar]
- Bromilow, F.J. Measurement and scheduling of construction time and cost performance in the building industry. Chart. Build. 1974, 10, 57–65. [Google Scholar]
- Sodangi, M.; Salman, A. AHP-DEMATEL modelling of consultant related delay factors affecting sustainable housing construction in Saudi Arabia. Int. J. Constr. Manag. 2022. [Google Scholar] [CrossRef]
- Assaf, S.A.; Al-Hejji, S. Causes of delay in large construction projects. Int. J. Proj. Manag. 2006, 24, 349–357. [Google Scholar] [CrossRef]
- Al Saeedi, A.S.; Karim, A.M. Major Factors of Delay in Developing Countries Construction Projects: Critical Review. Int. J. Acad. Res. Bus. Soc. Sci. 2022, 12, 797–809. [Google Scholar] [CrossRef] [PubMed]
- Sambasivan, M.; Soon, Y.W. Causes and effects of delays in Malaysian construction industry. Int. J. Proj. Manag. 2007, 25, 517–526. [Google Scholar] [CrossRef]
- Love, P.; Edwards, D.J. Forensic project management: The underlying causes of rework in construction projects. Civ. Eng. Environ. Syst. 2004, 21, 207–228. [Google Scholar] [CrossRef]
- Al-Gahtani, K.; Alsugair, A.; Alsanabani, N.; Alabduljabbar, A.; Almutairi, B. Forecasting delay-time model for Saudi construction projects using DEMATEL–SD technique. Int. J. Constr. Manag. 2022, 1–15. [Google Scholar] [CrossRef]
- Pewdum, W.; Rujirayanyong, T.; Sooksatra, V. Forecasting final budget and duration of highway construction projects. Eng. Constr. Archit. Manag. 2009, 16, 544–557. [Google Scholar] [CrossRef]
- Han, S.; Lee, S.; Peña-Mora, F. Identification and Quantification of Non-Value-Adding Effort from Errors and Changes in Design and Construction Projects. J. Constr. Eng. Manag. 2012, 138, 98–109. [Google Scholar] [CrossRef]
- Gondia, A.; Siam, A.; El-Dakhakhni, W.; Nassar, A.H. Machine learning algorithms for construction projects delay risk prediction. J. Constr. Eng. Manag. 2020, 146, 4019085. [Google Scholar] [CrossRef]
- Anbari, F.T. Earned value project management method and extensions. Proj. Manag. J. 2003, 34, 12–23. [Google Scholar] [CrossRef]
- Vanhoucke, M.; Vandevoorde, S. A simulation and evaluation of earned value metrics to forecast the project duration. J. Oper. Res. Soc. 2007, 58, 1361–1374. [Google Scholar] [CrossRef]
- Urgilés, P.; Claver, J.; Sebastián, M.A. Analysis of the earned value management and earned schedule techniques in complex hydroelectric power production projects: Cost and time forecast. Complexity 2019, 2019, 3190830. [Google Scholar] [CrossRef] [Green Version]
- Sackey, S.; Lee, D.E.; Kim, B.S. Duration Estimate at Completion: Improving Earned Value Management Forecasting Accuracy. KSCE J. Civ. Eng. 2020, 24, 693–702. [Google Scholar] [CrossRef]
- Jin, R.; Han, S.; Hyun, C.; Cha, Y. Application of Case-Based Reasoning for Estimating Preliminary Duration of Building Projects. J. Constr. Eng. Manag. 2016, 142, 04015082. [Google Scholar] [CrossRef]
- Skitmore, R.M.; Ng, S.T. Forecast models for actual construction time and cost. Build. Environ. 2003, 38, 1075–1083. [Google Scholar] [CrossRef] [Green Version]
- Thomas, N.; Thomas, A.V. Regression modelling for prediction of construction cost and duration. Appl. Mech. Mater. 2017, 857, 195–199. [Google Scholar] [CrossRef]
- Badawy, M. A hybrid approach for a cost estimate of residential buildings in Egypt at the early stage. Asian J. Civ. Eng. 2020, 21, 763–774. [Google Scholar] [CrossRef]
- Ujong, J.A.; Mbadike, E.M.; Alaneme, G.U. Prediction of cost and duration of building construction using artificial neural network. Asian J. Civ. Eng. 2022, 23, 1117–1139. [Google Scholar] [CrossRef]
- Gab-Allah, A.A.; Ibrahim, A.H.; Hagras, O.A. Predicting the construction duration of building projects using artificial neural networks. Int. J. Appl. Manag. Sci. 2015, 7, 123–141. [Google Scholar] [CrossRef]
- Pasini, A.; Lorè, M.; Ameli, F. Neural network modelling for the analysis of forcings/temperatures relationships at different scales in the climate system. Ecol. Model. 2006, 191, 58–67. [Google Scholar] [CrossRef]
- Loy, J. Neural Network Projects with Python: The Ultimate Guide to Using Python to Explore the True Power of Neural Networks through Six Projects; Packt Publishing Ltd.: Birmingham, UK, 2019. [Google Scholar]
- Cardellicchio, A.; Ruggieri, S.; Nettis, A.; Renò, V.; Uva, G. Physical interpretation of machine learning-based recognition of defects for the risk management of existing bridge heritage. Eng. Fail. Anal. 2023, 149, 107237. [Google Scholar] [CrossRef]
- Cardellicchio, A.; Ruggieri, S.; Leggieri, V.; Uva, G. View VULMA: Data Set for Training a Machine-Learning Tool for a Fast Vulnerability Analysis of Existing Buildings. Data 2022, 7, 4. [Google Scholar] [CrossRef]
- Anysz, H.; Zbiciak, A.; Ibadov, N. The Influence of Input Data Standardization Method on Prediction Accuracy of Artificial Neural Networks. Procedia Eng. 2016, 153, 66–70. [Google Scholar] [CrossRef] [Green Version]
- Badawy, M.; Alqahtani, F.; Hafez, H. Identifying the risk factors affecting the overall cost risk in residential projects at the early stage. Ain Shams Eng. J. 2022, 13, 101586. [Google Scholar] [CrossRef]
- Zayed, T. Assessment of Productivity for Concrete Bored Pile Construction. Ph.D. Thesis, Purdue University, West Lafayette, IN, USA, 2001. [Google Scholar]
- Sharma, S.; Sharma, S.; Athaiya, A. Activation Functions in Neural Networks. Towards Data Sci. 2017, 6, 310–316. [Google Scholar] [CrossRef]
- Bishop, C.M. Neural Networks for Pattern Recognition; Oxford University Press: Oxford, UK, 1995. [Google Scholar]
- Pasini, A.; Pelino, V.; Potestà, S. A neural network model for visibility nowcasting from surface observations: Results and sensitivity to physical input variables. J. Geophys. Res. Atmos. 2001, 106, 14951–14959. [Google Scholar] [CrossRef]
- Gustriansyah, R.; Sensuse, D.I.; Ramadhan, A. A sales prediction model adopted the recency-frequency-monetary concept. Indones. J. Electr. Eng. Comput. Sci. 2017, 6, 711–720. [Google Scholar] [CrossRef] [Green Version]
- Bromilow, F.J. Contract time performance expectations and the reality. Build. Forum 1969, 1, 70–80. [Google Scholar]











| Parameters | Pearson Correlation Coefficient | p-Value | N | ||
|---|---|---|---|---|---|
| 1 | FCCD | CD | 0.784 | <0.0001 | 135 |
| 2 | FCCD | CC | 0.424 | <0.0001 | 135 |
| 3 | FCCD | Project sector | 0.520 | <0.0001 | 135 |
| 4 | FCCD | Project types | 0.037 | 0.666 | 135 |
| NO | Input | Output | ||||
|---|---|---|---|---|---|---|
| Public | Semi-Public | Private | ||||
| 1 | 20.66 | 13.01 | 0 | 1 | 0 | 14.90 |
| 2 | 33.08 | 0.05 | 0 | 1 | 0 | 0.04 |
| 3 | 20.20 | 12.68 | 0 | 1 | 0 | 10.86 |
| 4 | 27.01 | 14.46 | 0 | 1 | 0 | 17.03 |
| 5 | 35.23 | 15.22 | 0 | 1 | 0 | 13.85 |
| 6 | 22.57 | 14.77 | 0 | 1 | 0 | 15.72 |
| 7 | 21.58 | 16.81 | 0 | 1 | 0 | 17.60 |
| 8 | 32.86 | 15.92 | 0 | 1 | 0 | 15.82 |
| 9 | 34.51 | 14.39 | 0 | 1 | 0 | 17.46 |
| 10 | 29.65 | 14.95 | 0 | 1 | 0 | 15.77 |
| 11 | 24.43 | 14.77 | 0 | 1 | 0 | 15.04 |
| 12 | 30.00 | 14.95 | 0 | 1 | 0 | 16.25 |
| . | . | . | . | . | . | . |
| . | . | . | . | . | . | . |
| 122 | 33.68 | 16.38 | 1 | 0 | 0 | 16.36 |
| Model | Regression Formula |
| LR1 | |
| LR2 | |
| LR3 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Alsugair, A.M.; Al-Gahtani, K.S.; Alsanabani, N.M.; Alabduljabbar, A.A.; Almohsen, A.S. Artificial Neural Network Model to Predict Final Construction Contract Duration. Appl. Sci. 2023, 13, 8078. https://doi.org/10.3390/app13148078
Alsugair AM, Al-Gahtani KS, Alsanabani NM, Alabduljabbar AA, Almohsen AS. Artificial Neural Network Model to Predict Final Construction Contract Duration. Applied Sciences. 2023; 13(14):8078. https://doi.org/10.3390/app13148078
Chicago/Turabian StyleAlsugair, Abdullah M., Khalid S. Al-Gahtani, Naif M. Alsanabani, Abdulmajeed A. Alabduljabbar, and Abdulmohsen S. Almohsen. 2023. "Artificial Neural Network Model to Predict Final Construction Contract Duration" Applied Sciences 13, no. 14: 8078. https://doi.org/10.3390/app13148078