1. Introduction
The goal of multi-object tracking (MOT) is to track objects within a video sequence. Compared with single-object tracking [
1,
2,
3], which aims to track a single designated target, multi-object tracking requires to detect and associate all targets within a sequence. The detection sub-task aims to identify and localize objects in the current frame, and the association sub-task aims to establish connections between targets across frames. One main challenge of the association sub-task is to distinguish minor appearance differences between targets and continuously track objects with complex motion. Currently, tracking under scenes featuring uniform appearance and complex motions is one of the hot spots of computer vision. Such challenges are common in downstream tasks like optical motion capture and athlete tracking.
Traditional MOT methods [
4,
5,
6] often fail in scenes featuring uniform appearance and complex motions because of the limited association performance. In recent years, the new transformer-based detection model DETR [
7] has gradually emerged. These models can easily distinguish similar objects and handle complex human poses, achieving state-of-the-art performance on various computer vision tasks. This inspires researchers in the MOT field to explore the query-based detection structure in transformer models for better tracking under complex scenes. Such a design choice is called the track-by-attention (TBA) paradigm. We further classify models under this paradigm into two categories: single stage and two stage.
As shown in
Figure 1a, the two-stage models, including MQT [
8] and TransTrack [
9], apply separate decoders on object and track queries to obtain detection and tracking results. The track states are then updated using matched detection results. Meanwhile, single-stage models like MOTR and TrackFormer adopt a new end-to-end structure as shown in
Figure 1b. They directly classify and localize targets in the current frame using object and track queries to represent the states of newborn targets and existing targets, respectively. Both models can continuously track targets under complex occlusion and similar appearance conditions well because of the expressive ability brought by the transformer decoder architecture.
However, there are still some areas to be improved in the existing TBA methods for scenes with similar appearance and complex motion. Firstly, the tracking and detection tasks are not properly connected. In single-stage models, detection and tracking share the same network weights, making it difficult for models to accomplish two tasks simultaneously under similar appearance. Since the features required for detection and tracking are not consistent and sometimes even contradictory, this creates a trade-off between the two tasks of detection and tracking, reducing the accuracy of both. On the contrary, detection and tracking are completely independent in the two-stage models. While this avoids the coupling problem caused by inconsistent gradients, it also makes the tracking branch lack guidance from the detection branch. Secondly, in single-stage models, object queries are only responsible for matching with new targets rather than all targets. This prevents the model from fully utilizing the knowledge brought by state-of-the-art pretrained models to handle complex motion. Moreover, existing methods do not utilize the multi-layer design of the transformer decoder. For example, in TransCenter [
10] and MOTR [
11], only the output from the last layer of the decoder, is used as the feature for tracking targets, and the information from other layers is discarded.
This paper proposes a transformer-based model to address these issues. It achieves efficient multi-object tracking in complex scenes by improving the feature fusion within and between frames; hence, we call it FusionTrack.
To better transfer and aggregate information within the frame between the track and detection tasks, we propose a joint track–detection decoder to simultaneously identify all detection and tracking targets by separating the object query and track query tasks on top of MOTR [
11]. The optimization goal of the detection branch is reset to detect all targets. This allows it to fully utilize the knowledge in the pretrained weights of existing DETR detectors [
7,
12] to achieve more robust detection results. Masked self-attention is adopted to transfer in-frame information from object queries to track queries only, maintaining a relatively independent detector to ensure that the model is adaptable to different detectors.
To improve the feature fusion between the frame for better continuous tracking, a score-guided multi-level query fuser is proposed to align and transfer information between frames for track query propagation. This module aggregates queries from different decoder layers and fuses them with the guide of prediction scores for better appearance representation.
The model is evaluated on the DanceTrack [
13] dataset, a MOT dataset featuring similar appearance and complex motions, where association is the main challenge for tracking. The results are competitive compared with existing models like MOTR and TransTrack on both validation and test sets. Overall, our contribution can be summarized into the following three aspects:
- 1.
We propose a joint track–detection decoder to fuse information between the track and detection branches, improving the performance for both tasks.
- 2.
We propose a score-guided multi-level query fuser to extract instance representation for long-term tracking by fusing multiple intermediate queries based on the confidence score.
- 3.
We implement FusionTrack on top of the modules and perform comprehensive experiments on the DanceTrack dataset, achieving competitive results.
2. Related Works
In this section, we first provide a brief overview of the development of the transformer and its application in object detection and multi-object tracking. We then discuss two categories of track-by-attention methods: two stage and single stage. Two-stage methods perform tracking using a detection-association process, while single-stage methods track in an end-to-end manner. The simplified workflows of the two categories as well as our model are illustrated in
Figure 1.
2.1. Transformers in Computer Vision
Transformer is first proposed in the neural language processing field [
14]. It employs an encoder–decoder architecture to iteratively process the query feature using the attention mechanism. ViT [
15] introduced this architecture into computer vision as a feature extractor. SWin transformer [
16,
17] and CSwin transformer [
18] introduced positional bias by adopting different local windows to limit the attention range while preserving a large receptive field through window transformations.
Following ViT, DETR [
7] borrowed the decoder architecture to create an object detector. Compared with traditional CNN-based detection methods [
19,
20], DETR realizes the end-to-end detection design and does not require additional NMS modules. It takes a series of predefined queries as object proposals and passes them through a series of decoder layers to iteratively refine these features. Self-attention within queries and cross-attention with image features are performed in each layer of the decoder to better aggregate the features. Deformable DETR [
21] proposed the deformable attention mechanism to improve the inference speed and detection accuracy of small objects. DAB-DETR [
12] separated the query into content query and position anchor to introduce positional prior, achieving faster convergence and better performance. Group DETR [
22] and H-DETR [
23] introduced one-to-many matching from non-DETR detectors in different ways to achieve the same goal.
2.2. Two-Stage Track-by-Attention Methods
Two-stage track-by-attention methods primarily follow the track-by-detection (TBD) design [
4,
5,
6,
24,
25,
26,
27], a dominant multiple-object tracking paradigm. These methods can be further divided into four main parts according to [
26] detection, motion model, association and track life cycle management. At each frame, a detection model is used to localize and classify objects. Simultaneously, a motion model is employed to predict the locations of tracked objects in the current frame. The detection and track predictions are then associated based on their similarity. Finally, track states are updated and new tracks are added, following hand-crafted life cycle management rules.
First proposed by SORT [
6], the track-by-detection paradigm achieves competitive results despite its simple design. It uses only a Kalman filter as a motion model, intersection over union (IoU) as a similarity metric, and the Hungarian algorithm as an association method on top of an existing detector. DeepSORT [
24] and Tracktor [
25] improved the association component by introducing the cosine distance of appearance features as a matching cost. SimpleTrack [
26] formulated the four components of the track-by-detection method and selected the best methods for each component based on extensive experimentation. ByteTrack [
4] introduced a two-stage association method to better match severely occluded objects with low confidence. BOT-SORT [
5] introduced camera motion compensation and modified the track state representation in the Kalman filter to achieve state-of-the-art performance.
One characteristic of track-by-detection methods is that their four components are all replaceable. State-of-the-art detectors can be directly integrated into the tracker, allowing tracking performance to benefit from detectors pre-trained on large-scale datasets. In this work, we adopt the separable detector design to unleash the full potential of pre-trained detectors.
Inspired by transformer-based detection methods, TransTrack [
9] introduced the decoder architecture into the field of multiple-object tracking to refine track positions from the previous frame. Object queries and track queries are processed with different decoders and then matched using the Kuhn–Munkres algorithm applied to IoU similarity. Matched detection features are used as track queries for the next frame, and unmatched detections are filtered to create new tracklets. Following TransTrack, TransCenter [
10] introduced a dense pixel-level multi-scale representation for detection prediction. These methods use separate decoders to object and track queries and establish associations using traditional matching algorithms as the track-by-detection methods used. The tracking branch lacks information from detection objects and therefore suffers from low accuracy.
In contrast to these methods, we adopt a masked self-attention mechanism to allow information to flow from the detection branch to the tracking branch. In this way, the tracking branch can utilize pre-trained knowledge from the detection branch and achieve better performance.
2.3. Single-Stage Track-by-Attention Methods
Single-stage track-by-attention methods are one of the recent trends in multiple object tracking. It simplifies the complicated association part from the track-by-detection paradigm, forming an end-to-end architecture that only contains few hyper-parameters.
MOTR [
11] and TrackFormer [
28] both introduce such end-to-end architecture by processing object and track queries with the same decoder and then matching them with different strategies. During training, outputs from object queries are matched only with newborn tracklets and outputs from track queries are matched by looking up their instance IDs in ground truth objects. MOTRv2 [
29] further utilizes the existing detection model by using cosine positional embeddings of object boxes predicted by a high-quality pretrained detection model to initialize the object query. However, because of the order-independent characteristic of the transformer, all queries are equally processed with the same decoder weights in these models, discarding the fact that they are optimizing towards different targets. Although information can be shared to remove duplicate detection and improve track quality, the model has to distinguish the query type implicitly to optimize for different targets, leading to sub-optimal performance.
Compared with end-to-end methods, we separate the feed-forward network and detection heads to decompose object queries and track queries, allowing the model to learn different representations for different optimize targets.
3. Methodology
In this section, we first formulate the target of multi-object tracking and give an overview of the proposed FusionTrack model in the first two sections. We then follow the computation order of the model to present details of the proposed joint track–detection decoder, score-guided multi-level query fuser, and the track management and propagation strategy. Finally, we discuss how we train the proposed method.
3.1. Basic Formulations
The process of multi-object tracking can be formulated as follows: given a sequence of S images , the objective is to generate a list of predictions for each frame . Each prediction comprises a list of objects represented by their class , bounding box and instance ID .
3.2. FusionTrack
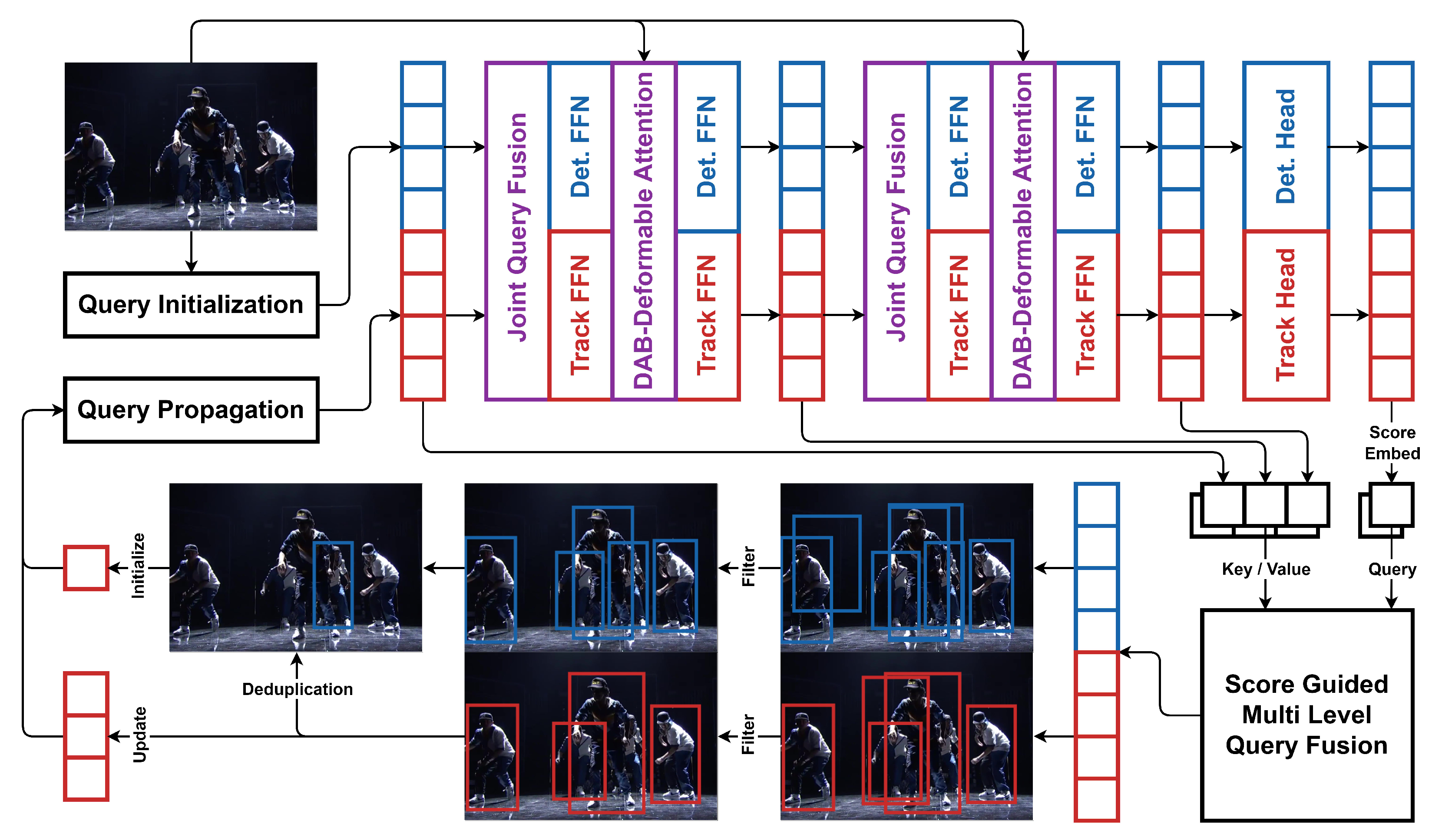
We propose FusionTrack to combine the advantages of independent detectors in traditional track-by-detection methods and the integrated decoder in end-to-end track-by-attention methods. To address the issue of correlation between the detection and tracking branches, we propose a unique joint track–detection decoder. It performs detection and tracking tasks simultaneously and independently while allowing the tracking branch to take information from the detection branch. To better utilize the multi-level property of the decoder structure, we propose a score-guided multi-level query fuser. It extracts the input and intermediate query features from each level of the decoder layers and fuses them per object to obtain appearance features. These appearance features are saved per tracklet and then used to generate queries for the next frame. The in-frame and cross-frame target feature fusion are performed in the joint track–detection decoder and score-guided multi-level query fuser for better feature representation, respectively.
In FusionTrack, the prediction is performed iteratively. We illustrate this process in
Figure 2. At each frame, a backbone feature extractor and a transformer encoder first extract the basic features
from the raw input image
. Object queries
are generated in the query initialization stage as a two-stage DETR [
7] does. These queries, along with the track queries
generated by the states of currently active tracklets, are then sent to the joint track–detection decoder to iteratively refine the features. The output object and track queries are then used to generate two sets of predictions
and
, representing all detected objects and tracking objects, respectively. Each prediction contains the classification
c and localization
b for an object candidate. The input and intermediate queries of the decoder are then fused in the score-guided multi-level query fuser to obtain the corresponding appearance feature for each object candidate. Finally, a tracklet manager filters and combines these results to updates the states of all present tracklets. These states are then used in the query propagation module to generate track queries for the next frame. The details of mentioned modules are discussed in execution order in the following sections.
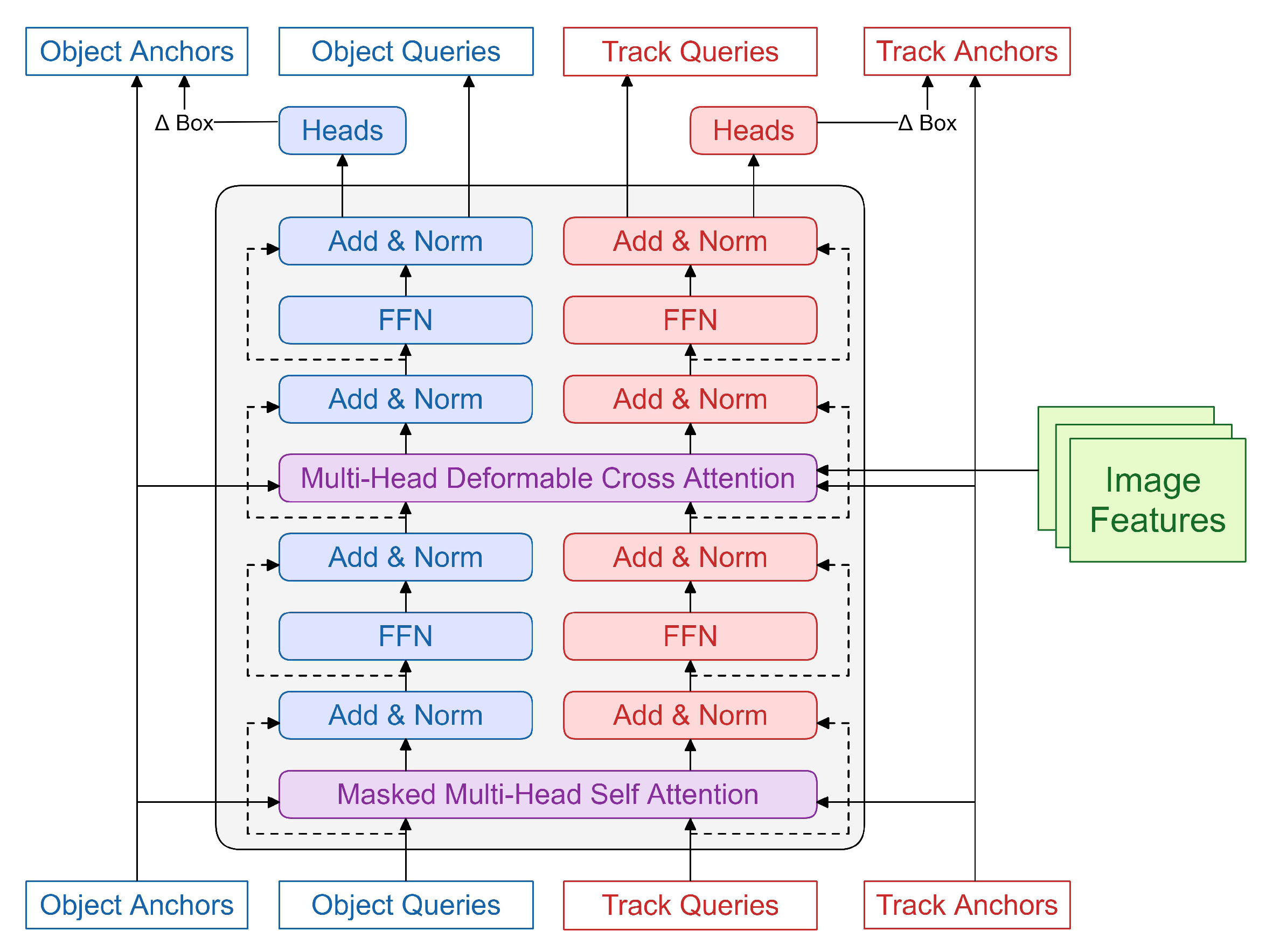
3.3. Joint Track–Detection Decoder
The joint track–detection decoder is designed to incorporate information from both detection and tracking branches. It takes object queries and track queries as inputs and refines them with two relatively independent yet correlated branches.
We chose the decoder of two-stage DAB Deformable DETR [
12] as our initial model to minimize the difference between the detection and tracking branches. This ensures the attention calculations between features of two branches are valid. Compared to the single-stage Deformable DETR used by MOTR, our model initializes the object query based on image features rather than a fixed set of features. This design aligns with the feature-based procedure of track query generation. We did not choose the two-stage variant of Deformable DETR because its object query is obtained by linearly projecting the predicted box. Such a design prevents the appearance information from propagating to the initial query and contradicts our approach of using appearance to obtain track queries.
The joint track–detection decoder has two branches for detection and tracking. Each of them takes a set of queries and position anchors as input. For the detection branch, a dense prediction is first performed on the image feature map
output by the encoder to obtain a series of predictions
. The model selects the predictions with the highest confidence and utilizes their corresponding features as the object queries
. The corresponding predicted boxes are used as the detect position anchors
. For the tracking branch, the appearance feature and bounding box motion of each object are used to obtain the track queries
and track position anchors
. The detailed track propagation procedure is described in
Section 3.6. The object and track queries and position anchors are iteratively refined through multiple layers of the joint track–detection decoder.
As shown in
Figure 3, in each layer of the decoder, the object and track queries
and anchors
first pass through a shared masked self-attention module for feature fusion. An attention mask is used to block the flow of information from the tracking branch to the detection branch while allowing the tracking branch to receive information from the detection branch. This design makes the detection branch completely identical to the original DAB Deformable DETR. The model can easily inherit the pre-trained knowledge of the original detector without any change. At the same time, knowledge can be effectively transferred from the detection branch to the tracking branch for better tracking. The object and track queries are then processed independently in the following FFN and cross-attention module as the original DAB-DETR to obtain queries
for the next level. Separate prediction heads are finally used to generate offset values
for iterative anchors refinement and other object properties for calculating auxiliary loss.
3.4. Score Guided Multi-Level Query Fuser
To better extract appearance information from queries and fuse the appearance features across frames, we propose the score-guided multi-level query fuser. It takes the input and intermediate results of the joint track–detection decoder and extracts target appearance information from multi-level and historical features.
In a decoder using an iterative refinement framework, the output features of the final layer are only supervised by classification and bounding box offset based on previous output. Such features may not represent the target’s appearance information needed for tracking well. To obtain richer appearance information, we fully utilize the intermediate queries from different levels that may potentially focus on different aspects of the target during the iterative refinement process. This module also incorporates the query input from the previous frame to fuse historical appearance features between frames. Since the accuracy of detection also affects the importance of historical information during fusion, we use the classification scores of each target as a basic hint for querying the required appearance information from these features.
As shown in
Figure 4, the features we need to fuse come from the current frame’s track queries
, which contains historical information about the tracked targets, and the intermediate queries
obtained by each layer of the decoder, which contains information about the targets in the current frame. Sinusoidal embedding followed by a single-layer network is used to embed the targets’ classification scores to obtain a score embedding of the same feature dimension as the query. We concatenate it with the aforementioned features to obtain a feature vector of
. This vector is treated as a batched token of length
. After adding sinusoidal position encoding to the tokens, the tokens are sent into multiple layers of transformer encoder-like structure for feature fusion. In this structure, we utilize self-attention as a fusion module, where different queries are fused using attention weights. It is similar to a combination of self-attention between queries and cross-attention between queries and score embedding. The final appearance feature is obtained by selecting the output token that is derived from score embedding.
Considering the difference in form between the object query and track query, we use two separate score-guided multi-level query fusers to obtain their respective appearances and in FusionTrack.
3.5. Tracklet Management
For most MOT models, a tracklet manager module receives the object candidates and corresponding appearance features from object queries and track queries. These inputs are used to update the states of all tracking tracklets and initialize newborn tracklets. Inspired by the end-to-end track-by-attention models, we propose a simple yet effective tracklet management scheme.
In FusionTrack, a tracklet is represented using its class label, appearance features, bounding box, and confidence. The label remains unchanged during a tracklet’s lifetime, while other features are updated during the tracking process. Following BOT-SORT [
5], an additional group of kinematic states
representing the bounding box position, size and their changing rate for each tracklet is maintained using the Kalman filter.
In FusionTrack, the detections that overlap with the tracking targets are removed from all detection objects, and the remaining detections are used to initialize tracklets. Meanwhile, the predictions from track queries are directly used to update the tracklet states as MOTR [
11] does. The detailed process is listed in execution order as follows:
- 1.
NMS and confidence filters are applied on detection and tracking predictions separately to remove poor results. This step is essential since duplicated prediction can result in a large number of false positives.
- 2.
The IoU between the remaining detection and tracking results is computed, and detection boxes that overlap any track box with IoU higher than the threshold are removed to avoid generating duplicate tracklets.
- 3.
Remaining track predictions are used to update the states of tracklets.
- 4.
Remaining detections are used to generate new tracklets.
- 5.
Tracklets that have not been updated for more than k frames are removed from the active list.
Compared with the traditional models that match track predictions with detections using complicated algorithms and additional reID module, the association in FusionTrack is done implicitly using bounding box information only. We claim that its effectiveness is a side effect of the query fusion module, where the track queries receive information from the detection branch to generate closer bounding box predictions.
3.6. Track Query Propagation
To complete a full autoregressive tracker, we propose that the query propagation module is used to convert tracklet states into track queries for the next frame. This module comprehensively utilizes the disappearance time, confidence score, and appearance feature of a tracklet to better guide the track of the next frame.
Figure 5 shows an example of this pipeline.
For appearance information, we directly take the appearance features from the fuser output as the tracks’ features at the current frame. This simple design is expressive enough since the tracks’ appearance features have already been fused with the in-frame and cross-frame information in the previous modules. For confidence information, we use a similar embedding method as in score-guided multi-level query fuser (
Section 3.4) to convert score values to embeddings. Additionally, to model the temporal uncertainty of the targets that are missing in previous frames, we use discrete delta-time embeddings to encode the frames passed since the last update of each tracking target. The appearance features and the confidence and time embeddings are concatenated and then passed through a simple MLP network to obtain track queries for the next frame.
To obtain better position priors as reference points for deformable attention, we refer to the kinematic states stored in each tracklet to generate rough predictions as track position anchor inputs.
3.7. Training
3.7.1. Batched Query Denoising Training
We train FusionTrack with video clips containing several frames. Since the number of ground truth objects in each video clip varies during training, it is difficult to align the number of track queries between different segments. This prevents the hardware from performing batched parallel training. To unify the number of track queries in different clips and provide negative samples for the tracking branch to assist convergence, we introduce the batched query denoising method. This design aligns the number of track queries in each sample by adding additional fake tracklets.
Let the video clip length be L and the batch size be b. For a batched frame containing real objects for each sample, we set the target track query length for that frame to be . We then unify the number of track queries in each sample to the target length by adding or removing fake tracklets according to the total number of tracks in each sample.
Preferentially, low-score detections are randomly selected, and their appearance features and predictions are used to initialize fake tracks. Under some rare situations when there are not enough low-score detections to initialize all fake tracks, random appearance features and bounding boxes are used instead.
Figure 6 shows an example of an intermediate frame from a batched training sample containing two different clips.
3.7.2. Tracklet Management
We adopt a different tracklet management scheme during training. For the tracklet representation, an additional ground truth instance ID is stored in the tracklet to represent its identity. For the detection branch, we directly match the outputs with all ground truth objects using the Hungarian algorithm. A new tracklet is initialized if a detection matches a ground truth object and the no existing tracklet with the same ground truth instance ID is found. The tracklet management scheme for the tracking branch stays the same as MOTR.
Compared to MOTR, we use all ground truth targets instead of only newborn targets to match the predictions of object queries, stabilizing the training of the detection branch. Such a design can also make the supervision of the detection branch identical to traditional detectors, making it easier to transfer knowledge from pretrained existing detectors. Compared to TransTrack, we directly forward the feature and prediction of the existing tracklet as MOTR, ensuring the continuity of the features.
3.7.3. Losses
To train the detection branch, we use the same training method as DETR does. For each matched detection, the class loss (FocalLoss), IoU loss and L1 loss are calculated and the weighted sum of these losses is the detection loss .
For the tracking branch, we use the ground truth instance ID to match each track query with its corresponding ground truth instance and calculate the same focal loss, IoU loss and L1 loss to obtain the track loss . This loss also passes gradients to train the score-guided multi-level query fuser and query propagation module.
The detection loss and track loss are weighted to obtain the training loss for each sampled frame:
Finally, we refer to the collective average loss (CAL) in MOTR to weigh the losses according to the number of ground truth objects. Unlike CAL, since the number of targets contained in different frames within one video sequence does not change much, we only weigh the losses between batches. Letting the number of ground truth objects in a sample in a batch of
N samples with
F frames be
, the final training loss is obtained as follows:
4. Experiments
This section describes the implementation details of the model and experiment results on the DanceTrack dataset. It also includes an ablation study conducted on the proposed modules to show their effectiveness.
4.1. Implementation Details
4.1.1. Model Structure
We build our model on top of a pretrained two-stage DAB-Deformable-DETR, which adopts ResNet-50 [
30] as the backbone image feature extractor. The structure of the model is shown in
Figure 2. Detailed model parameters are listed in
Table 1.
4.1.2. Training FusionTrack
For faster training and better performance, the model is trained on a weighted joint dataset containing CrowdHuman [
31], and DanceTrack [
13]. We define a key image’s difficulty by calculating the max overlap IoU of objects and the number of objects. Difficult samples with more occlusion and more objects are given more weights. For DanceTrack, 4 frames from a 10-frame interval are sampled randomly around the keyframe. Random resizing, cropping, hue and flipping augmentations are applied to each frame. For CrowdHuman, pseudo clips are generated by applying different augmentations on static images following MOTR [
11].
We adopt a multi-stage training strategy for faster convergence. For all experiments, we start with a COCO [
32] pretrained DAB-Deformable-DETR [
12]. We first train the base detector on the unweighted joint dataset for 4 epochs with batch size of 4 and learning rate of 2 · 10
−5. After that, we initialize the whole model by copying the weights from the detection branch to the tracking branch and randomly initialize the query propagation and query fusion modules. We then freeze the detection branch and train newly initialized modules for 4 epochs with batch size of 16, learning rate of
and clip length of 2 on the unweighted dataset to avoid new parameters from disturbing the pretrained ones. This gives a base pretrained model for all following experiments.
On top of the two-stage pretrained model, the model that gives the main results is trained using another two-stage finetuning process. It is first trained for 400,000 iterations with a learning rate of on the weighted joint dataset, which is approximately equivalent to 6 epochs of the DanceTrack dataset. It is then fine tuned on the DanceTrack dataset only for 2 epochs with a learning rate of to obtain the final model.
All stages utilize the AdamW optimizer with weight decay at to train the model. The learning rate varies depending on the training stage and decays in a cosine annealing pattern that eventually drops to 1/1000 of the starting learning rate.
4.2. Dataset and Metrics
We use the DanceTrack [
13] and CrowdHuman [
31] to train the network, and then evaluate it on the DanceTrack dataset.
DanceTrack is a large-scale dataset targeting the association problem in multi-human tracking under dancing scenes. The objects in this dataset have uniform appearance and a wide range of motions, making it difficult to associate objects across frames.
CrowdHuman is a dataset containing static images of crowded scenes. It features objects with severe occlusion. Random augmentations are applied to generate pseudo videos from these images to improve the detection performance under occlusion situations.
To evaluate the performance of FusionTrack, we mainly use the higher-order tracking accuracy (HOTA) [
33] metric. We also report the detection accuracy (DetA), association accuracy (AssA), and multi-object tracking accuracy (MOTA) [
34] and IDF1 [
35] metrics for comparison.
4.3. Results
We test FusionTrack on the DanceTrack private test set and collect performance data for related methods to form
Table 2. Without any test time augmentation or model ensemble, FusionTrack achieves 65.3 HOTA, which is an improvement of +11.1 compared to the structurally similar model MOTR.
We claim that such improvement mainly benefits from the advance of the ability to correctly re-identify objects despite no additional reID module being used. The resulting association accuracy and IDF1 metrics outperform previous methods by a large margin of +12.1 and +11.7, respectively. This shows that the in-frame and cross-frame feature fusion added in FusionTrack can efficiently improve the tracklets’ feature representation.
4.4. Ablation Study
To show the effectiveness of the proposed modules, we test different combinations of the score-guided multi-level query fuser (SG-MLQF) and query propagation module (QPM) on the DanceTrack validation set. Results are shown in
Table 3.
The score-guided multi-level query fuser significantly boosts the performance by about 3 HOTA. Such improvements are achieved by a significant improvement of the association accuracy. With the score-guided multi-level query fuser enabled, both IDF1 and AssA gain a +10% improvement compared with models without it. This observation, combined with the fact that we only adopt simple matching schemes to improve the association accuracy by a large margin compared with previous methods, shows that the in-frame query fusion is performing some degree of implicit matching. Meanwhile, the query propagation module can also slightly improve performance by providing more direct information to the track decoder.
5. Analysis and Discussion
5.1. Complexity Analysis
The inference speed of the model is approximately 7 fps on the DanceTrack dataset at full resolution on an A5000 GPU. Compared with the baseline model MOTR, which reports an inference speed of 7.5 fps, the main differences are as follows:
- 1.
The object queries and track queries are computed separately. This doubles the parameter of FFNs in each layer, while keeping the computation complexity unchanged. Let be the number of decoder layers and C be the feature channel; this adds parameters to the model.
- 2.
The score-guided multi-level query fuser performs attention in a different way than the TAN module in MOTR. Let be the number of tracklets in a frame, the computation complexity of the score-guided multi-level query fuser and TAN is and , respectively. In practice, our method requires slightly more computation in the DanceTrack dataset. This is negligible since both modules make few contributions in a model that performs the attention calculation in the decoder layers.
- 3.
FusionTrack requires a post-process for the prediction outputs. Let be the number of object queries, and the computation complexity of the post-process be . This is also negligible for the same reason as the score-guided multi-level query fuser.
5.2. Joint Track–Detection Decoder
The joint track–detection decoder is split into detection and tracking branches, which are connected by a shared masked self-attention module. Such a design allows information to flow from the detection branch to the tracking branch, allowing the tracking branch to better classify and localize the objects. We visualize the information flow in the self-attention module in
Figure 7 to better understand the module. As shown in the figure, the predictions of detection and tracking branches highly overlap each other. And the tracking branch takes information from the corresponding instance in the detection branch to improve performance, leading to more weights on the diagonal at the top-left corner of the attention map.
5.3. Score-Based Multi-Level Query Fuser
We analyze how the score-based multi-level query fuser works by recording and visualizing the information sharing through attention maps. This module consists of two consecutive attention modules in the implementation. Given a input query
q containing
tokens, the appearance feature
a is calculated as follows:
where
represents the product of the attention map and query in-projection weights. We ignore the influence of the intermediate feed-forward network and normalization modules and approximate the relationship between the final appearance feature and each intermediate query as the matrix product
of two attention maps. The last row of the influence matrix is taken to represent the weight of each token in the output appearance feature. For a continuously tracked target, we visualized the change of weights as shown in
Figure 8.
The upper segment of the figure illustrates how the approximated weights of each layer occupying the final feature change across frames. Each row represents the influence of the input query generated by the previous appearance, the query output by each of the six decoder layers, and the score embeddings in a top–down order, forming an old-to-new transition. A noticeable trend is that the score embeddings hardly contribute any information to the final appearance, while other weights fluctuate within a small range around a fixed value. We believe that this can be explained as follows: when most predicted scores are greater than 0.9, the difference between the score embedding queries used for querying across frames is not significant, which leads to this relatively fixed weight for each layer.
Meanwhile, for frames where targets overlap with each other, the weights of tokens closer to the previous frame are higher than those in frames without occlusion. An example is shown at the bottom-right corner of the figure, where we demonstrate the relative difference between the weights of single frames and the average weights across the video for a fixed instance. In frame 161, where object 2 and object 4 are severely occluded, the weights for the old query and the first decoder output are more than 50% higher than average. On the contrary, in frame 166 when all objects are separated, the weights for relatively new queries are higher. This is consistent with our intuition that “under complex overlapping conditions, old appearance features are more credible than current ones”.
5.4. Choosing Parameters for Matching
Since the association is made implicitly in the in-frame query fusion step, using only IoU for detection filtering can achieve excellent performance. The advantage of using such an end-to-end-like method is that the number of parameters that need to be adjusted is minimal compared with the two-stage matching method used in traditional MOT models like ByteTrack [
4]. The two most important parameters are the IoU threshold
and the confidence threshold
responsible for deleting duplicate detection objects and low-quality tracking boxes, respectively. Experiments on different combinations of these parameters on part of the DanceTrack validation set are conducted to find optimal parameters; the results are shown in
Figure 9.
We draw two conclusions from the experiments: Firstly, the performance of this model is greatly affected by the IoU threshold for filtering. If the threshold for IoU between the detection box and the existing tracking box is too high, a large number of false positives will be generated, influencing the performance of the model. This indicates that detecting objects that reappear shortly from behind foreground objects is still a challenging problem. Secondly, when the IoU threshold is reasonable, the confidence threshold does not have a significant impact on model performance, indicating that the results may still be accurate, even when the track confidence score is low and the tracking branch can be further improved. Based on the experimental results, we empirically choose and as the final parameters.
7. Conclusions
In this work, we propose FusionTrack, a transformer-based model for long-term tracking under scenes featuring uniform appearance and complex motions. As discussed in
Section 4 and
Section 5, the proposed joint track–detection decoder, score-guided multi-level query fuser and query propagation module can effectively fuse in-frame and cross-frame information into the track queries to obtain richer representations of tracking objects. With these modules and a new tracklet management scheme as shown in
Table 2, FusionTrack achieves 65.3 in HOTA metric on the DanceTrack dataset, which is +11.1 higher than the baseline model MOTR [
11]. More importantly, the association accuracy and IDF1 metric are improved by more than 40%. This suggests that the proposed modules improve the performance of the proposed model by better associating objects with uniform appearance and complex motions. We hope that the proposed modules and design choices can help researchers to develop stronger multi-object tracking models.


 ,
, 









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}