
FMGAN: A Filter-Enhanced MLP Debias Recommendation Model Based on Generative Adversarial Network

Abstract
:1. Introduction
- (1)
- We proposed a filter-enhanced MLP recommendation model based on the Generative Adversarial Network framework to solve the problem of recommendation bias. Through comparisons of two real-world datasets from Movielens and Ciao, we demonstrated the effectiveness of filter-enhanced MLP to improve data partitioning to address recommendation bias and achieve better results compared to baseline models.
- (2)
- We designed three different condition vectors to enhance the learning ability of the model and verified the influence of different condition vectors on the model effect through experimental comparison.
2. Related Work
2.1. Model-Based Collaborative Filtering
2.2. Debias Methods
2.3. Generative Adversarial Network and GAN-Based Recommendation
2.4. Filter-Enhanced Recommendation
2.5. Analytical Summary of the Literature
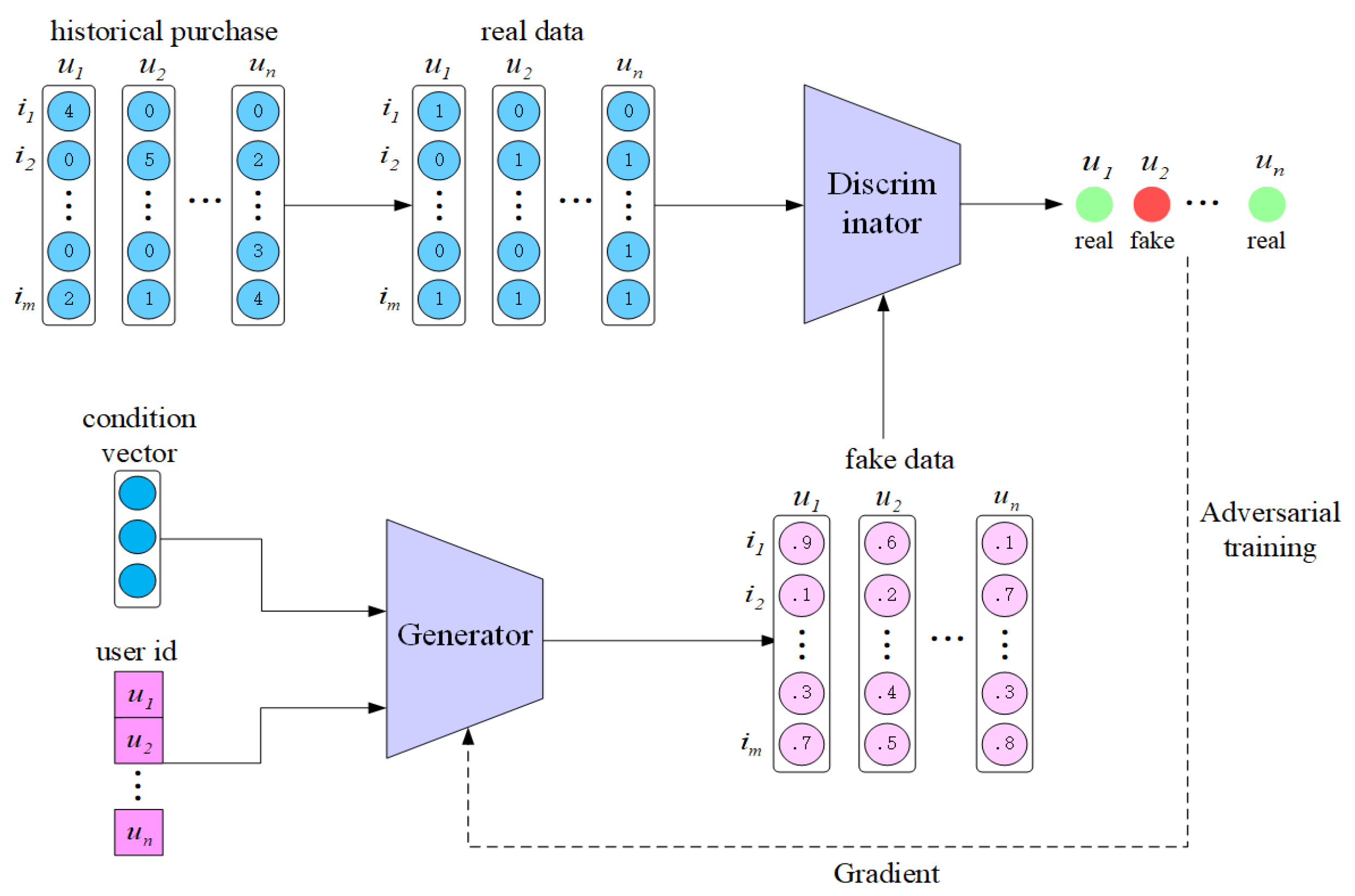
3. Methodology
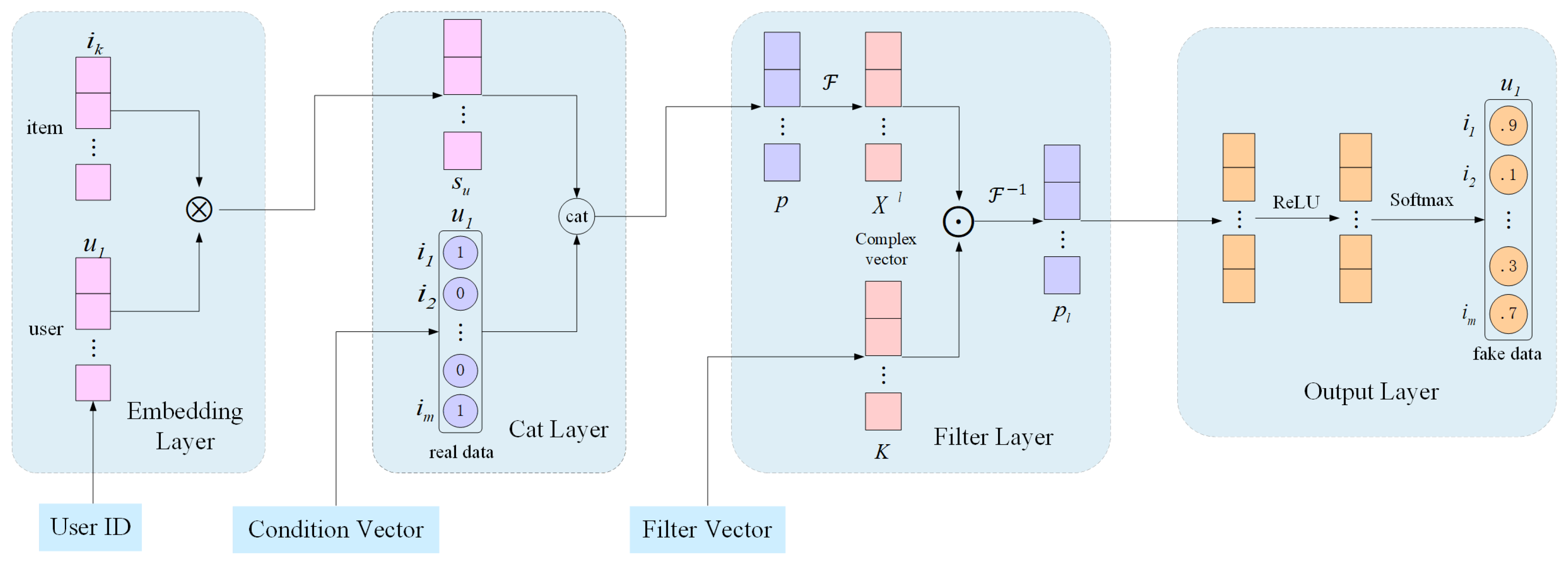
3.1. Generator
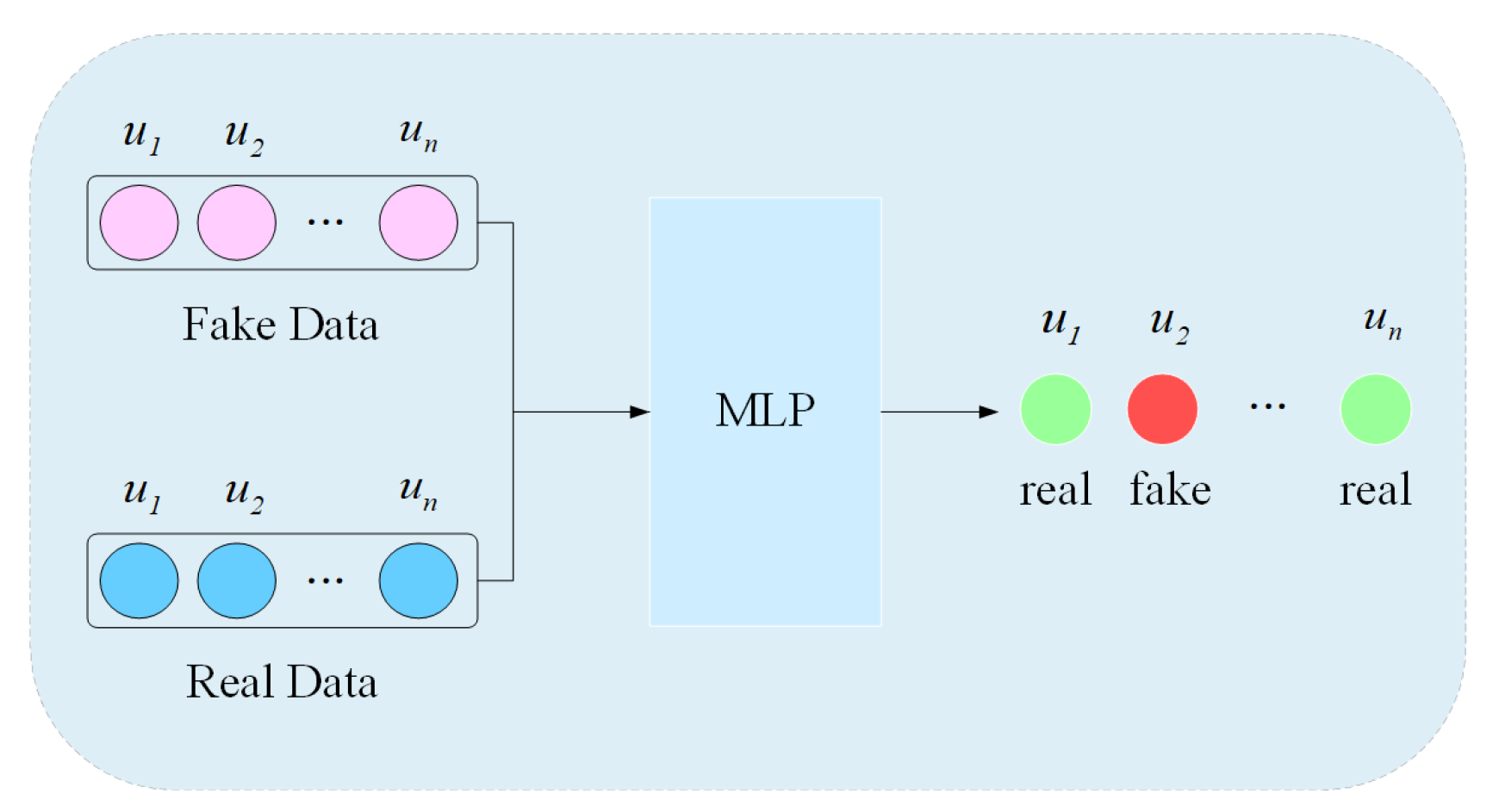
3.2. Discriminator
3.3. Adversarial Training
3.4. FMGAN Recommendation
4. Experiment and Discussion
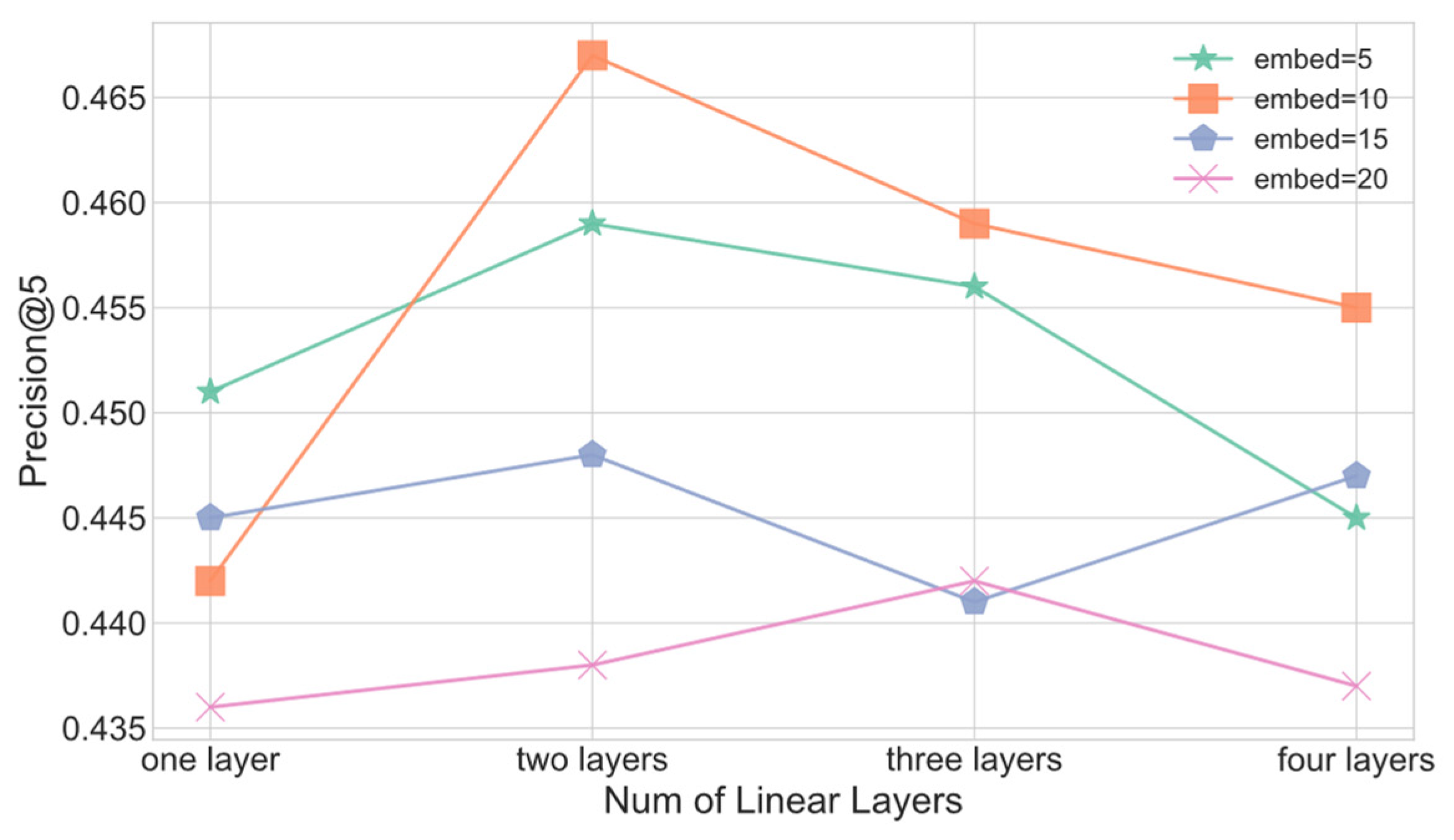
- Effect of embedding dimensions and linear layers.
- Effect of the filter.
- Model performance under different condition vectors.
- Performance comparison of the model with other benchmark models.
4.1. Experiment Setup
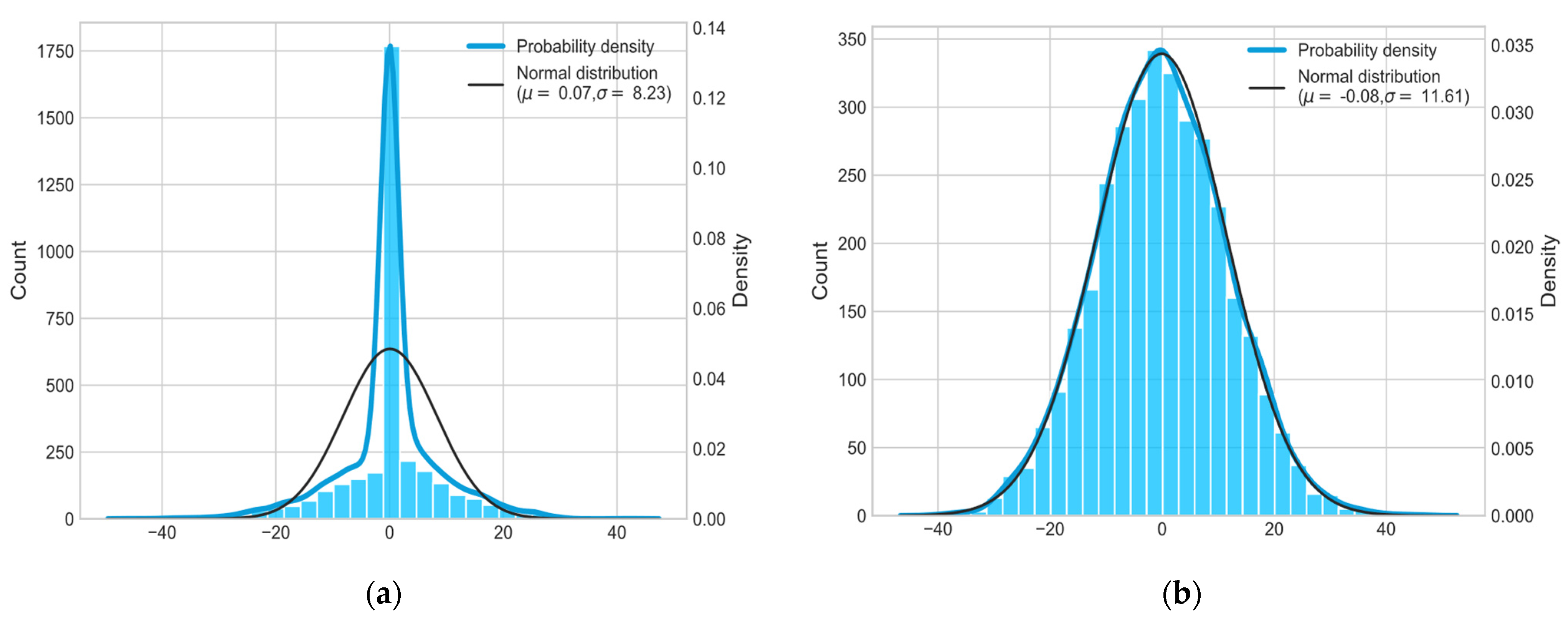
4.1.1. Datasets
4.1.2. Evaluation Metrics
4.1.3. Implementation Details
4.2. Discussion and Results
4.2.1. Effect of Embedding Dimensions and Linear Layers
4.2.2. Effect of the Filter
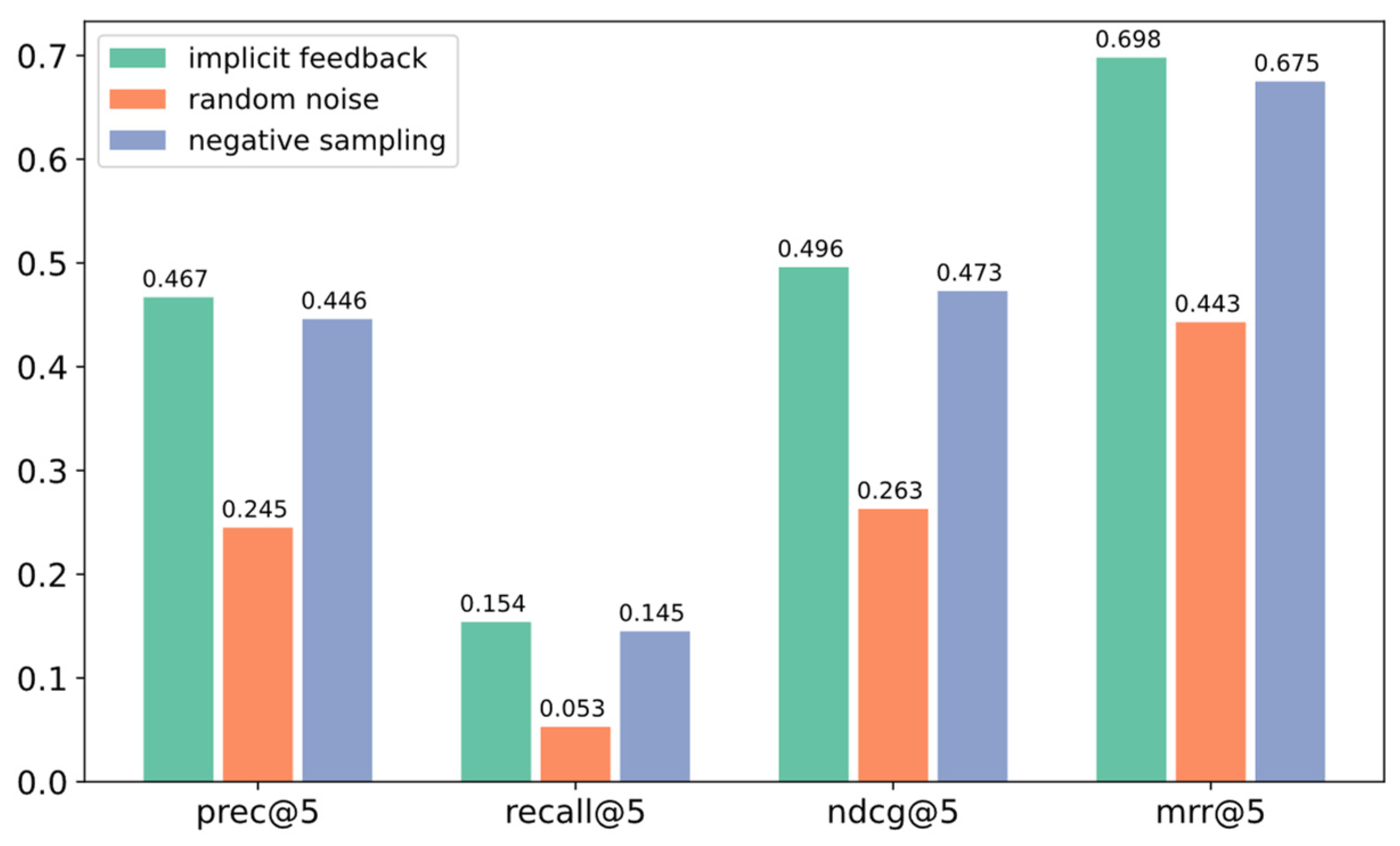
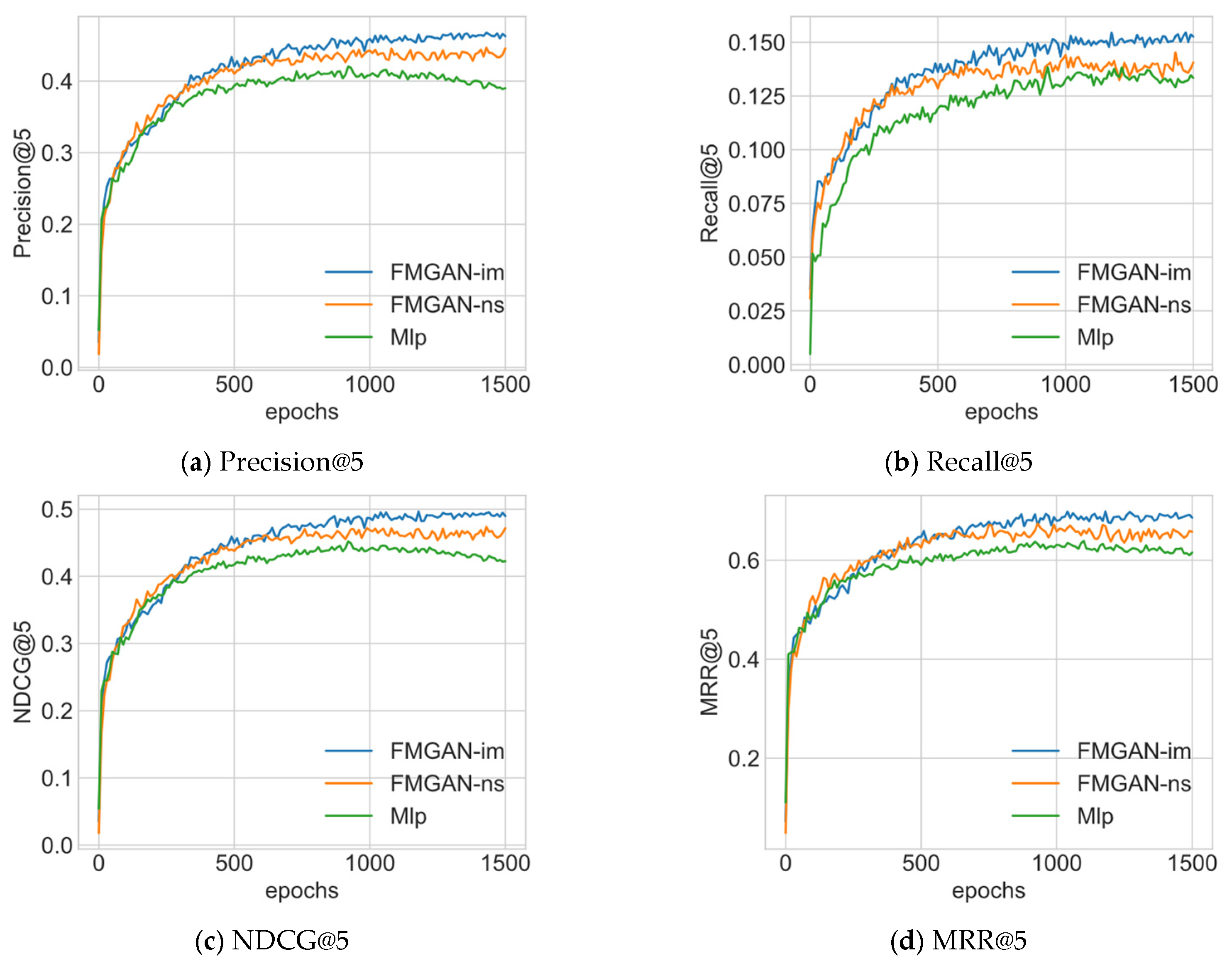
4.2.3. Model Performance under Different Condition Vectors
- ItemPop: A model that uses the most purchase records for recommendation, which is the simplest non-personalized algorithm method.
- BPR: The model pairs purchased items with unpurchased items and optimizes the correct ranking order between item pairs.
- FISM: The model uses two low-latitude latent vectors to simulate the item–item similarity matrix.
- IRGAN: The model applies the GAN architecture to the recommendation system and uses the binary classification loss to train point states or point pairs. This method is specifically introduced in Section 2.2.
- CFGAN: Improves the use of vectors as training parameters and introduces a sampling method to improve the training process. This method is specifically introduced in Section 2.2.
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Burges, C.; Shaked, T.; Renshaw, E.; Lazier, A.; Deeds, M.; Hamilton, N.; Hullender, G. Learning to rank using gradient descent. In Proceedings of the 22nd International Conference on Machine Learning, Bonn, Germany, 7–11 August 2005; pp. 89–96. [Google Scholar]
- Koren, Y.; Bell, R.; Volinsky, C. Matrix factorization techniques for recommender systems. Computer 2009, 42, 30–37. [Google Scholar] [CrossRef]
- Qin, T.; Liu, T.-Y.; Xu, J.; Li, H. LETOR: A benchmark collection for research on learning to rank for information retrieval. Inf. Retr. 2010, 13, 346–374. [Google Scholar] [CrossRef]
- Adomavicius, G.; Tuzhilin, A. Toward the next generation of recommender systems: A survey of the state-of-the-art and possible extensions. IEEE Trans. Knowl. Data Eng. 2005, 17, 734–749. [Google Scholar] [CrossRef]
- Liu, T.-Y. Learning to rank for information retrieval. Found. Trends® Inf. Retr. 2009, 3, 225–331. [Google Scholar] [CrossRef]
- Ekstrand, M.D.; Riedl, J.T.; Konstan, J.A. Collaborative filtering recommender systems. Found. Trends® Hum. Comput. Interact. 2011, 4, 81–173. [Google Scholar] [CrossRef]
- Gao, C.; Wang, X.; He, X.; Li, Y. Graph neural networks for recommender system. In Proceedings of the Fifteenth ACM International Conference on Web Search and Data Mining, Tempe, AZ, USA, 21–25 February 2022; pp. 1623–1625. [Google Scholar]
- Zhao, Z.; Chen, J.; Zhou, S.; He, X.; Cao, X.; Zhang, F.; Wu, W. Popularity Bias Is Not Always Evil: Disentangling Benign and Harmful Bias for Recommendation. arXiv 2021, arXiv:2109.07946. [Google Scholar] [CrossRef]
- Zhou, Y.; Xu, J.; Wu, J.; Taghavi, Z.; Korpeoglu, E.; Achan, K.; He, J. PURE: Positive-Unlabeled Recommendation with Generative Adversarial Network. In Proceedings of the 27th ACM SIGKDD Conference on Knowledge Discovery & Data Mining, Singapore, 14–18 August 2021; pp. 2409–2419. [Google Scholar]
- Schnabel, T.; Swaminathan, A.; Singh, A.; Chandak, N.; Joachims, T. Recommendations as treatments: Debiasing learning and evaluation. In Proceedings of the international conference on machine learning, New York, NY, USA, 19–24 June 2016; pp. 1670–1679. [Google Scholar]
- Park, D.H.; Chang, Y. Adversarial Sampling and Training for Semi-Supervised Information Retrieval. In Proceedings of the World Wide Web Conference, San Francisco, CA, USA, 13 May 2019; pp. 1443–1453. [Google Scholar]
- Zhang, S.; Yao, L.; Sun, A.; Tay, Y. Deep Learning Based Recommender System: A Survey and New Perspectives. ACM Comput. Surv. 2019, 52, 5. [Google Scholar] [CrossRef] [Green Version]
- Ning, X.; Karypis, G. SLIM: Sparse Linear Methods for Top-N Recommender Systems. In Proceedings of the 2011 IEEE 11th International Conference on Data Mining, Washington, DC, USA, 11–14 December 2011; pp. 497–506. [Google Scholar]
- Dervishaj, E.; Cremonesi, P. GAN-based matrix factorization for recommender systems. In Proceedings of the 37th ACM/SIGAPP Symposium on Applied Computing, Virtual Event, 25–29 April 2022; pp. 1373–1381. [Google Scholar]
- Andriy, M.; Salakhutdinov, R.R. Probabilistic Matrix Factorization. Adv. Neural Inf. Process. Syst. 2007, 20, 1257–1264. [Google Scholar]
- Rendle, S.; Freudenthaler, C.; Gantner, Z.; Schmidt-Thieme, L. BPR: Bayesian Personalized Ranking from Implicit Feedback. arXiv 2012, arXiv:1205.2618. [Google Scholar] [CrossRef]
- Kabbur, S.; Ning, X.; Karypis, G. Fism: Factored item similarity models for top-n recommender systems. In Proceedings of the 19th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Chicago, IL, USA, 11–14 August 2013; pp. 659–667. [Google Scholar]
- Xu, J.; He, X.; Li, H. Deep Learning for Matching in Search and Recommendation. In Proceedings of the 41st International ACM SIGIR Conference on Research & Development in Information Retrieval, Ann Arbor, MI, USA, 27 June 2018; pp. 1365–1368. [Google Scholar]
- Sedhain, S.; Menon, A.K.; Sanner, S.; Xie, L. AutoRec. In Proceedings of the 24th International Conference on World Wide Web, Florence, Italy, 18 May 2015; pp. 111–112. [Google Scholar]
- He, X.; Liao, L.; Zhang, H.; Nie, L.; Hu, X.; Chua, T.-S. Neural Collaborative Filtering. In Proceedings of the 26th International Conference on World Wide Web, Perth, Australia, 3–7 April 2017; pp. 173–182. [Google Scholar]
- Nguyen, L.V.; Hong, M.-S.; Jung, J.J.; Sohn, B.-S. Cognitive Similarity-Based Collaborative Filtering Recommendation System. Appl. Sci. 2020, 10, 4183. [Google Scholar] [CrossRef]
- Yang, L.; Cui, Y.; Xuan, Y.; Wang, C.; Belongie, S.; Estrin, D. Unbiased offline recommender evaluation for missing-not-at-random implicit feedback. In Proceedings of the 12th ACM Conference on Recommender Systems, Vancouver, BC, Canada, 2 October 2018; pp. 279–287. [Google Scholar]
- Hu, Y.; Koren, Y.; Volinsky, C. Collaborative Filtering for Implicit Feedback Datasets. In Proceedings of the 2008 Eighth IEEE International Conference on Data Mining, Washington, DC, USA, 15–19 December 2008; pp. 263–272. [Google Scholar]
- Liang, D.; Charlin, L.; McInerney, J.; Blei, D.M. Modeling User Exposure in Recommendation. In Proceedings of the 25th International Conference on World Wide Web, Montréal, QC, Canada, 11–15 May 2016; pp. 951–961. [Google Scholar]
- Arjovsky, M.; Bottou, L.; Gulrajani, I.; Lopez-Paz, D. Invariant risk minimization. arXiv 2019, arXiv:1907.02893. [Google Scholar]
- Wang, Z.; He, Y.; Liu, J.; Zou, W.; Yu, P.S.; Cui, P. Invariant Preference Learning for General Debiasing in Recommendation. In Proceedings of the 28th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, New York, NY, USA, 14–18 August 2022; pp. 1969–1978. [Google Scholar]
- Zhang, A.; Zheng, J.; Wang, X.; Yuan, Y.; Chua, T.-S. Invariant Collaborative Filtering to Popularity Distribution Shift. In Proceedings of the ACM Web Conference 2023, Austin, TX, USA, 30 April–4 May 2023; pp. 1240–1251. [Google Scholar]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative Adversarial Nets. Adv. Neural Inf. Process. Syst. 2014, 27, 2672–2680. [Google Scholar]
- Choi, Y.; Choi, M.; Kim, M.; Ha, J.-W.; Kim, S.; Choo, J. StarGAN: Unified Generative Adversarial Networks for Multi-Domain Image-to-Image Translation. arXiv 2017, arXiv:1711.09020. [Google Scholar] [CrossRef]
- Donahue, C.; McAuley, J.; Puckette, M. Adversarial Audio Synthesis. arXiv 2018, arXiv:1802.04208. [Google Scholar] [CrossRef]
- Yu, L.; Zhang, W.; Wang, J.; Yu, Y. SeqGAN: Sequence Generative Adversarial Nets with Policy Gradient. arXiv 2016, arXiv:1609.05473. [Google Scholar] [CrossRef]
- Wang, J.; Yu, L.; Zhang, W.; Gong, Y.; Xu, Y.; Wang, B.; Zhang, P.; Zhang, D. IRGAN: A Minimax Game for Unifying Generative and Discriminative Information Retrieval Models. In Proceedings of the 40th International ACM SIGIR Conference on Research and Development in Information Retrieval, Tokyo, Japan, 7–11 August 2017; pp. 515–524. [Google Scholar]
- Chae, D.-K.; Kang, J.-S.; Kim, S.-W.; Lee, J.-T. CFGAN: A Generic Collaborative Filtering Framework based on Generative Adversarial Networks. In Proceedings of the 27th ACM International Conference on Information and Knowledge Management, Torino, Italy, 22–26 October 2018; pp. 137–146. [Google Scholar]
- Mirza, M.; Osindero, S. Conditional Generative Adversarial Nets. arXiv 2014, arXiv:1411.1784. [Google Scholar] [CrossRef]
- Li, P.; Wu, Q.; Burges, C. McRank: Learning to Rank Using Multiple Classification and Gradient Boosting. In Proceedings of the NIPS’07: Proceedings of the 20th International Conference on Neural Information Processing Systems, Vancouver, BC, Canada, 3–7 December 2007. [Google Scholar]
- Zhou, K.; Yu, H.; Zhao, W.X.; Wen, J.-R. Filter-enhanced MLP is All You Need for Sequential Recommendation. In Proceedings of the ACM Web Conference 2022, Lyon, France, 25–29 April 2022; pp. 2388–2399. [Google Scholar]
- Tang, J.; Gao, H.; Liu, H. mTrust: Discerning multi-faceted trust in a connected world. In Proceedings of the Fifth ACM International Conference on Web Search and Data Mining, Seattle, WA, USA, 8–12 February 2012; pp. 93–102. [Google Scholar]
- Blair, D.C.; Maron, M.E. An evaluation of retrieval effectiveness for a full-text document-retrieval system. Commun. ACM 1985, 28, 289–299. [Google Scholar] [CrossRef]
- Saracevic, T.; Kantor, P.; Chamis, A.Y.; Trivison, D. A study of information seeking and retrieving. I. Background and methodology. J. Am. Soc. Inf. Sci. 1988, 39, 161–176. [Google Scholar] [CrossRef]
- Järvelin, K.; Kekäläinen, J. Cumulated gain-based evaluation of IR techniques. ACM Trans. Inf. Syst. 2002, 20, 422–446. [Google Scholar] [CrossRef]
- Voorhees, E. The TREC-8 question answering track report. In Proceedings of the Second International Conference on Language Resources and Evaluation (LREC’00), Athens, Greece, 31 May–2 June 2000. [Google Scholar]
- Saito, Y. Asymmetric Tri-training for Debiasing Missing-Not-At-Random Explicit Feedback. In Proceedings of the 43rd International ACM SIGIR Conference on Research and Development in Information Retrieval, Xi’an, China, 25–30 July 2020; pp. 309–318. [Google Scholar]
- Ding, J.; Quan, Y.; He, X.; Li, Y.; Jin, D. Reinforced negative sampling for recommendation with exposure data. In Proceedings of the 28th International Joint Conference on Artificial Intelligence, Macao, China, 10–16 August 2019; pp. 2230–2236. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Statics | Movielens 100K | Movielens 1M | Ciao |
|---|---|---|---|
| users | 943 | 6039 | 996 |
| items | 1682 | 3883 | 1927 |
| ratings | 100,000 | 1,000,209 | 18,648 |
| sparsity | 93.69% | 95.72% | 99.03% |
| FMGAN Model Settings and Hyperparameters | ||||||||
|---|---|---|---|---|---|---|---|---|
| Dataset | lr | Hidden Layers | First Layer Input Size | Activation Function | Second Layer Input Size | Embedding Dimension | Batch Size | |
| Movielens 100K | 0.3 | 1 × 10−4 | 2 | 3306 | ReLU | 1983 | 10 | 64 |
| Movielens 1M | 0.3 | 3 × 10−4 | 2 | 7364 | ReLU | 4418 | 10 | 128 |
| Ciao | 0.3 | 7 × 10−5 | 2 | 2694 | ReLU | 1616 | 10 | 64 |
| Datasets | Model | Prec@5 | Recall@5 | NDCG@5 | MRR@5 |
|---|---|---|---|---|---|
| Movielens 100K | FMGAN-im | 0.467 | 0.154 | 0.496 | 0.698 |
| MLP | 0.421 | 0.139 | 0.449 | 0.657 | |
| Movielens 1M | FMGAN-im | 0.435 | 0.110 | 0.458 | 0.650 |
| MLP | 0.402 | 0.101 | 0.425 | 0.629 | |
| Ciao | FMGAN-im | 0.070 | 0.081 | 0.092 | 0.153 |
| MLP | 0.061 | 0.071 | 0.086 | 0.146 |
| Metrics | P@5 | P@20 | R@5 | R@20 | G@5 | G@20 | M@5 | M@20 |
|---|---|---|---|---|---|---|---|---|
| ItemPop | 0.182 | 0.139 | 0.105 | 0.253 | 0.165 | 0.196 | 0.255 | 0.293 |
| BPR | 0.350 | 0.237 | 0.117 | 0.288 | 0.372 | 0.381 | 0.558 | 0.575 |
| FISM | 0.428 | 0.285 | 0.146 | 0.354 | 0.464 | 0.429 | 0.675 | 0.686 |
| IRGAN | 0.320 | 0.223 | 0.110 | 0.278 | 0.346 | 0.370 | 0.539 | 0.525 |
| CFGAN | 0.445 | 0.327 | 0.149 | 0.360 | 0.477 | 0.440 | 0.682 | 0.701 |
| FMGAN-ns | 0.446 | 0.330 | 0.145 | 0.359 | 0.473 | 0.437 | 0.675 | 0.698 |
| FMGAN-im | 0.467 | 0.340 | 0.154 | 0.365 | 0.496 | 0.454 | 0.698 | 0.719 |
| Metrics | P@5 | P@20 | R@5 | R@20 | G@5 | G@20 | M@5 | M@20 |
|---|---|---|---|---|---|---|---|---|
| ItemPop | 0.155 | 0.120 | 0.075 | 0.195 | 0.153 | 0.179 | 0.251 | 0.296 |
| BPR | 0.340 | 0.251 | 0.075 | 0.207 | 0.347 | 0.361 | 0.535 | 0.554 |
| FISM | 0.419 | 0.304 | 0.106 | 0.269 | 0.442 | 0.398 | 0.635 | 0.649 |
| IRGAN | 0.262 | 0.213 | 0.071 | 0.165 | 0.265 | 0.245 | 0.302 | 0.337 |
| CFGAN | 0.431 | 0.307 | 0.107 | 0.164 | 0.452 | 0.404 | 0.643 | 0.659 |
| FMGAN-ns | 0.433 | 0.308 | 0.106 | 0.162 | 0.451 | 0.402 | 0.641 | 0.654 |
| FMGAN-im | 0.435 | 0.311 | 0.110 | 0.169 | 0.458 | 0.406 | 0.650 | 0.662 |
| Metrics | P@5 | P@20 | R@5 | R@20 | G@5 | G@20 | M@5 | M@20 |
|---|---|---|---|---|---|---|---|---|
| ItemPop | 0.030 | 0.023 | 0.039 | 0.126 | 0.046 | 0.063 | 0.054 | 0.067 |
| BPR | 0.035 | 0.024 | 0.040 | 0.140 | 0.050 | 0.065 | 0.067 | 0.079 |
| FISM | 0.060 | 0.037 | 0.071 | 0.179 | 0.080 | 0.110 | 0.127 | 0.147 |
| IRGAN | 0.034 | 0.022 | 0.042 | 0.110 | 0.045 | 0.065 | 0.080 | 0.087 |
| CFGAN | 0.068 | 0.040 | 0.079 | 0.190 | 0.089 | 0.117 | 0.151 | 0.164 |
| FMGAN-ns | 0.065 | 0.039 | 0.076 | 0.186 | 0.087 | 0.113 | 0.149 | 0.163 |
| FMGAN-im | 0.070 | 0.043 | 0.081 | 0.192 | 0.092 | 0.120 | 0.153 | 0.166 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, Z.; Luo, W. FMGAN: A Filter-Enhanced MLP Debias Recommendation Model Based on Generative Adversarial Network. Appl. Sci. 2023, 13, 7975. https://doi.org/10.3390/app13137975
Liu Z, Luo W. FMGAN: A Filter-Enhanced MLP Debias Recommendation Model Based on Generative Adversarial Network. Applied Sciences. 2023; 13(13):7975. https://doi.org/10.3390/app13137975
Chicago/Turabian StyleLiu, Zhaoxuan, and Wenjie Luo. 2023. "FMGAN: A Filter-Enhanced MLP Debias Recommendation Model Based on Generative Adversarial Network" Applied Sciences 13, no. 13: 7975. https://doi.org/10.3390/app13137975