
CRBF: Cross-Referencing Bloom-Filter-Based Data Integrity Verification Framework for Object-Based Big Data Transfer Systems


Abstract
:1. Introduction
- The proposed framework employs object-, file-, and dataset-level integrity verification, minimizing the data to be retransmitted due to integrity errors.
- We analyzed the memory and false-positive overhead of the proposed framework. We concluded that the proposed framework is effective in eliminating false-positive errors while maintaining a similar memory footprint to the TPBF-based integrity framework.
- In order to evaluate the efficacy of the proposed framework in detecting and recovering from integrity errors, we simulated integrity errors at the object, file, and dataset levels. The experimental results showed that the proposed framework is very accurate at detecting and re-transmitting erroneous objects, files, and datasets.
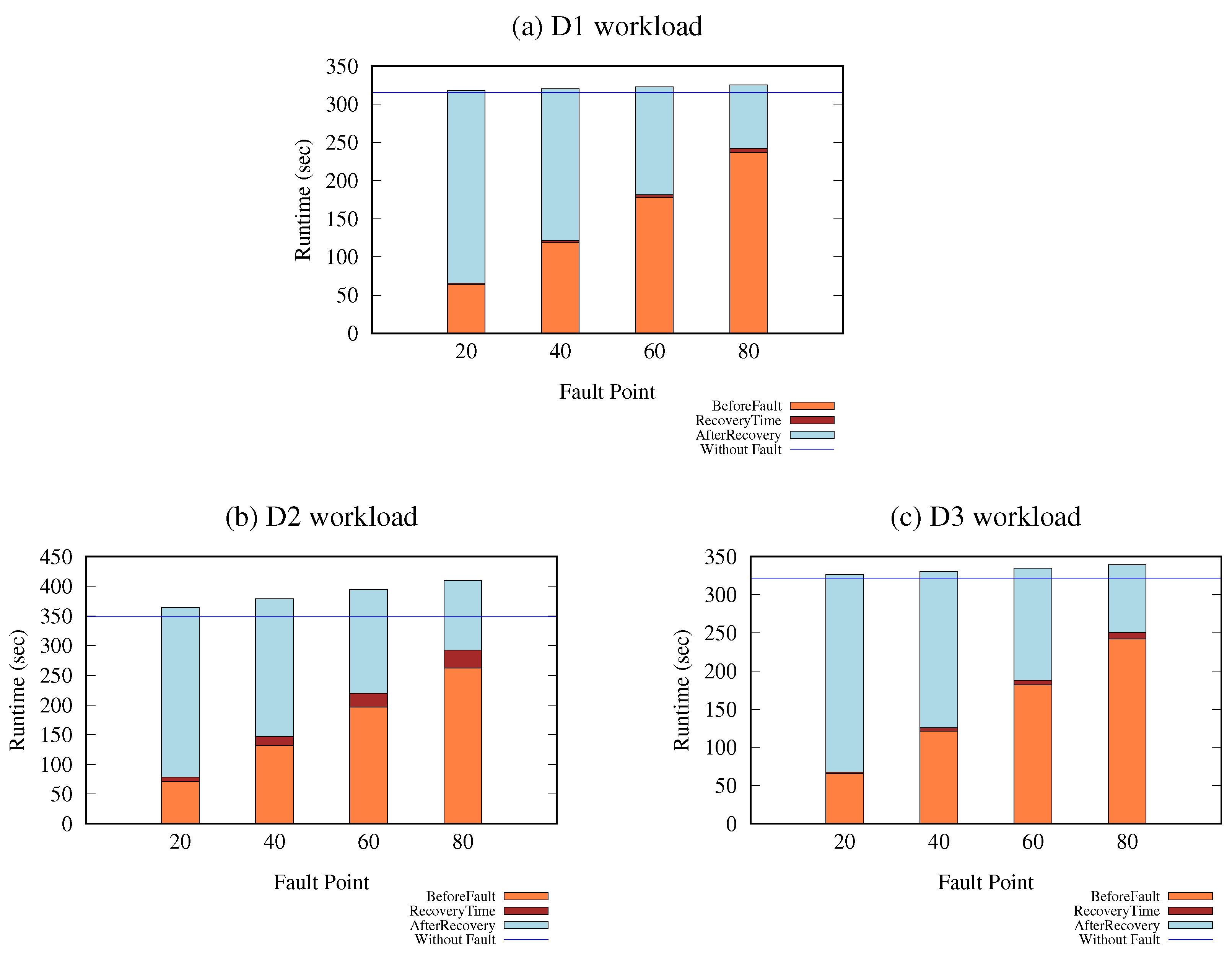
- We simulated faults at different points in the data transmission process to analyze the recovery overhead and false-positive rate of the proposed framework. Faults were simulated after transmitting 20%, 40%, 60%, and 80% of the total data. The experimental findings demonstrated negligible recovery time and zero false positives for all workloads at all fault points.
2. Background and Motivation
2.1. Background
2.1.1. Object-Based Big Data Transfer Systems (OBDTS) and Data Integrity
2.1.2. Bloom Filter Data Structure
- Insert: To insert each object in the set S,
- –
- Compute the hash values , …., for each object . The hash functions can be any hash functions that are collision-resistant.
- –
- Set the corresponding bits in the Bloom filter B such that B[] = B[] = …. = B[] = 1.
Figure 2a depicts the insert operation of object, object, and object. - Query: To determine whether an object, , belongs to set S,
- –
- Compute the hash values , …., for each object .
- –
- If all corresponding bits in the Bloom filter B are set, then membership query is successful; otherwise, the element is not in the set. However, if collisions occur during the hashing process and cause , …., in the bit vector B to be set to 1, this leads to false positives.
- Figure 2b depicts the query operation of object and object. As object was originally inserted into the Bloom filter, its membership query results are positive. In contrast, object was not inserted into the Bloom filter. However, the membership query returns a positive result due to the hash collisions. This approach results in false-positive errors.
2.2. Motivation
3. Related Work
3.1. Performance Optimization of the Bloom Filter
3.2. Data Integrity
4. Data- and Layout-Aware Bloom Filter (DLBF)
- Insert Operation: Calculate the hash values , …., for each object and set the corresponding hashed bits, along with the object layout bit, in the Bloom filter B, such that B[i] = B[] = B[] = …. = B[] = 1.
- Query Operation: To test object membership, compute the hash values , …., for each object and check the corresponding hashed bits along with the object layout bit in the Bloom filter B are set to 1 or not. If all of B[i] = B[] = B[] = …. = B[] = 1 are 1, then membership query is successful; otherwise, the element is not in the set.
5. Cross-Referencing Bloom-Filter-Based Data Integrity Framework
5.1. System Architecture
- Data- and Layout-Aware Bloom filter (DLBF): This Bloom filter [28] data structure stores the successfully transferred object information of an active file. The number of active files and active DLBFs depends on the number of I/O threads. As described in Section 4, DLBF is a modified data structure designed to prevent false positives of the standard Bloom filter. It consists of two segments: the layout and the Bloom filter, as shown in Figure 5. After a successful object transfer and subsequent integrity verification, the object layout bit (located in the layout segment) and k hashed bit positions, computed based on the object signature, are set to 1 in the DLBF. However, if the object fails the integrity verification, the file handler reschedules the object for retransfer. This process will be continued until all file objects have been successfully transferred without any errors.During data transfer, if there is a fault and if the data transfer is resumed from a fault point, the proposed data integrity framework retrieves successfully transferred objects by querying the DLBF. Owing to the layout-aware nature of the data structure, the DLBF produces no false positives. Furthermore, dynamic changes to the objects and files can be detected using this data structure.
- Dataset Bloom Filter (DSBF): This Bloom filter data structure maintains information regarding successfully transferred files. Upon transferring all file objects, a file signature is computed using the DLBF. If the file signature at both ends of the data transfer is the same, file-level integrity verification succeeds, and the k hashed bit positions computed on the file signature are set to 1 in the DSBF. If the file-level integrity verification fails, then the file handler schedules all objects of that file for retransfer. The process of transferring files is continued until all files in the dataset have been transferred successfully and without any errors.If a fault occurs and the transfer resumes from the fault point, the DSBF is used to retrieve successfully transferred files. However, because Bloom filters are probabilistic in nature, there is a chance of false positives. To efficiently detect the false-positive errors of the DSBF, metadata Bloom filters (MDBF) at both ends of the data transfer are used as cross-referencing Bloom filters. If both the cross-referencing Bloom filters produce positive results, then the positive result of DSBF is considered as positive. Conversely, if any of the cross-referencing Bloom filters produces a negative result, then the positive result of DSBF is considered as negative.
- Metadata Bloom Filter (MDBF): This Bloom filter stores the metadata of files that have been successfully transferred. File metadata in the following format is used at both ends of the data transfer.
- Upon successful file-level integrity verification, both ends of the data transfer update MDBF with the k hashed bit positions computed on the file metadata. This Bloom filter acts as a cross-referencing Bloom filter for the DSBF to minimize false-positive errors while recovering from a fault.
- Figure 5 depicts the MDBF aggregation mechanism. As indicated in the figure, on a successful file transfer, both the source and sink endpoints use file metadata to aggregate the MDBF. At the sink end, the file metadata are transformed using 1’s complement and are hashed using a different set of hash functions. Thus, the resulting MDBF at both ends has an entirely different bit vector for the same input data. A lower false-positive rate than that of the standard Bloom filter can be achieved using these independent MDBFs at the source and sink endpoints. Therefore, in the proposed design, we used MDBFs as cross-referencing Bloom filters to validate the positive results of the DSBF.
5.2. Implementation Details
| Listing 1. Communication message type. |
|
enum message { MSG_CONNECT = 0, //Initial connect request MSG_SUCCESS, //Successful connection MSG_NEWFILE, //Send new file MSG_FILEID, //Create fileid at sink. MSG_NEWOBJ, //Send new object MSG_OBJSYNC, //Receive object sync MSG_FILECLOSE, //Send file close MSG_FILECHECK, //Cross-check MDBF MSG_CHECKRSP, //MDBF response MSG_DISCONNECT //Ready to disconnect } msg_type_t; |
- The source initiates a connection to the sink by sending aMSG_CONNECT request. Upon successful connection, the sink responds with a MSG_SUCCESS message.
- The source creates a list of files that need to be transferred.
- If the transfer is resumed from a failed transfer, then go to Step 12.
- For each file, the source end sends a MSG_NEWFILE request to the sink end. The request message contains file metadata information. The sink end opens the file specified in the request message and responds with a MSG_FILEID message. The response message includes the file descriptor used in the sink end.
- The source queries the DLBF to see if the object has already been transferred. If it has not, the source initiates the object transfer by sending a MSG_NEWOBJ request to the sink. Upon receiving the data, the sink writes the object data to the PFS. Once the object has been successfully written, the sink computes the block hash and compares it to the hash that was received in the MSG_NEWOBJ request. If the hashes match, the sink responds with a MSG_OBJSYNC message.
- If the object integrity verification is successful, the file-based DLBF is aggregated at both the source and sink endpoints. However, if the verification fails, the source endpoint marks the object as failed and schedules it for re-transfer.
- Steps 5 and 6 are repeated for all file objects.
- Upon receiving all objects of a file, the sink endpoint validates the integrity of the file by comparing the computed file hash with the file hash received from the source endpoint. If the hashes match, the sink endpoint acknowledges the completion of the file transfer by sending a MSG_FILECLOSE message.
- If the file integrity verification is successful, both the dataset Bloom filter (DSBF) and the metadata Bloom filter (MDBF) at both ends of the data transfer are aggregated with the file information. However, if the file integrity verification fails, the source endpoint schedules a re-transfer of the file.
- For each file in the dataset, Steps 3 to 9 are repeated.
- After transferring all files in the dataset, the source endpoint performs a dataset integrity verification. If the verification is successful, it sends a MSG_DISCONNECT message to the sink endpoint. However, if the verification fails, the source endpoint repeats Steps 2 to 11.
- For each file, the source endpoint queries the DSBF to check whether the file is already transferred and whether the file integrity is maintained.
- If the DSBF query result is negative, then go to Step 4.
- If the DSBF query result is positive, the source endpoint issues a FILE_CHECK request with the file metadata. The sink endpoint queries the sink-end MDBF and responds with CHECK_RSP by including the MDBF query result.
- If the sink-end MDBF query result is positive, the source endpoint queries the source-end MDBF. If the result is positive, the file is considered successfully transferred and skipped from the transfer. Otherwise, go to Step 4.
5.3. Memory Overhead Analysis
5.3.1. Memory Requirements of a Standard Bloom-Filter-Based Data Integrity Solution
5.3.2. Memory Requirements of CRBF-Based Data Integrity Solution
5.4. False-Positive Rate Analysis
5.4.1. False-Positive Rate Analysis of Data Integrity Solution Based on the Standard Bloom Filter
5.4.2. False-Positive Rate Analysis of Data Integrity Solution Based on the CRBF
6. Evaluation
6.1. Test Environment
6.1.1. Testbed Specification
6.1.2. Workload Specification
6.2. Performance Evaluation
6.2.1. Data Transfer Rate
6.2.2. CPU Load Analysis
6.2.3. Memory Load Analysis
6.2.4. Recovery Overhead and False-Positive Error Analysis
7. Conclusions
8. Future Work
Author Contributions
Funding
Conflicts of Interest
Abbreviations
| CRBF | Cross-Referencing Bloom Filter |
| PFS | Parallel File System |
| LADS | Layout-Aware Data Scheduling |
| OST | Object Storage Target |
| OSS | Object Storage Server |
| OBDTS | Object-based Big Data Transfer Systems |
| TPBF | Two-Phase Bloom Filter |
| DLBF | Data- and Layout-Aware Bloom Filter |
| DSBF | Dataset Bloom Filter |
| MDBF | Metadata Bloom Filter |
| OLCF | Oak Ridge Leadership Computing Facility |
References
- CERN. Available online: https://home.cern/ (accessed on 20 March 2023).
- LIGO. Available online: https://www.ligo.caltech.edu/ (accessed on 20 April 2023).
- ORNL. Available online: https://www.ornl.gov/ (accessed on 20 April 2023).
- Matsunaga, H.; Isobe, T.; Mashimo, T.; Sakamoto, H.; Ueda, I. Data transfer over the wide area network with a large round trip time. J. Phys. Conf. Ser. 2010, 219, 062056. [Google Scholar] [CrossRef]
- Carns, P.H.; Ligon, W.B., III; Ross, R.B.; Thakur, R. PVFS: A Parallel File System for Linux Clusters. In Proceedings of the 4th Annual Linux Showcase & Conference (ALS 2000), Atlanta, GA, USA, 10–14 October 2000. [Google Scholar]
- Enhancing Scalability and Performance of Parallel File Systems. Available online: https://www.intel.com/content/dam/www/public/us/en/documents/white-papers/enhancing-scalability-and-performance-white-paper.pdf (accessed on 25 February 2022).
- Kim, Y.; Atchley, S.; Vallée, G.R.; Shipman, G.M. LADS: Optimizing Data Transfers using Layout-Aware Data Scheduling. In Proceedings of the 13th USENIX Conference on File and Storage Technologies, FAST ’15, Berkeley, CA, USA, 16–19 February 2015. [Google Scholar]
- Kim, Y.; Atchley, S.; Vallee, G.R.; Shipman, G.M. Layout-aware I/O Scheduling for terabits data movement. In Proceedings of the 2013 IEEE International Conference on Big Data, Santa Clara, CA, USA, 6–9 October 2013; pp. 44–51. [Google Scholar] [CrossRef]
- Kim, Y.; Atchley, S.; Vallee, G.R.; Lee, S.; Shipman, G.M. Optimizing End-to-End Big Data Transfers over Terabits Network Infrastructure. IEEE Trans. Parallel Distrib. Syst. 2017, 28, 188–201. [Google Scholar] [CrossRef]
- Kasu, P.; Kim, T.; Um, J.; Park, K.; Atchley, S.; Kim, Y. FTLADS: Object-Logging Based Fault-Tolerant Big Data Transfer System Using Layout Aware Data Scheduling. IEEE Access 2019, 7, 37448–37462. [Google Scholar] [CrossRef]
- Alliance, G. The Globus Toolkit. Available online: http://http://www.globus.org/toolkit/ (accessed on 23 April 2022).
- Allen, B.; Bresnahan, J.; Childers, L.; Foster, I.; Kandaswamy, G.; Kettimuthu, R.; Kordas, J.; Link, M.; Martin, S.; Pickett, K.; et al. Software as a Service for Data Scientists. Commun. ACM 2012, 55, 81–88. [Google Scholar] [CrossRef] [Green Version]
- Hanushevsky, A. BBCP. Available online: http://www.slac.stanford.edu/~abh/bbcp/ (accessed on 23 April 2022).
- File Integrity Testing. Available online: https://www.gridpp.ac.uk/wiki/File_Integrity_Testing/ (accessed on 23 April 2022).
- Stone, J.; Partridge, C. When the CRC and TCP checksum disagree. ACM SIGCOMM Comput. Commun. Rev. 2001, 30, 309–319. [Google Scholar] [CrossRef]
- Kettimuthu, R.; Liu, Z.; Wheeler, D.; Foster, I.; Heitmann, K.; Cappello, F. Transferring a petabyte in a day. Future Gener. Comput. Syst. 2018, 88, 191–198. [Google Scholar] [CrossRef]
- Kasu, P.; Hamandawana, P.; Chung, T.S. TPBF: Two-Phase Bloom-Filter-Based End-to-End Data Integrity Verification Framework for Object-Based Big Data Transfer Systems. Mathematics 2022, 10, 1591. [Google Scholar] [CrossRef]
- Bloom, B.H. Space/Time Trade-Offs in Hash Coding with Allowable Errors. Commun. ACM 1970, 13, 422–426. [Google Scholar] [CrossRef]
- Putze, F.; Sanders, P.; Singler, J. Cache-, Hash- and Space-Efficient Bloom Filters. In Experimental Algorithms, Proceedings of the 6th International Workshop, WEA 2007, Rome, Italy, 6–8 June 2007; Springer: Berlin/Heidelberg, Germany, 2007; pp. 108–121. [Google Scholar]
- Broder, A.; Mitzenmacher, M. Survey: Network Applications of Bloom Filters: A Survey. Internet Math. 2003, 1, 485–509. [Google Scholar] [CrossRef] [Green Version]
- Bloom Filter. Available online: https://en.wikipedia.org/wiki/Bloom_filter (accessed on 20 April 2023).
- Lim, H.; Lee, N.; Lee, J.; Yim, C. Reducing False Positives of a Bloom Filter using Cross-Checking Bloom Filters. Appl. Math. Inf. Sci. 2014, 8, 1865–1877. [Google Scholar] [CrossRef]
- Luo, L.; Guo, D.; Ma, R.T.B.; Rottenstreich, O.; Luo, X. Optimizing Bloom Filter: Challenges, Solutions, and Comparisons. IEEE Commun. Surv. Tutor. 2019, 21, 1912–1949. [Google Scholar] [CrossRef] [Green Version]
- Kiss, S.Z.; Hosszu, E.; Tapolcai, J.; Ronyai, L.; Rottenstreich, O. Bloom Filter With a False Positive Free Zone. IEEE Trans. Netw. Serv. Manag. 2021, 18, 2334–2349. [Google Scholar] [CrossRef]
- Rottenstreich, O.; Reviriego, P.; Porat, E.; Muthukrishnan, S. Constructions and Applications for Accurate Counting of the Bloom Filter False Positive Free Zone. In Proceedings of the SOSR ’20, New York, NY, USA, 3 March 2020; pp. 135–145. [Google Scholar] [CrossRef] [Green Version]
- Nayak, S.; Patgiri, R. countBF: A General-purpose High Accuracy and Space Efficient Counting Bloom Filter. In Proceedings of the 2021 17th International Conference on Network and Service Management (CNSM), Virtual, 25–29 October 2021; pp. 355–359. [Google Scholar] [CrossRef]
- Tabataba, F.S.; Hashemi, M.R. Improving false positive in Bloom filter. In Proceedings of the 2011 19th Iranian Conference on Electrical Engineering, Tehran, Iran, 17–19 May 2011; pp. 1–5. [Google Scholar]
- Kasu, P.; Hamandawana, P.; Chung, T.S. DLFT: Data and Layout Aware Fault Tolerance Framework for Big Data Transfer Systems. IEEE Access 2021, 9, 22939–22954. [Google Scholar] [CrossRef]
- Sivathanu, G.; Wright, C.P.; Zadok, E. Ensuring Data Integrity in Storage: Techniques and Applications. In Proceedings of the 2005 ACM Workshop on Storage Security and Survivability, StorageSS ’05, Fairfax, VA, USA, 11 November 2005; pp. 26–36. [Google Scholar] [CrossRef]
- Zhang, Y.; Myers, D.S.; Arpaci-Dusseau, A.C.; Arpaci-Dusseau, R.H. Zettabyte reliability with flexible end-to-end data integrity. In Proceedings of the 2013 IEEE 29th Symposium on Mass Storage Systems and Technologies (MSST), Long Beach, CA, USA, 6–10 May 2013; pp. 1–14. [Google Scholar] [CrossRef] [Green Version]
- Reyes-Anastacio, H.G.; Gonzalez-Compean, J.; Morales-Sandoval, M.; Carretero, J. A data integrity verification service for cloud storage based on building blocks. In Proceedings of the 2018 8th International Conference on Computer Science and Information Technology (CSIT), Amman, Jordan, 11–12 July 2018; pp. 201–206. [Google Scholar] [CrossRef]
- Luo, W.; Bai, G. Ensuring the data integrity in cloud data storage. In Proceedings of the 2011 IEEE International Conference on Cloud Computing and Intelligence Systems, Beijing, China, 15–17 September 2011; pp. 240–243. [Google Scholar] [CrossRef]
- Zhang, Y.; Rajimwale, A.; Arpaci-Dusseau, A.C.; Arpaci-Dusseau, R.H. End-to-end Data Integrity for File Systems: A ZFS Case Study. In Proceedings of the 8th USENIX Conference on File and Storage Technologies (FAST 10), San Jose, CA, USA, 23–26 February 2010. [Google Scholar]
- Lustre, ZFS, and Data Integrity. Available online: https://wiki.lustre.org/images/0/00/Tuesday_shpc-2009-zfs.pdf (accessed on 25 February 2022).
- Jung, E.S.; LIU, S.; Kettimuthu, R.; CHUNG, S. High-Performance End-to-End Integrity Verification on Big Data Transfer. IEICE Trans. Inf. Syst. 2019, E102.D, 1478–1488. [Google Scholar] [CrossRef] [Green Version]
- Liu, S.; Jung, E.S.; Kettimuthu, R.; Sun, X.H.; Papka, M. Towards optimizing large-scale data transfers with end-to-end integrity verification. In Proceedings of the 2016 IEEE International Conference on Big Data (Big Data), Washington, DC, USA, 5–8 December 2016; pp. 3002–3007. [Google Scholar] [CrossRef]
- Arslan, E.; Alhussen, A. A Low-Overhead Integrity Verification for Big Data Transfers. In Proceedings of the 2018 IEEE International Conference on Big Data (Big Data), Seattle, WA, USA, 10–13 December 2018; pp. 4227–4236. [Google Scholar] [CrossRef]
- Xiong, S.; Wang, F.; Cao, Q. A Bloom Filter Based Scalable Data Integrity Check Tool for Large-Scale Dataset. In Proceedings of the 1st Joint International Workshop on Parallel Data Storage & Data Intensive Scalable Computing Systems, PDSW-DISCS ’16, Salt Lake, UT, USA, 14 November 2016; pp. 55–60. [Google Scholar]
- Yildirim, E.; Arslan, E.; Kim, J.; Kosar, T. Application-Level Optimization of Big Data Transfers through Pipelining, Parallelism and Concurrency. IEEE Trans. Cloud Comput. 2016, 4, 63–75. [Google Scholar] [CrossRef] [Green Version]
- Mitzenmacher, M. Compressed Bloom filters. IEEE/ACM Trans. Netw. 2002, 10, 604–612. [Google Scholar] [CrossRef]
- George, A.; Mohr, R.; Simmons, J.; Oral, S. Understanding Lustre Internals, 2nd ed.; Oak Ridge National Lab. (ORNL): Oak Ridge, TN, USA, 2021. [Google Scholar] [CrossRef]
- Lustre File System. Available online: https://docs.csc.fi/computing/lustre/ (accessed on 20 December 2022).
- Atlas. Available online: https://github.com/ORNL-TechInt/Atlas_File_Size_Data (accessed on 20 April 2023).
- Kirsch, A.; Mitzenmacher, M. Less Hashing, Same Performance: Building a Better Bloom Filter. Random Struct. Algorithms 2008, 33, 187–218. [Google Scholar] [CrossRef] [Green Version]
- Lu, J.; Yang, T.; Wang, Y.; Dai, H.; Jin, L.; Song, H.; Liu, B. One-hashing bloom filter. In Proceedings of the 2015 IEEE 23rd International Symposium on Quality of Service (IWQoS), Portland, OR, USA, 15–16 June 2015; pp. 289–298. [Google Scholar]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Feature | Sequential Transfer | Object-Based Transfer |
|---|---|---|
| Data transfer order | Sequential | Out of order |
| Data integrity verification | Simple checksum aggregation | Complex sorting algorithms |
| Memory requirements | Low | High |
| Computational requirements | Low | High |
| Files in the dataset | N |
| Objects per file | S |
| Total objects in the dataset | (N × S) |
| Total elements in DLBF | (C × S) |
| Total elements in DSBF | N |
| Total elements in MDBF | N |
| Dataset | No. of Files | File Size Range |
|---|---|---|
| D1 (Big workload) | 100 | 1 GB∼2 GB |
| D2 (Small workload) | 100,000 | 1 KB∼1 MB |
| D3 (Mixed workload) | 20,050 * | 1 KB∼2 GB |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kasu, P.; Hamandawana, P.; Chung, T.-S. CRBF: Cross-Referencing Bloom-Filter-Based Data Integrity Verification Framework for Object-Based Big Data Transfer Systems. Appl. Sci. 2023, 13, 7830. https://doi.org/10.3390/app13137830
Kasu P, Hamandawana P, Chung T-S. CRBF: Cross-Referencing Bloom-Filter-Based Data Integrity Verification Framework for Object-Based Big Data Transfer Systems. Applied Sciences. 2023; 13(13):7830. https://doi.org/10.3390/app13137830
Chicago/Turabian StyleKasu, Preethika, Prince Hamandawana, and Tae-Sun Chung. 2023. "CRBF: Cross-Referencing Bloom-Filter-Based Data Integrity Verification Framework for Object-Based Big Data Transfer Systems" Applied Sciences 13, no. 13: 7830. https://doi.org/10.3390/app13137830