1. Introduction
In order to facilitate various aspects of everyday life, modern applications or devices often have to solve the problems of Multi-Label Classification (MLC). Classification of texts to the most relevant categories [
1,
2,
3,
4,
5,
6], finding types of objects that appear on a given image [
7,
8,
9,
10,
11], or recognizing multiple sources of sounds heard in sound samples [
12,
13,
14,
15,
16] are examples of MLCs from various domains. Classification is always a transition from objects (e.g., text documents, images, or sound samples) to labels (document categories, types of objects in images, sound sources). In the task of MLC, an object should be assigned to a subset of the most appropriate labels out of a predefined set of all available labels. In contrast to single-label classification, where only one (the most appropriate label) is expected, in MLC, the returned subset of labels can have arbitrary sizes, which should depend on the objects to classify. For example, a text document can belong to a couple of relevant categories, a single image can contain many objects, and a sound can be a mix of acoustic waves from various sources.
A typical classification system, while calculating its output (subset of labels) for a given input, internally operates in continuous latent space and provides a certain floating point value—a
score—for all (or the most promising) labels. The higher the label score, the more appropriate this label is for a given input, according to the classifier. In order to return a set of labels, the classifier must make final decisions about the prediction of labels, basing them on these per-label scores. This stage of making ultimate predictions based on scores is called
thresholding. All classifiers, implicitly (e.g., [
10,
11]) or explicitly (e.g., [
17,
18,
19,
20,
21]) have to use some form of thresholding of the calculated per-label scores to obtain the final bipartition of the set of all available labels into subsets of relevant and irrelevant ones. The thresholding phase is typically meant to be as simple as taking labels, where scores exceed a suitably chosen
threshold value (e.g., it can be 0.5 if the scores have a probabilistic interpretation, see, e.g., [
20,
21]). Thresholding can also be more complex (see
Section 3.1), which can lead to overall better label predictions.
When there are thousands or even millions of available labels to choose from, the task is known as eXtreme Multi-Label Classification (XMLC) [
22]. Such a large number of labels in XMLC makes it a suitable framework for analyzing and even solving other problems closely related to classification, such as recommendation, tagging, and ranking [
23,
24,
25,
26]. These are the prevailing applications and use cases of extreme multi-label classifiers. In the ranking, recommendation, and most tagging applications, we care about the top
k outputs of the system, such as the
k-most appropriate adverts,
k-most relevant search engine results, or
k-top-scoring topics describing a given post or tweet (not necessarily the whole subset of relevant tags). In the literature on XMLC (e.g., [
25,
26,
27,
28,
29,
30,
31]), the quality of extreme multi-label classifiers is evaluated based on label lists sorted in descending order, according to their real-valued scores calculated by the classifier. The XMLC repository (
http://manikvarma.org/downloads/XC/XMLRepository.html, accessed on 26 May 2023) curates benchmark results of many extreme multi-label classifiers on a collection of datasets using the following metrics: precision at
k (P@
k), propensity scored precision at
k (PSP@
k), discounted cumulative gain at
k (DCG@
k), normalized discounted cumulative gain at
k (nDCG@
k), etc. The
k values for which performances are reported are as follows: 1, 3, and 5 (e.g., P@1, PSP@3, nDCG@5). The important thing to notice here is that all these metrics are
ranking quality metrics, not
classification quality metrics, e.g., F1 score [
1,
32]. There are a couple of reasons for the choice of ranking-based metrics over classification-based metrics in XMLC [
24]. In addition to the aforementioned typical applications of extreme classifiers (recommendation systems), there is also the inevitable problem of missing labels in ground truth predictions in the presence of millions of labels, which makes the ground truth in XMLC less trustworthy than in other tasks; the difference in relevance between true positive prediction (especially for rare labels) and true negative prediction (most of the labels should not be assigned to a given input); and the high imbalance in label sizes. Typically, there are some labels with thousands of training examples, but also thousands of
tail labels, i.e., labels that are very rare (e.g., in a Wikipedia dataset, there are thousands of categories that contain less than five articles each). Considering all these factors, the use of ranking-based benchmarks for evaluating ranking or recommendation systems is the most appropriate and valid approach.
However, when evaluating classification systems based on ranking metrics, the quality assessment of a crucial step of every proper classifier, i.e., the
thresholding phase, is missed. In particular, for multi-label classification tasks, thresholding strategies are shown to be highly impactful on the evaluation of classifications in terms of proper classification metrics, such as the F1 score (see, e.g., [
18,
19,
32]). For applications, where it is useful to obtain a subset of labels, instead of a fixed-sized list of the most promising labels, i.e., for middle-sized or large proper classification tasks (but not for XMLC with unreliable ground truth), it is, therefore, crucially important to experiment with thresholding methods and measure the results using proper classification metrics. The thresholding methods can work on top of scores obtained from extensively researched XMLC classifiers.
This is the main motivation behind this paper, where we focused on experimenting with advanced thresholding strategies based on label scores already calculated with the use of XMLC classifiers and in isolation from ideas behind the scoring algorithms. Our contribution is as follows:
We designed novel, neural network-based thresholding models, called ThresNets, which, in terms of classification metrics, and as shown in experiments on synthetic and real datasets, are preferable compared to traditional thresholding methods. The models achieve this in a linear space complexity with respect to the number of labels. One of the proposed architectural variants of ThresNets is suitable to be initialized using threshold values obtained from traditional methods. This allows for knowledge transfer between the two methods. The independence of the method from the source of label scores is demonstrated by its positive results when applied to scores from both tested third-party scorers. A hybrid approach that combines neural and traditional thresholding strategies offers the best performance as measured by the macro-averaged F-measure metric on the tested real datasets.
We draw a connection between classic thresholding techniques and neural network models by showing that our method can be seen as a neural implementation and a generalized version of traditional per-label optimized thresholding.
This generalized thresholding method bases the final prediction for a given label on the score for that label as well as on all of the scores in a score vector, enabling it to the previously unseen ability to recover the classification system from mis-scoring situations. This ability is showcased for some concrete examples on real datasets. It was also empirically measured on artificially created multi-label score datasets created with the use of a simple generator coupled with a controlled scoring corruption module.
The rest of the paper is structured as follows. The next section describes the formal specification of the problem. Thresholding strategies and related methods are presented in
Section 3.
Section 4 presents our proposition, which is then evaluated in
Section 5. Moreover, the quantitative results section contains examples of difficult, yet successful, predictions, which our method enables. The final section concludes the paper.
4. Neural Network Models for Thresholding Prediction Scores
4.1. From Classic Strategies to Neural Networks
S-cut and CS-cut strategies (as well as their scaled counterparts) can be easily implemented as very simple, one-layered neural networks (see
Figure 1a).
Typically, a
dense neural layer performs the following calculation:
where
is a weight matrix,
is a
bias vector (both are trainable parameters of the layer), and
is a nonlinear activation function. Setting the
Heaviside step function
as
, forcing
to be the identity matrix, and
, i.e., setting the bias vector to the negative threshold vector of the CS-cut strategy, and feeding the net with score vectors
(or
ss), we have the following:
where
which is exactly equivalent to the CS-cut strategy, from Formula (
7). We call this architecture
CS-Net. If
t is further forced to share one (and the same) value for all
L positions, then such a restricted neural network realizes the S-cut strategy. With sorted scores at the input, one can even turn this model into R-cut or DS-cut thresholding equivalents.
The benefit of formulating thresholding strategies in neural network terms comes when the normal neural connections of a dense layer are retained.
Figure 1b shows a natural generalization of the previous model, i.e., a fully connected neural network layer that maps score vectors to prediction vectors. This model conditions its decision about the
i-th label prediction, not only on the
i-th score value but on
all values in the score vector, via a dense weight matrix
.
The problem with such a natural generalization is the O(
) space complexity of this model. For very large number of labels, such a naive model is infeasible. One possible solution to this problem is to add a hidden layer of
h neurons, where
, reducing the space complexity to O(
). Another possibility would be to apply sparse weight matrices, such as in [
42], but this approach would limit the generality of the model.
4.2. ThresNet—Neural Thresholding Model with Label Embeddings
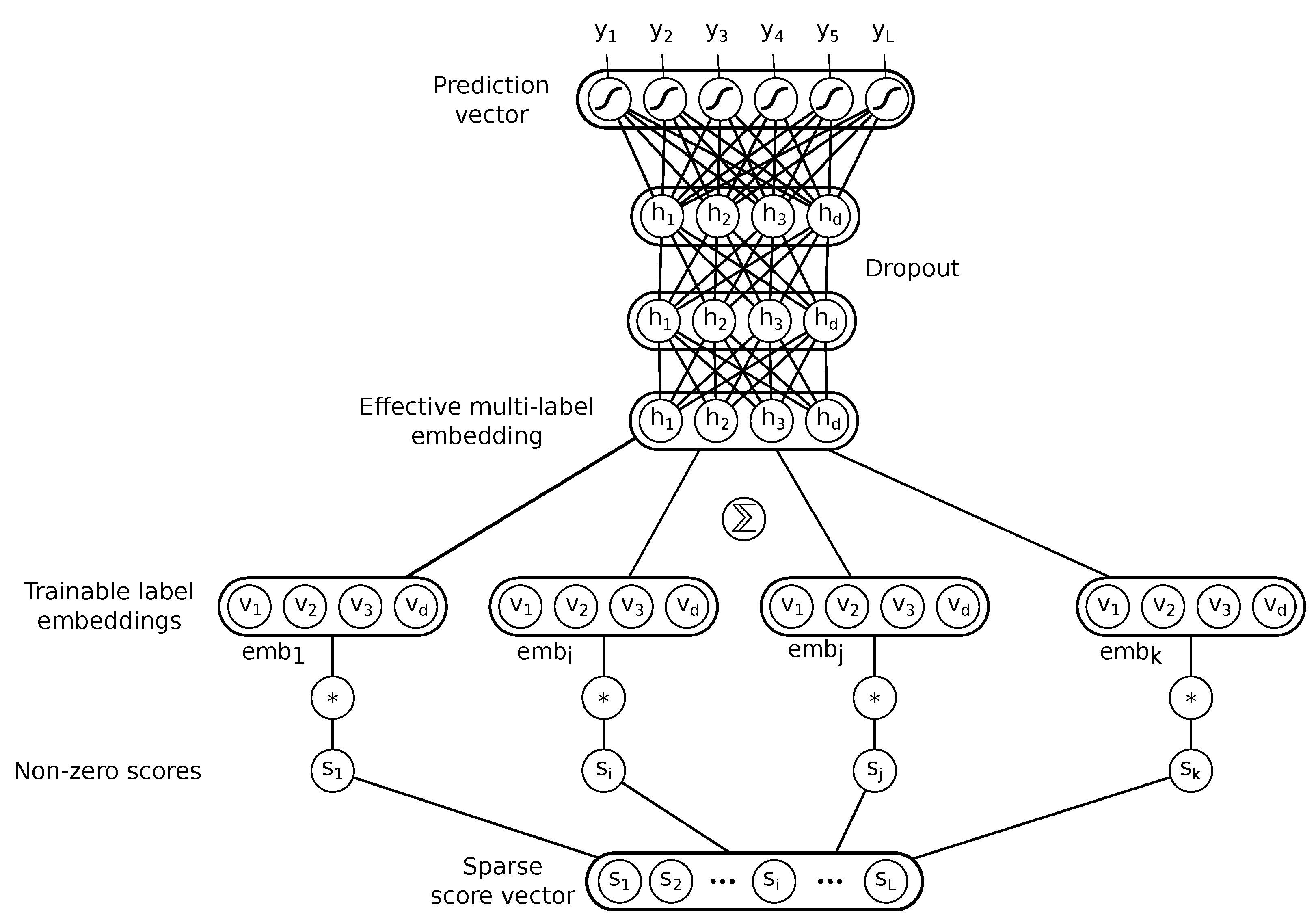
To overcome the space complexity problem of the above naive model, we propose a different architecture, presented in
Figure 2, inspired by a FastText model [
43]. In this model, each label is associated with a trainable label embedding (such as word embeddings in FastText), which is a vector of
d floating point values. For a given input, which is a scaled score vector
ss, the model calculates the
effective multi-label embedding , which can be described as a result of sparse vector–dense matrix multiplication:
, where
is an
matrix with the
i-th label embedding in its
i-th row. In other words, the effective multi-label embedding is a weighted sum of the label embeddings (not a simple average of the embeddings, as in the original FastText), with label scores as the weights of the components. This way, it includes information about which labels are involved in a given input as well as the intensity of these labels in the mix, as judged by a source scorer.
This multi-label embedding could be directly used to produce prediction vectors via a dense layer with
L output units. After initial experiments, we found that slightly better results are possible with a deeper model. The final model has two additional hidden layers, both having
d units (the same sizes as embeddings), and using the popular ReLU [
44] activation function (
). The final model realizes the following function:
For training purposes, the Heaviside is replaced by sigmoid (), which enables a standard gradient-based training. During inference, the Heaviside function is used again to achieve binary predictions.
The presented architecture enables complex, nonlinear, and non-obvious thresholding, while having complexity, where . Dimensionality of label embeddings d (which is also the hidden layer size), is the main hyperparameter for controlling the complexity of the model.
ThresNet, while inspired by FastText, is considerably different. First, the purposes of these models are different: thresholding for ThresNet versus representation learning or end-to-end classification for FastText. The main consequence of that is the nature of the model inputs: ThresNet obtains label scores and not raw feature vectors (especially not features from a fixed-sized moving context window). Second, ThresNet calculates a weighted average of label embeddings, while FastText calculates a simple average of feature embeddings. Third, ThresNet includes a couple of bottleneck hidden layers to mitigate the O () complexity and improve performance, while FastText maps averaged embeddings directly into the output space. Finally, the ThresNetCSS variant, described below, is the enhancement that does not have any equivalent counterpart in FastText (and which is rather impossible, because input and output spaces are different in sizes there).
4.3. ThresNetCSS—A Residual Variant
ThresNet can learn complex patterns for seemingly easy tasks of thresholding score vectors. Although this ability is crucial to be able to correctly predict mis-scored labels, making a prediction about a label should fundamentally be based on its label score. However, ThresNet architecture does not allow for this easily, because there is no direct connection between the i-th input ss and the i-th output . The signal between these units has to go through three bottleneck layers and nonlinearities of activation functions.
ThresNet
CSS, depicted in
Figure 3, is a variant designed specifically to remedy the aforementioned problem. The idea here is to combine the powerfulness of ThresNet with traditional CS-cut thresholding, implemented as CS-net (shown in
Figure 1a and Equation (
12)). The model adds the input score vector just before the final activation function of ThresNet, transforming the architecture into a form of a
residual network [
45]. The residual connection joins the corresponding elements of large sparse input and output vectors, which are otherwise connected through bottleneck layers, similar to what is done to images in UNet-like image segmentation models [
46].
Additionally, it is possible to
transfer knowledge from a CS(S)-cut traditional strategy into the model via a non-trainable bias vector
. The overall function of the model is as follows:
During training, this residual model learns to exhibit behaviors that differ from simply applying a priori-given CSS-cut thresholds. The intuition is that complex pattern-based thresholding should be applied only when it outweighs the default CSS-cut strategy. The space complexity of ThresNetCSS is the same as the primary ThresNet.
4.4. Network Training
The presented models are trained in a standard way using stochastic gradient descent with mini-batches to minimize
binary cross-entropy loss for each label:
where
is the model response given the
i-th train-scaled score vector
. To minimize this loss, we used the NAdam optimizer [
47] with the default settings.
In experiments on real datasets (
Section 5.2), 10-fold cross-validation was employed. Partitioning data into stratified folds, which is challenging in multi-label problems, was conducted using iterative stratification described in [
48]; this stratification is publicly available alongside the data [
49]. To prevent overfitting, the dropout [
50] layer was added to the models before the final prediction layer and early stopping was used by monitoring the loss on the validation data. In each data fold, we ran 10 trials of random searches for the best hyperparameters; thus, we trained 100 models for each dataset to select the best ones based on validation results. The whole code was implemented in Python using a TensorFlow 2.0 framework and is available at
github.com/szarakawka/nn-thresholding, (accessed on 26 May 2023).
6. Conclusions
In this paper, we proposed two variants of a novel neural network-based thresholding method for obtaining high-quality multi-label predictions from class scores already available from external scorers. Our models, called ThresNets, are designed to scale linearly with the number of labels and can be trained offline entirely, e.g., after the training of a scorer is finished. The second variant of our proposal shows a way to incorporate classic CS/CSS thresholds into the neural model, which can be viewed as a kind of transfer learning between heterogeneous models. The presented thresholding methods exhibit interesting recovering possibilities from scoring errors that are unavailable in classic approaches.
Our method is well suited for middle-sized MLC tasks, where the label space is large enough, such that informative dependencies between label scores can be found, and the ground truth of label assignments is still reliable (which is problematic in XMLC problems). Our experiments on artificially created scores show that the complex thresholding phase can be especially beneficial when the scoring phase leaves enough room for improvements. For example, popular nearest neighbor-based classifiers (such as k-NN and LEML, among others) may produce underscored or overscored labels due to their use of local information about the instance. In such cases, ThresNets proved to be useful.
In our empirical evaluation on real datasets, ThresNets clearly show better performances according to Favg, Fmi, as part of a hybrid with classical methods, Fma metrics, tested on four dataset–scorer combinations, as well as on synthetic datasets. Among single thresholding methods, we had up to 40.6% relative improvement over the CSS-cut baseline in Fmi (0.6 over 0.43), 3.6% relative improvement in Fma (0.174 over 0.168), and 30.1% relative improvement (0.389 over 0.299) in Favg (the results for scores).
Among the downsides of the proposed methods, one of the hardest to overcome is the risk of overfitting to training data. We attempted to minimize this risk by using regularization methods while training neural models (dropout layer, early stopping, cross-validation) as well as designing ThresNetCSS architecture that learns only the residuals over the CSS-cut baseline. Still, the abundance of long-tail labels, for which only a few positive samples are available, makes the training hard, and we found that a hybrid of ThresNetCSS and the CSS-cut strategy often works better than ThresNetCSS only.
In the future, we will utilize the external knowledge of class structure by encoding it in label embeddings. We can then start ThresNet training with such prepared embeddings instead of random ones, as is currently done. Intuitively, when such a structure exists (e.g., Wikipedia (pseudo)-hierarchy of categories), encoding it in pretrained label embeddings should be beneficial, and our models can make use of them without any changes in architecture. This external knowledge could also be used in a more complicated way, for example, to initialize an additional sparsely connected first layer, where instead of a dense matrix
, there would be, e.g., a sparse category graph adjacency matrix of a fixed structure, with trainable weights. Another potential extension of the presented neural models is to make them work on scores obtained not only from one scorer but from two or more scorers at the same time; in this way, they can work as merging units trained to produce optimal predictions based on available scorers. Yet another interesting direction of the development of ThresNets is to include hierarchy-related cost-sensitivity (see e.g., [
19,
54,
55]) while training them, enabling better performance in terms of hierarchical classification metrics. Sometimes hierarchical organization of categories may change; if so, it would be faster to fine-tune a thresholding phase than retrain the whole classification system.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}