
UTTSR: A Novel Non-Structured Text Table Recognition Model Powered by Deep Learning Technology

Abstract
:1. Introduction
- (1)
- Table detection utilizes Cascade Faster R-CNN with the ResNeXt105 to extract image features. Additionally, TPS transformation and radiation are employed to enhance the accuracy of table detection.
- (2)
- Improved DBNet and attention-based CRNN are utilized for the detection and recognition phase of text lines in order to identify simple formulas and special characters.
- (3)
- TableMaster is implemented to convert the resulting table structure into an HTML format that can be easily used for future applications.
2. Related Work
2.1. Table Detection
2.2. Table Structure Recognition
2.3. Table Content Recognition
3. Methods
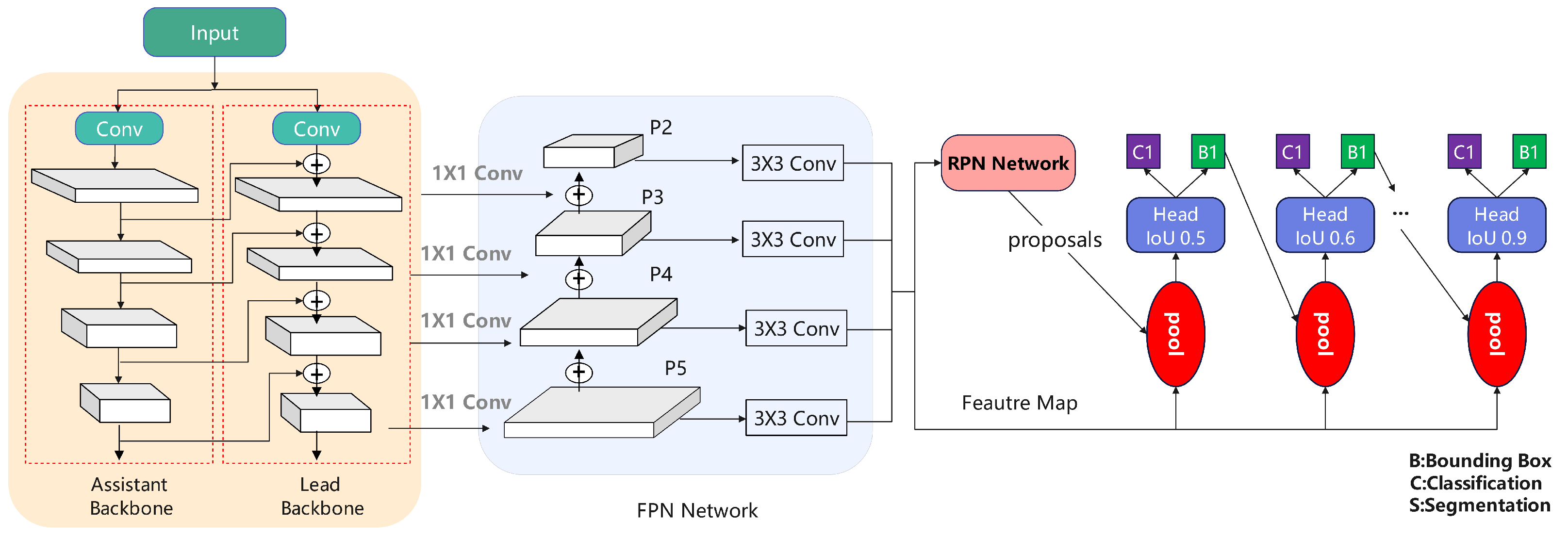
3.1. Regional Detection Based on Cascade Faster R-CNN
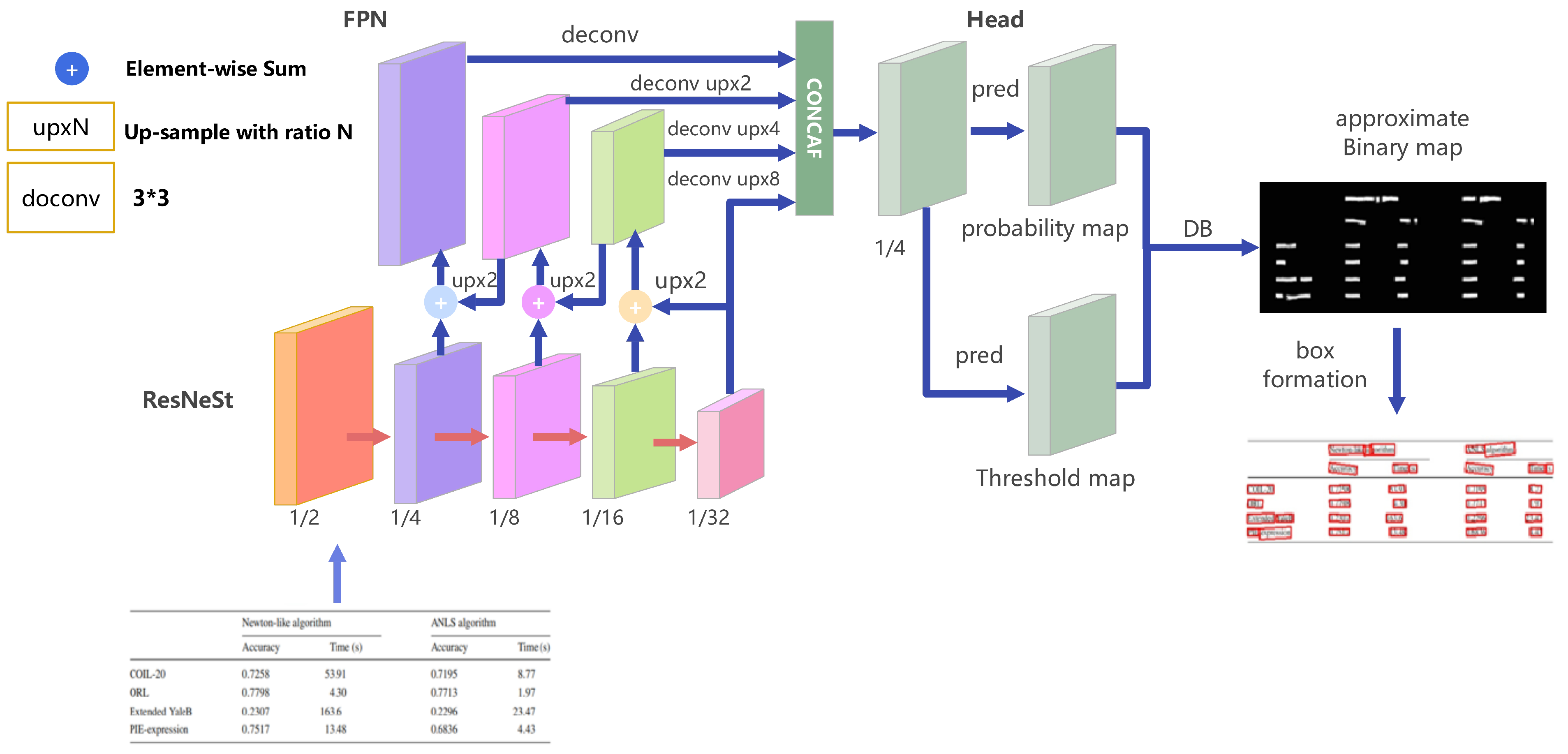
3.2. DBNet Text Detection Based on Do-Conv
3.3. Attention-Based CRNN Text Recognition
3.4. Sequence Structure Recognition Based on Transformer
4. Experiment
4.1. Dataset
4.2. Experimental Settings
4.2.1. Experimental Environment
4.2.2. Evaluation Index
4.3. Comparative Experiment
4.4. Ablation Experiment
4.5. Implementation Details
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Kashinath, T.; Jain, T.; Agrawal, Y.; Anand, T.; Singh, S. End-to-end table structure recognition and extraction in heterogeneous documents. Appl. Soft Comput. 2022, 123, 108942. [Google Scholar] [CrossRef]
- Prasad, D.; Gadpal, A.; Kapadni, K.; Visave, M.; Sultanpure, K. CascadeTabNet: An approach for end to end table detection and structure recognition from image-based documents. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Seattle, WA, USA, 14–19 June 2020; pp. 572–573. [Google Scholar]
- Watanabe, T.; Luo, Q.; Sugie, N. Structure recognition methods for various types of documents. Mach. Vis. Appl. 1993, 6, 163–176. [Google Scholar] [CrossRef]
- Hirayama, Y. A method for table structure analysis using DP matching. In Proceedings of the 3rd International Conference on Document Analysis and Recognition, Montreal, QC, Canada, 14–16 August 1995; Volume 2, pp. 583–586. [Google Scholar]
- Ramel, J.Y.; Crucianu, M.; Vincent, N.; Faure, C. Detection, extraction and representation of tables. In Proceedings of the Seventh International Conference on Document Analysis and Recognition, Edinburgh, UK, 6 August 2003; pp. 374–378. [Google Scholar]
- Watanabe, T.; Luo, Q.; Sugie, N. Toward a practical document understanding of table-form documents: Its framework and knowledge representation. In Proceedings of the 2nd International Conference on Document Analysis and Recognition (ICDAR’93), Tsukuba, Japan, 20–22 October 1993; pp. 510–515. [Google Scholar]
- Schreiber, S.; Agne, S.; Wolf, I.; Dengel, A.; Ahmed, S. Deepdesrt: Deep learning for detection and structure recognition of tables in document images. In Proceedings of the 2017 14th IAPR International Conference on Document Analysis and Recognition (ICDAR), Kyoto, Japan, 9–15 November 2017; Volume 1, pp. 1162–1167. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. In Proceedings of the 28th International Conference on Neural Information Processing Systems, Cambridge, MA, USA, 7–12 December 2015; Volume 28. [Google Scholar]
- Wang, W.; Xie, E.; Li, X.; Hou, W.; Lu, T.; Yu, G.; Shao, S. Shape robust text detection with progressive scale expansion network. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 9336–9345. [Google Scholar]
- Zhang, P.; Li, C.; Qiao, L.; Cheng, Z.; Pu, S.; Niu, Y.; Wu, F. VSR: A unified framework for document layout analysis combining vision, semantics and relations. In Document Analysis and Recognition–ICDAR 2021, Proceedings of the 16th International Conference, Lausanne, Switzerland, 5–10 September 2021; Springer: Berlin/Heidelberg, Germany, 2021; Part I, pp. 115–130. [Google Scholar]
- Rahgozar, M.A.; Fan, Z.; Rainero, E.V. Tabular document recognition. In Document Recognition Proceedings of the 1994 International Symposium on Electronic Imaging: Science and Technology, San Jose, CA, USA, 6–10 February 1994; SPIE: Bellingham, WA, USA, 1994; Volume 2181, pp. 87–96. [Google Scholar]
- Khan, S.A.; Khalid, S.M.D.; Shahzad, M.A.; Shafait, F. Table structure extraction with bi-directional gated recurrent unit networks. In Proceedings of the 2019 International Conference on Document Analysis and Recognition (ICDAR), Sydney, Australia, 20–25 September 2019; pp. 1366–1371. [Google Scholar]
- Xue, W.; Yu, B.; Wang, W.; Tao, D.; Li, Q. Tgrnet: A table graph reconstruction network for table structure recognition. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 1295–1304. [Google Scholar]
- Ye, J.; Qi, X.; He, Y.; Chen, Y.; Gu, D.; Gao, P.; Xiao, R. PingAn-VCGroup’s solution for ICDAR 2021 competition on scientific literature parsing task B: Table recognition to HTML. arXiv 2021, arXiv:2105.01848. [Google Scholar]
- Fischer, P.; Smajic, A.; Abrami, G.; Mehler, A. Multi-Type-TD-TSR–Extracting Tables from Document Images Using a Multi-stage Pipeline for Table Detection and Table Structure Recognition: From OCR to Structured Table Representations. In KI 2021: Advances in Artificial Intelligence, Proceedings of the 44th German Conference on AI, Virtual Event, 27 September–1 October 2021; Springer: Berlin/Heidelberg, Germany, 2021; pp. 95–108. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Paliwal, S.S.; Vishwanath, D.; Rahul, R.; Sharma, M.; Vig, L. Tablenet: Deep learning model for end-to-end table detection and tabular data extraction from scanned document images. In Proceedings of the 2019 International Conference on Document Analysis and Recognition (ICDAR), Sydney, Australia, 20–25 September 2019; pp. 128–133. [Google Scholar]
- Siddiqui, S.A.; Fateh, I.A.; Rizvi, S.T.R.; Dengel, A.; Ahmed, S. Deeptabstr: Deep learning based table structure recognition. In Proceedings of the 2019 International Conference on Document Analysis and Recognition (ICDAR), Sydney, Australia, 20–25 September 2019; pp. 1403–1409. [Google Scholar]
- Zhong, X.; ShafieiBavani, E.; Jimeno Yepes, A. Image-based table recognition: Data, model, and evaluation. In Computer Vision–ECCV 2020, Proceedings of the 16th European Conference, Glasgow, UK, 23–28 August 2020; Springer: Berlin/Heidelberg, Germany, 2020; Part XXI, pp. 564–580. [Google Scholar]
- Qiao, L.; Li, Z.; Cheng, Z.; Zhang, P.; Pu, S.; Niu, Y.; Ren, W.; Tan, W.; Wu, F. Lgpma: Complicated table structure recognition with local and global pyramid mask alignment. In Document Analysis and Recognition–ICDAR 2021, Proceedings of the 16th International Conference, Lausanne, Switzerland, 5–10 September 2021; Springer: Berlin/Heidelberg, Germany, 2021; Part I, pp. 99–114. [Google Scholar]
- Long, R.; Wang, W.; Xue, N.; Gao, F.; Yang, Z.; Wang, Y.; Xia, G.S. Parsing table structures in the wild. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 944–952. [Google Scholar]
- Duan, K.; Bai, S.; Xie, L.; Qi, H.; Huang, Q.; Tian, Q. Centernet: Keypoint triplets for object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 6569–6578. [Google Scholar]
- Li, M.; Cui, L.; Huang, S.; Wei, F.; Zhou, M.; Li, Z. Tablebank: A benchmark dataset for table detection and recognition. arXiv 2019, arXiv:1903.01949. [Google Scholar]
- Lu, N.; Yu, W.; Qi, X.; Chen, Y.; Gong, P.; Xiao, R.; Bai, X. Master: Multi-aspect non-local network for scene text recognition. Pattern Recognit. 2021, 117, 107980. [Google Scholar] [CrossRef]
- Li, Y.; Huang, Z.; Yan, J.; Zhou, Y.; Ye, F.; Liu, X. GFTE: Graph-based financial table extraction. In Proceedings of the Pattern Recognition, ICPR International Workshops and Challenges, Virtual Event, 10–15 January 2021; Springer: Berlin/Heidelberg, Germany, 2021. Part II. pp. 644–658. [Google Scholar]
- Yang, Q.; Cao, Y.; Li, H.; Luo, P. Numerical Formula Recognition from Tables. In Proceedings of the 27th ACM SIGKDD Conference on Knowledge Discovery &Data Mining, Singapore, 14–18 August 2021; pp. 1986–1996. [Google Scholar]
- Wu, X.; Zhang, J.; Li, H. Text-to-table: A new way of information extraction. arXiv 2021, arXiv:2109.02707. [Google Scholar]
- Ly, N.T.; Takasu, A. An End-to-End Multi-Task Learning Model for Image-based Table Recognition. arXiv 2023, arXiv:2303.08648. [Google Scholar]
- Smock, B.; Pesala, R.; Abraham, R. Aligning benchmark datasets for table structure recognition. arXiv 2023, arXiv:2303.00716. [Google Scholar]
- Wang, H.; Xue, Y.; Zhang, J.; Jin, L. Scene table structure recognition with segmentation collaboration and alignment. Pattern Recognit. Lett. 2023, 165, 146–153. [Google Scholar] [CrossRef]
- Huang, Y.; Lu, N.; Chen, D.; Li, Y.; Xie, Z.; Zhu, S.; Gao, L.; Peng, W. Improving Table Structure Recognition with Visual-Alignment Sequential Coordinate Modeling. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–22 June 2023; pp. 11134–11143. [Google Scholar]
- Kazdar, T.; Jmal, M.; Souidene, W.; Attia, R. Table Recognition in Scanned Documents. In Computational Collective Intelligence, Proceedings of the 14th International Conference, ICCCI 2022, Hammamet, Tunisia, 28–30 September 2022; Springer: Berlin/Heidelberg, Germany, 2022; pp. 744–754. [Google Scholar]
- Zhou, M.; Ramnath, R. A Structure-Focused Deep Learning Approach for Table Recognition from Document Images. In Proceedings of the 2022 IEEE 46th Annual Computers, Software, and Applications Conference (COMPSAC), Los Alamitos, CA, USA, 27 June–1 July 2022; pp. 593–601. [Google Scholar]
- Lee, E.; Park, J.; Koo, H.I.; Cho, N.I. Deep-learning and graph-based approach to table structure recognition. Multimed. Tools Appl. 2022, 81, 5827–5848. [Google Scholar] [CrossRef]
- Nassar, A.; Livathinos, N.; Lysak, M.; Staar, P. Tableformer: Table structure understanding with transformers. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 4614–4623. [Google Scholar]
- Smock, B.; Pesala, R.; Abraham, R. PubTables-1M: Towards comprehensive table extraction from unstructured documents. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 4634–4642. [Google Scholar]
- Fang, J.; Tao, X.; Tang, Z.; Qiu, R.; Liu, Y. Dataset, ground-truth and performance metrics for table detection evaluation. In Proceedings of the 2012 10th IAPR International Workshop on Document Analysis Systems, Gold Coast, Australia, 27–29 March 2012; pp. 445–449. [Google Scholar]
- Chi, Z.; Huang, H.; Xu, H.D.; Yu, H.; Yin, W.; Mao, X.L. Complicated table structure recognition. arXiv 2019, arXiv:1908.04729. [Google Scholar]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Methods | Precision (%) | Recall (%) | F1 (%) | TEDS (%) |
|---|---|---|---|---|---|
| ICDAR2015 | SPLETGE | 99.2 | 98.8 | 98.99 | - |
| UTTSR (ours) | 99.5 | 99.4 | 99.45 | - | |
| TableNet | 97.4 | 96.2 | 96.80 | - | |
| Marmote | SPLETGE | 98.8 | 99.0 | 98.90 | - |
| UTTSR (ours) | 99.2 | 98.7 | 98.94 | - | |
| TableNet | 93.1 | 90.1 | 91.58 | - | |
| PubTabnet | SPLETGE | - | - | - | 97.1 |
| UTTSR (ours) | - | - | - | 98.5 | |
| TableNet | - | - | - | 96.7 | |
| SCITSR | SPLETGE | 85.4 | 82.3 | 83.82 | - |
| UTTSR (ours) | 95.2 | 94.8 | 95.00 | - | |
| TableNet | 92.2 | 89.8 | 90.98 | - |
| Method | Backbone | Precision (%) |
|---|---|---|
| Faster RCNN | VGG16 | 62.70 |
| Cascade Faster RCNN | ResNet101 | 79.20 |
| ResNeXt105 | 80.10 | |
| Cascade Faster RCNN+ FPN | ResNet101 | 80.50 |
| ResNeXt105 | 81.40 |
| Method | Precision (%) | Recall (%) | F1 (%) |
|---|---|---|---|
| Image Algorithm+PDF | 90.00 | 30.36 | 72.0 |
| Layout Parser | 95.25 | 84.16 | 89.0 |
| TableMaster | 96.95 | 93.07 | 95.0 |
| Method | Precision (%) | Recall (%) | F1 (%) |
|---|---|---|---|
| DBNet | 88.60 | 76.50 | 82.10 |
| DBNet++ | 87.80 | 77.50 | 82.60 |
| DBNet (Do-cov) | 90.60 | 76.00 | 82.70 |
| TD | TSR | TLD | TLR | F1 (%) |
|---|---|---|---|---|
| Cascade Faster R-CNN | Transformer | DBNet (Do-cov) | CRNN | |
| ✓ | × | × | × | 82.45 |
| ✓ | ✓ | × | × | 86.42 |
| ✓ | ✓ | ✓ | × | 92.31 |
| ✓ | ✓ | ✓ | ✓ | 97.85 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, M.; Zhang, L.; Zhou, M.; Han, D. UTTSR: A Novel Non-Structured Text Table Recognition Model Powered by Deep Learning Technology. Appl. Sci. 2023, 13, 7556. https://doi.org/10.3390/app13137556
Li M, Zhang L, Zhou M, Han D. UTTSR: A Novel Non-Structured Text Table Recognition Model Powered by Deep Learning Technology. Applied Sciences. 2023; 13(13):7556. https://doi.org/10.3390/app13137556
Chicago/Turabian StyleLi, Min, Liping Zhang, Mingle Zhou, and Delong Han. 2023. "UTTSR: A Novel Non-Structured Text Table Recognition Model Powered by Deep Learning Technology" Applied Sciences 13, no. 13: 7556. https://doi.org/10.3390/app13137556