1. Introduction
Extended producer responsibility (EPR) refers to the practice whereby manufacturing companies are responsible not only for designing, producing, and selling products but also for their recycling, dismantling, and reuse. EPR is also an indispensable part of zero waste management [
1]. By reducing the amount of waste products, EPR can promote the full utilization of resources and facilitate the development of a circular economy. In China, EPR has been applied to various manufacturing industries, such as household appliances [
2], automobiles [
3], and electronic products [
4]. It is now extending to more industries under the encouragement of national policies. According to the UN’s 2020 Global E-waste Monitor Report, only 17.4% of the 53.6 million tons of global e-waste produced in 2019 were recycled [
5]. EPR can effectively solve various social and environmental issues in e-waste recycling, such as handling heavy metals including lead, chromium, and mercury, in addition to addressing the problem of raw material shortages in manufacturing [
6].
The main products involved in household appliance recycling are generally known as the “four appliances and one brain”, namely televisions, refrigerators, washing machines, air conditioners, and computers [
7].
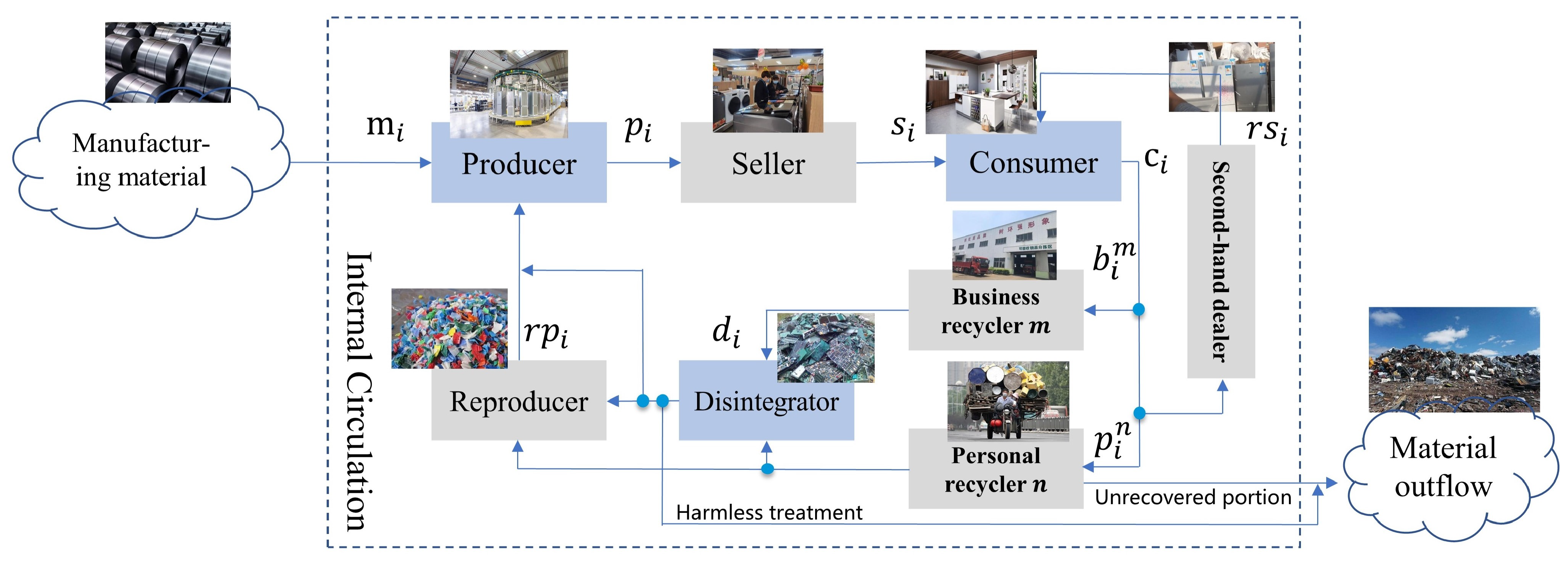
Figure 1 shows the material circulation process in the manufacturing and recycling of household appliances.
As shown in
Figure 1, the industrial chain of household appliance recycling involves many participants, including producers, sellers, consumers, second-hand dealers, business recyclers, personal recyclers, disintegrators, and reproducers. Raw materials such as metal, plastic, and glass are sold to household appliance producers at a price of
. Producers sell household appliances to sellers at a factory price of
, and sellers sell them to consumers online or offline at a price of
. Since household appliances that are replaced by consumers may be sold to second-hand dealers or directly to scrap dealers, there are two circulation pathways for waste household appliances. One is to sell them to second-hand dealers at a price of
, then sell them to consumers at a price of
. The second is to sell them to scrap dealers at a price of
. Scrap dealers can be divided into business recyclers and personal recyclers, and they are generally organized into multilevel networks according to their location. The selling price of the mth-level business recycler is denoted by
, and the selling price of the nth-level personal recycler is denoted by
. Personal recyclers usually do not have professional equipment, and they tend to dismantle waste household appliances privately, which not only exposes their employees to harmful substances and endangers their health [
8] but also causes materials that cannot be recycled to flow out of the material circulation [
9]. After dismantling, disintegrators sell the dismantled raw materials to reproducers at a price of
, and some materials that cannot be recycled are treated for harmless disposal, then flow out of material circulation [
10]. Reproducers process the waste raw materials into reusable raw materials and sell them to household appliance producers at a price of
, completing the internal circulation of materials in the manufacturing and recycling of household appliances. The pricing variables in the household appliance manufacturing and recycling process described above are summarized in
Table 1.
Research on the household appliance recycling chain includes recycling techniques, pricing strategies based on game theory, market competition and cooperation models, etc. Bressanelli et al. [
7] introduced the 4R strategy in the household appliance recycling circular economy, which includes reduction, reuse, remanufacturing, and recycling. Motoori et al. [
11] proposed the full recycling of various metal materials in electronic products by increasing reuse rates and enhanced recycling efficiency. Cao et al. [
12] constructed and analyzed a pricing strategy for recyclers based on a Stackelberg game model under EPR regulations, and the results showed that when the government is not the decision maker, the optimal product price of producers does not change under different strategies. They focused on three different closed-loop supply chain (CLSC) structures and different consumer categories. The authors of [
13,
14] studied competition and cooperation between producers and reproducers and investigated a circular game model of patents and carbon emissions. They discussed the impact of various policies and environmental factors on the decision making of supply chain system members. In China, there is a high production capacity for household appliances. Due to the longer lifespan of appliances and the rapid pace of product upgrades, the occurrence of reuse is relatively limited among Chinese consumers. As a result, the value assessment during the recycling process becomes even more critical, as the majority of waste household appliances are reprocessed through recycling methods. Although there is a growing emphasis on the replacement of old appliances with new ones in current policies, there is still a long way to go in terms of transitioning from the recycling stage to the reuse stage for waste household appliances. Therefore, conducting value assessment before the recycling process holds greater practical significance in terms of application and promotion. Consequently, the datasets used in our study specifically focus on the recycling scenario. During recycling, appliances are dismantled and crushed to recover materials, and the value of these materials remains relatively stable, making it feasible to obtain reasonably accurate estimates of material values.
However, there are still relatively few studies on the evaluation of household appliance recycling. The evaluation of each stage in the recycling chain is of considerable significance. For example, it helps to formulate reasonable pricing strategies, ensuring the profitability of recycling enterprises and providing more fair and reasonable prices for consumers. Moreover, it is helpful to find potential optimization space, such as by exploring more efficient recycling methods, reducing recycling costs, and improving recycling efficiency, thereby enhancing the efficiency of the entire recycling chain. Accurate evaluation methods are also beneficial for the discovery of potential economic benefits during the recycling process, attracting more enterprises and personnel to participate in recycling activities and promoting the effective recovery and utilization of resources. Johansson et al. compiled five short articles that focus on value assessment and pricing capabilities, bridging the gap between marketing, pricing, and strategic research [
15]. Han et al. [
16] proposed a fuzzy neural network-based evaluation model for the problem of accurate pricing in the process of recycling waste mobile phones. However, this model cannot be effectively applied to household appliance recycling due to differences in recycling mechanisms between mobile phones and household appliances. Wang et al. [
17] proposed an attribute classification modeling method for electronic product evaluation. This method divides the attributes of electronic products into standard value, basic value, and depreciation value. However, the article did not provide a calculation method for the classified values. Sahan et al. [
18] estimated components of recyclable precious metals and rare-earth elements from waste mobile phones in Turkey, but they did not apply the estimated results to recycling appraisal. No effective evaluation method for waste household appliance recycling has been proposed in the literature because the evaluation of household appliance recycling has unique characteristics and should be focused on waste raw materials as the main evaluation factor and combined with market game modeling to price the entire recycling chain. The most important entry point is the valuation of waste household appliances in the hands of consumers flowing into the recycling market, which is the most important part of the entire evaluation process in the recycling chain [
19]. Machine learning methods have not yet been introduced for the evaluation of recycled waste household appliances.
The traditional method of evaluating waste household appliances is usually based on manual experience and rules. As a comparison, machine learning methods can adaptively learn and process new data and continuously improve prediction accuracy. Moreover, machine learning can process a large amount of data, optimize algorithms, and improve the accuracy as and speed of waste household appliance valuation while enabling intelligent decision making in support of the recycling industry. In this paper, we focus on value assessment for waste household appliances (i.e., the
data in
Figure 1) and propose a machine-learning-based evaluation model for recycling waste household appliances. The three main contributions of this paper are as follows:
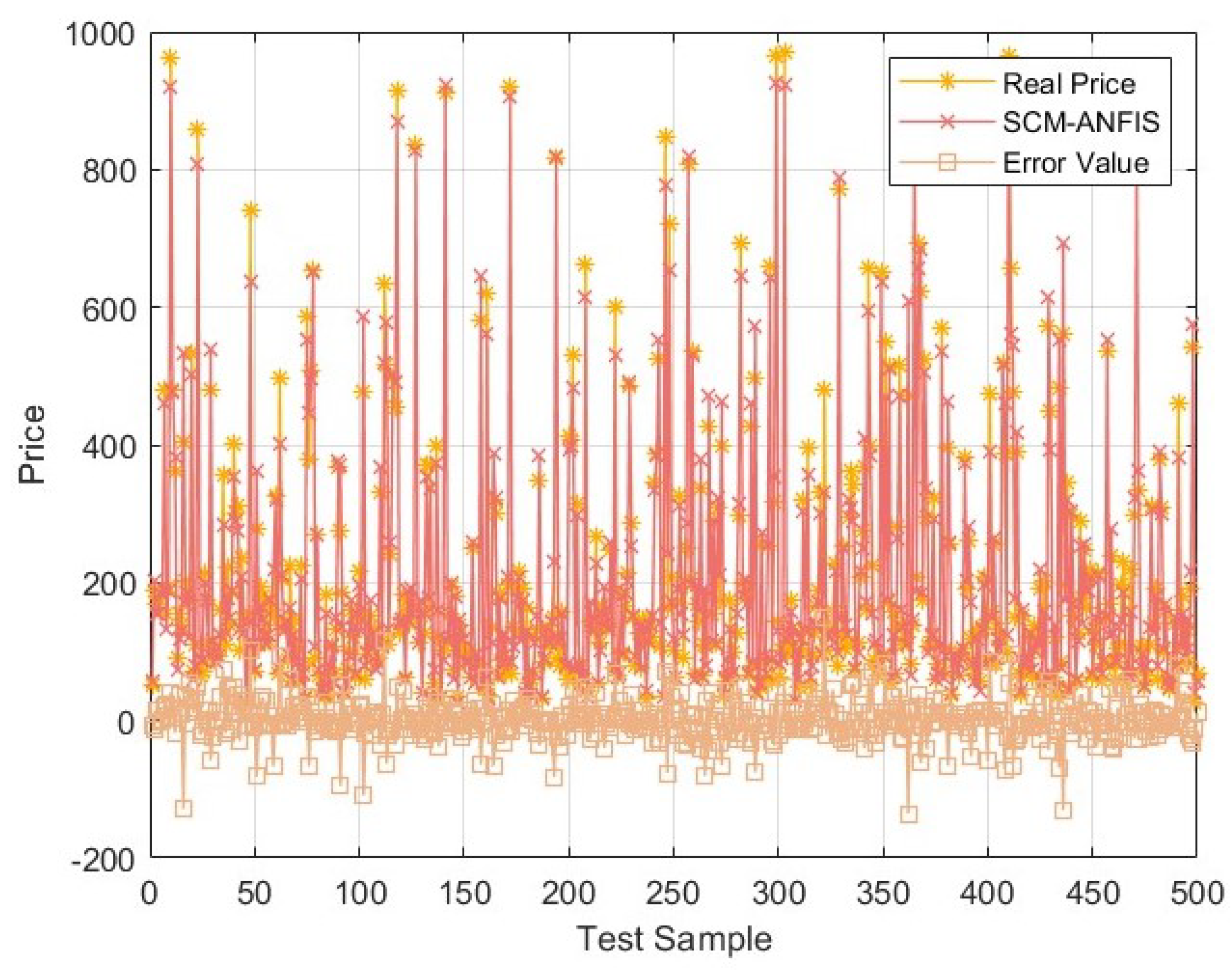
A subtractive clustering method and adaptive network fuzzy inference system (SCM–ANFIS)-based evaluation algorithm is used to evaluate the waste TELEVISION dataset, achieving better results in terms of mean absolute percentage error (MAPE) than long short-term memory (LSTM), BP neural network, random forest (RF), and Takagi–Sugeno fuzzy neural network (T–S FNN);
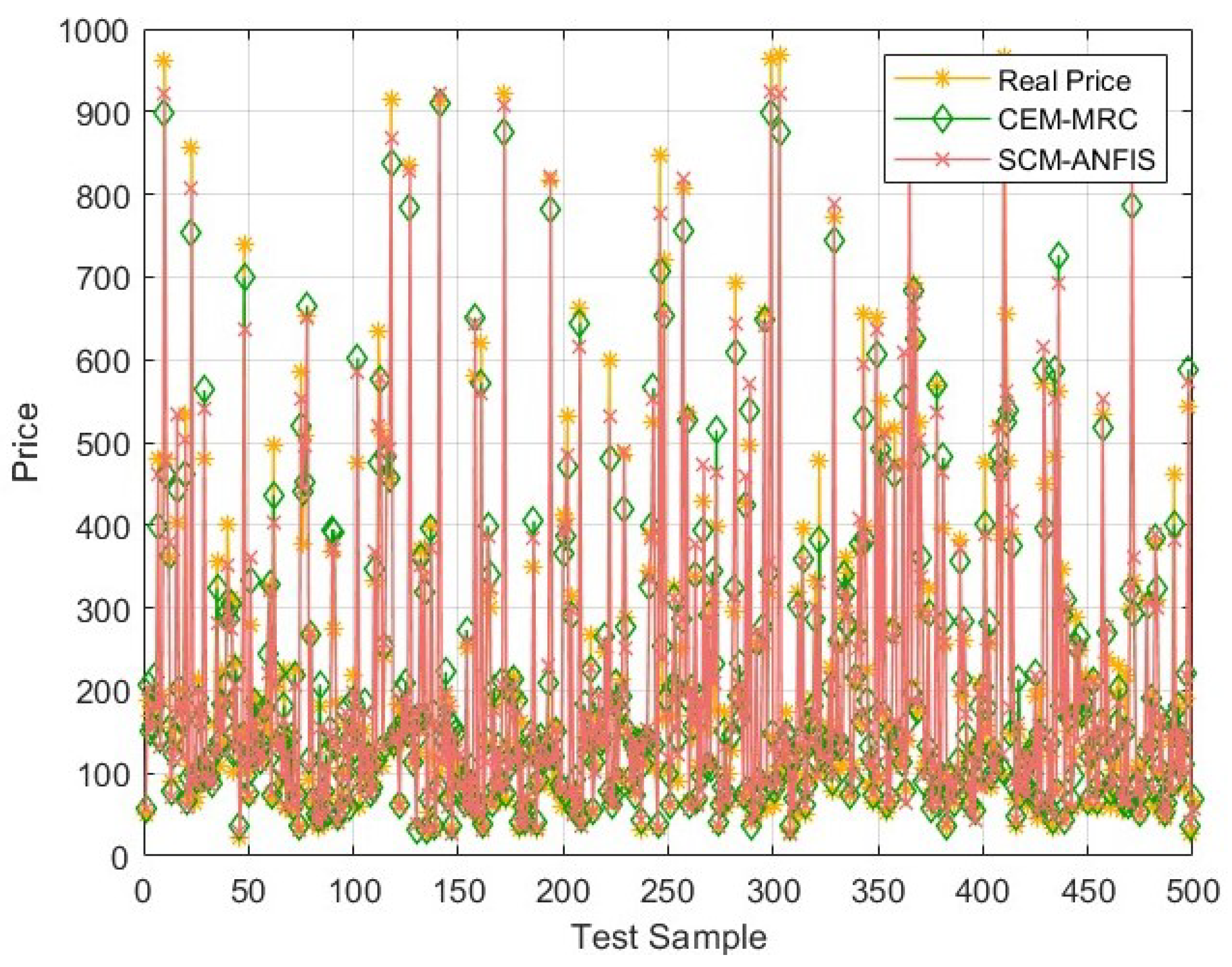
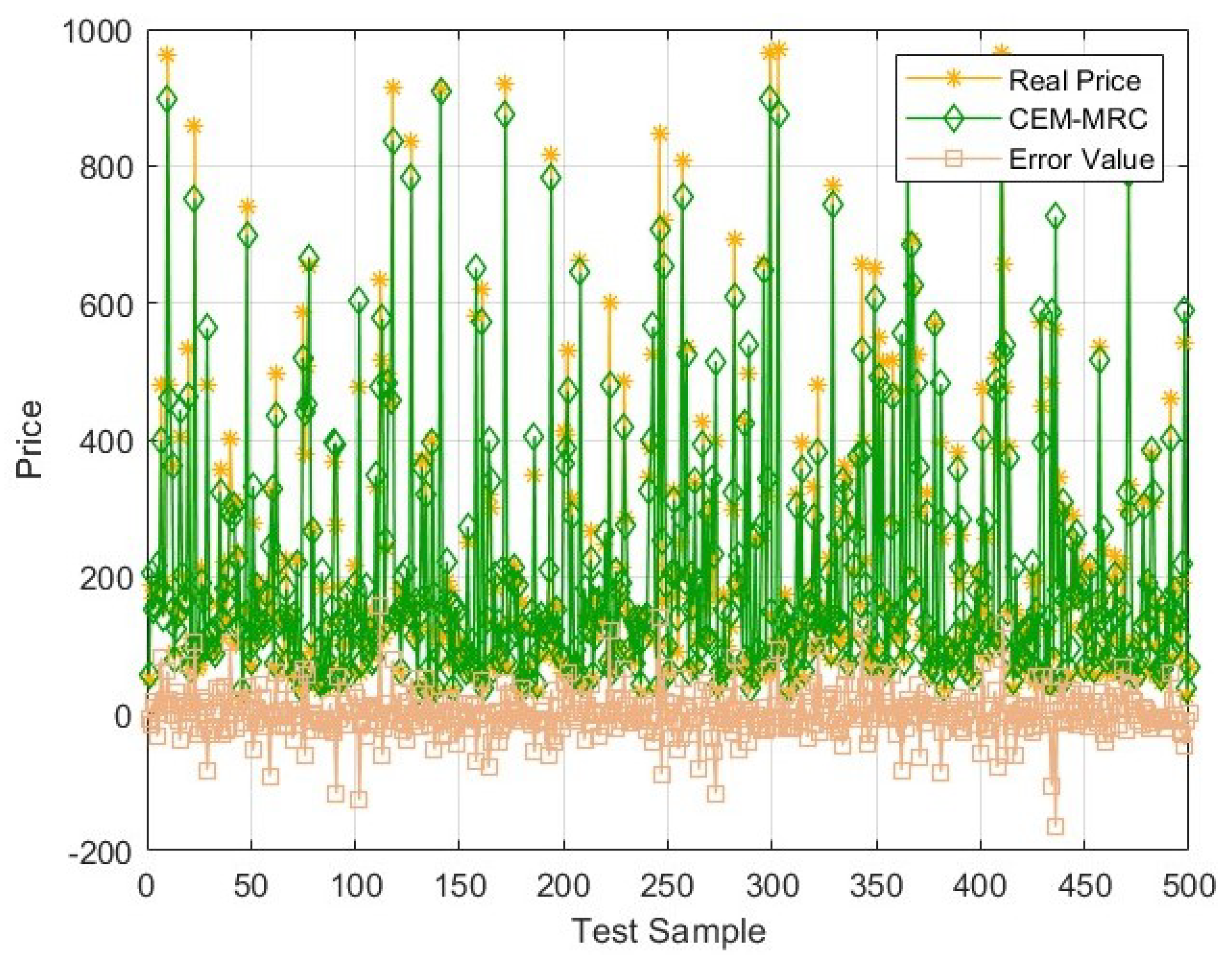
A combination evaluation model based on maximum ratio combination (CEM–MRC) is constructed based on the machine learning methods mentioned above and compared with different combination methods to predict results. The results show that the maximum ratio combination method achieves the best performance among tested combination methods, with a lower MAPE than the suboptimal BP method, reducing it by 0.1%;
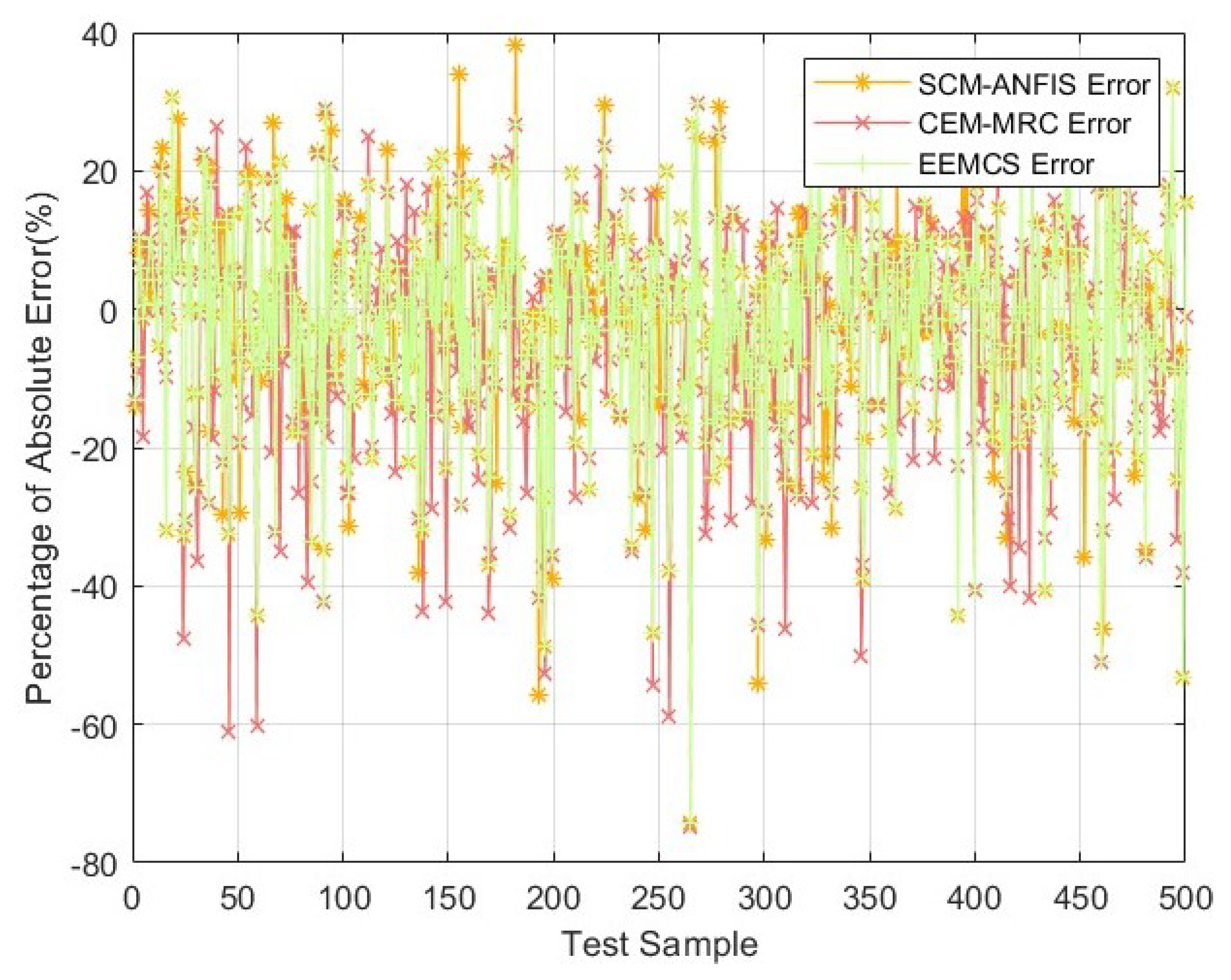
An enhanced evaluation model based on classification selection (EEM–CS) is designed by combining the prediction models of CEM–MRC and SCM–ANFIS, which automatically selects the evaluation results between them. This method reduces the MAPE by 0.73% compared to the optimal SCM–ANFIS method and by 1.42% compared to the suboptimal CEM–MRC method on the training set.
The remainder of this paper is organized as follows. The second section provides an overview of the relevant technologies and their application in this research. The third section presents the framework for evaluating waste household appliances, elaborating on the algorithms and technical approach of the proposed model. In the fourth section, the evaluation results are presented, along with comparisons with different models, while the fifth section concludes the paper and provides future research directions.
3. Value Assessment Framework for Waste Household Appliances
In this section, we introduce the main factors influencing the value assessment of waste household appliances. Subsequently, the evaluation framework and data processing methods are presented using the case of waste televisions. Then, a detailed explanation of the steps involved in the SCM–ANFIS method, the CEM–MRC algorithm, and the EEM–CS algorithm are presented.
3.1. Key Factors in Value Assessment of Waste Home Appliances
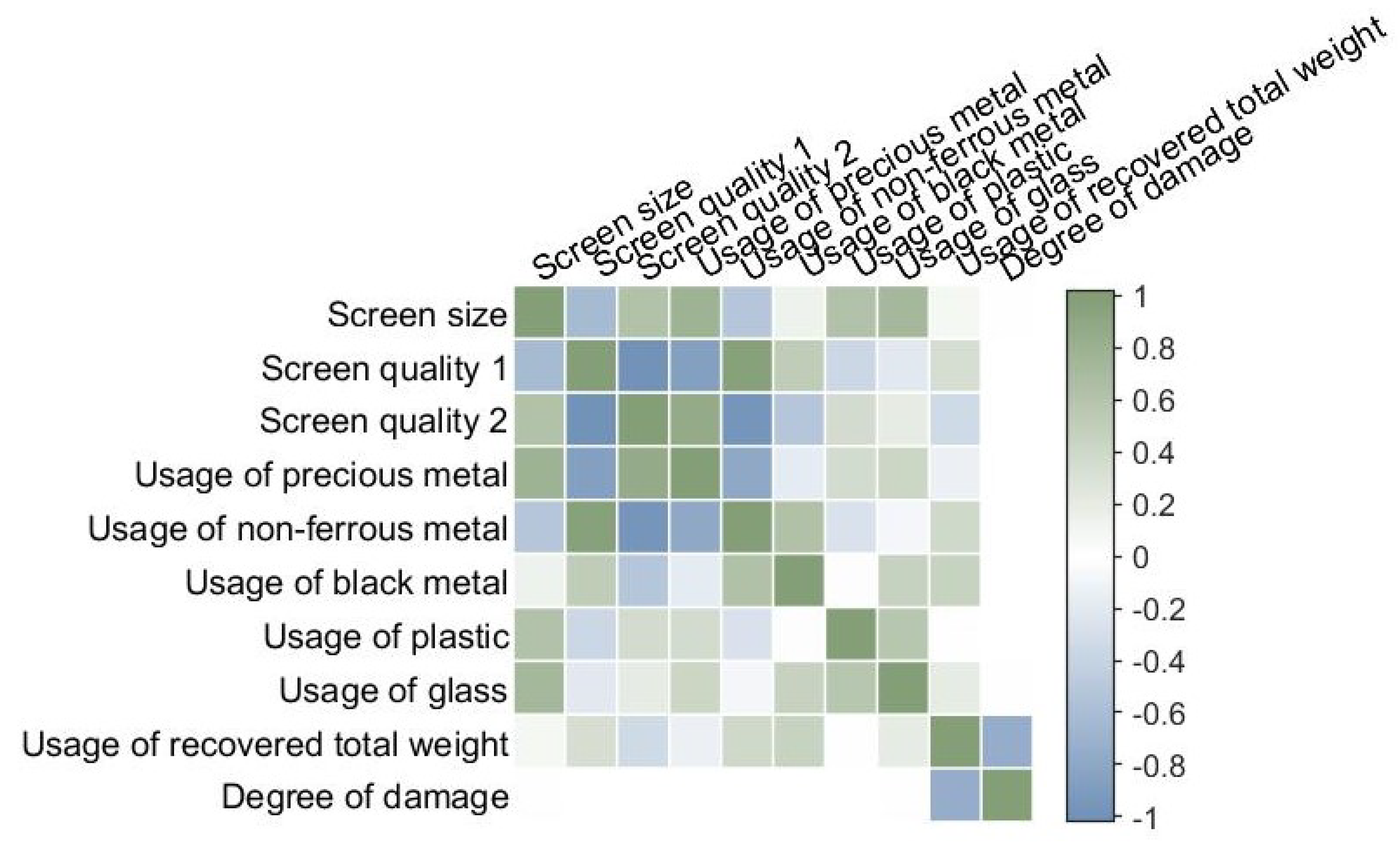
The methods for evaluating the value of waste household appliances are different from those used to evaluate recycled mobile phones or cars. Specifically, in the recycling of used mobile phones and cars, there is a large number of reusable components that can be repaired and refurbished before being reintroduced to the market. The main factors affecting the recycling price of these products are the model, usage time, and component parameters. However, waste household appliances have been used by users for a long time and are often considered outdated and undesirable. As a result, the recycling of these appliances mainly focuses on the recovery of raw materials such as metals (copper, steel, aluminum, etc.), glass, plastic, and paper. Waste household appliances are generally heavy, with a large proportion of metal materials. The pricing of waste household appliances for recycling is largely dependent on their weight, as well as other auxiliary factors, such as the brand of the appliance, usage time, damage level, screen type and condition, and the contents of various materials.
Therefore, it is necessary to propose effective algorithms for evaluation of recycled waste household appliances. In this paper, we take television recycling as an example to conduct an in-depth study on machine learning and fuzzy neural network algorithms for the evaluation of waste household appliances. Based on real market data on television recycling in China, a dataset of 6000 television recycling prices was expanded for evaluation.
3.2. Value Assessment Framework for TELEVISION Scrap
In order to achieve accurate valuation of waste televisions, we propose a reinforcement prediction model called EEM–CS with a classification selection mechanism, as shown in
Figure 2. The main idea of this algorithm is to utilize different machine learning methods to evaluate the value of waste household appliances. Through iterative classification prediction training, the algorithm is able to select the optimal evaluation result as the final output value assessment.
The design architecture mainly consists of three modules: data preprocessing, model training, and evaluated price output. The functions of each module are described below.
3.2.1. Data Preprocessing
The data preprocessing module includes abnormal data processing, one-hot encoding, data diversity, and normalization submodules, as described below.
Abnormal data processing: For the dataset of 6000 waste television recycling data entries, outlier and noise data are handled using methods such as the 3-sigma rule, Boxplot, Z-score, and Grubbs. Outlier data can be deleted, while missing data can be supplemented using the mean.
One-hot encoding: Since the dataset involves characteristics such as television brand and screen quality that cannot be recognized directly by neural networks, they need to be encoded as numerical data. One-hot encoding is used as an effective encoding method. Assuming there are M states to be encoded, the number of bits in one-hot encoding is M, and only one bit is 1, while the rest are 0. For example, there are two states in the case of screen quality in waste home appliances: good or bad. The code for good screen quality can be represented by “01”, while the code for bad screen quality can be represented by “10”. After all text information is one-hot-encoded, it is concatenated with the original data to form a new dataset.
Data diversity and normalization: The 6000 encoded data entries are randomly divided into a training set and a test set in a ratio of 11:1. Both the training and test sets are standardized to eliminate numerical problems caused by different dimensions and scales of data [
30]. In this paper, we adopt the MinMax normalization method, which scales the original data to the interval [0, 1]. Let
,
, …
, …
be the data, where
represents the maximum datum, and
represents the minimum datum. The processed new data (
) of the original data (
) are represented by:
3.2.2. Model Training
The model-training module includes PCA dimensionality reduction and model-training submodules, as follows:
PCA dimensionality reduction: Principal component analysis (PCA) is a detection method based on multivariate statistical analysis, which is usually used for feature extraction and data dimensionality reduction in machine learning [
31]. PCA can represent data using fewer principal components without losing too much information, thus reducing the dimensionality of the data [
32].
After normalizing the indicator data, the training set (X), which has p feature factors and n samples, is represented as follows:
Next, the matrix (
Z) is calculated.
Z is obtained by standardizing the matrix operation on
X, and the correlation coefficient matrix
R is obtained as follows:
Then, we solve the unknown variable (
) in the characteristic equation (
) of the correlation matrix (
R) and obtain
p eigenvalues:
The value of
is calculated and represents the contribution rate of the
principal component. The magnitude of the contribution rate reflects the amount of information contained in
.
Then, the cumulative contribution rate (
C) of the eigenvalues can be calculated. Generally, if
m feature factors are selected for dimension reduction,
m is chosen such that the cumulative contribution rate (
C) is greater than 0.85, indicating that these
m indicators can already represent the major information related to
X [
16]. In this paper, feature factors with a
C value greater than 0.9 are selected as the primary input.
Model Training
After PCA dimensionality reduction, the data are trained using five models: SCM–ANFIS, BP, T–S FNN, RF, and LSTM. The output result of the SCM–ANFIS model is denoted as
. A BP neural network is a multilayer feed-forward neural network, and its learning algorithm uses backpropagation to update the network weights. T–S FNN is a type of neural network based on fuzzy logic, and each output of T–S FNN is composed of a set of linear functions. T–S FNN maps the input variables to membership functions, then uses fuzzy rules for inference and weights each output of each rule. RF uses randomly selected subsets of training data and feature subsets to train each decision tree to increase the randomness of the tree. RF determines the final output by voting for each decision tree. LSTM is a special type of recurrent neural network used to handle sequence data with long-term dependencies. The state unit in LSTM can store long-term information, while the hidden state can pass short-term information [
33].
The training set uses 5500 sets of data, and we save the trained model and input it into the evaluation module. The output prices of the above five models are denoted as , , , , and .
3.2.3. Value Evaluation Module
We propose two algorithms for the evaluation module, namely CEM–MRC and EEM–CS. CEM–MRC utilizes the maximum ratio combination algorithm to weightedly combine the five evaluation prices (, , , , and ) to obtain an evaluation result that comprehensively incorporates the advantages of various methods. On the other hand, EEM–CS employs supervised learning after the addition of labels to enable the model to output the optimal evaluation result between SCM–ANFIS and CEM–MRC.
CEM–MRC
The output results of the training set data of the above five models are calculated using the maximum ratio combination method to obtain the weights of different models. The weights are then used to obtain the output result of the CEM–MRC method in the test set (denoted as ) through weighted combination.
EEM–CS
We use the maximum ratio combination method on the training set to construct auxiliary reference price variables, i.e., using and to construct the estimated true price (). The three prices and the dataset after PCA dimensionality reduction are used as the output of the training set and sent to the EEM–CS prediction model for training. In the training set, we mark which method obtains the lowest MAPE between SCM–ANFIS and CEM–MRC as the classification basis. After training the classification model with the above data, the model can evaluate which method should be chosen for value assessment of an arbitrary test datum. Finally, the EEM–CS method selects either the SCM–ANFIS or CEM–MRC method to output the final evaluation results of the waste household appliances in the test set.
3.3. SCM–ANFIS Algorithm Design
In this section, we present the details of the proposed SCM–ANFIS. Similar to T–S fuzzy neural networks, ANFIS also uses
if–then rules. Each rule consists of an antecedent (
if) and consequent (
then) parts. The antecedent specifies the fuzzy conditions based on the input variables, and the consequent part specifies the fuzzy conclusion based on the output variable. Let
denote a fuzzy rule, where
p indicated the number of rules. The expression of the rule is as follows:
Here, the
“if” part is fuzzy and is called the antecedent or premise.
represent the input system variables, and
represent the corresponding fuzzy sets. The
“then” part is determinate and is called the consequent or inference part.
y represents the inference result (e.g., estimated value), and
represent different weights of input variables.
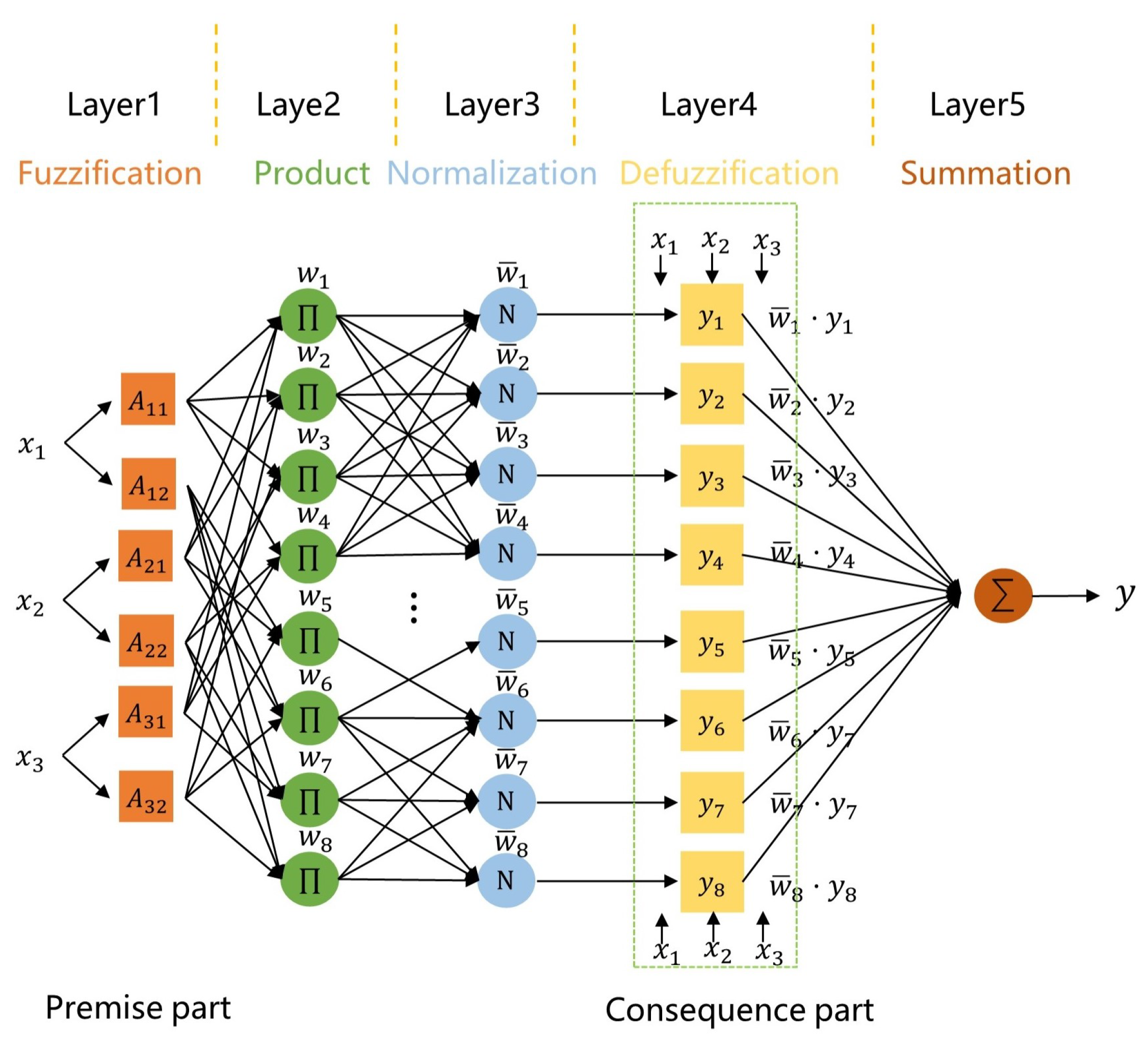
Figure 3 illustrates a three-input–one-output ANFIS structure. The input represents the input variables required for the valuation of waste home appliances, such as appliance specifications, brand, weight, etc. Each input variable is typically represented by a set of fuzzy sets, which are used to capture the degree of fuzziness or membership of the input variables. The fuzzification layer converts the input variables from their actual values into membership degrees within the fuzzy sets. The product layer consists of a set of fuzzy rules. The condition part of each rule matches the membership degrees of the input variables, and an activation level is assigned to each rule, indicating the degree or weight of the rule. The normalization layer combines the activation levels of the fuzzy rules with the membership functions of the rules to calculate the matching degree of each rule. The defuzzification layer combines the activation levels of all rules to generate the aggregated fuzzy output. The summation layer converts the aggregated fuzzy output into concrete values or fuzzy sets, representing the final evaluation result.
Before we input the data samples into the ANFIS network, they should be clustered to reduce the number of potential rules that will be generated, as shown in the following. Assuming
n data samples (
) in the training set, each data point (
) is a potential cluster center, and the density (
) of each data point is calculated first.
where
represents the radius of clustering. A large number of data points within the radius indicates that the density of the data point is high. The clustering algorithm selects the data point with the highest density as the center. When calculating the density of other data points, the influence of the selected cluster centers needs to be removed. Let
be the selected data point and
be its density. Then, Formula (10) is modified as follows:
where
represents the radius with obvious decreased density, indicating that the density of the data points near the first cluster center (
) decreases after modification and that they are unlikely to become the next cluster center. The above steps are repeated to select the next cluster center until the desired number of cluster centers is obtained [
34].
3.4. CEM–MRC Algorithm Design
We propose three main principles for CEM–MRC: the reverse combination method, the direct combination method, and the maximum ratio combination method. The difference between these methods lies in the weighting method used for different machine learning methods during the weighting process.
3.4.1. Inverse Combination Method
Suppose that the MAPE of different training models (i.e., SCM–ANFIS, BP, T–S FNN, RF, and LSTM) on the training set is
and that the corresponding combination weight (
) is
The output value of the inverse combination method is
where
represent the evaluation prices of different models. A lower MAPE of a specific model indicates that a smaller error can be achieved, and, hence, the weight of that model should be larger.
3.4.2. Exponential Combination Method
Suppose that the MAPE of different training models( i.e.,SCM–ANFIS, BP, T–S FNN, RF, and LSTM) on the training set is
and that the combination weight (
) can be expressed as
The output value of the exponential combination method is
where
represent the evaluation prices of different models. This method has is advantageous because it has a lower MAPE as compare to the inverse combination method.
3.4.3. Maximum Ratio Combination Method
The maximum ratio combination (MRC) method is different from the two combination methods mentioned above. It adopts the idea of maximizing the signal-to-noise ratio from communication and is therefore an optimal solution.
Let
be the output results of different training models for 5500 data samples in the training set, as represented by column vectors.
represents the true price of the training set, and
represent the errors between the predicted values and the true values.
Let
Y be the aggregated matrix composed of the output results of different training models on the training set; then,
Let
represent the weights of different models, where
is scalar. Then,
The signal-to-noise ratio (SNR) can then be expressed as:
To maximize SNR,
is a known fixed value. Thus,
is a constant, and the above equation is equal to maximizing the following formula:
As this is a weighted method, we have
To maximize the above Formula (22), the denominator needs to be minimized:
Finally, the maximum combined output value is
3.5. EEM–CS Algorithm Design
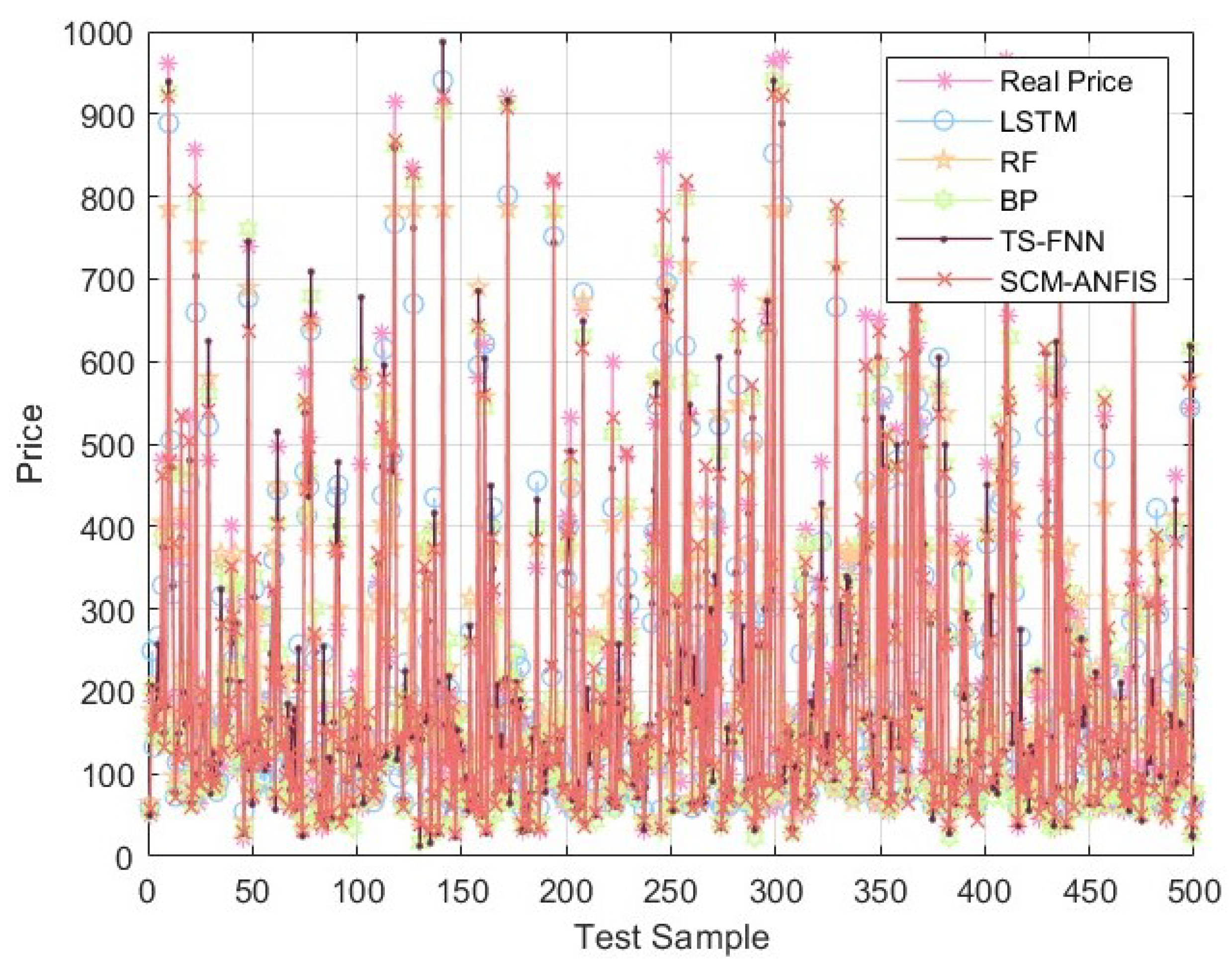
Although the SCM–ANFIS method achieves better performance in terms of absolute error for 3003 datasets among the 5500 training sets, there are still nearly 40% of data samples for which the CEM–MRC method performs better. If specific scenarios can be identified with respect to when to use SCM–ANFIS and when to use CEM–MRC, then the MAPE in the testing set can be further improved. Motivated by this, we propose the EEM–CS method as shown in
Figure 4, which combines SCM–ANFIS and CEM–MRC methods and uses the classification regression method of machine learning to set up supervised learning on the training set in order to achieve intelligent selection of SCM–ANFIS or CEM–MRC in the testing set. Specifically, we expect that the classification model can accurately select the algorithm that should be used for the testing set. To this end, we set labels for the data samples in the training set based on which algorithm can achieve a smaller error as compared to the real price. However, the exact value of the recycled TV scrap is usually not known in practice, so it cannot be input to the training set for training. To solve this difficulty, we propose the use of the maximum ratio-merging algorithm to construct an auxiliary variable, denoted as
, from the estimation results of SCM–ANFIS and CEM–MRC, which is used to take the place of the real price of TV scrap as the input for the classification regression training algorithm. Algorithm 1 shows a flow chart of the proposed EEM–CS algorithm, which uses an RF algorithm to train the classification model and achieve the intelligent selection of evaluation algorithms.
| Algorithm 1: EEM–CS algorithm description. |
- 1:
Carry out one-hot coding, convert text information into coded information, so as to adapt to computer calculation - 2:
Divide 6000 sets of data into 5500 sets as training sets and 500 sets as test sets - 3:
Perform data normalization to adapt to algorithmic perception - 4:
Carry out PCA principal component analysis, and select principal components with cumulative contribution >90% for value evaluation algorithm - 5:
Carry out training algorithm on the training sets based on SCM–ANFIS, BP neural network, LSMT, T–S FNN, and random forest model, and the training results are denoted as - 6:
Calculate the weights of the different models using the maximum ratio combining algorithm, with represent the error between the estimated value and the actual value:
- 7:
The training results of the test sets are denoted as ; calculate the maximum ratio and combine the output results of the training set and test set - 8:
Mark on each data sample in the training set by 1 or 2 based on whether or has smaller error as compared to the true price respectively: - 9:
Use the maximum ratio merging algorithm 5–6 to construct the auxiliary variable price , and insert the three data into the input data set of the classification model together - 10:
Use RF algorithm to train the classification model to realize the enhanced prediction of classification selection, automatically select or in the test set, , in order to achieve reduced MAPE
|

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}