1. Introduction
In recent years, point cloud classification and segmentation methods using deep learning have dominated the field. The pioneer work in the field is the PointNet [
1], in which the point positions are fed directly to the network. After PointNet’s success, many other methods handled the problem using a deep learning approach [
2,
3,
4]. Despite the mentioned studies feeding a whole point cloud to the network in the training process, it is shown that not all points in a point cloud have the same contribution to the output of the network [
5], and using a relatively smaller amount of points, similar results could be obtained [
6]. Thus, especially for large point cloud sets, an active learning-based approach could be adopted to only use a certain count of patches in the training procedure [
7,
8,
9,
10]. A keypoint-based approach is followed, which also utilizes a relatively smaller number of points while matching the point clouds [
3,
11].
Point cloud registration, which could be defined as the calculation of the rigid transformation between multiple point clouds and aligning them, is an important problem for many computer vision tasks in robotics, autonomous driving, and 3D reconstruction [
12]. The traditional methods, like Iterative Closest Point (ICP) [
13] and other methods considering point-to-point or point-to-plane matching using only mathematical constraints [
14,
15,
16], have been replaced by learning-based methods [
3,
17,
18]. Using the deep feature representation of each point or local patch of the point cloud, feature-based metrics are involved to gain more robust matching against outliers and noises. Even though point cloud registration has achieved significant progress using the previously mentioned methods, most of them (even in the partial-to-partial point cloud registration [
19,
20,
21]) are focused on the use of the whole shape to train the network for registration. However, similarly, this problem could also be handled using active learning which was not been addressed in the literature.
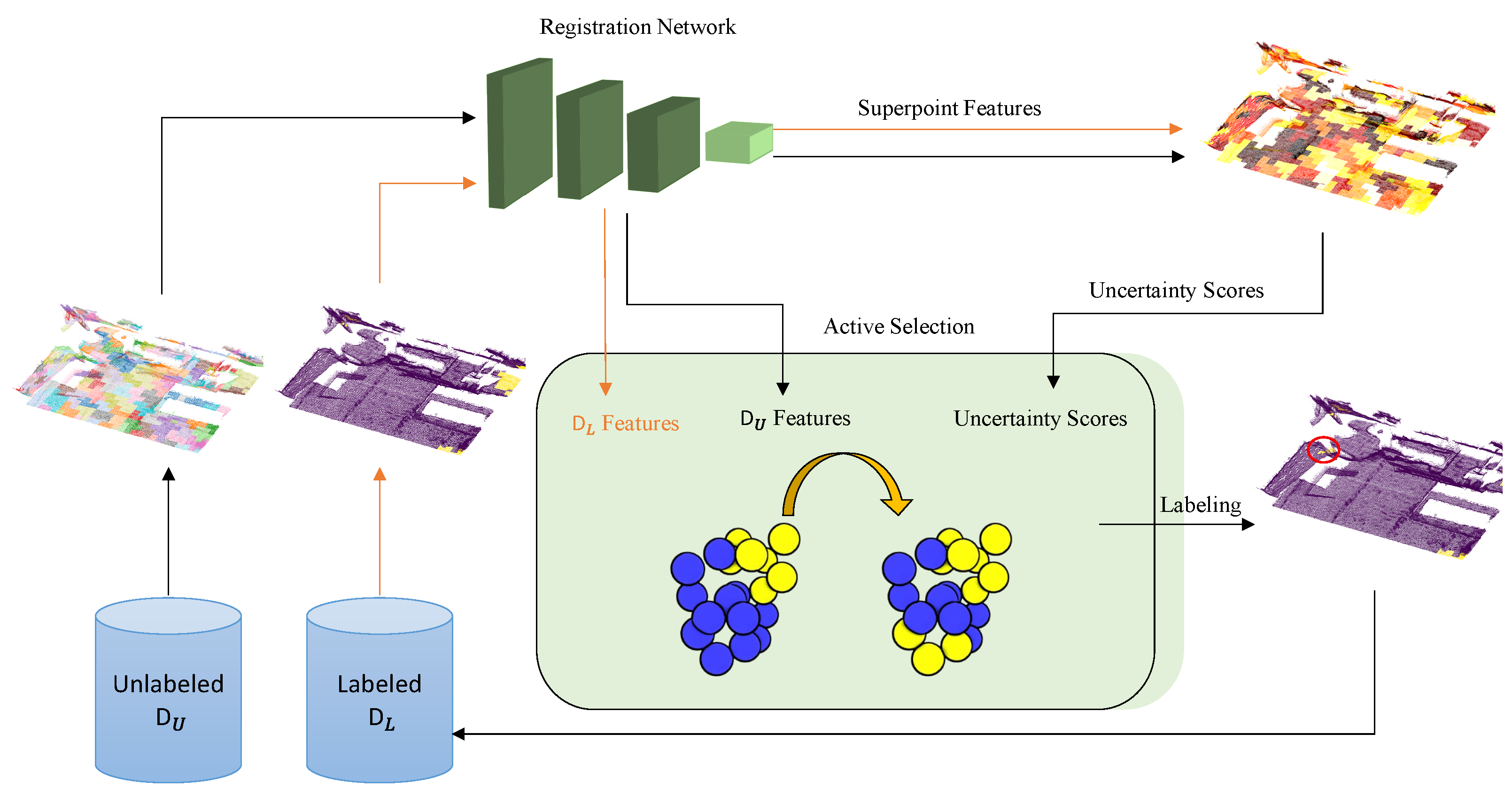
Active learning is substantially useful where data labeling is costly, and hence, only a subset of the data ought to be used in the training process. Thus, the most discriminative and diverse subset of the data should be selected. Initially, the training is started with a very small subset of the training data and, using the active learning pipeline, this subset is expanded. A simplified active learning pipeline could be considered as a three-part system: A
predictor, an
oracle, and a
guide [
22]. In the common approach, the predictor is a parametric machine learning model (e.g., a deep neural network) which is trained for the task using the labeled data (despite the traditional denomination in segmentation and classification problems, the term labeled data here refers to the data engaged in the training procedure). The guide calculates an acquisition score for each unlabeled data using a heuristic function and/or the feedback obtained from the predictor. This feedback could be simply the uncertainty/discrepancy amount of each unlabeled sample, since a sample for which the network could not reach a decision certainly, will have an impact on the construction of the network when included in the training procedure. Finally, the oracle uses the Guide’s scores and labels some of the unlabeled data according to a policy.
Instead of selecting samples from the training set, in the 2D image segmentation methods utilizing active learning [
23,
24,
25], some parts of each image could also be selected. Considering that the labeling cost of 3D segmentation is higher than its 2D counterparts, some efforts have been devoted to using active learning in point cloud segmentation [
26,
27,
28]. These studies adopted the superpoint [
29] representation where each point cloud is divided into many superpoints using an over-segmentation approach and labeled superpoints in the active learning pipeline.
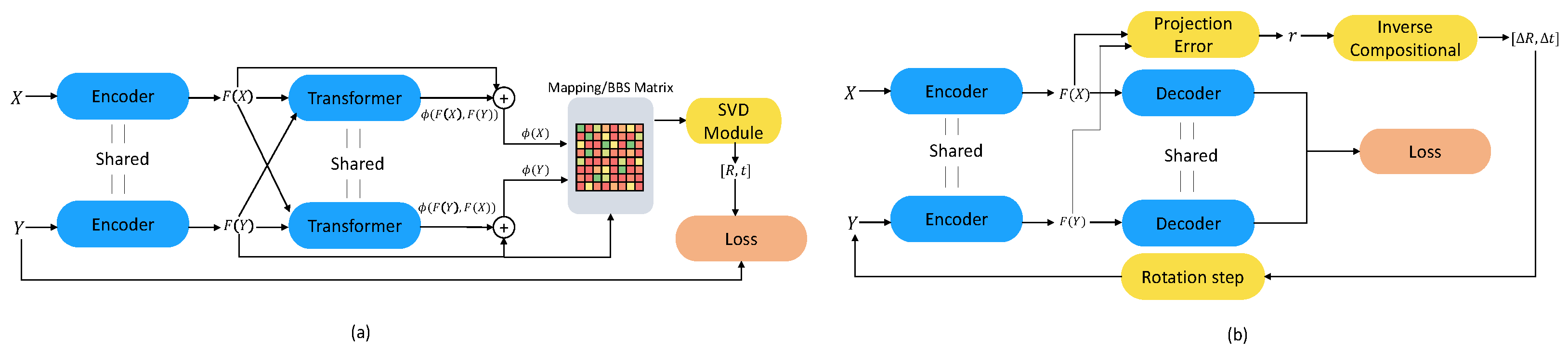
A similar approach could be applied to point cloud registration. Instead of decreasing the time budget allocated to manually label the dataset, our main aim is to decrease the training time of the network model. Since learning the rigid transform between two point clouds is equivalent to learning the transform between patches of these point clouds, the learning procedure can be altered to its superpoint variant. It is unnecessary to use similarly structured point cloud patches that have resembling features. In this study, we present ALReg, an active learning approach to efficiently use the informative regions for point cloud registration to decrease the training time. As the predictor, the baseline registration networks are modified to use Monte Carlo DropOut (MCDO) [
30] to efficiently calculate uncertainty. The guide works on each point cloud separately and calculates acquisition scores for a given point cloud’s unlabeled superpoints. The oracle provides a superpoint chosen by the guide.
Our main motivation is that, by using fewer point clouds or point cloud parts in the training phase of any point cloud registration network, a similar accuracy score could be obtained. However, it depends to the efficient selection of these training samples/parts. By the usage of ALReg, we aim the involve the most effective point cloud parts to the training procedure.
To demonstrate the effect of the ALReg, we took three deep learning-based methods as our baselines: Deep Best Buddies (DeepBBS) [
31], Feature Metric Registration (FMR) [
32] and Deep Closest Point (DCP) [
33]. As in the official papers, we evaluated FMR on 7Scenes [
34] and the other methods on ModelNet40 [
35]. To further investigate our method we also evaluated our trained FMR networks on 3DMatch [
18] as unseen data. To demonstrate the performance of ALReg extensively, we used datasets from different domains and structures. We observe in our experiments, that our method matches or outperforms other existing methods, but with significantly reduced computation time.
The three main contributions of this study are as follows:
We propose ALReg, an active learning pipeline that can be used to drastically decrease trainingtime for registration networks with either a similar performance or even an increase in terms of accuracy. Regarding the drawbacks of the overcalculations for network training for whole-to-whole point cloud registration, ALReg focuses on using only a relevant and adequate subset of superpoints during the process.
A novel uncertainty-based acquisition function that could be used to calculate superpoint uncertainties is presented. In the previous studies focusing on active learning for point cloud data, class labels were used for uncertainty calculations.
ALReg is tested on three popular registration methods (DCP, FMR, DeepBBS) for both real (7Scenes, 3DMatch) and synthetic (ModelNet) point cloud datasets. Overall, an improvement over the existing methods in terms of accuracy scores is obtained.
4. Experiments
To evaluate our method, we have done experiments using ModelNet40 (for DCP and DeepBBS) and 7Scenes (for FMR) datasets. We test the ALReg method against random selection (RAND) and also report the original results (FULL) obtained using the official source code. We performed all the experiments on a computer with an NVIDIA RTX A5000 GPU and Intel(R) Core(TM) i7-7700K CPU @ 4.20 GHz.
We used the default hyperparameters of the mentioned methods. In FMR we used Chamfer loss and geometric loss. In DCP we used an MSE based loss as
where
and
refer to ground truth rotation matrix and translation vector and
and
refer to their predictions. The last part is a network regularization. For DeepBBS, the used loss function is
where
is an indicator showing whether
and
are matching points in the source and target point clouds,
is a multiplier decreasing according to epoch number
n. Here
is selected as 0.95. For all experiments, the Adam [
83] optimizer is used with a learning rate of
and the batch size is selected as 32.
The only difference between our setup and the baselines is placing dropouts with after each layer of the encoders. After the last active selection phase, the dropouts are removed from the networks for better convergence. Active selection is done after epochs [20, 50, 70] for DCP/DeepBBS and after epochs for FMR.
For DCP (the second version containing a transformer) and FMR, the official weights are directly used. However, DeepBBS which originally uses 786 sampled points in both train and test time, is retrained using 1024 points to ensure a fair comparison. For both networks, using the common procedure, a rotation of and translation of [−0.5, 0.5] is used. For FMR, a rotation of and and translation of [−0.5, 0.5] is used following the original setup.
7Scenes is an indoor 3D scan dataset that contains 296 objects having an average of points and it has 57 test point cloud objects. Since 7Scenes is a dense dataset, in full FMR, randomly sampled 10,000 points are used during training and testing. In our active learning setup, we used VCSS [
84] algorithm to divide each object into ∼150 superpoints. For each superpoint, 20 sampled points from the superpoint are fed to the network. Initiall, 3 superpoints (60 points) of each object are used for training. After the last active selection phase, only 4.16% of the training set is selected.
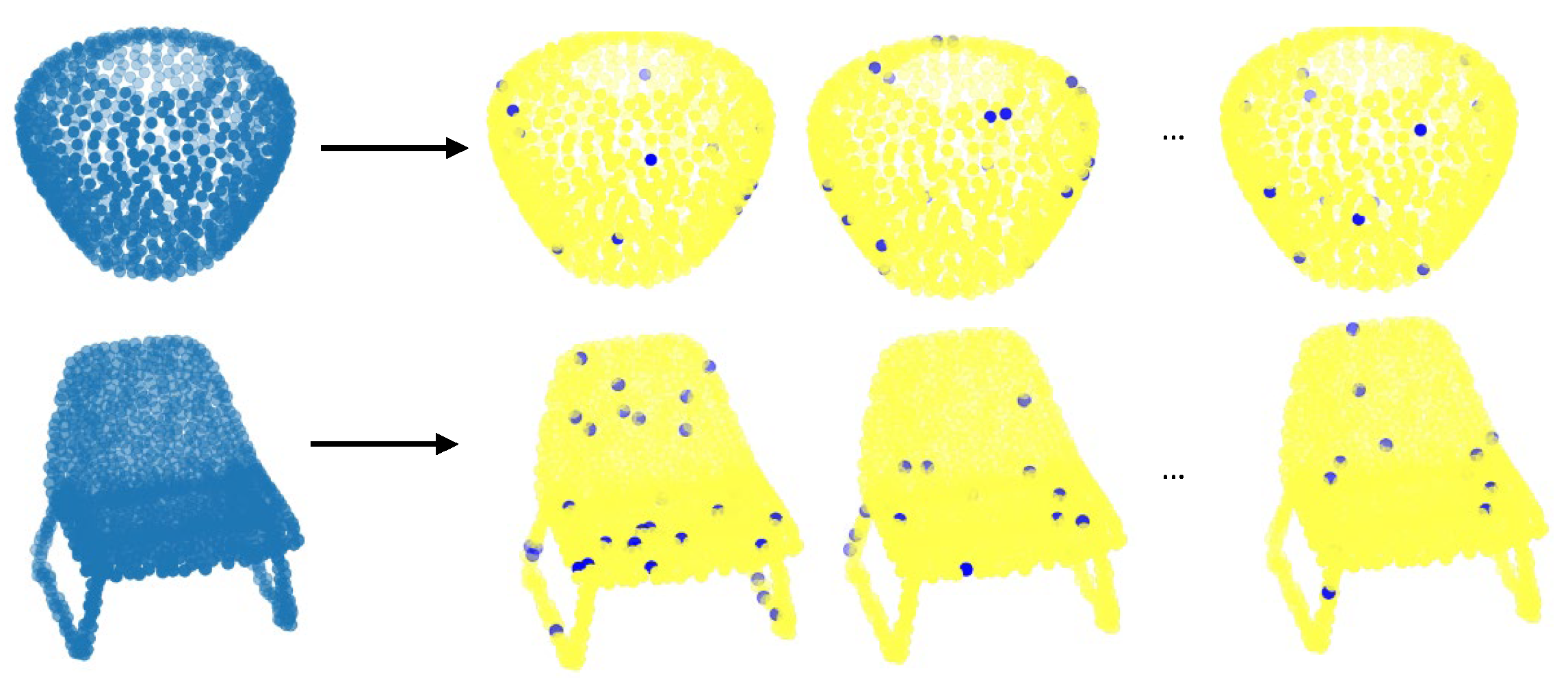
ModelNet40 is a CAD dataset of daily life objects containing 9840 training samples and 2468 test samples from 40 different categories. In the aforementioned registration methods, it is a rule of thumb to use 1024 points from CAD model for each object. Using random sampling, ∼100 superpoints are created for each object as given in
Figure 3.
After training the networks with the mentioned datasets, we also evaluated their accuracy on 3DMatch to show their consistency on unseen data. 3DMatch is a real-life scan dataset containing a total of 520 samples in its test set. Since we evaluated the dataset with the FMR setup, color information is not used and each fragment is subsampled to contain 10,000 points.
To evaluate our method, adopting the metrics from DCP [
33], mean square error (MSE), root MSE (RMSE) and mean absolute error (MAE) for rotation and transformation are used.
For the FMR training setup, the results on 7Scenes and 3DMatch datasets are given in
Table 1. As can be seen from the results, using only a limited amount of training data with both
and
, better results are obtained than random selection for 7Scenes. Also, all methods outperformed the full train scenario, which demonstrates that using all points leads to confusion for the network. Evaluating the network on 3DMatch,
method still outperforms random selection.
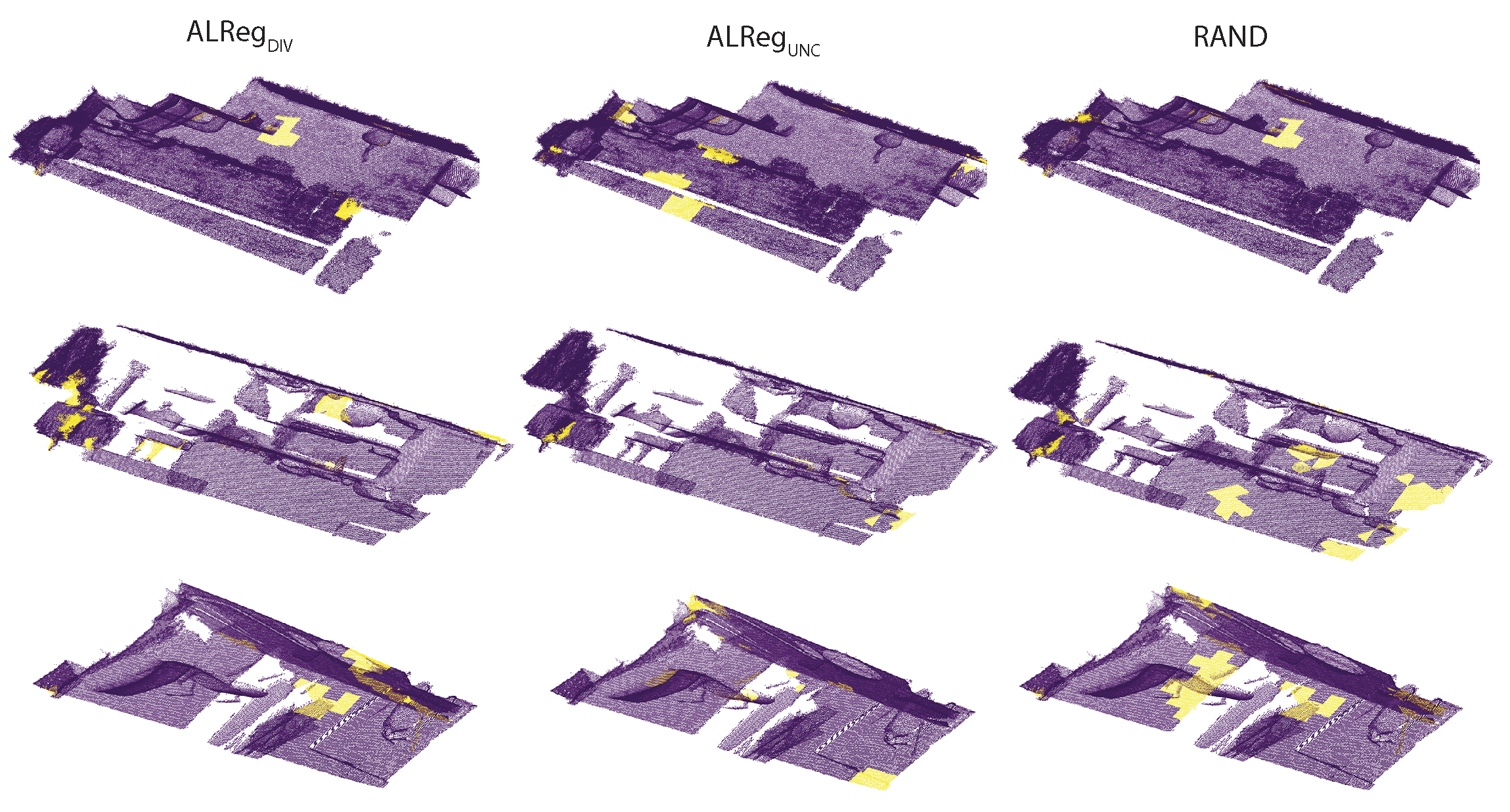
In
Figure 4, the superpoints actively selected by the different methods are visualized. Qualitatively, both
and
selected a more representative set compared to the random selection. In fact, there are many common superpoints. Considering the locations of these superpoints, it could be asserted that, selecting superpoints from the borders is a better approach than selecting randomly.
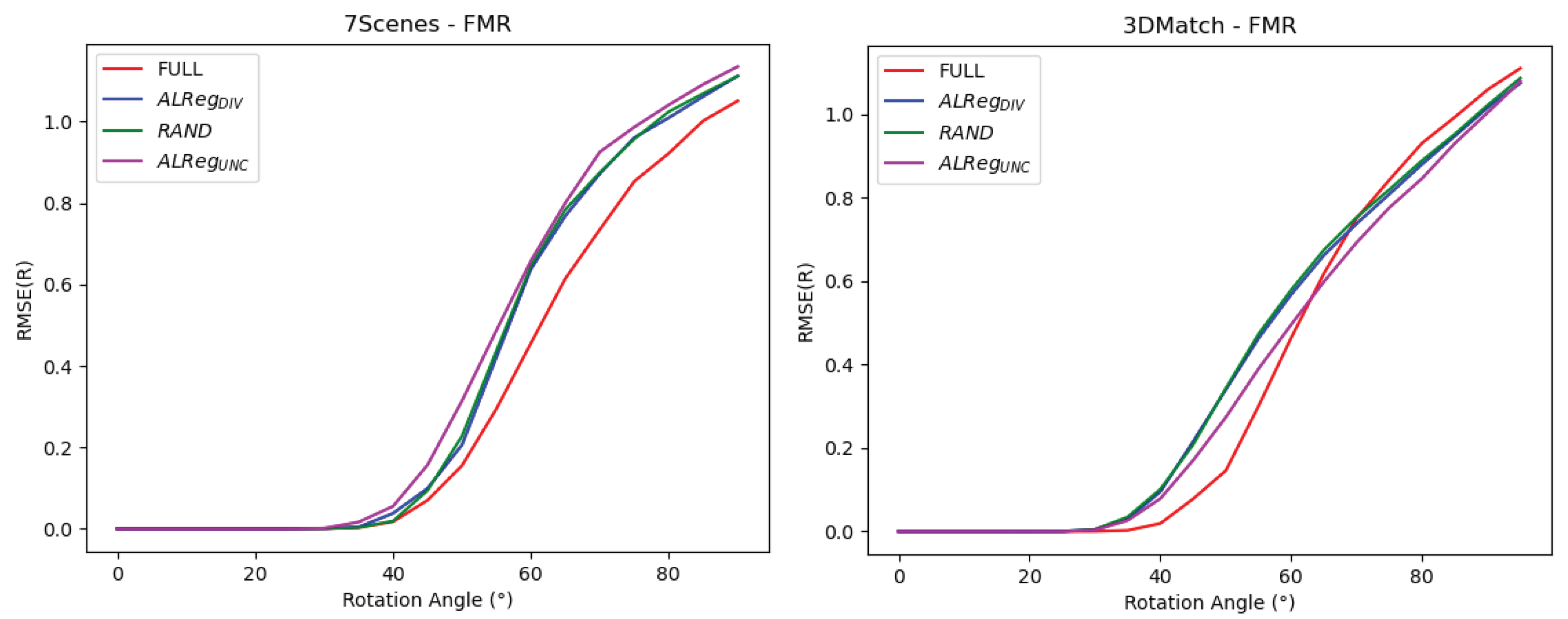
We also evaluated ALReg’s performance on FMR according to the amount of rotation starting from [0, 0, 0] to
. According to
Figure 5, even though their metric performances are worse, it is observed that for larger rotations on 3DMatch, both ALReg methods provide reduced errors than the full point cloud training.
For DCP and DeepBBS methods, the numerical results are given in
Table 2. According to the results, our
performs slightly behind performance than the full train procedure in all cases.
We also evaluated ALReg’s robustness against Gaussian noise as well as incomplete point clouds and used 7Scenes and 3DMatch as testbeds. For Gaussian noise, we jittered each point cloud with a noise of
. For incomplete point clouds, we randomly select
of each point cloud. The results for each study are as given in
Table 3 and
Table 4. In both cases, ALReg’s performance is practically similar to other methods.
In
Table 5, a comparison of training times for the full train and ALReg is given. Using limited data, ALReg achieves to decrease in the training time by 25%, 18% and 20% for FMR, DCP and DeepBBS respectively.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}