The approach, however, has its own limitations due to the particularities of the dataset. Data were collected by third parties for other purposes. We have limited information on the collection process and methodology or the validity of the information provided and how it was ensured. Missing data and errors in the values collected are challenges that we aim to address by using preprocessing techniques, to some extent, as described in the following. However, some issues cannot be fully addressed and the final model will be somewhat influenced by data inconsistencies. For example, the weekly percentage of land planted is a very general description and does not address particular cases such as replanting of an area because previous sowing failed a few weeks before (for example, affected by frost). Such an issue would change the average planting day feature and therefore influence the model. All these issues could be exacerbated by human error, at the collection phase, or lack of validation of the data.
The models were implemented using the scikit-learn 1.1.2 Python package. The average execution time for building and evaluating the model was approximately between 20 and 40 min for each of the algorithms and combination of the preprocessing techniques, on a computer with an Intel(R) Core(TM) i7-10510U CPU@1.80 GHz–2.30 GHz processor and 16.0 GB RAM.
3.2.1. Handling Missing Values for the Planting Day
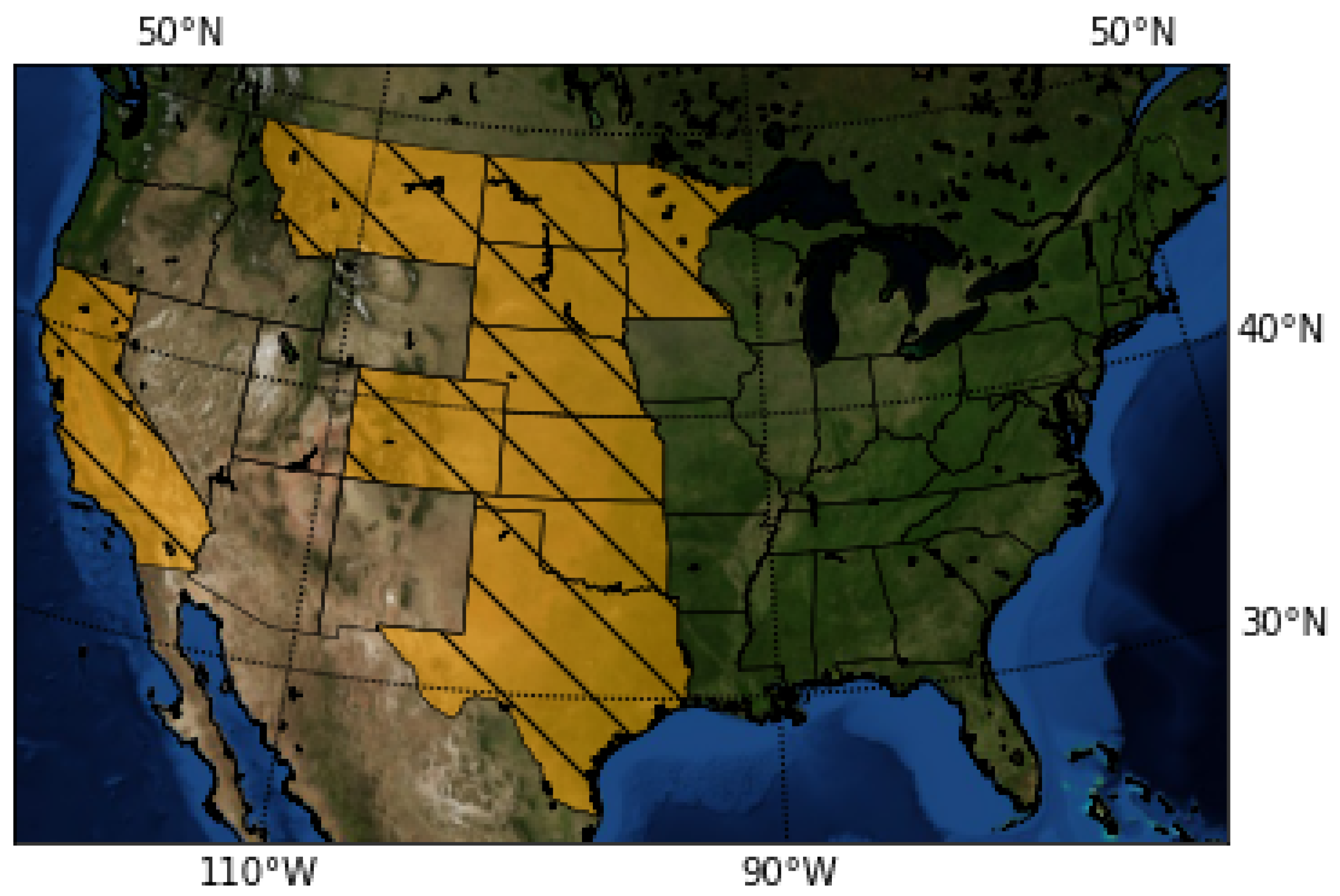
For the purpose of handling the approximately 80% of missing planting day data (14.3% of the initial crop data), we experimented with several approaches for random missing data, as described below. Considering very few studies handle large data missing rates, and the literature reveals that results depend on the dataset characteristics, pattern of missing data and data size, we used a variety of methods selected based on our literature review (
Section 2). We chose five different approaches, and up to three different methods for each (where possible) that have been used with similar datasets for univariate imputation [
13]. In
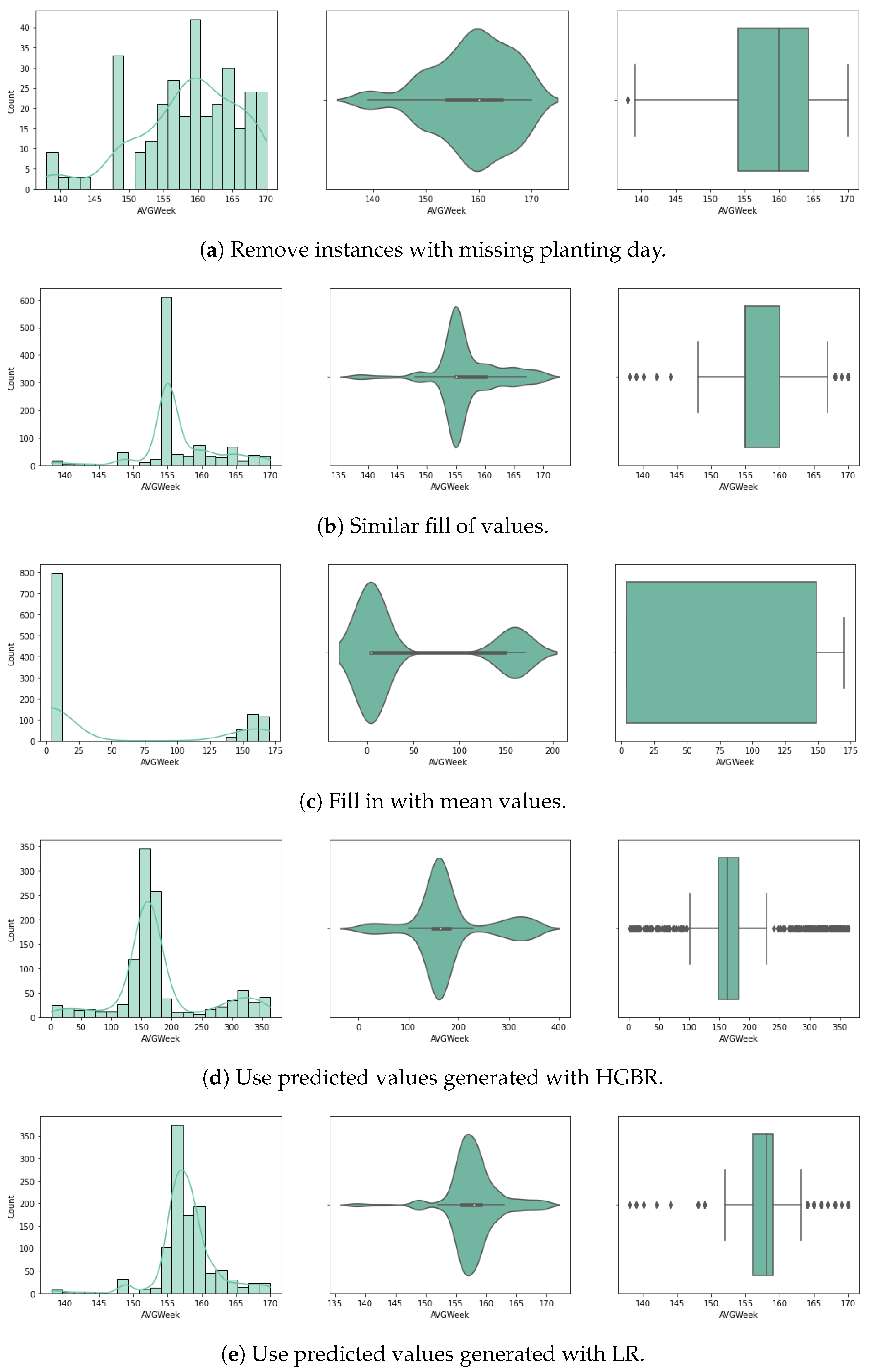
Figure 3 and
Figure 4 we visualise the value distribution graph for the planting day feature after using each method.
The first method involves the removal of incomplete instances from the dataset. While this is one of the most common approaches with incomplete data, it results in our case with the loss of 80% of our dataset, with very few remaining instances to train the models. Since the sowing day is central to our experiments in predicting the crop yield, we also considered other approaches.
The second approach is to fill the null values with adjacent ones. For this method, the forward fill () Pandas DataFrame algorithm was used. Given that the data was sorted by state, the missing values were completed with similar values of planting day for the same state, by duplicating the last existing value for that state. This method is also called hot-deck imputation. Although the values would closely correspond to real planting days for that state, given its specific climate context, the risk is that we might introduce inconsistencies corresponding with the meteorological data and yearly variations occurring that interfere with the planting day.
The third approach is to complete with mean values. For this method, we complete all missing values with the overall mean value of the planting day from the dataset. This method is commonly applied as it has the advantage of not introducing statistical changes. However, a great disadvantage is that it cannot simulate seasonality or trends.
For the fourth approach we use prediction to fill in the missing data. Several algorithms have been used to generate univariate prediction models for missing values, informed by the literature review, to perform effectively on similar data and missing data rates [
13], including (1) linear regression (LR), (2) histogram gradient boosting regressor (HGBR), (3) extreme gradient boosting tree regressor (XGBT), and (4) random forest (RF). In our case, this approach is expected to be better than using the mean values, provided that the models can predict based on all other features, with more accuracy, based on a trend expected to influence the data.
For this purpose, we have split the dataset in two: dataset A containing the instances missing the value for the planting day, and dataset B containing the complete rows. Next, we created a prediction model using dataset B for training, based on the attributes year, state ANSI, crop type and yield, with target planting day. In the next step, this model was used on dataset A to predict all the missing values for the planting day. Finally, the two datasets were joined again to be used further, together with meteorological data, to predict the yield.
The fifth method consists in the use of an interpolation method. In this approach, the null values of the planting day have been filled using interpolation. This is a statistical method for estimating unknown values based on several known points. The estimation refers to points in between the known values. Here, we used linear interpolation, which estimates a linear polynomial for curve fitting. The pad method was also used, which fills the dataset in with existing values (similar to a hot-deck imputation method). A third interpolation method is spline, which involves fitting the data to several low-degree polynomials. The implementations used in this study are part of the Python Sklearn interpolate() method, with each of the three options.
3.2.2. Handling Outliers
The purpose of outlier detection (OD) is to identify and separate outliers in a sample (anomalies from usual data) from normal data (also called inliers). This is usually an unsupervised problem, as there is not enough knowledge about the data patterns. The general scope of OD algorithms is to allow for the identification of outliers, as their removal from the dataset can be crucial to improving model performance [
26].
The crop data involved in the study contained self-reported information filled in by the farmers in a national statistics information platform. A first analysis of the data showed a small percentage (5–10%) of inconsistent or incomplete data (for example, the percentage of planting per week was not filled in for all weeks). This is normal for data collected in an uncontrolled manner. Furthermore, the missing data on planting day were completed using various methods, generating values for 80% of the instances. This is likely to have either introduced or exacerbated anomalies in the dataset.
Given these reasons, we analysed the impact of removing outliers from our data to create the prediction models. In this sense, we applied and compared the unsupervised algorithms for anomaly detection described below, chosen based on the robustness and computation requirements for the regression tasks, as found in the literature.
Isolation forest (IF) uses isolation trees to separate each instance from the rest, and compute the anomaly score from the expected path length
of each instance, with
as the average estimation path length and
defined based on
, the harmonic number.
This method is very flexible, as it has been proven to work well even in high-dimensional problems (even for a large number of irrelevant attributes), or in the case where the training set does not contain anomalies [
29]. It can be configured by the number of trees and contamination rate (expected rate of outliers in the dataset).
Minimum covariance determinant (MCD) uses a statistical covariance distance to compute a tolerance ellipse, defined as the set of
p-dimensional points
x whose Mahalanobis distance
describes the distance from the centre of the data cloud to
x [
30]. The elliptic envelope (EE) implementation in Sklearn was used in our case, as described by [
31], and requires setting the contamination rate parameter.
The Local outlier factor (LOF) approach defines LOF of an instance
p as
the degree to which we call
p an outlier, calculated as the average of the ratio of the local reachability density of
p (that is, the average reachability distance based on the MinPts-nearest neighbours of
p) and those of
p’s MinPts-nearest neighbours. The reachability distance of object
p with respect to object
o is calculated as the distance between an object and the k-neighbourhood of
p:
OneClass-SVM (OC-SVM) is a kernel-based algorithm focused on estimating the density function of the input data (K) in order to define a binary function that decides if a point is an outlier or inlier based on an anomaly detection sensitivity [
32]. In short, this involves solving a dual optimisation problem, defined formally as:
where
K is a Gaussian kernel function,
is the kernel scale, and
measures the anomaly detection sensitivity [
26]. The
hyperparameter needs to be optimised, considering a low value involves a small chance for a point to be an anomaly.
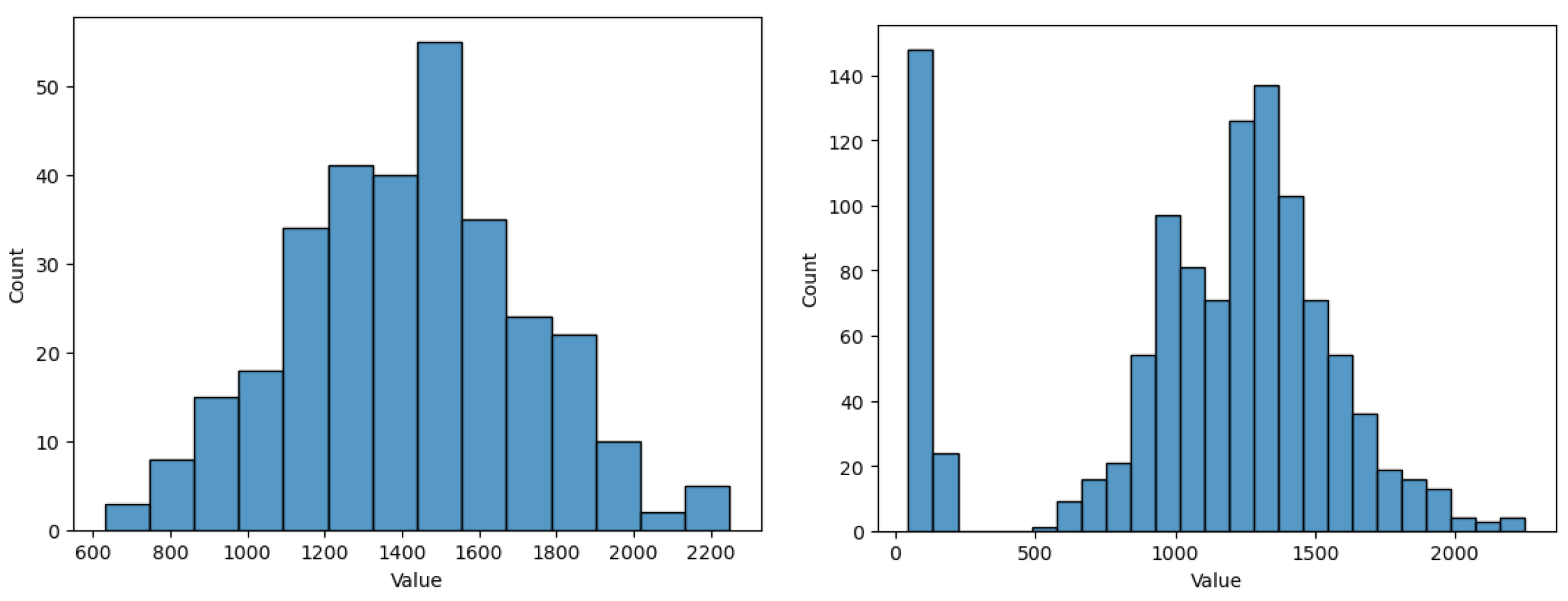
Figure 5 and
Figure 6 show the model variation for each outlier removal method with contamination rates from
to
, when using the prediction with RF as the imputation method, and the XBGT model, HGBR, for evaluation. The metric used for evaluation is
. The number of instances remaining in the dataset for each contamination rate applied, further used in model training, is presented in
Table 2. The research problem in this case is to identify the smallest contamination rate to avoid model overfitting while obtaining the best model performance.
Looking at
Figure 5 for the XGBT model, we notice that IF increases the performance constantly as the contamination rate increases, suggesting an overfitting trend, and a specialisation of the algorithms to select outliers to specialise the model. EE produces a similar variation, with the exception of a local maximum for
, suggesting that this is a good choice of the anomaly rate. On the other hand, LOF presents a local maximum for
, and then performance decreases for higher contamination rates, meaning higher contamination rates will lead to a loss of relevant information for the model. OC-SVM is similar with LOF, with the exception that the local maximum is at
.
Figure 6 presents very similar patterns for the HGBR model to those expressed in
Figure 5.
For each of the algorithms presented above, we used the Python Sklearn implementations: IF, LOF, EE (for MCD) and OC-SVM. Considering the experiments with different contamination rates and their impact on the model, the proposed candidates for the best results were 0.1, 0.2 and 0.3. Considering the literature recommendations for the contamination rate to avoid model overfitting and the limited data available in our case, we decided on the value for our future experiments. For larger datasets of this type, a better choice could be , provided it was collected similarly in an uncontrolled environment without specific validation.















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}