
A Long-Term Traffic Flow Prediction Model Based on Variational Mode Decomposition and Auto-Correlation Mechanism


Abstract
:1. Introduction
2. Related Work
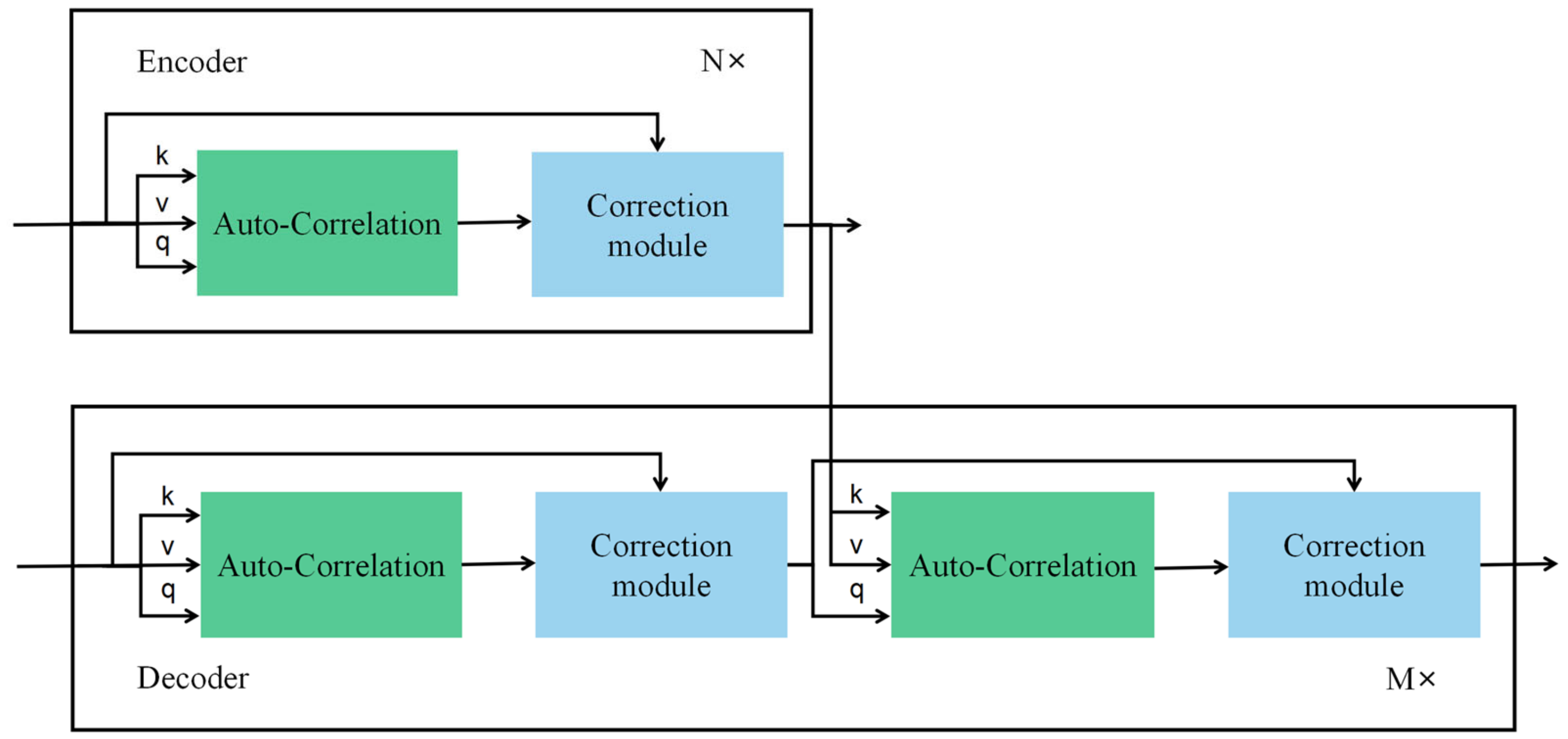
3. Model Structure
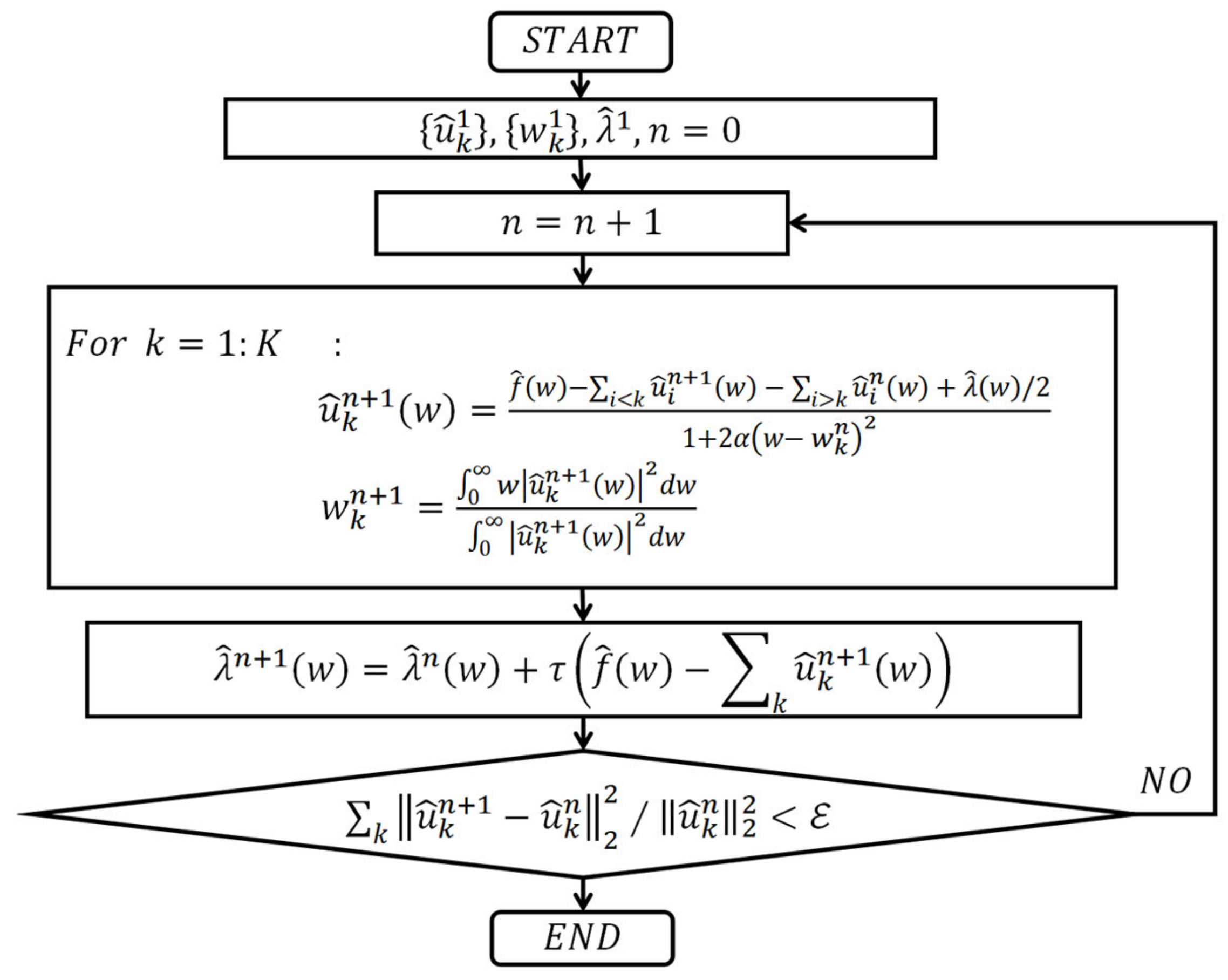
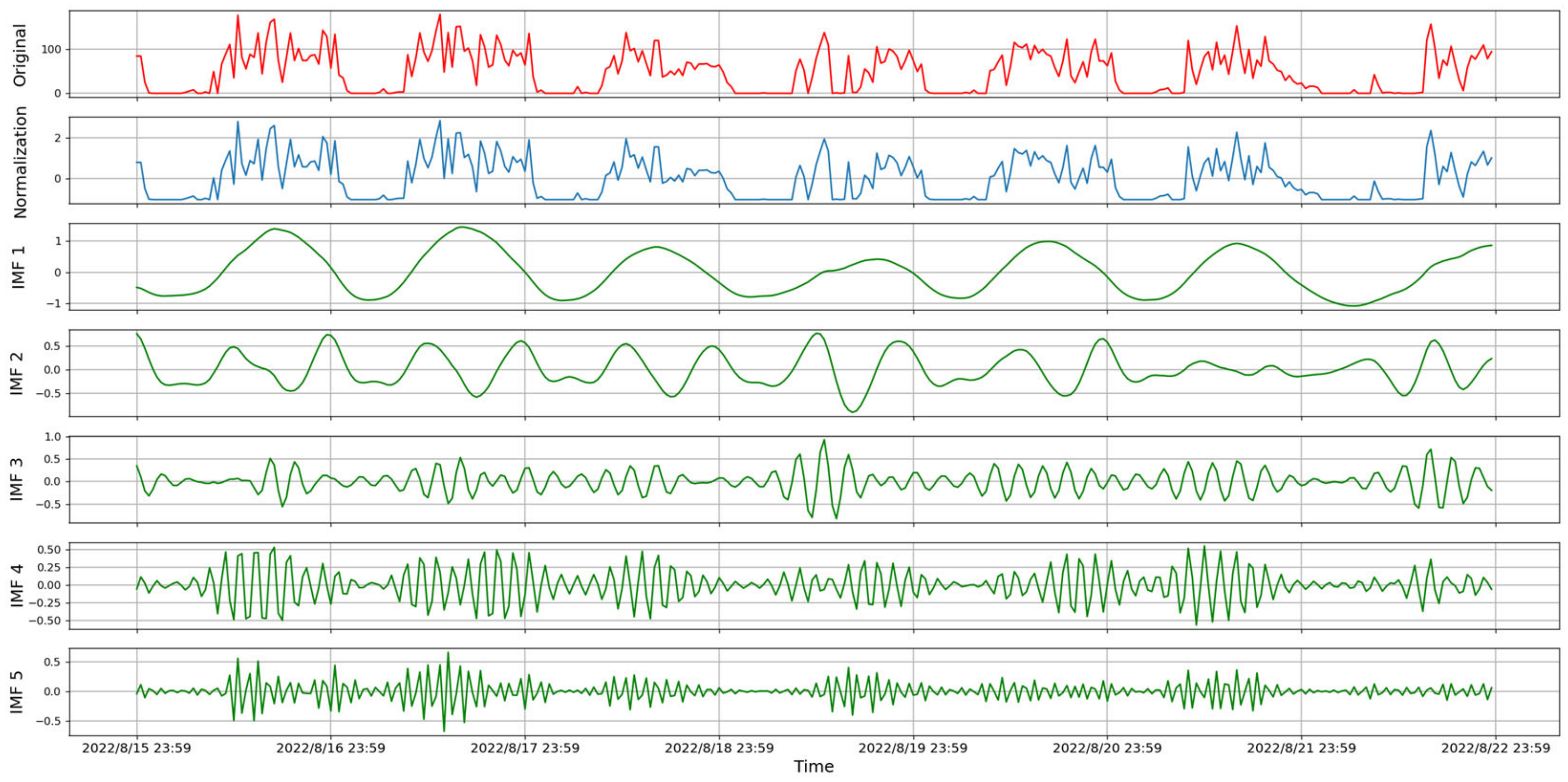
3.1. Variational Mode Decomposition
3.2. Auto-Correlation Mechanism and Correction Module
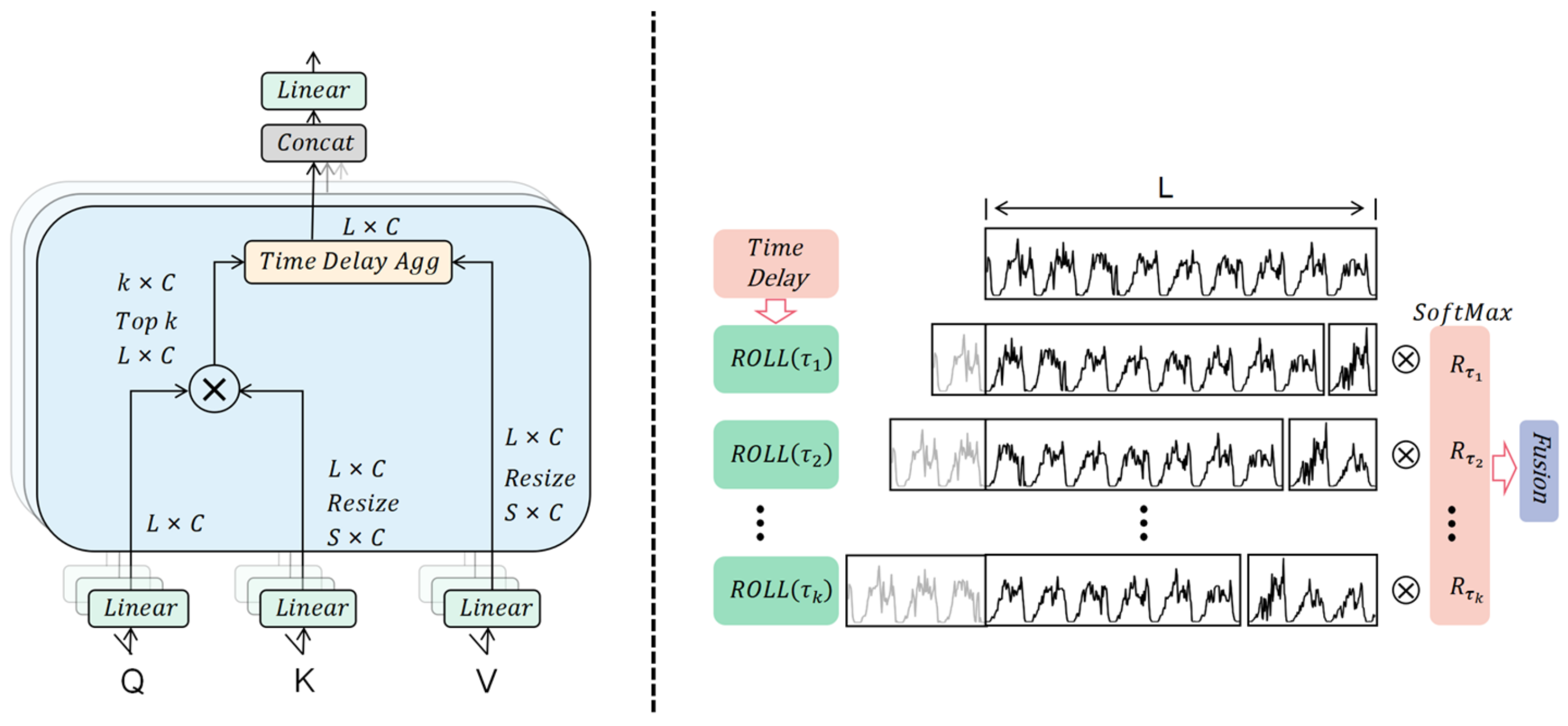
3.2.1. Auto-Correlation Mechanism
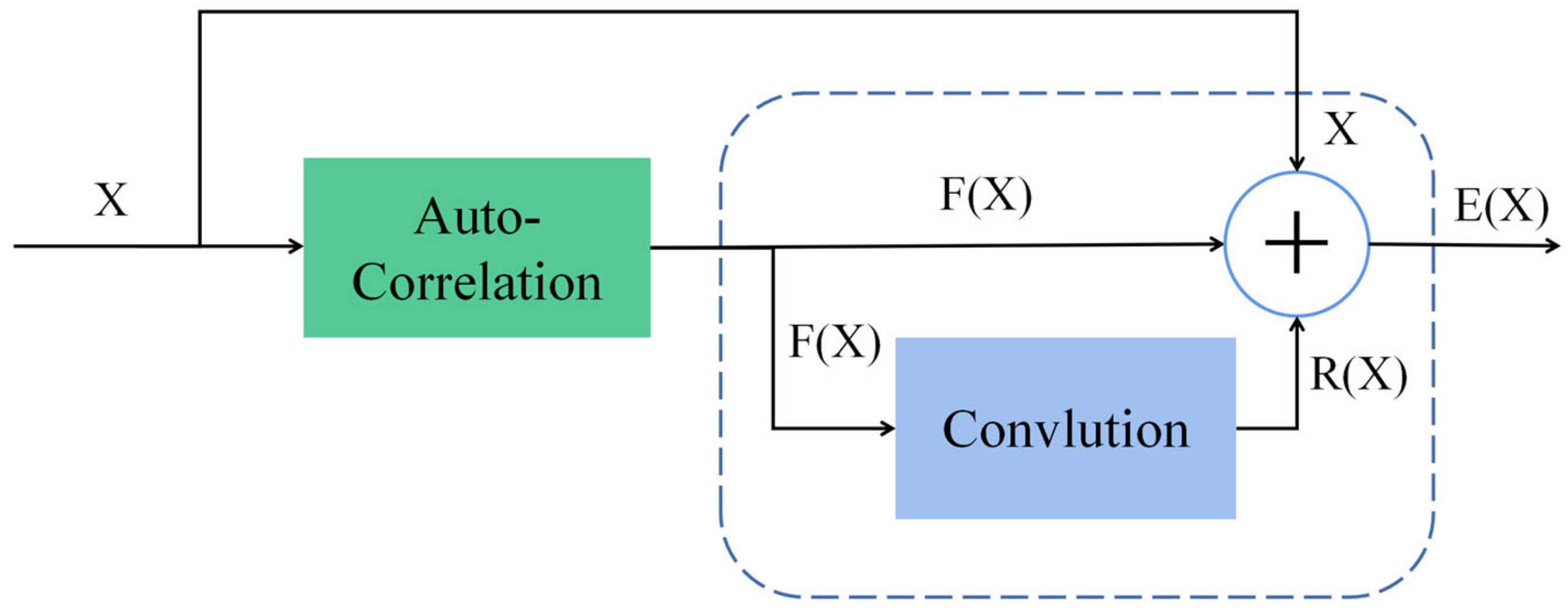
3.2.2. Correction Module
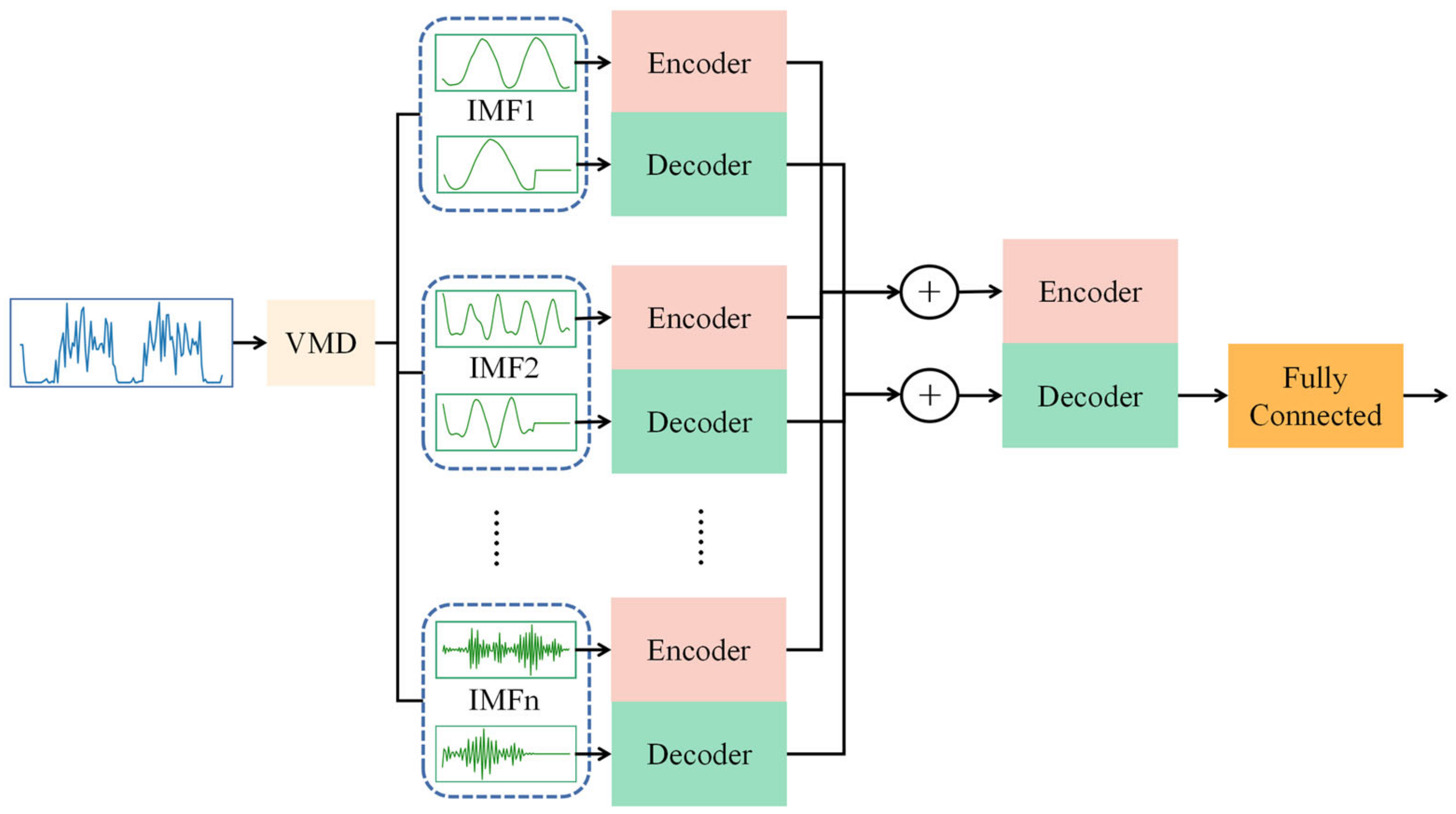
3.3. Model Framework
4. Experiment and Analysis
4.1. Experimental Data and Evaluation Indexes
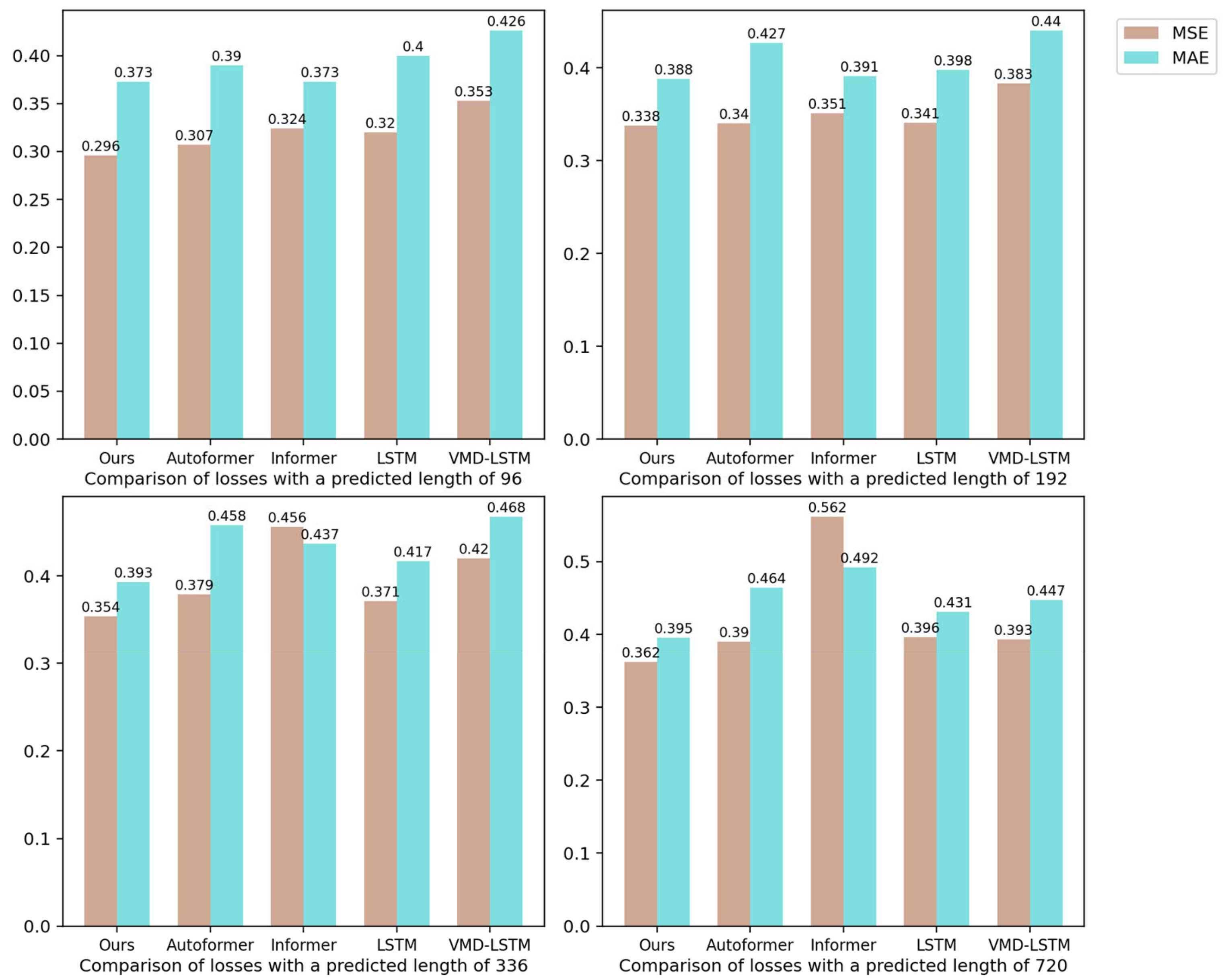
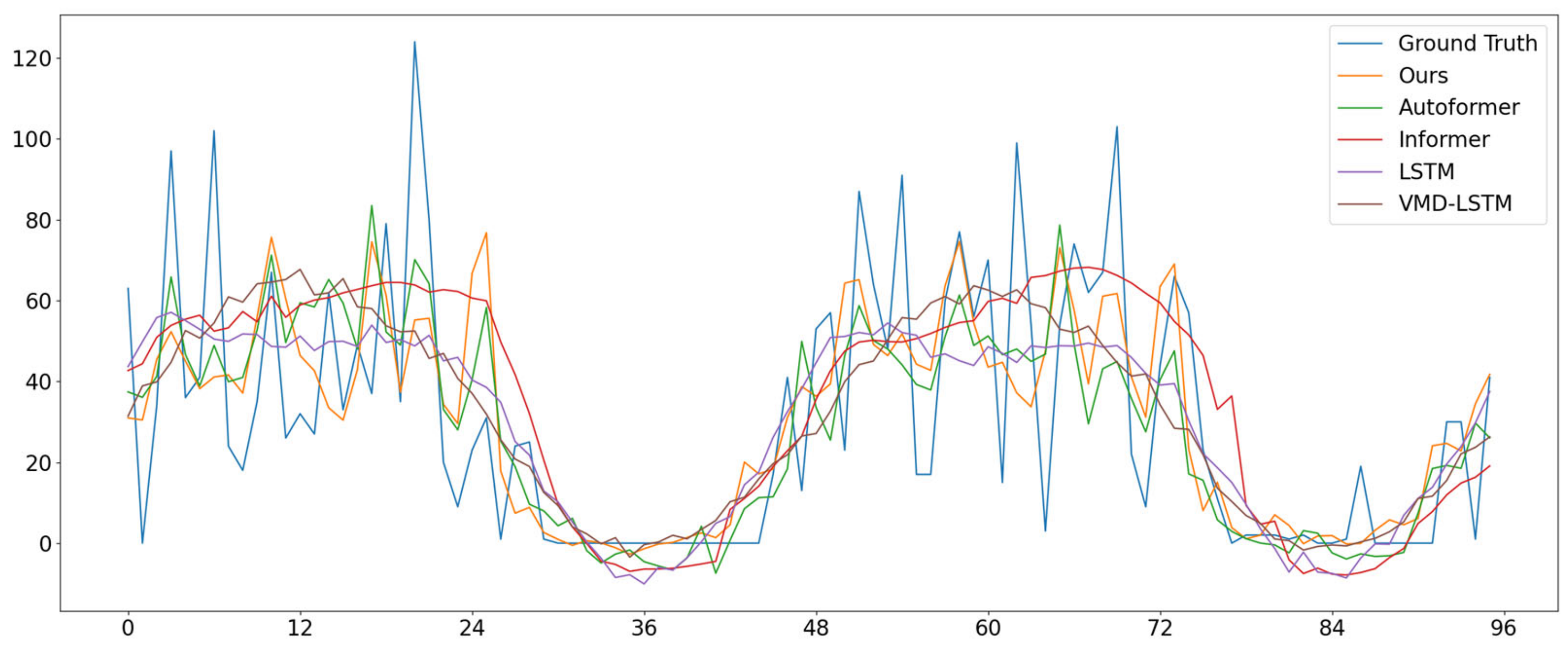
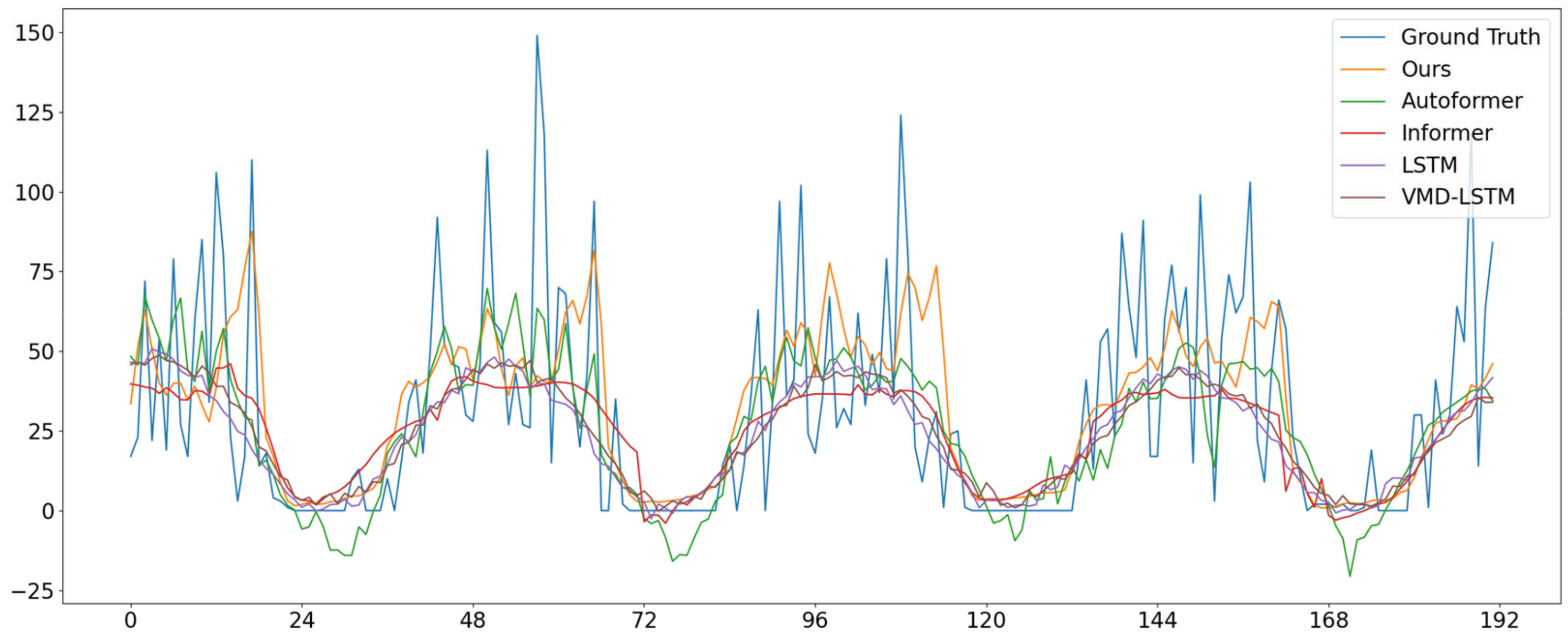
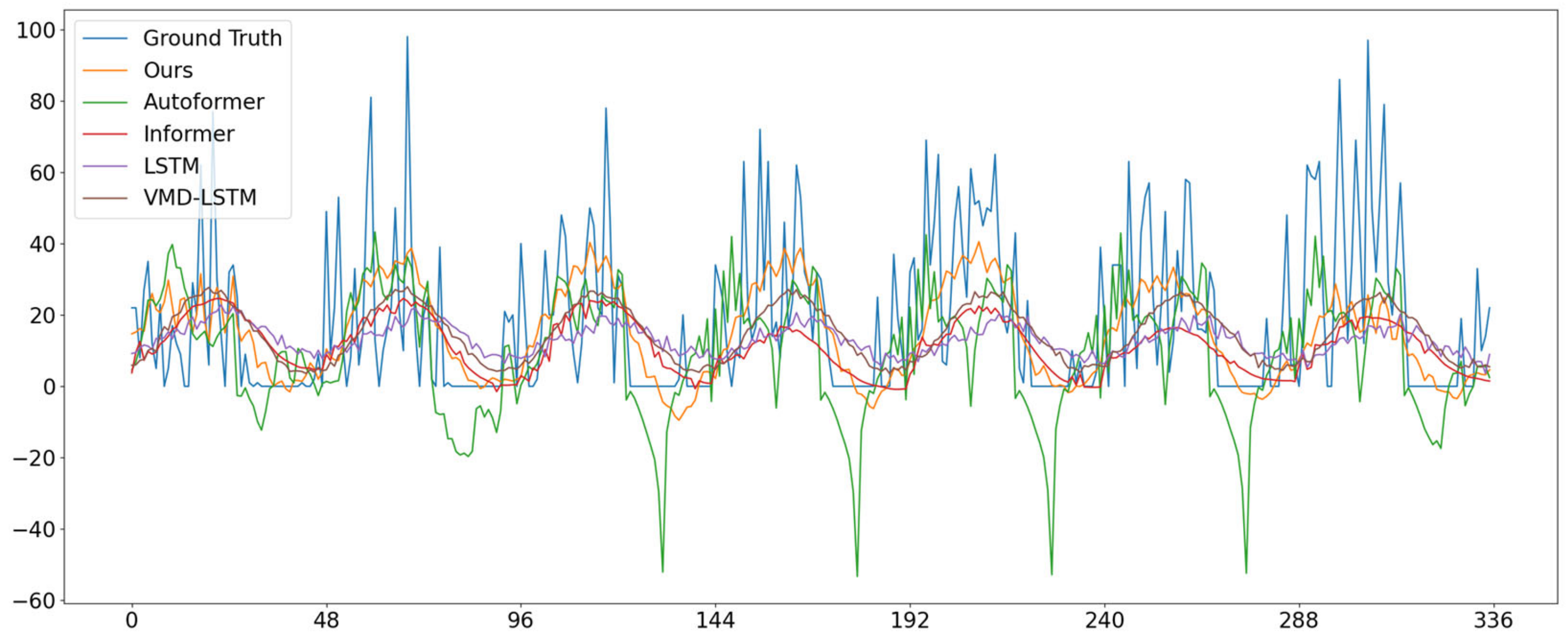
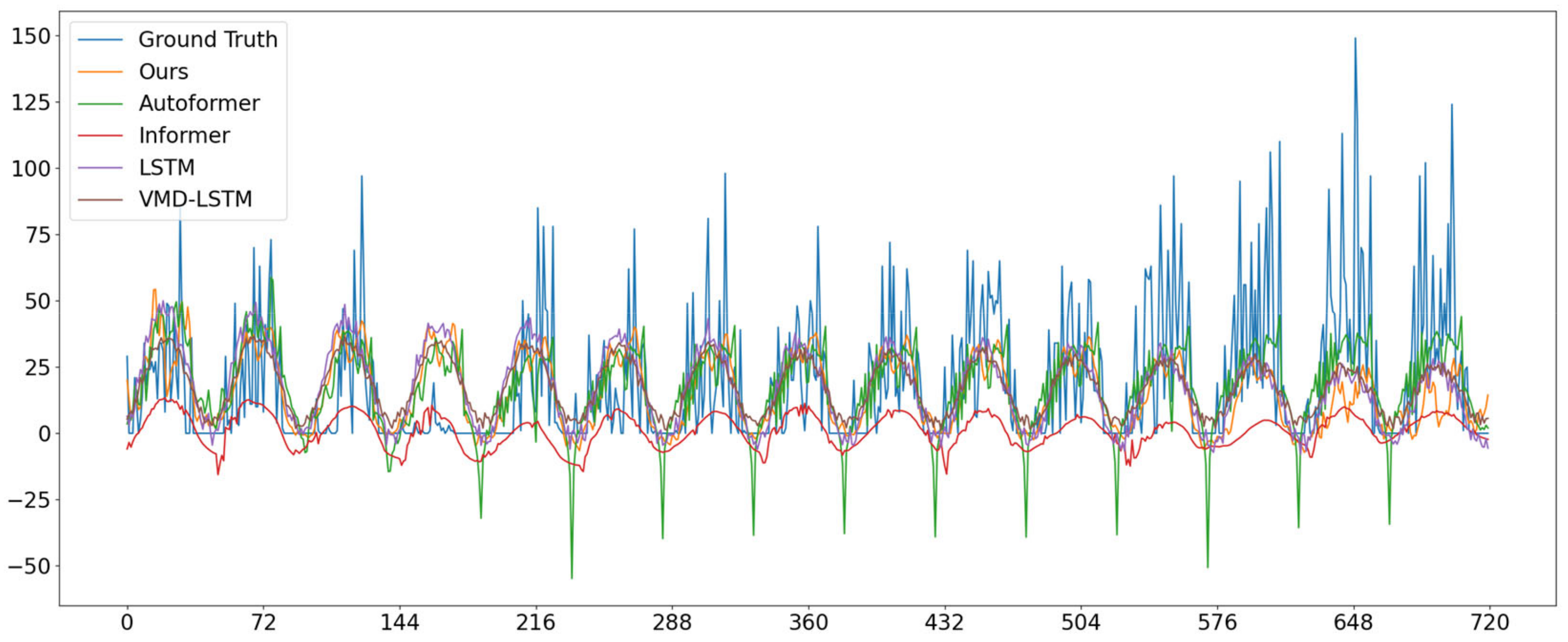
4.2. Compare Experiments
| Algorithm 1 Training process | |
| 1: = 512) | |
| 2: | |
| 3: | |
| 4: | |
| 5: | |
| 6: | |
| 7: | |
| 8: | |
| 9: | |
| 10: | |
| 11: | |
| 12: | |
| 13: | |
| 14: | |
| 15: | |
| 16: Repeat above all | |
| 17: Until the stopping criteria are met | |
| 18: Ending the program | |
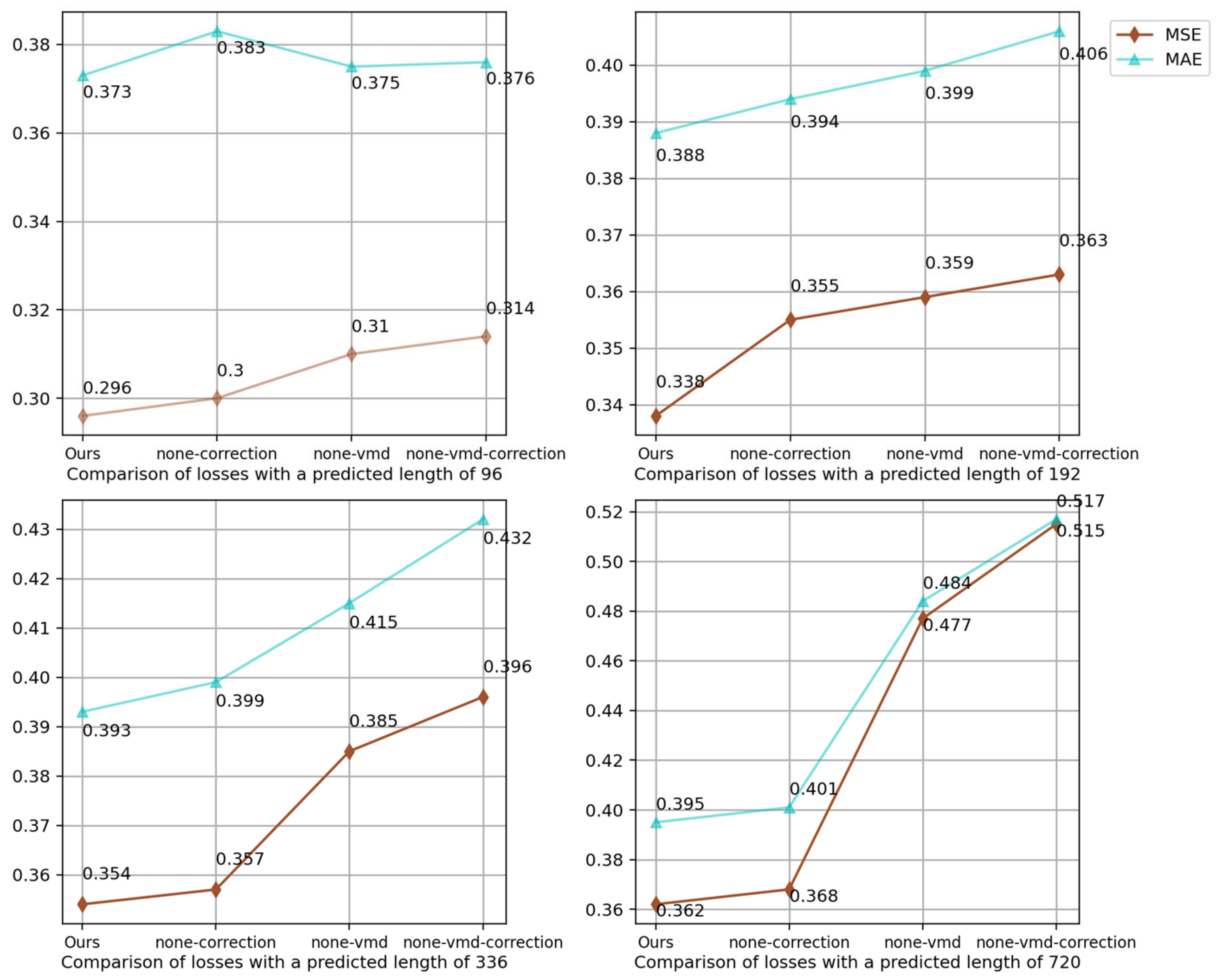
4.3. Ablation Experiments
5. Conclusions and Future Research
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- An, J.; Fu, L.; Hu, M.; Chen, W.; Zhang, J. A novel fuzzy-based convolutional neural network method to traffic flow prediction with uncertain traffic accident information. IEEE Access 2019, 7, 20708–20722. [Google Scholar] [CrossRef]
- Liu, Y.; Wang, X.; Hou, W.; Liu, H.; Wang, J. A novel hybrid model combining a fuzzy inference system and a deep learning method for short-term traffic flow prediction. Knowl.-Based Syst. 2022, 255, 109760. [Google Scholar] [CrossRef]
- Kumar, S.V.; Vanajakshi, L. Short-term traffic flow prediction using seasonal ARIMA model with limited input data. Eur. Transp. Res. Rev. 2015, 7, 21. [Google Scholar] [CrossRef] [Green Version]
- Chen, C.; Hu, J.; Meng, Q.; Zhang, Y. Short-time traffic flow prediction with ARIMA-GARCH model. In Proceedings of the 2011 4nd IEEE Conference on Intelligent Vehicles Symposium, Baden-Baden, Germany, 5–9 June 2011; pp. 607–612. [Google Scholar]
- Wei, Y.; Liu, H. Convolutional Long-Short Term Memory Network with Multi-Head Attention Mechanism for Traffic Flow Prediction. Sensors 2022, 22, 7994. [Google Scholar] [CrossRef] [PubMed]
- Zhang, L.; Lin, W. Calibration-free Traffic Signal Control Method Using Machine Learning Approaches. In Proceedings of the 2022 International Conference on Electrical, Computer and Energy Technologies (ICECET), Prague, Czech Republic, 20–22 July 2022; pp. 1–6. [Google Scholar]
- Gu, J.; Jia, Z.; Cai, T.; Song, X.; Mahmood, A. Dynamic correlation adjacency-matrix-based graph neural networks for traffic flow prediction. Sensors 2023, 23, 2897. [Google Scholar] [CrossRef]
- Braz, F.J.; Ferreira, J.; Gonçalves, F.; Weege, K.; Almeida, J.; Baldo, F.; Goncalves, P. Road traffic forecast based on meteorological information through deep learning methods. Sensors 2022, 22, 4485. [Google Scholar] [CrossRef]
- Tong, M.; Xue, H. Highway traffic volume forecasting based on seasonal ARIMA model. J. Highw. Transp. Res. Dev. Engl. Ed. 2008, 3, 109–112. [Google Scholar] [CrossRef]
- Bai, S.; Kolter, J.Z.; Koltun, V. An empirical evaluation of generic convolutional and recurrent networks for sequence modeling. arXiv 2018, arXiv:1803.01271. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Cho, K.; Van Merriënboer, B.; Bahdanau, D.; Bengio, Y. On the properties of neural machine translation: Encoder-decoder approaches. arXiv 2014, arXiv:1409.1259. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is all you need. In Proceedings of the 2017 Conference on Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; Volume 30, pp. 5998–6008. [Google Scholar]
- Huang, N.E.; Shen, Z.; Long, S.R.; Wu, M.C.; Shih, H.H.; Zheng, Q.; Yen, N.C.; Tung, C.C.; Liu, H.H. The empirical mode decomposition and the Hilbert spectrum for nonlinear and non-stationary time series analysis. Proc. R. Soc. Lond. Ser. A 1998, 454, 903–995. [Google Scholar] [CrossRef]
- Dragomiretskiy, K.; Zosso, D. Variational mode decomposition. IEEE Trans. Signal Process. 2013, 62, 531–544. [Google Scholar] [CrossRef]
- Cong, Y.; Wang, J.; Li, X. Traffic flow forecasting by a least squares support vector machine with a fruit fly optimization algorithm. Procedia Eng. 2016, 137, 59–68. [Google Scholar] [CrossRef] [Green Version]
- Zhang, L.; Alharbe, N.R.; Luo, G.; Yao, Z.; Li, Y. A hybrid forecasting framework based on support vector regression with a modified genetic algorithm and a random forest for traffic flow prediction. Tsinghua Sci. Technol. 2018, 23, 479–492. [Google Scholar] [CrossRef]
- Sun, B.; Cheng, W.; Goswami, P.; Bai, G. Short-term traffic forecasting using self-adjusting k-nearest neighbours. IET Intell. Transp. Syst. 2018, 12, 41–48. [Google Scholar] [CrossRef] [Green Version]
- Zhang, N.; Zhang, Y.; Lu, H. Short-term freeway traffic flow prediction combining seasonal autoregressive integrated moving average and support vector machines. In Proceedings of the 90th Board Annual Conference on Transportation Research, Washington, DC, USA, 23–27 January 2011; pp. 1–16. [Google Scholar]
- Cai, L.; Yu, Y.; Zhang, S.; Song, Y.; Xiong, Z.; Zhou, T. A sample-rebalanced outlier-rejected $ k $-nearest neighbor regression model for short-term traffic flow forecasting. IEEE Access 2020, 8, 22686–22696. [Google Scholar] [CrossRef]
- Zhao, W.; Gao, Y.; Ji, T.; Wan, X.; Ye, F.; Bai, G. Deep temporal convolutional networks for short-term traffic flow forecasting. IEEE Access 2019, 7, 114496–114507. [Google Scholar] [CrossRef]
- Yang, B.; Sun, S.; Li, J.; Lin, X.; Tian, Y. Traffic flow prediction using LSTM with feature enhancement. Neurocomputing 2019, 332, 320–327. [Google Scholar] [CrossRef]
- Ali, A.; Zhu, Y.; Zakarya, M. A data aggregation based approach to exploit dynamic spatio-temporal correlations for citywide crowd flows prediction in fog computing. Multimed. Tools. Appl. 2021, 80, 31401–31433. [Google Scholar] [CrossRef]
- Luo, X.; Li, D.; Yang, Y.; Zhang, S. Spatiotemporal traffic flow prediction with KNN and LSTM. J. Adv. Transp. 2019, 2019, 4145353. [Google Scholar] [CrossRef] [Green Version]
- Zhao, Z.; Chen, W.; Wu, X.; Chen, P.C.Y.; Liu, J. LSTM network: A deep learning approach for short-term traffic forecast. IET Intell. Transp. Syst. 2017, 11, 68–75. [Google Scholar] [CrossRef] [Green Version]
- Liu, Y.; Zheng, H.; Feng, X.; Chen, Z. Short-term traffic flow prediction with Conv-LSTM. In Proceedings of the 2017 9th International Conference on Wireless Communications and Signal Processing (WCSP), Nanjing, China, 11–13 October 2017; pp. 1–6. [Google Scholar]
- Fu, R.; Zhang, Z.; Li, L. Using LSTM and GRU neural network methods for traffic flow prediction. In Proceedings of the 2016 31st Youth Academic Annual Conference of Chinese Association of Automation (YAC), Wuhan, China, 11–13 November 2016; pp. 324–328. [Google Scholar]
- Zhaowei, Q.; Haitao, L.; Zhihui, L.; Tao, Z. Short-term traffic flow forecasting method with MB-LSTM hybrid network. IEEE Trans. Intell. Transp. Syst. 2020, 23, 225–235. [Google Scholar] [CrossRef]
- Zhou, H.; Zhang, S.; Peng, J.; Zhang, S.; Li, J.; Xiong, H.; Zhang, W. Informer: Beyond effificient transformer for long sequence time-series forecasting. Proc. AAAI Conf. Artif. Intell. 2021, 35, 11106–11115. [Google Scholar] [CrossRef]
- Wu, H.; Xu, J.; Wang, J.; Long, M. Autoformer: Decomposition transformers with auto-correlation for long-term series forecasting. Adv. Neural Inf. Process. Syst. 2021, 34, 22419–22430. [Google Scholar]
- Zhou, T.; Ma, Z.; Wen, Q.; Wang, X.; Sun, L.; Jin, R. Fedformer: Frequency enhanced decomposed transformer for long-term series forecasting. arXiv 2022, arXiv:2201.12740. [Google Scholar]
- Hao, W.; Sun, X.; Wang, C.; Chen, H.; Huang, L. A hybrid EMD-LSTM model for non-stationary wave prediction in offshore China. Ocean Eng. 2022, 246, 110566. [Google Scholar] [CrossRef]
- Li, Y.; Chai, S.; Ma, Z.; Wang, G. A hybrid deep learning framework for long-term traffic flow prediction. IEEE Access 2021, 9, 11264–11271. [Google Scholar] [CrossRef]
- Huang, Y.; Deng, Y. A new crude oil price forecasting model based on variational mode decomposition. Knowl.-Based Syst 2021, 213, 106669. [Google Scholar] [CrossRef]
- Niu, H.; Xu, K.; Wang, W. A hybrid stock price index forecasting model based on variational mode decomposition and LSTM network. Appl. Intell. 2020, 50, 4296–4309. [Google Scholar] [CrossRef]
- Hu, H.; Wang, L.; Tao, R. Wind speed forecasting based on variational mode decomposition and improved echo state network. Renew. Energ. 2021, 164, 729–751. [Google Scholar] [CrossRef]
- Zhang, Z.; Hong, W.C. Application of variational mode decomposition and chaotic grey wolf optimizer with support vector regression for forecasting electric loads. Knowl.-Based Syst. 2021, 228, 107297. [Google Scholar] [CrossRef]
- Bing, Q.; Shen, F.; Chen, X.; Zhang, W.; Hu, Y.; Qu, D. A hybrid short-term traffic flow multistep prediction method based on variational mode decomposition and long short-term memory model. Discrete Dyn. Nat. Soc. 2021, 2021, 4097149. [Google Scholar] [CrossRef]
- Liu, H.; Zhang, X.; Yang, Y.; Li, Y.; Yu, C. Hourly traffic flow forecasting using a new hybrid modelling method. J. Cent. South Univ. 2022, 29, 1389–1402. [Google Scholar] [CrossRef]
- Tang, J.; Chien, Y.R. Research on Wind Power Short-Term Forecasting Method Based on Temporal Convolutional Neural Network and Variational Modal Decomposition. Sensors 2022, 22, 7414. [Google Scholar] [CrossRef]
- Cai, C.; Li, Y.; Su, Z.; Zhu, T.; He, Y. Short-Term Electrical Load Forecasting Based on VMD and GRU-TCN Hybrid Network. Appl. Sci. 2022, 12, 6647. [Google Scholar] [CrossRef]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Time | Acquisition Frequency | Total Number | Splitting Strategy | ||
|---|---|---|---|---|---|---|
| Train Validation Test | ||||||
| BACT | 15 August 2022–31 December 2022 | 30 min | 6600 | 0–3960 | 3960–5280 | 5280–6600 |
| K | IMF1 | IMF2 | IMF3 | IMF4 | IMF5 | IMF6 | IMF7 | IMF8 |
|---|---|---|---|---|---|---|---|---|
| 2 | 0.02011 | 0.25129 | ||||||
| 3 | 0.01700 | 0.04149 | 0.33699 | |||||
| 4 | 0.01844 | 0.04184 | 0.25042 | 0.33892 | ||||
| 5 | 0.01845 | 0.10044 | 0.17884 | 0.26595 | 0.41738 | |||
| 6 | 0.01788 | 0.04046 | 0.10638 | 0.25459 | 0.33735 | 0.42155 | ||
| 7 | 0.02001 | 0.03570 | 0.06523 | 0.18236 | 0.25355 | 0.33450 | 0.42184 | |
| 8 | 0.01869 | 0.03885 | 0.10596 | 0.18952 | 0.27130 | 0.32840 | 0.37020 | 0.43156 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Guo, K.; Yu, X.; Liu, G.; Tang, S. A Long-Term Traffic Flow Prediction Model Based on Variational Mode Decomposition and Auto-Correlation Mechanism. Appl. Sci. 2023, 13, 7139. https://doi.org/10.3390/app13127139
Guo K, Yu X, Liu G, Tang S. A Long-Term Traffic Flow Prediction Model Based on Variational Mode Decomposition and Auto-Correlation Mechanism. Applied Sciences. 2023; 13(12):7139. https://doi.org/10.3390/app13127139
Chicago/Turabian StyleGuo, Kaixin, Xin Yu, Gaoxiang Liu, and Shaohu Tang. 2023. "A Long-Term Traffic Flow Prediction Model Based on Variational Mode Decomposition and Auto-Correlation Mechanism" Applied Sciences 13, no. 12: 7139. https://doi.org/10.3390/app13127139