
An Optimized Approach to Translate Technical Patents from English to Japanese Using Machine Translation Models

Abstract
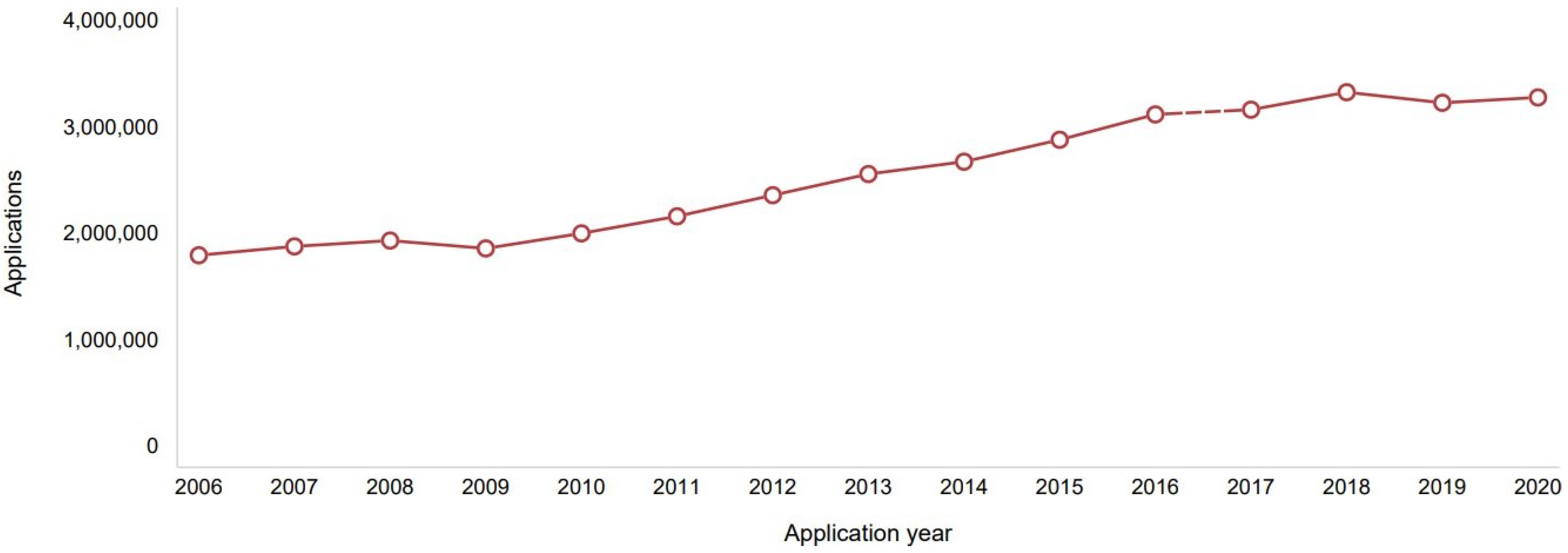
:1. Introduction
- To solve the problem of translating technical multi-domain patents, from English to Japanese, the performance of different MT models with varying parameters are evaluated.
- Start from the best-performing model to develop and implement a novel multi-step approach to fine-tune models to improve accuracy in patent translation.
- The offered model is able to overcome consistent problems for the problem at hand, including lexical ambiguity and sentence structure challenges, as indicated by superior BLEU score performance compared to previous solutions to this problem.
2. Machine Translation Approaches
2.1. Rule-Based Machine Translation
2.2. Statistical Machine Translation
2.3. Neural Machine Translation
3. English-to-Japanese Patent Machine Translation
4. Evaluation Methods
4.1. BLEU
4.2. NIST
4.3. WER
4.4. METEOR
5. Related Works
6. Methodology
6.1. Computing Setup
6.2. Approach I: Transformer Model with Attention
6.3. Approach II: Pre-Trained Hugging Face Models
6.4. Dataset Used for Fine-Tuning
7. Results
7.1. Result I: NLP-Model-I
7.2. Result II: NLP-Model-II
7.3. Result III: NLP-Model-III
8. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Somers, H. Machine Translation: History, Development, and Limitations. In The Oxford Handbook of Translation Studies; Malmkjær, K., Windle, K., Eds.; Oxford Academic: Oxford, UK, 2012. [Google Scholar] [CrossRef]
- Weaver, W. Translation. In Proceedings of the Conference on Mechanical Translation, 1952. Available online: https://aclanthology.org/volumes/1952.earlymt-1/ (accessed on 10 January 2023).
- Newsmantraa. Machine Translation Market to Observe Exponential Growth by 2022 to 2030: Microsoft Corporation, IBM. Digital Journal, 14 June 2022. Available online: https://www.digitaljournal.com/pr/machine-translation-market-to-observe-exponential-growth-by-2022-to-2030-microsoft-corporation-ibm (accessed on 10 January 2023).
- Bianchi, C. Everything You Should Know about Patent Translation, the Professional Translation Blog. Language Buró, 20 October 2020. Available online: https://languageburo.com/blog/everything-to-know-about-patent-translation (accessed on 8 February 2023).
- Galvani, T.W. Accuracy and Precision in Patent Writing. 30 August 2019. Available online: https://galvanilegal.com/accuracy-and-precision-in-patent-writing/ (accessed on 11 February 2023).
- Okpor, M.D. Machine Translation Approaches: Issues and Challenges. Int. J. Comput. Sci. Issues (IJCSI) 2014, 11, 159–165. [Google Scholar]
- Poibeau, T. Machine Translation; MIT Press: Cambridge, MA, USA, 2017. [Google Scholar]
- Garg, A.; Agarwal, M. Machine translation: A literature review. arxiv 2018, arXiv:1901.01122. [Google Scholar]
- Tsarfaty, R.; Seddah, D.; Goldberg, Y.; Kuebler, S.; Versley, Y.; Candito, M.; Foster, J.; Rehbein, I.; Tounsi, L. Statistical parsing of morphologically rich languages (spmrl) what, how and whither. In Proceedings of the NAACL HLT 2010 First Workshop on Statistical Parsing of Morphologically-Rich Languages, Los Angeles, CA, USA, 5 June 2010; pp. 1–12. [Google Scholar]
- Stahlberg, F. Neural machine translation: A review. J. Artif. Intell. Res. 2020, 69, 343–418. [Google Scholar] [CrossRef]
- Tan, Z.; Wang, S.; Yang, Z.; Chen, G.; Huang, X.; Sun, M.; Liu, Y. Neural machine translation: A review of methods, resources, and tools. AI Open 2020, 1, 5–21. [Google Scholar] [CrossRef]
- Cifka, O. Continuous Sentence Representations in Neural Machine Translation; Institute of Formal and Applied Linguistics: Prague, Czech Republic, 2018. [Google Scholar]
- Collobert, R.; Weston, J. A unified architecture for natural language processing: Deep neural networks with multitask learning. In Proceedings of the 25th international conference on Machine learning, Helsinki, Finland, 5–9 July 2008; pp. 160–167. [Google Scholar]
- Yousuf, H.; Lahzi, M.; Salloum, S.A.; Shaalan, K. A systematic review on sequence-to-sequence learning with neural network and its models. Int. J. Electr. Comput. Eng. (IJECE) 2021, 11, 2315. [Google Scholar] [CrossRef]
- Brownlee, J. How Does Attention Work in Encoder-Decoder Recurrent Neural Networks. MachineLearningMastery.com. 2019. Available online: https://machinelearningmastery.com/how-does-attention-work-in-encoder-decoder-recurrent-neural-networks/ (accessed on 9 January 2023).
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention Is All You Need. Advances in Neural Information Processing Systems. 2017. Available online: https://proceedings.neurips.cc/paper_files/paper/2017/file/3f5ee243547dee91fbd053c1c4a845aa-Paper.pdf (accessed on 9 January 2023).
- Compton, E. Analyzing Japanese with Natural Language Processing and Go. Medium, 19 June 2018. Available online: https://medium.com/@enocom/analyzing-japanese-with-natural-language-processing-and-go-64b26cb2436 (accessed on 9 January 2023).
- Nagao, M. A Framework of a Mechanical Translation between Japanese and English by Analogy Principle. Available online: https://aclanthology.org/www.mt-archive.info/70/Nagao-1984.pdf (accessed on 9 January 2023).
- Barchas-Lichtenstein, J. Low and High Context Communication. CultureReady, 1 March 2016. Available online: https://www.cultureready.org/blog/low-and-high-context-communication (accessed on 9 January 2023).
- Shih, J. Linguistic differences between Japanese and English. JBI Localization, 13 October 2020. Available online: https://jbilocalization.com/linguistic-differences-japanese-english/ (accessed on 9 January 2023).
- Lauffer, S.; Harold, S. (Eds.) Computers and Translation: A Translator’s Guide; John Benjamins Publishing Company: Philadelphia, PA, USA, 2003; 349p. [Google Scholar]
- WIPO. World Intellectual Property Indicators 2021; World Intellectual Property Organization: Geneva, Switzerland, 2021. [Google Scholar]
- Nitoń-Greczuk, E. Things to Know about Patent Translation: Textology. WeAreTextoloxy, 16 December 2022. Available online: https://wearetextology.com (accessed on 9 January 2023).
- Madhavan, R. Machine Translation—14 Current Applications and Services. Emerj Artificial Intelligence Research, 22 November 2019. Available online: https://emerj.com/ai-sector-overviews/machine-translation-14-current-applications-and-services/ (accessed on 10 January 2023).
- Pricing Translator: Microsoft Azure. Available online: https://azure.microsoft.com/en-us/pricing/details/cognitive-services/translator/#pricing (accessed on 10 January 2023).
- 2021 Top 50 US Patent Assignees. IFI CLAIMS® Patent Services. Available online: https://www.ificlaims.com/rankings-top-50-2021.htm (accessed on 10 January 2023).
- Chatzikoumi. How to evaluate machine translation: A review of automated and human metrics. Nat. Lang. Eng. 2020, 26, 137–161. [Google Scholar] [CrossRef]
- Panić, M. Automated Mt Evaluation Metrics. TAUS, 22 July 20200. Available online: https://www.taus.net/resources/blog/automated-mt-evaluation-metrics (accessed on 11 January 2023).
- Evaluating Models. Google. Available online: https://cloud.google.com/translate (accessed on 11 January 2023).
- Dorr, B.; Snover, M.; Madnani, N. Part 5: Machine translation evaluation. Handb. Nat. Lang. Process. Mach. Transl. DARPA Glob. Auton. Lang. Exploit 2011, 801–887. [Google Scholar]
- Doshi, K. Foundations of NLP explained. Medium, 11 May 2021. Available online: https://towardsdatascience.com (accessed on 11 January 2023).
- Vashee, K. Understanding Machine Translation Quality: BLEU Scores. 12 April 2019. Available online: https://www.rws.com/blog/understanding-mt-quality-bleu-scores/ (accessed on 11 January 2023).
- Chauhan, S.; Daniel, P. A comprehensive survey on various fully automatic machine translation evaluation metrics. Neural Process. Lett. 2022, 1–55. [Google Scholar] [CrossRef]
- Zhang, Y.; Vogel, S.; Waibel, A. Interpreting bleu/nist scores: How much improvement do we need to have a better system? In Proceedings of the LREC. 2004. Available online: http://www.lrec-conf.org/proceedings/lrec2004/pdf/755.pdf (accessed on 12 January 2023).
- The Trustees of Princeton University. WordNet. Princeton University. Available online: https://wordnet.princeton.edu/ (accessed on 12 January 2023).
- Poornima, C.; Dhanalakshmi, V.; Anand, K.M.; Soman, K.P. Rule based sentence simplification for english to tamil machine translation system. Int. J. Comput. Appl. 2011, 25, 38–42. [Google Scholar]
- Terumasa, E. Rule Based Machine Translation Combined with Statistical Post Editor for Japanese to English Patent Translation. In Proceedings of the Workshop on Patent translation. 2007. Available online: https://aclanthology.org/2007.mtsummit-wpt.4.pdf (accessed on 12 January 2023).
- Şatır, E.; Bulut, H. A Novel Hybrid Approach to Improve Neural Machine Translation Decoding using Phrase-Based Statistical Machine Translation. In Proceedings of the 2021 International Conference on INnovations in Intelligent SysTems and Applications (INISTA), Kocaeli, Turkey, 25–27 August 2021; IEEE: Piscataway Township, NJ, USA, 2021; pp. 1–5. [Google Scholar]
- Artetxe, M.; Labaka, G.; Agirre, E.; Cho, K. Unsupervised neural machine translation. arXiv 2017, arXiv:1710.11041. [Google Scholar]
- Bharadwaj, S.; Janardhanan, M.T.; Minkuri, P. Translation of Japanese to English language. GitHub. 2020. Available online: https://github.com/bharadwaj1098/Machine_Translation (accessed on 12 January 2023).
- Team AI. Japanese-English Bilingual Corpus. Kaggle. 2017. Available online: https://www.kaggle.com/datasets/team-ai/japaneseenglish-bilingual-corpus (accessed on 12 January 2023).
- Tab-Delimited Bilingual Sentence Pairs from the Tatoeba Project. Available online: https://www.manythings.org/anki/ (accessed on 12 January 2023).
- Neural Machine Translation Background. Tutorial: Neural Machine Translation—seq2seq. Available online: https://google.github.io/seq2seq/nmt/ (accessed on 12 January 2023).
- Helsinki-NLP/Opus-Tatoeba-en-ja. Helsinki-NLP/opus-tatoeba-en-ja · Hugging Face. Available online: https://huggingface.co/Helsinki-NLP/opus-tatoeba-en-ja (accessed on 12 January 2023).
- Tiedemann, J. The Tatoeba Translation Challenge–Realistic Data Sets for Low Resource and Multilingual MT. arXiv 2020, arXiv:2010.06354. [Google Scholar]
- The Open Parallel Corpus. Available online: https://opus.nlpl.eu/ (accessed on 12 January 2023).
- Tiedemann, J. Parallel data, tools, and interfaces in OPUS. In Proceedings of Eighth International Conference on Language Resources and Evaluation (LREC’12), Istanbul, Turkey, 21–27 May 2012; Volume 2012, pp. 2214–2218. [Google Scholar]
- Collection of Sentences and Translations, Tatoeba. Available online: https://tatoeba.org/en/ (accessed on 12 January 2023).
- Japanese-English Subtitle Corpus. JESC, 12 May 2019. Available online: https://nlp.stanford.edu/projects/jesc/ (accessed on 12 January 2023).
- Neubig, G. The Kyoto Free Translation Task (KFTT). The Kyoto Free Translation Task. Available online: http://www.phontron.com/kftt/ (accessed on 12 January 2023).
- Tanaka Corpus—EDRDG Wiki. Available online: http://www.edrdg.org/wiki/index.php/TanakaCorpus (accessed on 12 January 2023).
- Japanese SNLI Dataset. Available online: https://nlp.ist.i.kyoto-u.ac.jp (accessed on 12 January 2023).
- Facebookresearch. GitHub. 2019. Available online: https://github.com/facebookresearch/LASER/tree/main/tasks/WikiMatrix (accessed on 12 January 2023).
- Team, A.I. Japanese-English Bilingual Corpus of Wikipedia’s Kyoto Articles [Data Set]. Kaggle. 2018. Available online: https://www.kaggle.com/datasets/team-ai/japaneseenglish-bilingual-corpus (accessed on 12 January 2023).
- Novak, M. (2012, May 29). The Cold War Origins of Google Translate. BBC Future. Available online: https://www.bbc.com/future/article/20120529-a-cold-war-google-translate (accessed on 9 January 2023).



{kind=link}
{kind=link}
| Evaluation Metric | Advantages | Disadvantages |
|---|---|---|
| BLEU |
| |
| NIST |
|
|
| WER |
| |
| METEOR |
| Relative Pronouns | Who, which, whose, whom |
| Coordinating conjunction | For, and, not, but, or, yet, so |
| Subordinating conjunction | After, although, because, before, if, since, that, though, unless, where, wherever, when, whenever, whereas, while, why |
| Model | Parameters | Dataset | BLEU |
|---|---|---|---|
| NLP-Model-I |
| Japanese–English Bilingual Corpus [54] and Japanese–English sentence pairs [42] | |
| NLP-Model-II |
| tatoeba mt [45] | |
| NLP-Model-III |
| tailored patent dataset (Not publicly available) | 46.8 |
| Model | English (Original) | Japanese (After Translation) |
|---|---|---|
| NLP-Model-I | The car scheduling server receives a ride request sent by the client. | The no break Izu NAGATA suffering? Six a ? military shop She Please—not because The have n’t OK I I I am—such good I I I are I I I good I—Bus—Bus restaurant I I—while home sha—while home Tokyo—while home studying delicious the I I—not He could not He Monday delicious not He could wearing " mother and not He could |
| NLP-Model-II | The present invention provides a carbon dioxide absorbent during combustion of fossil fuels comprising a pressed dry powder of plant fibers, and a fossil fuel characterized by comprising of such a pressed dry powder of plant fibers. | The present invention is characterized by absorbing carbon dioxide during the combustion of fossil fuels comprising a pressed dry powder of plant fibers, drying the plant fibers in such a way as to produce fossil fuels. We supply. |
| NLP-Model-III | The present invention provides a carbon dioxide absorbent during combustion of fossil fuels comprising a pressed dry powder of plant fibers, and a fossil fuel characterized by comprising such a pressed dry powder of plant fibers. | The present invention provides a carbon dioxide absorbent at the time of combustion of fossil fuels containing a compressed dry powder of plant fibers, and such a compressed dry powder of plant fibers. |
| Hyperparameters | Experiment 1 | Experiment 2 | Experiment 3 |
|---|---|---|---|
| Learning rate | 0.1 | 0.01 | 0.0001 |
| Weight decay | 0.1 | 0.001 | 0.0001 |
| Batch size | 8 | 16 | 32 |
| BLEU | 33.32 | 31.22 | 34.74 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ahmed, M.; Ouda, A.; Abusharkh, M.; Kohli, S.; Rai, K. An Optimized Approach to Translate Technical Patents from English to Japanese Using Machine Translation Models. Appl. Sci. 2023, 13, 7126. https://doi.org/10.3390/app13127126
Ahmed M, Ouda A, Abusharkh M, Kohli S, Rai K. An Optimized Approach to Translate Technical Patents from English to Japanese Using Machine Translation Models. Applied Sciences. 2023; 13(12):7126. https://doi.org/10.3390/app13127126
Chicago/Turabian StyleAhmed, Maimoonah, Abdelkader Ouda, Mohamed Abusharkh, Sandeep Kohli, and Khushwant Rai. 2023. "An Optimized Approach to Translate Technical Patents from English to Japanese Using Machine Translation Models" Applied Sciences 13, no. 12: 7126. https://doi.org/10.3390/app13127126