

Cascaded Convolutional Recurrent Neural Networks for EEG Emotion Recognition Based on Temporal–Frequency–Spatial Features
Abstract
:Featured Application
Abstract
1. Introduction
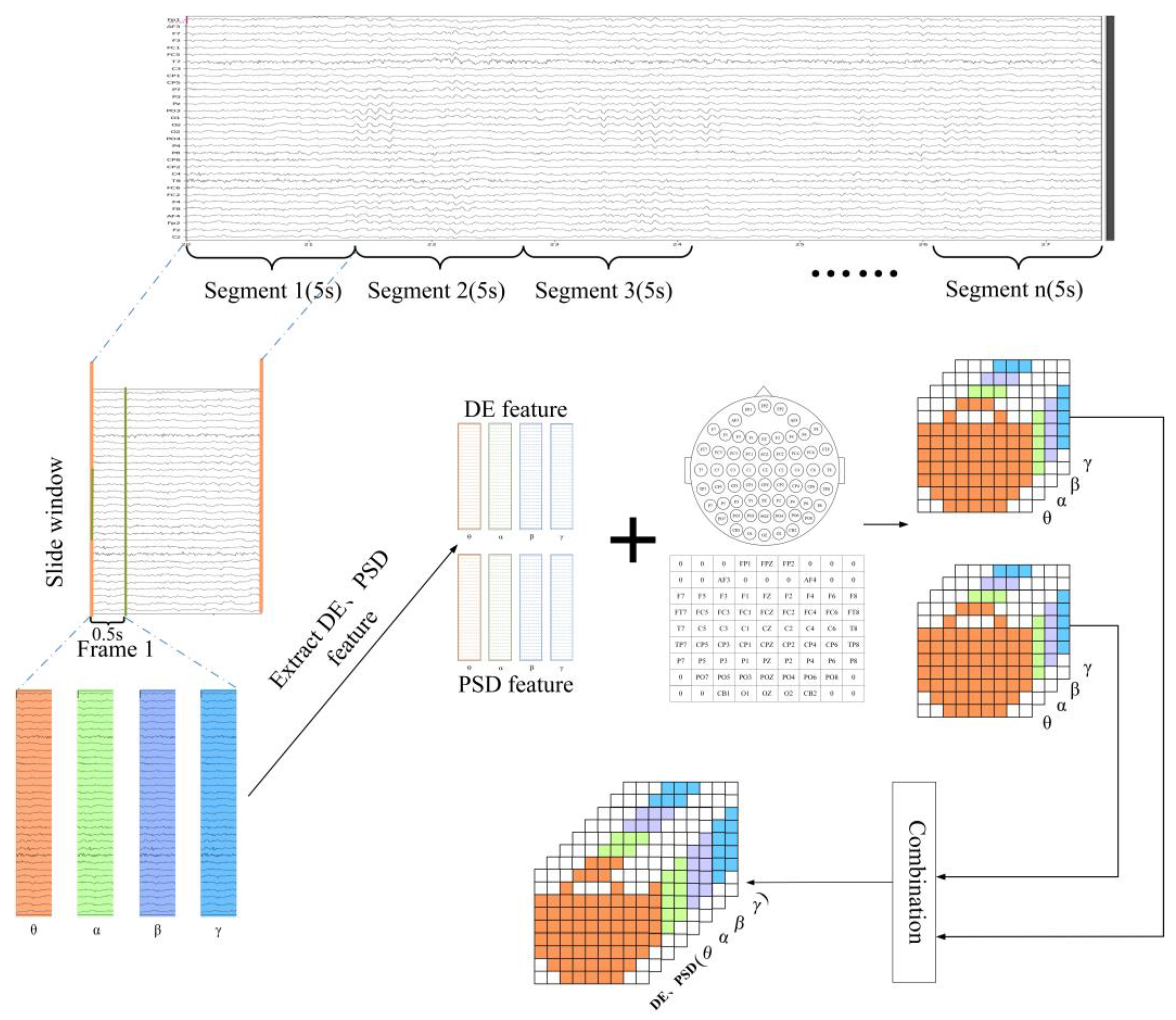
- EEG data are converted into a 4D matrix structure consisting of multiple frames, which contain information in three dimensions: temporal, frequency, and spatial, and can effectively represent the neural features of different emotions.
- In this paper, a novel attention module FcaNet is introduced. FcaNet redistributes the weights of different channels to obtain high-quality discrimination. FcaNet is found to be superior to traditional channel attention squeeze-and-excitation networks (SENet) while incurring no significant computational cost.
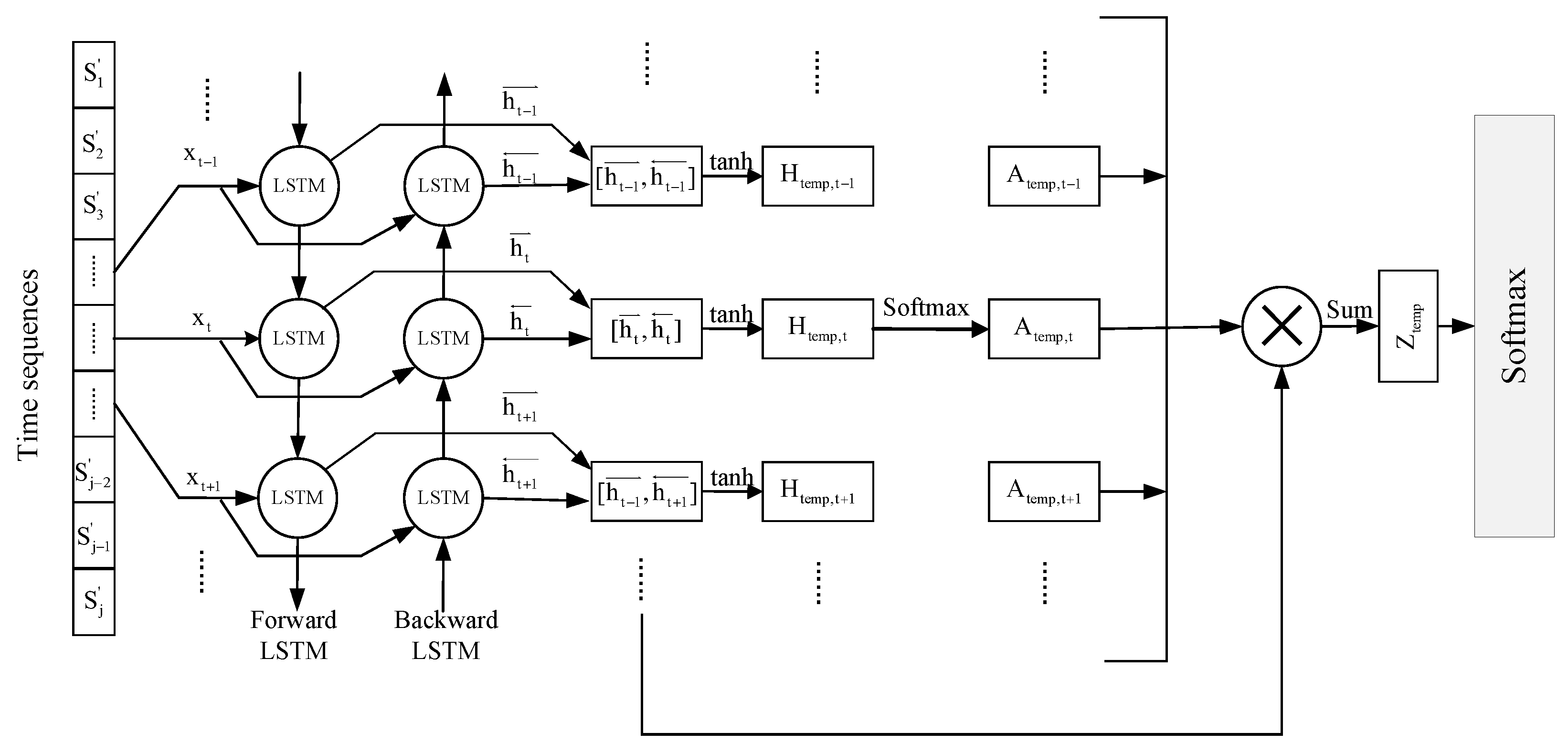
- To satisfy the real-time demands of the emotion recognition system, a residual network is devised, which comprises DC and PC to decrease the computational burden while utilizing the attributes of depth-separable convolution to segregate the spatial and channel mixing dimensions. Furthermore, the existence of a residual structure prevents overfitting. Ultimately, Bi-LSTM is employed to understand the temporal interdependence among different frames in the sample. The hidden layer states at each frame moment are allocated weights and then summed to serve as the input to softmax.
2. Related Work
3. Methods
3.1. Data Preprocessing
3.2. Multiband Four-Dimensional Feature Construction
3.3. Network Architecture
3.3.1. FcaNet
3.3.2. Spatial–Frequency Feature Learning
3.3.3. Temporal Feature Learning
4. Materials and Experimental Results
4.1. Dataset
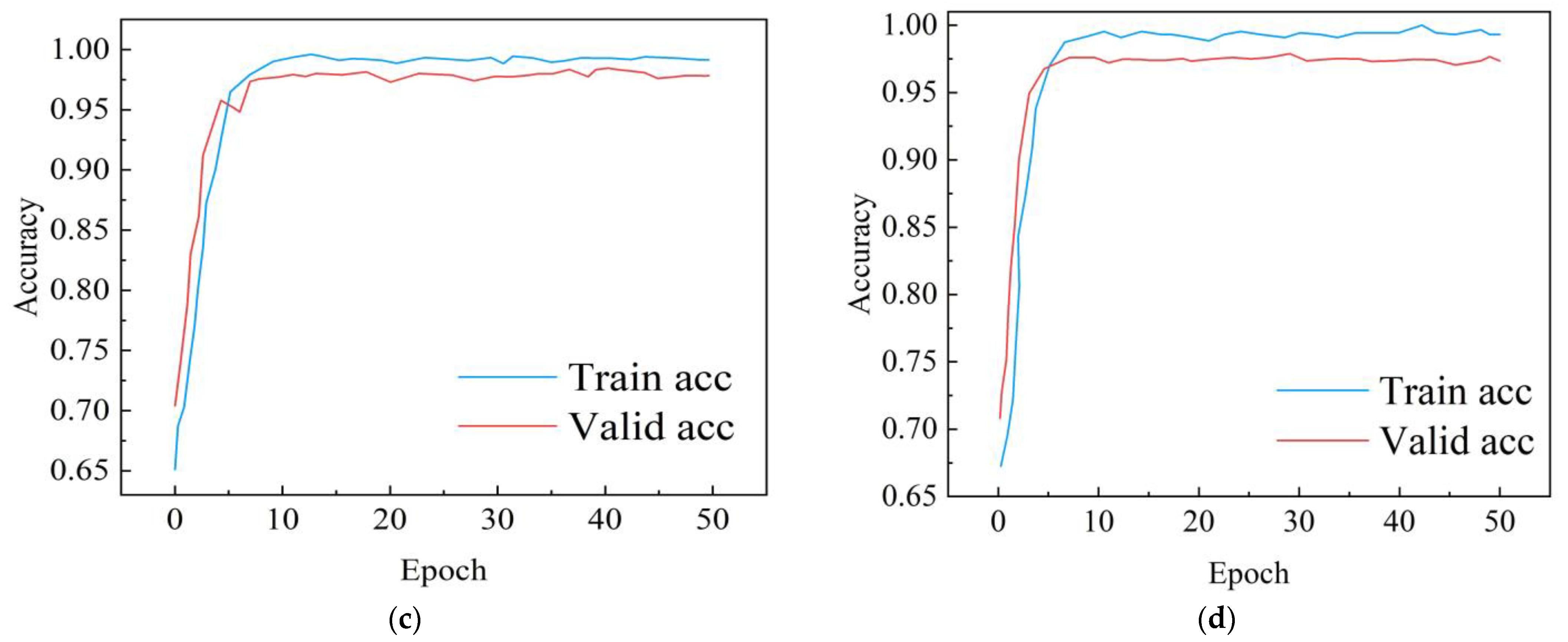
4.2. Experimental Parameter Settings and Evaluation Indices
4.3. Emotion Recognition Binary Classification Experiment
4.4. Experiment on Four Classes of Emotion Recognition
4.5. Ablation Experiments
4.6. Experimental Comparison
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Kim, M.-K.; Kim, M.; Oh, E.; Kim, S.-P. A review on the computational methods for emotional state estimation from the human EEG. Comput. Math. Methods Med. 2013, 2013, 573734. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Li, Y.; Zheng, W.; Cui, Z.; Zhang, T.; Zong, Y. A Novel Neural Network Model Based on Cerebral Hemispheric Asymmetry for EEG Emotion Recognition. In Proceedings of the Twenty-Seventh International Joint Conference on Artificial Intelligence (IJCAI-18), Stockholm, Sweden, 13–19 July 2018; pp. 1561–1567. [Google Scholar]
- Wang, F.; Wu, S.; Zhang, W.; Xu, Z.; Zhang, Y.; Wu, C.; Coleman, S. Emotion recognition with convolutional neural network and EEG-based EFDMs. Neuropsychologia 2020, 146, 107506. [Google Scholar] [CrossRef] [PubMed]
- Bhise, P.R.; Kulkarni, S.B.; Aldhaheri, T.A. Brain computer interface based EEG for emotion recognition system: A systematic review. In Proceedings of the 2020 2nd International Conference on Innovative Mechanisms for Industry Applications (ICIMIA), Bangalore, India, 5–7 March 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 327–334. [Google Scholar]
- Prochazka, A.; Vysata, O.; Marik, V. Integrating the role of computational intelligence and digital signal processing in education: Emerging technologies and mathematical tools. IEEE Signal Process. Mag. 2021, 38, 154–162. [Google Scholar] [CrossRef]
- Houssein, E.H.; Hammad, A.; Ali, A.A. Human emotion recognition from EEG-based brain–computer interface using machine learning: A comprehensive review. Neural Comput. Appl. 2022, 34, 12527–12557. [Google Scholar] [CrossRef]
- Zubair, M.; Yoon, C. EEG based classification of human emotions using discrete wavelet transform. In IT Convergence and Security 2017; Springer: Berlin/Heidelberg, Germany, 2018; Volume 2, pp. 21–28. [Google Scholar]
- Gupta, V.; Chopda, M.D.; Pachori, R.B. Cross-subject emotion recognition using flexible analytic wavelet transform from EEG signals. IEEE Sens. J. 2018, 19, 2266–2274. [Google Scholar] [CrossRef]
- Aguiñaga, A.R.; Ramirez, M.A.L. Emotional states recognition, implementing a low computational complexity strategy. Health Inform. J. 2018, 24, 146–170. [Google Scholar] [CrossRef]
- Xing, X.; Li, Z.; Xu, T.; Shu, L.; Hu, B.; Xu, X. SAE+ LSTM: A New framework for emotion recognition from multi-channel EEG. Front. Neurorobotics 2019, 13, 37. [Google Scholar] [CrossRef] [Green Version]
- Ma, J.; Tang, H.; Zheng, W.-L.; Lu, B.-L. Emotion recognition using multimodal residual LSTM network. In Proceedings of the 27th ACM International Conference on Multimedia, Nice, France, 21–25 October 2019; pp. 176–183. [Google Scholar]
- Ye, W.; Li, X.; Zhang, H.; Zhu, Z.; Li, D. Deep Spatio-Temporal Mutual Learning for EEG Emotion Recognition. In Proceedings of the 2022 International Joint Conference on Neural Networks (IJCNN), Padua, Italy, 18–23 July 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 1–8. [Google Scholar]
- Wang, Z. Emotion Recognition Based on Multi-scale Convolutional Neural Network. In Proceedings of the Data Mining and Big Data: 7th International Conference, DMBD 2022, Beijing, China, 21–24 November 2022; Proceedings, Part I. Springer: Berlin/Heidelberg, Germany, 2023; pp. 152–164. [Google Scholar]
- Singh, K.; Ahirwal, M.K.; Pandey, M. Quaternary classification of emotions based on electroencephalogram signals using hybrid deep learning model. J. Ambient Intell. Humaniz. Comput. 2023, 14, 2429–2441. [Google Scholar] [CrossRef]
- Catrambone, V.; Greco, A.; Scilingo, E.P.; Valenza, G. Functional linear and nonlinear brain–heart interplay during emotional video elicitation: A maximum information coefficient study. Entropy 2019, 21, 892. [Google Scholar] [CrossRef] [Green Version]
- Zheng, W.-L.; Guo, H.-T.; Lu, B.-L. Revealing critical channels and frequency bands for emotion recognition from EEG with deep belief network. In Proceedings of the 2015 7th International IEEE/EMBS Conference on Neural Engineering (NER), Montpellier, France, 22–24 April 2015; IEEE: Piscataway, NJ, USA, 2015; pp. 154–157. [Google Scholar]
- Zhang, G.; Yu, M.; Liu, Y.-J.; Zhao, G.; Zhang, D.; Zheng, W. SparseDGCNN: Recognizing emotion from multichannel EEG signals. IEEE Trans. Affect. Comput. 2021, 14, 537–548. [Google Scholar] [CrossRef]
- Hwang, S.; Hong, K.; Son, G.; Byun, H. Learning CNN features from DE features for EEG-based emotion recognition. Pattern Anal. Appl. 2020, 23, 1323–1335. [Google Scholar] [CrossRef]
- Song, T.; Zheng, W.; Song, P.; Cui, Z. EEG emotion recognition using dynamical graph convolutional neural networks. IEEE Trans. Affect. Comput. 2018, 11, 532–541. [Google Scholar] [CrossRef] [Green Version]
- Cui, G.; Li, X.; Touyama, H. Emotion recognition based on group phase locking value using convolutional neural network. Sci. Rep. 2023, 13, 3769. [Google Scholar] [CrossRef] [PubMed]
- Mei, H.; Xu, X. EEG-based emotion classification using convolutional neural network. In Proceedings of the 2017 International Conference on Security, Pattern Analysis, and Cybernetics (SPAC), Shenzhen, China, 15–17 December 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 130–135. [Google Scholar]
- Bai, Z.; Liu, J.; Hou, F.; Chen, Y.; Cheng, M.; Mao, Z.; Song, Y.; Gao, Q. Emotion recognition with residual network driven by spatial-frequency characteristics of EEG recorded from hearing-impaired adults in response to video clips. Comput. Biol. Med. 2023, 152, 106344. [Google Scholar] [CrossRef]
- Xu, X.; Cheng, X.; Chen, C.; Fan, H.; Wang, M. Emotion Recognition from Multi-channel EEG via an Attention-Based CNN Model. In Advances in Natural Computation, Fuzzy Systems and Knowledge Discovery, Proceedings of the ICNC-FSKD 2022, Fuzhou, China, 30 July–1 August 2022; Springer: Berlin/Heidelberg, Germany, 2023; pp. 285–292. [Google Scholar]
- Xuan, H.; Liu, J.; Yang, P.; Gu, G.; Cui, D. Emotion Recognition from EEG Using All-Convolution Residual Neural Network. In Proceedings of the Human Brain and Artificial Intelligence: Third International Workshop, HBAI 2022, Held in Conjunction with IJCAI-ECAI 2022, Vienna, Austria, 23 July 2022; Revised Selected Papers. Springer: Berlin/Heidelberg, Germany, 2022; pp. 73–85. [Google Scholar]
- Qu, Z.; Zheng, X. EEG Emotion Recognition Based on Temporal and Spatial Features of Sensitive signals. J. Electr. Comput. Eng. 2022, 2022, 5130184. [Google Scholar] [CrossRef]
- Meng, M.; Zhang, Y.; Ma, Y.; Gao, Y.; Kong, W. EEG-based emotion recognition with cascaded convolutional recurrent neural networks. Pattern Anal. Appl. 2023, 26, 783–795. [Google Scholar] [CrossRef]
- Li, Q.; Liu, Y.; Liu, Q.; Zhang, Q.; Yan, F.; Ma, Y.; Zhang, X. Multidimensional Feature in Emotion Recognition Based on Multi-Channel EEG Signals. Entropy 2022, 24, 1830. [Google Scholar] [CrossRef] [PubMed]
- Li, Q.; Liu, Y.; Shang, Y.; Zhang, Q.; Yan, F. Deep Sparse Autoencoder and Recursive Neural Network for EEG Emotion Recognition. Entropy 2022, 24, 1187. [Google Scholar] [CrossRef]
- Zhang, Y.; Zhang, Y.; Wang, S. An attention-based hybrid deep learning model for EEG emotion recognition. Signal Image Video Process. 2022, 17, 2305–2313. [Google Scholar] [CrossRef]
- Saha, O.; Mahmud, M.S.; Fattah, S.A.; Saquib, M. Automatic Emotion Recognition from Multi-Band EEG Data Based on a Deep Learning Scheme with Effective Channel Attention. IEEE Access 2022, 11, 2342–2350. [Google Scholar] [CrossRef]
- Lv, Z.; Zhang, J.; Epota Oma, E. A Novel Method of Emotion Recognition from Multi-Band EEG Topology Maps Based on ERENet. Appl. Sci. 2022, 12, 10273. [Google Scholar] [CrossRef]
- Kamble, K.; Sengupta, J. A comprehensive survey on emotion recognition based on electroencephalograph (EEG) signals. Multimed. Tools Appl. 2023, 46, 1–36. [Google Scholar] [CrossRef]
- Frantzidis, C.A.; Lithari, C.D.; Vivas, A.B.; Papadelis, C.L.; Pappas, C.; Bamidis, P.D. Towards emotion aware computing: A study of arousal modulation with multichannel event-related potentials, delta oscillatory activity and skin conductivity responses. In Proceedings of the 2008 8th IEEE International Conference on BioInformatics and BioEngineering, Athens, Greece, 8–10 October 2008; IEEE: Piscataway, NJ, USA, 2008; pp. 1–6. [Google Scholar]
- Li, J.; Zhang, Z.; He, H. Hierarchical convolutional neural networks for EEG-based emotion recognition. Cogn. Comput. 2018, 10, 368–380. [Google Scholar] [CrossRef]
- Shen, F.; Dai, G.; Lin, G.; Zhang, J.; Kong, W.; Zeng, H. EEG-based emotion recognition using 4D convolutional recurrent neural network. Cogn. Neurodynamics 2020, 14, 815–828. [Google Scholar] [CrossRef]
- Xu, W.; Liu, S.; Hou, X.; Yin, X. Sensitive Trans Formation and Multi-Level Spatiotemporal Awareness Based Eeg Emotion Recognition Model. Adv. Comput. Signals Syst. 2022, 6, 31–41. [Google Scholar]
- Qin, Z.; Zhang, P.; Wu, F.; Li, X. Fcanet: Frequency channel attention networks. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 783–792. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Sharma, R.; Pachori, R.B.; Sircar, P. Automated emotion recognition based on higher order statistics and deep learning algorithm. Biomed. Signal Process. Control 2020, 58, 101867. [Google Scholar] [CrossRef]
- Chao, H.; Dong, L. Emotion recognition using three-dimensional feature and convolutional neural network from multichannel EEG signals. IEEE Sens. J. 2020, 21, 2024–2034. [Google Scholar] [CrossRef]
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Frequency Band | Frequency Range | Brain States | Awareness |
|---|---|---|---|
| 1–4 | Extreme fatigue and deep sleep states | Sleep mode | |
| 4–8 | Light sleep, frustrated state | Low | |
| 8–13 | Awake, quiet, and eyes closed state | Medium | |
| 13–30 | Active thinking, mental tension, anxiety, concentration state | High | |
| 30–50 | Multimodal sensory stimulation, mentally active state | High |
| Number | Test Accuracy (%) (2-Class) | F1-Score | Test Accuracy (%) (4-Class) |
|---|---|---|---|
| 64 | 95.09 | 93.47 | 86.33 |
| 128 | 95.42 | 94.35 | 87.27 |
| 256 | 97.84 | 96.61 | 88.46 |
| 512 | 96.57 | 94.66 | 87.65 |
| Epoch | Test Accuracy (%) (2-Class) | F1-Score | Test Accuracy (%) (4-Class) |
|---|---|---|---|
| 50 | 97.84 | 96.61 | 88.46 |
| 100 | 97.53 | 96.49 | 86.93 |
| 150 | 96.81 | 95.12 | 86.10 |
| 200 | 97.04 | 96.83 | 85.79 |
| Shape | Valence | Arousal | Valence–Arousal | ||||
|---|---|---|---|---|---|---|---|
| Acc (%) | Time (s) | Acc (%) | Time (s) | Acc (%) | Time (s) | ||
| Compact Mapping | 8 × 9 | 97.09 | 89 s | 96.85 | 86 s | 87.59 | 93 s |
| Sparse Mapping | 19 × 19 | 97.32 | 255 s | 97.06 | 247 s | 88.07 | 262 s |
| (Ours) | 9 × 9 | 98.12 | 95 s | 97.72 | 91 s | 88.46 | 103 s |
| DEAP–Valence | DEAP–Arousal | Valence–Arousal | |||||||
|---|---|---|---|---|---|---|---|---|---|
| t = 0.25 s | t = 0.5 s | t = 1 s | t = 0.25 s | t = 0.5 s | t = 1 s | t = 0.25 s | t = 0.5 s | t = 1 s | |
| u = 3 s | 95.87% | 96.62% | 94.08% | 95.85% | 96.23% | 93.83% | 87.98% | 88.11% | 85.38% |
| u = 4 s | 96.83% | 97.53% | 95.02% | 97.15% | 97.64% | 94.58% | 88.12% | 88.20% | 85.05% |
| u = 5 s | 97.43% | 98.12% | 95.90% | 97.30% | 97.72% | 95.82% | 88.30% | 88.46% | 85.46% |
| u = 6 s | 95.82% | 96.72% | 95.17% | 96.57% | 96.89% | 94.53% | 87.95% | 88.14% | 85.49% |
| Methods | Metrics | Accuracy (%) (avg) | Training Time (s) | Testing Time (s) |
|---|---|---|---|---|
| CNN-LSTM | Valence Arousal Dominance Liking | 84.45 | 90.51 | 11.67 |
| CNN-BiLSTM | Valence Arousal Dominance Liking | 88.53 | 93.05 | 12.26 |
| CNN-SENet-BiLSTM | Valence Arousal Dominance Liking | 90.02 | 86.20 | 11.47 |
| CNN-FcaNet-BiLSTM | Valence Arousal Dominance Liking | 92.25 | 88.57 | 11.82 |
| Ours | Valence Arousal Dominance Liking | 94.58 | 89.43 | 11.87 |
| Literature | Metrics | Dataset | Features | Test Accuracy (%) | F1-Score (%) | Methods |
|---|---|---|---|---|---|---|
| Wang Z [13] | Valence Arousal | DEAP | Temporal | 83.97 83.72 | N/A | Multiscale CNN |
| Singh K [14] | Valence Arousal H/M/L valence H/M/L arousal | DEAP | Temporal | 91.31 (avg) --- 89.32 (avg) | N/A | 1DCNN-Bi-LSTM |
| Bai Z [22] | Valence Arousal Negative/neutral/positive | DEAP --- SEED | Spatial Frequency | 88.75 (avg) --- 90.04 (avg) | N/A | CNN (DC + PC + Residual) |
| Xu X [23] | Negative/neutral/positive | SEED | Spatial Frequency | 96.01 (avg) | N/A | CNN (channel attention + Residual) |
| Meng M [26] | Valence Arousal Negative/neutral/positive | DEAP --- SEED | Frequency temporal spatial | 94.85 94.43 --- 94.16 (avg) | N/A | VGG16-LSTM |
| Li Q [27] | Valence Arousal Negative/neutral/positive | DEAP --- SEED | Frequency temporal spatial | 95.02 94.61 --- 95.49 (avg) | 96.29 95.72 --- 95.57 | CNN-ON-LSTM |
| Zhang Y [29] | Valence Arousal Negative/neutral/positive | DEAP --- SEED | Frequency temporal spatial | 85.86 84.27 --- 92.47 (avg) | N/A | CNN-attention LSTM-attention |
| Saha O [30] | Valence Arousal | DEAP | Temporal Frequency | 97.06 97.34 | 96.39 | 3DCNN-channel attention |
| Ours | Valence Arousal Dominance Liking | DEAP | Frequency temporal spatial | 97.84 (avg) | 97.22 97.02 97.17 97.11 | CNN-BiLSTM-FcaNet |
| Literature | Metrics | Dataset | Test Accuracy (%) | Methods |
|---|---|---|---|---|
| Zubair [7] | H/L V-A | DEAP | 45.40 | mRMR |
| Guptal [8] | H/L V-A Negative/neutral/positive On beta gamma | DEAP --- SEED | 71.43 --- 83.33 (avg) | FAWT-SVM |
| Aguiñaga [9] | Valence/arousal H/L V-A | DEAP | 84.20 (avg) 80.90 | WP-NN-SVM |
| Mei [21] | Valence Arousal H/L V-A Theta alpha gamma | DEAP | 83.60 83.0 73.10 | CNN |
| Sharma [39] | Valence Arousal H/L V-A | DEAP | 84.16 85.21 82.01 | PSO-BiLSTM |
| Chao [40] | Valence Arousal H/L V-A | DEAP | 85.53 85.88 76.77 | Multiscale CNN |
| Ours | H/L V-A | DEAP | 88.46 | CNN-BiLSTM-FcaNet |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Luo, Y.; Wu, C.; Lv, C. Cascaded Convolutional Recurrent Neural Networks for EEG Emotion Recognition Based on Temporal–Frequency–Spatial Features. Appl. Sci. 2023, 13, 6761. https://doi.org/10.3390/app13116761
Luo Y, Wu C, Lv C. Cascaded Convolutional Recurrent Neural Networks for EEG Emotion Recognition Based on Temporal–Frequency–Spatial Features. Applied Sciences. 2023; 13(11):6761. https://doi.org/10.3390/app13116761
Chicago/Turabian StyleLuo, Yuan, Changbo Wu, and Caiyun Lv. 2023. "Cascaded Convolutional Recurrent Neural Networks for EEG Emotion Recognition Based on Temporal–Frequency–Spatial Features" Applied Sciences 13, no. 11: 6761. https://doi.org/10.3390/app13116761