
Retrieval of Injection Molding Industrial Knowledge Graph Based on Transformer and BERT
 , and
, and
Abstract
:1. Introduction
2. Background Knowledge
2.1. Knowledge Graph
2.2. Neo4j
2.3. MongoDB
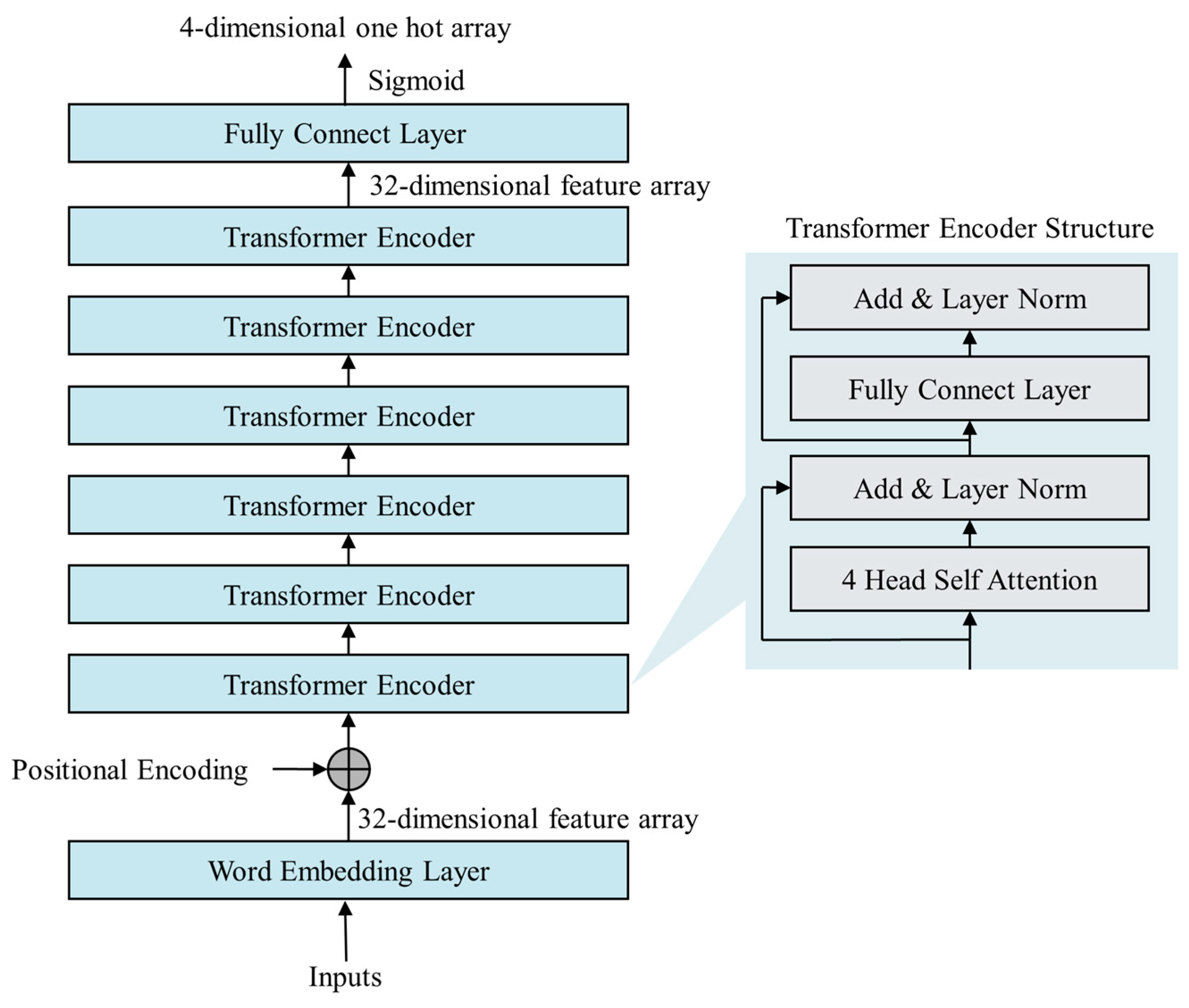
2.4. Transformer Encoder
2.5. BERT
3. Methodology
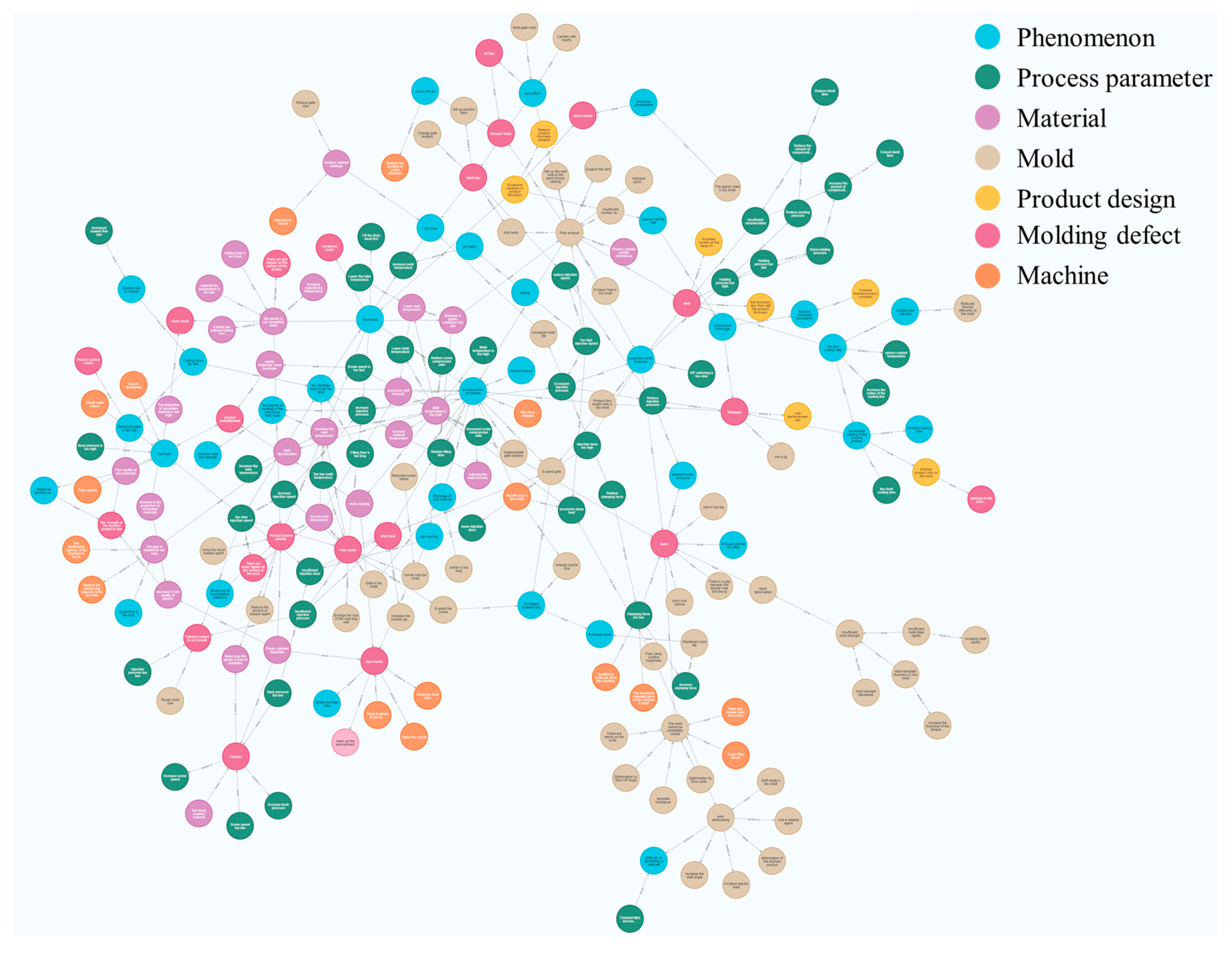
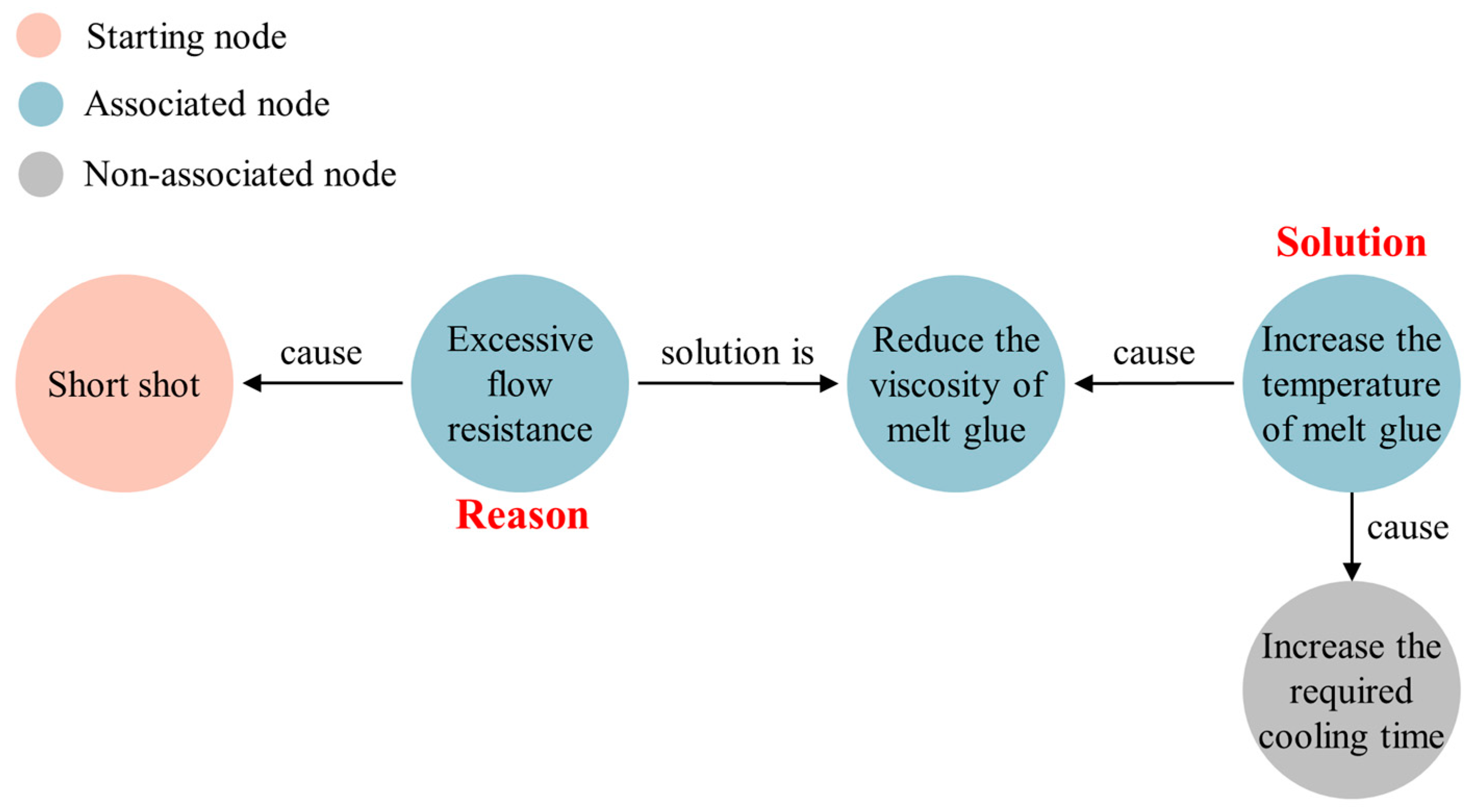
3.1. Injection Molding Industrial Knowledge Graph
3.2. Question Understanding
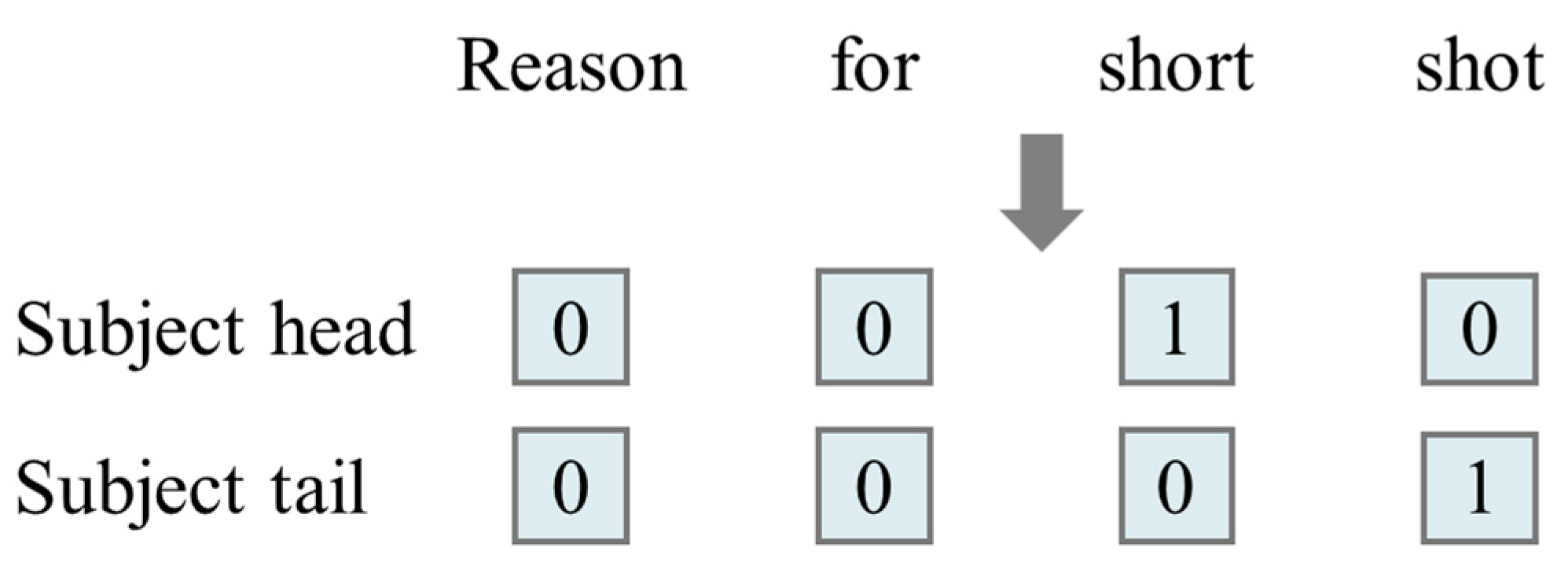
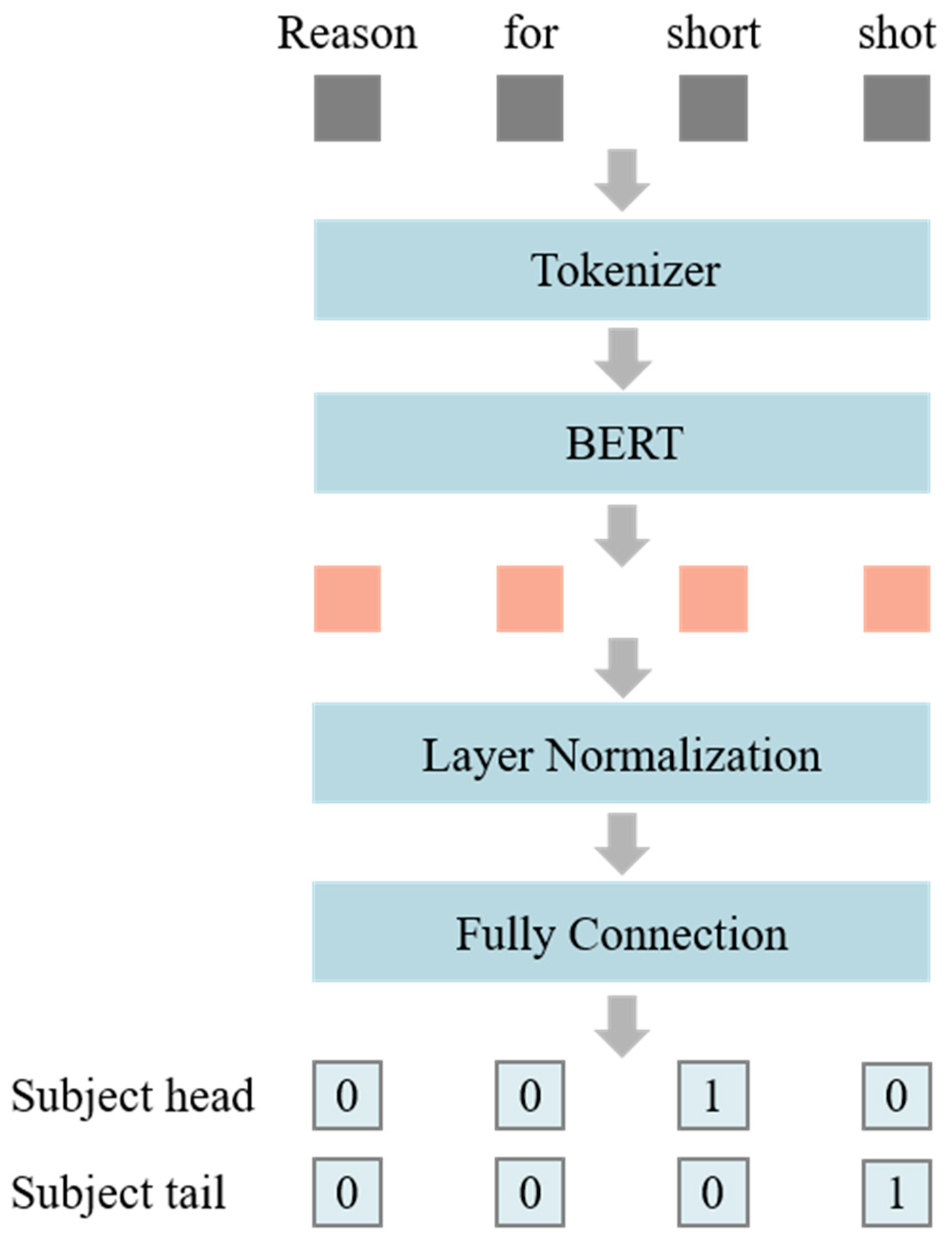
3.2.1. Subject Recognition
3.2.2. Semantic Classification
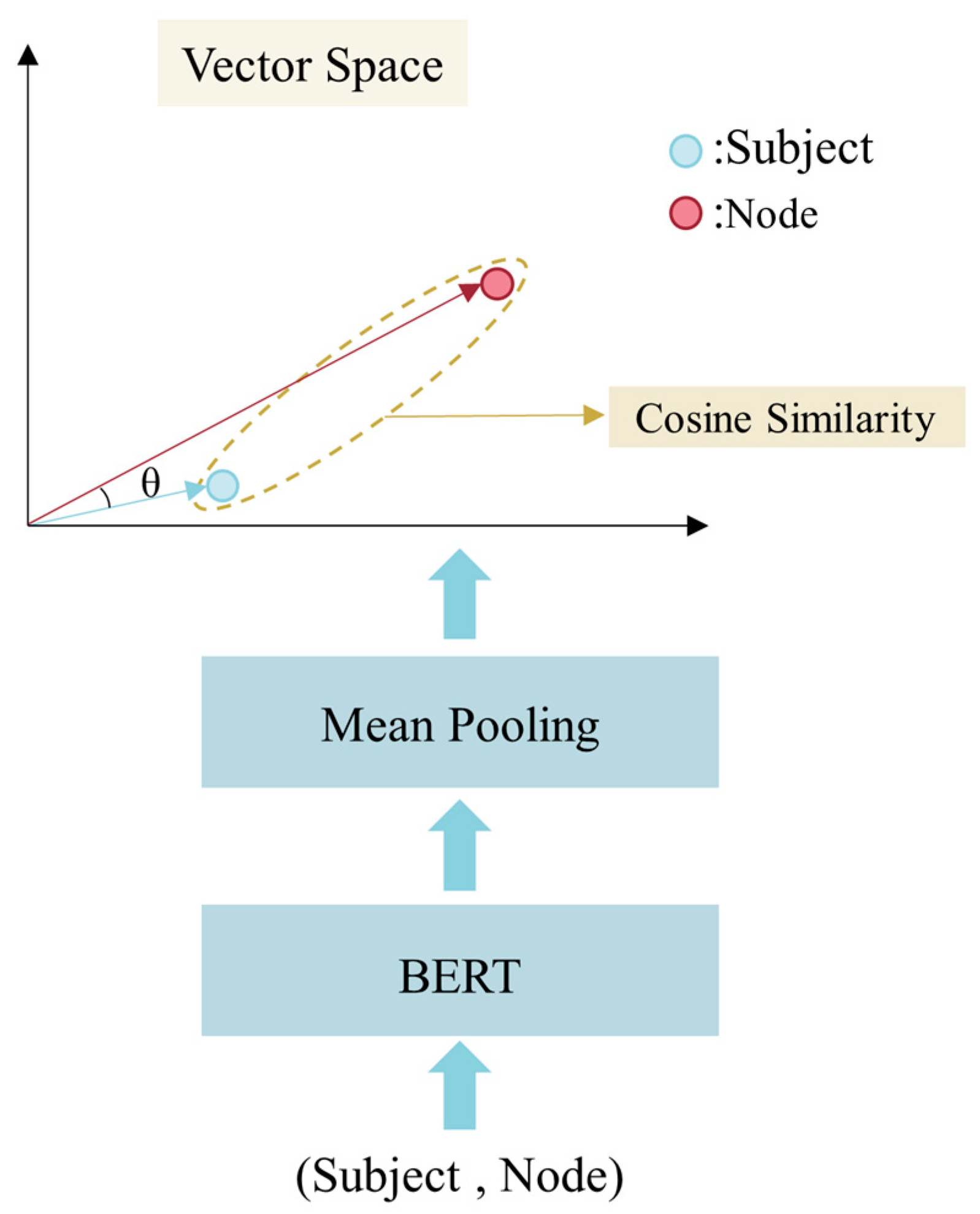
3.2.3. Entity Alignment
3.3. Searching Engine
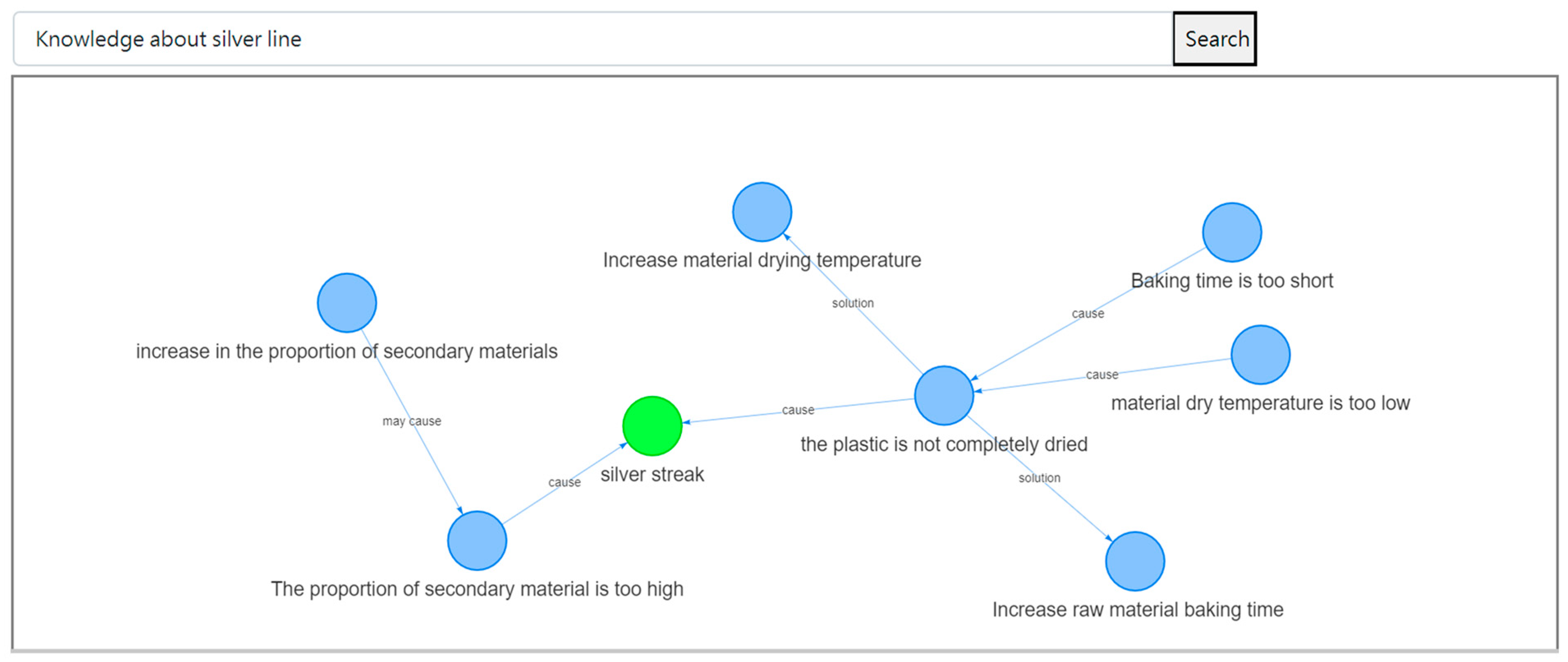
3.4. Case Verification
4. Discussion
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Jong, W.R.; Wu, C.H.; Li, M.Y. Web-based navigating system for conceptual mould design with knowledge management. Int. J. Prod. Res 2010, 49, 553–567. [Google Scholar] [CrossRef]
- Jong, W.R.; Ting, Y.H.; Li, T.C.; Chen, K.Y. An integrated application for historical knowledge management with mould design navigating process. Int. J. Prod. Res 2012, 51, 3191–3205. [Google Scholar]
- Khosravani, M.R.; Nasiri, S.; Weinberg, K. Application of case-based reasoning in a fault detection system on production of drippers. Appl. Soft Comput. 2018, 75, 227–232. [Google Scholar] [CrossRef]
- Mikos, W.L.; Ferreira, J.C.E.; Gomes, F.G.C. A distributed system for rapid determination of nonconformance causes and solutions for the thermoplastic injection molding process: A Case-Based Reasoning Agents approach. In Proceedings of the IEEE International Conference on Automation Science and Engineering, Trieste, Italy, 24–27 August 2011. [Google Scholar]
- Bader, S.R.; Grangel-Gonzalez, I.; Nanjappa, P.; Vidal, M.E.; Maleshkova, M. A Knowledge Graph for Industry 4.0. In Proceedings of the European Semantic Web Conference: The Semantic Web, Heraklion, Greece, 31 May–4 June 2020. [Google Scholar]
- Shi, Y.X.; Zhang, B.K.; Wang, Y.X.; Luo, H.Q.; Li, X. Constructing Crop Portraits Based on Graph Databases Is Essential to Agricultural Data Mining. Information 2021, 12, 227. [Google Scholar] [CrossRef]
- Chen, Y.; Subburathinam, A.; Chen, C.H.; Zaki, M.J. Personalized Food Recommendation as Constrained Question Answering over a Large-scale Food Knowledge Graph. In Proceedings of the 14th ACM International Conference on Web Search and Data Mining, Virtual Event, Israel, 8–12 March 2021. [Google Scholar]
- Chi, Y.; Yu, C.; Qi, X.; Xu, H. Knowledge Management in Healthcare Sustainability: A Smart Healthy Diet Assistant in Traditional Chinese Medicine Culture. Sustainability 2018, 10, 4197. [Google Scholar] [CrossRef]
- Yu, T.; Li, J.; Yu, Q.; Tian, Y.; Shun, X.; Xu, L.; Zhu, L.; Gao, H. Knowledge graph for TCM health preservation: Design, construction, and applications. Artif. Intell. Med. 2017, 77, 48–52. [Google Scholar] [CrossRef] [PubMed]
- Cui, M.; Yang, S.; Yu, T.; Yang, C.; Gao, Y.; Zhu, H. Expert knowledge maps for knowledge management: A case study in Traditional Chinese Medicine research. J. Tradit. Chin. Med. 2013, 33, 698–702. [Google Scholar] [CrossRef] [PubMed]
- Zhang, Y.; Sheng, M.; Zhou, R.; Wang, Y.; Han, G.; Zhang, H.; Xing, C.; Dong, J. HKGB: An Inclusive, Extensible, Intelligent, Semi-auto-constructed Knowledge Graph Framework for Healthcare with Clinicians’ Expertise Incorporated. Inf. Process. Manag. 2020, 57, 102324. [Google Scholar] [CrossRef]
- Kim, H. A knowledge graph of medical institutions in Korea. Web Semant. 2021, 55–68. [Google Scholar] [CrossRef]
- Jiang, Y.; Gao, X.; Su, W.; Li, J. Systematic Knowledge Management of Construction Safety Standards Based on Knowledge Graphs: A Case Study in China. Int. J. Environ. Res. Public Health 2021, 18, 10692. [Google Scholar] [CrossRef] [PubMed]
- Gao, H.; Miao, L.; Liu, J.; Dong, K.; Lin, X. Construction and Application of Knowledge Graph for Power System Dispatching. In Proceedings of the 7th International Forum on Electrical Engineering and Automation, Hefei, China, 25–27 September 2020. [Google Scholar]
- Zhang, J.; Song, Z. Research on knowledge graph for quantification of relationship between enterprises and recognition of potential risks. In Proceedings of the 4th IEEE International Conference on Cybernetics, Beijing, China, 5–7 July 2019. [Google Scholar]
- Wu, N.; Green, B.; Ben, X.; O’Banion, S. Deep Transformer Models for Time Series Forecasting: The Influenza Prevalence Case. arXiv 2020, arXiv:2001.08317. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Ilya, S.; Oriol, V.; Quoc, V.L. Sequence to sequence learning with neural networks. In Proceedings of the 27th International Conference on Neural Information Processing Systems, Montreal, QC, Canada, 8–13 December 2014. [Google Scholar]
- Grechishnikova, D. Transformer neural network for protein-specific de novo drug generation as a machine translation problem. Sci. Rep. 2021, 11, 321. [Google Scholar] [CrossRef] [PubMed]
- Ding, Y.; Jia, M. A Convolutional Transformer Architecture for Remaining Useful Life Estimation. In Proceedings of the 2021 Global Reliability and Prognostics and Health Management, Nanjing, China, 15–17 October 2021. [Google Scholar]
- Zhang, K.; Qiang, S.; Liang, Z.; Chang, Y. A greenhouse temperature prediction framework based on transformer neural network. In Proceedings of the 2021 International Conference on Computer Information Science and Artificial Intelligence, Kunming, China, 17–19 September 2021. [Google Scholar]
- Hu, R.; Chen, J.; Zhou, L. A transformer-based deep neural network for arrhythmia detection using continuous ECG signals. Comput. Biol. Med. 2022, 144, 105325. [Google Scholar] [CrossRef] [PubMed]
- Chen, Y.; Chen, X.; Xu, A.; Sun, Q.; Peng, X. A hybrid CNN-Transformer model for ozone concentration prediction. Air Qual Atmos Health 2022, 15, 1533–1546. [Google Scholar] [CrossRef]
- Acikalin, U.U.; Bardak, B.; Kutlu, M. Turkish Sentiment Analysis Using BERT. In Proceedings of the 2020 28th Signal Processing and Communications Applications Conference, Gaziantep, Turkey, 5–7 October 2020. [Google Scholar]
- Mozafari, M.; Farahbakhsh, R.; Crespi, N. A BERT-Based Transfer Learning Approach for Hate Speech Detection in Online Social Media. In Proceedings of the Eighth International Conference on Complex Networks and Their Applications COMPLEX NETWORKS, Lisbon, Portugal, 10–12 December 2019. [Google Scholar]
- Zheng, X.; Wang, B.; Zhao, Y.; Mao, S.; Tang, Y. A knowledge graph method for hazardous chemical management: Ontology design and entity identification. Neurocomputing 2020, 430, 104–111. [Google Scholar] [CrossRef]
- Yu, J.; Sun, J.; Dong, Y.; Zhao, D.; Chen, X.; Chen, X. Entity recognition model of power safety regulations knowledge graph based on BERT-BiLSTM-CRF. In Proceedings of the 2021 IEEE International Conference on Power Electronics, Computer Applications, Shenyang, China, 22–24 January 2021. [Google Scholar]
- Harnoune, A.; Rhanoui, M.; Mikram, M.; Yousfi, S.; Elkaimbillah, Z.; Asri, B.E. BERT based clinical knowledge extraction for biomedical knowledge graph construction and analysis. Comput. Methods Programs Biomed. Update 2021, 1, 100042. [Google Scholar] [CrossRef]
- Chansai, T.; Rojpaismkit, R.; Boriboonsub, T.; Tuarob, S.; Yin, M.S.; Haddawy, P.; Hassan, S.; Pomarlan, M. Automatic Cause-Effect Relation Extraction from Dental Textbooks Using BERT. In Proceedings of the International Conference on Asian Digital Libraries, Virtual Event, 1–3 December 2021. [Google Scholar]
- Singhal, A. Introducing the Knowledge Graph: Things, not Strings. 2012. Available online: https://blog.google/products/search/introducing-knowledge-graph-things-not/ (accessed on 15 March 2023).
- Guia, J.; Soares, V.G.; Bernardino, J. Graph Databases: Neo4j Analysis. In Proceedings of the International Conference on Enterprise Information Systems, Porto, Portugal, 26–29 April 2017. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention Is All You Need. In Proceedings of the 31st International Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Zhou, Z.W.; Ting, Y.H.; Jong, W.R.; Chen, S.C.; Chiu, M.C. Development and Application of Knowledge Graphs for the Injection Molding Process. Machines 2023, 11, 271. [Google Scholar] [CrossRef]
- Zhou, Z.W.; Ting, Y.H.; Jong, W.R.; Chiu, M.C. Knowledge Management for Injection Molding Defects by a Knowledge Graph. Appl. Sci. 2022, 12, 11888. [Google Scholar] [CrossRef]





















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Class | Label |
|---|---|
| Impact | [1,0,0] |
| Solution | [0,1,0] |
| Reason | [0,0,1] |
| All | [0,0,0] |
| Object | Code |
|---|---|
| Node | 1 |
| Cause (forward) | 2 |
| May-cause (forward) | 3 |
| Solution is (forward) | 4 |
| Cause (reverse) | 5 |
| May-cause (reverse) | 6 |
| Solution is (reverse) | 7 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhou, Z.-W.; Jong, W.-R.; Ting, Y.-H.; Chen, S.-C.; Chiu, M.-C. Retrieval of Injection Molding Industrial Knowledge Graph Based on Transformer and BERT. Appl. Sci. 2023, 13, 6687. https://doi.org/10.3390/app13116687
Zhou Z-W, Jong W-R, Ting Y-H, Chen S-C, Chiu M-C. Retrieval of Injection Molding Industrial Knowledge Graph Based on Transformer and BERT. Applied Sciences. 2023; 13(11):6687. https://doi.org/10.3390/app13116687
Chicago/Turabian StyleZhou, Zhe-Wei, Wen-Ren Jong, Yu-Hung Ting, Shia-Chung Chen, and Ming-Chien Chiu. 2023. "Retrieval of Injection Molding Industrial Knowledge Graph Based on Transformer and BERT" Applied Sciences 13, no. 11: 6687. https://doi.org/10.3390/app13116687