
Evaluation of Table Grape Flavor Based on Deep Neural Networks

Abstract
:1. Introduction
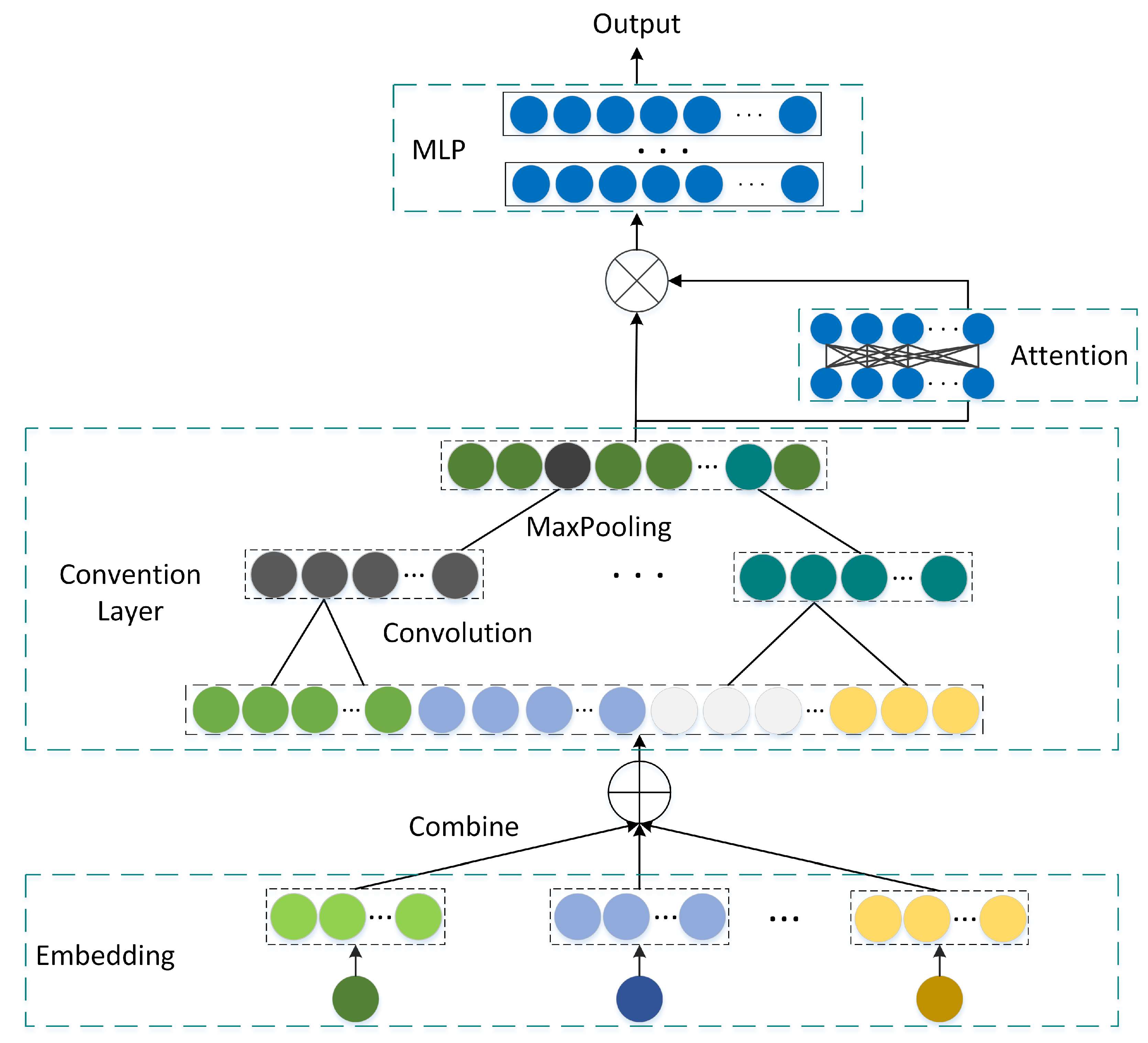
- An embedding layer is added after the input layer to achieve a more comprehensive representation of the input indicators in the form of feature vectors.
- Convolution kernels of different sizes are used in the convolutional layer to extract interaction features between adjacent features.
- An attention module is embedded to enhance important features and weaken unimportant features.
- The experimental results show that the proposed flavor evaluation model achieves high accuracy in evaluating the flavor of table grapes.
2. Related Work
2.1. Statistical Methods for Grape Quality Evaluation
2.2. Machine Learning for Wine Quality Evaluation
3. Deep-Neural-Network-Based Grape Flavor Evaluation
3.1. Batch Normalization Layer
3.2. Embedding Layer
3.3. Convolutional Layer
3.4. Attention Layer
3.5. Multilayer Perceptron Layer
4. Experiments and Performance Evaluation
4.1. Data Collection
4.1.1. Flavor Data Collection
4.1.2. Sensory Evaluation Data Collection
4.2. Performance Evaluation Indicators
4.2.1. , RMSE, and AIC for Prediction Evaluation
4.2.2. Accuracy, Precision, Recall, and F1-Score for Classification Evaluation
4.3. Environmental Setup
4.4. Evaluation Results
4.4.1. Comparison of Different Models
4.4.2. Effects of Different Layers
4.4.3. Effects of Different Dimensions of the Embedding Layer
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Winkler, A.J. Better grapes for wine. Am. J. Enol. Vitic. 1958, 9, 202–203. [Google Scholar] [CrossRef]
- Diamanti, J.; Battino, M.; Mezzetti, B. Breeding for fruit nutritional and nutraceutical quality. In Breeding for Fruit Quality; John Wiley & Sons: Hoboken, NJ, USA, 2011; pp. 61–80. [Google Scholar]
- Muñoz-Robredo, P.; Robledo, P.; Manríquez, D.; Molina, R.; Defilippi, B.G. Characterization of sugars and organic acids in commercial varieties of table grapes. Chil. J. Agric. Res. 2011, 71, 452. [Google Scholar] [CrossRef]
- Cehnglin, G.; Aimin, G.; Xiaowei, W. Integrated evaluation of grape quality by the method of gray related degree analysis and analytic hierarchy process. Southwest China J. Agric. Sci. 2002, 15, 79–82. [Google Scholar]
- Pan, Z.; Zhou, W.; Xiao, Y.; Huizi. Quality evaluation of different table grape based on principal component analysis. Food Mach. 2018, 34, 139–146. [Google Scholar]
- Dawei, C.; He, S.; Li, M.; Gu, H.; Guo, X.; Chen, J. Difference and Comprehensive Evaluation of Fruit Nutritional Quality of Different Grape Varieties. Acta Agric. Jiangxi 2020, 32, 72–76. [Google Scholar]
- Shen, T.; Niu, R.; Huang, X.; Xu, Z.; Chen, W. Quality Assessment of Seedless Table Grapes Based on Hierarchy-relation and Principal Component Analysis. Sci. Technol. Food Ind. 2021, 42, 53–60. [Google Scholar]
- Xiangyan, Z.; Liangzhong, Z.; Wenbing, S.; Shengyan, J. Prediction model of quality of wine on principal component analysis and BP neural networks. Food Mach. 2014, 30, 40–44. [Google Scholar]
- Luo, Y.; Huang, Z.; Xu, J.; Wen, Q.; Ma, C.; Zhang, Z. Evaluation on Wine Quality Based on the Extraction of Neural Network Weights and Consistency of Particle Size. J. Liaocheng Univ. 2015, 28, 67–73. [Google Scholar]
- Liu, Y.; Wang, Y.; Miao, Y.; Song, J.; Chen, L. Research of the wine evaluation model based on PCA & neural network. Intell. Comput. Appl. 2016, 6, 67–69. [Google Scholar]
- Trivedi, A.; Sehrawat, R. Wine quality detection through machine learning algorithms. In Proceedings of the 2018 International Conference on Recent Innovations in Electrical, Electronics & Communication Engineering (ICRIEECE), Bhubaneswar, India, 27–28 July 2018; pp. 1756–1760. [Google Scholar]
- Aich, S.; Al-Absi, A.A.; Hui, K.L.; Sain, M. Prediction of quality for different type of wine based on different feature sets using supervised machine learning techniques. In Proceedings of the 2019 21st International Conference on Advanced Communication Technology (ICACT), Pyeongchang, Republic of Korea, 17–20 February 2019; pp. 1122–1127. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In Proceedings of the International Conference on Machine Learning, PMLR, Lille, France, 7–9 July 2015; pp. 448–456. [Google Scholar]
- Neishi, M.; Sakuma, J.; Tohda, S.; Ishiwatari, S.; Yoshinaga, N.; Toyoda, M. A bag of useful tricks for practical neural machine translation: Embedding layer initialization and large batch size. In Proceedings of the 4th Workshop on Asian Translation (WAT2017), Taipei, Taiwan, 27 November–1 December 2017; pp. 99–109. [Google Scholar]
- Dahiya, S.; Tyagi, R.; Gaba, N. Streamlining choice of CNNs and structure framing of convolution layer. In Proceedings of the Soft Computing: Theories and Applications: Proceedings of SoCTA 2019; Springer: Berlin/Heidelberg, Germany, 2020; pp. 705–718. [Google Scholar]
- Pang, Y.; Sun, M.; Jiang, X.; Li, X. Convolution in convolution for network in network. IEEE Trans. Neural Netw. Learn. Syst. 2017, 29, 1587–1597. [Google Scholar] [CrossRef]
- Maoz, I.; Kaplunov, T.; Raban, E.; Dynkin, I.; Degani, O.; Lewinsohn, E.; Lichter, A. Insights into the chemosensory basis of flavor in table grapes. J. Sci. Food Agric. 2020, 100, 1405–1417. [Google Scholar] [CrossRef] [PubMed]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Proceedings of the 31st Conference on Neural Information Processing Systems (NIPS 2017), Long Beach, CA, USA, 4–9 December 2017.
- Zare, M.; Pourghasemi, H.R.; Vafakhah, M.; Pradhan, B. Landslide susceptibility mapping at Vaz Watershed (Iran) using an artificial neural network model: A comparison between multilayer perceptron (MLP) and radial basic function (RBF) algorithms. Arab. J. Geosci. 2013, 6, 2873–2888. [Google Scholar] [CrossRef]
- GB/T 16291. 1-2012; General Guidelines for the Selection, Training and Management of Evaluators by Sensory Analysis Part 1: Preferred Evaluators. Standardization Administration of the People’s Republic of China: Beijing, China, 2012.
- Liu, Z. Grape Flavor Dataset. 2023. Available online: https://doi.org/10.6084/m9.figshare.22730081 (accessed on 2 May 2023).
- Chai, T.; Draxler, R.R. Root mean square error (RMSE) or mean absolute error (MAE)?–Arguments against avoiding RMSE in the literature. Geosci. Model Dev. 2014, 7, 1247–1250. [Google Scholar] [CrossRef]
- Ministry of Agriculture of the PRC. Thompson Seedless NY/T 704-2003; Standards Press of China: Beijing, China, 2004.
- Dawei, C.; Jinyong, C.; Hong, G.; Weiyuan, Z.; Yang, Z.; Xizhi, G.; Luzhen, J. Resarech on grading evaluation about fruit quality of‘Summer Black’ grape. J. Fruit Sci. 2016, 33, 1396–1404. [Google Scholar]
- Tian, S.; Ruimin, N.; Weiping, C.; Zehua, X.; Xiaojing, H. Evaluating the quality of eighteen table grapes by applying hierarchy-correlation degree and cluster analysis. North. Hortic. 2017, 23, 64–72. [Google Scholar]
- Guoguang, L. Quality Requirements and Taste Scoring Criteria for Table Grapes. Sino-Overseas Grapevine Wine 1986, 3, 4–7. [Google Scholar]
- DB65/T2832-2007; Red Globe Quality Classification Standard of Xinjiang Uygur Autonomous Region Quality and Technical Supervision Bureau. Administration of Quality and Technology Supervision of Xinjiang Uygur Autonomous Region: Xinjiang, China, 2008.
- Buhai, Z.; Keyu, G.; Hongshan, L.; Yuxiang, S.; Yanan, J.; Guowei, H.; Huawei, M. Comparative Study on Fruit Quality of Six Eurasia Grape Varieties. Acta Agric. Jiangxi 2011, 12, 45–47. [Google Scholar]
- Peng, L.; Tao, Y.; Ye, M.; Ye, X. Comparison of Physicochemical Properties and Phenolic Substances Composition of Five Grape Varieties. Food Ferment. Ind. 2019, 45, 74–81. [Google Scholar]
- Wei, S.; Chengmin, L.; Shouming, S.; Jiawei, W.; Yue, J. Comparative Analysis of Fruit Quality and Aroma Components of Different Grape Varieties. China South. Agric. Mach. 2022, 53, 20–25. [Google Scholar]
- Serratosa, M.P.; Marquez, A.; Moyano, L.; Zea, L.; Merida, J. Chemical and morphological characterization of Chardonnay and Gewürztraminer grapes and changes during chamber-drying under controlled conditions. Food Chem. 2014, 159, 128–136. [Google Scholar] [CrossRef]
- Bo, L.; Yuxia, S.; Xinjie, Z.; Xiao, W.; Jinhua, D. The volatile components of Muscat Hambourg grape were analyzed by GC-MS. Sino-Overseas Grapevine Wine 2005, 2, 4–6. [Google Scholar]
- Zhigang, G.; Tianming, L.; Changzeng, Z.; Minfang, Z.; Hui, W. Comparison of Aroma Components of the Grape and Wine from Different Area. China Brew. 2008, 16, 15–18. [Google Scholar]
- Dharmadhikari, M. Composition of grapes. Vineyard Vintage View State Univ. 1994, 9, 3–8. [Google Scholar]
- Egorov, E. Grape breeding is a key link in the development of the grapes and wine-making industry. Vavilov J. Genet. Breed. 2021, 25, 408. [Google Scholar] [CrossRef]
- Feng, H.; Feng, J.; Tian, D.; Mu, W. Consumers’ perceptions of quality and safety for grape products: A case study in Zhejiang Province, China. Br. Food J. 2012, 114, 1587–1598. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Indicator | Method |
|---|---|
| Total soluble solids (TSS) | Brix meter |
| Titratable acid (TA) | Acid–base titration |
| Solid/acid ratio | Calculation |
| Total phenols (TP) | Folin–Ciocalteu |
| Volatile substances (VS) | HS-SPME |
| Index | TSS (%) | TA (%) | Solid/Acid Ratio | VS (%) | TP (mg/g) |
|---|---|---|---|---|---|
| Range | 11.4∼26.9 | 0.34∼1.22 | 11.45∼72.35 | 0.14∼13.40 | 1.05∼2.39 |
| Average | 19.30 | 0.73 | 29.24 | 8.73 | 1.79 |
| STDEV | 3.90 | 0.23 | 11.31 | 4.24 | 0.45 |
| Score Grade | Taste | Aroma |
|---|---|---|
| 0∼20 (points) | Rough, little juice | Weak aroma |
| 20∼40 (points) | Light, no harshness | Light aroma |
| 40∼60 (points) | Fresh, slight acidity | Distinct aroma |
| 60∼80 (points) | Rich, multiple layers | Strong aroma |
| 80∼100 (points) | Full-bodied, superior taste | Extremely intense aroma |
| Age Group | Number | Percentage |
|---|---|---|
| 20∼29 | 5 | 33.3% |
| 30∼39 | 5 | 33.3% |
| 40∼49 | 3 | 20% |
| 50∼59 | 2 | 13.3% |
| Gender | Number | Percentage |
|---|---|---|
| Male | 8 | 53.3% |
| Female | 7 | 46.7% |
| Configuration | Parameter |
|---|---|
| CPU | Intel(R) Xeon Silver 4114 |
| Memory | 128GB DDR4 |
| Operating System | Ubuntu18.04 STL |
| Graphics Card | GTX1060 Ti |
| Disk | 1TB SSD |
| Program Language | Python 3.7 |
| Framework | PyTorch 1.6 |
| IDE | Pycharm 2020.3.5 |
| Model | RMSE | R2 | AIC | Accuracy | Precision | Recall | F1 |
|---|---|---|---|---|---|---|---|
| SVM | - | - | - | 0.728 | 0.685 | 0.698 | 0.691 |
| Random Forest | - | - | - | 0.795 | 0.751 | 0.776 | 0.763 |
| CNN | 6.458 | 0.701 | 800.119 | 0.845 | 0.820 | 0.826 | 0.823 |
| BPNN | 5.748 | 0.855 | 550.927 | 0.852 | 0.832 | 0.866 | 0.835 |
| Our Model | 2.657 | 0.987 | 206.472 | 0.948 | 0.920 | 0.936 | 0.928 |
| Model | RMSE | R2 | AIC | Accuracy | Precision | Recall | F1 |
|---|---|---|---|---|---|---|---|
| Without embedding layer | 3.526 | 0.923 | 512.444 | 0.906 | 0.899 | 0.903 | 0.901 |
| Without convolutional layer | 4.291 | 0.869 | 553.997 | 0.891 | 0.845 | 0.898 | 0.869 |
| Without attention layer | 2.964 | 0.948 | 392.081 | 0.924 | 0.901 | 0.930 | 0.915 |
| The complete model | 2.657 | 0.987 | 206.472 | 0.948 | 0.920 | 0.936 | 0.928 |
| TSS (%) | TA (%) | Solid/Acid Ratio | TP (mg/g) | VS (%) | |
|---|---|---|---|---|---|
| Range | 18.10∼22.30 | 0.40∼0.70 | 30.90∼40.45 | 1.62∼2.23 | 6.84∼13.40 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, Z.; Zhang, Y.; Zhang, Y.; Guo, L.; Wu, C.; Shen, W. Evaluation of Table Grape Flavor Based on Deep Neural Networks. Appl. Sci. 2023, 13, 6532. https://doi.org/10.3390/app13116532
Liu Z, Zhang Y, Zhang Y, Guo L, Wu C, Shen W. Evaluation of Table Grape Flavor Based on Deep Neural Networks. Applied Sciences. 2023; 13(11):6532. https://doi.org/10.3390/app13116532
Chicago/Turabian StyleLiu, Zheng, Yu Zhang, Yicheng Zhang, Lei Guo, Chase Wu, and Wei Shen. 2023. "Evaluation of Table Grape Flavor Based on Deep Neural Networks" Applied Sciences 13, no. 11: 6532. https://doi.org/10.3390/app13116532