
AFFNet: An Attention-Based Feature-Fused Network for Surface Defect Segmentation

Abstract
:1. Introduction
- A Residual-RepGhost-Dblock (RRD) module is presented to replace the simple CNN convolution layer, it could be used as a flexible module to enable the network to perform multiscale feature extraction.
- A global feature attention (GFA) module is proposed to selectively fuse feature maps with different resolutions, so as to fuse more contextual semantic information and improve network segmentation performance.
- We adopt the OHEM cross-entropy loss to address the issue of imbalanced samples. As a result, our framework exhibits exceptional performance on the NEU-seg defect dataset, particularly in enhancing the segmentation accuracy of challenging samples.
- A novel attention-based feature-fused network for surface defect segmentation is proposed, our proposed method achieves an 80.94% mIoU on the NEU-seg dataset, outperforming other state-of-the-art methods.
2. Related Work
2.1. Traditional Detection Approaches
2.2. Deep Learning Segmentation Approaches
2.3. Attention Mechanism
3. Proposed Method
3.1. Residual-RepGhost-Dblock Module
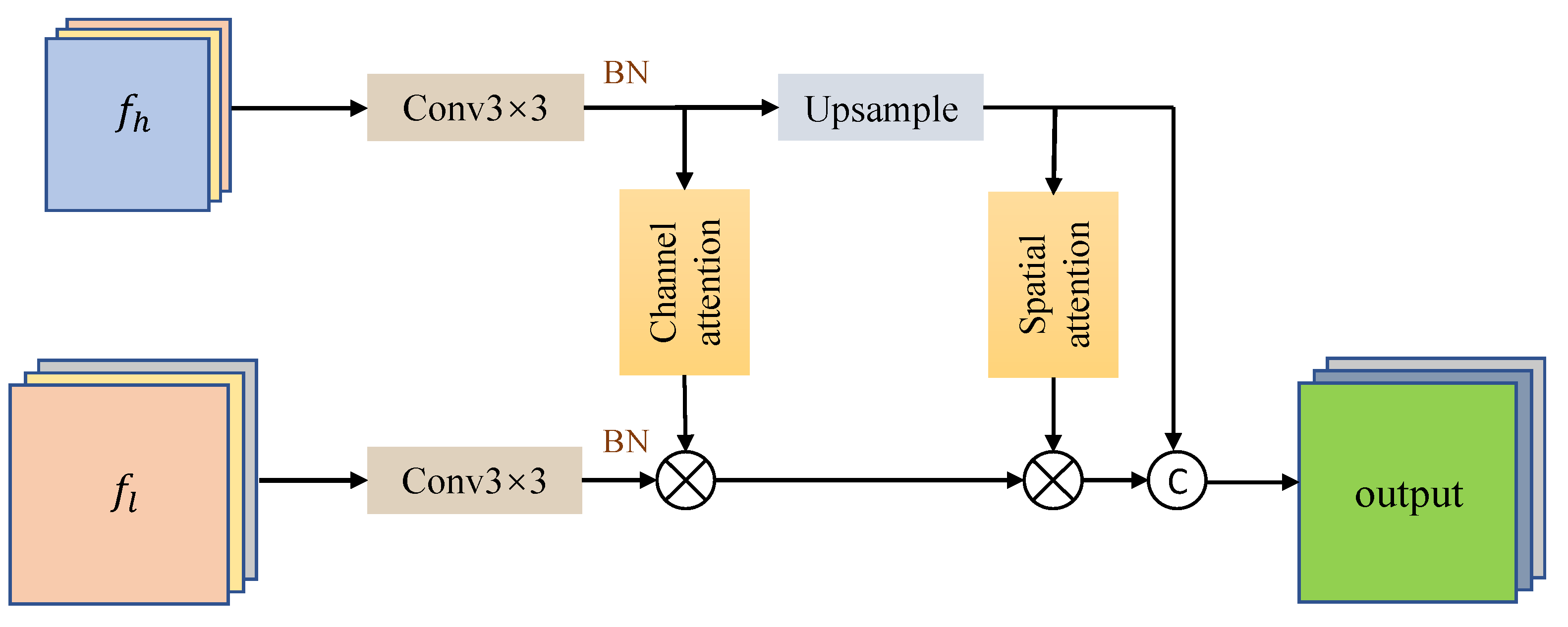
3.2. Global Feature Attention Module
3.2.1. Channel Attention Module
3.2.2. Spatial Attention Module
3.3. Loss Function
4. Experiments and Results
4.1. Dataset
4.2. Evaluation Metrics
4.3. Implementation Details
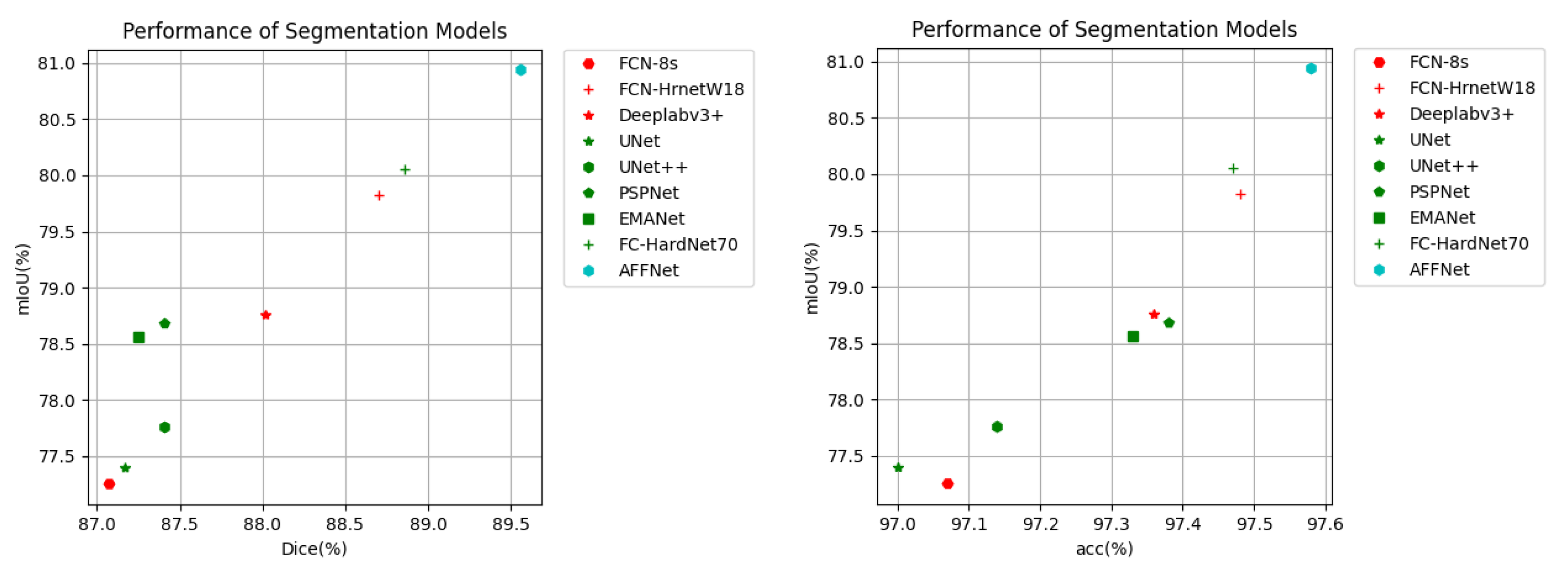
4.4. Comparative Experiments with State-of-the-Art Methods
4.5. Ablation Study
4.5.1. Effectiveness of the RRD Module
4.5.2. Effectiveness of the GFA Module
4.5.3. The Ablation Studies for the OHEM Strategy
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Zhang, H.; Jin, X.; Wu, Q.J.; Wang, Y.; He, Z.; Yang, Y. Automatic visual detection system of railway surface defects with curvature filter and improved Gaussian mixture model. IEEE Trans. Instrum. Meas. 2018, 67, 1593–1608. [Google Scholar] [CrossRef]
- Wang, J.; Li, Q.; Gan, J.; Yu, H.; Yang, X. Surface defect detection via entity sparsity pursuit with intrinsic priors. IEEE Trans. Ind. Inform. 2019, 16, 141–150. [Google Scholar] [CrossRef]
- Luo, Q.; Sun, Y.; Li, P.; Simpson, O.; Tian, L.; He, Y. Generalized completed local binary patterns for time-efficient steel surface defect classification. IEEE Trans. Instrum. Meas. 2018, 68, 667–679. [Google Scholar] [CrossRef]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef] [PubMed]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Chen, F.C.; Jahanshahi, M.R. NB-FCN: Real-time accurate crack detection in inspection videos using deep fully convolutional network and parametric data fusion. IEEE Trans. Instrum. Meas. 2019, 69, 5325–5334. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention–MICCAI 2015: 18th International Conference; Munich, Germany, 5–9 October 2015, Proceedings, Part III 18; Springer: Berlin/Heidelberg, Germany, 2015; pp. 234–241. [Google Scholar]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. Segnet: A deep convolutional encoder-decoder architecture for image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid scene parsing network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2881–2890. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 834–848. [Google Scholar] [CrossRef]
- Xu, J.; Lu, K.; Wang, H. Attention fusion network for multi-spectral semantic segmentation. Pattern Recognit. Lett. 2021, 146, 179–184. [Google Scholar] [CrossRef]
- Yan, L.; Cui, Y.; Chen, Y.; Liu, D. Hierarchical attention fusion for geo-localization. In Proceedings of the ICASSP 2021–2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Virtual, 6–12 June 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 2220–2224. [Google Scholar]
- Wang, J.; Huang, R.; Guo, S.; Li, L.; Zhu, M.; Yang, S.; Jiao, L. NAS-Guided Lightweight Multiscale Attention Fusion Network for Hyperspectral Image Classification. IEEE Trans. Geosci. Remote Sens. 2021, 59, 8754–8767. [Google Scholar] [CrossRef]
- Liang, Y.; Qin, G.; Sun, M.; Yan, J.; Jiang, H. MAFNet: Multi-style attention fusion network for salient object detection. Neurocomputing 2021, 422, 22–33. [Google Scholar] [CrossRef]
- Chu, M.; Gong, R. Invariant feature extraction method based on smoothed local binary pattern for strip steel surface defect. ISIJ Int. 2015, 55, 1956–1962. [Google Scholar] [CrossRef]
- Truong, M.T.N.; Kim, S. Automatic image thresholding using Otsu’s method and entropy weighting scheme for surface defect detection. Soft Comput. 2018, 22, 4197–4203. [Google Scholar] [CrossRef]
- Su, B.; Chen, H.; Zhu, Y.; Liu, W.; Liu, K. Classification of manufacturing defects in multicrystalline solar cells with novel feature descriptor. IEEE Trans. Instrum. Meas. 2019, 68, 4675–4688. [Google Scholar] [CrossRef]
- Luo, Q.; Fang, X.; Sun, Y.; Liu, L.; Ai, J.; Yang, C.; Simpson, O. Surface defect classification for hot-rolled steel strips by selectively dominant local binary patterns. IEEE Access 2019, 7, 23488–23499. [Google Scholar] [CrossRef]
- Zhao, J.; Peng, Y.; Yan, Y. Steel Surface Defect Classification Based on Discriminant Manifold Regularized Local Descriptor. IEEE Access 2018, 6, 71719–71731. [Google Scholar] [CrossRef]
- Liu, Y.; Xu, K.; Xu, J. An Improved MB-LBP Defect Recognition Approach for the Surface of Steel Plates. Appl. Sci. 2019, 9, 4222. [Google Scholar] [CrossRef]
- Navarro, P.J.; Fernández-Isla, C.; Alcover, P.M.; Suardíaz, J. Defect detection in textures through the use of entropy as a means for automatically selecting the wavelet decomposition level. Sensors 2016, 16, 1178. [Google Scholar] [CrossRef]
- Sharma, P.; Said, Z.; Kumar, A.; Nizetic, S.; Pandey, A.; Hoang, A.T.; Huang, Z.; Afzal, A.; Li, C.; Le, A.T.; et al. Recent advances in machine learning research for nanofluid-based heat transfer in renewable energy system. Energy Fuels 2022, 36, 6626–6658. [Google Scholar] [CrossRef]
- Sharma, P.; Bora, B.J. A Review of Modern Machine Learning Techniques in the Prediction of Remaining Useful Life of Lithium-Ion Batteries. Batteries 2023, 9, 13. [Google Scholar] [CrossRef]
- Liu, Z.; Fang, L.; Jiang, D.; Qu, R. A machine-learning-based fault diagnosis method with adaptive secondary sampling for multiphase drive systems. IEEE Trans. Power Electron. 2022, 37, 8767–8772. [Google Scholar] [CrossRef]
- Ren, M.; Wang, X.; Xiao, G.; Chen, M.; Fu, L. Fast defect inspection based on data-driven photometric stereo. IEEE Trans. Instrum. Meas. 2018, 68, 1148–1156. [Google Scholar] [CrossRef]
- Li, D.; Li, Y.; Xie, Q.; Wu, Y.; Yu, Z.; Wang, J. Tiny defect detection in high-resolution aero-engine blade images via a coarse-to-fine framework. IEEE Trans. Instrum. Meas. 2021, 70, 3512712. [Google Scholar] [CrossRef]
- Ju, Y.; Jian, M.; Guo, S.; Wang, Y.; Zhou, H.; Dong, J. Incorporating lambertian priors into surface normals measurement. IEEE Trans. Instrum. Meas. 2021, 70, 5012913. [Google Scholar] [CrossRef]
- Ren, M.; Xiao, G.; Zhu, L.; Zeng, W.; Whitehouse, D. Model-driven photometric stereo for in-process inspection of non-diffuse curved surfaces. CIRP Ann. 2019, 68, 563–566. [Google Scholar] [CrossRef]
- Lu, P.; Jing, J.; Huang, Y. MRD-net: An effective CNN-based segmentation network for surface defect detection. IEEE Trans. Instrum. Meas. 2022, 71, 2516812. [Google Scholar] [CrossRef]
- Zhang, J.; Ding, R.; Ban, M.; Guo, T. FDSNeT: An Accurate Real-Time Surface Defect Segmentation Network. In Proceedings of the ICASSP 2022–2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Singapore, 22–27 May 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 3803–3807. [Google Scholar]
- Tian, S.; Huang, P.; Ma, H.; Wang, J.; Zhou, X.; Zhang, S.; Zhou, J.; Huang, R.; Li, Y. CASDD: Automatic surface defect detection using a complementary adversarial network. IEEE Sens. J. 2022, 22, 19583–19595. [Google Scholar] [CrossRef]
- Zhou, X.; Fang, H.; Fei, X.; Shi, R.; Zhang, J. Edge-Aware Multi-Level Interactive Network for Salient Object Detection of Strip Steel Surface Defects. IEEE Access 2021, 9, 149465–149476. [Google Scholar] [CrossRef]
- Li, Z.; Wu, C.; Han, Q.; Hou, M.; Chen, G.; Weng, T. CASI-Net: A Novel and Effect Steel Surface Defect Classification Method Based on Coordinate Attention and Self-Interaction Mechanism. Mathematics 2022, 10, 963. [Google Scholar] [CrossRef]
- Tang, Z.; Tian, E.; Wang, Y.; Wang, L.; Yang, T. Nondestructive defect detection in castings by using spatial attention bilinear convolutional neural network. IEEE Trans. Ind. Inform. 2020, 17, 82–89. [Google Scholar] [CrossRef]
- Pan, Y.; Zhang, L. Dual attention deep learning network for automatic steel surface defect segmentation. Comput.-Aided Civ. Infrastruct. Eng. 2022, 37, 1468–1487. [Google Scholar] [CrossRef]
- Wu, Y.; Qin, Y.; Qian, Y.; Guo, F.; Wang, Z.; Jia, L. Hybrid deep learning architecture for rail surface segmentation and surface defect detection. Comput.-Aided Civ. Infrastruct. Eng. 2022, 37, 227–244. [Google Scholar] [CrossRef]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Wang, X.; Girshick, R.; Gupta, A.; He, K. Non-local neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7794–7803. [Google Scholar]
- Fu, J.; Liu, J.; Tian, H.; Li, Y.; Bao, Y.; Fang, Z.; Lu, H. Dual attention network for scene segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 3146–3154. [Google Scholar]
- Chen, C.; Guo, Z.; Zeng, H.; Xiong, P.; Dong, J. RepGhost: A Hardware-Efficient Ghost Module via Re-parameterization. arXiv 2022, arXiv:2211.06088. [Google Scholar]
- Hou, Q.; Zhou, D.; Feng, J. Coordinate attention for efficient mobile network design. In Proceedings of theIEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 13713–13722. [Google Scholar]
- Zhang, Z.; Sabuncu, M. Generalized cross entropy loss for training deep neural networks with noisy labels. In Proceedings of the 32nd International Conference on Neural Information Processing Systems, Montreal, QC, Canada, 3–8 December 2018; pp. 8792–8802. [Google Scholar]
- Bao, Y.; Song, K.; Liu, J.; Wang, Y.; Yan, Y.; Yu, H.; Li, X. Triplet-graph reasoning network for few-shot metal generic surface defect segmentation. IEEE Trans. Instrum. Meas. 2021, 70, 5011111. [Google Scholar] [CrossRef]
- Ma, Y.; Yu, D.; Wu, T.; Wang, H. PaddlePaddle: An Open-Source Deep Learning Platform from Industrial Practice. Front. Data Comput. 2019, 1, 105. [Google Scholar] [CrossRef]
- Bottou, L. Large-scale machine learning with stochastic gradient descent. In Proceedings of the COMPSTAT’2010: 19th International Conference on Computational Statistics, Paris, France, 22–27 August 2010; Keynote, Invited and Contributed Papers 2010. Physica-Verlag HD: Heidelberg, Germany, 2010. [Google Scholar]
- Zhou, Z.; Rahman Siddiquee, M.M.; Tajbakhsh, N.; Liang, J. Unet++: A nested u-net architecture for medical image segmentation. In Deep Learning in Medical Image Analysis and Multimodal Learning for Clinical Decision Support, Proceedings of the 4th International Workshop, DLMIA 2018, and 8th International Workshop, ML-CDS 2018, Held in Conjunction with MICCAI 2018, Granada, Spain, 20 September 2018; Proceedings 4; Springer: Berlin/Heidelberg, Germany, 2018; pp. 3–11. [Google Scholar]
- Wang, J.; Sun, K.; Cheng, T.; Jiang, B.; Deng, C.; Zhao, Y.; Liu, D.; Mu, Y.; Tan, M.; Wang, X.; et al. Deep high-resolution representation learning for visual recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 43, 3349–3364. [Google Scholar] [CrossRef] [PubMed]
- Chao, P.; Kao, C.Y.; Ruan, Y.S.; Huang, C.H.; Lin, Y.L. Hardnet: A low memory traffic network. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 3552–3561. [Google Scholar]
- Li, X.; Zhong, Z.; Wu, J.; Yang, Y.; Lin, Z.; Liu, H. Expectation-maximization attention networks for semantic segmentation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 9167–9176. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | mIoU (%) | Dice (%) | mAP | Recall |
|---|---|---|---|---|
| FCN-8s [5] | 77.25 | 87.07 | 0.9707 | 0.8758 |
| FCN-hrnetw18 [49] | 79.82 | 88.70 | 0.9748 | 0.8712 |
| Deeplabv3+ [11] | 78.76 | 88.02 | 0.9736 | 0.8739 |
| UNet [7] | 77.40 | 87.17 | 0.9700 | 0.8786 |
| UNet++ [48] | 77.76 | 87.41 | 0.9714 | 0.8669 |
| PSPNet [9] | 78.68 | 87.41 | 0.9738 | 0.8603 |
| EMANet [51] | 78.56 | 87.25 | 0.9733 | 0.8544 |
| FC-HardNet70 [50] | 80.05 | 88.86 | 0.9747 | 0.8853 |
| AFFNet (ours) |
| Method | Params (MB) | FLOPs (GB) | Inference Time (ms/per Image) |
|---|---|---|---|
| FCN-8s [5] | 18.6 | 25.5 | |
| FCN-hrnetw18 [49] | 9.67 | 4.64 | 50.79 |
| Deeplabv3+ [11] | 26.79 | 28.55 | 18.03 |
| UNet [7] | 13.46 | 31.15 | 13.17 |
| UNet++ [48] | 8.37 | 30.06 | 16.46 |
| PSPNet [9] | 67.9 | 66.43 | 25.68 |
| EMANet [51] | 42.41 | 44.57 | 19.27 |
| FC-HardNet70 [50] | 19.7 | ||
| AFFNet (ours) | 11.42 | 25.16 | 20.89 |
| Method | mIoU (%) | Gain |
|---|---|---|
| UNet | 77.40 | - |
| UNet+RRD | 79.93 | +2.53 |
| UNet+GFA | 78.68 | +1.28 |
| UNet+RRD+GFA | 80.54 | +3.14 |
| Ours (+OHEM) | +3.54 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, X.; Fu, C.; Tie, M.; Sham, C.-W.; Ma, H. AFFNet: An Attention-Based Feature-Fused Network for Surface Defect Segmentation. Appl. Sci. 2023, 13, 6428. https://doi.org/10.3390/app13116428
Chen X, Fu C, Tie M, Sham C-W, Ma H. AFFNet: An Attention-Based Feature-Fused Network for Surface Defect Segmentation. Applied Sciences. 2023; 13(11):6428. https://doi.org/10.3390/app13116428
Chicago/Turabian StyleChen, Xiaodong, Chong Fu, Ming Tie, Chiu-Wing Sham, and Hongfeng Ma. 2023. "AFFNet: An Attention-Based Feature-Fused Network for Surface Defect Segmentation" Applied Sciences 13, no. 11: 6428. https://doi.org/10.3390/app13116428