
Contactless Palm Vein Recognition Based on Attention-Gated Residual U-Net and ECA-ResNet


Abstract
:1. Introduction
- We propose a deep-learning-based approach for both palm vein segmentation and recognition with promising identification and verification results;
- With the advantages of the attention gate, we propose an attention-aware residual U-Net segmentation model to learn domain-specific features such as vein vascular structure from low contrast and blurry palm images, allowing for more precise authentication performance;
- We propose a light-weight attention-aware feature extractor for palm vein recognition that can efficiently extract palm vein features without any extra computational overhead;
- We propose the most effective loss function for palm vein discriminative learning by combining state-of-the-art loss functions, such as ArcFace, focal loss, and triplet loss.
2. Related Work
2.1. Handcrafted Methods
2.2. Deep Learning Methods
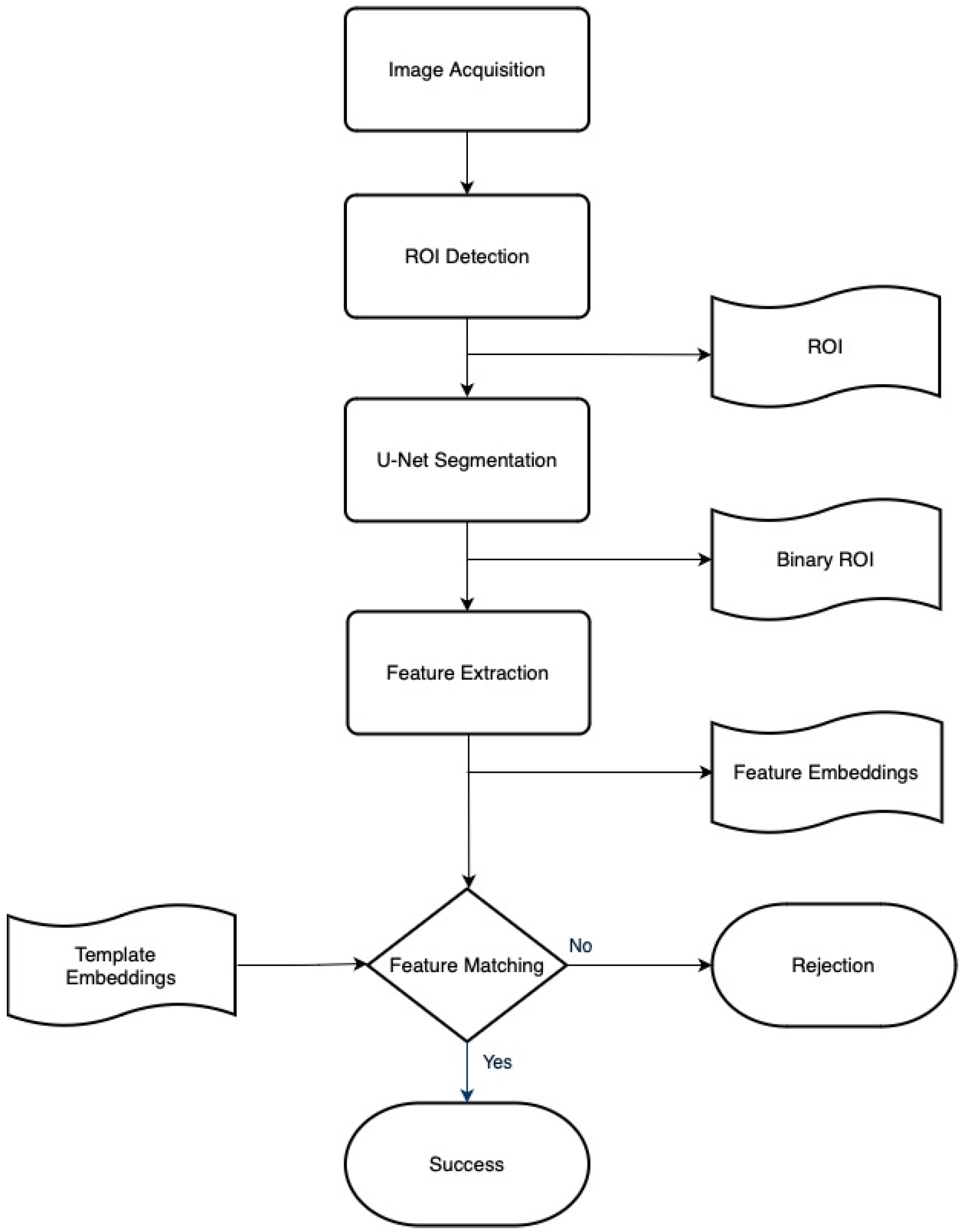
3. Attention-Gated Residual U-Net and ECA-ResNet
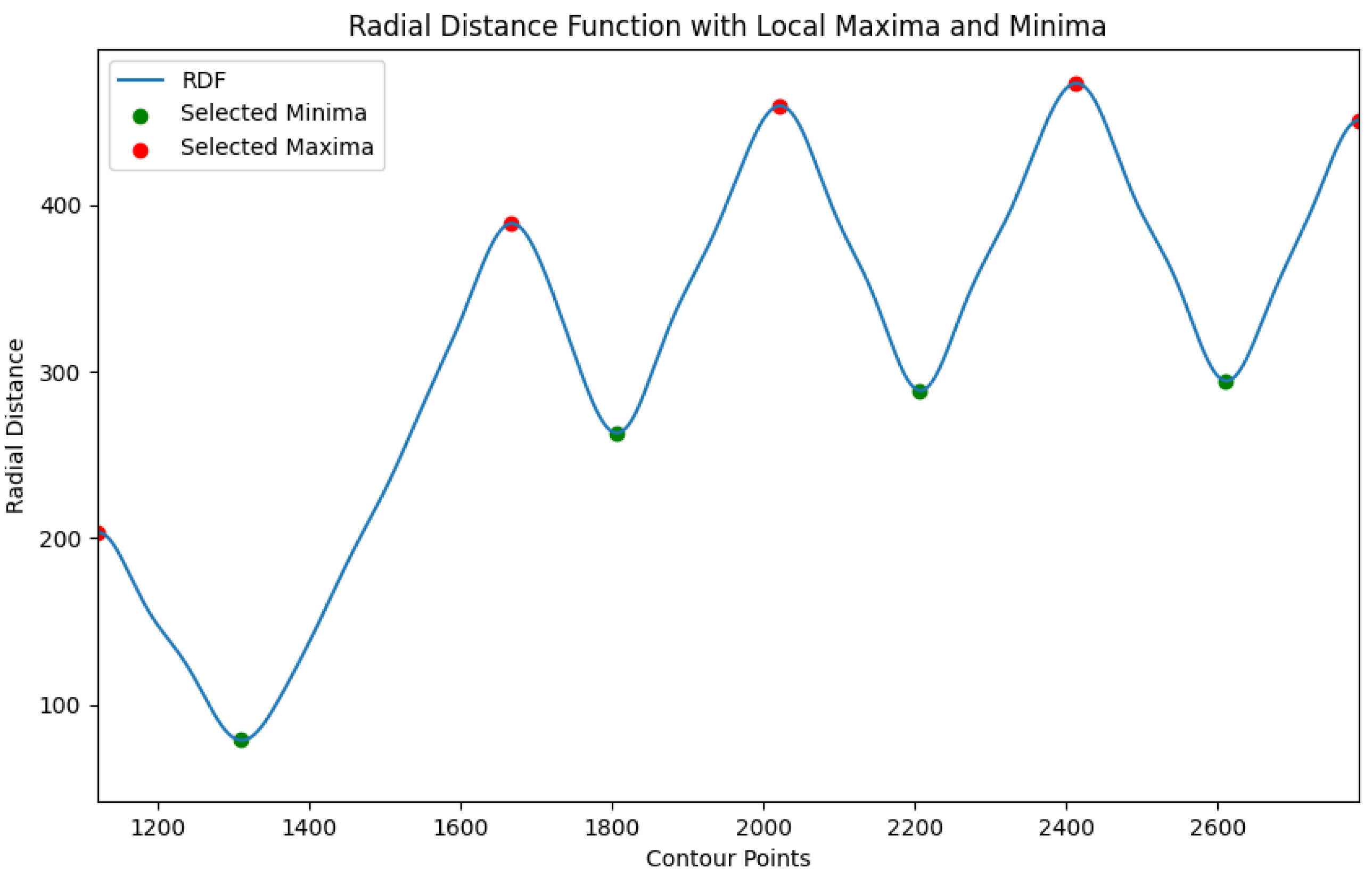
3.1. Region of Interest Extraction
3.2. Palm Vein Segmentation
3.2.1. Ground-Truth Labeling
3.2.2. Attention Mechanism
3.2.3. Residual Units
3.2.4. Proposed Attention-Gated Residual U-Net
3.2.5. Loss Function
3.3. Palm Vein Recognition
3.3.1. Efficient Channel Attention
3.3.2. Proposed ECA-ResNet
3.3.3. Loss Function
4. Experiments
4.1. Dataset
4.2. Experimental Setup
4.3. Evaluation Metrics
4.3.1. IoU Coefficient
4.3.2. Dice Similarity Coefficient
4.3.3. Identification Accuracy
4.3.4. Precision, Recall, and F1 Score
4.3.5. Equal Error Rate (EER)
5. Results
5.1. Palm Vein Segmentation
5.2. Palm Vein Authentication
Ablation Study
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Kumar, A.; Zhou, Y. Human identification using finger images. IEEE Trans. Image Process. 2011, 21, 2228–2244. [Google Scholar] [CrossRef] [PubMed]
- Wildes, R.P. Iris recognition: An emerging biometric technology. Proc. IEEE 1997, 85, 1348–1363. [Google Scholar] [CrossRef]
- Florian, S.; Kalenichenko, D.; Philbin, J. FaceNet: A unified embedding for face recognition and clustering. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Lu, G.; Zhang, D.; Wang, K. Palmprint recognition using eigenpalms features. Pattern Recognit. Lett. 2003, 24, 1463–1467. [Google Scholar] [CrossRef]
- Wu, X.; Zhang, D.; Wang, K. Fisherpalms based palmprint recognition. Pattern Recognit. Lett. 2003, 24, 2829–2838. [Google Scholar]
- Han, A.W.-Y.; Lee, J.-C. Palm vein recognition using adaptive Gabor filter. Expert Syst. Appl. 2012, 39, 13225–13234. [Google Scholar] [CrossRef]
- Van, H.T.; Duong, C.M.; Van Vu, G.; Le, T.H. Palm vein recognition using enhanced symmetry local binary pattern and sift features. In Proceedings of the 2019 19th International Symposium on Communications and Information Technologies (ISCIT), Ho Chi Minh City, Vietnam, 25–27 September 2019; pp. 311–316. [Google Scholar]
- Deng, J.; Guo, J.; Xue, N.; Zafeiriou, S. Arcface: Additive angular margin loss for deep face recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Wang, H.; Wang, Y.; Zhou, Z.; Ji, X.; Gong, D.; Zhou, J.; Li, Z.; Liu, W. Cosface: Large margin cosine loss for deep face recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 5265–5274. [Google Scholar]
- Zhang, Z.; Liu, Q.; Wang, Y. Road extraction by deep residual U-net. IEEE Geosci. Remote Sens. Lett. 2018, 15, 749–753. [Google Scholar] [CrossRef]
- Wang, R.; Wang, G.; Chen, Z.; Zeng, Z.; Wang, Y. A palm vein identification system based on Gabor wavelet features. Neural Comput. Appl. 2014, 24, 161–168. [Google Scholar] [CrossRef]
- Wu, K.-S.; Lee, J.-C.; Lo, T.-M.; Chang, K.-C.; Chang, C.-P. A secure palm vein recognition system. J. Syst. Softw. 2013, 86, 2870–2876. [Google Scholar] [CrossRef]
- Lu, W.; Li, M.; Zhang, L. Palm vein recognition using directional features derived from local binary patterns. Int. J. Signal Process. Image Process. Pattern Recognit. 2013, 9, 87–98. [Google Scholar] [CrossRef]
- Mirmohamadsadeghi, L.; Drygajlo, A. Palm vein recognition with local binary patterns and local derivative patterns. In Proceedings of the 2011 International Joint Conference on Biometrics (IJCB), Washington, DC, USA, 11–13 October 2011; pp. 1–6. [Google Scholar] [CrossRef]
- Aglio-Caballero, A.; Rios-Sanchez, B.; Sanchez-Avila, C.; Giles, M.J.M.D. Analysis of local binary patterns and uniform local binary patterns for palm vein biometric recognition. In Proceedings of the 2017 International Carnahan Conference on Security Technology (ICCST), Madrid, Spain, 23–26 October 2017; pp. 1–6. [Google Scholar] [CrossRef]
- Kang, W.; Wu, Q. Contactless palm vein recognition using a mutual foreground-based local binary pattern. IEEE Trans. Inf. Forensics Secur. 2014, 9, 1974–1985. [Google Scholar] [CrossRef]
- Aberni, Y.; Boubchir, L.; Daachi, B. Palm vein recognition based on competitive coding scheme using multi-scale local binary pattern with ant colony optimization. Pattern Recognit. Lett. 2020, 136, 101–110. [Google Scholar] [CrossRef]
- Fronitasari, D.; Gunawan, D. Palm vein recognition by using modified of local binary pattern (LBP) for extraction feature. In Proceedings of the 2017 15th International Conference on Quality in Research (QiR): International Symposium on Electrical and Computer Engineering, Nusa Dua, Bali, Indonesia, 24–27 July 2017; pp. 18–22. [Google Scholar] [CrossRef]
- Mirmohamadsadeghi, L.; Drygajlo, A. Palm vein recognition with local texture patterns. IET Biom. 2014, 3, 198–206. [Google Scholar] [CrossRef]
- Saxena, J.; Teckchandani, K.; Pandey, P.; Dutta, M.K.; Travieso, C.M.; Alonso-Hernández, J.B. Palm vein recognition using local tetra patterns. In Proceedings of the 2015 4th International Work Conference on Bioinspired Intelligence (IWOBI), San Sebastian, Spain, 10–12 June 2015; pp. 151–156. [Google Scholar]
- Rahul, R.C.; Cherian, M.; Mohan, M.C.M. A novel MF-LDTP approach for contactless palm vein recognition. In Proceedings of the 2015 International Conference on Computing and Network Communications (CoCoNet), Trivandrum, India, 16–19 December 2015; pp. 793–798. [Google Scholar] [CrossRef]
- Akbar, A.F.; Wirayudha, T.A.B.; Sulistiyo, M.D. Palm vein biometric identification system using local derivative pattern. In Proceedings of the 2016 4th International Conference on Information and Communication Technology (ICoICT), Bandung, Indonesia, 25–27 May 2016; pp. 1–6. [Google Scholar] [CrossRef]
- Kasiselvanathan, M.; Sangeetha, V.; Kalaiselvi, A. Palm pattern recognition using scale invariant feature transform. Int. J. Intell. Sustain. Comput. 2020, 1, 44–52. [Google Scholar] [CrossRef]
- Gurunathan, V.; Sathiyapriya, T.; Sudhakar, R. Multimodal biometric recognition system using SURF algorithm. In Proceedings of the 2016 10th International Conference on Intelligent Systems and Control (ISCO), Coimbatore, India, 7–8 January 2016; pp. 1–5. [Google Scholar] [CrossRef]
- Kang, W.; Liu, Y.; Wu, Q.; Yue, X. Contact-free palm-vein recognition based on local invariant features. PLoS ONE 2014, 9, e97548. [Google Scholar] [CrossRef]
- Kim, H.G.; Lee, E.J.; Yoon, G.J.; Yang, S.D.; Lee, E.C.; Sang, M.Y. Illumination normalization for sift based finger vein authentication. In Proceedings of the International Symposium on Visual Computing, Rethymnon, Greece, 16–18 July 2012; Springer: Berlin, Germany, 2012; pp. 21–30. [Google Scholar]
- Xiuyuan, L.; Tiegen, L.; Shichao, D.; Jin, H.; Yun, W. Fast recognition of hand vein with surf descriptors. Chin. J. Sci. Instrum. 2011, 32, 831–836. [Google Scholar]
- Perwira, D.Y.; Agung, B.W.T.; Sulistiyo, M.D. Personal palm vein identification using principal component analysis and probabilistic neural network. In Proceedings of the 2014 International Conference on Information Technology Systems and Innovation (ICITSI), Bandung, Indonesia, 24–27 November 2014; pp. 99–104. [Google Scholar] [CrossRef]
- Bayoumi, S.; Al-Zahrani, S.; Sheikh, A.; Al-Sebayel, G.; Al-Magooshi, S.; Al-Sayigh, S. PCA-based palm vein authentication system. In Proceedings of the 2013 International Conference on Information Science and Applications (ICISA), Pattaya, Thailand, 24–26 June 2013; pp. 1–3. [Google Scholar] [CrossRef]
- Ahmad, F.; Cheng, L.-M.; Khan, A. Lightweight and privacy- preserving template generation for palm-vein-based human recognition. IEEE Trans. Inf. Forensics Secur. 2020, 15, 184–194. [Google Scholar] [CrossRef]
- Micheletto, M.; Orru, G.; Rida, I.; Ghiani, L.; Marcialis, G.L. A multiple classifiers-based approach to palmvein identification. In Proceedings of the 2018 Eighth International Conference on Image Processing Theory, Tools and Applications (IPTA), Xi’an, China, 7–10 November 2018; pp. 1–6. [Google Scholar]
- Rizki, F.; Wirayuda, T.A.B.; Ramadhani, K.N. Identity recognition based on palm vein feature using two-dimensional linear discriminant analysis. In Proceedings of the 2016 1st International Conference on Information Technology, Information Systems and Electrical Engineering (ICITISEE), Yogyakarta, Indonesia, 23–24 August 2016; pp. 21–25. [Google Scholar]
- Elnasir, S.; Shamsuddin, S.M. Palm vein recognition based on 2D-discrete wavelet transform and linear discrimination analysis. Int. J. Adv. Soft Comput. Appl. 2014, 6, 43–59. [Google Scholar]
- Elnasir, S.; Shamsuddin, S.M. Proposed scheme for palm vein recognition based on linear discrimination analysis and nearest neighbour classifier. In Proceedings of the 2014 International Symposium on Biometrics and Security Technologies (ISBAST), Kuala Lumpur, Malaysia, 26–27 August 2014; pp. 67–72. [Google Scholar]
- Obayya, M.I.; El-Ghandour, M.; Alrowais, F. Contactless palm vein authentication using deep learning with bayesian optimization. IEEE Access 2021, 9, 1940–1957. [Google Scholar] [CrossRef]
- Pan, Z.; Wang, J.; Wang, G.; Zhu, J. Multi-Scale Deep Representation Aggregation for Vein Recognition. IEEE Trans. Inf. Forensics Secur. 2021, 16, 1–15. [Google Scholar] [CrossRef]
- Wei, W.; Wang, Q.; Yu, S.; Luo, Q.; Lin, S.; Han, Z.; Tang, Y. Outside Box and Contactless Palm Vein Recognition Based on a Wavelet Denoising ResNet. IEEE Access 2021, 9, 82471–82484. [Google Scholar]
- Pan, Z.; Wang, J.; Shen, Z.; Chen, X.; Li, M. Multi-layer convolutional features concatenation with semantic feature selector for vein recognition. IEEE Access 2019, 7, 90608–90619. [Google Scholar] [CrossRef]
- Yao, C.Y.; Jhong, S.Y.; Hsia, C.H.; Hua, K.L. Explainable AI: A Multispectral Palm-Vein Identification System with New Augmentation Features. ACM Trans. Multimed. Comput. Commun. Appl. 2021, 17, 1–21. [Google Scholar] [CrossRef]
- Felix, M.; Abdulla, W.H. Segmentation of Palm Vein Images Using U-Net. In Proceedings of the 2020 Asia-Pacific Signal and Information Processing Association Annual Summit and Conference (APSIPA ASC), Auckland, New Zealand, 7–10 December 2020; pp. 64–70. [Google Scholar]
- Wang, P.; Qin, H. Palm-vein verification based on U-net. IOP Conf. Ser. Mater. Sci. Eng. 2020, 806, 012043. [Google Scholar] [CrossRef]
- Thapar, D.; Jaswal, G.; Nigam, A.; Kanhangad, V. Pvsnet: Palm Vein Authentication Siamese Network Trained Using Triplet Loss and Adaptive Hard Mining by Learning Enforced Domain Specific Features; Institute of Electrical and Electronics Engineers Inc.: Hyderabad, India, 2019. [Google Scholar] [CrossRef]
- Tim, J.; Pernus, F.; Likar, B.; Špiclin, Ž. Beyond Frangi: An improved multiscale vesselness filter. In Medical Imaging 2015: Image Processing, Proceedings of the SPIE Medical Imaging, Orlando, FL, USA, 21–26 February 2015; Ourselin, S., Styner, M.A., Eds.; SPIE: Bellingham, WA, USA, 2015; Volume 9413, pp. 623–633. [Google Scholar] [CrossRef]
- Oktay, O.; Schlemper, J.; Folgoc, L.L.; Lee, M.; Heinrich, M.; Misawa, K.; Mori, K.; McDonagh, S.; Hammerla, N.Y.; Kainz, B.; et al. Attention U-Net: Learning where to look for the pancreas. arXiv 2018, arXiv:1804.03999. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar]
- Olaf, R.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Medical Image Computing and Computer-Assisted Intervention; Springer: Cham, Switzerland, 2015. [Google Scholar]
- Hu, J.; Shen, L.; Albanie, S.; Sun, G.; Wu, E. Squeeze-and-excitation networks. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 2011–2023. [Google Scholar] [CrossRef] [PubMed]
- Wang, Q.; Wu, B.; Zhu, P.; Li, P.; Zuo, W.; Hu, Q. ECA-Net: Efficient Channel Attention for Deep Convolutional Neural Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Elad, H.; Ailon, N. Deep metric learning using triplet network. In International Workshop on Similarity-Based Pattern Recognition; Springer: Cham, Switzerland, 2015. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- CASIA-MS-PalmprintV1. Available online: http://biometrics.idealtest.org/ (accessed on 1 May 2023).
- Meraoumia, A.; Kadri, F.; Bendjenna, H.; Chitroub, S.; Bouridane, A. Improving biometric identification performance using PCANet deep learning and multispectral palmprint. In Signal Processing for Security Technologies; Springer: Cham, Switzerland, 2017; pp. 51–69. [Google Scholar]
- Htet, A.S.M.; Lee, H.J. TripletGAN VeinNet: Palm Vein Recognition Based on Generative Adversarial Network and Triplet Loss. In Proceedings of the 2021 International Conference on Computer Engineering and Artificial Intelligence (ICCEAI), Shanghai, China, 27–29 August 2021. [Google Scholar]
- Ananthi, G.; Sekar, J.R.; Arivazhagan, S. Ensembling Scale Invariant and Multiresolution Gabor Scores for Palm Vein Identification. Inf. Technol. Control 2022, 51, 704–722. [Google Scholar] [CrossRef]
- Chen, Y.-Y.; Hsia, C.; Chen, P. Contactless multispectral palm-vein recognition with lightweight convolutional neural network. IEEE Access 2021, 9, 149796–149806. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | IoU Coef. | Dice Coef. |
|---|---|---|
| U-Net | 95.59 | 97.75 |
| Attention U-Net | 95.83 | 97.87 |
| Residual U-Net | 96.16 | 98.04 |
| Proposed method | 96.24 | 98.09 |
| Method | Accuracy | ERR |
|---|---|---|
| Without vein segmentation | 98.375 | 0.547 |
| Proposed method | 100 | 0.018 |
| Method | Year | Accuracy |
|---|---|---|
| PCANet with deep learning [52] | 2017 | 96.50 |
| PVSNet [42] | 2018 | 85.16 |
| Hong et al. [7] | 2019 | 96.33 |
| CNN + Bayesian optimization [35] | 2020 | 99.40 |
| TripletGAN VeinNet [53] | 2021 | 97 |
| Explainable palm vein recognition [39] | 2021 | 100 |
| Ensembling scale invariant and multiresolution Gabor scores [54] | 2022 | 99.73 |
| Proposed Method | 2023 | 100 |
| Method | Year | ERR |
|---|---|---|
| PCANet with deep learning [52] | 2017 | 0.949 |
| PVSNet [42] | 2018 | 3.170 |
| Wang et al. [41] | 2019 | 0.470 |
| CNN + Bayesian optimization [35] | 2020 | 0.068 |
| Chen et al. [55] | 2021 | 0.056 |
| Ensembling scale invariant and multiresolution Gabor scores [54] | 2022 | 0.026 |
| Proposed Method | 2023 | 0.018 |
| Loss Func. | Train Acc. | Test Acc. | Recall | Precision | F1 | ERR |
|---|---|---|---|---|---|---|
| Triplet loss | 100 | 98.95 | 91.66 | 95.37 | 93.48 | 0.096 |
| Focal loss | 98.44 | 96.25 | 83.33 | 92.59 | 87.72 | 0.400 |
| ArcFace loss | 100 | 99.58 | 96.66 | 99.71 | 98.16 | 0.065 |
| ArcFace + triplet loss | 100 | 99.79 | 97.50 | 99.71 | 98.59 | 0.040 |
| ArcFace + focal loss | 100 | 99.58 | 96.94 | 99.71 | 98.31 | 0.052 |
| ArcFace + triplet + focal loss (proposed) | 100 | 100 | 98.61 | 100 | 99.30 | 0.018 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Htet, A.S.M.; Lee, H.J. Contactless Palm Vein Recognition Based on Attention-Gated Residual U-Net and ECA-ResNet. Appl. Sci. 2023, 13, 6363. https://doi.org/10.3390/app13116363
Htet ASM, Lee HJ. Contactless Palm Vein Recognition Based on Attention-Gated Residual U-Net and ECA-ResNet. Applied Sciences. 2023; 13(11):6363. https://doi.org/10.3390/app13116363
Chicago/Turabian StyleHtet, Aung Si Min, and Hyo Jong Lee. 2023. "Contactless Palm Vein Recognition Based on Attention-Gated Residual U-Net and ECA-ResNet" Applied Sciences 13, no. 11: 6363. https://doi.org/10.3390/app13116363