1. Introduction
The purpose of investment is quite clear. There is no question that it is profitable, and stock trading is one of the most general arbitrage methods for investment. Nevertheless, it is also sure that making profits by stock trading is not easy because the real-time changes in the stock market are hard to predict. For this reason, there have been several attempts to create an automated stock trading system that guarantees a positive return, and reinforcement learning is one of the most common critical ideas for these attempts. The emergence of reinforcement learning (RL) in the financial market is driven by several advantages inherent in this artificial intelligence field. In particular, RL allows combining the “forecasting” and the “portfolio construction” tasks into one integrated step: the automated stock trading system thereby closely connects machine learning issues with the objectives of investors [
1]. Developing a robust automated stock trading system is one of the challenges for financial engineers and officials since it is not easy to consider all relevant factors in a complicated and fluctuating stock market in a model [
2,
3,
4]. There are two main existing approaches for stock trading: traditional approaches [
5] and Markov Decision Process approaches that use dynamic programming to draw the optimal trading strategy [
6,
7,
8,
9]. According to [
10], these approaches do not derive satisfactory results. As an alternative to these approaches, ref. [
10] proposes an ensemble strategy that combines three DRL algorithms to find the optimal trading strategy in a complex and dynamic stock market. The three actor–critic algorithms [
11] are Advantage Actor Critic (A2C) [
12,
13], Deep Deterministic Policy Gradient (DDPG) [
14,
15,
16], and Proximal Policy Optimization (PPO) [
11,
15,
17].
Even though we believe that the ensemble strategy of [
10] is an innovative idea, we intended to verify it through empirical analysis. We judged that it was not easy to grasp the actual performance of DRL agents, including the ensemble strategy, with only the single case experiment shown in [
10]. Thus, we conducted five experiments for each trading agent and analyzed the results. As an extension to empirical analysis, we added a new ensemble-based algorithm as an agent with the existing DRL-based trading strategy. Secondly, we extended the model to various markets and applied the model. These attempts stemmed from the question of whether automated stock trading could generally assure high returns.
The results and insights obtained through the empirical analysis are as follows: First, the new ensemble-based Remake Ensemble did not show noticeable performance compared to other agents. Therefore, we concluded that adding a new algorithm is not a sure solution to contribute to the general performance of automated stock trading, even if the algorithm is based on a novel idea. Second, the model showed lower performance than the benchmark indexes in the Dow Jones 30, KOSPI, and JPX markets. Along with this, the model performance in each market was also different. For this reason, we reasoned that for the model to obtain stable returns for each market, a trading strategy suitable for each market would be needed. On that count, we refined the trading strategy of the model in a conservative direction to suit the KOSPI market and conducted experiments again. As a result, the performance of each agent in the KOSPI market increased overall, so we extended the model to two other markets and observed the results. In the JPX market, the conservative trading strategy seemed to have a substantial effect, whereas the performance worsened in the Dow Jones 30. Accordingly, we tentatively concluded that while conservative-trading-strategy-based DRL stock trading might be effective in the KOSPI and JPX markets, an aggressive trading strategy in Dow Jones may yield stabler and higher returns.
To summarize, the main contributions of this paper are as follows: (a) We conducted empirical analysis of a stock trading agent trained using an ensemble of multiple reinforcement learning algorithms claiming to achieve outstanding performance. We added more reinforcement learning algorithms to train the ensemble model and tested its performance. (b) We applied the trading strategy to various stock markets such as KOSPI and JPX, in contrast to the previous work that only used DJIA as the evaluation data. The results showed that RL-based trading models do not always guarantee stable returns. (c) We adjusted the actions in the models and studied whether the modified strategy is effective in increasing the robustness of model performance. The lessons learned are that careful design of the actions can be more crucial in terms of outcome than selecting which RL algorithms to use for training the model. The implications of our work are that careful design of actions as well as tuning of parameters is necessary to achieve the best performance with respect to each trading environment.
The remainder of this paper is organized as follows:
Section 2 introduces related works.
Section 3 provides background information, including a brief description of RL and agents for automated stock trading. In
Section 4, we explain our results of empirical analysis, including the performance evaluation of five automated stock trading agents in three different stock markets.
Section 5 describes various attempts to change the trading strategy and the direction and potential for improving the universal performance of automated stock trading. We conclude this paper and suggest some future tasks in
Section 6.
2. Related Work
With the development of artificial intelligence, machine learning naturally has wide applications in finance, such as fundamentals analysis, behavioral finance, technical analysis, financial engineering, and financial technology (FinTech) [
18]. RL can suggest an answer to some sequential decision-making finance problems, such as option pricing, multi-period portfolio optimization, and trading [
19,
20]. RL also has many applications in business management, such as ads, recommendations, customer management, and marketing [
18,
21].
In the option pricing area, ref. [
22] handles Monte Carlo methods. The authors of [
23] deal with the least squares Monte Carlo (LSM) method, which is a standard approach in the finance area for pricing American options. For American-type option pricing, it is critical to calculate the conditional expected value of continuation [
18,
23,
24,
25].
In the portfolio optimization area, following the empirical evidence of return predictability [
26], dynamic portfolio optimization in multi-periods is increasing its value [
27,
28]. The authors of [
29] introduce direct reinforcement learning to trade with no forecasting, and the method is extended with deep neural networks [
30]. This could be a better solution to deal with some problems in risk management with DRL. Generalizing the continuous action spaces and state is essential to applying DRL to dynamic portfolio optimization [
18].
In the trading area, the RL methodology is extensively used to predict future stock prices and decide stock trading policies [
1,
10,
13,
16,
29,
30,
31,
32,
33,
34,
35,
36,
37]. These methods differ in which RL algorithm to use, which data to use as input, and how to define states, actions, and rewards. Some methods use artificial intelligence techniques other than RL, such as genetic algorithms [
38]. Some other methods use information other than historical price data and technical indicators, such as applying sentiment analysis based on finance blog posts and using the results for stock price prediction [
39].
Most of these work claim that their methods can outperform baseline strategies such as “buy and hold”, achieving higher profit. However, most evaluations only cover a single or a few trading environments. Therefore, it is questionable if their methods can be generalized to other environments such as markets other than the New York Stock Exchange. If an RL-based trading algorithm can always gain higher profit in various environments, it may contradict the Efficient Market Hypothesis (EMH) of Eugene Fama [
40]. According to EMH, our stock market is an “efficient” market, where price fully reflects “all available information”. Thus, it is impossible to predict future prices and gain profit that exceeds market returns. Among the three forms of “available information” specified in EMH, most previous work on RL-based automatic stack trading has been related to the weak form, which includes only market transaction data such as past stock prices and trading volume. A major goal of our analysis is to study whether an RL-based stock trading method can find clues that can reliably predict future stock prices and therefore gain profit in a stable manner.
5. Empirical Analysis
The experiments are divided into two parts. One is an experiment based on Dow Jones 30 stocks using the DRL algorithm, which is A2C, PPO, DDPG, and the ensemble strategy shown in [
10]. We used Remake Ensemble as an additional agent. Another is an experiment based on expanding the stock market area to KOSPI and JPX. KOSPI stands for the Korea Composite Stock Price Index, which refers to the composite stock index of the Korea Exchange’s securities market. However, its meaning has expanded, and the securities market is called the KOSPI market. In addition to the Tokyo Stock Exchange, JPX refers to the Japanese Exchange Group, which includes the Osaka Stock Exchange. In this paper, the stock market listed on the Tokyo Stock Exchange under JPX is referred to as the JPX market. The performance of each agent in each stock market is expressed by evaluation metrics: cumulative return, annual return, annual volatility, Sharpe ratio, and max drawdown.
The cumulative return, which is also called aggregate return, is the total change in the investment price over a set time period, and its formula is as follows:
The annual return is the return on the investment that occurred during the year and is calculated as a percentage of the initial investment. In other words, the annual return is the cumulative return on an annual basis, and its formula is as follows:
Volatility is a statistical metric of the variance of returns on a given security or market index. It is often calculated from the standard deviation between returns from that same portfolio. The annual volatility is volatility measured on a yearly basis, and its formula is as follows:
The Sharpe ratio is the average return earned in excess of the risk-free rate per unit of volatility. It is a mathematical measure of the insight that excess returns over a certain period of time can mean greater volatility and risk in an investment strategy. The Sharpe ratio is calculated by the return of the portfolio, the risk-free rate, and the standard deviation of the portfolio value, and the formula is as follows:
The max drawdown, which is an indicator of downside risk over a specified period, means the maximum observed loss from the peak to the low point, which is called the trough point, in the portfolio before reaching a new peak. The formula of the max drawdown is as follows:
These EMs were obtained using pyfolio (
https://github.com/quantopian/pyfolio). The risk-free rate is set to zero by default in pyfolio, and we applied it to calculate the Sharpe ratio without changing the setting.
5.1. Dow Jones 30 Stocks
This experiment with the Dow Jones 30 as its domain is an empirical analysis of the ideas and content of [
10]. Therefore, the process of designing the model, building the environment, stock trading constraints, and the data employed are the same as in [
10]. However, not only did we employ Remake Ensemble as a new trading agent, but there are also two main differences.
The first is the number of experiments. For more objective experimental results, we conducted five experiments and for each agent, and we compared and analyzed the evaluation metrics obtained through each agent. Ref. [
10] only shows the results of a single experiment. Since we believe that the results of a single experiment alone are not adequate for judging the robustness of an automated stock trading system, we ran five backtesting experiments on each trading agent. We calculated the average value of each based on the five evaluation metrics. The results are shown in
Table 1. In particular, we considered the cumulative return as the main criterion among the five evaluation metrics because it is the final benefit obtained through stock arbitrage.
Figure 3 visualizes this evaluation metric in a box chart to make it easier to compare each agent’s experimental results and the DJIA.
Second, the duration of the data employed for trading is different. There was no need to preprocess the data separately because we used the refined Dow Jones 30 data that [
10] used. As in [
10], we used data from 1 January 2009 to 30 September 2015 for training, and validation data were from 1 October 2015 to 31 December 2015. However, we set the trading period from 1 January 2016 to 6 July 2020, while [
10] set the trading period from 1 January 2016 to 8 May 2020. Currently, the number of days of stock market opening used in the test was 1071 days in the case of [
10], and in our case, there were 1134 days in total. We fixed the validation window and rebalance window to 63 days as in the code provided and extended the trading period from the previous one, where rebalance window means the number of months to retrain the model, and the validation window is the number of months to validate the model and select for trading. There is a 63-day difference between the number of stock opening days used in the current work and the number of stock opening days we used.
We ran backtesting by changing the trading period to ensure that the automated stock trading system still showed strong results even if the trading period changed. However, as shown in
Table 1 and
Figure 3, each agent did not generate a higher cumulative return than the DJIA. In our experiments, only DDPG and the ensemble strategy among the five agents produced higher cumulative returns than the DJIA, and there were few differences between the DJIA and their cumulative returns. Moreover, the Remake Ensemble agent showed a lower cumulative return than the DJIA.
5.2. KOSPI and JPX 30 Stocks
We conducted the same experiments by expanding our domain to the KOSPI and JPX stock markets because we wanted to know whether or not the automated stock trading model has general robustness. In the case of the KOSPI and JPX markets, there is no index representing 30 blue-chip corporate stocks similar to the DJIA. Thus, we arbitrarily generated indexes by arithmetically averaging the stock price returns of the top 30 companies in each market based on market capitalization and named them KOSPI30 and JPX30, respectively.
To collect the KOSPI30 and JPX30, we used FinanceDataReader (
https://github.com/financedata-org/FinanceDataReader) and yfinance (
https://github.com/ranaroussi/yfinance) libraries for collecting each market’s 1134 days of stock price data from the top 30 companies as in the case of the Dow Jones 30. Furthermore, five backtesting experiments were conducted for each trading agent to facilitate the performance comparison of automated stock trading systems in each stock market, as in the case of the Dow Jones. Meanwhile, the start time of the training, validation, and test sections was the same as in the Dow Jones, but the end time of the test section was different because the number of stock opening days in the U.S., Korea, and Japan was different. Thus, unlike the case of the Dow Jones 30, the trading end date was 13 August 2020 and 21 July 2020, respectively, for the KOSPI30 and JPX30.
In the KOSPI and JPX domains, we conducted five experiments per agent and obtained the average value by evaluation metrics, shown in
Table 2 and
Table 3.
Figure 4 and
Figure 5 offer a comparison of the cumulative returns of the five agents and each index by a box plot. Each table and figure demonstrates that the automated stock trading system could not guarantee stable returns. Although in the JPX market, the ensemble strategy and Remake Ensemble recorded significant average returns, standard deviations of their cumulative returns are very high at 48.807 and 30.192, respectively. In other words, variances of the cumulative return are considerable for each of the five experiments. Even in the case of the KOSPI market, all trading agents generated lower average returns than KOSPI30.
6. Diversification of Trading Strategies
As shown in the previous sections, several empirical analyses were conducted in different stock markets. Although some agents generated cumulative returns higher than the benchmark indexes, the differences in the cumulative return values for each experiment were huge. Moreover, the ensemble strategy failed to show stunning results in the Dow Jones 30. As shown in
Figure 6, only one experiment iteration exceeded the CR of the DJIA. For this reason, we tried to improve it to make it a more potent DRL-based stock trading model.
There were two main criteria for robust models that we thought of. The first was whether the performance of the DRL-based trading agent used for automated stock trading could be improved over the original model. Performance here refers to the average cumulative return for each agent. The second was whether at least one of the agents could consistently guarantee a higher cumulative return than the benchmark index in all experiments over the same period. No matter how much the average cumulative return is higher than the original model, stable profit cannot be ensured if the trading agent gets a lower value than the benchmark index in the other iterations.
We conducted experiments based on the KOSPI market because all trading agents’ average return was lower than the benchmark index. This means the original model performed the worst in the KOSPI market. If the performance improvement in the KOSPI market was successful, we tried to determine whether a general application is possible by expanding the model application to the JPX and DJIA later. We thought about how to improve the original model and tried various methods. As part of these methods, we decided to change the trading strategy of the model according to a hypothesis that we thought could improve the performance. First, we adjusted the values of the validation window and the rebalance window. This attempt was based on the hypothesis that changing the validation term to a shorter period than the existing 63 days would make the trading agent learn better and perform better. However, the performance did not improve, so this method did not pay off.
Secondly, we adjusted the turbulence threshold. The turbulence threshold is a hyperparameter generated by the authors of [
10] that reflects risk aversion for market crashes such as wars, the collapse of stock market bubbles, sovereign debt default, and financial crises. To regulate the risk in a worst-case scenario such as the 2008 global financial crisis, they used the financial turbulence index to measure extreme asset price movements [
47]. According to them, when the turbulence index is higher than a threshold, which indicates low market conditions, trading agents stop buying and sell all stocks. When the turbulence index is below the threshold, then agents resume trading. We hypothesized that the appropriate turbulence threshold is different for each market, and we expected trading agents to perform better in the KOSPI market by adjusting the turbulence index. According to the source code, the appropriate threshold ranges from 90 to 150, so we set the thresholds over the range of the minimum of 90 and maximum of 150. However, this also had no significant impact on performance. We tried putting the threshold to zero, but it produced a similar result.
While the previous methods failed to improve the original model, we checked the trading process of the model by analyzing the source code. In the model, the agent buys and sells shares as follows:
Step 1. Create an action space corresponding to 30 stocks and recognize the action normalized to [−1, 1] as a selling or buying signal, respectively, since the RL algorithms A2C and PPO define the policy directly on a Gaussian distribution, which needs to be normalized and symmetric.
Step 2. If the action is below the selling threshold, the stock is sold, and on the contrary, if the action is higher than the buying threshold, the stock is purchased.
Step 3. At this time, the number of shares sold or bought is that signal times , which is a predefined parameter that sets the maximum number of shares for each buying or selling action. In other words, the model was designed to buy or sell shares relative to the strength of the action signal.
We found three interesting points in this process. The first is that the type of shares traded through the model is an actual number, not a natural number. Although it is not impossible to trade stocks on a decimal basis, we judged that the model becomes clearer when stocks are traded in the form of natural numbers. In the model, shares were traded in real numbers with decimal points because the model did not integrate the signal and used it for trading. We transformed the signal into an integer so that the model would take the form of more straightforward stock trading. The second was that there was no holding stock in each trading window. This is because both the buying and selling thresholds are set to zero in the model. If the action is below zero, the model sells the stock, and if the action is more than zero, the model buys the stock, as shown in Step 2, so holding stocks occurs when the action is zero. For this reason, we decided to adjust the buying and selling threshold values to make a case for holding stocks. Finally, what is interesting is that is set to 100. We thought 100 shares were too many for the average small investor to trade at once, so we also felt the need to lower .
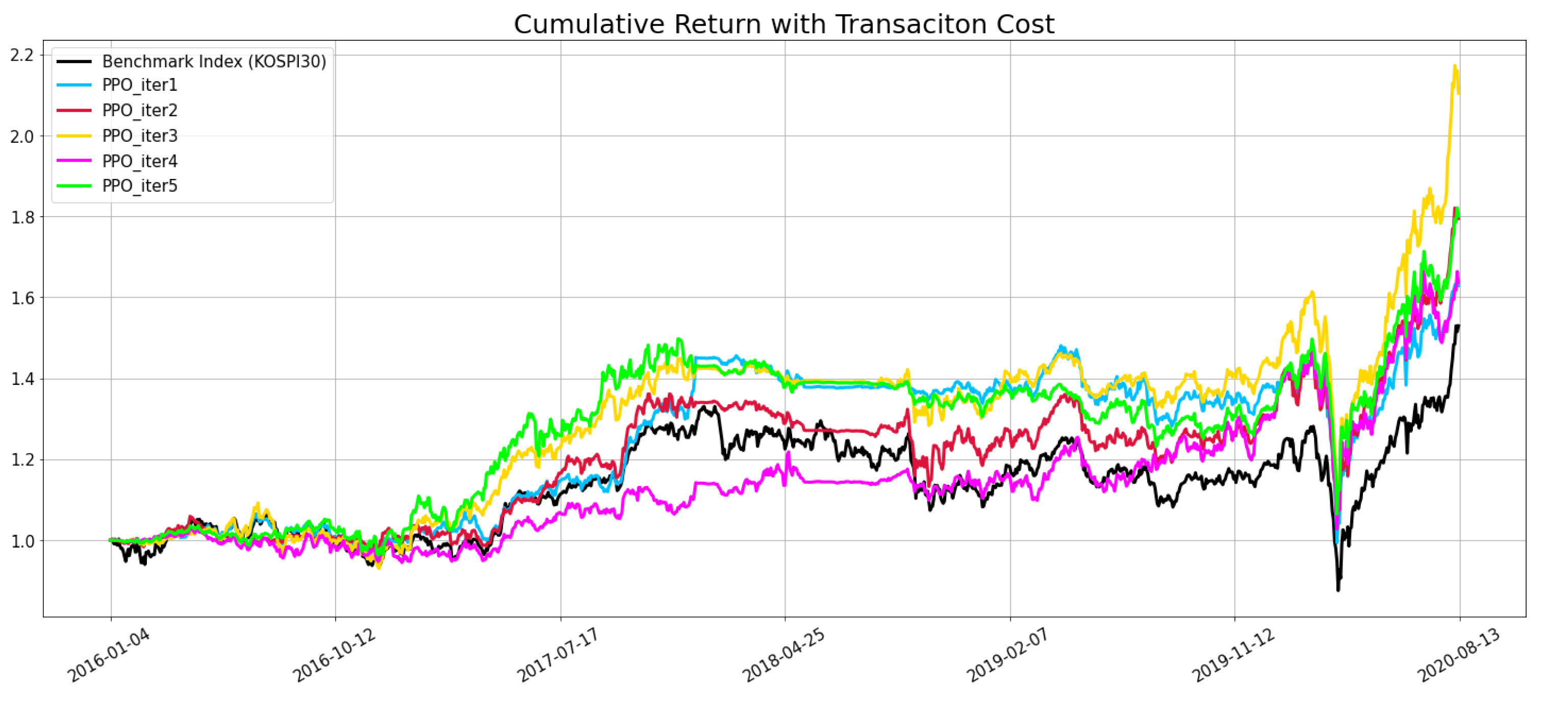
We tried to improve the model’s performance in the KOSPI market with the earlier adjustments. These adjustments have in common that they transformed the trading process of the model into a more conservative and general form. We adjusted stock trading units, adding cases of holding shares and reducing the number of shares traded once we changed the model to resemble the usual trading behavior of small investors. We observed whether the model’s performance was improved through changing the trading strategy. We tested whether the model’s performance was enhanced by changing
, buying threshold, and selling threshold based on the PPO agent because the trading agent with the best average performance in the KOSPI market was PPO. The PPO agent obtained a higher cumulative return than the KOSPI30 in all five experimental iterations through the trading strategy changes. The values of
, buying threshold, and selling threshold were 10, 3, and 0, respectively, and the results are shown in
Figure 7.
We extended the application of this trading strategy to A2C, DDPG, the ensemble strategy, and Remake Ensemble Trading agents and conducted five experiments, as in the case of PPO. As a result, the average performance of all agents was better than before the trading strategy adjustment, and overall performance was better for individual iterations. In particular, in the case of the ensemble strategy, similar to PPO, the cumulative return was higher than the benchmark index in all its periods, and the average performance was also the best of the five trading agents. Although limited to the KOSPI market, in the end, we successfully improved the model in a way that met both of the conditions of robustness that we thought of earlier.
Table 4 describes these results, and in cases where agents performed better than the KOSPI 30, the text is marked in bold.
We applied the same trading strategy to the Dow Jones 30 and JPX and compared the cumulative returns between each benchmark index and the trading agents. The results are shown in
Table 5 and
Table 6, respectively. As shown in
Table 6, for JPX stocks, the new trading state showed good performance, as in the case of the KOSPI. In contrast, in the Dow Jones 30, unlike in the case of KOSPI, the new trading strategy significantly reduced all agents’ performance.
As mentioned earlier, the core of the new trading strategy is conservatism. Given that this strategy backfired in the Dow Jones 30 market, it can be assumed that aggressive trading strategies may be more effective in the Dow Jones 30 market. On the other hand, in the case of the JPX market, similar performance improvements to the KOSPI were made under the new trading strategy established based on the KOSPI. Thus it can be assumed that the JPX and KOSPI markets are almost identical, and the conservative approach is relatively practical. Of course, it can be seen that if we are to improve performance better than in the previous experiment, we need sophisticated and customized trading strategies for the Dow Jones 30 and JPX rather than the strategy tailored to the KOSPI, which sets
, buying threshold, and selling threshold to 10, 3, 0, respectively. Our experimental results are available on
https://github.com/kongminseok/EAASTUDRL.
7. Conclusions and Future Work
In this paper, we empirically analyzed the performance of automated stock trading based on deep reinforcement learning through experiments to validate the contents of [
10]. We conducted empirical analysis in three ways to determine whether it is possible to generalize automated stock trading, including several DRL-based trading agents. First, we added a new trading agent, which is named ’Remake Ensemble’, and it is based on the ensemble strategy. Since Remake Ensemble showed no significant performance difference compared to other agents, we concluded that adding several different DRL algorithms to the ensemble-based trading agent would make it difficult to increase the robustness of the model.
Furthermore, we expanded the trading model to the KOSPI and JPX markets for analysis and wondered if there was a way to increase the model’s performance in each market. As one of the methods, the trading strategy was changed to a more conservative and general form by adjusting several model hyperparameters. A new trading strategy was applied based on the KOSPI, which had the lowest performance.
Finally, by changing the trading strategy of the original model, we observed that the model’s robustness could be improved in the KOSPI and JPX markets. The average performance of all agents was better than before changing the trading strategy, and the whole performance was better for individual iterations. However, the performance was low when the same model was applied to the Dow Jones 30.
This empirical analysis is only one possible direction toward a robust automated stock trading system. It cannot be guaranteed that it is optimal for a more stable and robust model. If the experimental iteration exceeds five times, it is unknown whether the PPO and the ensemble strategy still guarantee a higher cumulative return than the KOSPI30 for all iterations. Further, there is no promise that the model will yield stable returns if the trading period or timing are changed.
Although it is clear that the ensemble strategy presented in [
10] is a novel and innovative approach, we thought the automated stock trading system still had many potential improvements that have not yet been empirically demonstrated apart from the experiments we conducted. The key is generalization and higher profit. One of the methods related to generalization is the possibility of performance improvement in the Dow Jones 30 and JPX markets through customizing the trading strategy, as in the KOSPI market. Suppose it is possible ensuring a higher return than the benchmark index of the three markets. In that case, it can be challenging to make a general model guarantee stable returns in more diverse markets such as the S&P 500 and KOSDAQ. These things can be called market generalization. The other task is to create a model that assures higher profits than the benchmark index during all trading intervals in various markets. It can be called time generalization.
The original model verifies the agent’s performance based on the current SR, but other metrics such as CR can be used instead of the SR. In addition, a way to replace the turbulence threshold by reflecting rates such as the U.S. Federal Reserve’s interest rates in the environment may be a keyword for higher prediction and performance improvement. This idea is conceived based on the observation that the Fed’s recent rate hike and the financial market shrinkage were carried out in parallel. In addition to interest rates, major economic indicators such as oil prices and the consumer price index (CPI) can be used as components of the environment to train the model. Designing rewards more elaborately can also be a topic for future work.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}