
Gender Recognition of Bangla Names Using Deep Learning Approaches



Abstract
:1. Introduction
2. Related Works
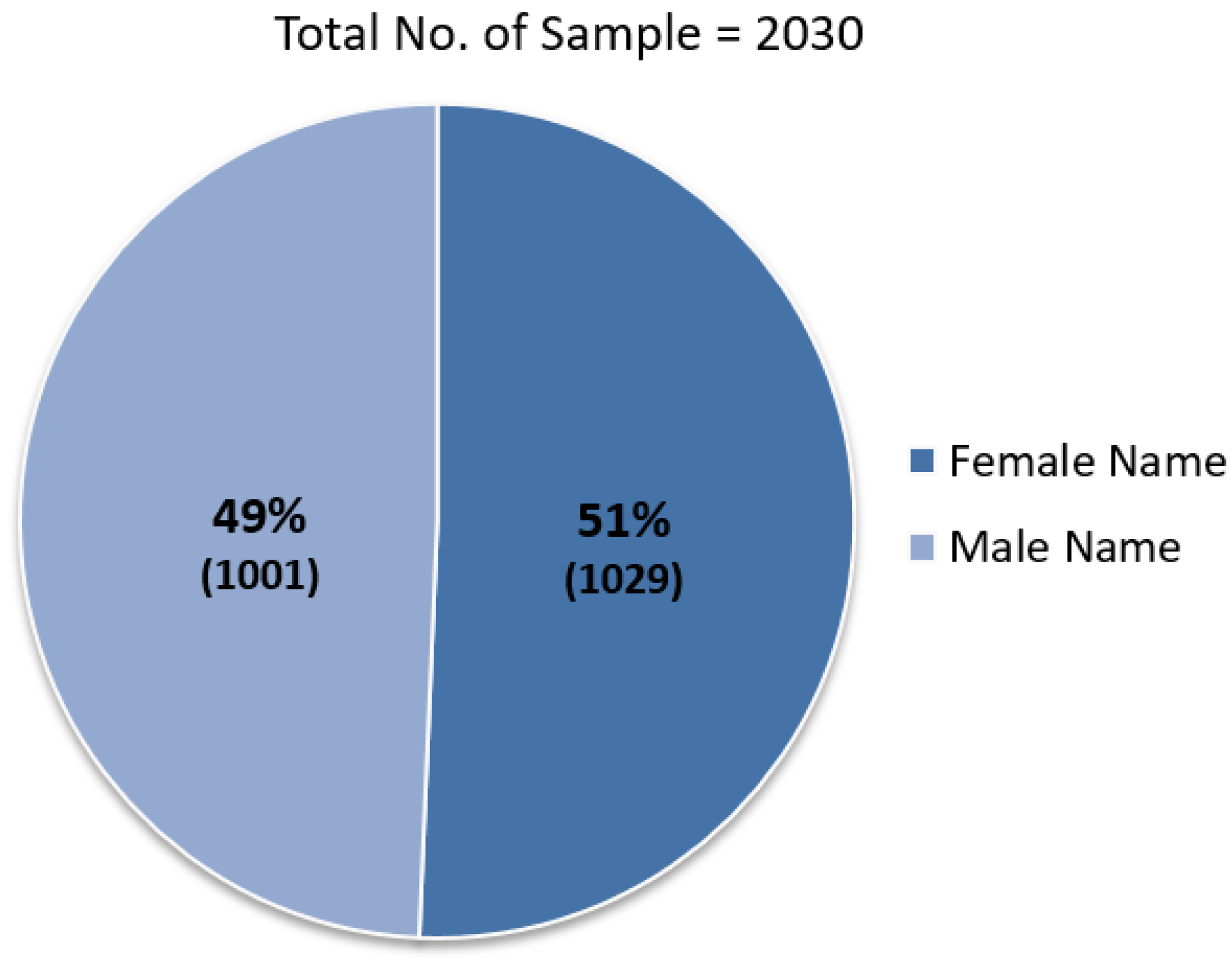
3. Dataset Preparation
4. The Proposed Framework
4.1. Char-Level Sequence Generator
4.2. Char-Level Embedding
4.3. Feature Extractor and Binary Classifier
5. DNN-Based Models
5.1. Convolutional Neural Network
5.2. Long Short-Term Memory
5.3. Loss Function
5.4. Optimizer
5.5. Model Configurations
6. Experimental Setup
7. Prediction and Performance Analysis
8. Experimental Results and Discussion
9. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Iman Ghosh. Ranked: The 100 Most Spoken Languages around the World. Last Modified 15 February 2020. Available online: https://www.visualcapitalist.com/100-most-spoken-languages/ (accessed on 8 January 2021).
- Sen, O.; Fuad, M.; Islam, M.N.; Rabbi, J.; Masud, M.; Hasan, M.K.; Awal, M.A.; Fime, A.A.; Fuad, M.T.H.; Sikder, D.; et al. Bangla Natural Language Processing: A Comprehensive Analysis of Classical, Machine Learning, and Deep Learning-Based Methods. IEEE Access 2022, 10, 38999–39044. [Google Scholar] [CrossRef]
- Patel, S.; Shah, B.; Kaur, P. Leveraging User Comments in Tweets for Rumor Detection. In Advances in Intelligent Systems and Computing; Springer: Singapore, 2022; Volume 1388. [Google Scholar] [CrossRef]
- Bhowmik, N.; Arifuzzaman, M.; Mondal, M. Sentiment Analysis on Bangla Text Using Extended Lexicon Dictionary and Deep Learning Algorithms; Elsevier Inc.: Amsterdam, The Netherlands, 2022; Volume 13, pp. 1–14. [Google Scholar]
- Ani, J.F.; Islam, M.; Ria, N.J.; Akter, S.; Masum AK, M. Estimating Gender Based On Bengali Conventional Full Name With Various Machine Learning Techniques. In Proceedings of the 2021 12th International Conference on Computing Communication and Networking Technologies (ICCCNT), Kharagpur, India, 6–8 July 2021; pp. 1–6. [Google Scholar] [CrossRef]
- Abdallah, E.E.; Alzghoul, J.R.; Alzghool, M. Age and Gender prediction in Open Domain Text. Procedia Comput. Sci. 2020, 170, 563–570. [Google Scholar] [CrossRef]
- Karako, C.; Manggala, P. Using image fairness representations in diversity-based re-ranking for recommendations. In Proceedings of the Adjunct Publication of the 26th Conference on User Modeling, Adaptation and Personalization, Singapore, 8–11 July 2018; pp. 23–28. [Google Scholar]
- Yao, S.; Huang, B. Beyond parity: Fairness objectives for collaborative filtering. In Advances in Neural Information Processing Systems; MIT press: Cambridge, MA, USA, 2017; pp. 2921–2930. [Google Scholar]
- Gattal, A.; Djeddi, C.; Bensefia, A.; Ennaji, A. Handwriting Based Gender Classification Using COLD and Hinge Features. In Lecture Notes in Computer Science Image and Signal Processing; Springer: Cham, Switzerland, 2020; pp. 233–242. [Google Scholar]
- Roy, P.; Bhagath, P.; Das, P. Gender Detection from Human Voice Using Tensor Analysis. In Proceedings of the 1st Joint SLTU and CCURL Conference on Language Resources and Evaluation (LREC), Marseille, France, 16 May 2020; pp. 211–217. [Google Scholar]
- Bérubé, N.; Ghiasi, G.; Sainte-Marie, M.; Larivière, V. Wiki-Gendersort: Automatic gender detection using first names in Wikipedia. arXiv 2020. [Google Scholar] [CrossRef] [Green Version]
- To, H.Q.; Nguyen, K.V.; Nguyen, N.L.; Nguyen, A.G. Gender Prediction Based on Vietnamese Names with Machine Learning Techniques. In Proceedings of the 4th International Conference on Natural Language Processing and Information Retrieval, Seoul, Republic of Korea, 18–20 December 2020. [Google Scholar]
- Sotelo, A.F.; Gómez-Adorno, H.; Esquivel-Flores, O.; Bel-Enguix, G. Gender Identification in Social Media Using Transfer Learning. In Lecture Notes in Computer Science Pattern Recognition; Springer: Cham, Switzerland, 2020; pp. 293–303. [Google Scholar]
- Kowsher, M.; Sanjid, M.Z.I.; Das, A.; Ahmed, M.; Sarker, M.M.H. Machine Learning and Deep Learning based Information Extraction from Bangla Names. Procedia Comput. Sci. 2020, 178, 224–233. [Google Scholar] [CrossRef]
- Karim, R.; Islam, M.A.; Simanto, S.R.; Chowdhury, S.A.; Roy, K.; Al Neon, A.; Hasan, M.S.; Firoze, A.; Rahman, R.M. A Step Towards Information Extraction: Named Entity Recognition in Bangla Using Deep Learning. J. Intell. Fuzzy Syst. 2019, 37, 1–13. [Google Scholar] [CrossRef]
- Chollet, F. Deep Learning with Python; Manning Publications: New York, NY, USA, 2017. [Google Scholar]
- Shuai, Q.; Wang, R.; Jin, L.; Pang, L. Research on Gender Recognition of Names Based on Machine Learning Algorithm. In Proceedings of the 10th International Conference on Intelligent Human-Machine Systems and Cybernetics (IHMSC), Hangzhou, China, 25–26 August 2018; Volume 2, pp. 335–338. [Google Scholar]
- Zhang, S.; Zhang, S.; Wang, X. Automatic Recognition of Chinese Organization Name Based on Conditional Random Fields. In Proceedings of the International Conference on Natural Language Processing and Knowledge Engineering, Beijing, China, 30 August–1 September 2007; pp. 229–233. [Google Scholar]
- Hu, Y.; Hu, C.; Tran, T.; Kasturi, T.; Joseph, E.; Gillingham, M. What’s in a name?—Gender classification of names with character based machine learning models. Data Min. Knowl. Discov. 2021, 35, 1537–1563. [Google Scholar] [CrossRef]
- Rego, R.C.; Silva, V.M. Predicting gender of Brazilian names using deep learning. arXiv 2021, arXiv:2106.10156. [Google Scholar]
- Panchenko, A.; Teterin, A. Detecting gender by full name: Experiments with the russian language. In International Conference on Analysis of Images, Social Networks and Texts; Springer: Cham, Switzerland, 2014; pp. 169–182. [Google Scholar]
- Tripathi, A.; Faruqui, M. Gender prediction of Indian names. In Proceedings of the IEEE Technology Students’ Symposium, Kharagpur, India, 14–16 January 2011; pp. 137–141. [Google Scholar] [CrossRef]
- Tang, Q.; Lin, H. Research on Gender Recognition for Character in Text. J. Chin. Inf. Process. 2010. Available online: https://en.cnki.com.cn/Article_en/CJFDTotal-MESS201002005.htm (accessed on 18 January 2020).
- Paiva, E.; Paim, A.; Ebecken, N. Convolutional Neural Networks and Long Short-Term Memory Networks for Textual Classification of Information Access Requests. IEEE Lat. Am. Trans. 2021, 19, 826–833. [Google Scholar] [CrossRef]
- Han, X.; Li, B.; Wang, Z. An attention-based neural framework for uncertainty identification on social media texts. Tsinghua Sci. Technol. 2020, 25, 117–126. [Google Scholar] [CrossRef]
- Arkhipenko, K.; Kozlov, I.; Trofimovich, J.; Skorniakov, K.; Gomzin, A.; Turdakov, D. Comparison of neural network architectures for sentiment analysis of Russian tweets. Proc. Dialogue 2016. Available online: http://www.dialog-21.ru/media/3380/arkhipenkoetal.pdf (accessed on 20 January 2020).
- Wang, W.; Gang, J. Application of Convolutional Neural Network in Natural Language Processing. In Proceedings of the International Conference on Information Systems and Computer Aided Education (ICISCAE), Changchun, China, 6–8 July 2018; pp. 64–70. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long Short-Term Memory. J. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Yao, L.; Guan, Y. An Improved LSTM Structure for Natural Language Processing. In Proceedings of the IEEE International Conference of Safety Produce Informatization (IICSPI), Chongqing, China, 10–12 December 2018; pp. 565–569. [Google Scholar] [CrossRef]
- Keras API Docs. Binary Cross-Entropy Class. Available online: https://keras.io/api/losses/probabilistic_losses/#binarycrossentropy-class (accessed on 2 January 2021).
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2015, arXiv:1412.6980. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Article | Origin of Names | Language | Processing Methods | Dataset and Results |
|---|---|---|---|---|
| Q. Shuai et al. [17] | Chinese | English | Naïve Bayes, support vector, decision tree, and maximum tree classifier-based models. | NLTK (Natural Language Toolkit) dataset with 7944 entries is used for English names. These models achieved around 72%, 73%, 71%, and 69% accuracy, respectively. |
| Y. Hu et al. [19] | USA | English | Character-based machine learning models such as LSTM and BERT. | A dataset of 21M unique first names from SSA and YAHOO data. LSTM and BERT-based different models obtained approximately 87% and 88% accuracy, respectively. |
| C. B. Rego et al. [20] | Brazilian | English | DNN-based models, including MLP, RNN, GRU, CNN, and Bi-LSTM. | The dataset consists of 100,787 Brazilian names, of which 54.82% are female names and 45.18% are male, based on 2010 CENSO data. CNN, Bi-LSTM, RNN, MLP, and GRU-based models achieved 92%, 95%, 93%, 86%, and 94% accuracy, respectively. |
| A. Panchenko et al. [21] | Russian | English | Statistical models based on one type of features: endings, character trigrams, and dictionary. | A dataset of 100,000 Russian full names from Facebook. Accuracy of up to 96% is obtained from a combined model: endings + 3-g + dictionary. |
| A. Tripathi et al. [22] | Indian | English | Support vector machine (SVM)-based different classifiers. | A dataset of 2000 Indian names with almost equal numbers of Gujarati, Punjabi, Bangla, Hindi, Urdu, Tamil, and Telugu names. The compiled training data contained 890 female and 1110 male names. Achieved maximum F1 score is 94.9%. |
| Model No. | Model Name | Embedding Layer | Conv1D Layer | MaxPooling1D Layer | LSTM Layer | Bi-LSTM Layer | Fully Connected Layer | Dropout Layer | Classification Layer |
|---|---|---|---|---|---|---|---|---|---|
| Model 1 | LSTM Based Model | Dimension: 64 | N/A | N/A | Layer: 1 Unit: 64 | N/A | Layer: 1 Unit: 256 | Layer: 1 (40%) | Unit: 1 (Sigmoid) |
| Model 2 | Bi-LSTM Based Model | Dimension: 64 | N/A | N/A | N/A | Layer: 1 Unit: 64 | Layer: 1 Unit: 128 | Layer: 1 (40%) | Unit: 1 (Sigmoid) |
| Model 3 | Stacked LSTM Based Model | Dimension: 64 | N/A | N/A | Layer: 2 Unit: 32 (L1), 64 (L2) | N/A | Layer: 1 Unit: 256 | Layer: 1 (40%) | Unit: 1 (Sigmoid) |
| Model 4 | Conv1D Based Model | Dimension: 64 | Layer: 3 Filter: 16 (L1), 32 (L2), 64 (L3) Filter Size: 3 | Layer: 2 Pooling Size: 2 | N/A | N/A | Layer: 1 Unit: 256 | Layer: 1 (40%) | Unit: 1 (Sigmoid) |
| Model 5 | Conv1D & Stacked Bi-LSTM Based Model | Dimension: 64 | Layer: 3 Filter: 16 (L1), 32 (L2), 64 (L3) Filter Size: 3 | Layer: 2 Pooling Size: 2 | N/A | Layer: 3 Unit: 64 (L1), 128 (L2), 256 (L3) | Layer: 1 Unit: 128 | Layer: 1 (40%) | Unit: 1 (Sigmoid) |
| Data Type | Data Point |
|---|---|
| Training | 1643 |
| Validation | 183 |
| Test | 204 |
| Model Name | Accuracy | Precision | Recall | F1-Score | ROC AUC Score |
|---|---|---|---|---|---|
| LSTM-Based Model | 0.715686 | 0.638712 | 0.980198 | 0.773438 | 0.718254 |
| Bi-LSTM-Based Model | 0.872549 | 0.878788 | 0.861386 | 0.870012 | 0.872441 |
| Stacked LSTM-Based Model | 0.813725 | 0.811881 | 0.811881 | 0.811881 | 0.813708 |
| Conv1D-Based Model | 0.921569 | 0.929293 | 0.910891 | 0.920021 | 0.921465 |
| Conv1D and Stacked Bi-LSTM-Based Model | 0.921569 | 0.938144 | 0.900991 | 0.919192 | 0.921369 |
| Gender Classification Model Name | Prediction Accuracy | ||
|---|---|---|---|
| Training | Validation | Test | |
| LSTM-Based Model | 83.51% | 75.96% | 71.57% |
| Bi-LSTM-Based Model | 88.68% | 85.79% | 87.25% |
| Stacked LSTM-Based Model | 86.62% | 81.97% | 81.37% |
| Conv1D-Based Model | 95.65% | 93.44% | 92.16% |
| Conv1D and Stacked Bi-LSTM-Based Model | 94.96% | 90.26% | 92.16% |
| Best Achieved Accuracy | Best Performing Classifier | Second Best Performing Classifier | Least Accuracy | Least Performing Classifier | Best F1 Score |
|---|---|---|---|---|---|
| 92.16% | Conv1D-Based Model | Conv1D and Stacked Bi-LSTM-Based Model | 71.57% | LSTM-Based Model | 0.920 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kabir, M.H.; Ahmad, F.; Hasan, M.A.M.; Shin, J. Gender Recognition of Bangla Names Using Deep Learning Approaches. Appl. Sci. 2023, 13, 522. https://doi.org/10.3390/app13010522
Kabir MH, Ahmad F, Hasan MAM, Shin J. Gender Recognition of Bangla Names Using Deep Learning Approaches. Applied Sciences. 2023; 13(1):522. https://doi.org/10.3390/app13010522
Chicago/Turabian StyleKabir, Md. Humaun, Faruk Ahmad, Md. Al Mehedi Hasan, and Jungpil Shin. 2023. "Gender Recognition of Bangla Names Using Deep Learning Approaches" Applied Sciences 13, no. 1: 522. https://doi.org/10.3390/app13010522